目錄
- 一、透明大頁
- 1.1 原理
- 1.2 透明大頁的三大優勢
- 1.3 透明大頁控制接口詳解
- 1.4 使用場景與最佳實踐
- 1.5 問題排查與監控
- 1.6 與傳統大頁的對比
- 二、Linux伙伴系統水位機制詳解
- 2.1 三種核心水位詳解
- 2.2 水位在伙伴系統中的實現
- 2.3 水位觸發機制的實際行為
- 2.4 水位關鍵操作接口
- 2.5 水位優化策略
- 2.6 水位與其他機制的關系
- 2.7 kswapd:內存回收守護進程
- 三、/proc/sys/vm/extfrag_threshold
- 3.1 基本概念
- 3.2 作用
- 3.3 配置方法
- 3.4 kcompactd:內存碎片規整守護進程
- 3.5 與伙伴系統水位有什么區別
- 四、Linux 內存規整機制
- 4.1 內存規整關鍵特性演進
- 4.2 新舊內核性能對比分析
- 4.3 kswapd與kcompactd的協同機制
- 4.4 診斷命令與參數調整
- 五、/proc/sys/vm/min_free_kbytes
- 5.1 這個保留的內存能不能被使用?
- 5.2 保留的意義是什么?
- 5.3 詳細解釋和工作機制
- 5.4 假如設置 `echo 16384 > /proc/sys/vm/min_free_kbytes`
- 六、直接同步回收(Direct Reclaim)深度解析
- 6.1 直接同步回收 vs kswapd/kcompactd
- 6.2 直接同步回收的完整執行流程
- 6.3 性能影響與優化
- 6.4 總結
一、透明大頁
# 1. 手動觸發內存壓縮
echo 1 > /proc/sys/vm/compact_memory# 2. 檢查碎片指數
cat /proc/buddyinfo
cat /proc/pagetypeinfo# 3. 調整透明大頁
echo always > /sys/kernel/mm/transparent_hugepage/enabled
1.1 原理
??透明大頁(Transparent HugePages,簡稱 THP)是 Linux 內核的一種自動化內存優化技術,它通過將多個標準 4KB 頁動態合并為更大的 2MB 或 1GB 頁,顯著提升系統性能。/sys/kernel/mm/transparent_hugepage/enabled 正是控制這一特性的關鍵接口。
| 特性 | 標準頁 (4KB) | 透明大頁 (2MB/1GB) |
|---|---|---|
| 頁大小 | 4KB | 2MB (512倍) 或 1GB |
| 頁表項數量 | 多 (約 50 萬/GB) | 少 (512/GB) |
| TLB 覆蓋率 | 低 | 高 |
| 內存管理 | 靜態分配 | 動態合并 |
??在 Linux 系統中,可以通過以下幾種方法來確認內核是否開啟透明大頁(Transparent Huge Pages,THP)功能:
方法一:查看 /sys/kernel/mm/transparent_hugepage/enabled 文件
??透明大頁的狀態信息存儲在 /sys/kernel/mm/transparent_hugepage/enabled 文件中,你可以使用 cat 命令查看該文件的內容:
cat /sys/kernel/mm/transparent_hugepage/enabled
- 輸出示例及含義
- 如果輸出為
[always] madvise never,表示透明大頁功能已開啟,并且始終嘗試使用大頁。方括號[]括起來的選項表示當前生效的設置。 - 如果輸出為
always madvise [never],則表示透明大頁功能已關閉。 - 如果輸出為
always [madvise] never,表示使用madvise系統調用的方式來決定是否使用大頁,即應用程序可以通過madvise系統調用顯式地請求或避免使用大頁。
- 如果輸出為
方法二:使用 grep 結合 /proc/meminfo 文件
