過去幾年里,YOLOs因在計算成本和檢測性能之間實現有效平衡而成為實時目標檢測領域的主流范式。研究人員針對YOLOs的結構設計、優化目標、數據增強策略等進行了深入探索,并取得了顯著進展。然而,對非極大值抑制(NMS)的后處理依賴阻礙了YOLOs的端到端部署,并對推理延遲產生負面影響。此外,YOLOs中各種組件的設計缺乏全面和徹底的審查,導致明顯的計算冗余并限制了模型的性能。這導致次優的效率,以及性能提升的巨大潛力。在這項工作中,我們旨在從后處理和模型架構兩個方面進一步推進YOLOs的性能-效率邊界。為此,我們首先提出了用于YOLOs無NMS訓練的持續雙重分配,該方法同時帶來了競爭性的性能和較低的推理延遲。此外,我們為YOLOs引入了全面的效率-準確性驅動模型設計策略。我們從效率和準確性兩個角度全面優化了YOLOs的各個組件,這大大降低了計算開銷并增強了模型能力。我們的努力成果是新一代YOLO系列,專為實時端到端目標檢測而設計,名為YOLOv10。廣泛的實驗表明,YOLOv10在各種模型規模下均達到了最先進的性能和效率。例如,在COCO數據集上,我們的YOLOv10-S在相似AP下比RT-DETR-R18快1.8倍,同時參數和浮點運算量(FLOPs)減少了2.8倍。與YOLOv9-C相比,YOLOv10-B在相同性能下延遲減少了46%,參數減少了25%。
論文地址:YOLOv10: Real-Time End-to-End Object Detection點擊即可跳轉
官方代碼:官方代碼倉庫點擊即可跳轉
關注我后續會發布更詳細的解讀以及創新
目錄
1. 創新點
2.?精度對比
3. 一致匹配度量(Consistent Matching Metric)
3.1 效率驅動的模型設計
3.2 基于秩的塊設計(Rank-Guided Block Design)
3.3 精度驅動的模型設計
4.總結

1. 創新點
無NMS的一致雙分配(consistent dual assignments):
-
YOLOv10提出了一種通過雙標簽分配而不用非極大值抑制NMS的策略。這種方法結合了一對多和一對一分配策略的優勢,提高了效率并保持了性能。
效率-精度驅動的模型設計(Holistic Efficiency-Accuracy Driven Model Design):
-
輕量化分類頭:在不顯著影響性能的情況下,減少了計算開銷。
-
空間-通道解耦下采樣:解耦空間下采樣和通道調整,優化計算成本。
-
基于秩的塊設計:根據各階段的內在秩適應塊設計,減少冗余,提高效率。
-
大核卷積和部分自注意力PSA:在不顯著增加計算成本的情況下,增強了感受野和全局建模能力。

1. 一致雙分配策略(Consistent Dual Assignments)
YOLOv10引入了一種新的雙分配策略,用于在訓練期間同時利用一對多(one-to-many)和一對一(one-to-one)標簽分配。這種方法在保持模型高效訓練的同時,擺脫了推理過程中對非極大值抑制NMS的依賴。
雙標簽分配(Dual Label Assignments)
-
一對多分配:在訓練期間,多個預測框被分配給一個真實物體標簽。這種策略提供了豐富的監督信號,優化效果更好。
-
一對一分配:僅一個預測框被分配給一個真實物體標簽,避免了NMS,但由于監督信號較弱,容易導致收斂速度慢和性能欠佳。
-
雙頭架構:模型在訓練期間使用兩個預測頭,一個使用一對多分配,另一個使用一對一分配。這樣,模型可以在訓練期間利用一對多分配的豐富監督信號,而在推理期間則使用一對一分配的預測結果,從而實現無NMS的高效推理。
2.?精度對比
-

