
LatentSync是什么
字節跳動與北京交通大學聯合推出了全新的唇形同步框架?LatentSync,它基于音頻驅動的潛在擴散模型,跳過了傳統的3D建模或2D特征點提取,直接生成自然逼真的說話視頻。
LatentSync借助Stable Diffusion強大的圖像生成能力,精準捕捉聲音與唇部動作之間的復雜關聯。為了解決擴散模型在不同幀之間生成不一致的問題,團隊提出了名為?TREPA(Temporal Representation Alignment)?的方法,引入大規模自監督視頻模型提取時間特征,有效增強生成視頻的時間連貫性,同時保持唇形同步的準確性。
在實驗中,LatentSync成功解決了傳統模型SyncNet的收斂難題,顯著提升了唇形對齊的質量和穩定性。
LatentSync的主要功能
- 唇形同步生成:根據輸入音頻生成對應口型,讓嘴唇與語音完美對齊。
- 高分辨率輸出:突破傳統擴散模型對顯卡的高要求,輕松生成清晰流暢的視頻畫面。
- 動態真實表現:能捕捉情感語調中的細微變化,讓說話表情更生動自然。
- 時間一致性優化:通過TREPA方法提升視頻幀間連貫性,減少閃爍,讓播放更平滑。
LatentSync的技術原理
- 音頻驅動的潛在擴散模型:不同于傳統在像素空間中進行擴散的方式,LatentSync在潛在空間中直接建模,以音頻為條件生成唇形動作,避免兩階段生成過程,大幅提升質量與效率,同時精準捕捉視聽之間的復雜關聯。
- 端到端建模架構:整個流程從音頻輸入到唇部運動輸出,全在一個統一模型中完成,省去了冗余的中間步驟,確保生成過程更加高效和一致。
- TREPA時間一致性優化:引入 VideoMAE-v2 自監督模型提取時間特征,通過衡量生成幀與真實幀的時間表示距離,作為訓練中的額外損失,有效減少視頻播放中的跳幀、閃爍問題,提升自然度。
- SyncNet監督機制:訓練時結合預訓練的 SyncNet,對生成的唇部動作進行精準監督,確保音視頻高度對齊。在像素層面引入 SyncNet 損失,使模型更深入地理解音頻與唇形之間的對應關系。
LatentSync的項目地址
