Title
題目
Robust image representations with counterfactual contrastive learning
基于反事實對比學習的魯棒圖像表征
01
文獻速遞介紹
醫學影像中的對比學習已成為利用未標記數據的有效策略。這種自監督學習方法已被證明能顯著提升模型跨領域偏移的泛化能力,并減少訓練所需的高質量標注數據量(Azizi等人,2021,2023;Ghesu等人,2022;Zhou等人,2023)。然而,基于對比的學習能否成功在很大程度上依賴于正樣本對生成流程(Tian等人,2020)。這些正樣本對通常通過對原始圖像重復應用預定義的數據增強生成。因此,增強流程的變化會對所學表征的質量產生顯著影響,最終影響下游任務性能以及對領域變化的魯棒性(Tian等人,2020;Scalbert等人,2023)。傳統上,為自然圖像開發的增強流程被直接應用于醫學影像,但由于醫學影像采集方式存在獨特挑戰和特點,這種做法可能并非最優。特別是,領域變異通常遠大于細微的類別差異。這可能導致通過對比學習獲得的表征無意中將這些無關的采集相關變異編碼到所學表征中。 在本研究中,我們旨在提高通過對比學習獲得的表征對領域偏移(尤其是采集偏移)的魯棒性。采集偏移由圖像采集協議的變化(設備設置、后處理軟件等)引起,是醫學影像領域數據集偏移的主要來源。我們假設,通過在正樣本對創建階段更真實地模擬領域變異,可以提高對比學習特征對這類圖像特征變化的魯棒性。為此,我們提出并評估了“反事實對比學習”——一種新的對比樣本對生成框架,它利用深度生成模型的最新進展來生成高質量、真實的反事實圖像(Ribeiro等人,2023;Fontanella等人,2023)。反事實生成模型使我們能夠回答“如果……會怎樣”的問題,例如模擬用一種設備采集的乳腺X線影像若用另一種設備采集會呈現何種樣子。具體而言,在我們提出的反事實對比框架中,我們通過將真實圖像與其領域反事實圖像匹配,創建跨領域正樣本對,從而真實模擬設備變化。重要的是,所提出的方法不依賴于對比目標的選擇,因為它僅影響正樣本對的創建步驟。我們以兩種廣泛使用的對比學習框架為例闡述該方法的優勢:開創性研究SimCLR(Chen等人,2020)和新發布的DINO-V2(Oquab等人,2023)目標。此外,為精確衡量所提出的反事實樣本對生成過程的效果,我們還將該方法與一種更簡單的方法進行對比——后者僅通過生成的反事實圖像擴展訓練集。 我們在兩種醫學影像模態(乳腺X線和胸部X線)、五個公共數據集以及兩項臨床相關分類任務上評估所提出的反事實對比學習框架,結果表明我們的方法能生成對領域變化更魯棒的特征。這種增強的魯棒性在特征空間中可直接觀察到,更重要的是,它帶來了下游任務性能的顯著提升,尤其是在標簽有限的情況下以及針對訓練時代表性不足的領域。關鍵的是,盡管訓練目標存在顯著差異,這些發現對SimCLR和DINO-V2均成立。本文是我們近期MICCAI研討會論文(Roschewitz等人,2024)的擴展。其差異體現在以下方面: ? 我們此前僅考慮了SimCLR目標,本文將反事實對比方法擴展至新提出的DINO-V2(Oquab等人,2023)目標。這些新結果從經驗上證明,所提出的方法具有通用性,且不依賴于對比目標的選擇。 ? 盡管本研究的主要焦點是對采集偏移的魯棒性,但在本擴展中,我們表明所提出的方法可擴展至其他場景,例如改善亞組性能。 ? 我們大幅擴充了討論、方法和相關工作部分。
Abatract
摘要
Contrastive pretraining can substantially increase model generalisation and downstream performance. However, the quality of the learned representations is highly dependent on the data augmentation strategy appliedto generate positive pairs. Positive contrastive pairs should preserve semantic meaning while discardingunwanted variations related to the data acquisition domain. Traditional contrastive pipelines attempt tosimulate domain shifts through pre-defined generic image transformations. However, these do not alwaysmimic realistic and relevant domain variations for medical imaging, such as scanner differences. To tackle thisissue, we herein introduce counterfactual contrastive learning, a novel framework leveraging recent advances incausal image synthesis to create contrastive positive pairs that faithfully capture relevant domain variations.Our method, evaluated across five datasets encompassing both chest radiography and mammography data,for two established contrastive objectives (SimCLR and DINO-v2), outperforms standard contrastive learningin terms of robustness to acquisition shift. Notably, counterfactual contrastive learning achieves superiordownstream performance on both in-distribution and external datasets, especially for images acquired withscanners under-represented in the training set. Further experiments show that the proposed framework extendsbeyond acquisition shifts, with models trained with counterfactual contrastive learning reducing subgroupdisparities across biological sex.
對比預訓練能顯著提升模型的泛化能力和下游任務性能。然而,所學表征的質量高度依賴于用于生成正樣本對的數據增強策略。對比學習中的正樣本對應在保留語義含義的同時,摒棄與數據采集領域相關的非期望變異。傳統的對比學習流程試圖通過預定義的通用圖像變換來模擬領域偏移。但對于醫學影像而言,這些變換并不總能模擬真實且相關的領域變異,例如掃描儀差異。 為解決這一問題,我們在此提出反事實對比學習——一種利用因果圖像合成最新進展的新型框架,旨在生成能真實捕捉相關領域變異的對比正樣本對。我們的方法在五個涵蓋胸部X線和乳腺X線數據的數據集上進行了評估,針對兩種成熟的對比目標(SimCLR和DINO-v2),結果顯示其在對采集偏移的魯棒性方面優于標準對比學習。值得注意的是,反事實對比學習在分布內數據集和外部數據集上均實現了更優的下游性能,尤其對于訓練集中代表性不足的掃描儀所采集的圖像而言。進一步實驗表明,該框架的優勢不僅限于采集偏移:經反事實對比學習訓練的模型還能減少不同生物學性別亞組間的差異。
Results
結果
In this section, we compare the quality and robustness of thelearned representations for various pre-training paradigms. First, standard SimCLR. Secondly, SimCLR+, where we train a model using classicSimCLR on a training set enriched with domain counterfactuals. Finally,CF-SimCLR combines SimCLR with our proposed counterfactual contrastive pair generation framework. We then repeat the same analysisfor models pre-trained with the DINO objective, comparing DINO, CFDINO and DINO+. Note that in SimCLR+ (resp. DINO+), counterfactualsand real images are not paired during the contrastive learning step;they are all considered as independent training samples. As such, SimCLR+/DINO+ represent the common paradigm of simply enriching thetraining set with synthetic examples. In CF-SimCLR/CF-DINO, on theother hand, we systematically pair real images with their correspondingcounterfactual for positive pair creation (Fig. 1).We compare the effect of these three pretraining strategies on chestX-rays and mammograms. For chest X-rays, we evaluate the qualityof the learned representations by assessing downstream performanceon pneumonia detection. For mammography, we focus on the task ofbreast density prediction (important for risk modelling). Pre-trainingstrategies are evaluated with linear probing (i.e. classifiers trained ontop of frozen encoders) as well as full model finetuning (unfrozen encoders). Linear probes are best representative of the quality of learnedrepresentation during pre-training, as representations are unchangedduring downstream training. However we also include the comparisonwith full model finetuning, as this is often the training paradigm ofchoice in practical scenarios. All models are finetuned with real dataonly, using a weighted cross-entropy loss. We evaluate the pre-trainedencoders in two settings. First, we test the encoders on ID datasets,i.e. using the same data for pre-training, finetuning and testing. Secondly, encoders are evaluated on OOD datasets, i.e. where the model isfinetuned/linear-probed and tested on data external to the pre-trainingdata. Evaluation on external datasets is crucial to assess how counterfactual contrastive pretraining performs on unseen domains (outside ofscanner distribution used for training the causal inference model). Allencoders are pretrained on the full, unlabelled, PadChest and EMBEDdatasets. However, the main motivation for self-supervised pretrainingis to increase robustness when only a limited amount of labelled datais available (Azizi et al., 2023). Hence, we evaluate the encoders forvarying amounts of annotated data. Specifically, we finetune (or linearprobe) the encoder using a pre-defined amount of labelled samples, andthen evaluate the resulting classifier on a fixed test set. We repeat thisprocess several times, varying the amount of labelled samples to assessthe effect of pre-training in function of number of labelled samplesavailable for training the downstream classifier, e.g. for PadChest, thenumber of labelled training samples varies from 3249 to 64,989. Allour code is publicly available at https://github.com/biomedia-mira/counterfactual-contrastive.For each task, we compare downstream performance across variouspretraining strategies, for each scanner, for both SimCLR (Figs. 5 and
and DINO (Figs. 9 and 11) objectives. Moreover, to help visualiseperformance differences across encoders, we report the performancedifferences between the proposed encoders and the baseline in Figs.6, 8, 10 and 12.
