
一、數據加載器
數據集和加載器
1.1構建數據類
1.1.1 Dataset類
Dataset是一個抽象類,是所有自定義數據集應該繼承的基類。它定義了數據集必須實現的方法。
必須實現的方法
-
__len__: 返回數據集的大小 -
__getitem__: 支持整數索引,返回對應的樣本
構建自定義數據加載類通常需要繼承 torch.utils.data.Dataset
-
__init__ 方法 用于初始化數據集對象:通常在這里加載數據,或者定義如何從存儲中獲取數據的路徑和方法。
def __init__(self, data, labels):self.data = dataself.labels = labels
-
__len__ 方法 返回樣本數量:需要實現,以便 Dataloader加載器能夠知道數據集的大小。
def __len__(self):return len(self.data)
-
__getitem__ 方法 根據索引返回樣本:將從數據集中提取一個樣本,并可能對樣本進行預處理或變換。
def __getitem__(self, index):sample = self.data[index]label = self.labels[index]return sample, label
代碼參考
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader# 定義數據加載類
# 把“數據 + 標簽”包成一個 Dataset
class CustomDataset(Dataset):def __init__(self, data, labels):self.data = dataself.labels = labelsdef __len__(self):return len(self.data)def __getitem__(self, index):index = min(max(index, 0), len(self.data) - 1)sample = self.data[index]label = self.labels[index]return sample, labeldef test001():# 簡單的數據集準備data_x = torch.randn(666, 20, requires_grad=True, dtype=torch.float32)data_y = torch.randn(data_x.shape[0], 1, dtype=torch.float32)dataset = CustomDataset(data_x, data_y)# 隨便打印個數據看一下print(dataset[0])if __name__ == "__main__":test001()
'''這段代碼沒有訓練、沒有模型、沒有 DataLoader,只是演示:
“怎樣把隨機張量包裝成自定義 Dataset,并取出第一條看看長啥樣”。'''
1.1.2 TensorDataset類
使Dataset的簡單實現,封裝了張量數據,適用數據已經是張量的情況
特點:
-
簡單快捷:當數據已經是張量形式時,無需自定義Dataset類
-
多張量支持:可以接受多個張量作為輸入,按順序返回
-
索引一致:所有張量的第一個維度必須相同,表示樣本數量
class TensorDataset(Dataset):def __init__(self, *tensors):# size(0)在python中同shape[0],獲取的是樣本數量# 用第一個張量中的樣本數量和其他張量對比,如果全部相同則通過斷言,否則拋異常assert all(tensors[0].size(0) == tensor.size(0) for tensor in tensors)self.tensors = tensorsdef __getitem__(self, index):return tuple(tensor[index] for tensor in self.tensors)def __len__(self):return self.tensors[0].size(0)
def test03():torch.manual_seed(0)# 創建特征張量和標簽張量features = torch.randn(100, 5) # 100個樣本,每個樣本5個特征labels = torch.randint(0, 2, (100,)) # 100個二進制標簽# print(labels)# 創建TensorDatasetdataset = TensorDataset(features, labels)# 使用方式與自定義Dataset相同print(len(dataset)) # 輸出: 100print(dataset[0]) # 輸出: (tensor([...]), tensor(0))
