文章目錄
- 5,事務
- 5.1Redis 事務不保證原子性的原因
- 5.2事務操作過程
- 5.3監控
- 6,SpringBoot整合Redis
- 6.1Redis客戶端
- 6.1.1Jedis簡單使用
- 6.1.2Lettuce&Jedis
- 6.2配置相關
- 6.3使用
- 6.3.1使用RedisTemplate
- 6.3.2Redis工具類
- 7,持久化RDB
- 7.1RDB持久化原理
- 7.2觸發機制
- save命令
- flushall命令
- bgsave命令
- 7.3優缺點
- 8,持久化AOF
- 8.1AOF持久化原理
- 8.2相關配置
- 8.3aof文件重寫
- 8.3優缺點
5,事務
Redis 事務雖然具備一次性、順序性、排他性(即事務中的命令會按順序執行,且執行期間不會被其他命令插入)。Redis的單條命令是保證原子性的,但是redis事務不能保證原子性。
Redis 事務的本質是一組命令的集合,其執行過程可概括為三個階段:
- 開啟事務(
MULTI):標記事務的開始,后續命令會被加入隊列而非立即執行。 - 命令入隊:所有輸入的命令(如
SET、HSET等)會按順序存入事務隊列,等待執行。 - 執行事務(
EXEC):一次性執行隊列中的所有命令,執行期間不會被其他客戶端的命令干擾。
5.1Redis 事務不保證原子性的原因
原子性的核心是 “要么全部成功,要么全部失敗”,但 Redis 事務不滿足這一點:
- 若命令語法錯誤(如命令不存在):在
EXEC執行前,Redis 會檢測到錯誤并拒絕執行事務,此時所有命令都不執行(類似 “全部失敗”)。 - 若命令邏輯錯誤(如對字符串執行
INCR):EXEC會正常執行其他命令,錯誤命令僅自身失敗,不會影響其他命令(即 “部分成功,部分失敗”)。
例如:
MULTI
SET key1 "123" // 成功
INCR key1 // 邏輯錯誤(字符串無法自增)
SET key2 "456" // 成功
EXEC
執行后,key1和key2都會被創建,僅INCR key1失敗,事務并未回滾,因此不滿足原子性。
5.2事務操作過程
- 開啟事務(
multi) - 命令入隊
- 執行事務(
exec)
所以事務中的命令在加入時都沒有被執行,直到提交時才會開始執行(Exec)一次性完成。
127.0.0.1:6379> multi # 開啟事務
OK
127.0.0.1:6379> set k1 v1 # 命令入隊
QUEUED
127.0.0.1:6379> set k2 v2 # ..
QUEUED
127.0.0.1:6379> get k1
QUEUED
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> keys *
QUEUED
127.0.0.1:6379> exec # 事務執行
1) OK
2) OK
3) "v1"
4) OK
5) 1) "k3"2) "k2"3) "k1"
取消事務(discurd)
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> DISCARD # 放棄事務
OK
127.0.0.1:6379> EXEC
(error) ERR EXEC without MULTI # 當前未開啟事務
127.0.0.1:6379> get k1 # 被放棄事務中命令并未執行
(nil)
事務錯誤
代碼語法錯誤(編譯時異常)所有的命令都不執行
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> error k1 # 這是一條語法錯誤命令
(error) ERR unknown command `error`, with args beginning with: `k1`, # 會報錯但是不影響后續命令入隊