在本節中,我們對比了不同預訓練范式下所學表征的質量和魯棒性。首先是標準的SimCLR;其次是SimCLR+,即在添加了領域反事實圖像的訓練集上,使用經典SimCLR方法訓練模型;最后是CF-SimCLR,它將SimCLR與我們提出的反事實對比樣本對生成框架相結合。隨后,我們對采用DINO目標函數預訓練的模型進行了相同分析,對比了DINO、CF-DINO和DINO+。需要注意的是,在SimCLR+(分別對應DINO+)中,反事實圖像與真實圖像在對比學習步驟中并未配對,而是均被視為獨立的訓練樣本。因此,SimCLR+/DINO+代表了一種常見范式——僅通過合成樣本來擴充訓練集。與之不同的是,在CF-SimCLR/CF-DINO中,我們系統性地將真實圖像與其對應的反事實圖像配對,用于正樣本對的創建(圖1)。 我們在胸部X線和乳腺X線影像上對比了這三種預訓練策略的效果。對于胸部X線,我們通過評估肺炎檢測下游任務的性能來衡量所學表征的質量;對于乳腺X線,我們重點關注乳腺密度預測任務(這對風險建模至關重要)。預訓練策略的評估采用兩種方式:線性探測(即在凍結的編碼器頂部訓練分類器)和全模型微調(解凍編碼器)。線性探測最能代表預訓練階段所學表征的質量,因為在下游訓練過程中表征保持不變。但我們也納入了與全模型微調的對比,因為這通常是實際場景中首選的訓練范式。所有模型均僅使用真實數據進行微調,并采用加權交叉熵損失函數。 我們在兩種設置下評估預訓練編碼器:首先,在分布內(ID)數據集上測試編碼器,即預訓練、微調和測試均使用相同數據;其次,在分布外(OOD)數據集上評估編碼器,即模型的微調/線性探測和測試均使用預訓練數據之外的數據。在外部數據集上的評估至關重要,這能衡量反事實對比預訓練在未見過的領域(超出用于訓練因果推斷模型的掃描儀分布范圍)上的表現。所有編碼器均在完整的、未標記的PadChest和EMBED數據集上進行預訓練。 然而,自監督預訓練的主要目的是在僅有有限標注數據可用時提高模型魯棒性(Azizi等人,2023)。因此,我們在不同數量的標注數據下對編碼器進行了評估。具體而言,我們使用預定義數量的標注樣本對編碼器進行微調(或線性探測),然后在固定測試集上評估所得分類器的性能。我們重復這一過程多次,通過改變標注樣本的數量,來評估預訓練效果隨下游分類器訓練可用標注樣本數量的變化——例如,在PadChest數據集中,標注訓練樣本的數量從3249個到64989個不等。我們的所有代碼均公開可獲取,鏈接為:https://github.com/biomedia-mira/counterfactual-contrastive。 對于每個任務,我們在SimCLR(圖5和圖7)和DINO(圖9和圖11)兩種目標函數下,按掃描儀分別對比了不同預訓練策略的下游任務性能。此外,為便于可視化不同編碼器之間的性能差異,我們在圖6、圖8、圖10和圖12中報告了所提編碼器與基線模型的性能差異。
Figure
圖
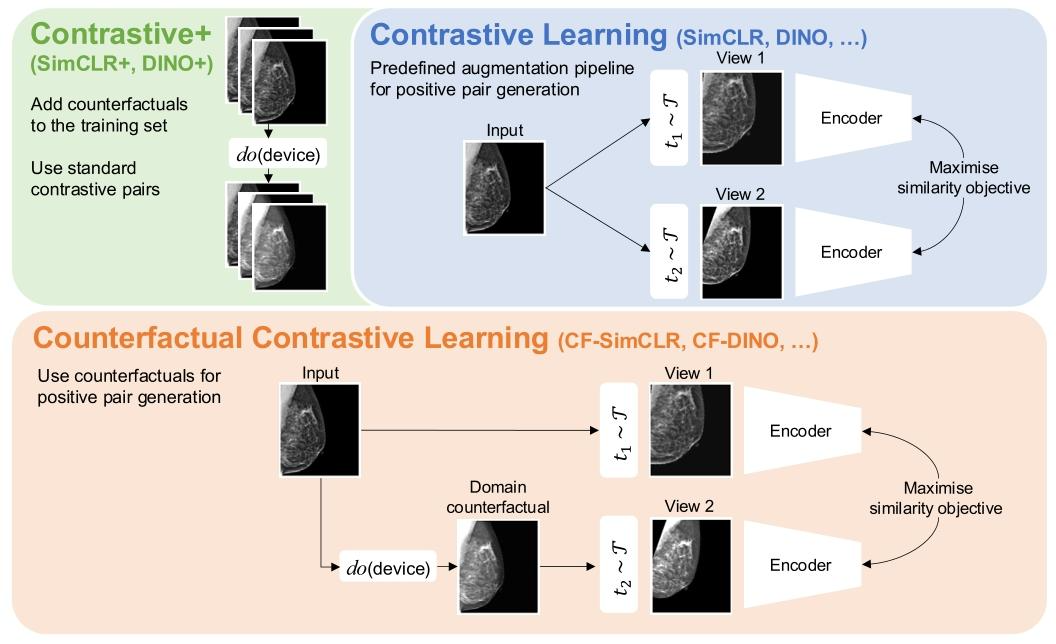
Fig. 1. We propose a novel counterfactual contrastive pair generation framework for improving robustness of contrastively-learned features to distribution shift. As opposed tosolely relying on a pre-defined augmentation generation pipeline (as in standard contrastive learning), we propose to combine real images with their domain counterfactuals tocreate realistic cross-domain positive pairs. Importantly, this proposed approach is independent of the specific contrastive objective employed. The causal image generation modelis represented by the ‘do’ operator. We also compare the proposed method to another approach where we simply extend the training set with the generated counterfactual imageswithout explicit matching with their real counterparts, treating real and counterfactuals as independent training samples.
