作者:來自 Elastic?Carlos Delgado
kNN 是什么?
語義搜索(semantic search)是相關性排名的強大工具。 它使你不僅可以使用關鍵字,還可以考慮文檔和查詢的實際含義。
語義搜索基于向量搜索(vector search)。 在向量搜索中,我們要搜索的文檔具有為其計算的向量嵌入。 這些嵌入是使用機器學習模型計算的,并作為向量返回,與我們的文檔數據一起存儲。
執行查詢時,將使用相同的機器學習模型來計算查詢文本的嵌入。 語義搜索包括通過將查詢嵌入與文檔嵌入進行比較來查找最接近查詢的結果。
kNN(或 k nearest neighbors - k 最近鄰)是一種用于獲取與特定嵌入最接近的前 k 個結果的技術。
使用嵌入計算查詢的 kNN 有兩種主要方法:精確和近似。 這篇文章將幫助你:
- 了解什么是精確和近似 kNN 搜索
- 如何為這些方法準備索引
- 如何確定哪種方法最適合你的用例
精確 kNN:搜索所有內容
計算更接近結果的一種方法是將所有現有文檔嵌入與查詢的文檔嵌入進行比較。 這將確保我們獲得盡可能最接近的匹配,因為我們將比較所有匹配。 我們的搜索結果將盡可能準確,因為我們正在考慮整個文檔語料庫并將所有文檔嵌入與查詢嵌入進行比較。
當然,與所有文檔進行比較有一個缺點:需要時間。 我們將使用相似度函數對所有文檔逐一計算嵌入相似度。 這也意味著我們將線性擴展 —— 文檔數量增加一倍可能需要兩倍的時間。
可以使用 script_score 和用于計算向量之間相似度的向量函數在向量場上進行精確搜索。
近似 kNN:一個很好的估計
另一種方法是使用近似值而不是考慮所有文檔。 為了提供 kNN 的有效近似,Elasticsearch 和 Lucene 使用分層導航小世界 HNSW (Hierachical Navigation Small Worlds)。
HNSW 是一種圖數據結構,它維護不同層中靠近的元素之間的鏈接。 每層都包含相互連接的元素,并且還與其下方層的元素相連接。 每層包含更多元素,底層包含所有元素。

可以把它想象成開車:有高速公路、道路和街道。在高速公路上行駛時,你會看到一些描述高層次區域(如城鎮或社區)的出口標志。然后你會到達一條有具體街道指示的道路。一旦你到達某條街道,你就可以找到具體的地址,以及同一社區內的其他地址。
HNSW(Hierarchical Navigable Small World)結構類似于此,它創建了不同層次的向量嵌入。它計算離初始查詢較近的 “高速公路”,選擇看起來更有希望的出口,繼續尋找更接近目標地址的地方。這在性能方面非常優秀,因為它不必考慮所有文檔,而是使用這種多層次的方法快速找到接近目標的近似結果。
但是,這只是一個近似值。并不是所有節點都是互聯的,這意味著可能會忽略某些更接近特定節點的結果,因為它們可能沒有連接。節點的互聯程度取決于 HNSW 結構的創建方式。
HNSW 的效果取決于多個因素:
-
它是如何構建的。HNSW 的構建過程會考慮一定數量的候選節點,作為某一特定節點的近鄰。增加考慮的候選節點數量會使結構更精確,但會在索引時花費更多時間。dense vector index_options 中的 ef_construction 參數用于此目的。
-
搜索時考慮的候選節點數量。在尋找更近結果時,過程會跟蹤一定數量的候選節點。這個數量越大,結果越精確,但搜索速度會變慢。kNN 參數中的 num_candidates 控制這種行為。
-
我們搜索的分段數量。每個分段都有一個需要搜索的 HNSW 圖,其結果需要與其他分段圖的結果結合。分段越少,搜索的圖就越少(因此速度更快),但結果集的多樣性會減少(因此精度較低)。
總的來說,HNSW 在性能和召回率之間提供了良好的權衡,并允許在索引和查詢兩方面進行微調。
使用 HNSW 進行搜索可以在大多數情況下通過 kNN 搜索部分完成。對于更高級的用例,也可以使用 kNN 查詢,例如:
- 將 kNN 與其他查詢結合(作為布爾查詢或固定查詢的一部分)
- 使用 function_score 微調評分
- 提高聚合和字段折疊(field collapse)的多樣性
你可以在這篇文章中查看關于 kNN 查詢及其與 kNN 搜索部分的區別。我們將在下面深入討論何時使用這種方法與其他方法。
為精確和近似搜索建立索引
dense_vector 字段類型
對于存儲嵌入,dense_vector 字段有兩種主要的索引類型可供選擇:
-
flat 類型(包括 flat 和 int8_flat):存儲原始向量,不添加 HNSW 數據結構。使用 flat 索引類型的 dense_vector 將始終使用精確的 kNN,kNN 查詢將執行精確查詢而不是近似查詢。
-
HNSW 類型(包括 hnsw 和 int8_hnsw):創建 HNSW 數據結構,允許使用近似 kNN 搜索。
這是否意味著你不能對 HNSW 字段類型使用精確的 kNN?并非如此!你可以通過 script_score 查詢使用精確 kNN,也可以通過 kNN 部分和 kNN 查詢使用近似 kNN。這樣可以根據你的搜索用例提供更多的靈活性。
使用 HNSW 字段類型意味著需要構建 HNSW 圖結構,這需要時間、內存和磁盤空間。如果你只會使用精確搜索,可以使用 flat 向量字段類型。這確保了你的嵌入索引是最佳的,并且占用更少的空間。
請記住,在任何情況下都應避免將嵌入存儲在 _source 中,以減少存儲需求。
量化
使用量化技術,無論是 flat(int8_flat)還是 HNSW(int8_hnsw)類型的索引,都可以幫助你減少嵌入的大小,從而使用更少的內存和磁盤存儲來保存嵌入信息。
由于搜索性能依賴于盡可能多地將嵌入存儲在內存中,因此你應該始終尋找減少數據的方法。使用量化是在內存和召回率之間進行權衡。
如何在精確搜索和近似搜索之間做出選擇?
沒有一種適用于所有情況的答案。你需要考慮多個因素,并進行實驗,以找到性能和準確性之間的最佳平衡:
數據規模
不應該不惜一切代價避免搜索所有內容。根據你的數據規模(文檔數量和嵌入維度),進行精確的 kNN 搜索可能是合理的。
作為一個經驗法則,如果需要搜索的文檔少于一萬,可能表明應該使用精確搜索。請記住,可以提前過濾需要搜索的文檔數量,因此通過應用過濾條件可以限制實際需要搜索的文檔數量。
近似搜索在文檔數量方面具有更好的擴展性,因此如果你有大量文檔需要搜索,或者預計文檔數量會顯著增加,應該選擇近似搜索。