127.0.0.1:6379> get k2
QUEUED
127.0.0.1:6379> EXEC
(error) EXECABORT Transaction discarded because of previous errors. # 執行報錯
127.0.0.1:6379> get k1
(nil) # 其他命令并沒有被執行
代碼邏輯錯誤 (運行時異常) **其他命令可以正常執行 ** >>> 所以不保證事務原子性
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> INCR k1 # 這條命令邏輯錯誤(對字符串進行增量)
QUEUED
127.0.0.1:6379> get k2
QUEUED
127.0.0.1:6379> exec
1) OK
2) OK
3) (error) ERR value is not an integer or out of range # 運行時報錯
4) "v2" # 其他命令正常執行# 雖然中間有一條命令報錯了,但是后面的指令依舊正常執行成功了。
# 所以說Redis單條指令保證原子性,但是Redis事務不能保證原子性。
5.3監控
悲觀鎖(Pessimistic Locking)
核心思想:總是假設最壞的情況,認為數據隨時可能被其他線程修改,因此在訪問數據前先加鎖,確保只有自己能操作數據。
樂觀鎖(Optimistic Locking)
核心思想:假設數據一般不會被其他線程修改,因此不上鎖,僅在更新數據時檢查是否有人在此期間修改過(使用版本號進行檢查)。
而Redis使用watch key監控指定數據,相當于樂觀鎖加鎖。監控某一key后,如果key在一個線程/客戶端A執行事務時,有另外一個客戶端/線程B對key進行修改,則執行A的事務失敗(全部失敗)。
并且Redis 的 WATCH 是一次性的,且第二次事務沒有重新執行 WATCH money。
案例一:成功案例
客戶端B在客戶端A的事務期間執行(multi之后和exec之前)。
-------------客戶端A--------------
127.0.0.1:6379[2]> set money 100
OK
127.0.0.1:6379[2]> set use 0
OK
127.0.0.1:6379[2]> watch money
OK
127.0.0.1:6379[2]> multi
OK
127.0.0.1:6379[2]> decrby money 20
QUEUED
127.0.0.1:6379[2]> incrby money 20
QUEUED
127.0.0.1:6379[2]> exec
(nil)
127.0.0.1:6379[2]> get money
"600"
127.0.0.1:6379[2]> get use
"0"
-------------客戶端B--------------
127.0.0.1:6379[2]> incrby money 500
(integer) 600
案例二:失敗案例
客戶端B在客戶端A的第二次事務期間執行(multi之后和exec之前)。這就是“Redis 的 WATCH 是一次性的,且第二次事務沒有重新執行 WATCH money。”
-------------客戶端A--------------
127.0.0.1:6379> set money 100
OK
127.0.0.1:6379> set use 0
OK
127.0.0.1:6379> watch money
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> decrby money 20
QUEUED
127.0.0.1:6379> incrby use 20
QUEUED
127.0.0.1:6379> exec