圖1. 我們提出一種新穎的反事實對比樣本對生成框架,旨在提高對比學習特征對分布偏移的魯棒性 ? 與標準對比學習中僅依賴預定義的增強生成流程(\mathcal{T})不同,我們提出將真實圖像與其領域反事實圖像相結合,以創建真實的跨領域正樣本對。重要的是,該方法獨立于所采用的特定對比目標。因果圖像生成模型由“do”算子表示。我們還將所提方法與另一種方法進行對比:后者僅通過生成的反事實圖像擴展訓練集,不與真實圖像進行顯式匹配,而是將真實圖像和反事實圖像視為獨立的訓練樣本。
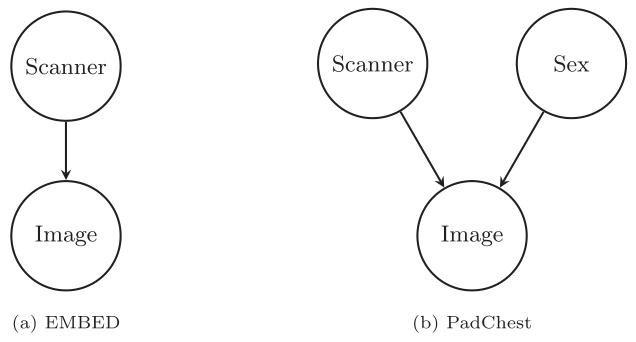
Fig. 2. Causal graphs used to train the counterfactual image generation models usedin this study
圖2. 本研究中用于訓練反事實圖像生成模型的因果圖
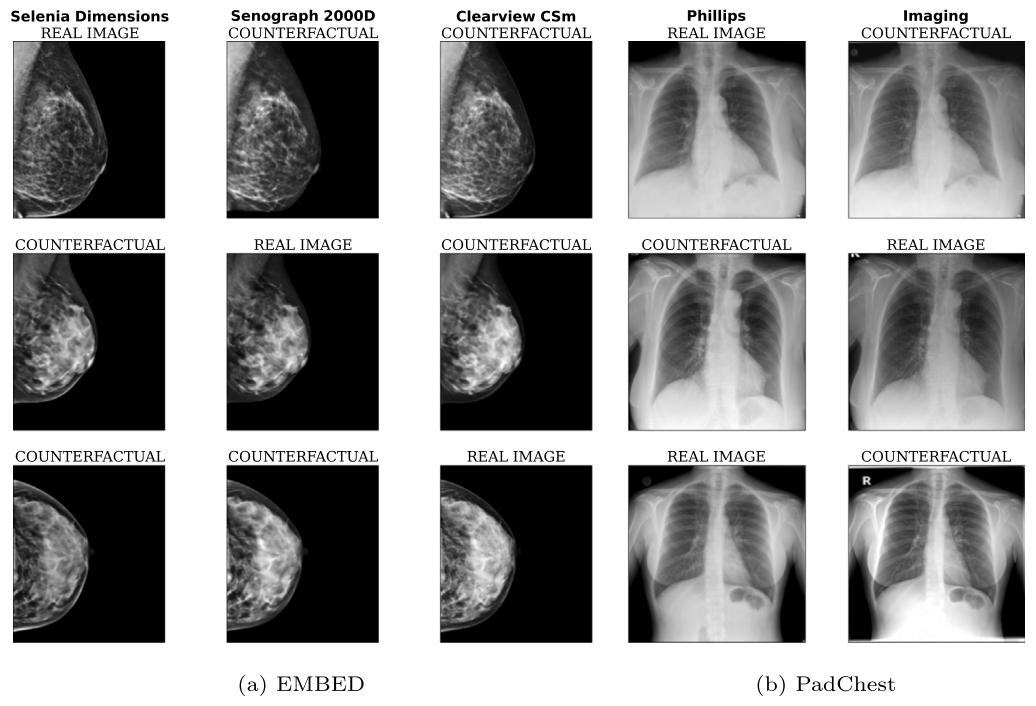
Fig. 3. Examples of counterfactual images generated with our model. Note that on PadChest, text is only imprinted on a subset of Imaging scans (not on Phillips): our modelrespects this by removing text when generating counterfactuals from Imaging to Phillips and vice-versa. Generated images have a resolution of 224 × 224 pixels for PadChest and224 × 192 for EMBED
圖3. 利用我們的模型生成的反事實圖像示例 ? 注意,在PadChest數據集中,文本僅標記在部分Imaging掃描儀的圖像上(未標記在Phillips掃描儀的圖像上):我們的模型在從Imaging到Phillips以及從Phillips到Imaging生成反事實圖像時,會相應地移除或添加文本,以此遵循這一特性。生成的圖像中,PadChest數據集的圖像分辨率為224×224像素,EMBED數據集的為224×192像素。
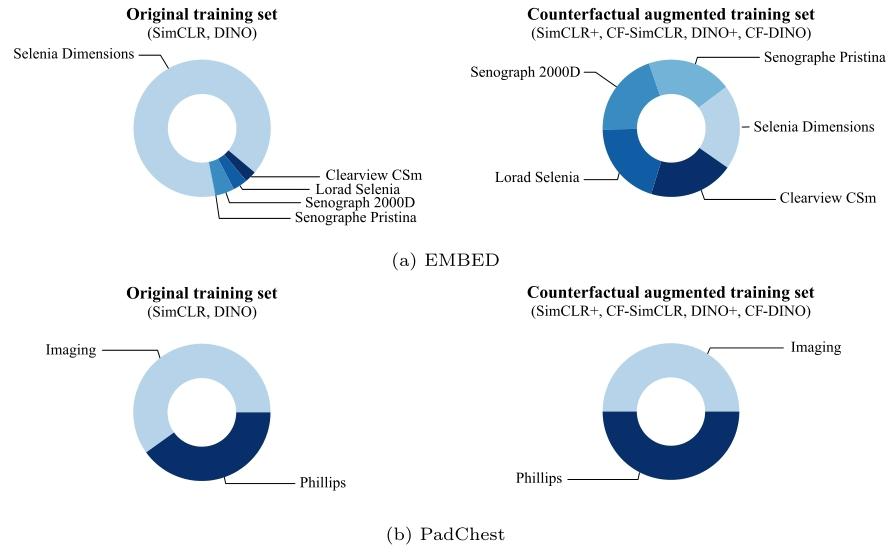
Fig. 4. Distribution of scanners in the original (real-only) training set and the counterfactual-augmented training set for EMBED (top) and PadChest (bottom)
圖4. EMBED(上)和PadChest(下)數據集在原始(僅真實圖像)訓練集與反事實增強訓練集中的掃描儀分布情況
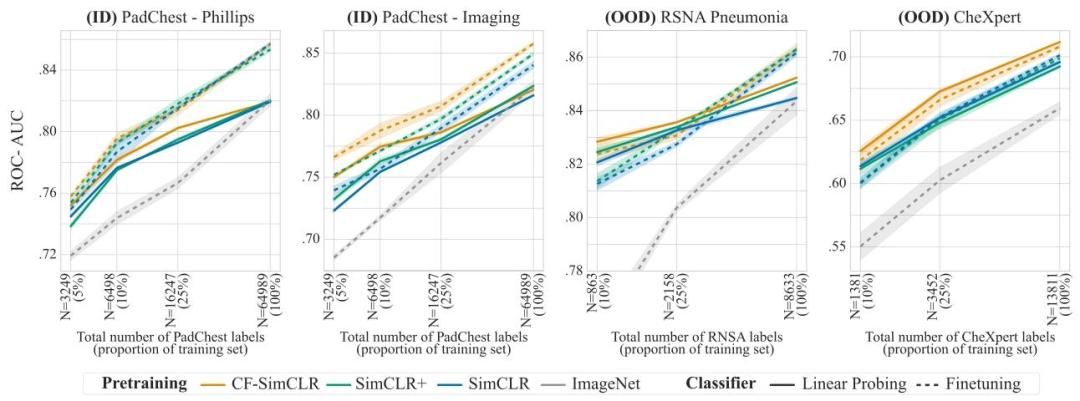
Fig. 5. Pneumonia detection results with linear probing (frozen encoder, solid lines) and finetuning (unfrozen encoder, dashed lines) for models trained with the SimCLR objective.Results are reported as average ROC-AUC over 3 seeds, shaded areas denote ± one standard error. We also compare self-supervised encoders to a supervised baseline initialisedwith ImageNet weights.