test03()1.2 數據加載器
DataLoader是一個迭代器 用于從Dataset中批量加載數據
????????批量加載:將多個樣本組合成一個批次。
????????打亂數據:在每個 epoch 中隨機打亂數據順序。
????????多線程加載:使用多線程加速數據加載。
# 創建 DataLoader
dataloader = DataLoader(
? ? dataset, ? ? ? ? ?# 數據集
? ? batch_size=10, ? ?# 批量大小
? ? shuffle=True, ? ? # 是否打亂數據
? ? num_workers=2 ? ? # 使用 2 個子進程加載數據
)
# 遍歷 DataLoader
# enumerate返回一個枚舉對象(iterator),生成由索引和值組成的元組
for batch_idx, (samples, labels) in enumerate(dataloader):
? ? print(f"Batch {batch_idx}:")
? ? print("Samples:", samples)
? ? print("Labels:", labels)
示例:
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader# 定義數據加載類
class CustomDataset(Dataset):def __init__(self, data, labels):self.data = dataself.labels = labelsdef __len__(self):return len(self.data)def __getitem__(self, index):index = min(max(index, 0), len(self.data) - 1)sample = self.data[index]label = self.labels[index]return sample, labeldef test01():# 簡單的數據集準備# 666 條樣本,每條 20 維特征data_x = torch.randn(666, 20, requires_grad=True, dtype=torch.float32)data_y = torch.randn(data_x.size(0), 1, dtype=torch.float32)dataset = CustomDataset(data_x, data_y)# 構建數據加載器data_loader = DataLoader(dataset, batch_size=7, shuffle=True)for i,(batch_x, batch_y) in enumerate(data_loader):print(batch_x, batch_y)breaktest01()2 數據集加載案例
2.1 加載csv數據集
import torch
from torch.utils.data import Dataset, DataLoader
import pandas as pdclass MyCsvDataset(Dataset):def __init__(self, filename):df = pd.read_csv(filename)# 刪除文字列df = df.drop(["學號", "姓名"], axis=1)# 轉換為tensordata = torch.tensor(df.values)# 最后一列以前的為data,最后一列為labelself.data = data[:, :-1]self.label = data[:, -1]self.len = len(self.data)def __len__(self):return self.lendef __getitem__(self, index):idx = min(max(index, 0), self.len - 1) # 1. 防止越界return self.data[idx], self.label[idx] # 2. 返回該索引對應的特征和標簽def test001():excel_path = r"./大數據答辯成績表.csv"dataset = MyCsvDataset(excel_path)dataloader = DataLoader(dataset, batch_size=4, shuffle=True)for i, (data, label) in enumerate(dataloader):print(i, data, label)if __name__ == "__main__":test001()或者