??你也可以通過在 /proc/meminfo 文件中查找與透明大頁相關的信息來間接確認其狀態:
grep -i huge /proc/meminfo
- 輸出示例及含義
- 如果輸出中包含類似
AnonHugePages的信息,且其值不為 0,則說明透明大頁功能可能是開啟的,因為AnonHugePages表示匿名大頁的使用情況。例如:
- 如果輸出中包含類似
AnonHugePages: 204800 kB
?? 不過這種方法只能作為一個參考,因為即使 AnonHugePages 為 0,也不能完全確定透明大頁功能是關閉的,還需要結合前面的方法來綜合判斷。
1.2 透明大頁的三大優勢
- TLB(轉換后援緩沖器)優化
- 問題:TLB 容量有限(通常 64-512 條目)
- 解決:單個 2MB 頁表項覆蓋 512 倍內存區域
- 效果:TLB 未命中率降低 80-90%
- 頁表遍歷加速
- 傳統頁表:4 級頁表查找(PGD→PUD→PMD→PTE)
- 大頁頁表:跳過 PTE 層查找(PGD→PUD→PMD)
- 性能提升:內存訪問延遲降低 30-70%
- 內存操作效率
| 操作 | 標準頁 (512次) | 大頁 (1次) | 提升倍數 |
|---|---|---|---|
| 頁分配/釋放 | 512 次系統調用 | 1 次 | 512x |
| 缺頁中斷 | 512 次 | 1 次 | 512x |
| 內存清零 | 512 次 | 1 次 | 512x |
1.3 透明大頁控制接口詳解
核心控制文件
/sys/kernel/mm/transparent_hugepage/enabled
- 可選值:
always:強制所有內存使用大頁madvise:僅對標記區域使用(推薦)never:完全禁用
相關調優參數
| 文件路徑 | 功能 | 推薦值 |
|---|---|---|
/defrag | 碎片整理策略 | defer (延遲整理) |
/khugepaged/defrag | 后臺整理 | 1 (啟用) |
/hpage_pmd_size | 大頁尺寸 | 2097152 (2MB) |
1.4 使用場景與最佳實踐
推薦啟用場景
- 內存密集型應用:MySQL, MongoDB, Redis
- 科學計算:MATLAB, TensorFlow
- 虛擬化平臺:KVM, Docker
- 大數據處理:Spark, Hadoop
配置示例
# 啟用透明大頁(madvise模式)
echo madvise > /sys/kernel/mm/transparent_hugepage/enabled# 優化后臺合并進程
echo 1 > /sys/kernel/mm/transparent_hugepage/khugepaged/defrag
echo 10 > /sys/kernel/mm/transparent_hugepage/khugepaged/pages_to_scan# 應用程序主動請求大頁
#include <sys/mman.h>
posix_memalign(&ptr, 2*1024*1024, size);
madvise(ptr, size, MADV_HUGEPAGE);
禁用場景
- 實時系統:避免合并導致的延遲波動
- 內存碎片嚴重:物理內存不足時
- 特定數據庫:如 Oracle 推薦禁用
1.5 問題排查與監控
# 查看大頁使用情況
grep AnonHugePages /proc/meminfo# 監控khugepaged活動
grep -E 'thp|khugepaged' /proc/vmstat# ubuntu可視化工具
sudo apt install hugeadm
hugeadm --pool-list
問題: 內存碎片導致大頁分配失敗
解決方案:
# 手動觸發碎片整理
echo 1 > /proc/sys/vm/compact_memory# 調整碎片閾值