- GitHub倉庫:https://github.com/bytedance/LatentSync
- arXiv技術論文:https://arxiv.org/pdf/2412.09262
LatentSync的應用場景
-
🎬?影視后期制作:自動為配音生成匹配口型動畫,提升效率,確保角色表演自然連貫。
-
📚?教育輔助教學:在在線英語課程中生成唇同步視頻,幫助學生更準確地模仿發音,提升語言學習效果。
-
📢?廣告視頻創作:為虛擬代言人自動生成自然的口型表達,讓廣告詞更具表現力和吸引力。
-
🧑?💻?遠程會議溝通:解決網絡延遲帶來的音畫不同步問題,提升跨國視頻會議的交流體驗。
-
🎮?游戲角色互動:讓NPC在游戲中實現語音與唇部動作同步,增強沉浸感與真實感。
先看效果
原視頻
原視頻
生成效果
生成結果
快速上手指南
AI工具已經被打包成一鍵啟動的版本,只需輕輕點擊即可使用,無需再為環境配置中的各種問題煩惱,一切變得更加便捷高效。
電腦配置要求
- 操作系統:Windows 10/11 64位
- 內存:16G以上
- 顯卡:至少8G及以上顯存的英偉達(NVIDIA)顯卡
- CUDA:顯卡驅動更新到最新,顯卡支持的CUDA版本大于等于12.8版本
- 整個包解壓完約21.3G,要留足硬盤空間
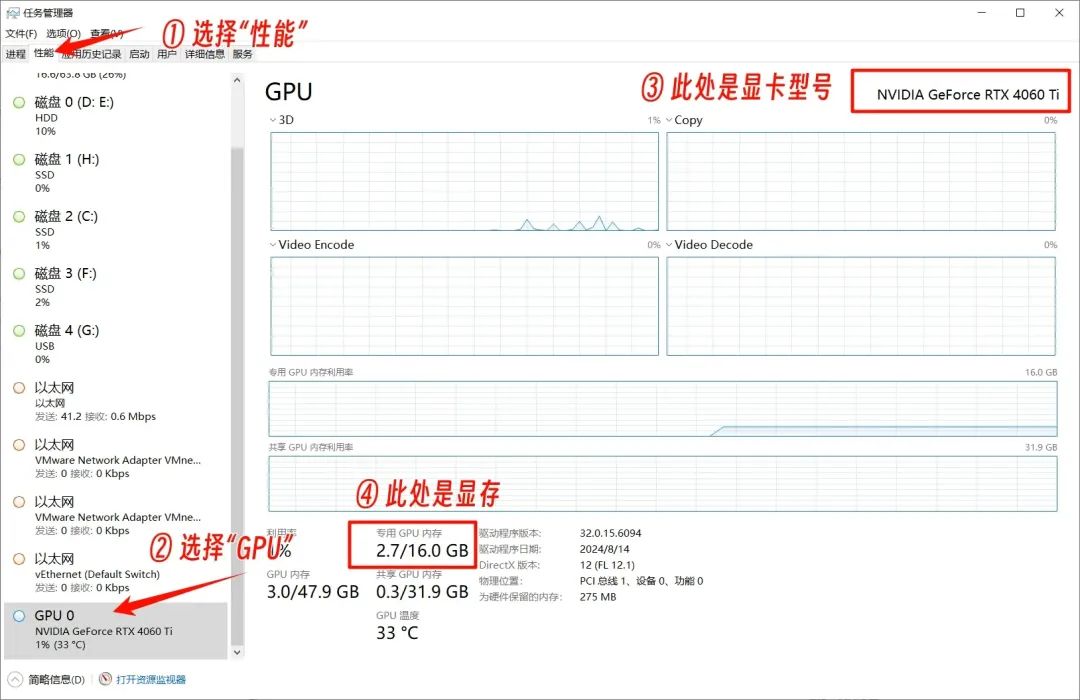
如何查看顯卡品牌型號和顯存:
- 打開任務管理器
- 點擊“性能”
- 點擊“GPU”
- 右上角可以看到顯卡型號,下方可以看到顯存大小
使用教程:
① 打開下載頁面:
- (方式1)直達鏈接:https://www.xyanai.com/2036.html
- (方式2)進入官網www.xyanai.com,搜索”LatentSync”
進入后點擊頁面右側下載按鈕,下載整合包之后解壓,建議使用winrar解壓(解壓軟件在文件包中,或者可以自己下載安裝,下載地址:https://www.winrar.com.cn/)
不要用Windows自帶解壓!!不要用360解壓!!
