CLIP 論文整體架構
該論文總共有 48 頁,除去最后的補充材料十頁去掉,正文也還有三十多頁,其中大部分篇幅都留給了實驗和響應的一些分析。
從頭開始的話,第一頁就是摘要,接下來一頁多是引言,接下來的兩頁就是講了一下方法,主要說的是怎么做預訓練,然后從第六頁一直到第十八頁全都是說的實驗,當然這里面也包括了怎么去做 zeor-shot 的推理,還有包括這種 prompt engineering 、prompt ensemble 等等,算是方法和實驗的合體。
講完了實驗作者大概花了一頁篇幅去討論了一下 CLIP 工作的局限性,然后接下來的五頁作者主要就是討論了一下CLIP這篇工作有可能能帶來的巨大的影響力,在這個部分首先討論的是 bias ,即模型的偏見,然后討論了 CLIP 有可能在監控視頻里的一些應用,最后作者展望了一下 CLIP 還有哪些可以做的這個未來工作,然后在講完了所有的這些方法、實驗和分析之后作者用了一頁的篇幅就大概說了一下相關工作,最后給出了一個簡短的小結論。
CLIP 到底是什么
CLIP 的遷移學習能力非常強,其預訓練好的模型能夠在任意一個視覺分類的數據集上取得不錯的效果。
最重要的是,其是 zero-shot 的:

預訓練的含義:

作者在這篇文章中做了超級多的實驗,在超過三十個數據集上做了測試:

CLIP 到底是什么?到底是怎么去做到 zero-shot 推理的?
看文章中的圖一:

上圖是模型總覽圖,這是 CLIP 工作的一個大概流程。
CLIP 是如何進行預訓練的?從題目中可以窺見一二,通過自然語言處理那邊來的一些監督信號,我們可以訓練一個遷移效果很好的視覺模型。因此明顯這是一個牽扯到文字、圖片的一個多模態的工作。
那么是如何利用來自自然語言處理那邊的信號的呢?在訓練過程中,模型的輸入是一個圖片和文字的配對。以上圖為例,圖片是一只狗,配對的文字也是 pepper 是一只小狗。
然后圖片會通過一個 Image Encoder 圖片編碼器,從而得到一些特征(這里的編碼器可以是一個 ResNet 也可以是一個Vision Transformer)。對于文本句子來說其也會通過一個文本編碼器,從而得到一些文本的特征。
假設現在每個Training Batch(訓練批次)里都有 n 個這樣的圖片文本對,也就是說有 n 個句子,n 張圖片,對應的會得到 n 個文本特征以及 n 個圖片特征,而 CLIP 就是在這些特征上去做對比學習。
對比學習非常的靈活,只需要一個正樣本和一個負樣本的定義即可,其他的都是正常套路。
正樣本是啥?其實很簡單,上面圖中的一個配對的 圖片-文本對 就是一個正樣本。因為其描述的是一個東西。
所以說在上圖中的特征矩陣里,沿著對角線方向上的內容都是正樣本:
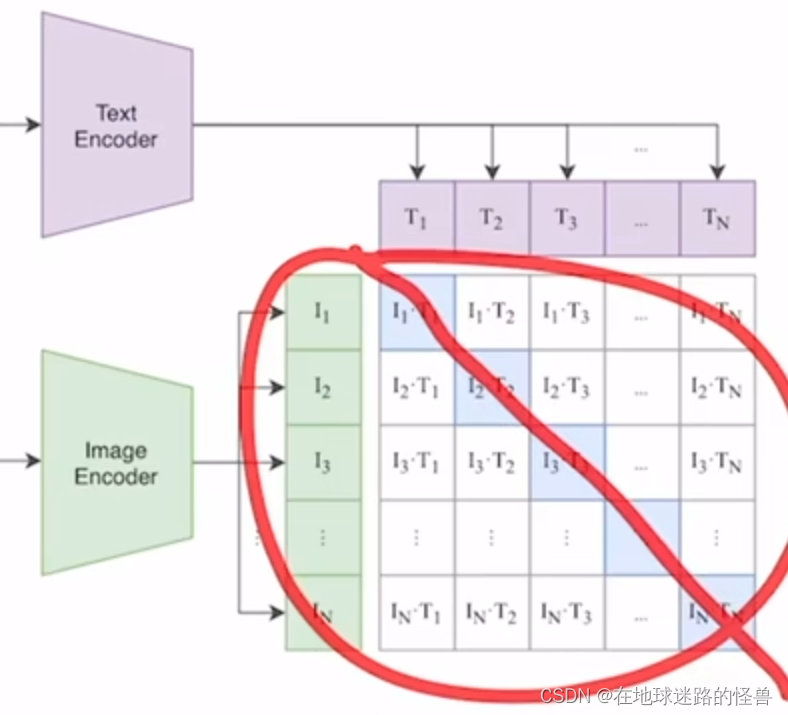
因為 I1T1 、I2T2 這些本身就都是配對的。
那么剩下矩陣中的不是對角線上的其他元素就都是負樣本了。也就是說我們有 n 個正樣本,然后又 n 平方減去 n 個負樣本。
一旦有了正負樣本,模型就可以通過對比學習的方式去訓練起來了,完全不需要任何手工的標注。
但是對于這種無監督的預訓練方式,也就是對比學習,其是需要大量的數據的,因此 OpenAI 還專門去收集了這么一個數據集。該數據集中有 4 億個 圖片-文本對,數據質量很高,這也是為什么 CLIP 這個預訓練模型為什么能這么強大的主要原因之一。
CLIP 如何做推理的
CLIP 如何去做 zeor-shot 的推理的呢?
從上面可以知道,CLIP 這個模型經過預訓練之后其實只能得到一些視覺上和文本上的特征,他并沒有在任何分類的任務上去做繼續的這種訓練或者微調,因此他是沒有分類頭的,沒有分類頭怎么做推理呢?
分類頭:

本文提出了一個非常巧妙的利用自然語言的一種辦法,叫 prompt template。
這里使用 Image Net 數據集做一個例子。
CLIP 就是先將 Image Net 里這 1000 個類,比如飛機啊、汽車啊、狗啊變成一個句子:
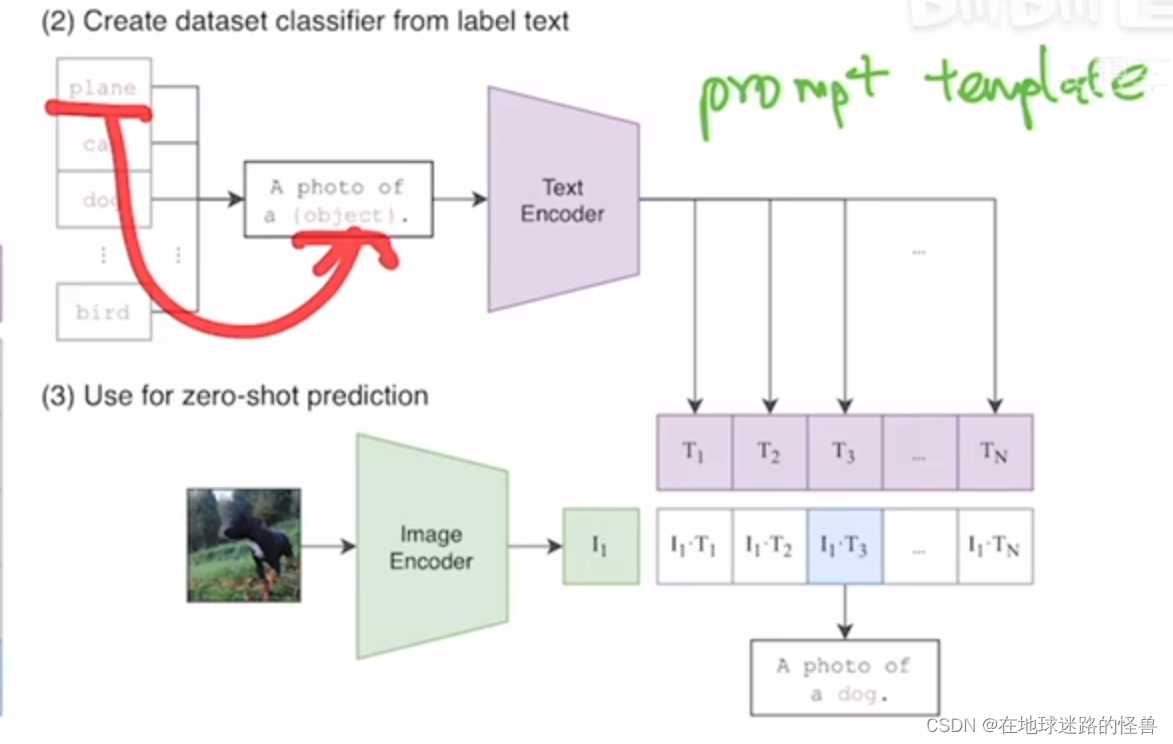
從上圖可以看到,也就是用 plane、cat、dog 等去替代花括號包起來的 object 的這個內容,就相當于一個模板(在很多 it 技術領域都有類似概念的存在)。
有 1000 個類,那么就生成了這樣的 1000 個句子。然后這 1000 個句子通過我們之前預訓練好的這個文本編碼器 Text Encoder 就會得到一千個這個文本的特征。
但其實直接使用原生的那些單詞去做文本特征的提取也是可以的,但是因為在模型預訓練的時候我們的圖片每次看到的基本都是一個句子,如果在推理的時候突然把所有的這個文本都變成了一個單詞,那這樣就跟在訓練的時候看到的這個文本就不太一樣了,效果就會稍有下降。
另外一個單詞如何變成一個句子也是很有講究的。因此 CLIP 這篇論文在后面還提出了 prompt engineering 和 prompt ensemble 這兩種方式去進一步的提高這個模型的準確率。而不需要重新訓練這個模型。
然后在推理的時候,不論此時來到的什么圖片,我們只要將這個圖片扔給這個圖片的編碼器,得到了這個圖片特征之后就讓這個圖片特征去跟所有的這些文本特征去做這個 cosine similarity(余弦相似度):