sysctl vm.extfrag_threshold=500
問題: khugepaged 占用高 CPU
解決方案:
# 減少掃描頻率
echo 100 > /sys/kernel/mm/transparent_hugepage/khugepaged/scan_sleep_millisecs
1.6 與傳統大頁的對比
| 特性 | 透明大頁 (THP) | 傳統大頁 (HugeTLB) |
|---|---|---|
| 配置方式 | 自動/動態 | 靜態預分配 |
| 管理復雜度 | 低 (內核自動管理) | 高 (手動配置) |
| 內存利用率 | 高 (按需分配) | 低 (固定預留) |
| 適用場景 | 通用工作負載 | 特定應用 |
| 調整靈活性 | 運行時動態調整 | 需重啟生效 |
最佳實踐:現代系統優先使用 THP,僅在特殊需求(如 DPDK)時使用傳統大頁。
??透明大頁技術通過智能化地平衡內存效率與系統開銷,已成為現代 Linux 系統性能優化的關鍵組件。合理配置后,可使內存密集型應用獲得高達 50% 的性能提升,同時保持系統的靈活性和穩定性。
二、Linux伙伴系統水位機制詳解
??伙伴系統中的水位(Watermarks) 是Linux內核內存管理的關鍵機制,用于動態監控內存壓力并觸發內存回收操作。它定義了系統內存使用的臨界閾值,確保內存分配不會耗盡系統資源。
2.1 三種核心水位詳解
最高水位 (high_wmark)
- 位置:內存區域的頂部
- 含義:系統內存充足狀態
- 觸發行為:
- 允許快速內存分配
- kswapd休眠狀態
- 計算公式:
high_wmark = min_free_kbytes * 5 / 4
低水位 (low_wmark)
- 位置:high和min之間
- 含義:中等內存壓力
- 觸發行為:
- 喚醒kswapd守護進程
- 開始后臺頁面回收
- 視覺表現:
內存使用 [||||||||||__________] low_wmark
最低水位 (min_wmark)
- 位置:內存區域的底部
- 含義:嚴重內存壓力
- 觸發行為:
- 直接同步回收(阻塞分配進程)
- 可能觸發OOM Killer
- 計算公式:
min_free_kbytes = sqrt(總內存*16) // 內核自動計算 也可以人為設定數值
2.2 水位在伙伴系統中的實現
數據結構
struct zone {unsigned long watermark[NR_WMARK]; // 三水位值// [0] = min_wmark// [1] = low_wmark// [2] = high_wmarkstruct per_cpu_pageset pageset[NR_CPUS];struct free_area free_area[MAX_ORDER]; // 伙伴系統核心
}
內存分配檢查流程
static struct page *get_page_from_freelist(...) {for_each_zone(zone) {// 檢查當前區域是否低于水位if (!zone_watermark_ok(zone, order, mark, ...))continue;// 嘗試分配頁面page = buffered_rmqueue(zone, order, gfp_mask);if (page)return page;}return NULL;
}
2.3 水位觸發機制的實際行為
正常狀態(高于high_wmark)
中等壓力(低于low_wmark)
嚴重壓力(低于min_wmark)
2.4 水位關鍵操作接口
查看當前水位
# 查看所有內存區域水位
cat /proc/zoneinfo | grep -E 'Node|min|low|high'# 示例輸出
Node 0, zone Normalpages free 32415min 14895low 18618high 22341
調整水位參數
# 臨時調整
echo 65536 > /proc/sys/vm/min_free_kbytes