1) (integer) 80
2) (integer) 20
127.0.0.1:6379> get money
"80"
127.0.0.1:6379> get use
"20"
127.0.0.1:6379> multi
OK
127.0.0.1:6379> decrby money 20
QUEUED
127.0.0.1:6379> incrby use 20
QUEUED
127.0.0.1:6379> exec
1) (integer) 560
2) (integer) 40
-------------客戶端B--------------
127.0.0.1:6379> incrby money 500
(integer) 580
6,SpringBoot整合Redis
6.1Redis客戶端
什么是客戶端?在 Spring Boot 應用中,Redis 客戶端是指用于連接和操作 Redis 數據庫的工具庫。spring-boot-starter-data-redis作為官方提供的啟動器,默認集成了Lettuce作為 Redis 客戶端。
6.1.1Jedis簡單使用
使用Java來操作Redis,Jedis是Redis官方推薦使用的Java連接redis的客戶端。
-
導入依賴
<!--導入jredis的包--> <dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>3.2.0</version> </dependency> <!--fastjson--> <dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.70</version> </dependency> -
這里直接在springboot的測試類里測試了
@SpringBootTest public class One {@Testpublic void test() {Jedis jedis = new Jedis("127.0.0.1", 6379);String pong = jedis.ping();System.out.println(pong);}@Testpublic void test2() {Jedis jedis = new Jedis("127.0.0.1", 6379);jedis.select(2);JSONObject jsonObject = new JSONObject();jsonObject.put("hello", "world");jsonObject.put("name", "Selena");// 開啟事務Transaction multi = jedis.multi();String result = jsonObject.toJSONString();try {multi.set("user1", result);multi.set("user2", result);// 執行事務multi.exec();}catch (Exception e){// 放棄事務multi.discard();} finally {// 關閉連接System.out.println(jedis.get("user1"));System.out.println(jedis.get("user2"));jedis.close();}} }
6.1.2Lettuce&Jedis
在 Spring Boot 應用中,spring-boot-starter-data-redis默認使用 Lettuce 作為 Redis 客戶端,因為其依賴中包含lettuce-core包。若要切換為 Jedis,需排除 Lettuce 并引入 Jedis 依賴。
| 特性 | Lettuce | Jedis |
|---|---|---|
