1、初識并發編程
1.1、串行,并行,并發
串行(serial):一個cpu上按順序完成多個任務;
并行(parallelism):任務數小于或等于cup核數,多個任務是同時執行的;
并發(concurrency):一個CPU采用時間片管理方式,交替的處理多個任務。一般是任務數多余cpu核數,通過操作系統的各種任務調度算法,實現用多個任務一起執行(實際上總有一些任務不在執行,因為切換任務的速度相當快,看上去一起執行而已)。
1.2、進程,線程,協程
通過案例了解概念:
進程:我的工廠有一條生產線,這條生產線就是一個進程。
線程:在我工廠的一條生產線上,我安排了五名工人在生產線上工作,五名工人就是五個線程。
一條生產線上有多名工人就是單進程多線程。
多個生產線上有多名工人就是多進程多線程。
協程:作為一個資本家,我看到工人在生產任務較輕的時候休息是不能接受的,于是我規定當生產線沒有任務時,就去幫工廠打掃衛生,即如果一個線程等待某些條件,可以充分利用這個時間去做其它事情,這就是協程。

進程,線程和協程的總結:
①、線程是程序執行的最小單位,而進程是操作系統分配資源的最小單位;
②、一個進程由一個或多個線程組成,線程是一個進程中代碼的不同執行路線;
③、進程之間相互獨立,但同一進程下的各個線程之間共享程序的內存空間(包括代碼段、數據集、堆等)及一些進程級的資源(如打開文件和信號),某進程內的線程在其它進程不可見;
④、調度和切換:線程上下文切換比進程上下文切換要快得多;
⑤、進程(Process):擁有自己獨立的堆和棧,既不共享堆,也不共享棧,進程由操作系統調度;進程切換需要的資源很最大,效率低(是一個具有一定獨立功能的程序關于某個數據集合的一次運行活動);
⑥、線程(Thread):擁有自己獨立的棧和共享的堆,共享堆,不共享棧,標準線程由操作系統調度;線程切換需要的資源一般,效率一般(線程是操作系統能夠進行運算調度的最小單位。它被包含在進程之中,是進程中的實際運作單位);
⑦、協程coroutine):擁有自己獨立的棧和共享的堆,共享堆,不共享棧,協程由程序員在協程的代碼里顯示調度;協程切換任務資源很小,效率高(協程是一種在線程中,比線程更加輕量級的存在,由程序員自己寫程序來管理。)。
1.3、同步,異步
概述:同步和異步強調的是消息通信機制?(synchronous communication/ asynchronous communication)。?
同步:A調用B,等待B返回結果后,A繼續執行。
異步:A調用B,A繼續執行,不等待B返回結果;B有結果了,通知A,A再做處理。
2、線程(Thread)

特點:
①、是操作系統能夠進行運算調度的最小單位。它被包含在進程之中,是進程中的實際運作單位;
②、線程是程序執行的最小單位,而進程是操作系統分配資源的最小單位;
③、一個進程由一個或多個線程組成,線程是一個進程中代碼的不同執行路線;
④、擁有自己獨立的棧和共享的堆,共享堆,不共享棧,標準線程由操作系統調度;
⑤、調度和切換:線程上下文切換比進程上下文切換要快得多。
概述:Python的標準庫提供了兩個模塊:_thread和threading,_thread是低級模塊,threading是高級模塊(threading是對_thread的封裝),大多數情況下,我們只需要使用threading這個高級模塊。
線程的創建方式:
①、方法包裝
②、類包裝
提示:線程的執行統一通過start()方法。
2.1、通過方法包裝創建線程
概述:
①、通過方法包裝創建線程時,線程通過Thread()方法進行創建,Thread()方法有兩個參數,參數1為target,表示線程開啟后執行哪個方法(方法不要帶小括號,帶小括號表示運行(或者說叫調用)某個函數,不帶小括號表示存儲了某個函數的地址),參數2為args,表示執行target指定的函數時傳入的參數(args的類型是元組)。
②、線程通過start()方法開啟,只創建線程而不開啟線程,線程是不會運行的。
實操:通過方法包裝的方式創建兩個線程,線程開啟后都打印信息(為了讓程序慢速運行,引入sleep()函數),通過實例觀察多個線程間是如何運行的。
from threading import Thread
from time import sleep# 線程觸發后運行的函數
def fun1(name):print(f"線程{name},start")for i in range(5):print(f"線程{name}正在打印")# 降低程序運行的速度sleep(1)print(f"線程{name},end")# 程序的入口
if __name__ == '__main__':print("主線程,start")# 創建線程,target表示線程開啟后執行哪個方法,args表示執行方法傳入的參數(args的類型是元組)t1 = Thread(target=fun1,args=("t1",))t2 = Thread(target=fun1,args=("t2",))# 啟動線程t1.start()t2.start()print("主線程,end")運行結果如下:

案例總結:①、主線程,線程t1,線程t2這三個線程是相互獨立的,即使主線程結束其他線程仍然能繼續運行。
②、由于只有一個cpu來處理,所以不同的線程要搶奪同一個打印流進行打印,導致打印順序較亂。
2.2、類包裝創建線程
概述:類包裝創建線程指創建一個實例對象,實例對象對應的類繼承了Thread,線程運行后執行指定類中的run函數(這里是對父類run函數的重寫),指定類中的構造方法還要調用Thread的構造方法,調用指定函數進行線程創建時,參數的個數取決于指定類中__init__除self外參數的個數。
from threading import Thread
from time import sleep# 傳入的參數一定是Thread
class myThread(Thread):def __init__(self,name):# 調用Thread的構造方法Thread.__init__(self)self.name = name# 函數名不能修改,這是對原有實例方法進行重寫def run(self):print(f"線程{self.name},start")for i in range(5):print(f"線程{self.name}正在打印")# 降低程序運行的速度sleep(1)print(f"線程{self.name},end")if __name__ == '__main__':print("主線程,start")# 創建線程t1 = myThread("t1")t2 = myThread("t2")# 啟動線程t1.start()t2.start()print("主線程,end")運行結果如下:

2.3、join()和守護線程
2.3.1、join()
概述:在前面的實操中可以發現,主線程,t1線程和t2線程都作為獨立線程,主線程提前結束也不會影響其他線程的運行,但是如果現在有需求讓主線程等待其他線程結束后再結束主線程,此時就可以用到join()方法。
實操:創建兩個線程,分別為t3和t4,指定主線程要等待t3進程結束再結束主線程。
from threading import Thread
from time import sleepdef fun2(name):for i in range(3):print(f"{name}線程start")sleep(1)print(f"{name}線程end")if __name__ == '__main__':print("主線程開啟")# 創建線程(創建線程時不要省略參數的指定,不如會報錯)t3 = Thread(target=fun2,args=("t3",))t4 = Thread(target=fun2,args=("t4",))# 開啟線程t3.start()t4.start()# 指定主線程在特定線程結束后結束t3.join()print("主線程結束")運行結果如下(為了突出運行結果,這里我選了一個極端的結果,由于t3和t4運行的是同樣的程序,運行速度完成看兩個線程誰搶打印流搶得快,t4有時會在t3結束前結束)

2.3.2、守護線程
概述:有一種線程叫守護線程,主要的特征是它的生命周期隨著主線程的死亡而死亡(由于這種特征導致守護線程一般都是為主線程服務)。在python中,線程通過setDaemon(True|False)方法或daemon屬性賦值為True來設置是否為守護線程。
實操:通過類包裝創建兩個名為t5,t6的線程,當主線程結束時,t5也會自動結束(將t5設置為守護線程)。
from threading import Thread
from time import sleepclass myThread(Thread):def __init__(self,name):Thread.__init__(self)self.name = namedef run(self):for i in range(5):print(f"{self.name}線程start")print(f"{self.name}線程end")if __name__ == '__main__':print("主線程開啟")# 通過類包裝創建線程t5 = myThread("t5")t6 = myThread("t6")# 指定t5為守護線程t5.daemon = True# t5.setDaemon(True)# 運行線程t5.start()t6.start()print("主線程結束")運行結果如下:

注意:
①、需要在線程開啟前設置守護線程;
②、線程正在執行某些耗時的操作或者等待某些資源釋放時,導致線程不能立即終止(可以在run函數中的循環中加入如下語句sleep(1),就會驚奇的發現守護進程不會被回收)。
2.4、全局解釋器鎖GIL問題
概述:在python中,無論你有多少核,在Cpython解釋器中永遠都是假象,同一時間只能執行一個進程,這是python設計的一個缺陷,所以說python中的線程是"含有水分的線程"。
GIL(Global Interpreter Lock):
概述:Python代碼的執行由Python 虛擬機(也叫解釋器主循環,CPython版本)來控制,Python 在設計之初就考慮到要在解釋器的主循環中,同時只有一個線程在執行,即在任意時刻,只有一個線程在解釋器中運行。對Python 虛擬機的訪問由全局解釋器鎖(GIL)來控制,正是這個鎖能保證同一時刻只有一個線程在運行。
注意:GIL并不是Python的特性,它是在實現Python解析器(CPython)時所引入的一個概念,同樣一段代碼可以通過CPython,PyPy,Psyco等不同的Python執行環境來執行,就沒有GIL的問題。然而因為CPython是大部分環境下默認的Python執行環境。所以在很多人的概念里CPython就是Python,也就想當然的把GIL歸結為Python語言的缺陷。
2.5、線程同步和互斥鎖
2.5.1、線程同步
概述:處理多線程問題時,多個線程訪問同一個對象,并且某些線程還想修改這個對象。 這時候,我們就需要用到“線程同步”。 線程同步其實就是一種等待機制,多個需要同時訪問此對象的線程進入這個對象的等待池形成隊列,等待前面的線程使用完畢后,下一個線程再使用。
實操:模擬一個取款案例,創建兩個類,第一個類為賬戶類Account,第二個類為取款類Withdraw,模擬兩個人同時對一個賬戶進行取款的操作,打印取款金額和賬戶余額。
# 模擬取款案例
from threading import Thread
from time import sleep# 定義賬戶類
class Account:def __init__(self,name,money):self.name = nameself.money = money# 定義取款類
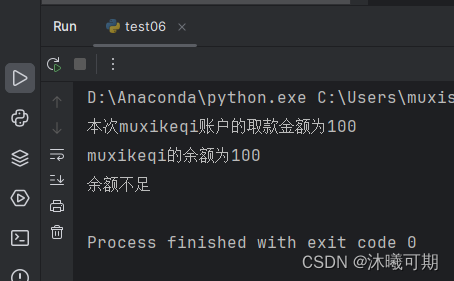
class Withdraw(Thread):def __init__(self,account,drawNum:int):Thread.__init__(self)self.account = accountself.drawNum = drawNum# 定義一個屬性用于統計取出的總數self.totalNum = 0def run(self):# 判斷取款金額是否大于賬戶余額if self.drawNum>self.account.money:return "賬戶余額不足"# 這里暫停一秒是為了讓線程阻塞,產生線程沖突問題sleep(1)self.account.money = self.account.money-self.drawNumself.totalNum += self.drawNumprint(f"本次{self.account.name}的取款金額為{self.totalNum}")print(f"{self.account.name}的余額為{self.account.money}")if __name__ == '__main__':# 創建一個賬戶muxikeqi = Account("muxikeqi",200)# 創建兩個線程模擬兩個人取同一個賬戶的錢boy1 = Withdraw(muxikeqi,200)boy2 = Withdraw(muxikeqi,200)# 開啟線程boy1.start()boy2.start()運行結果如下:

結果分析:導致賬戶余額為負數的主要原有就是sleep(1)語句,兩個線程都判斷賬戶余額是否大于取款金額,滿足就睡眠1秒,由于線程之間是單線程運行,所以會存在先后順序,導致兩個取款人都成功進入后面的取款操作,進而導致取款兩次。要解決這個問題,可以通過"鎖機制"來實現線程同步問題。
2.5.2、互斥鎖
概述:互斥鎖是對共享數據進行鎖定,保證同一時刻只能有一個線程去操作。
要點:
①、必須使用同一個鎖對象。
②、互斥鎖的作用就是保證同一時刻只能有一個線程去操作共享數據,保證共享數據不會出現錯誤問題。
③、使用互斥鎖的好處確保某段關鍵代碼只能由一個線程從頭到尾完整地去執行。
④、使用互斥鎖會影響代碼的執行效率。
⑤、同時持有多把鎖,容易出現死鎖的情況。
注意: 互斥鎖是多個線程一起去搶,搶到鎖的線程先執行,沒有搶到鎖的線程需要等待,等互斥鎖使用完釋放后,其它等待的線程再去搶這個鎖。
知識點補充:
①、threading模塊中定義了Lock變量,這個變量本質上是一個函數,通過調用這個函數可以獲取一把互斥鎖。
②、acquire和release方法之間的代碼同一時刻只能有一個線程去操作。
③、如果在調用acquire方法的時候 其他線程已經使用了這個互斥鎖,那么此時acquire方法會堵塞,直到這個互斥鎖釋放后才能再次上鎖。
實操:為2.5.1小節中的取款案例添加互斥鎖,實現線程同步。
# 為取款案例添加互斥鎖實現線程同步
from threading import Thread, Lock
from time import sleepclass Account:def __init__(self,username,money):self.username = usernameself.money = moneyclass Withdraw(Thread):def __init__(self,account,drawNum):Thread.__init__(self)self.account = accountself.drawNum = drawNumself.totalMoney = 0def run(self):# 這里表示鎖開始的地方,不同的線程從這里開始排隊myLock.acquire()# 判斷取款金額是否大于賬戶余額if self.drawNum > self.account.money:print("余額不足")return "余額不足"sleep(2)self.account.money -= self.drawNumself.totalMoney += self.drawNumprint(f"本次{self.account.username}賬戶的取款金額為{self.totalMoney}")print(f"{self.account.username}的余額為{self.account.money}")# 這里表示鎖結束的地方,到這里鎖就釋放并重新生成讓其他排隊的線程去搶myLock.release()if __name__ == '__main__':# 創建一個賬戶muxikeqi = Account("muxikeqi",200)# 創建兩個線程模擬兩個人同時取一個賬戶boy1 = Withdraw(muxikeqi,100)boy2 = Withdraw(muxikeqi,200)# 創建鎖myLock = Lock()# 開啟線程boy1.start()boy2.start()運行結果如下:
2.6、死鎖
概述:在多線程程序中,死鎖問題很大一部分是由于一個線程同時獲取多個鎖造成的。
解決辦法:同一個代碼塊,不要同時持有兩個對象鎖。
實操(了解,看懂代碼就行):假設在進行一場大逃殺類的游戲,你和敵人走進一個房間發現了一把手槍和一發子彈,用兩把鎖模擬你們搶武器的場景。
from threading import Thread, Lock
from time import sleepdef fun1():lock1.acquire()print('fun1拿到手槍')sleep(2)lock2.acquire()print('fun1拿到子彈')lock2.release()print('fun1丟棄子彈')lock1.release()print('fun1丟棄手槍')def fun2():lock2.acquire()print('fun2拿到子彈')lock1.acquire()print('fun2拿到手槍')lock1.release()print('fun2丟棄手槍')lock2.release()print('fun2丟棄子彈')if __name__ == '__main__':lock1 = Lock()lock2 = Lock()t1 = Thread(target=fun1)t2 = Thread(target=fun2)t1.start()t2.start()運行結果如下(程序會一直運行,進入死鎖狀態):