class TensorDataset(Dataset):def __init__(self,*tensors):assert all(t.shape[0]==tensors[0].shape[0] for t in tensors)self.tensors = tensorsdef __getitem__(self, index):return tuple(t[index] for t in self.tensors)def __len__(self):return self.tensors[0].shape[0]def build_dataset(filepath):df = pd.read_csv(filepath)df.drop(columns=['學號', '姓名'], inplace=True)data = df.iloc[..., :-1]labels = df.iloc[..., -1]x = torch.tensor(data.values, dtype=torch.float)y = torch.tensor(labels.values)dataset = TensorDataset(x, y)return datasetdef test001():filepath = r"./大數據答辯成績表.csv"dataset = build_dataset(filepath)dataloader = DataLoader(dataset, batch_size=4, shuffle=True)for i, (data, label) in enumerate(dataloader):print(i, data, label)
test001()2.2 加載圖片數據集
用ImageFloder
ImageFolder 會根據文件夾的結構來加載圖像數據。它假設每個子文件夾對應一個類別,文件夾名稱即為類別名稱

root 是根目錄。
class1、class2 等是類別名稱。
每個類別文件夾中的圖像文件會被加載為一個樣本。
ImageFolder構造函數如下:
torchvision.datasets.ImageFolder(root, transform=None, target_transform=None, is_valid_file=None)
參數解釋
root:字符串,指定圖像數據集的根目錄。
transform:可選參數,用于對圖像進行預處理。通常是一個torchvision.transforms的組合。
target_transform:可選參數,用于對目標(標簽)進行轉換。
is_valid_file:可選參數,用于過濾無效文件。如果提供,只有返回True的文件才會被加載。
2.3 加載官方數據集
在 PyTorch 中官方提供了一些經典的數據集,如 CIFAR-10、MNIST、ImageNet 等,可以直接使用這些數據集進行訓練和測試。
數據集:Datasets — Torchvision 0.22 documentation
常見數據集:
MNIST: 手寫數字數據集,包含 60,000 張訓練圖像和 10,000 張測試圖像。
CIFAR10: 包含 10 個類別的 60,000 張 32x32 彩色圖像,每個類別 6,000 張圖像。
CIFAR100: 包含 100 個類別的 60,000 張 32x32 彩色圖像,每個類別 600 張圖像。
COCO: 通用對象識別數據集,包含超過 330,000 張圖像,涵蓋 80 個對象類別。
torchvision.transforms 和 torchvision.datasets 是 PyTorch 中處理計算機視覺任務的兩個核心模塊,它們為圖像數據的預處理和標準數據集的加載提供了強大支持。
transforms 模塊提供了一系列用于圖像預處理的工具,可以將多個變換組合成處理流水線。
datasets 模塊提供了多種常用計算機視覺數據集的接口,可以方便地下載和加載。
四、激活函數
在隱藏層引入非線性,使得神經網絡能夠學習和表示復雜的函數關系,使網絡具備非線性能力 。
4.1基礎概念
4.1.1 線性理解
如果在隱藏層不使用激活函數,那么整個神經網絡會表現為一個線性模型。我們可以通過數學推導來展示這一點。
假設:
-
神經網絡有L 層,每層的輸出為 \mathbf{a}^{(l)}。
-
每層的權重矩陣為 \mathbf{W}^{(l)} ,偏置向量為\mathbf{b}^{(l)}。
-
輸入數據為\mathbf{x},輸出為\mathbf{a}^{(L)}。
一層網絡的情況
對于單層網絡(輸入層到輸出層),如果沒有激活函數,輸出\mathbf{a}^{(1)} 可以表示為: \mathbf{a}^{(1)} = \mathbf{W}^{(1)} \mathbf{x} + \mathbf{b}^{(1)}
兩層網絡的情況
假設我們有兩層網絡,且每層都沒有激活函數,則:
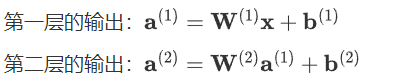

多層網絡的情況
如果有L層,每層都沒有激活函數,則第l層的輸出為:![]()