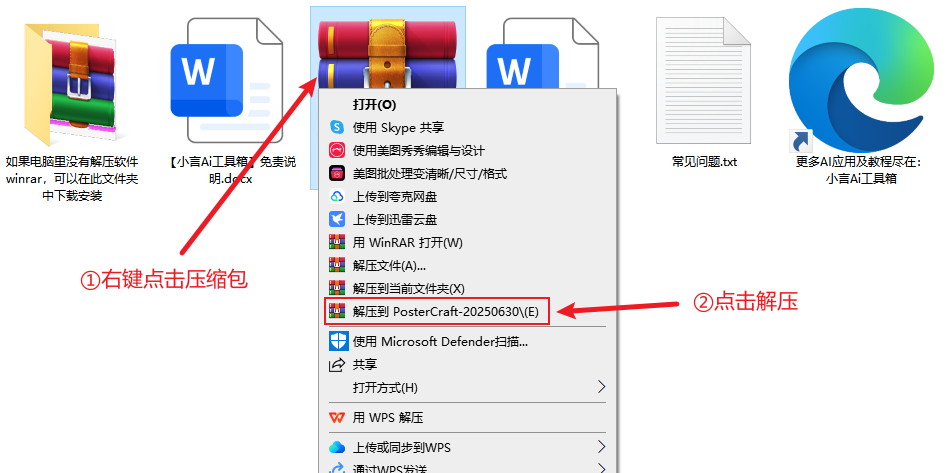
注意:文件夾路徑和文件名稱(包括音頻、圖片、視頻等文件名稱)不要出現中文字符,否則部分軟件會因識別不出而報錯
![]()
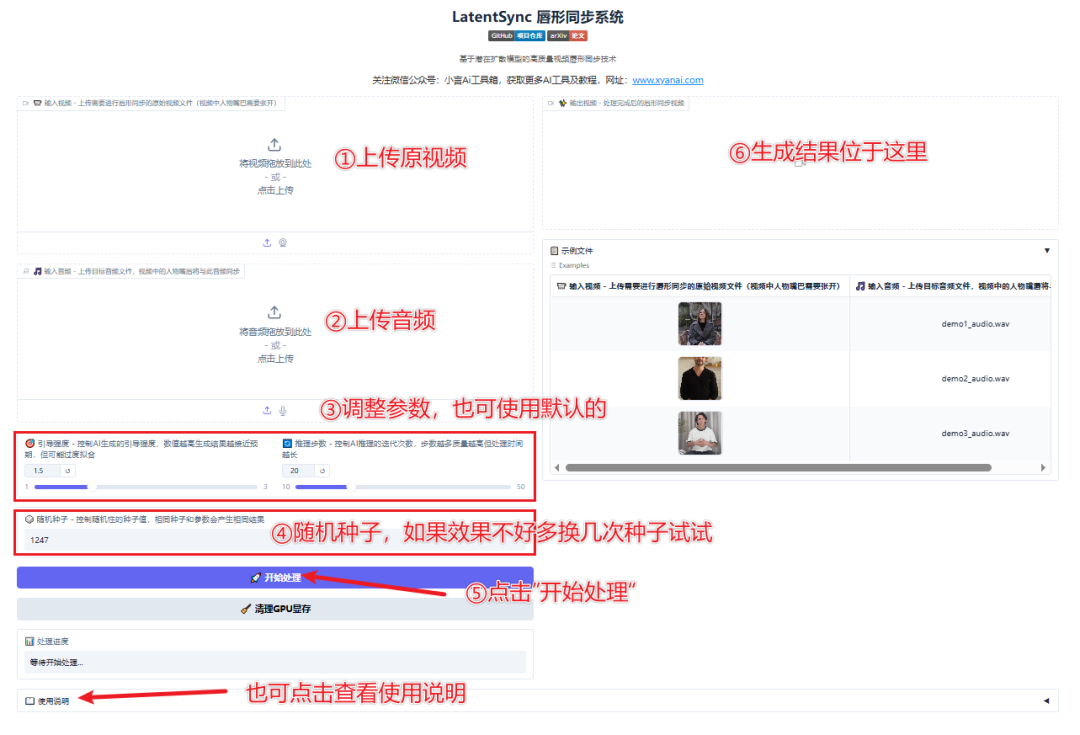
② 雙擊“啟動程序.exe”,稍等片刻會在瀏覽器中自動打開操作界面

③只需上傳一段人物視頻(MP4格式,建議時長長于音頻),再上傳一段音頻文件(支持常見格式如MP3、WAV等),系統便會自動生成與音頻精準對口型的唇形同步視頻。如果視頻時長短于音頻,系統會自動采用“正序→倒序”的循環方式,讓畫面更自然流暢。如需高清效果,可勾選“提升分辨率”選項,并選擇GFPGAN版本和放大倍數。準備完成后,點擊“生成”按鈕即可開始處理,全流程無需手動干預,輕松生成自然真實的說話視頻。
