目錄
一.故事背景
二、Elasticsearch 全面概述
1、核心定位
2、核心特性
a. 分布式架構
b. 高性能原理
c. 數據模型創新
3、核心技術組件 ?
4、核心應用場景
a. 企業級搜索
b. 可觀測性
c. 安全分析(SIEM)
5、版本演進關鍵特性
6、核心優勢對比
7、性能基準(AWS c5.4xlarge 實測)
8、適用行業
三、Logstash 全面概述
1、Logstash概述
作用
2、Logstash配置文件結構
3、常用插件詳細介紹
輸入插件
過濾插件
輸出插件
4、logstash中的條件判斷
1.條件判斷語句類型
2.條件表達式中的操作符
四、 Elasticsearch安裝與配置
五、 logstash安裝與配置
六、 kibana安裝與配置
七.總結
一.故事背景
在完成各種高可用配置之后,就要開始對Elasticsearch的研究,在安裝過程中發現歐拉的系統沒法直接yum安裝,需要自己編譯安裝,所以換了一個系統來安裝Elasticsearch,elkf分別指的是Elasticsearch+Logstash+Kibana+Filebeat,下面開始分開介紹
二、Elasticsearch 全面概述
1、核心定位
Elasticsearch(ES) 是開源的分布式搜索分析引擎,基于 Apache Lucene 構建,專為處理海量數據設計。核心能力包括:
實時數據分析(毫秒級響應)
全文檢索(支持復雜相關性評分)
結構化/非結構化數據處理
水平擴展性(支持 PB 級數據)
核心定位:解決傳統數據庫在全文檢索、復雜聚合、實時分析場景下的性能瓶頸
2、核心特性
a. 分布式架構
| 概念 | 說明 |
|---|---|
| 節點(Node) | 獨立運行實例,角色包括 Data/Master/Ingest/Coordinating |
| 集群(Cluster) | 多個節點組成的分布式系統 |
| 分片(Shard) | 數據最小單元(Primary Shard + Replica Shard) |
| 索引(Index) | 邏輯數據容器(類似數據庫的表) |
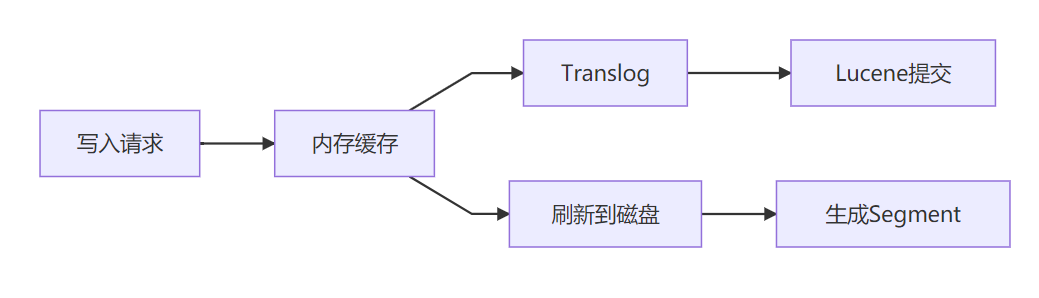
b. 高性能原理
c. 數據模型創新
| 傳統數據庫 | Elasticsearch |
|---|---|
| 固定表結構 | Schema-free JSON文檔 |
| SQL查詢語言 | DSL(JSON格式查詢) |
| ACID事務強一致 | 最終一致性 |
| 行存儲 | 倒排索引+列存(Doc Values) |
3、核心技術組件 ?
-
Lucene 引擎
-
倒排索引(詞項→文檔映射)
-
分詞器(Tokenizer + Filter)
-
評分算法(TF-IDF/BM25)
-
-
分布式協調層
-
一致性協議:Raft(7.x+ 取代 Zen Discovery)
-
元數據管理:Cluster State(由 Master 節點維護)
-
-
跨組件整合
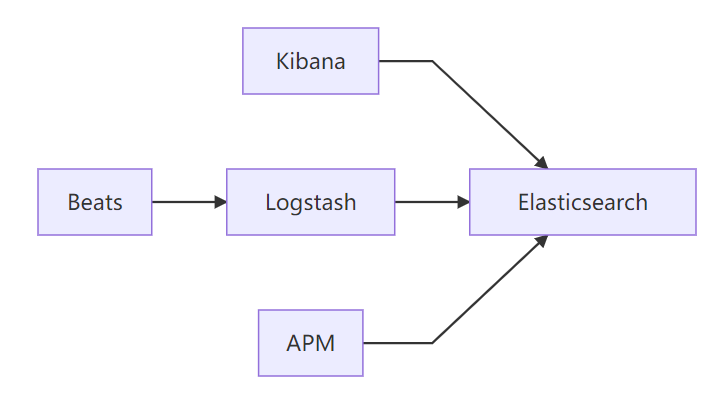
完整觀測體系:日志(Logs)、指標(Metrics)、追蹤(Traces)、APM(Application Performance Monitoring,應用性能監控)
4、核心應用場景
a. 企業級搜索
-
電商商品搜索(多屬性過濾、相關性排序)
-
內容平臺檢索(標題/內容/標簽聯合搜索)
b. 可觀測性
# 日志分析典型流程
filebeat → logstash(解析)→ ES → Kibana(可視化)
c. 安全分析(SIEM)
-
實時威脅檢測(KQL語法)
-
異常行為模式識別
5、版本演進關鍵特性
| 版本 | 里程碑特性 | 影響 |
|---|---|---|
| 7.0 | 廢除多 type 設計 | 簡化數據模型 |
| 7.4 | 引入地理矢量搜索(GeoGrid) | GIS分析能力增強 |
| 7.8 | 內置機器學習(Data Frame) | 異常檢測無需額外插件 |
| 7.12 | 可搜索快照(Searchable Snapshots) | 冷數據存儲成本降低 70% |
6、核心優勢對比
| 能力 | Elasticsearch | 傳統關系型數據庫 | Solr |
|---|---|---|---|
| 全文檢索速度 | ????? | ?☆ | ???? |
| 水平擴展能力 | ????? | ?? | ??? |
| 聚合分析性能 | ???? | ??? | ??? |
| 數據實時性 | ????? | ??? | ??? |
| 事務支持 | ? | ????? | ?? |
7、性能基準(AWS c5.4xlarge 實測)
| 場景 | 數據量 | QPS | 延遲(avg) |
|---|---|---|---|
| 日志寫入 | 1TB/日 | 85,000 | 12ms |
| 關鍵詞搜索 | 10億條 | 4,200 | 35ms |
| 聚合分析 | 1PB | 120 | 1.8s |
8、適用行業
-
電商平臺:商品搜索、推薦系統
-
金融科技:交易監控、風險分析
-
物聯網:設備數據實時分析(50萬+/秒數據點)
-
游戲行業:玩家行為分析、反作弊系統
總結:Elasticsearch 通過創新的分布式架構和倒排索引機制,解決了傳統數據庫在實時搜索與分析場景的瓶頸。作為現代數據棧的核心引擎,其價值已從搜索工具演進為實時數據分析平臺,成為企業數字化轉型的關鍵基礎設施。
三、Logstash 全面概述
1、Logstash概述
Logstash是一個開源的數據收集引擎,它具有強大的數據處理能力。主要功能是從多種數據源獲取數據,對數據進行轉換和過濾,然后將其輸出到目標存儲或分析系統。
作用
Logstash 是一個數據收集引擎,它可以從多個數據源(如文件、數據庫、消息隊列等)收集數據,對數據進行轉換和過濾,然后將其發送到其他存儲或分析工具(如 Elasticsearch)。例如,它可以從各種服務器上的日志文件中收集日志,對日志進行解析,提取出有用的信息(如時間戳、日志級別、消息內容等),還可以對數據進行清洗,去除不需要的信息或者對敏感信息進行脫敏處理
數據輸入源的多樣性:可以從文件(如系統日志文件、應用程序日志文件)、數據庫(通過JDBC等方式)、消息隊列(如Kafka、RabbitMQ)、網絡協議(如HTTP、TCP、UDP)等多種渠道收集數據。例如,在一個微服務架構的系統中,Logstash可以從各個微服務產生的日志文件以及消息隊列中的消息獲取數據。
數據轉換和過濾功能:它能夠解析、修改和豐富收集到的數據。比如,可以將日志文件中的文本內容按照特定的格式(如JSON、CSV等)進行解析,提取關鍵信息;對敏感數據進行脫敏處理;根據某些條件過濾掉不需要的數據。
數據輸出的靈活性:能夠將處理后的數據輸出到各種存儲和分析工具,如Elasticsearch(用于存儲和全文搜索)、Redis(用于緩存或簡單的數據存儲)、文件系統等。這樣可以方便地將數據整合到現有的數據處理和分析流程中。
2、Logstash配置文件結構
Logstash的配置文件是基于JSON樣式的配置語言編寫的,主要由三個部分組成:input(輸入)、filter(過濾)和output(輸出)。
input部分:
定義了數據的來源。例如,從文件讀取數據的配置如下:
input {
? ? ?file {
? ? ? ?path => "/var/log/messages"
? ? ? ?start_position => "beginning"
? ? ?}
? ?}
這里file是輸入插件類型,表示從文件讀取數據。path參數指定了要讀取的日志文件路徑,start_position參數表示從文件的開頭(beginning)還是結尾(end)開始讀取。如果要從網絡端口接收數據,可以使用tcp或udp輸入插件,如:
?input {
? ? ?tcp {
? ? ? ?port => 5000
? ? ? ?codec => json_lines
? ? ?}
? ?}
此配置通過tcp插件監聽5000端口,使用json_lines編解碼器來解析接收到的JSON格式的數據行。
filter部分:
用于對輸入的數據進行處理。例如,使用grok過濾器來解析日志中的內容。假設我們有一個常見的Nginx訪問日志格式,配置可以是:
??filter {
? ? ?grok {
? ? ? ?match => { "message" => '%{IPORHOST:clientip} - %{USERNAME:ident} - %{USERNAME:auth} \[%{HTTPDATE:timestamp}\] "%{WORD:verb} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}" %{NUMBER:response} %{NUMBER:bytes} "%{GREEDYDATA:referrer}" "%{GREEDYDATA:agent}"' }
? ? ?}
? ?}
這個grok過濾器會根據指定的模式(match)來解析message字段(假設輸入的數據中有這個字段),將其中的IP地址、用戶名、時間戳、請求方法等信息提取出來,分別賦值給新的字段(如clientip、ident等)。
還可以使用mutate過濾器來修改字段,比如將字符串轉換為整數:
?filter {
? ? ?mutate {
? ? ? ?convert => {
? ? ? ? ?"response" => "integer"
? ? ? ?}
? ? ?}
? ?}?