可視化結果

消融實驗和分析


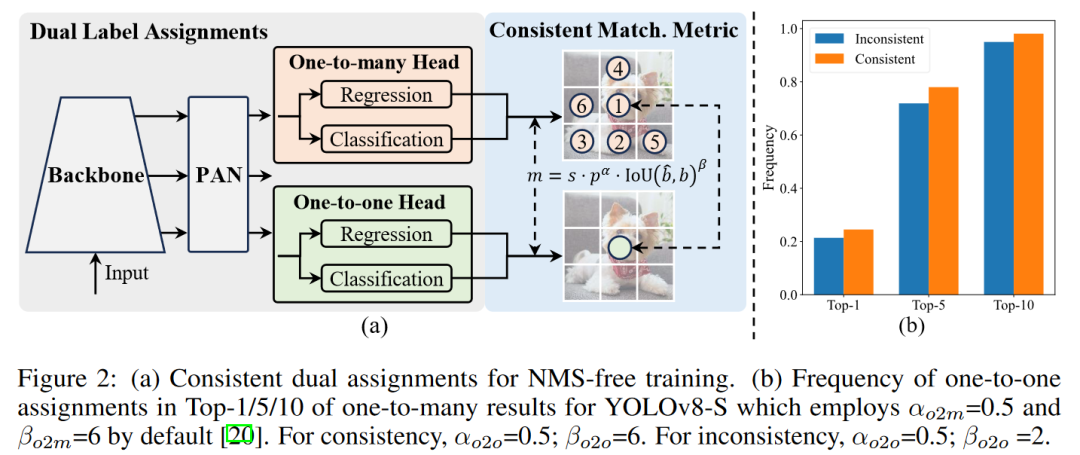
3. 一致匹配度量(Consistent Matching Metric)
為了在訓練期間保持兩個預測頭的一致性,提出了一致匹配度量。通過調整匹配度量參數,使得一對一和一對多分配的監督信號一致,減少了訓練期間的監督差距,提升了模型的預測質量。
整體效率-精度驅動的模型設計(Holistic Efficiency-Accuracy Driven Model Design)
YOLOv10在模型架構的各個方面進行了全面優化,旨在提升效率和精度。
3.1 效率驅動的模型設計
輕量化分類頭(Lightweight Classification Head)
在YOLO系列中,分類頭和回歸頭通常共享相同的架構,但分類任務的計算開銷更大。為分類頭采用輕量級的架構,包括兩個3×3的深度可分離卷積(depthwise separable convolutions)和一個1×1卷積,以減少計算開銷。
空間-通道解耦下采樣(Spatial-Channel Decoupled Downsampling)
傳統的下采樣方法同時進行空間和通道的轉換,計算成本較高。YOLOv10首先使用逐點卷積(pointwise convolution)調整通道維度,然后使用深度卷積(depthwise convolution)進行空間下采樣。這樣可以最大限度地保留信息,同時減少計算成本。
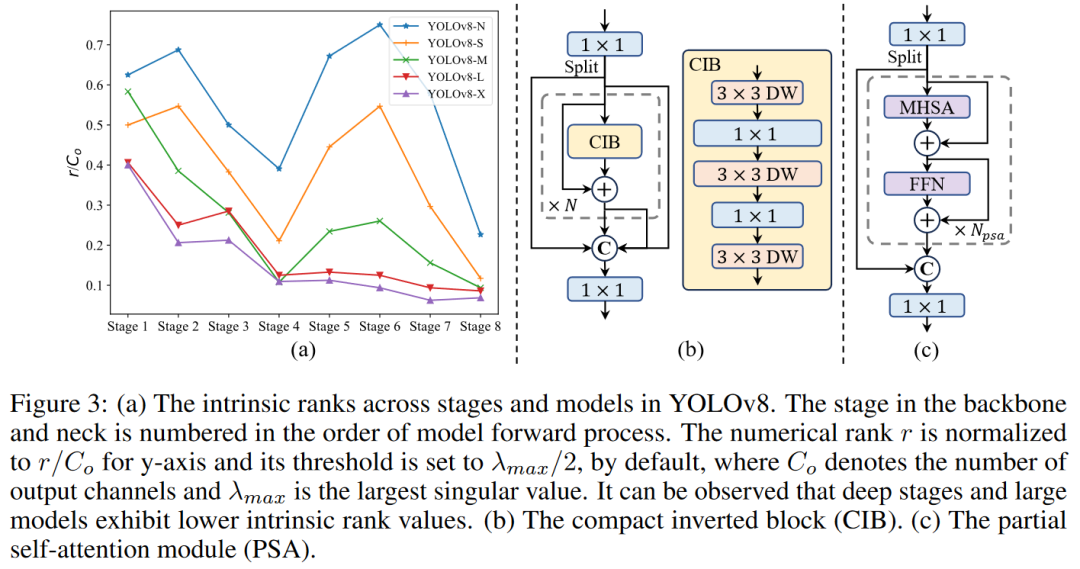
3.2 基于秩的塊設計(Rank-Guided Block Design)
在YOLO模型中,各階段通常使用相同的基本構建塊,容易導致深層階段的計算冗余。因此根據各階段的內在秩(intrinsic rank)調整塊設計,減少冗余,采用緊湊的反向塊(Compact Inverted Block, CIB)設計,用深度卷積進行空間混合和逐點卷積進行通道混合,提高效率。
3.3 精度驅動的模型設計
大核卷積(Large-Kernel Convolution)
大核卷積的感受野較大,能夠更好地捕捉圖像中的全局信息。然而,直接在所有階段使用大核卷積可能會導致小物體特征的污染,并增加高分辨率階段的I/O開銷和延遲。因此,在深層階段使用大核深度卷積(如7×7)來擴大感受野,增強模型能力,同時使用結構重參數化技術(structural reparameterization)優化訓練。
對于小模型規模(如YOLOv10-N/S),大核卷積的使用能夠顯著提升性能,而對于大模型規模(如YOLOv10-M),其天然較大的感受野使得大核卷積的效果不明顯,因此僅在小模型中使用。
部分自注意力(Partial Self-Attention, PSA)
部分自注意力模塊通過引入全局建模能力來提升模型性能,同時保持較低的計算開銷。
自注意力(self-attention)在視覺任務中因其出色的全局建模能力而被廣泛使用,但其計算復雜度和內存占用較高。本文引入PSA模塊,通過將特征按通道分成兩部分,僅對一部分應用多頭自注意力(Multi-Head Self-Attention, MHSA),然后進行融合,增強全局建模能力,降低計算復雜度。
3.4 YOLOv10的base版本yaml文件