| 連接模型 | 基于 Netty 的響應式、非阻塞 I/O,支持異步和多路復用 | 基于傳統 BIO(阻塞 I/O),每次操作需新建連接 |
| 線程安全性 | 線程安全,可多線程共享連接實例 | 線程不安全,需通過連接池管理連接 |
| 資源消耗 | 使用 Netty 事件循環,資源消耗少,適合長連接 | 頻繁創建 / 銷毀連接,資源消耗大,依賴連接池降開銷 |
| 功能特性 | 支持響應式編程(Reactive Redis API)、集群和哨兵模式 | 提供傳統同步 API,適合簡單業務場景 |
| 適用場景 | 高并發、異步操作、響應式應用(如 Spring WebFlux) | 簡單同步操作、傳統 Servlet 應用 |
6.2配置相關
RedisProperties 是 Spring Boot 中用于配置 Redis 連接信息的核心配置類,位于 org.springframework.boot.autoconfigure.data.redis 包下。它通過 @ConfigurationProperties 注解綁定 spring.redis 前綴的配置項,讓你可以在 application.properties 或 application.yml 中輕松配置 Redis 連接參數。
此外,RedisAutoConfiguration這個類,顧名思義就是Redis的自動化配置。在這個類中,會引入LettuceConnectionConfiguration 和 JedisConnectionConfiguration 兩個配置類,分別對應lettuce和jedis兩個客戶端。而這個兩個類上都是用了ConditionalOnClass注解來進行判斷是否加載。
而由于我們的項目自動引入了lettuce-core,而沒有引入jedis相關依賴,所以LettuceConnectionConfiguration這個類的判斷成立會被加載,而Jedis的判斷不成立,所以不會加載。進而lettuce的配置生效,所以我們在使用的使用, 默認就是lettuce的客戶端。
配置文件(基礎配置):
server: # 服務器配置port: 8080servlet:context-path: /
spring:# redis 配置redis:# 地址host: localhost# 端口,默認為6379port: 6379# 數據庫索引database: 0# 密碼password:# 連接超時時間timeout: 10s
但是有的時候我們想要給我們的redis客戶端配置上連接池。就像我們連接mysql的時候,也會配置連接池一樣,目的就是增加對于數據連接的管理,提升訪問的效率,也保證了對資源的合理利用。
如果使用的是jedis,就把lettuce換成jedis(同時要注意依賴也是要換的)。
spring:# redis 配置redis:# 地址host: localhost# 端口,默認為6379port: 6379# 數據庫索引database: 0# 密碼password:# 連接超時時間timeout: 10slettuce:pool:# 連接池中的最小空閑連接min-idle: 0# 連接池中的最大空閑連接max-idle: 8# 連接池的最大數據庫連接數max-active: 8# #連接池最大阻塞等待時間(使用負值表示沒有限制)max-wait: -1ms
但是僅僅這在配置文件中加入,其實連接池是不會生效的。還少了最關鍵的一步,就是要導入一個依賴,不導入的話,這么配置也沒有用。
<dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId>
</dependency>
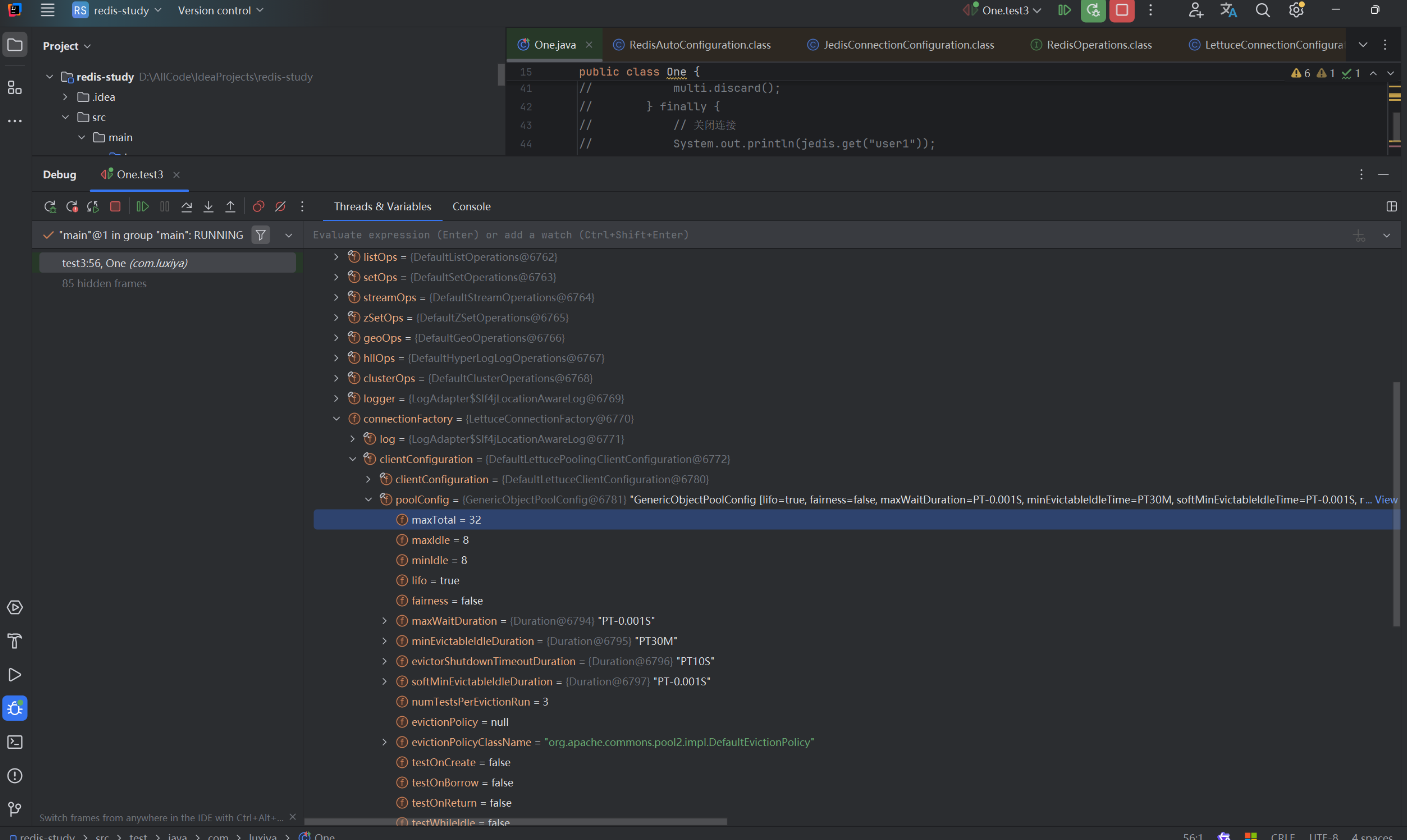
之后,連接池才會生效。我們可以做一個對比。 在導包前后,觀察RedisTemplate對象的值就可以看出來。
添加依賴前:
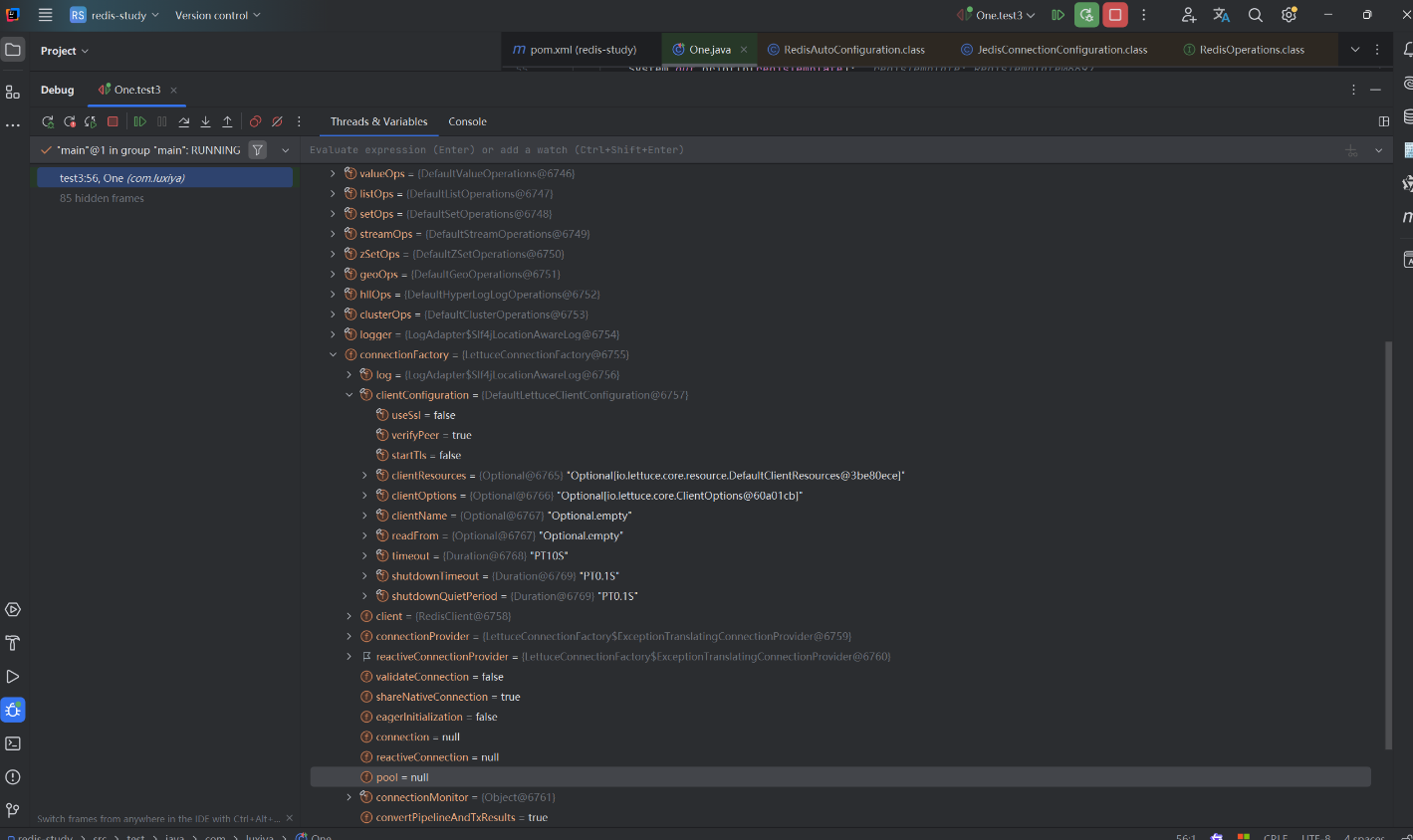
添加依賴后:
6.3使用
6.3.1使用RedisTemplate
簡單案例:
@SpringBootTest
public class RedisTemplateTest {@Autowiredprivate RedisTemplate redisTemplate;@Testpublic void testRedisTemplate1() {redisTemplate.opsForValue().set("name", "saber");}
}
在 Spring 的RedisTemplate中,opsForValue()是用于獲取操作 Redis 字符串(String)類型數據的操作接口,通過它能執行一系列針對字符串的操作。除了opsForValue()外,RedisTemplate還提供了opsForHash()(操作哈希類型數據)、opsForList()(操作列表類型數據 )、opsForSet()(操作集合類型數據 )和opsForZSet()(操作有序集合類型數據)等方法,方便開發者針對不同的 Redis 數據類型進行操作。
拿opsForValue()舉例,其常用方法
set(String key, Object value):將鍵值對存儲到 Redis 中。如果對應的 key 已經存在,新值會覆蓋舊值。get(String key):根據給定的 key,從 Redis 中獲取對應的字符串值,如果 key 不存在,則返回null。set(String key, Object value, long timeout, TimeUnit unit):存儲鍵值對,并設置該鍵值對的過期時間。increment(String key, long delta):對存儲在 Redis 中的數字類型的 key 進行自增操作,delta表示自增的步長,返回自增后的值。若 key 不存在,會將其初始化為delta的值。decrement(String key, long delta):對存儲在 Redis 中的數字類型的 key 進行自減操作,delta表示自減的步長,返回自減后的值。
6.3.2Redis工具類
Redis工具類-CSDN博客
7,持久化RDB
7.1RDB持久化原理
RDB 是 Redis 默認的持久化方式,其核心機制是:
- 定期執行:Redis 在指定時間間隔內(如 5 分鐘),將內存中的數據快照保存為二進制文件(默認名為
dump.rdb可以通過配置文件修改)。 - fork 子進程:執行快照時,Redis 主進程會
fork一個子進程,由子進程負責將數據寫入磁盤,主進程繼續處理客戶端請求。 - 全量復制:RDB 文件包含某一時刻 Redis 的全部數據,恢復時直接加載整個文件。
fork是操作系統提供的一個系統調用,用于創建一個與父進程幾乎完全相同的子進程。RDB 持久化需要將內存中的全量數據寫入磁盤,如果由主線程直接執行,會導致長時間阻塞(尤其數據量大時),影響 Redis 的響應性能。
在進行 RDB 的時候,redis 的主線程是不會做 io 操作的,主線程會 fork 一個子線程來完成該操作;
- Redis 調用forks。同時擁有父進程和子進程。
- 子進程將數據集寫入到一個臨時 RDB 文件中。
- 當子進程完成對新 RDB 文件的寫入時,Redis 用新 RDB 文件替換原來的 RDB 文件,并刪除舊的 RDB 文件。
這種工作方式使得 Redis 可以從寫時復制(copy-on-write)機制中獲益(因為是使用子進程進行寫操作,而父進程依然可以接收來自客戶端的請求。)
1,寫時復制(Copy-On-Write):初始時,父子進程共享同一塊物理內存;當父進程或子進程修改數據時,才會復制被修改的內存頁,避免了全量復制的性能消耗。
2,什么是 “臨時的 RDB 文件”?