監控水位變化
watch -n 1 "grep -E 'min|low|high' /proc/zoneinfo"
2.5 水位優化策略
嵌入式設備優化
# 減少保留內存(內存緊張設備)
echo 8192 > /proc/sys/vm/min_free_kbytes# 更積極回收
echo 150 > /proc/sys/vm/vfs_cache_pressure
解決常見問題:頻繁觸發直接回收導致卡頓
# 查看事件計數
grep "pgsteal" /proc/vmstat# 優化方案:
1. 增加 min_free_kbytes
2. 優化應用程序內存使用
3. 添加物理內存
2.6 水位與其他機制的關系
??水位機制是Linux內存管理的"預警系統",它:
- 預防內存耗盡:提前觸發回收避免OOM
- 平衡性能:后臺回收減少阻塞
- 動態適應:根據系統負載自動調整壓力響應
??理解水位機制對優化系統性能、診斷內存壓力問題至關重要,特別是在高負載服務器和資源受限的嵌入式系統中。
2.7 kswapd:內存回收守護進程
核心功能
-
內存水位維護:當系統空閑內存低于低水位線(
low watermark)時,kswapd被喚醒,異步回收內存,確保空閑內存恢復到高水位線(high watermark)以上。 -
回收對象:主要回收兩類內存:
- 文件頁(Page Cache):緩存的文件數據,可直接丟棄(除非臟頁需寫回磁盤)。
- 匿名頁(Anonymous Pages):進程堆棧等數據,需交換(swap)到磁盤。
-
觸發條件:
- 常規周期喚醒(默認100毫秒)。
- 進程分配內存失敗時(如
alloc_pages()慢路徑觸發wakeup_kswapd())。
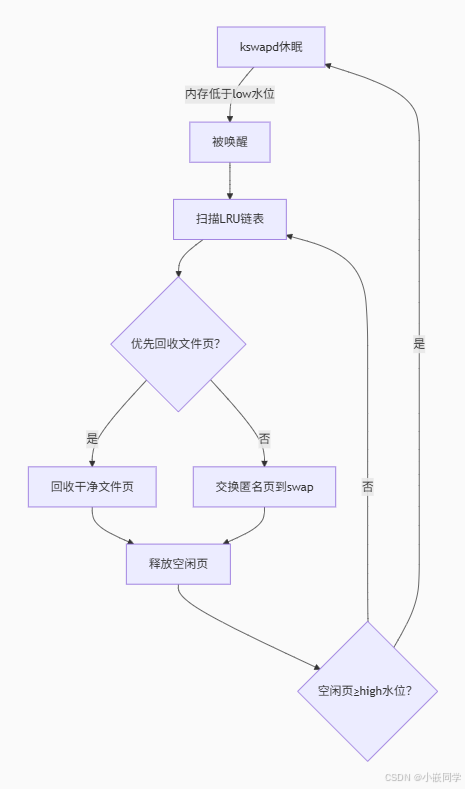
-
異步操作:不阻塞進程,后臺運行。
-
優先級策略:按頁面活躍度(Active/Inactive LRU)選擇回收對象。
-
NUMA優化:每個NUMA節點獨立運行一個
kswapd線程(如kswapd0、kswapd1)。
三、/proc/sys/vm/extfrag_threshold
3.1 基本概念
??extfrag_threshold 是Linux 內核中一個與內存碎片管理相關的參數,是一個范圍在 0 到 1000 的整數,它主要用于衡量系統對外部內存碎片的容忍程度。外部內存碎片指的是由于頻繁的內存分配和釋放操作,導致物理內存中出現大量不連續的空閑內存塊,使得即使系統中總的空閑內存量充足,但無法分配出連續的大塊內存的現象。
3.2 作用
??這個參數在內核進行內存分配決策時發揮著重要作用。內核在分配內存時,會根據當前系統的內存碎片情況和 extfrag_threshold 的值來選擇合適的分配策略:
- 低閾值(接近 0):表示系統對內存碎片的容忍度較低。當內存碎片程度達到較低水平時,內核就會采取積極的措施來減少碎片,例如進行內存緊湊(memory compaction)操作,將分散的空閑內存塊移動到一起,形成連續的大塊空閑內存,以滿足后續的大內存分配請求。不過,內存緊湊操作會消耗一定的系統資源和時間,可能會對系統性能產生一定影響。
- 高閾值(接近 1000):意味著系統對內存碎片有較高的容忍度。只有當內存碎片程度非常嚴重時,內核才會嘗試進行內存緊湊或其他減少碎片的操作。在這種情況下,系統在一定程度上可以避免頻繁進行內存緊湊帶來的性能開銷,但可能會面臨無法分配大塊連續內存的風險。
3.3 配置方法
??可以通過 /proc/sys/vm/extfrag_threshold 文件來查看和修改 extfrag_threshold 的值。
- 查看當前值:使用以下命令可以查看當前系統中
extfrag_threshold的設置:
cat /proc/sys/vm/extfrag_threshold
- 修改值:可以使用