圖5. 采用SimCLR目標函數訓練的模型在肺炎檢測任務中的線性探測(編碼器凍結,實線)和微調(編碼器解凍,虛線)結果 ? 結果以3次隨機種子實驗的平均ROC-AUC值呈現,陰影區域表示±1標準誤差。我們還將自監督編碼器與以ImageNet權重初始化的有監督基線模型進行了對比。
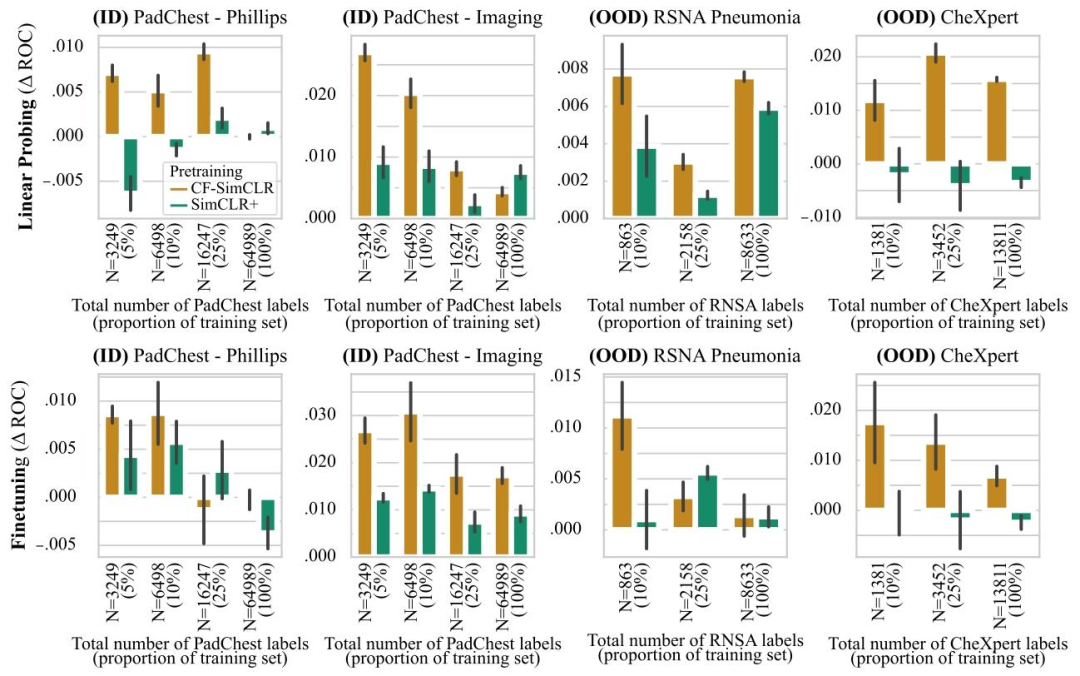
Fig. 6.ROC-AUC difference to SimCLR baseline for CF-SimCLR and SimCLR+ for pneumonia detection. The top row depicts results with linear probing, bottom row shows resultswith model finetuning. Results are reported as average ROC-AUC difference compared to the baseline (SimCLR) over 3 seeds, error bars denote ± one standard error. CF-SimCLRconsistently outperforms encoders trained with standard SimCLR and SimCLR+ (where counterfactuals are added to the training set) for linear probing, and performs best overallfor full model finetuning
圖6. CF-SimCLR和SimCLR+相對于SimCLR基線在肺炎檢測任務中的ROC-AUC差異** ? 上排為線性探測結果,下排為模型微調結果。結果以3次隨機種子實驗中相對于基線(SimCLR)的平均ROC-AUC差異呈現,誤差線表示±1標準誤差。在 linear probing 中,CF-SimCLR 始終優于采用標準 SimCLR 和 SimCLR+(將反事實圖像添加到訓練集)訓練的編碼器;在全模型微調中,CF-SimCLR 總體表現最佳。?
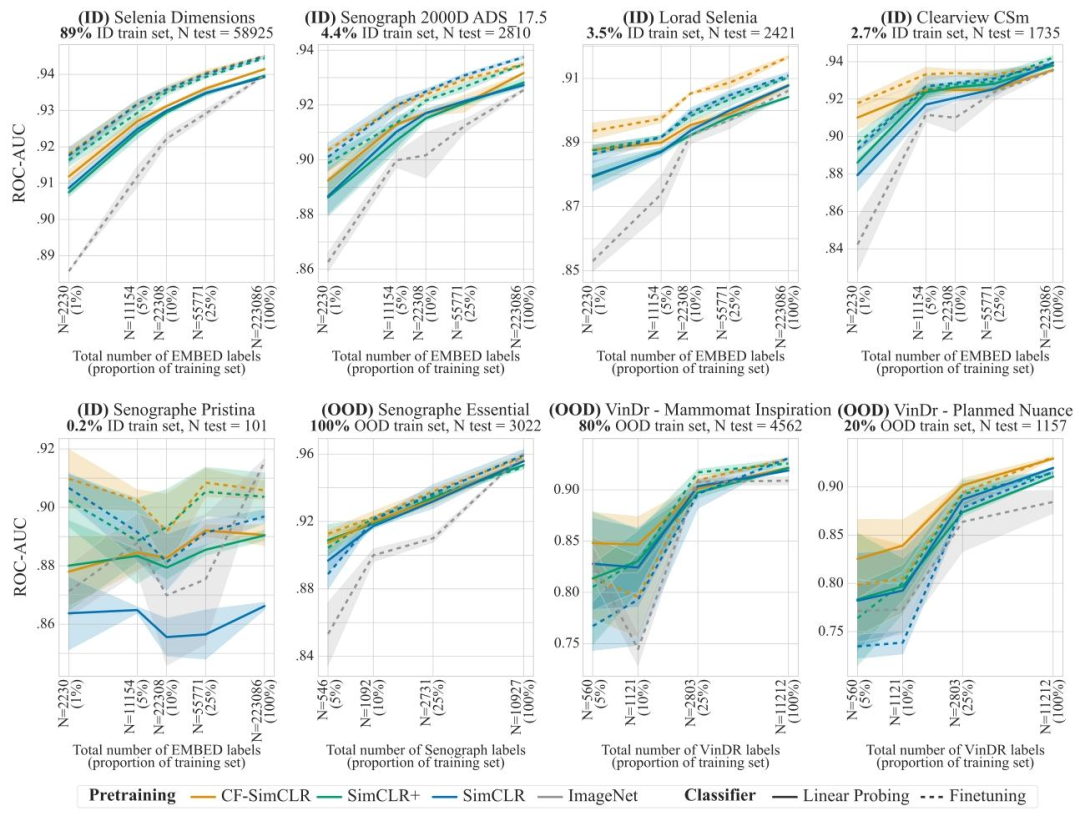
Fig. 7. Breast density results with linear probing (frozen encoder, solid lines) and finetuning (unfrozen encoder, dashed lines) for models trained with SimCLR. Results are reportedas average one-versus-rest macro ROC-AUC over 3 seeds, shaded areas denote ± one standard error. CF-SimCLR performs best overall across ID and OOD data, and improvementsare largest in the low data regime and on under-represented scanners