計算相似性,最后這個圖像特征和這里的哪個文本特征最相似,那么就把這個文本特征和所對應的那個句子挑出來,從而完成了分類這個任務:

也就是這張圖片里有狗這個物體。
并且在 CLIP 真正使用的時候,這里的標簽還是可以改的(比如不是飛機,而是坦克),不光是 Image Net 這 1000 個類,可以換成任意的單詞,同樣圖片也可以是任何的圖片,然后依舊可以使用這種通過算余弦相似度的方式去判斷這張圖片里到底還有哪些物體。
這個性質就是CLIP的強大之處,因為它徹底擺脫了 categorical label 的這個限制,也就是說不論是在訓練的時候還是在推理的時候,其都不需要有一個這么提前定好的這么一個標簽列表了。任意給我一張照片,我都可以通過給模型去喂這種不同的文本句子從而知道這張圖片里到底有沒有我所感興趣的物體。
而且 CLIP 不光是能識別新的物體,由于它真的把這個視覺的語義和文字的語義聯系到了一起,所以它學到的這個特征的語義性非常強,遷移效果也非常的好。
基于CLIP的應用
基于CLIP 的圖像生成,用文本去指導圖像的生成。
基于CLIP 的物體檢測和分割。
基于CLIP 的用來做視頻檢索的,意思是給定一段視頻,然后想去搜索這個視頻里到底有沒有出現過某個物體或者是場景,那么就可以通過直接輸入文本的這種形式去做檢索。




)