在 RDB 持久化過程中,子進程并非直接寫入最終的 RDB 文件(如默認的dump.rdb),而是先將內存數據寫入一個臨時文件(例如命名為temp-xxx.rdb)。
臨時文件的作用是:
- 保證數據完整性:如果子進程在寫入過程中意外崩潰(如磁盤滿、進程被 kill),臨時文件會被丟棄,不會影響原有的 RDB 文件(原文件仍可用于恢復數據)。
- 避免部分寫入:如果直接寫入目標文件,中途失敗會導致目標文件損壞,而臨時文件可確保只有當全量數據寫入完成后,才會成為有效的 RDB 文件。
3,替換過程是怎樣的?
當子進程成功將全量數據寫入臨時文件后,Redis 會執行原子性的文件替換操作:
- 子進程完成寫入后,通知主進程 “臨時文件已就緒”。
- 主進程通過操作系統的rename(或類似)系統調用,將臨時文件重命名為目標 RDB 文件名(如dump.rdb)。
- 例如:
temp-xxx.rdb→dump.rdb。
- 例如:
- 替換完成后,刪除舊的
dump.rdb文件(如果存在)。這意味著舊的數據會被新的數據覆蓋。
7.2觸發機制
- save的規則(配置文件中設值,在快照模塊,如下)滿足的情況下,會自動觸發rdb原則
- 執行flushall命令,也會觸發我們的rdb原則
- 退出redis,也會自動產生rdb文件
配置文件相關內容
# 當至少1個key被修改且時間超過900秒(15分鐘)時,執行一次快照
save 900 1
# 當至少10個key被修改且時間超過300秒(5分鐘)時,執行一次快照
save 300 10
# 當至少10000個key被修改且時間超過60秒時,執行一次快照
save 60 10000# RDB文件保存路徑
dir ./# RDB文件名
dbfilename dump.rdb# 啟用壓縮(可能影響性能)
rdbcompression yes
save命令
使用 save 命令,會立刻對當前內存中的數據進行持久化 ,但是會阻塞,也就是不接受其他操作了;
由于 save 命令是同步命令,會占用Redis的主進程。若Redis數據非常多時,save命令執行速度會非常慢,阻塞所有客戶端的請求。