圖7. 采用SimCLR訓練的模型在乳腺密度預測任務中的線性探測(編碼器凍結,實線)和微調(編碼器解凍,虛線)結果 ? 結果以3次隨機種子實驗的平均“一對多”宏ROC-AUC值呈現,陰影區域表示±1標準誤差。CF-SimCLR在分布內(ID)和分布外(OOD)數據上總體表現最佳,且在數據量較少的場景以及針對代表性不足的掃描儀時,改進效果最為顯著。
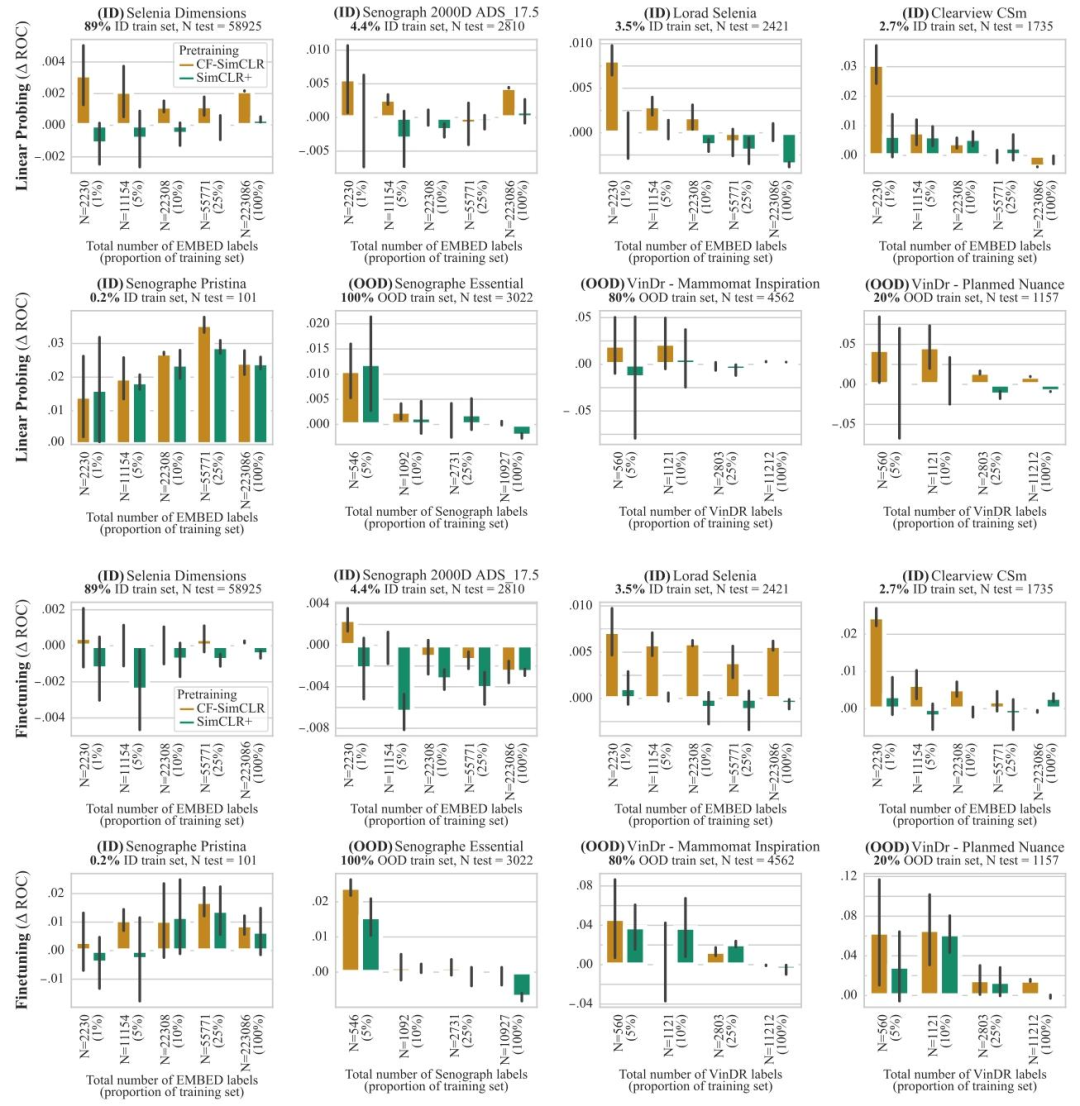
Fig. 8. ROC-AUC difference between SimCLR and CF-SimCLR (resp. SimCLR+) for breast density assessment. The top two rows denote results with linear probing, and the bottomtwo rows show results with model finetuning. Results are reported as average macro ROC-AUC difference compared to the baseline (SimCLR) over 3 seeds, error bars denote ±one standard error. CF-SimCLR overall performs best across ID and OOD data, improvements are largest in the low data regime and on under-represented scanners
圖8. SimCLR與CF-SimCLR(分別對應SimCLR+)在乳腺密度評估任務中的ROC-AUC差異 ? 上兩行表示線性探測結果,下兩行表示模型微調結果。結果以3次隨機種子實驗中相對于基線(SimCLR)的平均宏ROC-AUC差異呈現,誤差線表示±1標準誤差。CF-SimCLR在分布內(ID)和分布外(OOD)數據上總體表現最佳,且在數據量較少的場景以及針對代表性不足的掃描儀時,改進效果最為顯著。
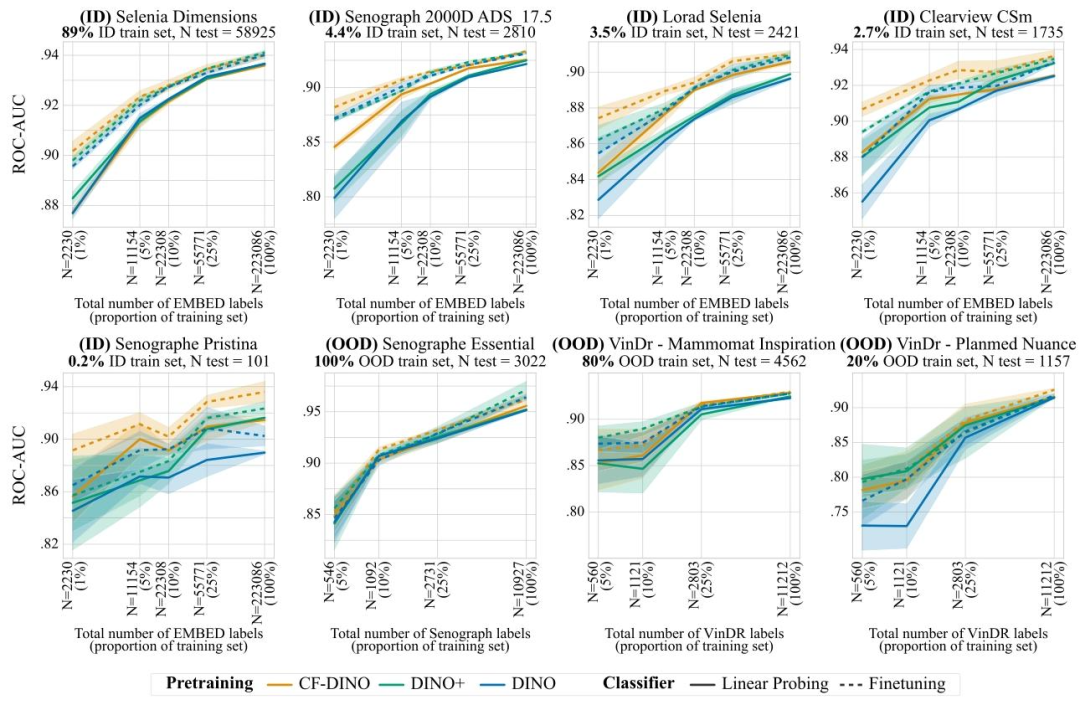
Fig. 9. Breast density classification results for models pretrained with DINO-v2, for both linear probing and finetuning. Results are reported as average one-versus-rest macroROC-AUC over 3 seeds, shaded areas denote ± one standard error. CF-DINO performs best overall, across ID and OOD data, improvements are largest in the low data regime.