此配置會將response字段從字符串類型轉換為整數類型。
output部分:
確定了數據的輸出目標。例如,將數據輸出到Elasticsearch的配置:
? output {
? ? ?elasticsearch {
? ? ? ?hosts => ["http://localhost:9200"]
? ? ? ?index => "logstash-logs"
? ? ?}
? ?}?
這里elasticsearch是輸出插件類型。hosts參數指定了Elasticsearch的主機地址列表,index參數定義了數據要存儲到Elasticsearch中的索引名稱。如果要將數據輸出到文件,可以使用file輸出插件:
?output {
? ? ?file {
? ? ? ?path => "/var/log/logstash/output.log"
? ? ?}
? ?}
這個配置會將處理后的數據寫入到/var/log/logstash/output.log文件中。
3、常用插件詳細介紹
輸入插件
jdbc插件:
用于從數據庫中讀取數據。需要配置數據庫連接信息,如jdbc_connection_string(數據庫連接字符串)、jdbc_user(用戶名)和jdbc_password(密碼)等。例如:
?input {
? ? ? ?jdbc {
? ? ? ? ?jdbc_connection_string => "jdbc:mysql://localhost:3306/mydb"
? ? ? ? ?jdbc_user => "user"
? ? ? ? ?jdbc_password => "password"
? ? ? ? ?statement => "SELECT * FROM mytable"
? ? ? ?}
? ? ?}?
這個配置會通過JDBC連接到本地的MySQL數據庫,執行SELECT * FROM mytable語句來獲取數據。
file(文件輸入插件)
- 功能:從文件系統中的文件讀取數據。它會跟蹤文件的變化,例如新行的添加,非常適合處理日志文件。可以配置為按行讀取,并且能夠處理多種文件編碼。
- 示例配置:
?input {
? ? file {
? ? ?path => "/var/log/messages"
? ? ?start_position => "beginning"
? ? ?sincedb_path => "/dev/null"
? ? }
? ?}
- 在這個示例中,Logstash會從/var/log/messages文件讀取數據。start_position => "beginning"表示從文件開頭開始讀取,sincedb_path => "/dev/null"用于忽略默認的記錄文件讀取位置的數據庫,這樣每次啟動都從指定位置讀取。
stdin(標準輸入插件)
- 功能:允許從標準輸入讀取數據。這在測試Logstash管道或者需要手動輸入數據進行處理時非常有用。
- 示例配置:
?input {
? ? stdin { }
? ?}?
- 配置很簡單,啟用后可以在Logstash運行時通過命令行手動輸入數據,這些數據會按照Logstash的管道配置進行處理。
syslog(系統日志輸入插件)
- 功能:用于接收通過syslog協議發送的系統日志消息。它可以監聽指定的UDP或TCP端口,支持RFC3164和RFC5424格式的syslog消息。
- 示例配置:
?input {
? ? syslog {
? ? ?port => 514
? ? ?type => "syslog"
? ? }
? ?}?
- 此配置會讓Logstash在端口514上監聽syslog消息,并且為這些消息設置一個type為syslog的標簽,方便后續在過濾器和輸出階段進行處理。
beats(Beats輸入插件)
- 功能:用于接收來自Elastic Beats(如Filebeat、Metricbeat等)發送的數據。Beats是輕量級的數據采集器,它們可以將數據發送到Logstash進行進一步的處理和轉發。
- 示例配置:
?input {
? ? beats {
? ? ?port => 5044
? ? }
? ?}?
- 這個配置會讓Logstash在端口5044上監聽來自Beats的數據。
http(HTTP輸入插件)
- 功能:允許通過HTTP協議接收數據。可以設置端點來接收POST請求等,用于接收來自Web應用程序或其他能夠通過HTTP發送數據的源的數據。
- 示例配置:
?input {
? ? http {
? ? ?host => "0.0.0.0"
? ? ?port => 8080
? ? ?codec => "json"
? ? }
? ?}?
- 這里配置Logstash在0.0.0.0:8080上監聽HTTP請求,并且期望接收的數據是JSON格式,接收到的數據會根據Logstash的管道流程進行后續處理。
過濾插件
grok插件:
是Logstash中非常強大的文本解析插件。它使用一種類似于正則表達式的語法來匹配和提取數據。除了前面的示例,還可以自定義模式。例如,如果有一個自定義的日志格式,其中包含一個以[KEY:VALUE]形式的字段,可以定義一個新的模式:
? ? ?grok {
? ? ? ?add_pattern => {
? ? ? ? ?"CUSTOM_PATTERN" => "\[%{WORD:key}:%{GREEDYDATA:value}\]"
? ? ? ?}
? ? ? ?match => { "message" => '%{CUSTOM_PATTERN}' }
? ? ?}?
這里先添加了一個名為CUSTOM_PATTERN的模式,然后使用這個模式來解析message字段。
date插件:
用于解析日期時間字段,并將其轉換為Logstash內部的時間格式。例如:
這個配置會將timestamp字段按照dd/MMM/yyyy:HH:mm:ss Z的格式解析為日期時間,然后將結果存儲到新的log_date字段中。
輸出插件
elasticsearch插件:
除了基本的hosts和index參數,還有document_type參數(在較新的Elasticsearch版本中可能不再常用,但在某些舊版本或特定場景下仍有作用)。例如:
?output {
? ? ? ?elasticsearch {
? ? ? ? ?hosts => ["http://localhost:9200"]
? ? ? ? ?index => "logstash-logs"
? ? ? ? ?document_type => "log"
? ? ? ?}
? ? ?}
此配置將數據存儲到logstash - logs索引中,文檔類型為log。另外,還可以配置批量發送數據的參數,如batch_size(每次批量發送的數據量)和worker_threads(用于發送數據的線程數),以提高數據發送效率。
stdout插件:
用于將數據輸出到控制臺,方便調試。可以配置輸出的格式,如codec(編解碼器)。例如:
?output {
? ? ? ?stdout {
? ? ? ? ?codec => rubydebug
? ? ? ?}
? ? ?}?
這個配置會使用rubydebug格式將數據輸出到控制臺,這種格式會詳細地顯示數據的結構和內容。
4、logstash中的條件判斷
1.條件判斷語句類型
if語句
作用:if語句是最常用的條件判斷語句。它根據給定的條件決定是否執行代碼塊中的操作。如果條件為真,則執行if語句塊內的操作;如果條件為假,則跳過該語句塊。
語法示例:
if [field_name] == "value" {
?#操作,如mutate、drop等操作
? ?}
應用場景:例如,在處理日志數據時,若只想處理日志級別為INFO的日志,可以使用if語句判斷[log_level] == "INFO",然后在語句塊中對這些日志進行字段添加、數據轉換等操作。
unless語句
作用:unless語句與if語句邏輯相反。當條件為假時,執行unless語句塊內的操作;當條件為真時,跳過該語句塊。
語法示例:
unless [field_name] == "value" {
?#操作,如mutate、drop等操作
? ?}?
應用場景:假設不想處理來自某個特定IP地址的日志,就可以使用unless語句。例如,unless [client_ip] == "192.168.1.1",在語句塊中對非該IP地址的日志進行處理。
case語句(在mutate插件中)
作用:case語句用于多分支條件判斷。它根據一個字段的不同取值來執行不同的操作,類似于編程語言中的switch語句。
語法示例:
?mutate {
? ? ?case [field_name] {
? ? ? ?"value1" => {
? ? ?#操作1
? ? ? ?}
? ? ? ?"value2" => {
? ? ?#操作2
? ? ? ?}
? ? ? ?default => {
? ? ?#當字段值不匹配前面任何一個分支時執行的操作
? ? ? ?}
? ? ?}
? ?}
應用場景:當日志中有一個表示事件類型的字段,如[event_type],可以根據不同的事件類型(如"login"、"logout"等)執行不同的字段添加或修改操作。
2.條件表達式中的操作符
比較操作符
相等(==)和不等(!=)
解釋:用于判斷兩個值是否相等或不相等。在Logstash中,可以用于比較字段值與常量,或者兩個字段值之間的比較。
示例:
if [log_level] == "ERROR":判斷log_level字段的值是否等于ERROR。
if [field1]!= [field2]:判斷field1和field2兩個字段的值是否不相等。
大小比較操作符(>、>=、<、<=)
解釋:用于比較數值型字段的值大小關系。這些操作符在比較日志中的時間戳、計數等數值型數據時很有用。
示例:
if [count] > 10:判斷count字段的值是否大于10。
if [response_time] <= 500:判斷response_time字段的值是否小于等于500(單位可能是毫秒等)。
正則表達式匹配操作符(=~和!~)
解釋:=~用于判斷一個字段的值是否匹配給定的正則表達式,!~則用于判斷一個字段的值是否不匹配給定的正則表達式。正則表達式在處理文本格式的日志數據時非常強大,可以用于匹配特定的模式。
示例:
if [message] =~ /error/:判斷message字段的值是否包含error這個單詞(簡單的正則表達式示例)。
if [user_agent]!~ /^Mozilla/:判斷user_agent字段的值是否不以Mozilla開頭。
邏輯操作符
與(&&)和或(||)
解釋:用于組合多個條件。&&表示只有當所有條件都為真時,整個表達式才為真;||表示只要有一個條件為真,整個表達式就為真。
示例:
if ([log_level] == "WARN" && [count] > 5):判斷log_level是否為WARN并且count是否大于5。
if ([source_ip] == "192.168.1.1" || [source_ip] == "10.0.0.1"):判斷source_ip是否為192.168.1.1或者是否為10.0.0.1。
包含和不包含操作符(in和not in)
解釋:用于判斷一個值是否在一個數組或者集合類型的字段中,或者不在其中。在Logstash中,一些插件可能會生成包含多個標簽(tags)的字段,這些操作符就可以用于判斷某個標簽是否存在。
示例:
?if "error" in [tags]:判斷tags字段中是否包含error這個標簽。
i
f "debug" not in [tags]:判斷tags字段中是否不包含debug這個標簽。
四、 Elasticsearch安裝與配置
(使用Rocky8系統)
修改主機名 ?