echo命令將新的值寫入該文件來修改參數設置。例如,將extfrag_threshold設置為 500:
echo 500 > /proc/sys/vm/extfrag_threshold
??合理設置 extfrag_threshold 參數對于平衡系統對內存碎片的處理和系統性能非常重要。在實際應用中,需要根據系統的具體負載和內存使用情況進行調整。
3.4 kcompactd:內存碎片規整守護進程
核心功能
- 碎片合并:將零散小內存塊合并為高階連續塊(如將
order=0的4KB頁合并為order=2的16KB頁),滿足大塊內存請求(如DMA、透明大頁)。 - 遷移策略:掃描內存區域,將可移動頁(
MIGRATE_MOVABLE)從低地址向高地址遷移,形成連續空閑空間。
觸發條件
- 被動觸發:高階內存分配失敗時(如
alloc_pages(order>0)失敗)。 - 主動觸發:內核≥5.0支持主動規整(Proactive Compaction),預測碎片風險提前規整。
工作流程
// 簡化版規整邏輯(mm/compaction.c)
compact_zone() {isolate_migratepages(); // 隔離可移動頁migrate_pages(); // 遷移至空閑區域release_freepages(); // 釋放新連續塊
}
3.5 與伙伴系統水位有什么區別
- 功能用途不同
extfrag_threshold關注的是內存碎片的程度,目的是在內存碎片達到一定水平時維護內存的連續性,以確保能夠分配出連續的大塊內存。- 伙伴系統的水位關注的是內存的使用量,目的是在內存分配時發現內存資源緊張回收內存,保證系統有足夠的可用內存。
- 數值范圍和含義不同
extfrag_threshold是一個 0 到 1000 的整數,數值越大表示系統對內存碎片的容忍度越高。- 伙伴系統的水位是以物理頁框的數量來表示的,不同的內存區域(如 DMA 區、普通區等)可能有不同的水位值,這些值反映了該區域內存的使用狀態。
- 兩者的聯系
??雖然extfrag_threshold和伙伴系統的水位是不同的概念,但它們都會影響內核的內存管理決策。例如,當系統內存接近或低于伙伴系統的低水位,同時內存碎片程度達到extfrag_threshold設定的閾值時,內核可能會更積極地進行內存緊湊和回收操作,以滿足內存分配需求并減少碎片。
四、Linux 內存規整機制
4.1 內存規整關鍵特性演進
| 特性 | 內核版本支持 | 嵌入式系統配置方式 | 功能描述 |
|---|---|---|---|
| 異步/后臺規整 | <4.6:不支持 ≥4.6:支持 | echo 1 > /sys/kernel/mm/transparent_hugepage/khugepaged/defrag | kcompactd 后臺線程自動規整 |
| 主動規整(Proactive) | <5.2:不支持 ≥5.2:默認開啟 | echo 1 > /sys/kernel/mm/transparent_hugepage/defrag | 預測性內存規整避免碎片 |
| 手動觸發 | < 3.10:不支持 ≥3.10:支持 | echo 1 > /proc/sys/vm/compact_memory | 立即觸發全系統內存規整 |
| 碎片閾值 | <4.12:不支持 ≥4.12:支持 | echo 500 > /proc/sys/vm/extfrag_threshold | 碎片敏感度調節(0-1000) |
| 規整力度 | <5.15:不支持 ≥5.15:支持 | echo 20 > /proc/sys/vm/compaction_proactiveness | 規整激進程度(0-100) |
# 減少 kcompactd CPU 占用 (嵌入式設備關鍵)
echo 1000 > /sys/kernel/mm/transparent_hugepage/khugepaged/scan_sleep_millisecs# 限制每次掃描頁數