圖9. 采用DINO-v2預訓練的模型在乳腺密度分類任務中的線性探測和微調結果 ? 結果以3次隨機種子實驗的平均“一對多”宏ROC-AUC值呈現,陰影區域表示±1標準誤差。CF-DINO在分布內(ID)和分布外(OOD)數據上總體表現最佳,且在數據量較少的場景中改進效果最為顯著。
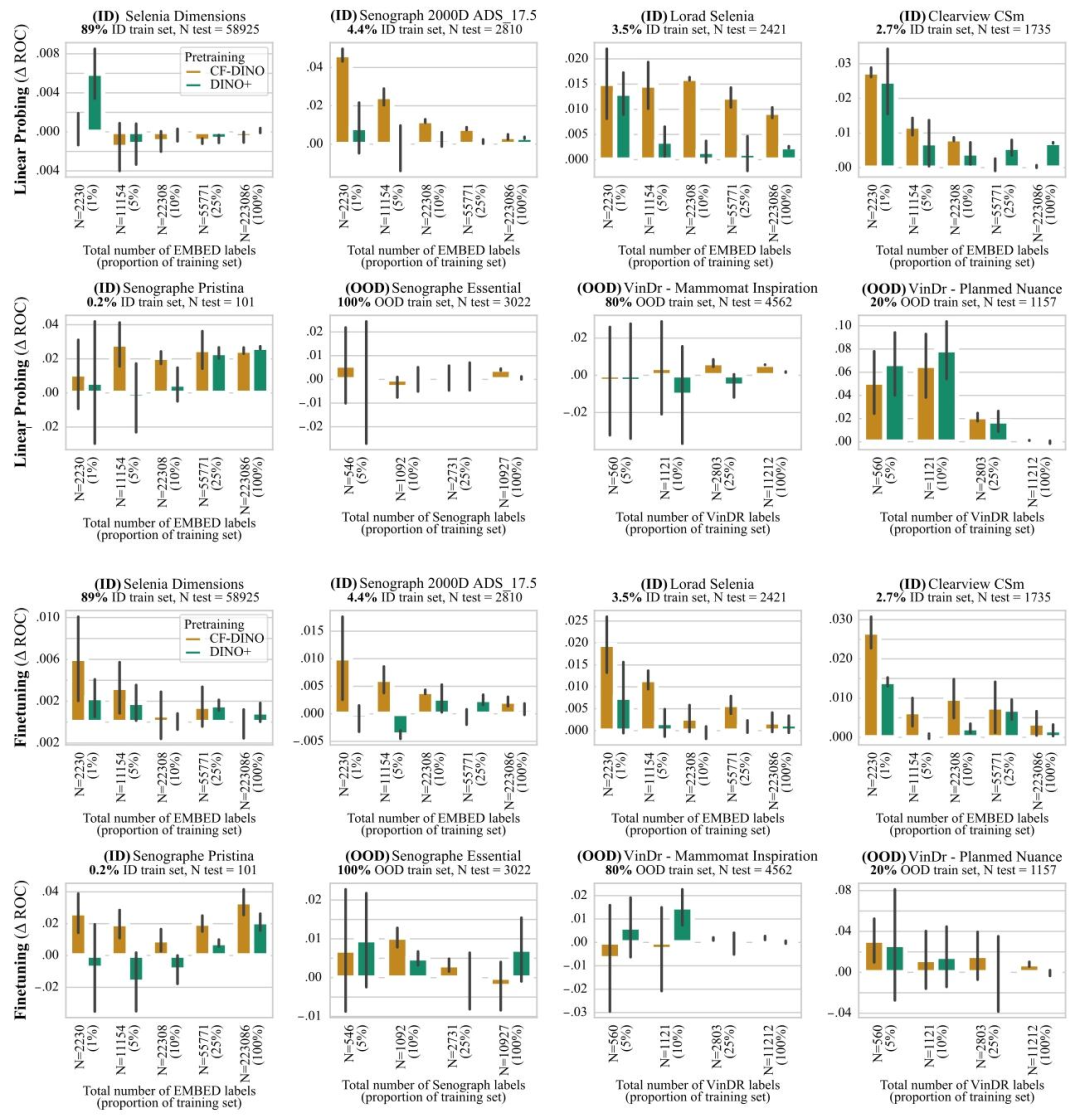
Fig. 10. ROC-AUC difference between DINO and CF-DINO (resp. DINO+). Top two rows denote results with linear probing, bottom two rows results with model finetuning. Resultsare reported as average macro ROC-AUC difference compared to the baseline (DINO) over 3 seeds, error bars denote ± one standard error. CF-DINO overall performs best acrossID and OOD data, improvements are largest in the low data regime and on under-represented scanners.
圖10. DINO與CF-DINO(分別對應DINO+)的ROC-AUC差異 ? 上兩行表示線性探測結果,下兩行表示模型微調結果。結果以3次隨機種子實驗中相對于基線(DINO)的平均宏ROC-AUC差異呈現,誤差線表示±1標準誤差。CF-DINO在分布內(ID)和分布外(OOD)數據上總體表現最佳,且在數據量較少的場景以及針對代表性不足的掃描儀時,改進效果最為顯著。
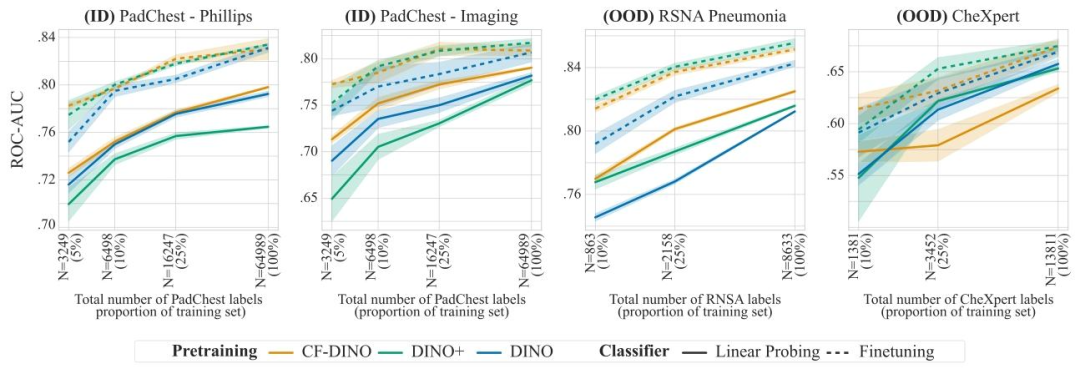
Fig. 11. Pneumonia detection results for models trained with DINO-v2, for both linear probing (frozen encoder) and finetuning. Results are reported as average ROC-AUC over 3seeds, shaded areas denote ± one standard error. CF-DINO consistently outperforms standard DINO.
圖11. 采用DINO-v2訓練的模型在肺炎檢測任務中的線性探測(編碼器凍結)和微調結果 ? 結果以3次隨機種子實驗的平均ROC-AUC值呈現,陰影區域表示±1標準誤差。CF-DINO始終優于標準DINO。
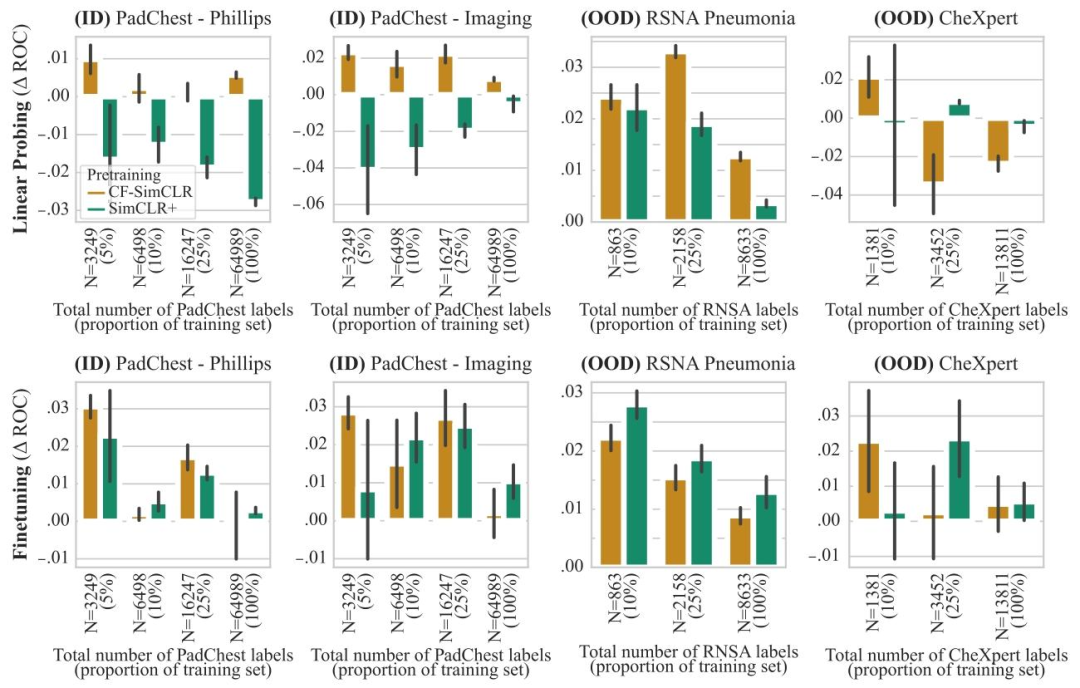
Fig. 12. ROC-AUC difference to DINO baseline for CF-DINO and DINO+ for pneumonia detection. The top row depicts results with linear probing, bottom row show results withmodel finetuning. Results are reported as average ROC-AUC difference compared to the baseline (DINO) over 3 seeds, error bars denote ± one standard error.