過濾 - filtering
過濾非常重要,因為它減少了需要考慮搜索的文檔數量。在決定使用精確搜索還是近似搜索時,需要考慮這一點。可以使用 query filters 來減少需要考慮的文檔數量,無論是精確搜索還是近似搜索。
然而,近似搜索在過濾時采用了不同的方法。在使用 HNSW 進行近似搜索時,查詢過濾器將在檢索到前 k 個結果后應用。這就是為什么與 kNN 查詢一起使用查詢過濾器被稱為 kNN 的后過濾。
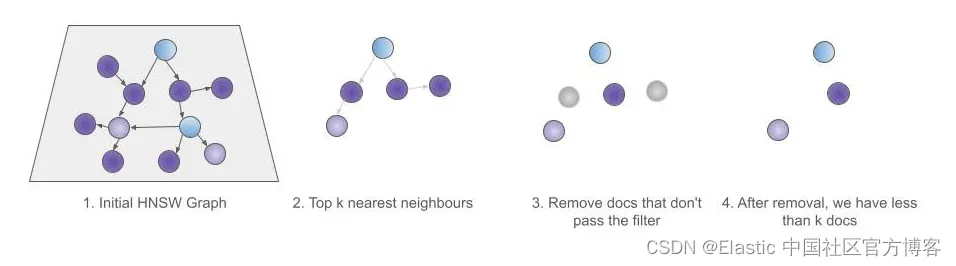
這種特定的 kNN 查詢過濾器被稱為 kNN 預過濾器,因為它在檢索結果之前應用,而不是之后。因此,在使用 kNN 查詢的上下文中,常規查詢過濾器被稱為后過濾器。
幸運的是,還有另一種與 kNN 一起使用的方法,即在 kNN 查詢本身中指定過濾器。 當遍歷 HNSW 圖收集結果時,此過濾器適用于圖元素,而不是事后應用。 這確保返回前 k 個元素,因為將遍歷圖 - 跳過未通過過濾器的元素 - 直到我們獲得前 k 個元素。
即將推出的功能
即將推出的一些改進將有助于精確和近似 kNN。
Elasticsearch 將增加將 dense_vector 類型從 flat 升級到 HNSW 的功能。這意味著你可以先使用 flat 向量類型進行精確 kNN,當需要擴展時可以開始使用 HNSW。使用近似 kNN 時,你的段將透明地被搜索,并在合并時自動轉換為 HNSW。
一個新的精確 kNN 查詢將被添加,以便使用簡單的查詢來對 flat 和 HNSW 字段進行精確 kNN,而不是依賴于 script score 查詢。這將使精確 kNN 更加簡便。
結論
那么,你應該在文檔上使用近似 kNN 還是精確 kNN 呢?請檢查以下幾點:
- 文檔數量:如果少于一萬(應用過濾器后),可能適合使用精確搜索。
- 你的搜索是否使用了過濾器:這會影響要搜索的文檔數量。如果需要使用近似 kNN,請記住使用 kNN 預過濾器以獲取更多結果,代價是性能下降。
你可以通過使用 HNSW dense_vector 進行索引,并將 kNN 搜索與 script_score 進行精確 kNN 的對比,來比較兩種方法的性能。這允許在使用相同字段類型的情況下比較兩種方法(如果決定使用精確搜索,請記住將 dense_vector 字段類型更改為 flat)。
祝你搜索愉快!
準備將 RAG 集成到你的應用中嗎?想嘗試在向量數據庫中使用不同的 LLMs 嗎? 查看我們在 Github 上的 LangChain、Cohere 等示例筆記本,并參加即將開始的 Elasticsearch 工程師培訓吧!
原文:kNN in Elasticsearch: How to choose between exact and approximate kNN search — Elastic Search Labs


)
 一面+二面面經)



--OpenFeign超時控制)








)


)