通過遞歸代入,可以得到:
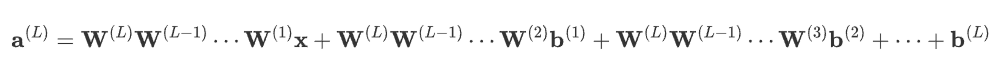
表達式可簡化為:
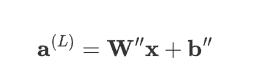
其中,\mathbf{W}'' 是所有權重矩陣的乘積,\mathbf{b}''是所有偏置項的線性組合。
如此可以看得出來,無論網絡多少層,意味著:
整個網絡就是線性模型,無法捕捉數據中的非線性關系。
激活函數是引入非線性特性、使神經網絡能夠處理復雜問題的關鍵。
1.2 非線性可視化
2 常見激活函數
2.1 sigmoid
是非常常見的非現金激活函數,特別是早期神經網絡應用中,它將輸入映射到0到1之前,非常適合處理概率問題
2.2.1 公式
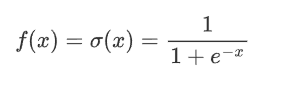
其中,e 是自然常數(約等于2.718),x 是輸入。
2.1.2 特征
1 將任意輸入的數映射到0到1之間 非常適合處理概率場景
2 sigmoid一般只用于二分類的輸出層
3 導數計算比較方便 可以自身表達式表示
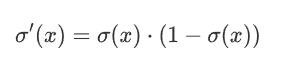
2.1.3 缺點
?梯度消失
在輸入非常大或非常小時,Sigmoid函數的梯度會變得非常小,接近于0。這導致在反向傳播過程中,梯度逐漸衰減。
最終使得早期層的權重更新非常緩慢,進而導致訓練速度變慢甚至停滯。
信息丟失
輸入100和輸入10000經過sigmoid的激活值幾乎都是等于 1 的,但是輸入的數據卻相差 100 倍。
計算成本高
由于涉及指數運算,Sigmoid的計算比ReLU等函數更復雜,盡管差異并不顯著
2.1.4 函數繪制
import torch
import matplotlib.pyplot as plt# plt支持中文
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = Falsedef test001():# 一行兩列繪制圖像_, ax = plt.subplots(1, 2)# 繪制函數圖像x = torch.linspace(-10, 10, 100)y = torch.sigmoid(x)# 網格ax[0].grid(True)ax[0].set_title("sigmoid 函數曲線圖")ax[0].set_xlabel("x")ax[0].set_ylabel("y")# 在第一行第一列繪制sigmoid函數曲線圖ax[0].plot(x, y)# 繪制sigmoid導數曲線圖x = torch.linspace(-10, 10, 100, requires_grad=True)# 自動求導# torch.sigmoid(x).sum().backward()ax[1].grid(True)ax[1].set_title("sigmoid 函數導數曲線圖", color="red")ax[1].set_xlabel("x")ax[1].set_ylabel("y")# 用自動求導的結果繪制曲線圖ax[1].plot(x.detach().numpy(), x.grad.detach().numpy())# 設置曲線顏色ax[1].lines[0].set_color("red")plt.show()if __name__ == "__main__":test001()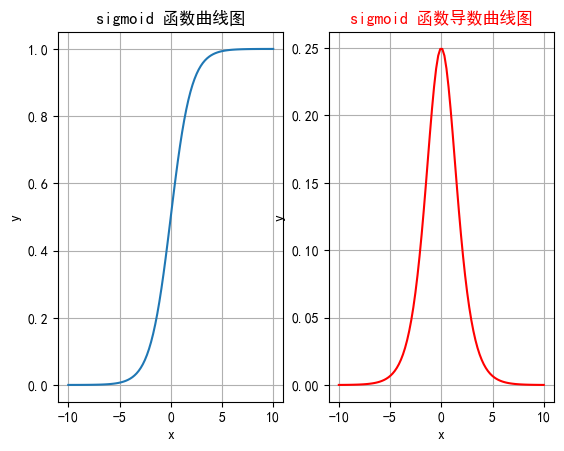
2.2 tanh
雙曲正切是一種常見的非線性激活函數,tanh 函數也是一種S形曲線,輸出范圍為(?1,1)。
2.2.1 公式
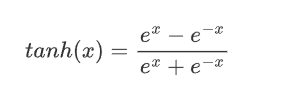
2.2.2 特征
-
輸出范圍: 將輸入映射到(-1, 1)之間,因此輸出是零中心的。相比于Sigmoid函數,這種零中心化的輸出有助于加速收斂。
-
對稱性: Tanh函數是關于原點對稱的奇函數,因此在輸入為0時,輸出也為0。這種對稱性有助于在訓練神經網絡時使數據更平衡。
-
平滑性: Tanh函數在整個輸入范圍內都是連續且可微的,這使其非常適合于使用梯度下降法進行優化。
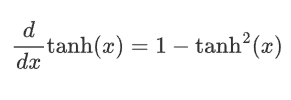
2.2.3 缺點
-
梯度消失: 雖然一定程度上改善了梯度消失問題,但在輸入值非常大或非常小時導數還是非常小,這在深層網絡中仍然是個問題。這是因為每一層的梯度都會乘以一個小于1的值,經過多層乘積后,梯度會變得非常小,導致訓練過程變得非常緩慢,甚至無法收斂。
-
計算成本: 由于涉及指數運算,Tanh的計算成本還是略高,盡管差異不大。
2.2.4 函數繪制
import torch
import matplotlib.pyplot as plt# plt支持中文