圖12. CF-DINO和DINO+相對于DINO基線在肺炎檢測任務中的ROC-AUC差異 ? 上排為線性探測結果,下排為模型微調結果。結果以3次隨機種子實驗中相對于基線(DINO)的平均ROC-AUC差異呈現,誤差線表示±1標準誤差。
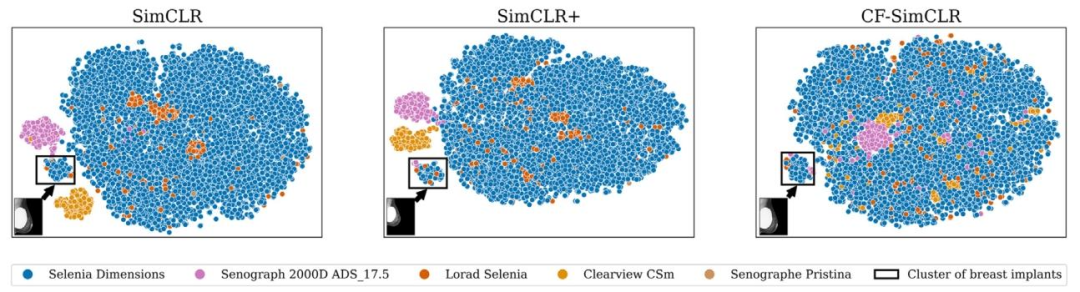
Fig. 13. t-SNE projections of embeddings from 16,000 randomly sampled test images from mammography encoders trained with SimCLR, SimCLR+ and CF-SimCLR. Encoderstrained with SimCLR and SimCLR+ exhibit domain clustering. CF-SimCLR embeddings are substantially less domain-separated and the only disjoint cluster exclusively containsbreasts with implants, semantically different. Thumbnails show a randomly sampled image from each ‘implant’ cluster.
圖13. 采用SimCLR、SimCLR+和CF-SimCLR訓練的乳腺影像編碼器對16,000張隨機采樣測試圖像的嵌入特征的t-SNE投影 ? 經SimCLR和SimCLR+訓練的編碼器存在領域聚類現象。CF-SimCLR的嵌入特征領域分離度顯著降低,且唯一的離散聚類僅包含帶有假體的乳腺圖像——這在語義上具有明確差異。縮略圖展示了每個“假體”聚類中隨機采樣的圖像。
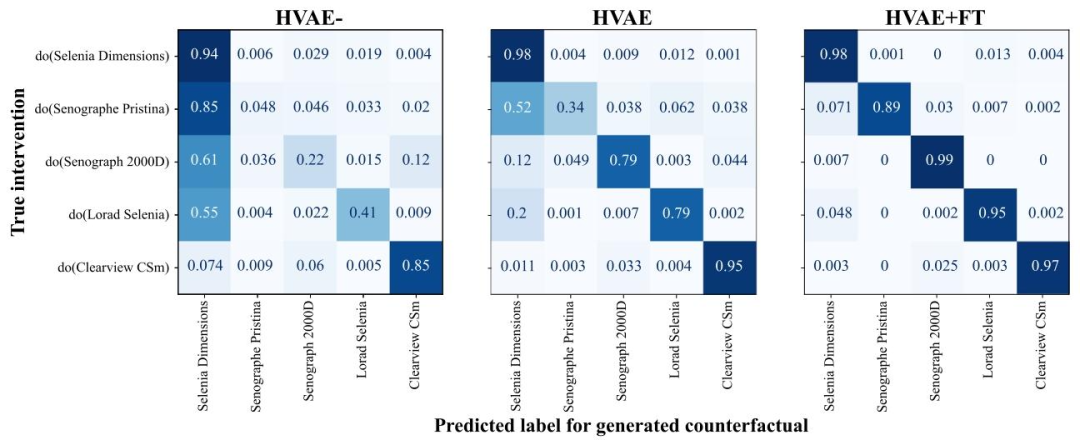
Fig. 14. Effectiveness comparison for the three counterfactual models considered in this ablation study, by intervention. Computed on 8304 validation set samples.
圖 14. 本消融研究中所考慮的三種反事實模型在不同干預條件下的有效性對比基于 8304 個驗證集樣本計算得出。
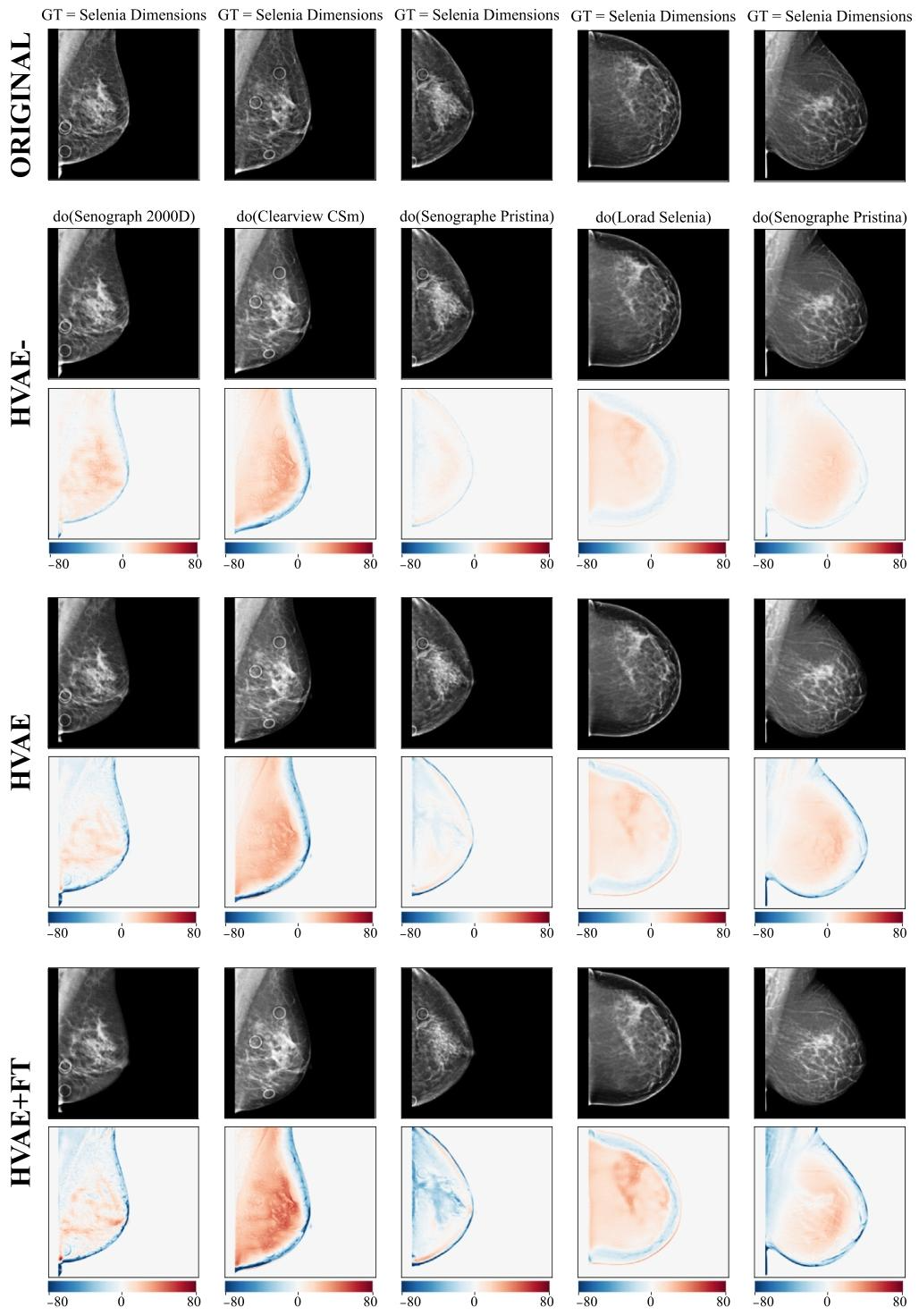
Fig. 15. Qualitative of comparison of the three counterfactual generation models, HVAE-, HVAE and HVAE+FT compared in the ablation study. For each model we show generatedcounterfactuals as well as direct effect maps. Direct effects give a visual depiction of the increase in effectiveness across the three models from top to bottom. We also observethat all models preserve semantic identity very well, a key aspect in positive pair creation contrastive learning
圖15. 消融研究中三種反事實生成模型(HVAE?、HVAE和HVAE+FT)的定性對比 ? 對于每個模型,我們展示了生成的反事實圖像以及直接效應圖。直接效應圖直觀呈現了從頂部到底部三個模型有效性的提升。我們還觀察到,所有模型都能很好地保留語義一致性——這是對比學習中構建正樣本對的關鍵要素。
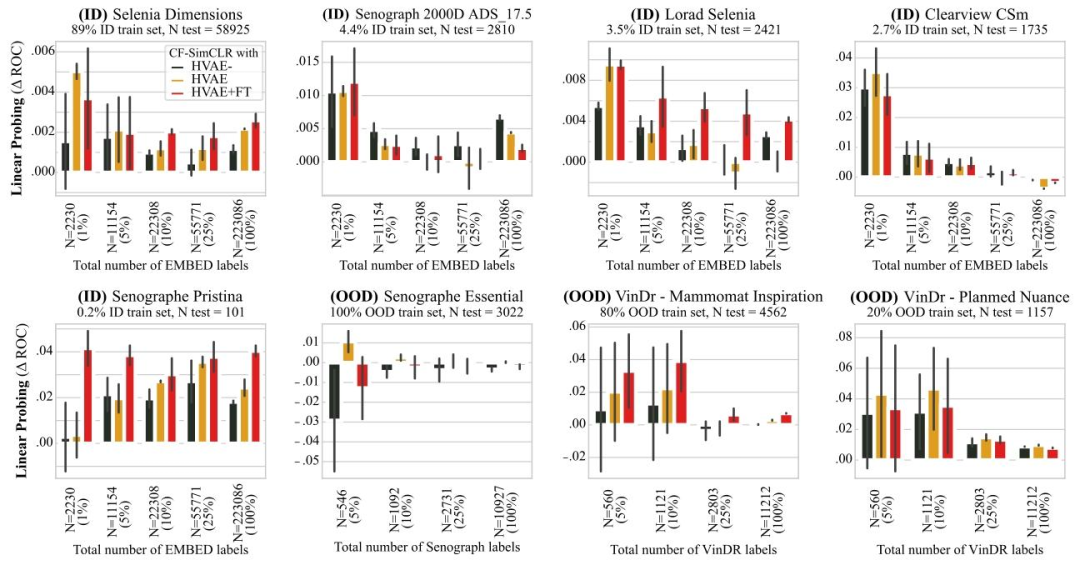
Fig. 16. Effect of counterfactual quality on downstream performance. Results are reported as average macro ROC-AUC difference compared to the baseline (SimCLR) over 3 seedsfor linear probing, error bars denote ± one standard error. We compare running CF-SimCLR with (i) HVAE- a counterfactual generation model of lesser effectiveness, (ii) HVAEthe generation model used in the rest of this study, (iii) HVAE+FT a counterfactual generation model with higher effectivenes