2.7、信號量(Semaphore)
概述:互斥鎖使用后,一個資源同時只有一個線程訪問。但如果我們想同時讓N個線程訪問某個資源時,就可以使用信號量。信號量用于控制同時訪問資源的數量。信號量和鎖相似,鎖同一時間只允許一個對象(進程)通過,信號量同一時間允許多個對象(進程)通過。
應用場景:
①、讀寫文件的時候,一般只能只有一個線程在進行寫操作,但讀操作可以有多個線程同時進行,如果需要限制同時讀文件的線程個數,這時候就可以用到信號量(如果用互斥鎖,就是限制同一時刻只能有一個線程讀取文件)。
②、爬蟲抓取數據時。
原理:信號量底層就是一個內置的計數器。每當資源獲取時(調用acquire)計數器-1,當計數器數值為零時其他線程就無法進入,資源釋放時(調用release)計數器+1。
實操:現有一個1VS1的游戲對局房間,每次只能有兩名玩家進入,利用線程中的信號量實現該游戲房間的玩家數量控制。
from threading import Thread,Semaphore
from time import sleepdef game(name , se):se.acquire()print(f"{name}進入對局")sleep(2)print(f"{name}離開對局")se.release()if __name__ == '__main__':# 創建信號量對象se = Semaphore(2)# 通過循環創建多個線程并啟動for i in range(5):t =Thread(target=game,args=(f"測試人機P{i}",se))t.start()運行結果如下:

易錯點提醒:
①、不要導錯包,信號量使用的是threading模塊中的semaphore。
②、注意看演示代碼,不要拼寫錯誤。
2.8、事件(Event)
概述:用于喚醒正在阻塞等待狀態的線程。
原理:Event 對象包含一個可由線程設置的信號標志,它允許線程等待某些事件的發生。在初始情況下,event 對象中的信號標志被設置假。如果有線程等待一個 event 對象,而這個 event 對象的標志為假,那么這個線程將會被一直阻塞直至該標志為真。一個線程如果將一個 event 對象的信號標志設置為真,它將喚醒所有處于等待的?event 對象的線程。如果一個線程等待一個已經被設置為真的 event 對象,那么它將忽略這個事件,繼續執行。
Event()可以創建一個事件管理標志,該標志(event)默認為False,event對象主要有四種方法可以調用:
| 方法名 | 說明 |
|---|---|
event.wait(timeout=None) | 調用該方法的線程會被阻塞,如果設置了timeout參數,超時后,線程會停止阻塞繼續執行; |
event.set() | 將event的標志設置為True,調用wait方法的所有線程將被喚醒 |
event.clear() | 將event的標志設置為False,調用wait方法的所有線程將被阻塞 |
event.is_set() | 判斷event的標志是否為True |
實操:現有三名運動員準備100米比賽,三名運動員到達起跑地點后要等待裁判法令后才能開始起跑,等到裁判一聲令下所有運動員都起跑,利用線程中的事件實現這一場景。
import threading
import time
from threading import Event,Thread
from time import sleepdef run(name, event):print(f"{name}進入起跑點")sleep(1)event.wait()print(f"{name}起跑了")if __name__ == '__main__':# 創建事件對象event = threading.Event()# 創建三個線程模擬三個運動員for i in range(3):t = Thread(target=run,args=(f"運動員{i+1}",event))t.start()time.sleep(4)print("預備,跑!")event. Set()運行結果如下:

2.9、生產者消費者模式
生產者:指的是負責生產數據的模塊(這里模塊可能是:方法、對象、線程、進程)。
消費者:指的是負責處理數據的模塊(這里模塊可能是:方法、對象、線程、進程)
緩沖區:消費者不能直接使用生產者的數據,它們之間有個"緩沖區"。生產者將生產好的數據放入"緩沖區",消費者從"緩沖區"拿要處理的數據。
設置緩沖區的優點 (緩沖區是實現并發的核心):
①、實現線程的并發協作:有了緩沖區以后,生產者線程只需要往緩沖區里面放置數據,而不需要管消費者消費的情況;同樣,消費者只需要從緩沖區拿數據處理即可,也不需要管生產者生產的情況。 這樣,就從邏輯上實現了“生產者線程”和“消費者線程”的分離。
②、解耦了生產者和消費者:生產者不需要和消費者直接打交道。
③、解決忙閑不均,提高效率:生產者生產數據慢時,緩沖區仍有數據,不影響消費者消費;消費者處理數據慢時,生產者仍然可以繼續往緩沖區里面放置數據
緩沖區和queue對象:從一個線程向另一個線程發送數據最安全的方式可能就是使用 queue 庫中的隊列了。創建一個被多個線程共享的 Queue 對象,這些線程通過使用 put()?和 get() 操作向隊列中添加或者刪除元素。Queue 對象已經包含了必要的鎖,所以可以通過它在多個線程間安全地共享數據。
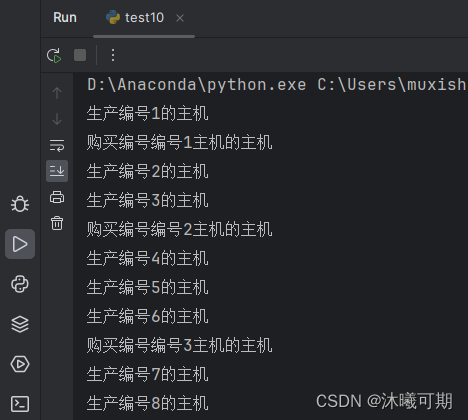
實操:現有一家初創公司經營主機組裝工作,當庫存少于10臺時就組織組裝新的主機,但由于市場疲軟,因此買家購買速度會低于公司的生產速度。
from queue import Queue
from threading import Thread
from time import sleepdef producer():# 用num變量來計數num = 1while True:# qsize()方法用于查詢緩沖區中有多少條數據if queue.qsize() < 5:print(f"生產編號{num}的主機")queue.put(f"編號{num}主機")num+=1else:print("貨源充足,無需補貨")sleep(1)def coustomer():while True:print(f"購買編號{queue.get()}的主機")sleep(3)if __name__ == '__main__':# 由于生產者和消費者都要使用到緩沖區,因此將其放在測試代碼中# 創建隊列對象queue = Queue()# 創建兩個線程分別代表生產者和消費者t_producter = Thread(target=producer)t_customer = Thread(target=coustomer)# 啟動線程t_producter.start()t_customer.start()運行結果如下:
3、進程(Process)
概述:
①、進程擁有自己獨立的堆和棧,既不共享堆,也不共享棧,進程由操作系統調度;進程切換需要的資源很最大,效率低。
②、對于操作系統來說,一個任務就是一個進程(Process),比如打開一個瀏覽器就是啟動一個瀏覽器進程。
優點:
①、可以使用計算機多核,進行任務的并行執行,提高執行效率。
②、運行不受其他進程影響,創建方便。
③、空間獨立,數據安全。
缺點:進程的創建和刪除消耗的系統資源較多。
3.1、創建進程
概述:Python的標準庫提供了模塊multiprocessing進行進程的創建。
創建方式:
①、方法包裝
②、類包裝
提示:和線程一樣,所有進程都需要通過start方法啟動。
3.1.1、方法包裝創建進程
實操:創建兩個進程,進程觸發后就調用fun1函數,打印主進程id和兩個子進程的id及子進程所屬父進程的id。
import os
from multiprocessing import Process
from time import sleepdef fun1(name):print(f"進程{name}start")sleep(1)print(f"進程{name}的id:{os.getpid()}")print(f"進程{name}的父進程ID:{os.getppid()}")print(f"進程{name}end")# 創建進程時,如果不加__main__的限制,就會無限制的創建子進程導致報錯(這是windows中的bug)
if __name__ == '__main__':print(f"當前進程id:{os.getpid()}")# 創建進程p1 = Process(target=fun1,args=("p1",))p2 = Process(target=fun1,args=("p2",))# 啟動進程p1.start()p2.start()運行結果如下:

3.1.2、類包裝創建進程
概述:通過類包裝創建進程就是使用 Process 類創建實例化對象,其本質是調用該類的構造方法創建新進程。
實操:通過類包裝的方式創建兩個進程,并打印兩個進程的生命周期。
from multiprocessing import Process
from time import sleepclass ProcessTest(Process):def __init__(self,name):Process.__init__(self)self.name = namedef run(self):print(f"{self.name},start")sleep(2)print(f"{self.name},end")if __name__ == '__main__':# 創建進程的實例對象p1 = ProcessTest("p1")p2 = ProcessTest("p2")# 啟動進程p1.start()p2.start()運行結果如下:

3.2、queue隊列實現進程通信
概述:在2.9小節的練習中使用queue模塊中的 Queue 類實現線程間通信,但要實現進程間通信,需要使用 multiprocessing?模塊中的 Queue?類。
原理:queue 實現進程間通信的方式,就是使用操作系統給開辟的一個隊列空間,各個進程可以把數據放到該隊列中,也可以從隊列中把自己需要的信息取走。
實操:通過queue隊列實現進程通信,主線程中為隊列添加多條數據,子線程開啟后拿到數據并打印獲取的數據,子線程獲取完數據后再為隊列添加任意一條數據,再在主線程中獲取子線程為隊列添加的數據,并且要保證子線程運行結束后再結束主線程。
from multiprocessing import Process, Queue
from time import sleepclass myProcess(Process):def __init__(self,name,mq):Process.__init__(self)self.name = nameself.mq = mqdef run(self):print(f"進程{self.name},start")# 子進程獲取隊列中的數據print(f"{self.name}獲取數據{self.mq.get()}")sleep(1)# 為隊列添加新的數據(由于有三個進程,所以這里會為隊列添加三條數據)self.mq.put("i'm new data")print(f"進程{self.name},end")if __name__ == '__main__':print("主線程start!")# 創建隊列對象(隊列的特性是先進先出)mq = Queue()# 通過變量num控制創建多少個進程和為隊列添加多少條數據num = 3# 為隊列添加數據for i in range(num):mq.put(i+1)# 創建一個空列表保存創建的進程p_list = []# 通過循環創建多個進程for i in range(num):# 創建進程時要傳入隊列對象,否則無法獲取到隊列中的內容p = myProcess(f"p{i+1}",mq)p_list.append(p)# 啟動進程p.start()# 主線程等待子線程結束(join方法只能加入已啟動的方法)p.join()print(f"獲取隊列中新加入的數據:{mq.get()}")print("主線程end!")運行結果如下:

3.3、管道(Pipe)實現進程通信
概述:Pipe方法返回(conn1, conn2)代表一個管道的兩個端。Pipe方法有duplex參數,如果duplex參數為True(默認值),那么這個參數是全雙工模式,也就是說conn1和conn2均可收發。若duplex為False,conn1只負責接收消息,conn2只負責發送消息。send和recv方法分別是發送和接受消息的方法。例如,在全雙工模式下,可以調用conn1.send發送消息,conn1.recv接收消息。如果沒有消息可接收,recv方法會一直阻塞。如果管道已經被關閉,那么recv方法會拋出EOFError。
實操:通過該案例了解如何通過管道實現進程的通信。
import multiprocessing
from multiprocessing import Process
from time import sleepdef fun1(name,conn1):# 準備要發送的數據info = "消息1"print(f"進程{name}發送數據:{info}")# 發送數據conn1.send(info)sleep(1)print(f"{name}接收到管道另一端的消息:{conn1.recv()}")def fun2(name,conn2):# 準備要發送的數據info = "消息2"print(f"進程{name}發送數據:{info}")# 發送數據conn2.send(info)sleep(1)print(f"{name}接收到管道另一端的消息:{conn2.recv()}")if __name__ == '__main__':# 創建管道conn1,conn2 = multiprocessing.Pipe()# 創建子線程p1 = Process(target=fun1,args=("p1",conn1))p2 = Process(target=fun2,args=("p2",conn2))# 啟動子線程p1.start()p2.start()運行結果如下:

3.4、Manager管理器實現進程通信
概述:管理器提供了一種創建共享數據的方法,從而可以在不同進程中共享。
注意:Manager管理器使用完后記得關閉,和操作文件的open()函數有點類似。
實操:在主線程中打開資源管理器,并為資源管理器創建一個列表和一個字典,然后為列表中添加任意數據,再創建一個子線程,要求主線程在子線程結束后結束,在子線程中獲取主線程為資源管理器中的列表添加的數據并為資源管理器中的字典和列表添加任意數據,最后在主線程中獲取子線程為資源管理器添加的數據。
from multiprocessing import Manager, Processdef func(name,m_list,m_dict):# 在子進程中獲取資源管理器中的列表數據print(f"子進程獲取到的資源管理器中列表數據如下:{m_list}")# 在子進程中為資源管理器中的字典和列表添加數據m_dict["name"] = "muxikeqi"m_list.append("新加入的內容")if __name__ == '__main__':with Manager() as m:# 資源管理器中的列表m_list = m.list()# 資源管理器中的字典m_dict = m.dict()# 在主進程中為資源管理器中的列表添加數據m_list.append("info1")# 將主進程中資源管理器的數據傳入子進程,讓子進程使用p1 = Process(target=func,args=("myUsername",m_list,m_dict))# 啟動子進程p1.start()# 主進程等待子進程p1結束后結束p1.join()# 主進程獲取子進程中為資源管理器添加的內容print("主進程獲取的m_list:",m_list)print("主進程獲取的m_dict:",m_dict)運行結果如下:

3.5、進程池(Pool)
概述:Python提供了更好的管理多個進程的方式,就是使用進程池。進程池可以提供指定數量的進程給用戶使用,即當有新的請求提交到進程池中時,如果池未滿,則會創建一個新的進程用來執行該請求;反之,如果池中的進程數已經達到規定最大值,那么該請求就會等待,只要池中有進程空閑下來,該請求就能得到執行。
優點:①、提高效率,節省開辟進程和開辟內存空間的時間及銷毀進程的時間。
②、節省內存空間。
| 類/方法 | 功能 | 參數 |
|---|---|---|
Pool(processes) | 創建進程池對象 | processes表示進程池中有多少進程 |
pool.apply_async(func,args,kwds) | 異步執行 ;將事件放入到進程池隊列 | func 事件函數 args 以元組形式給func傳參kwds 以字典形式給func傳參 返回值:返回一個代表進程池事件的對象,通過返回值的get方法可以得到事件函數的返回值 |
pool.apply(func,args,kwds) | 同步執行;將事件放入到進程池隊列 | func 事件函數 args 以元組形式給func傳參 kwds 以字典形式給func傳參 |
pool.close() | 關閉進程池 | |
pool.join() | 回收進程池 | |
pool.map(func,iter) | 類似于python的map函數,將要做的事件放入進程池 | func 要執行的函數 iter 迭代對象 |
實操:創建一個線程池,線程池中包含3個線程用于執行指定任務,再給出任意個數的任務讓線程池去執行,任務要包括多個函數的任務和單個函數的任務方便參考,并且主線程在子線程全部結束后再結束。
import os # import os
from multiprocessing import Pool
from time import sleepdef fun1(name):print(f"進程{name}id:{os.getpid()}正在執行fun1")sleep(2)return namedef fun2(name):print(f"進程{name}id:{os.getpid()}正在執行fun2")sleep(2)if __name__ == '__main__':print("主進程start!")# 創建線程池對象pool = Pool(3)# 某一個進程先執行fun1,執行完fun1函數后立即去執行fun2函數pool.apply_async(func=fun1,args=("p1",),callback=fun2)pool.apply_async(func=fun1,args=("p2",),callback=fun2)pool.apply_async(func=fun1,args=("p3",), callback=fun2)# 某一個進程執行fun1函數,執行完就看是否有其他任務需要執行pool.apply_async(func=fun1,args=("p4",))pool.apply_async(func=fun1,args=("p5",))pool.apply_async(func=fun2,args=("p6",))# 關閉線程池pool.close()# 主線程等待線程池結束后再結束pool.join()print("主線程end!")運行結果如下:

實操2:利用函數式編程實現實操1中類似的效果。
import os
from multiprocessing import Pool
from time import sleepdef fun1(name):print(f"進程{name}id:{os.getpid()}正在執行fun1")sleep(2)return nameif __name__ == '__main__':# 使用with進行管理,不用管關閉線程池的問題with Pool(3) as pool:args = pool.map(fun1,("p1","p2","p3","p4","p5","p6"))print("執行的任務包括:")for arg in args:print(arg,end="\t")運行結果如下:

4、協程(Coroutines)
4.1、初識協程
概述:①、協程也叫作纖程(Fiber),全稱是“協同程序”,用來實現任務協作。是一種在線程中,比線程更加輕量級的存在,由程序員自己寫程序來管理(進程和線程都有操作系統來管理)。
②、當出現IO阻塞時,CPU一直等待IO返回,處于空轉狀態。這時候用協程,可以執行其他任務。當IO返回結果后,再回來處理數據。充分利用了IO等待的時間,提高了效率。
協程的核心(控制流的讓出和恢復)
①、每個協程有自己的執行棧,可以保存自己的執行現場;
②、可以由用戶程序按需創建協程(比如:遇到io操作);
③、協程“主動讓出(yield)”執行權時候,會保存執行現場(保存中斷時的寄存器上下文和棧),然后切換到其他協程;
④、協程恢復執行(resume)時,根據之前保存的執行現場恢復到中斷前的狀態,繼續執行,這樣就通過協程實現了輕量的由用戶態調度的多任務模型。
協程和多線程的比較:(將設要完成三個任務)
①、在單線程同步模型中,任務按照順序執行。如果某個任務因為I/O而阻塞,其他所有的任務都必須等待,直到它完成之后它們才能依次執行。
②、多線程版本中,3個任務分別在獨立的線程中執行。這些線程由操作系統來管理,在多處理器系統上可以并行處理,或者在單處理器系統上交錯執行。這使得當某個線程阻塞在某個資源的同時其他線程得以繼續執行。
③、中協程版本的程序,3個任務交錯執行,但仍然在一個單獨的線程控制中。當處理I/O或者其他操作時,注冊一個回調到事件循環中,然后當I/O操作完成時繼續執行。回調描述了該如何處理某個事件。事件循環輪詢所有的事件,當事件到來時將它們分配給等待處理事件的回調函數。
協程的優點:
①、由于自身帶有上下文和棧,無需線程上下文切換的開銷,屬于程序級別的切換,操作系統完全感知不到,因而更加輕量級;
②、無需原子操作的鎖定及同步的開銷;
③、方便切換控制流,簡化編程模型;
④、單線程內就可以實現并發的效果,最大限度地利用cpu,且可擴展性高,成本低(注:一個CPU支持上萬的協程都不是問題。所以很適合用于高并發處理)
注意:asyncio協程是寫爬蟲比較好的方式。比多線程和多進程都好,因為開辟新的線程和進程是非常耗時的。
協程的缺點:
①、無法利用多核資源,因為協程的本質是個單線程,它不能同時將單個CPU 的多個核用上,協程需要和進程配合才能運行在多CPU上。
②、日常所編寫的絕大部分應用都沒有這個必要,除非是cpu密集型應用。
4.2、yield方式實現協程(了解,已淘汰)
python中引入協程的歷史:
①、最初的生成器變形 yield/send ;
②、引入 @asyncio.coroutine 和 yield from ;
③、Python3.5版本后,引入 async / await 關鍵字;
實操:通過下面的例子了解如何通過yield的方式實現協程。
import time
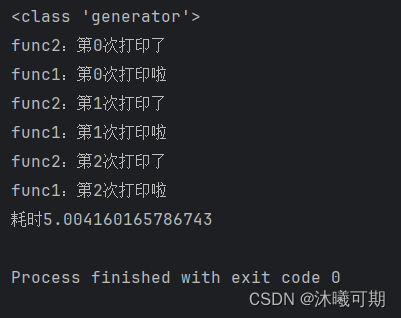
def func1():for i in range(3):print(f'func1:第{i}次打印啦')yield # 只要方法包含了yield,就變成一個生成器time. Sleep(1)
def func2():g = func1() #func1是一個生成器,func1()就不會直接調用,需要通過next()函數或for循環調用print(type(g))for k in range(3):print(f'func2:第{k}次打印了' )next(g) #繼續執行func1的代碼time.sleep(1)if __name__ == '__main__':#有了yield,我們實現了兩個任務的切換+保存狀態start_time = time.time()func2()end_time = time.time()print(f"耗時{end_time-start_time}") 運行結果如下:
4.3、syncio異步IO實現協程(重點)?
概述:
①、正常的函數執行時是不會中斷的,此時需要寫一個能夠中斷的函數,就需要加 async;
②、async 用來聲明一個函數為異步函數,異步函數的特點是能在函數執行過程中掛起,去執行其他異步函數,等到掛起條件(假設掛起條件是sleep(2))消失后,也就是2秒到了再回來執行
③、await 用來用來聲明程序掛起,比如異步程序執行到某一步時需要等待的時間很長,就將此掛起,去執行其他的異步程序。
④、asyncio?是python3.5之后的協程模塊,是python實現并發重要的包,這個包的底層是使用事件循環驅動實現并發。
實操:通過案例了解synicio異步IO如何實現協程。
import asyncio
import time# 用async標記這是一個異步函數
async def fun1():for i in range(3):print(f"fun1打印第{i+1}次")await asyncio.sleep(2) # 異步睡眠return ("fun1執行完畢")
async def fun2():for y in range(3):print(f"fun2打印第{y+1}次")await asyncio.sleep(2) # 異步睡眠return "fun2執行完畢"
async def main():# 用main函數調用fun1和fun2函數,也要聲明為異步函數res = await asyncio.gather(fun1(),fun2())print(res)if __name__ == '__main__':star_time = time.time()# 啟動調用fun1和fun2的異步函數main()asyncio.run(main())end_time = time.time()# 打印統計的耗時時間print(f"耗時:{end_time-star_time}")
運行結果如下:




)


)






)