echo 256 > /sys/kernel/mm/transparent_hugepage/khugepaged/pages_to_scan
4.2 新舊內核性能對比分析
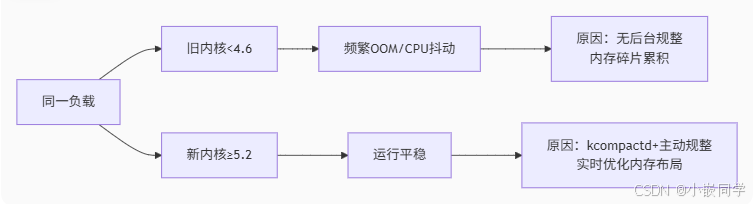
根本原因解析
-
kcompactd 作用(≥4.6):
- 持續后臺內存碎片整理
- 預防性合并可移動頁
- 保障高階連續內存可用
-
主動規整優勢(≥5.2)
4.3 kswapd與kcompactd的協同機制
協作場景
- 內存分配失敗時:
- 先喚醒
kswapd回收內存 → 若仍失敗,觸發kcompactd規整碎片。
- 先喚醒
- 后臺維護:
kswapd回收后若碎片指數高(/proc/buddyinfo顯示高階塊稀缺),喚醒kcompactd。
性能影響對比
| 指標 | kswapd | kcompactd |
|---|---|---|
| CPU開銷 | 中(掃描LRU/寫swap) | 高(頁面遷移消耗大量CPU) |
| 延遲 | 低(異步) | 可能阻塞進程(同步遷移) |
| 主要目標 | 釋放空閑頁 | 提升連續內存可用性 |
總結
kswapd:內存“回收者”,專注維護水位,異步釋放內存。kcompactd:碎片“修復師”,合并零散頁,保障大塊內存分配。- 協作價值:
??二者形成“釋放+規整”閉環,從空間(回收碎片)和時間(異步操作)維度優化內存管理。尤其在≥5.2內核中,主動規整機制顯著提升長期運行穩定性,避免舊版本因碎片累積導致的OOM問題。
4.4 診斷命令與參數調整
監控命令
- 碎片指數:
cat /proc/buddyinfo # 各階空閑塊分布(階數越高越連續) cat /proc/vmstat | grep compact # 規整次數統計 - 回收壓力:
cat /proc/zoneinfo | grep -E 'Node|min|low|high' # 水位線 cat /proc/vmstat | grep kswapd # 回收頁面計數
調優參數
| 目標 | 操作 | 文件路徑 |
|---|---|---|
| 降低kswapd頻率 | 延長掃描間隔 | /sys/kernel/mm/transparent_hugepage/khugepaged/scan_sleep_millisecs |
| 減少規整開銷 | 限制每次掃描頁數 | /sys/kernel/mm/transparent_hugepage/khugepaged/pages_to_scan |
| 調整碎片敏感度 | 增大閾值(>500減少規整) | echo 800 > /proc/sys/vm/extfrag_threshold |
| 關閉透明大頁 | 避免頻繁高階分配 | 內核啟動參數加transparent_hugepage=never |
嵌入式場景特別注意事項
- 資源受限:
- 減少
kcompactd掃描頁數(pages_to_scan),避免CPU過載。
- 減少
- 無swap設備:
kswapd僅回收文件頁,匿名頁回收失效,需依賴OOM Killer或LMKD。
- 實時性要求:
- 禁用主動規整(
compaction_proactiveness=0),減少非確定性延遲。
- 禁用主動規整(
五、/proc/sys/vm/min_free_kbytes
5.1 這個保留的內存能不能被使用?
??在系統內存充足時:可以! 當系統的空閑內存 (free) 遠大于 min_free_kbytes 時,這部分“保留”的內存區域完全可以被用戶進程申請和使用。它并不是被永久鎖定或隔離的區域。
??在系統內存緊張時:不行! 當系統的空閑內存接近或低于 min_free_kbytes 設定的閾值時,內核會強烈阻止用戶進程再消耗掉這最后一點“保留”內存。內核會采取激進措施(直接回收、OOM Killer)來釋放內存,確保空閑內存恢復到 min_free_kbytes 之上。
5.2 保留的意義是什么?