將elasticsearch軟件包拷貝至elk主機執行安裝
對時
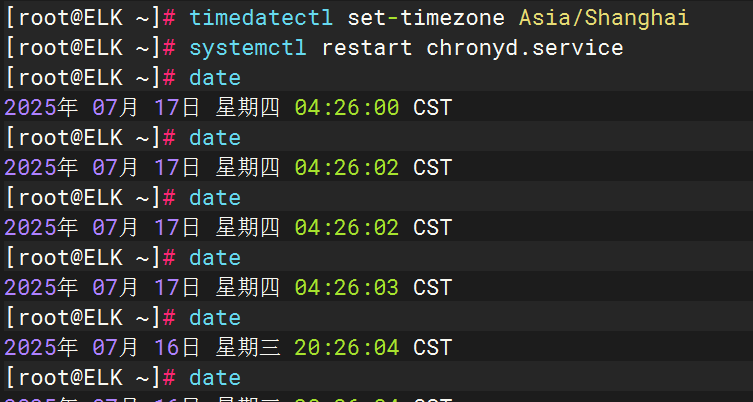
檢查java版本

配置elasticsearch 文件

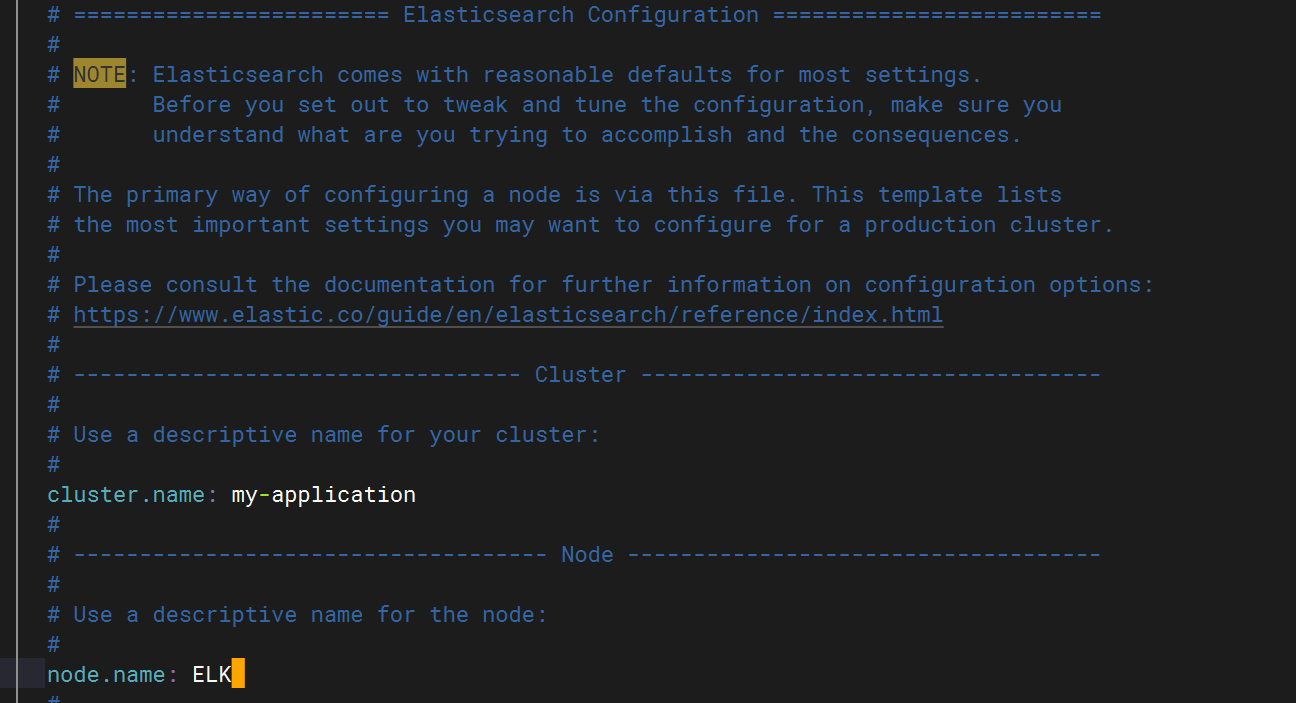
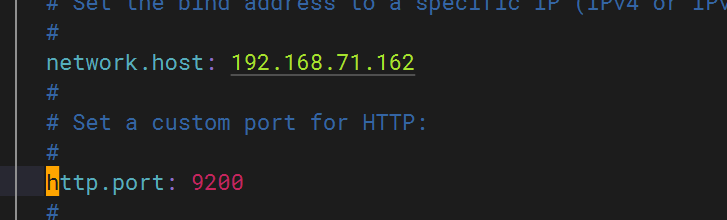
 ?配置主機名解析
?配置主機名解析

啟動elasticsearch服務并驗證啟動結果

五、 logstash安裝與配置
將logstash軟件包拷貝至elk主機執行安裝
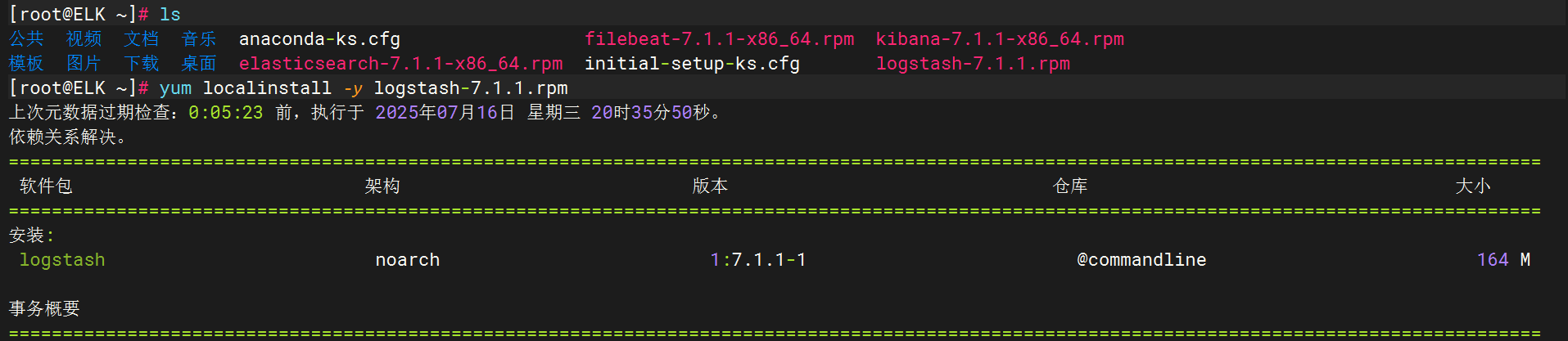