圖16. 反事實質量對下游任務性能的影響 結果以3次隨機種子實驗中線性探測相對于基線(SimCLR)的平均宏ROC-AUC差異呈現,誤差線表示±1標準誤差。我們對比了使用以下三種反事實生成模型的CF-SimCLR性能:(i)HVAE?——一種有效性較低的反事實生成模型;(ii)HVAE——本研究其余部分所使用的生成模型;(iii)HVAE+FT——一種有效性更高的反事實生成模型。?
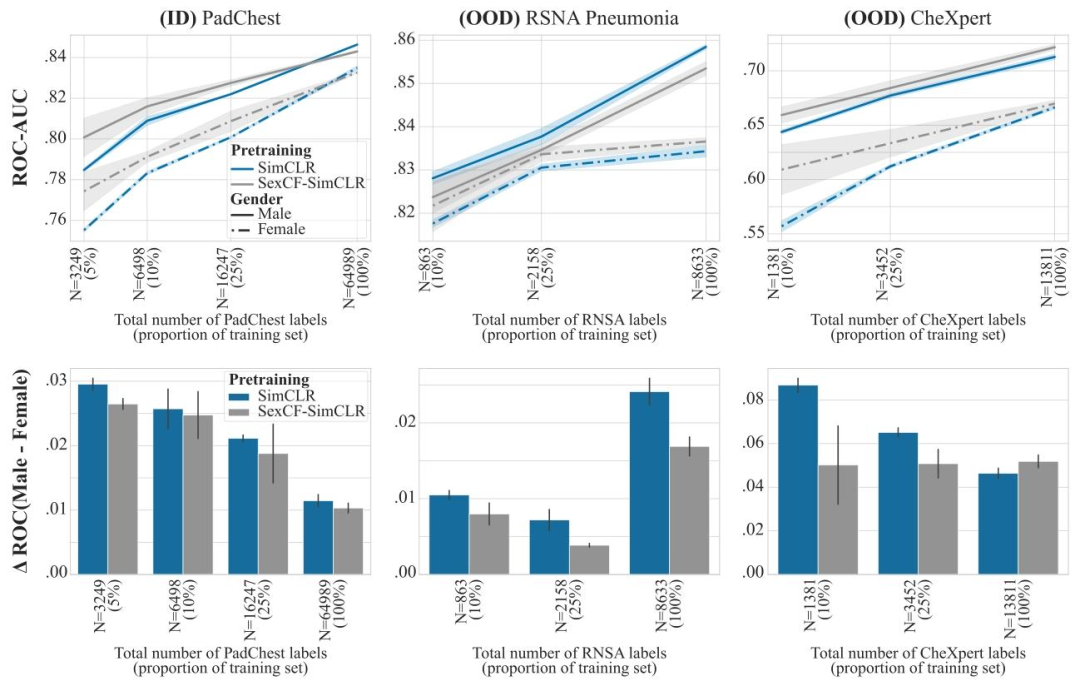
Fig. 17. Improving sub-group performance with counterfactual contrastive learning. Pneumonia detection results with linear probing for encoders trained with SimCLR andSexCF-SimCLR. In SexCF-SimCLR, we generate sex counterfactuals instead of domain counterfactuals for positive pair generation to improve robustness to subgroup shift and,ultimately, performance on under-represented subgroups. Top row: performance for the male (solid line) and female (dashed line) subgroups, reported as average ROC-AUC over3 seeds, shaded areas denote ± standard error. Bottom row: performance disparities across the two subgroups, reported as average ROC-AUC difference between the male andfemale subgroups, over 3 seeds. Sex CF-SimCLR reduces sub-group disparities for all datasets, substantially increasing performance on the female sub-group when limited amountsof labels are available, both on ID and OOD datasets
圖17. 利用反事實對比學習提升亞組性能 ?采用SimCLR和SexCF-SimCLR訓練的編碼器在肺炎檢測任務中的線性探測結果。在SexCF-SimCLR中,我們生成性別反事實而非領域反事實用于正樣本對構建,以增強對亞組偏移的魯棒性,并最終提升代表性不足亞組的性能。 ? 上排:男性(實線)和女性(虛線)亞組的性能,以3次隨機種子實驗的平均ROC-AUC值呈現,陰影區域表示±標準誤差。 ? 下排:兩個亞組間的性能差異,以3次隨機種子實驗中男性與女性亞組的平均ROC-AUC差值呈現。 ? SexCF-SimCLR降低了所有數據集的亞組性能差異,在標注數據有限的情況下,顯著提升了女性亞組在分布內(ID)和分布外(OOD)數據集上的性能。?
Table
表
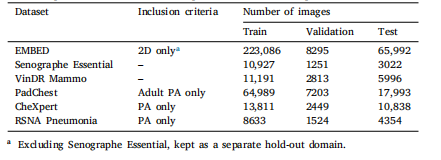
Table 1Datasets splits and inclusion criteria. Splits are created at the patient level
表1 數據集劃分及納入標準 ? 數據集劃分以患者為單位進行。
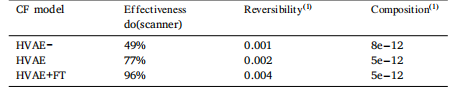
Table 2Axiomatic soundness metrics (Monteiro et al., 2022) for the three models consideredin this ablation study. Computed on the 8304 validation set samples
表2 本消融研究中所考慮的三種模型的公理合理性指標(Monteiro等人,2022) ? 基于8304個驗證集樣本計算得出。
:樸素貝葉斯分類算法)



、主機虛擬機(Windows、Ubuntu)、手機(筆記本熱點),三者進行相互ping通)