請確保上傳的視頻中人物面部清晰可見,且全過程中人物始終在畫面內,避免出現離開畫面或黑屏的情況,否則系統可能因無法檢測到人臉而報錯。處理時長將根據視頻長度和設備性能有所不同,請耐心等待生成完成。
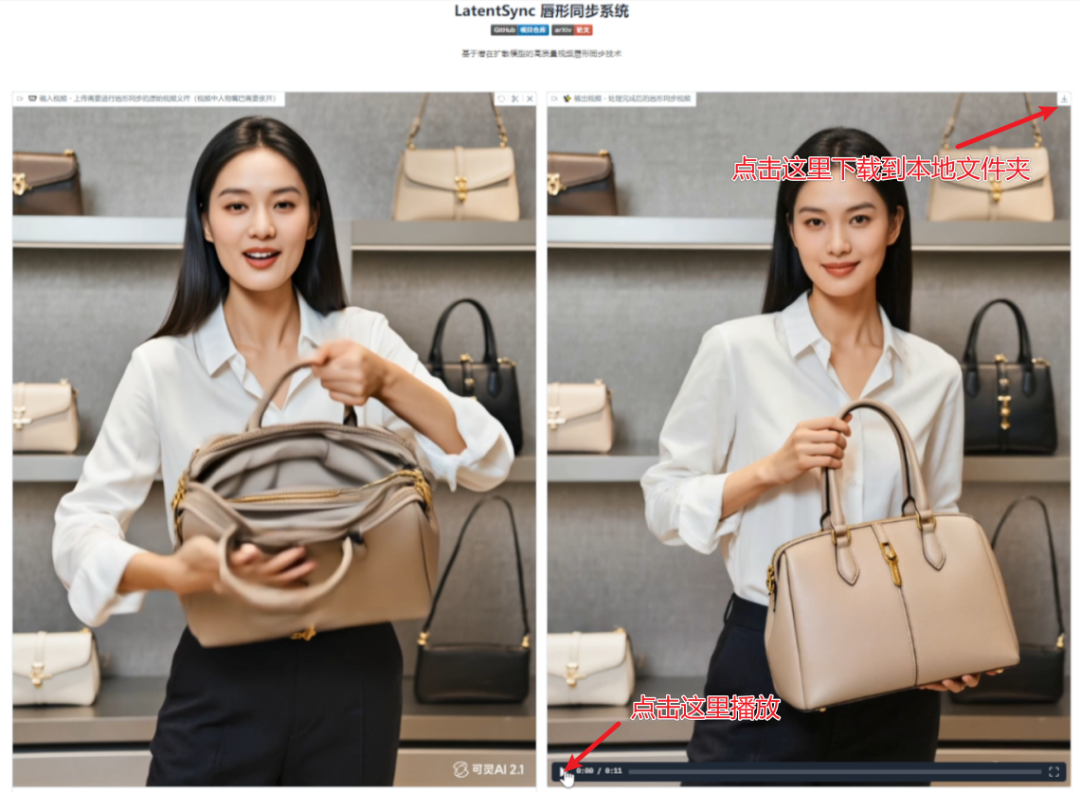
④等待處理完成后,右側將顯示生成的結果視頻,可以播放查看,點擊右上角下載按鈕可以保存至指定文件夾
總結
LatentSync 是字節跳動與北京交通大學聯合推出的一種音頻驅動唇形同步視頻生成框架。它基于潛在擴散模型,直接在潛在空間建模,無需3D建模或關鍵點提取,能高效生成高分辨率、時間一致性強、表情自然的說話視頻。通過引入TREPA時間表示對齊機制和SyncNet監督,LatentSync實現了更真實流暢的音視頻同步,廣泛適用于影視、教育、廣告、會議、游戲等場景。




)



--Collection集合體系)