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = Falsedef test001():# 一行兩列繪制圖像_, ax = plt.subplots(1, 2)# 繪制函數圖像x = torch.linspace(-10, 10, 100)y = torch.tanh(x)# 網格ax[0].grid(True)ax[0].set_title("tanh 函數曲線圖")ax[0].set_xlabel("x")ax[0].set_ylabel("y")# 在第一行第一列繪制tanh函數曲線圖ax[0].plot(x, y)# 繪制tanh導數曲線圖x = torch.linspace(-10, 10, 100, requires_grad=True)# 自動求導:需要標量才能反向傳播torch.tanh(x).sum().backward()ax[1].grid(True)ax[1].set_title("tanh 函數導數曲線圖", color="red")ax[1].set_xlabel("x")ax[1].set_ylabel("x.grad")# 用自動求導的結果繪制曲線圖ax[1].plot(x.detach().numpy(), x.grad.detach().numpy())# 設置曲線顏色ax[1].lines[0].set_color("red")plt.show()if __name__ == "__main__":test001()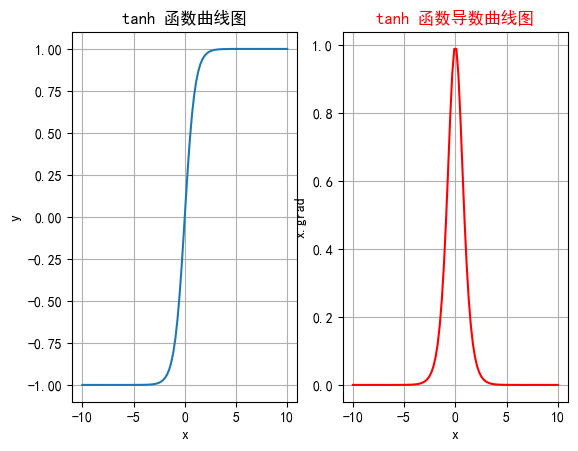
2.3 ReLU
深度學習中最常用的激活函數之一,它的全稱是修正線性單元?,ReLU 激活函數的定義非常簡單,但在實踐中效果非常好。
2.3.1 公式?
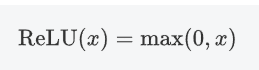
即ReLU對輸入x進行非線性變換:
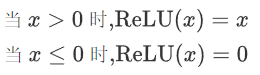
2.3.2 特征
-
計算簡單:ReLU 的計算非常簡單,只需要對輸入進行一次比較運算,這在實際應用中大大加速了神經網絡的訓練。
-
ReLU 函數的導數是分段函數:
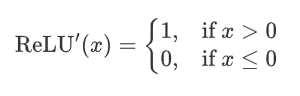
-
緩解梯度消失問題:相比于 Sigmoid 和 Tanh 激活函數,ReLU 在正半區的導數恒為 1,這使得深度神經網絡在訓練過程中可以更好地傳播梯度,不存在飽和問題。
-
稀疏激活:ReLU在輸入小于等于 0 時輸出為 0,這使得 ReLU 可以在神經網絡中引入稀疏性(即一些神經元不被激活),這種稀疏性可以減少網絡中的冗余信息,提高網絡的效率和泛化能力。
2.3.3 缺點
神經元死亡:由于ReLU在x≤0時輸出為0,如果某個神經元輸入值是負,那么該神經元將永遠不再激活,成為“死亡”神經元。隨著訓練的進行,網絡中可能會出現大量死亡神經元,從而會降低模型的表達能力。
2.3.4 函數繪圖
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt# 中文問題
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = Falsedef test006():# 輸入數據xx = torch.linspace(-20, 20, 1000)y = F.relu(x)# 繪制一行2列_, ax = plt.subplots(1, 2)ax[0].plot(x.numpy(), y.numpy())# 顯示坐標格子ax[0].grid()ax[0].set_title("relu 激活函數")ax[0].set_xlabel("x")ax[0].set_ylabel("y")# 繪制導數函數x = torch.linspace(-20, 20, 1000, requires_grad=True)F.relu(x).sum().backward()ax[1].plot(x.detach().numpy(), x.grad.detach().numpy())ax[1].grid()ax[1].set_title("relu 激活函數導數", color="red")# 設置繪制線色顏色ax[1].lines[0].set_color("red")ax[1].set_xlabel("x")ax[1].set_ylabel("x.grad")plt.show()if __name__ == "__main__":test006()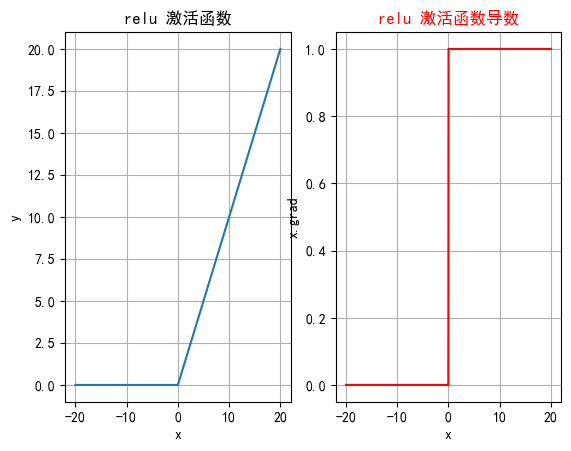
2.4 LeakyReLu
是ReLue函數的改進,解決ReLU的一些缺點,比如Dying ReLu,Leaky ReLU 通過在輸入為負時引入一個小的負斜率來改善這一問題。
2.4.1 公式?