創建配置文件
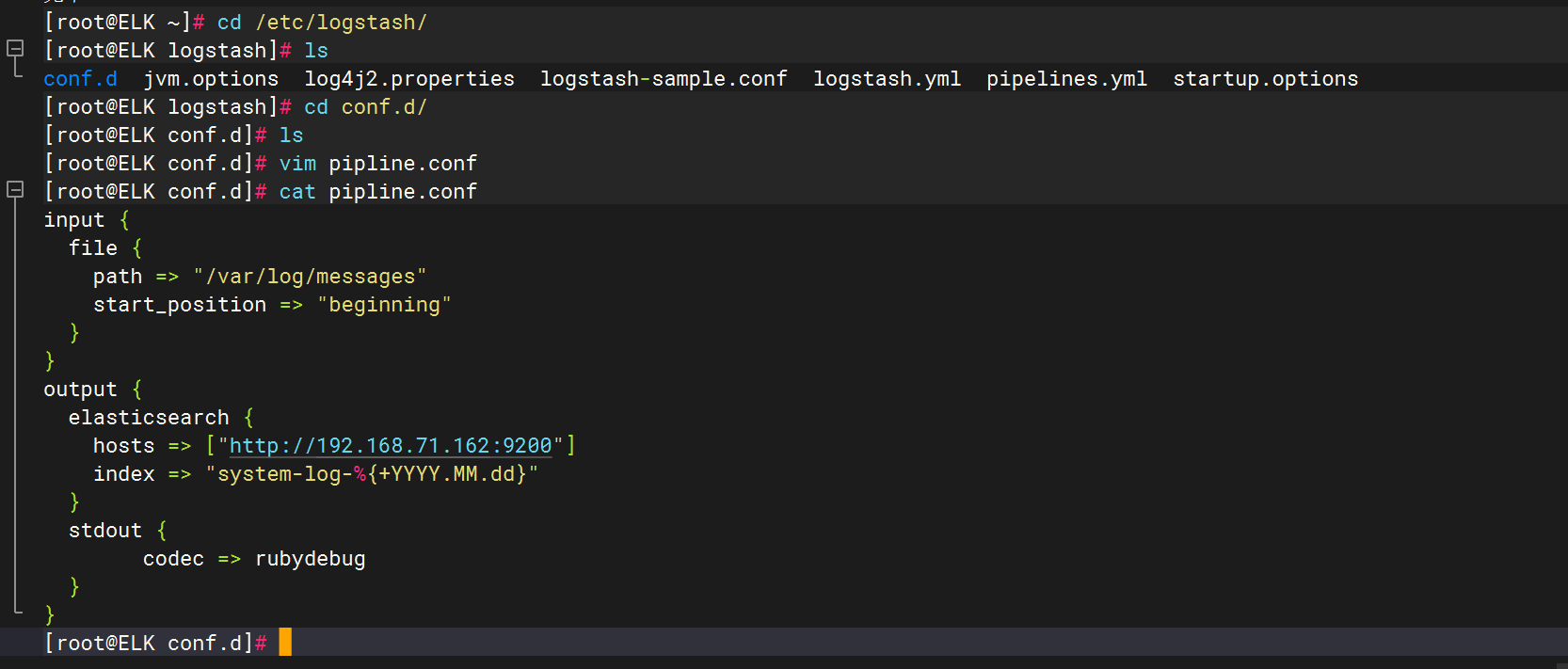
input {file {path => "/var/log/messages"start_position => "beginning"}
}
output {elasticsearch {hosts => ["http://192.168.71.162:9200"]index => "system-log-%{+YYYY.MM.dd}"}stdout {codec => rubydebug}
}
優化logstash命令

測試logstash服務的數據傳輸