保留這部分內存的核心目的是保障系統在最極端內存壓力下的基本功能性和穩定性,避免系統完全崩潰。具體來說:
- 防止死鎖和系統僵死: 這是最主要的原因。當所有物理內存都被耗盡時,內核自身執行關鍵操作(如調度進程、處理中斷、執行 I/O、回收內存)都可能需要分配少量內存。如果連這點內存都沒有,系統會陷入死鎖狀態:需要內存來釋放內存,但已無內存可用,整個系統完全無響應(僵死)。
min_free_kbytes確保在最壞情況下,內核仍有“救命錢”來執行這些關鍵操作 - 支持內核關鍵操作:
- 處理硬件中斷: 中斷處理程序可能需要分配內存緩沖區。
- 網絡和存儲 I/O: 網絡數據包和磁盤塊讀寫在進入用戶空間前需要內核緩沖區。
- 進程創建/銷毀: 創建新進程(
fork/exec)需要分配內核數據結構。 - 頁面回收:
kswapd或直接回收在執行時需要內存來管理回收過程本身(例如,存放需要寫回的臟頁鏈表)。
- 維持
kswapd有效工作:kswapd是內核的后臺內存回收守護進程。當空閑內存低于low水位線(與min_free_kbytes相關)時,kswapd會被喚醒并開始后臺異步回收內存。如果允許空閑內存降到極低甚至為零,kswapd可能來不及回收,迫使進程在申請內存時進行代價高昂的直接回收,導致嚴重的延遲(卡頓)。保留內存給kswapd一定的緩沖空間和時間來工作。 - 避免過早觸發 OOM Killer: OOM Killer 是內核在內存完全耗盡、回收失敗后的最后手段,它會強制殺死進程來釋放內存。這個過程非常粗暴,可能導致重要服務中斷。保留內存為內存回收提供了緩沖,降低了過早觸發 OOM Killer 的概率。
5.3 詳細解釋和工作機制
-
水位線: 內核基于
min_free_kbytes計算出三個關鍵的內存水位線:min: 直接對應于min_free_kbytes。這是最后的防線,空閑內存絕對不能低于此值。low: 高于min。當空閑內存低于low時,內核喚醒kswapd開始后臺異步回收內存。high: 高于low。當空閑內存回升到high時,kswapd停止回收。
-
內存分配行為:
- 當用戶進程通過
malloc等申請內存時,最終會觸發內核的頁面分配器(如buddy allocator)分配物理頁框。 - 分配器會檢查當前空閑內存是否充足。
- 如果空閑內存 >
low:分配成功,進程繼續運行。 - 如果空閑內存 <
low但 >min:分配器可能會讓進程進入等待狀態,同時喚醒或加速kswapd進行回收。回收出足夠內存后,進程被喚醒并獲得內存。 - 如果空閑內存 <=
min:分配器會進入直接回收模式。這發生在申請內存的進程上下文中,是同步阻塞的。該進程會被阻塞,內核在其上下文中立即嘗試回收內存(可能非常慢)。如果直接回收失敗且內存仍低于min,內核最終會調用 OOM Killer 選擇并殺死一個或多個進程來釋放內存。在這個階段,分配器會拒絕分配任何可能使空閑內存進一步低于min的請求,嚴格保護這塊保留內存。
- 如果空閑內存 >
- 當用戶進程通過
5.4 假如設置 echo 16384 > /proc/sys/vm/min_free_kbytes
- 這確實將最低保留內存設置為 16MB (16384 KB)。
- 將默認值(通常為幾MB)翻倍意味著:
- 好處: 系統在內存壓力下有更大的緩沖空間,
kswapd有更多時間工作,直接回收和 OOM Killer 被觸發的可能性降低,系統在高壓下可能更穩定。 - 潛在代價: 稍微增加了“浪費”內存的可能性。在內存非常緊張的系統中,16MB 可能意味著一個額外的進程無法運行(因為內核要保護這 16MB)。更關鍵的是,如果設置過高(比如在總內存很小的系統上設得太大),可能導致
kswapd過度活躍,即使系統負載不高也頻繁回收內存,反而增加 CPU 開銷和降低性能(回收本身有成本)。它也可能過早觸發直接回收,因為low水位線也相應提高了。
- 好處: 系統在內存壓力下有更大的緩沖空間,
??min_free_kbytes 設置的內存是動態保留的底線。在內存充足時,它可被自由使用;在內存緊張時,它是內核維持自身運轉和避免災難性崩潰的最后保障。你將其設置為 16MB 增加了安全緩沖,但需注意過高設置可能帶來性能開銷。最佳值取決于你的系統總內存大小和工作負載特性。監控 /proc/vmstat (關注 pgscan_kswapd, pgscan_direct, oom_kill 等) 和 /proc/meminfo 可以幫助評估當前設置是否合理。