flushall命令
flushall 命令也會觸發持久化 ;
bgsave命令
bgsave 是異步進行,進行持久化的時候,redis 還可以將繼續響應客戶端請求 ;配置文件中的save規則本質上也是bgsave,異步執行數據持久化。
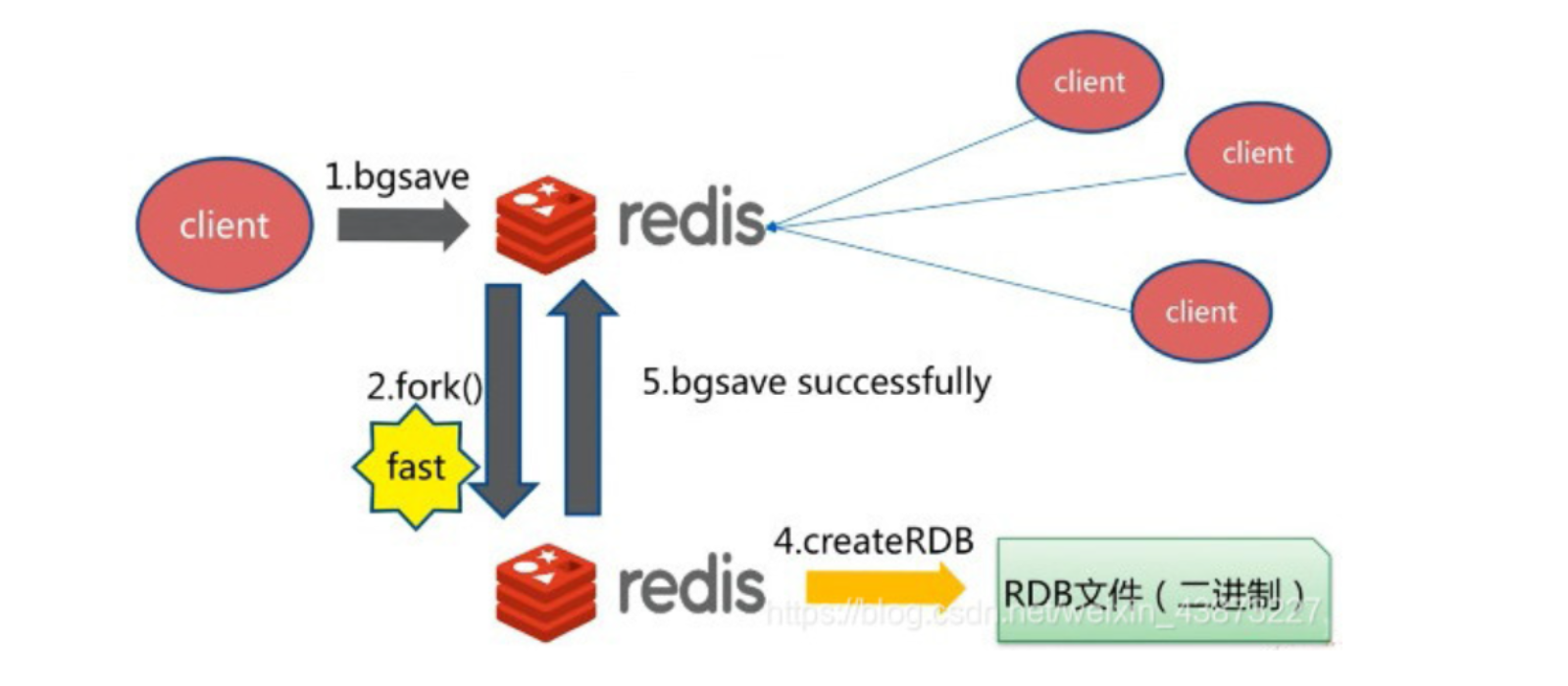
bgsave和save對比
| 命令 | save | bgsave |
|---|---|---|
| IO類型 | 同步 | 異步 |
| 阻塞? | 是 | 是(阻塞發生在fock(),通常非常快) |
| 復雜度 | O(n) | O(n) |
| 優點 | 不會消耗額外的內存 | 不阻塞客戶端命令 |
| 缺點 | 阻塞客戶端命令 | 需要fock子進程,消耗內存 |
7.3優缺點
優點:
- 適合大規模的數據恢復,相比AOF恢復速度快。
- 對數據的完整性要求不高
缺點:
- 需要一定的時間間隔進行操作,如果redis意外宕機了,這個最后一次修改的數據就沒有了,破快數據完整性。
- fork進程的時候,會占用一定的內容空間。
8,持久化AOF
8.1AOF持久化原理
Append Only File
將我們所有的命令都記錄下來,恢復的時候就把這個文件全部再執行一遍。
AOF 通過追加寫命令到日志文件的方式實現持久化:
- 命令實時記錄:Redis 執行寫命令后,會將命令追加到 AOF 緩沖區(內存)。
- 緩沖區同步到磁盤:根據配置的同步策略(
fsync),將緩沖區中的命令寫入磁盤 AOF 文件。 - 文件重寫(AOF Rewrite):定期通過
BGREWRITEAOF命令對 AOF 文件進行瘦身,去除冗余命令。
8.2相關配置
如果要使用AOF,需要修改配置文件:
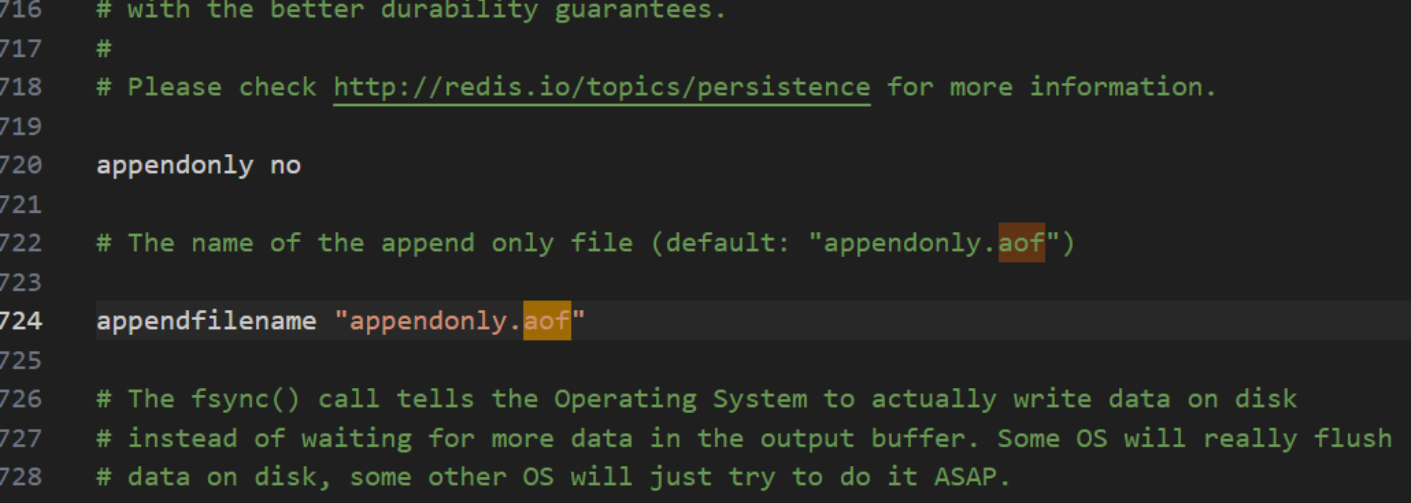
appendonly no yes則表示啟用AOF
默認是不開啟的,我們需要手動配置,然后重啟redis,就可以生效了!