標準輸入與輸出
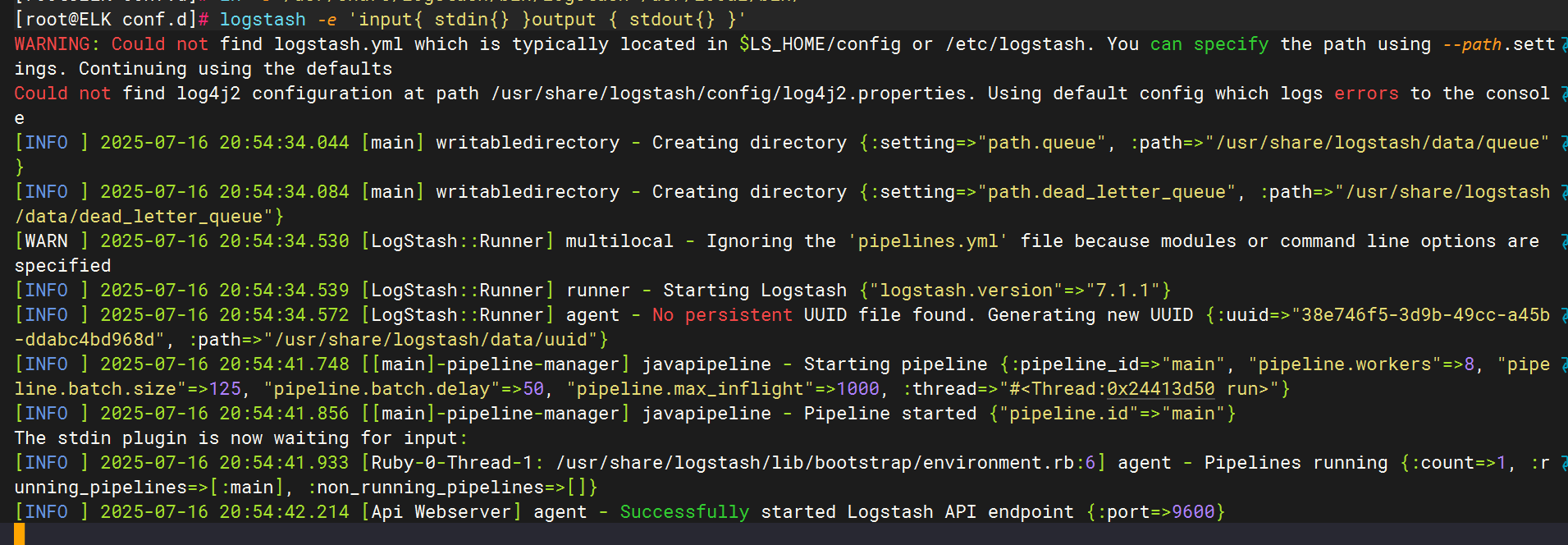
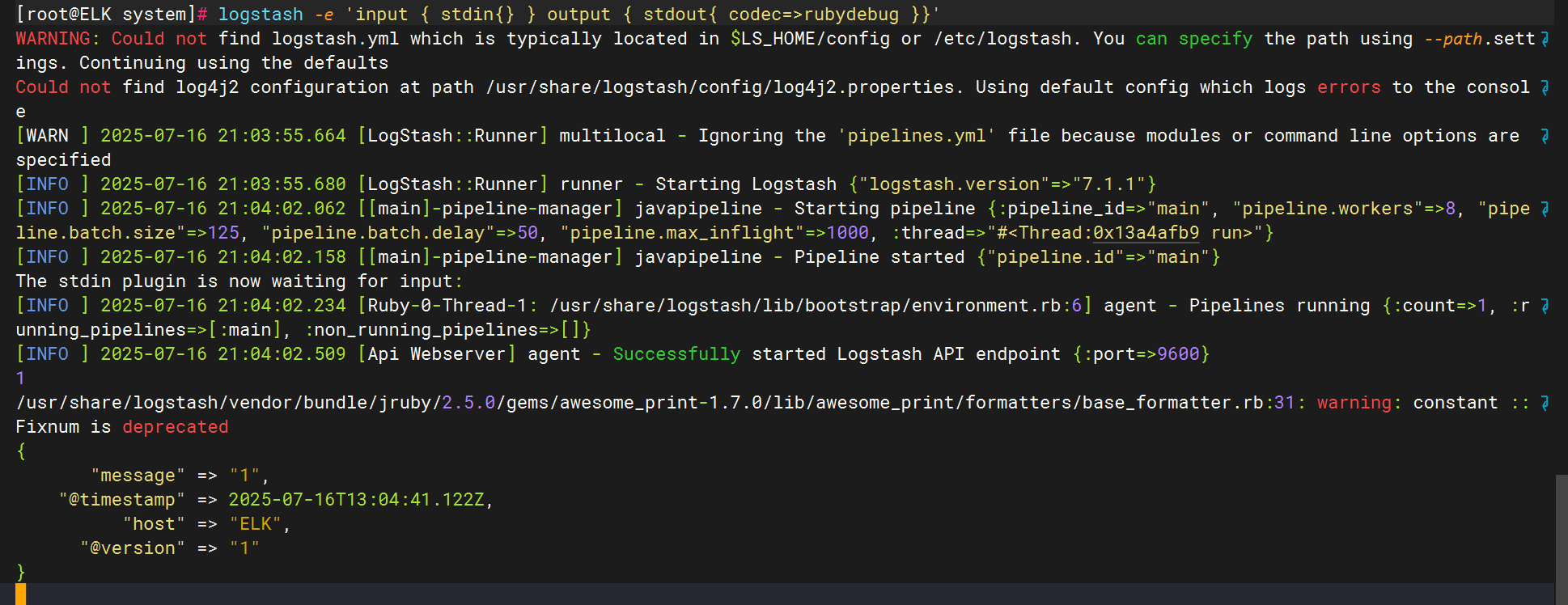
使用rubydebug解碼
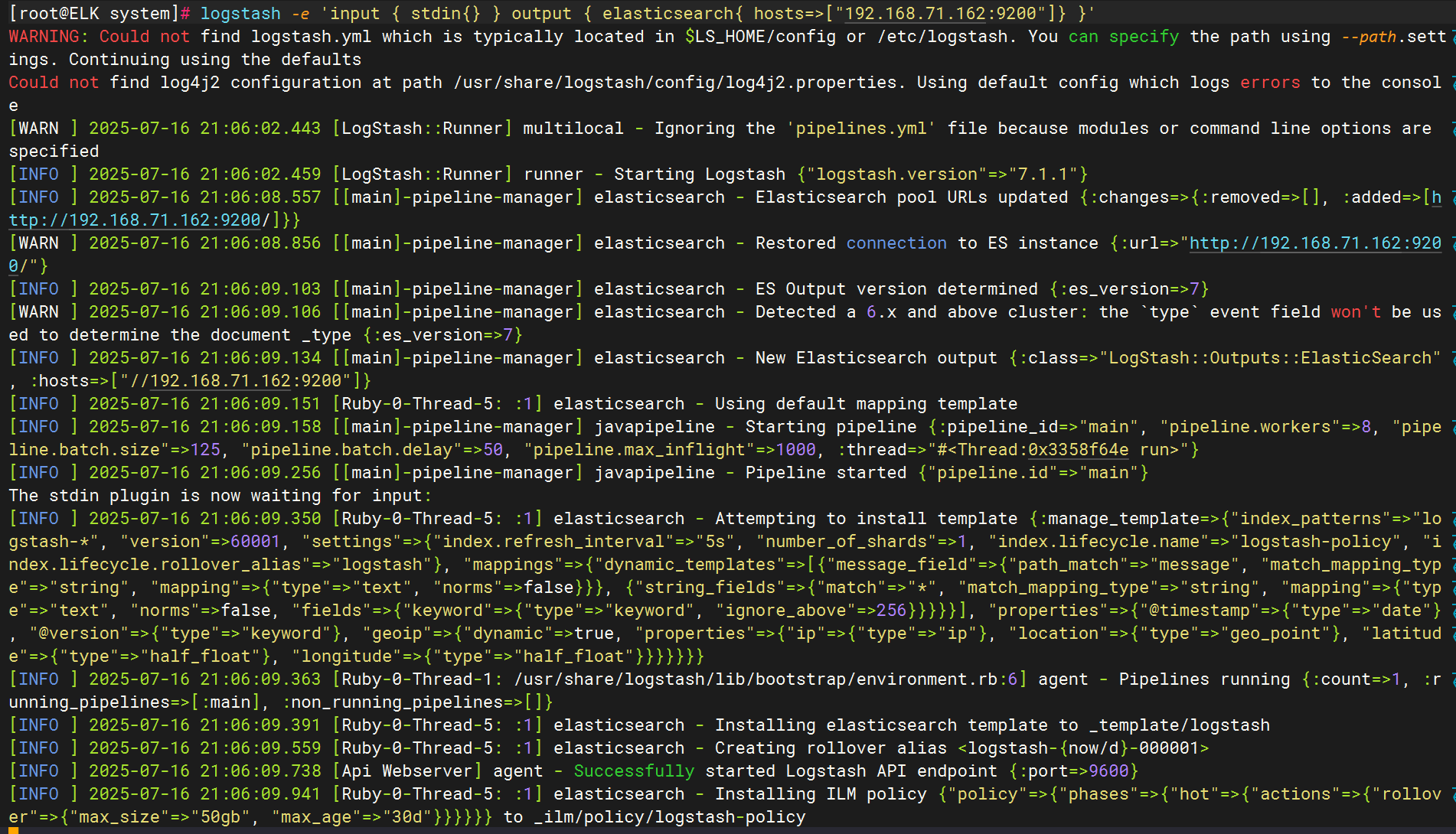
輸出到elasticsearch
登錄到9200端口
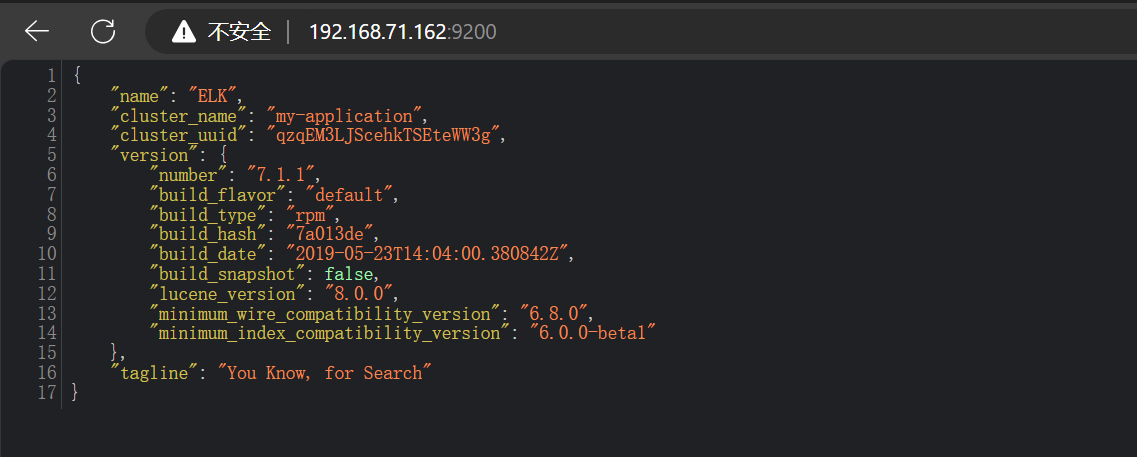
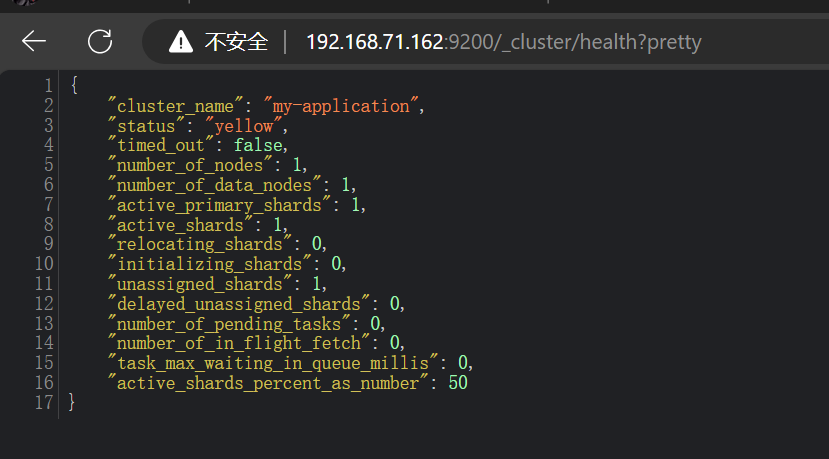
查看集群健康狀態
六、 kibana安裝與配置
將kibana軟件包拷貝至elk主機執行安裝