六、直接同步回收(Direct Reclaim)深度解析
??當系統內存低于最低水位(min_wmark)時觸發的直接同步回收是Linux內核最緊急的內存回收機制,其執行過程與kswapd/kcompactd有本質區別。
6.1 直接同步回收 vs kswapd/kcompactd
| 特性 | 直接同步回收 | kswapd | kcompactd |
|---|---|---|---|
| 觸發條件 | 內存≤min_wmark | 內存≤low_wmark | 碎片指數超標 |
| 執行者 | 請求內存的進程自身 | 內核后臺線程 | 內核后臺線程 |
| 執行模式 | 同步阻塞 | 異步 | 異步 |
| 優先級 | 最高(可搶占其他進程) | 普通 | 普通 |
| 延遲影響 | 直接導致進程卡頓 | 無感知 | 可能輕微影響 |
6.2 直接同步回收的完整執行流程
具體步驟解析:
-
進程阻塞
- 當
alloc_pages()檢測到zone_watermark_ok() == false - 當前進程進入
TASK_UNINTERRUPTIBLE狀態
- 當
-
頁面緩存回收
// 內核源碼 mm/vmscan.c unsigned long shrink_page_list(...) {while (!list_empty(page_list)) {if (PageDirty(page)) {// 同步寫回磁盤pageout(page, mapping); } else {// 直接回收干凈頁__remove_mapping(...);}} } -
匿名頁交換
- 對非活動匿名頁執行:
swap_writepage(page, &wbc); // 同步寫swap - 若配置了zswap,優先壓縮到內存
- 對非活動匿名頁執行:
-
SLAB緩存收縮
shrink_slab(GFP_KERNEL, ...); // 回收dentries/inodes -
解除阻塞
- 當釋放足夠頁面后,喚醒進程繼續分配內存
- 若回收失敗,觸發OOM Killer
6.3 性能影響與優化
性能瓶頸分析
優化策略(嵌入式場景)
-
預防性調優
# 增加保留內存緩沖 echo 16384 > /proc/sys/vm/min_free_kbytes # 默認值的2倍# 降低交換傾向 echo 10 > /proc/sys/vm/swappiness -
減少回收壓力
// 代碼層面:避免突發內存分配 for (i=0; i<1000; i++) {// 錯誤:每次分配4KBbuffer = malloc(4096); // 正確:批量分配40KBif (i % 10 == 0) big_buf = malloc(40960); } -
監控診斷工具
# 追蹤直接回收事件 echo 'vfs:shrink_*' > /sys/kernel/debug/tracing/set_event cat /sys/kernel/debug/tracing/trace_pipe# 輸出示例 kworker/0:1-125 [000] .... 316.256367: mm_vmscan_direct_reclaim_begin: order=0 kworker/0:1-125 [000] .... 316.259412: mm_vmscan_direct_reclaim_end: nr_reclaimed=32
6.4 總結
雖然直接回收由進程自身執行,但會與kswapd互動:
直接同步回收是Linux內存管理的"緊急制動"機制:
- 同步執行:由請求進程直接執行,導致阻塞
- 代價高昂:涉及磁盤I/O和密集計算
- 觸發條件:內存≤min_wmark的危急狀態
- 優化核心:
- 增加
min_free_kbytes緩沖 - 避免內存分配尖峰
- 監控
direct reclaim事件
- 增加
在嵌入式系統中,通過合理配置保留內存和優化應用行為,可顯著降低直接回收發生概率,保障系統實時性。
 vs 關鍵幀動畫 (Animation))




與自動化優化流程實戰)


)

搭建智能體并接入discord機器人)
)

)

))

多協議標記交換 MPLS)