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]b: [0.67, 1.00, 512] # YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, SCDown, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, SCDown, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2fCIB, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9- [-1, 1, PSA, [1024]] # 10# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2fCIB, [512, True]] # 13- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 16 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 13], 1, Concat, [1]] # cat head P4- [-1, 3, C2fCIB, [512, True]] # 19 (P4/16-medium)- [-1, 1, SCDown, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 3, C2fCIB, [1024, True]] # 22 (P5/32-large)- [[16, 19, 22], 1, v10Detect, [nc]] # Detect(P3, P4, P5)4.總結
YOLOv10引入了額外的one-to-one頭部,通過雙分配策略,在訓練時提供更豐富的監督信息,而在推理時則利用one-to-one頭部進行高效預測,從而無需NMS后處理。此外,YOLOv10從效率和準確性兩個方面全面優化了YOLO的各個組件,包括輕量級分類頭部、空間-通道解耦的下采樣層、基于秩的模塊設計等,以降低計算冗余并提升模型性能。?
YOLOv10檢測器的提出不僅為實時目標檢測領域帶來了新的突破,也展示了通過后處理和模型設計的聯合優化,同時提升效率和精度的有效思路。YOLOv10檢測器有望在自動駕駛、機器人導航、物體跟蹤等實際應用中得到廣泛應用,為實時目標檢測任務帶來更高的效率。
對于后處理,我們提出了用于NMS-free訓練的一致雙分配策略,實現了高效的端到端檢測。在模型架構方面,我們引入了全面的效率和準確性驅動的模型設計策略,改善了性能和效率之間的權衡。這些創新帶來了我們的YOLOv10,這是一個全新的實時端到端目標檢測器。大量的實驗結果表明,YOLOv10與其他先進檢測器相比,在性能和延遲方面都取得了state-of-the-art的成果,充分展示了其優越性。




)

軟件開發)

)





![[Android]在后臺線程執行耗時操作,然后在主線程更新UI](http://pic.xiahunao.cn/[Android]在后臺線程執行耗時操作,然后在主線程更新UI)




