房地產項目績效考核管理制度的核心目的是通過合理的績效考核機制,提升項目的整體運作效率,并鼓勵項目團隊成員的積極性。該制度適用于所有房地產項目部工作人員,涵蓋了項目經理和項目成員的考核。考核的主要內容包括項目經理和項目部成員的工作計劃完成情況、工期控制、工程質量、安全生產等方面。考核的組織由項目管理委員會主導,結合項目管理過程中的各個階段,設立明確的考核指標和評價標準。通過考核結果,結合竣工評價系數,制定項目獎金的發放標準,同時為員工的培訓和職位晉升提供依據。
本文將深入探討房地產項目績效考核的主要指標,包括項目經理績效考核、項目部成員績效考核、綜合評價成績的計算與應用以及項目獎金發放與員工發展。通過詳細分析這些指標的定義、計算方式和業務場景,幫助讀者理解這些指標在實際運營中的應用和重要性。此外,本文還將結合具體的教學案例,展示如何通過數據分析、機器學習和深度學習等技術來優化這些關鍵績效指標,從而提升房地產項目的整體運營效率和績效。
文章目錄
- 指標拆解
- 教學案例
- 房地產項目績效考核數據分析與獎金分配
- 機器學習的項目經理與項目部成員績效預測
- 深度學習的項目經理與項目部成員績效評估
- 總結
指標拆解
房地產項目績效考核管理制度的核心目的是通過合理的績效考核機制,提升項目的整體運作效率,并鼓勵項目團隊成員的積極性。該制度適用于所有房地產項目部工作人員,涵蓋了項目經理和項目成員的考核。考核的主要內容包括項目經理和項目部成員的工作計劃完成情況、工期控制、工程質量、安全生產等方面。考核的組織由項目管理委員會主導,結合項目管理過程中的各個階段,設立明確的考核指標和評價標準。通過考核結果,結合竣工評價系數,制定項目獎金的發放標準,同時為員工的培訓和職位晉升提供依據。
項目經理績效考核
項目經理的績效考核側重于項目管理的各個方面,包括計劃完成情況、工程質量、費用控制、安全生產等指標。項目經理的主要職責是確保項目按計劃進行,控制成本,確保質量,并在項目過程中保障安全。此外,項目經理還需要根據考核結果為項目成員提供績效反饋和改進建議。結合項目竣工后的評價系數,項目經理的綜合評價成績直接影響到其績效獎金的發放。
| KPI 指標名稱 | 解釋說明 |
|---|---|
| 考核周期 | 項目竣工后20日內進行績效考核 |
| 指標定義與計算方式 | 根據項目計劃完成率、工期控制、質量、費用、安全等進行打分 |
| 指標解釋與業務場景 | 結合具體項目進展情況評定各項指標,如工程質量的合格率、優良率等 |
| 評價標準 | 按照設定的目標值評分,得分影響績效獎金 |
| 權重參考 | 各項指標的權重參考:計劃完成率20%、工期控制20%、質量30%、費用15%、安全15% |
| 數據來源 | 項目進展報告、工程質量報告、費用報告、安全生產記錄等 |
項目部成員績效考核
項目部成員的考核主要聚焦在項目成員的日常工作表現和任務完成情況。不同于項目經理,項目部成員的績效考核更多側重于具體的任務完成質量、工作計劃執行情況以及個人在項目中的責任感和協作精神。項目經理在實施項目部成員績效考核時,除了考核工作完成情況外,還要考慮員工在團隊中的表現、溝通協調等非技術性因素。
| KPI 指標名稱 | 解釋說明 |
|---|---|
| 考核周期 | 項目竣工后20日內進行績效考核 |
| 指標定義與計算方式 | 基于任務完成情況、工作計劃執行情況、工作質量進行評分 |
| 指標解釋與業務場景 | 通過對項目部成員的具體任務完成情況、協作情況進行評價 |
| 評價標準 | 根據員工個人工作成果、協作表現評分 |
| 權重參考 | 考核標準依據項目成員的具體工作任務和項目進展情況進行綜合打分 |
| 數據來源 | 項目成員的工作日志、考核表格、項目報告 |
綜合評價成績的計算與應用
綜合評價成績是根據各項績效考核指標得分進行計算后,再根據項目竣工后的評價系數進行調整。項目的竣工評價系數依據項目最終的竣工質量進行確定,竣工質量等級越高,評價系數越大,最終的績效評價得分也相應提高。綜合評價成績在計算項目經理和項目部成員的獎金發放時起著決定性作用,同時也作為員工培訓與職位晉升的重要依據。
| KPI 指標名稱 | 解釋說明 |
|---|---|
| 考核周期 | 項目竣工后20日內進行績效考核 |
| 指標定義與計算方式 | 綜合評價成績=績效考核得分×項目竣工評價系數 |