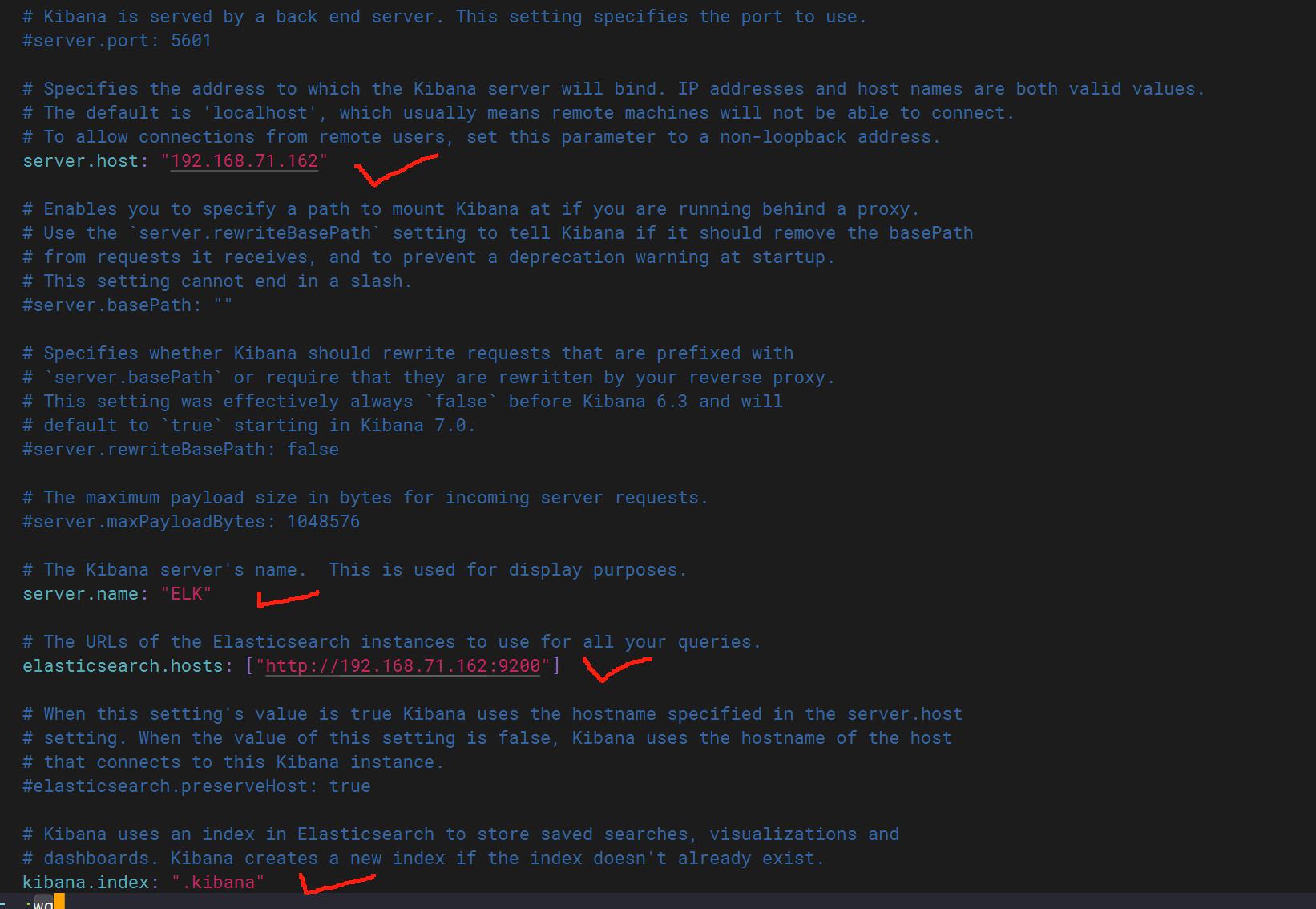
配置kibana文件

啟動kibana并查看狀態

正常后,登錄5601端口進入kibana頁面
從配置文件最后一行中修改為中文方便查看

重啟服務并刷新界面

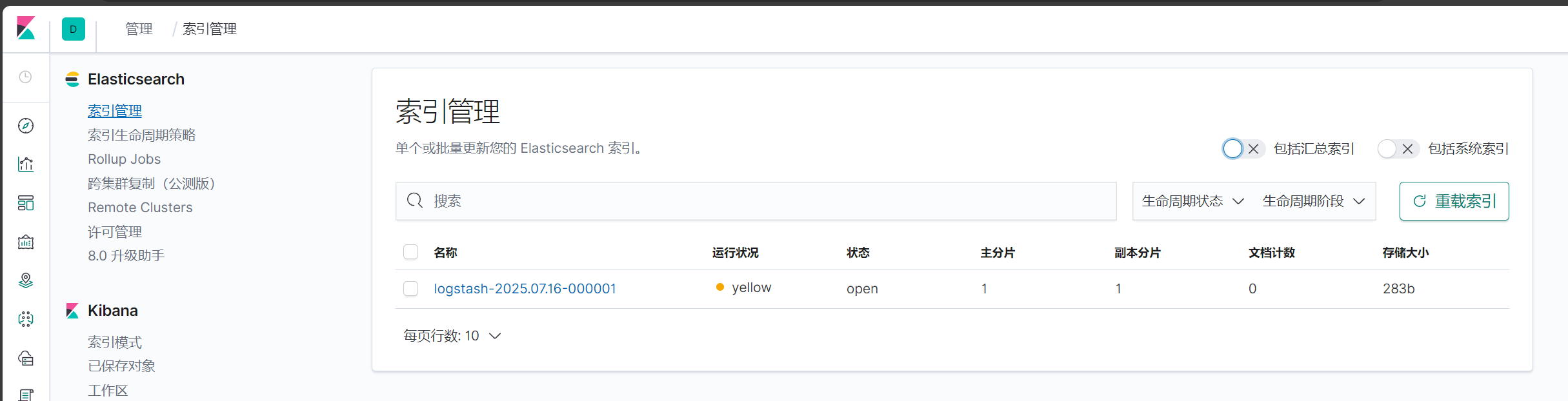
點擊自己瀏覽后點擊索引管理
使用logstash -f /etc/logstash/conf.d/pipline.conf? 命令監控日志信息
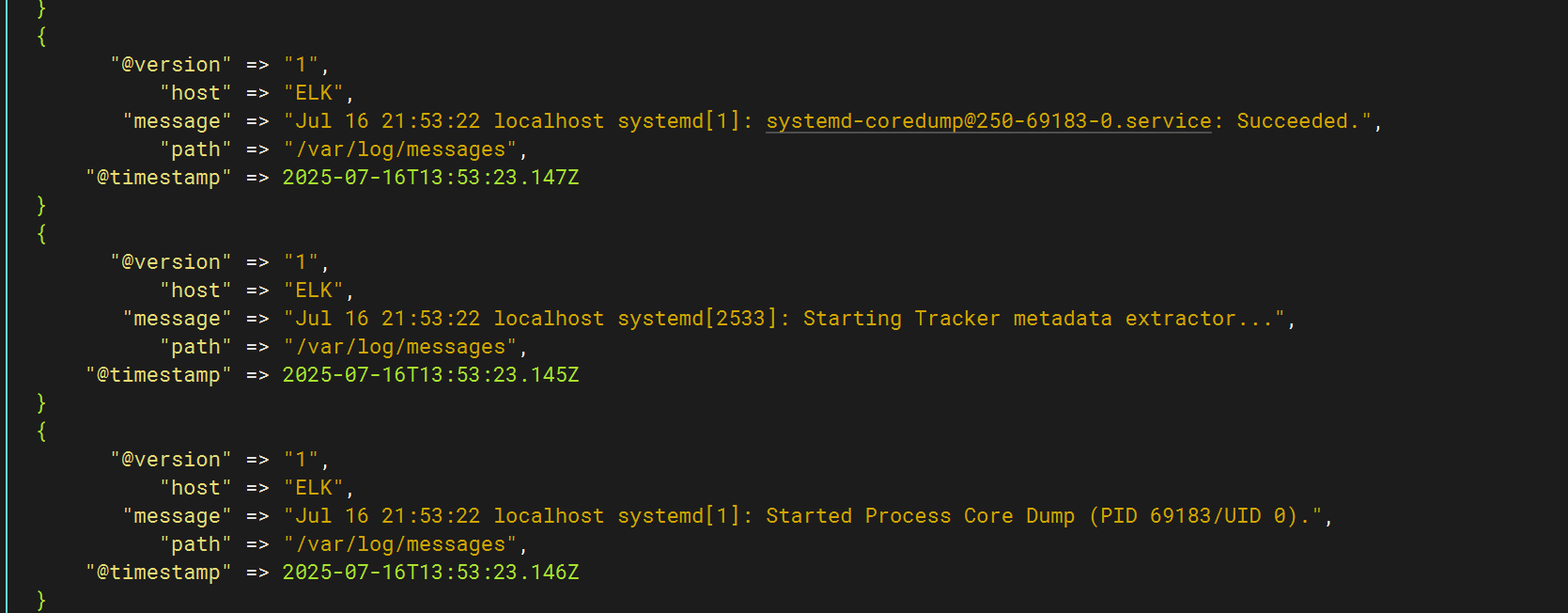