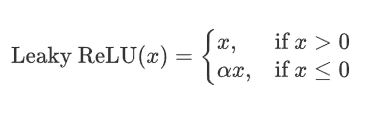
其中,alpha 是一個非常小的常數(如 0.01),它控制負半軸的斜率。這個常數 \alpha是一個超參數,可以在訓練過程中可自行進行調整。
2.4.2 特征
-
避免神經元死亡:通過在x\leq 0 區域引入一個小的負斜率,這樣即使輸入值小于等于零,Leaky ReLU仍然會有梯度,允許神經元繼續更新權重,避免神經元在訓練過程中完全“死亡”的問題。
-
計算簡單:Leaky ReLU 的計算與 ReLU 相似,只需簡單的比較和線性運算,計算開銷低。
2.4.3 缺點
-
參數選擇:\alpha 是一個需要調整的超參數,選擇合適的\alpha 值可能需要實驗和調優。
-
出現負激活:如果\alpha 設定得不當,仍然可能導致激活值過低。
2.4.4 函數繪制
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt# 中文設置
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = Falsedef test006():x = torch.linspace(-5, 5, 200)# 設置leaky_relu的負斜率超參數slope = 0.03y = F.leaky_relu(x, slope)# 一行兩列_, ax = plt.subplots(1, 2)# 開始繪制函數曲線圖ax[0].plot(x, y)ax[0].set_title("Leaky ReLU 函數曲線圖")ax[0].set_xlabel("x")ax[0].set_ylabel("y")ax[0].grid(True)# 繪制leaky_relu的梯度曲線圖x = torch.linspace(-5, 5, 200, requires_grad=True)F.leaky_relu(x, slope).sum().backward()ax[1].plot(x.detach().numpy(), x.grad.detach().numpy())ax[1].set_title("Leaky ReLU 梯度曲線圖", color="pink")ax[1].set_xlabel("x")ax[1].set_ylabel("x.grad")ax[1].grid(True)# 設置線的顏色ax[1].lines[0].set_color("pink")plt.show()if __name__ == "__main__":test006()
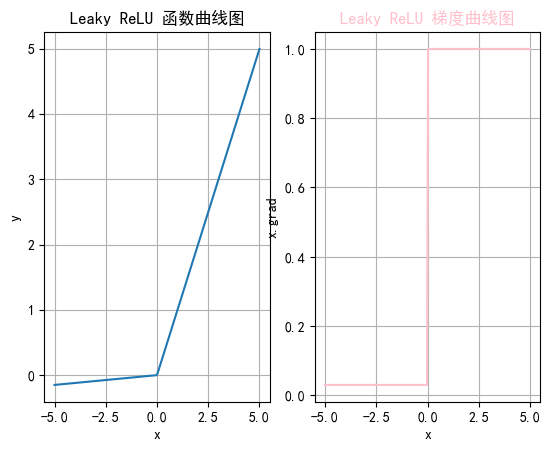
2.5 softmax
通常用于分類問題的輸出層,它能將網絡的輸出轉化為概率分布,使得輸出的各個類別的概率之和為 1。Softmax 特別適合用于多分類問題。
2.5.1 公式
假設神經網絡的輸出層有n個節點,每個節點的輸入為z_i,則 Softmax 函數的定義如下
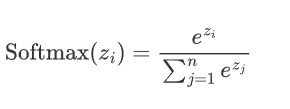
給定輸入向量 ![]()
1.指數變換:對每個 $z_i$進行指數變換,得到 ![]() ,使z的取值區間從
,使z的取值區間從![]() 變為
變為![]()
2.將所有指數變換后的值求和,得到![]()
3.將t中每個 ![]() 除以歸一化因子s,得到概率分布:
除以歸一化因子s,得到概率分布:
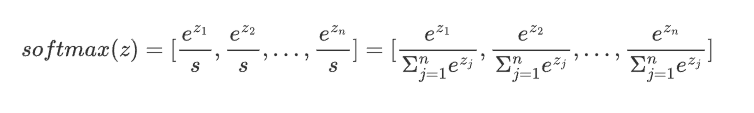
即:
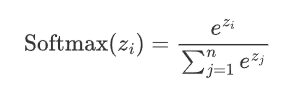
從上述公式可以看出:
1. 每個輸出值在 (0,1)之間
2. Softmax()對向量的值做了改變,但其位置不變
3. 所有輸出值之和為1,即?