相關配置:
appendonly yes # 默認是不開啟aof模式的,默認是使用rdb方式持久化的,在大部分的情況下,rdb完全夠用
appendfilename "appendonly.aof"# appendfsync always # 每次修改都會sync 消耗性能
appendfsync everysec # 每秒執行一次 sync 可能會丟失這一秒的數據
# appendfsync no # 不執行 sync ,這時候操作系統自己同步數據,速度最快# AOF文件重寫觸發條件
auto-aof-rewrite-percentage 100 # 當前AOF文件大小超過上次重寫后大小的100%時觸發
auto-aof-rewrite-min-size 64mb # AOF文件最小達到64MB時才考慮重寫
8.3aof文件重寫
重寫的作用:通過生成一個只包含當前數據庫最新狀態的 AOF 文件,替代舊文件,大幅減小文件體積。隨著 Redis 運行,AOF 文件會不斷追加寫命令,導致文件體積膨脹,例如:對同一 key 多次修改(如SET k 1 → SET k 2 → SET k 3),舊命令變得冗余。就是舍去大量的中間狀態,并記錄當前數據庫最新的狀態。
觸發方式
-
自動觸發:當滿足以下兩個條件時,Redis 自動觸發重寫:
auto-aof-rewrite-percentage 100 # 當前AOF文件大小超過上次重寫后大小的100% auto-aof-rewrite-min-size 64mb # AOF文件最小達到64MB才考慮重寫 -
手動觸發:執行命令:
redis-cli BGREWRITEAOF
重寫執行的流程。
- 主線程 fork 子進程
- 主線程通過
fork()創建子進程,子進程獲得當前內存數據的副本。 - 關鍵特性:寫時復制(Copy-On-Write),父子進程共享內存,僅在修改數據時復制內存頁,避免全量內存拷貝。
- 主線程通過
- 子進程生成新 AOF 文件
- 子進程遍歷內存中的所有鍵值對,生成對應的寫命令序列(如
SET k v、HSET hash f v)。 - 新 AOF 文件僅包含重建當前數據庫所需的最小命令集,不包含任何冗余命令。
- 子進程遍歷內存中的所有鍵值對,生成對應的寫命令序列(如
- 處理增量寫命令
- 在子進程重寫期間,主線程繼續處理客戶端請求,并將新的寫命令同時追加到:
- 舊 AOF 文件:確保當前持久化過程不受影響。
- AOF 重寫緩沖區:保存重寫期間的增量命令。
- 在子進程重寫期間,主線程繼續處理客戶端請求,并將新的寫命令同時追加到:
- 替換舊文件
- 子進程完成重寫后,向主線程發送信號。
- 主線程將 AOF 重寫緩沖區中的增量命令追加到新 AOF 文件中。
- 主線程使用原子性的
rename()系統調用,將新 AOF 文件替換舊文件。
8.3優缺點
優點
- 每一次修改都會同步,文件的完整性會更加好
- 每秒同步一次,可能會丟失一秒的數據
- 從不同步,效率最高
缺點
- 相對于數據文件來說,aof遠遠大于rdb,修復速度比rdb慢!
- Aof運行效率也要比rdb慢,所以我們redis默認的配置就是rdb持久化







)
)




+實例測試)