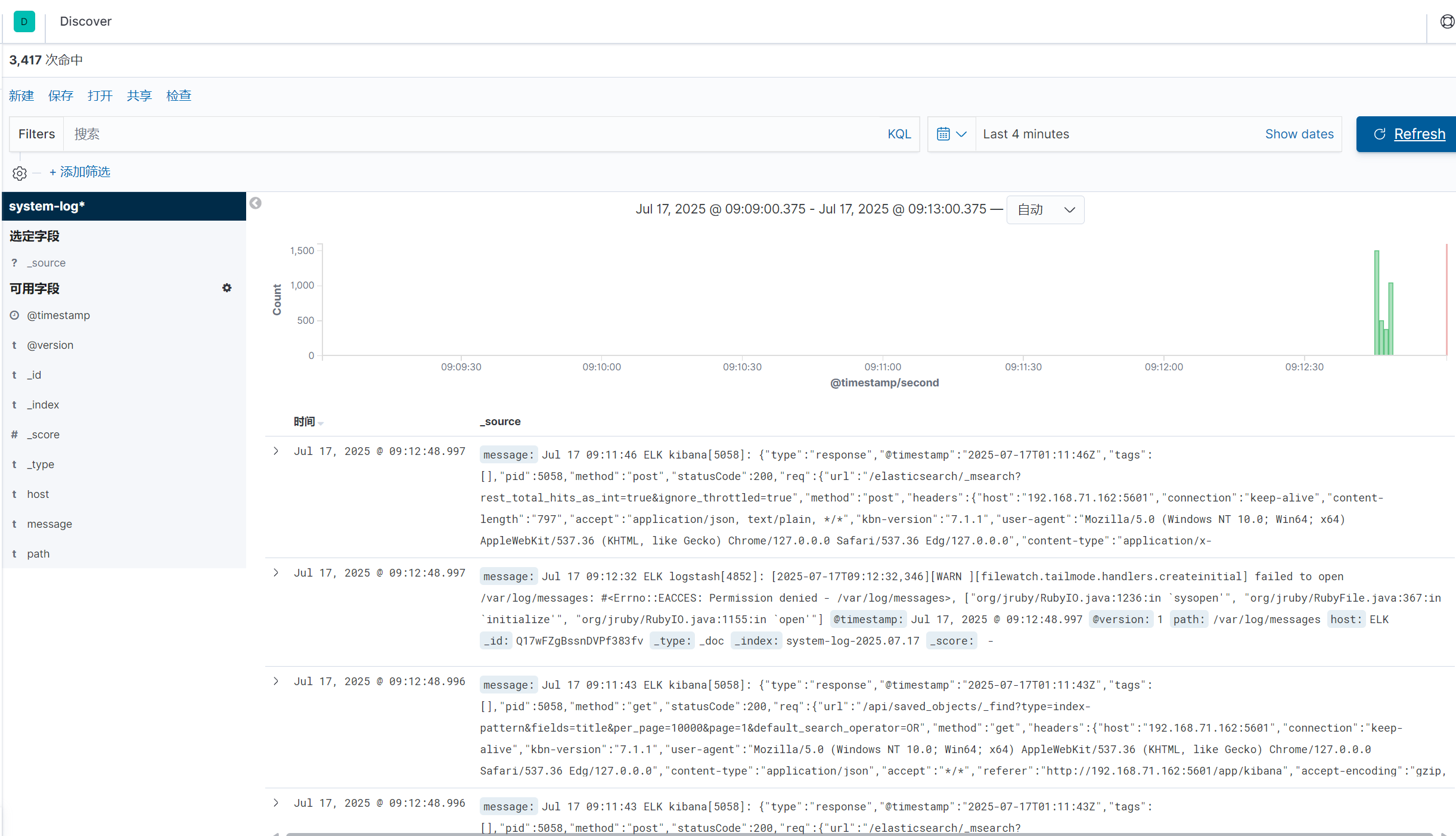
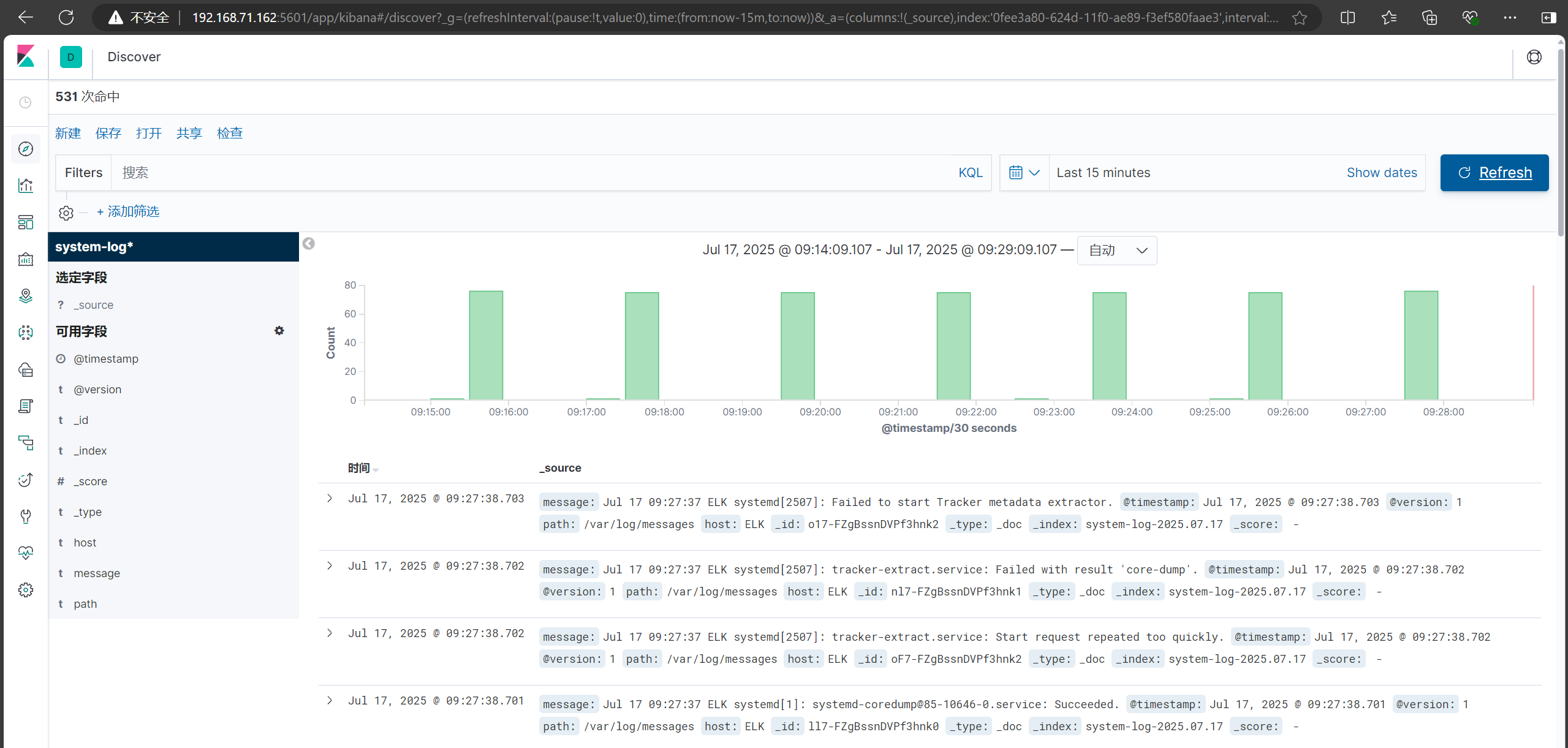
與此同時kibana頁面同步出日志內容
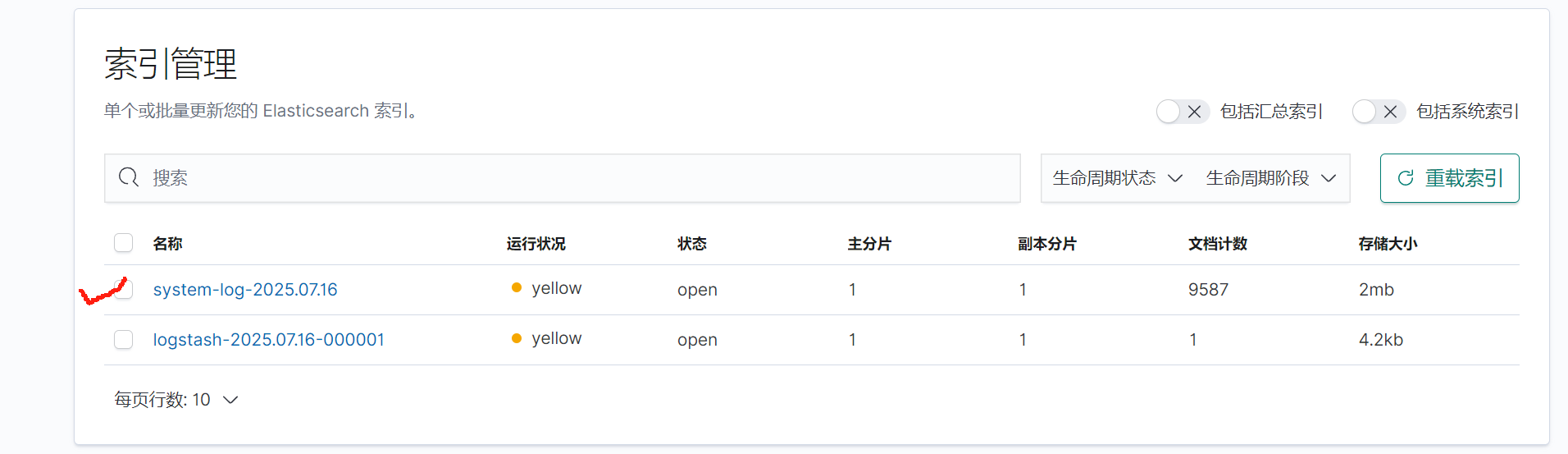
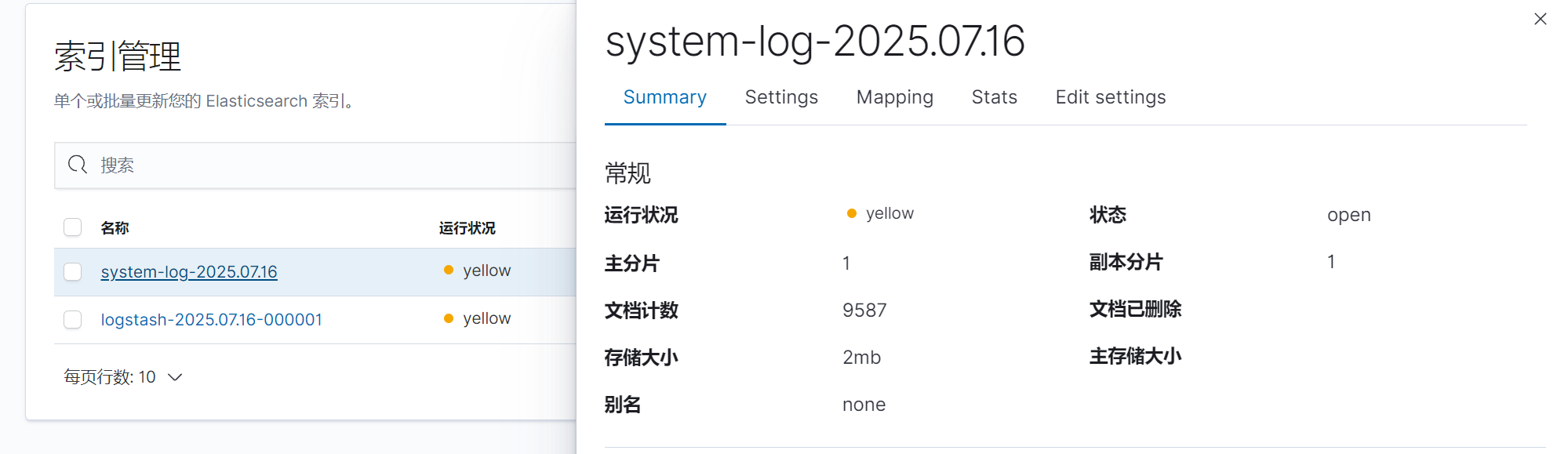
創建索引
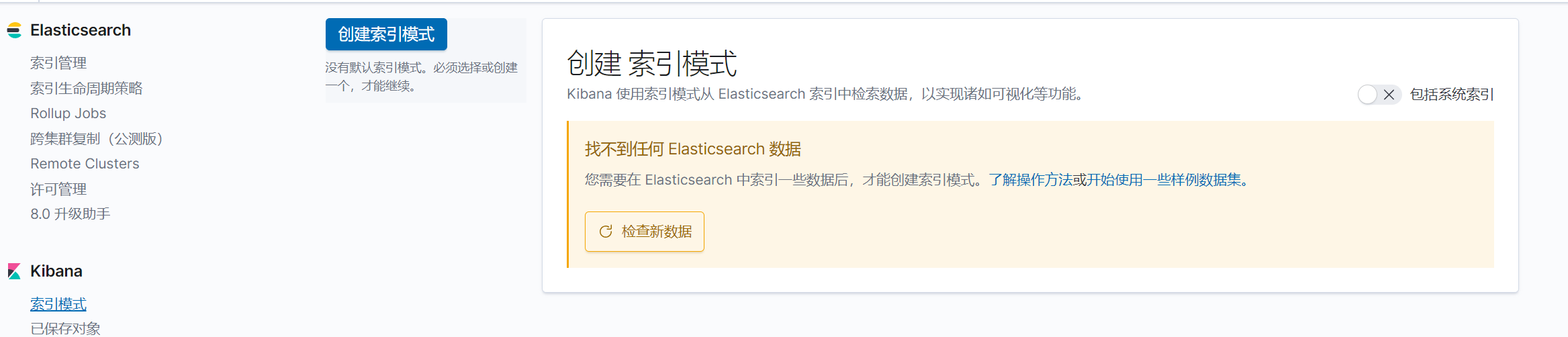
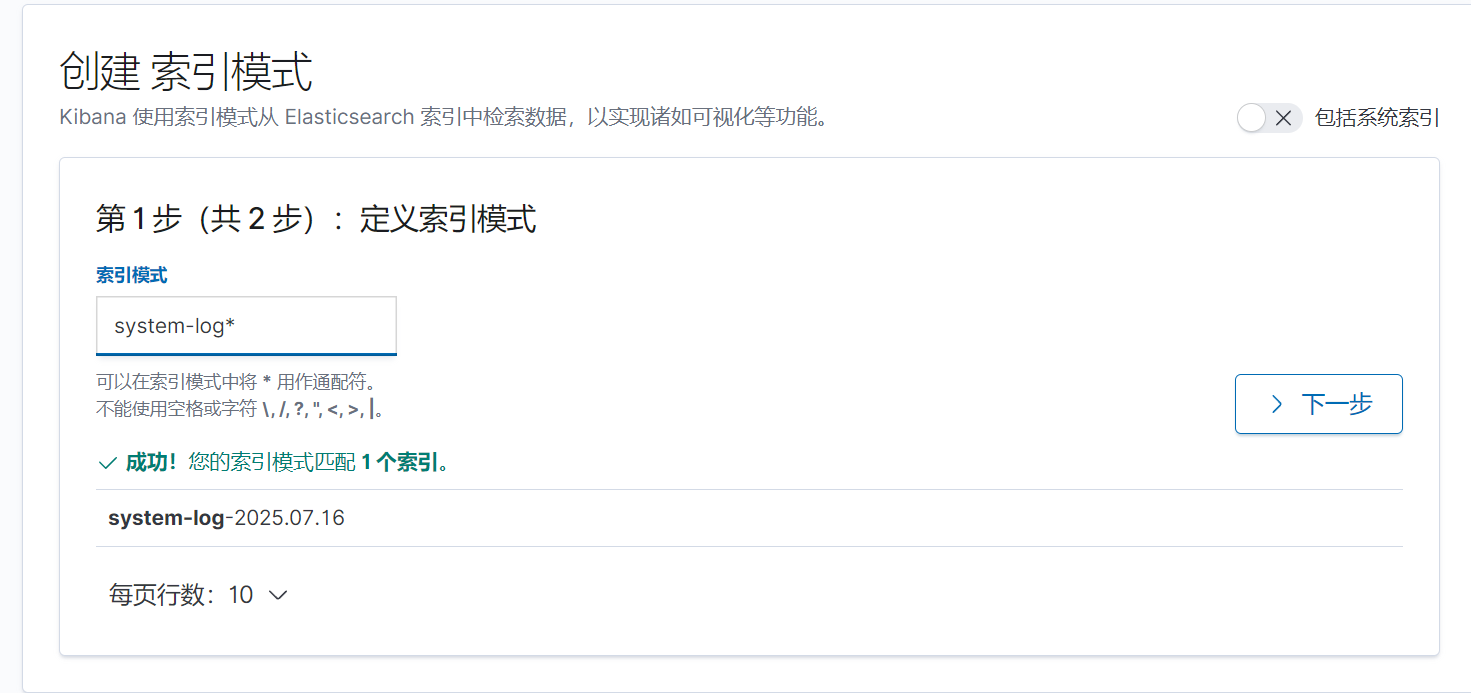
下一步,按時間戳進行篩選
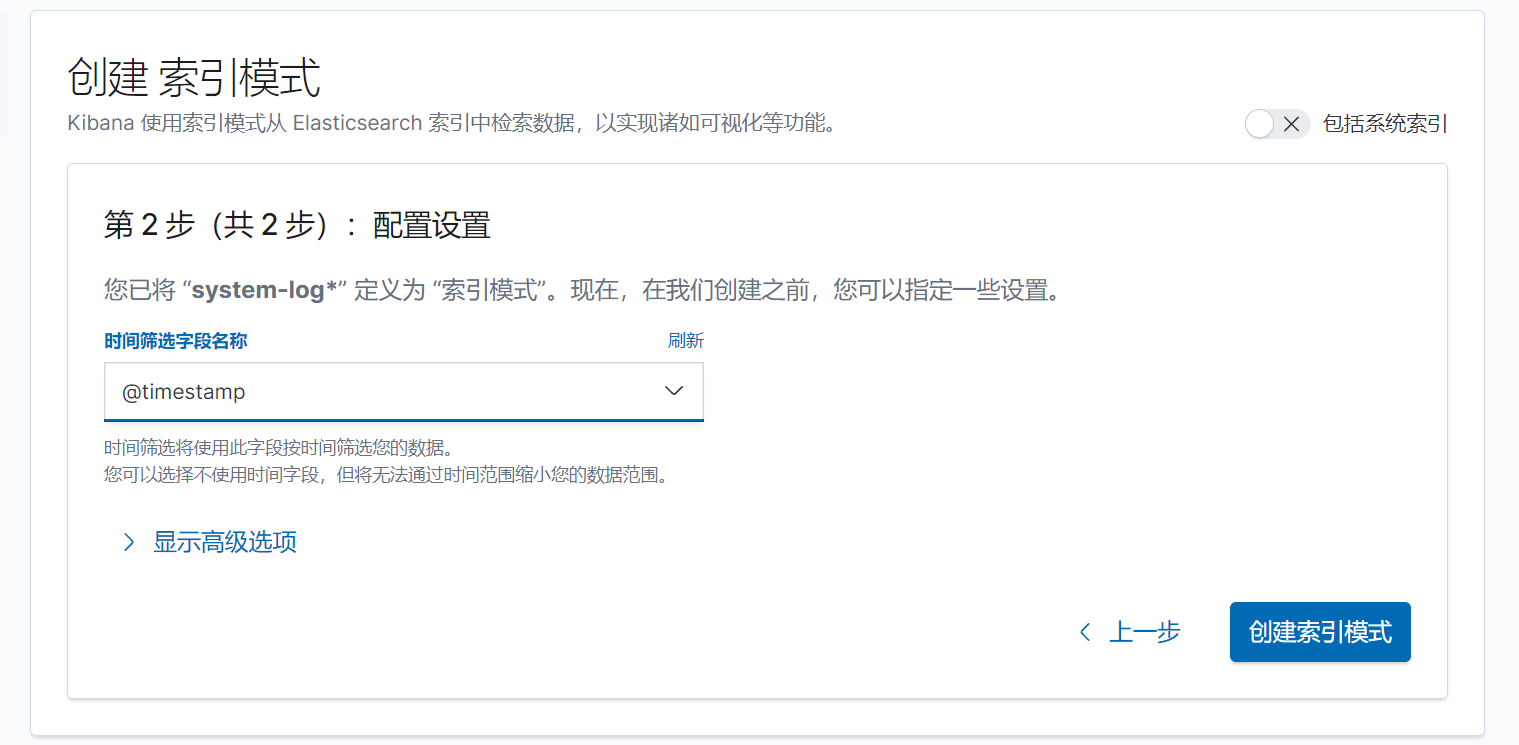