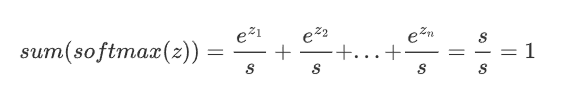
2.5.2 特征
-
將輸出轉化為概率:通過Softmax,可以將網絡的原始輸出轉化為各個類別的概率,從而可以根據這些概率進行分類決策。
-
將輸出轉化為概率:通過Softmax,可以將網絡的原始輸出轉化為各個類別的概率,從而可以根據這些概率進行分類決策。
-
概率分布:Softmax的輸出是一個概率分布,即每個輸出值\text{Softmax}(z_i)都是一個介于0和1之間的數,并且所有輸出值的和為 1:
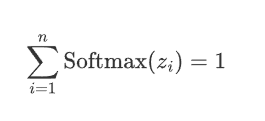
-
突出差異:Softmax會放大差異,使得概率最大的類別的輸出值更接近1,而其他類別更接近0。
-
在實際應用中,Softmax常與交叉熵損失函數Cross-Entropy Loss結合使用,用于多分類問題。在反向傳播中,Softmax的導數計算是必需的。

2.5.3 缺點
-
數值不穩定性:在計算過程中,如果z_i的數值過大,
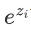 可能會導致數值溢出。因此在實際應用中,經常會對z_i進行調整,如減去最大值以確保數值穩定。
可能會導致數值溢出。因此在實際應用中,經常會對z_i進行調整,如減去最大值以確保數值穩定。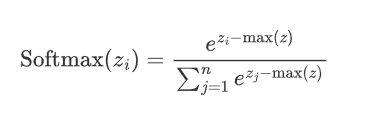
在 PyTorch 中,torch.nn.functional.softmax 函數就自動處理了數值穩定性問題。
? ? ? ?2.難以處理大量類別:Softmax在處理類別數非常多的情況下(如大模型中的詞匯表)計算開銷會較大。
2.5.4 代碼實現
import torch
import torch.nn as nn# 表示4分類,每個樣本全連接后得到4個得分,下面示例模擬的是兩個樣本的得分
input_tensor = torch.tensor([[-1.0, 2.0, -3.0, 4.0], [-2, 3, -3, 9]])softmax = nn.Softmax()
output_tensor = softmax(input_tensor)
# 關閉科學計數法
torch.set_printoptions(sci_mode=False)
print("輸入張量:", input_tensor)
print("輸出張量:", output_tensor)?
?三 、如何選擇激活函數
3.1隱藏層
1.優先選擇ReLU;
2.如果效果一般嘗試其他激活,如LeakyReLU;
3.使用ReLU時注意神經元死亡問題,避免過多神經元死亡
4.避免使用sigmoid,嘗試tanh
3.2輸出層
二分類選擇sigmoid
多分類選擇softmax



算法)
:with 語句、yield from、虛擬環境)
)








的設計與實現(源碼+論文))