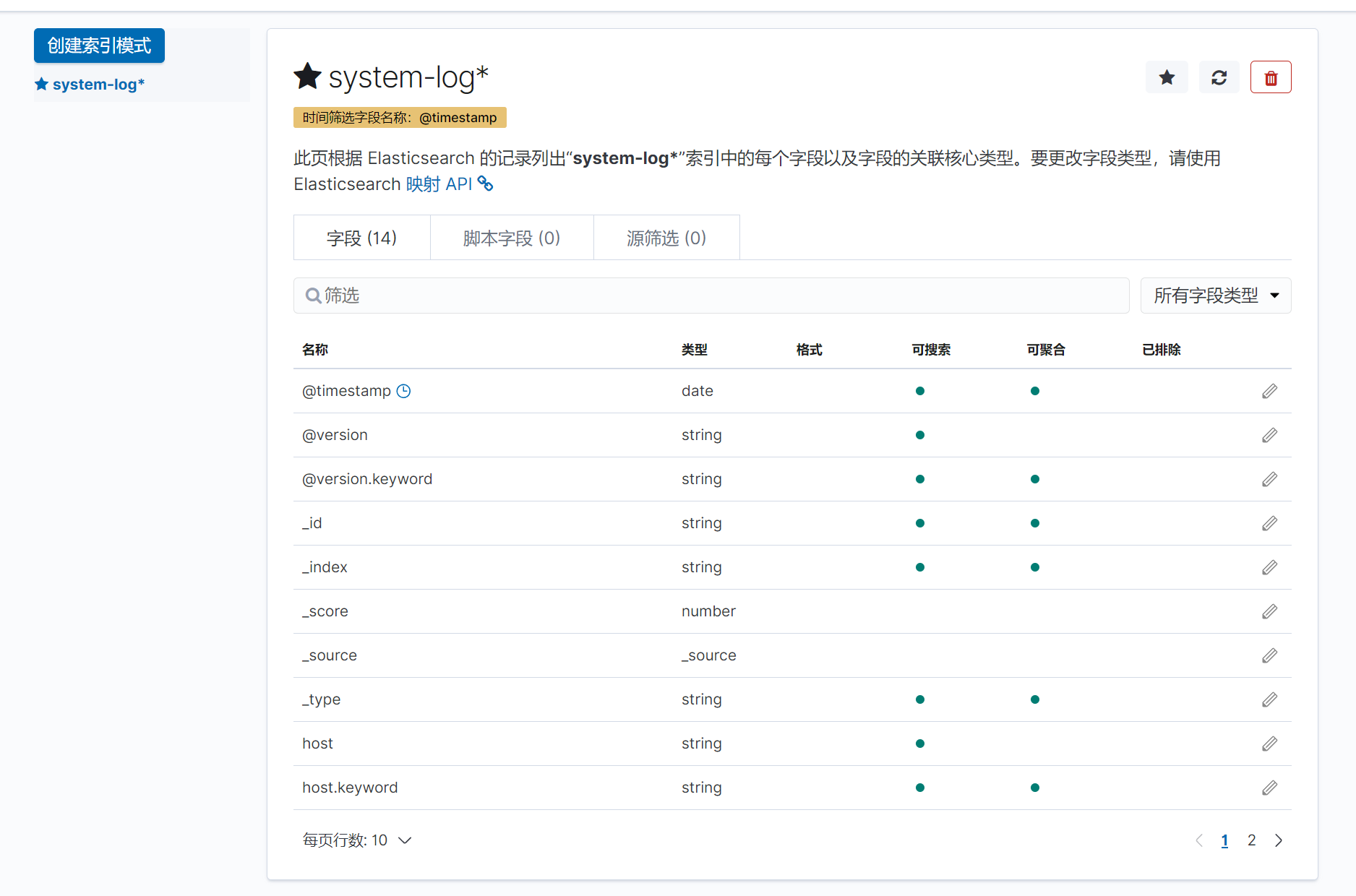
添加儀表盤 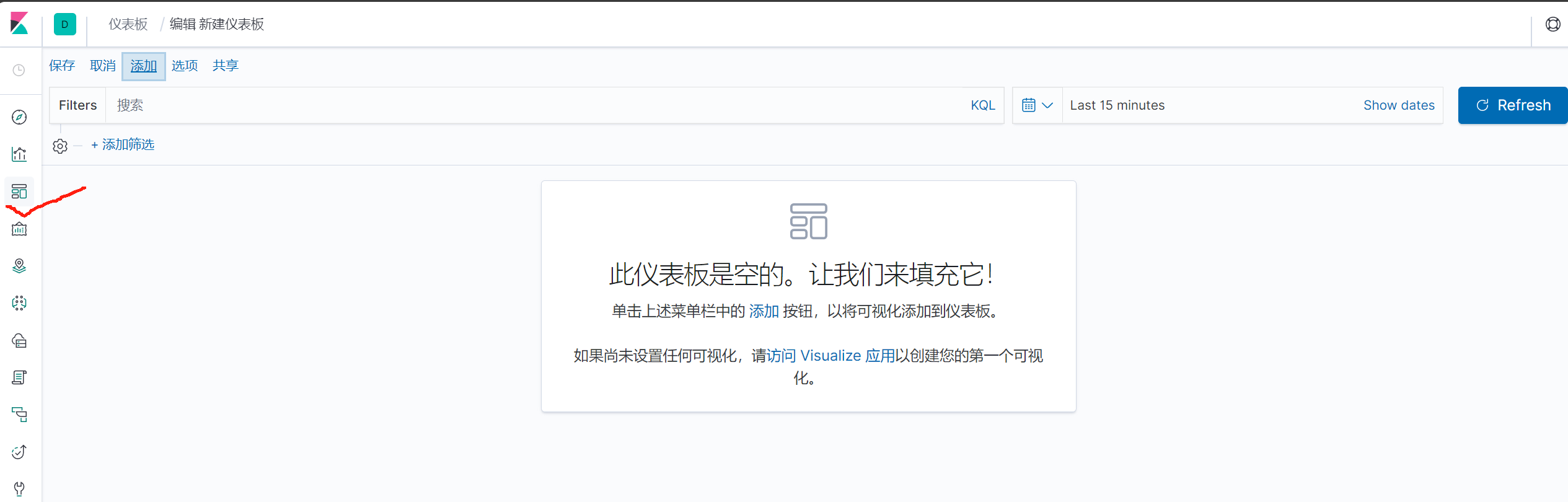
點擊左上角添加,點擊右邊添加可視化
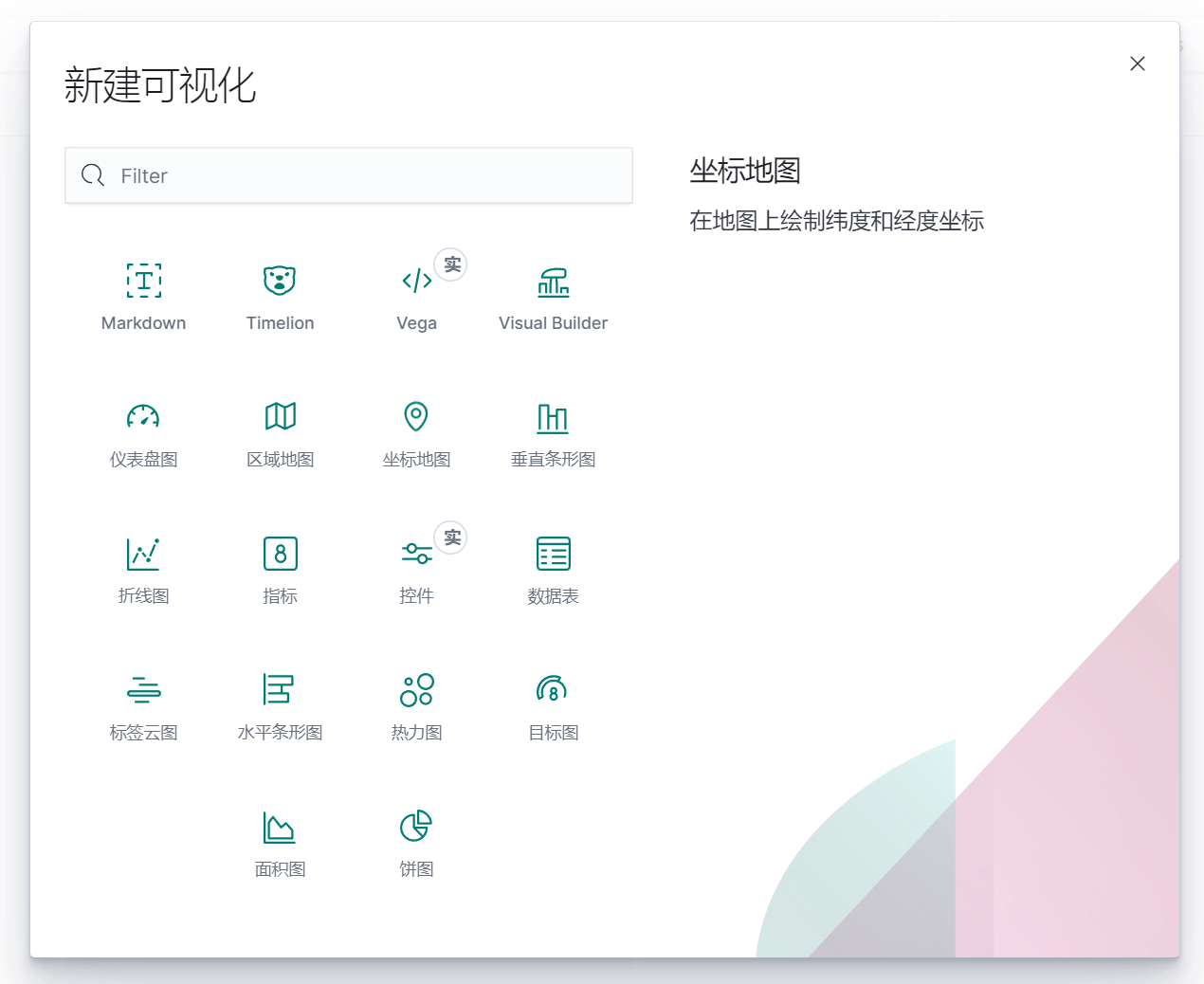
回到主頁有可視化和文字說明
七.總結
本節內容大致了解了Elasticsearch,logstash和kibana的相關內容,明白了ELK各個字母的含義以及下載安裝使用了對應的軟件,之后就可以使用這些來收集各個應用的日志來分析日志信息。








)






學術交流)