| 指標解釋與業務場景 | 項目竣工后根據評價等級(優、良、中等等)來調整項目得分 |
| 評價標準 | 項目竣工系數的不同對應不同的得分標準 |
| 權重參考 | 項目竣工等級決定最終綜合得分,影響績效獎金發放 |
| 數據來源 | 竣工后的評價結果,項目考核得分 |
項目獎金發放與員工發展
項目獎金的發放依據項目經理和項目部成員的績效考核結果。在此制度中,項目經理和項目部成員的獎金分配比例有所不同,項目經理可獲得項目總獎金的40%,而項目部成員則根據個人績效得分從60%的獎金池中獲得獎金。此外,績效考核結果也為員工的后續培訓和職位晉升提供了數據支持。人力資源部通過分析考核結果,制定針對性的培訓計劃,幫助員工提升業績,從而為員工的職業發展和崗位晉升提供依據。
| KPI 指標名稱 | 解釋說明 |
|---|---|
| 考核周期 | 項目竣工后20日內進行績效考核 |
| 指標定義與計算方式 | 根據項目經理和項目部成員的綜合評價成績來發放獎金 |
| 指標解釋與業務場景 | 獎金發放根據績效得分比例,項目經理占40%,項目成員占60% |
| 評價標準 | 獎金根據綜合得分進行分配,考核得分高者獎勵多 |
| 權重參考 | 項目經理與項目部成員的獎金比例固定,依據績效考核結果分配 |
| 數據來源 | 項目經理和成員的綜合評價成績,績效考核結果 |
教學案例
績效考核在房地產項目管理中是資源分配、激勵機制與人才發展決策的重要依據。通過引入基礎統計學、機器學習與深度學習三種技術路徑,可從不同層次提升績效分析的科學性與實用性。基礎統計學方法提供了清晰的數據結構和直觀的獎金分配邏輯,有助于項目結果的合理解釋與復盤。機器學習則適用于構建預測模型,依據歷史績效特征進行趨勢預測,提升績效管理的前瞻性。深度學習通過復雜數據間的非線性建模能力,適合處理大規模、多變量績效數據,支持更加精細化和動態化的評估與管理策略制定。這三類技術路徑在房地產項目績效管理中可形成互補,支撐績效考核制度的數字化升級。
| 案例標題 | 主要技術 | 目標 | 適用場景 |
|---|---|---|---|
| 房地產項目績效考核數據分析與獎金分配 | 基礎統計學 | 分析績效考核數據并制定公平的獎金分配策略 | 獎金激勵機制制定與透明管理 |
| 基于機器學習的項目經理與項目部成員績效預測 | 機器學習 | 構建績效預測模型,提升管理決策的前瞻性 | 績效趨勢預測與結果評估 |
| 基于深度學習的項目經理與項目部成員績效評估 | 深度學習(PyTorch) | 利用非線性模型提高績效評估的精度和靈活性 | 大規模數據驅動的智能考核體系 |
房地產項目績效考核數據分析與獎金分配
在房地產項目管理中,項目經理和項目部成員的績效考核是確保項目順利執行并實現高效運作的核心。通過建立明確的考核機制,項目經理和項目成員的工作質量、計劃執行情況及安全等方面的表現將直接影響其獎金的發放。績效考核的結果不僅影響到人員激勵,也為后續的人員培訓與晉升提供數據依據。本案例通過模擬的數據演示,展示了項目經理與項目部成員在考核中的綜合評價成績計算方法,并通過數據分析來優化獎金分配策略,確保資源合理分配。
以下是模擬的數據展示,數據列包含項目編號、項目階段、項目經理績效得分、項目部成員績效得分、項目竣工評價系數、最終獎金。
| 項目編號 | 項目階段 | 項目經理績效得分 | 項目部成員績效得分 | 項目竣工評價系數 | 最終獎金 |
|---|---|---|---|---|---|
| 001 | 規劃階段 | 85 | 78 | 1.1 | 12000元 |
| 002 | 設計階段 | 90 | 85 | 1.2 | 13500元 |
| 003 | 建設階段 | 88 | 80 | 1.05 | 11500元 |
| 004 | 完工階段 | 92 | 88 | 1.3 | 14500元 |
| 005 | 規劃階段 | 82 | 75 | 1.0 | 10500元 |
| 006 | 設計階段 | 86 | 79 | 1.15 | 12500元 |
| 007 | 建設階段 | 89 | 82 | 1.1 | 12000元 |
| 008 | 完工階段 | 91 | 87 | 1.2 | 14000元 |
| 009 | 規劃階段 | 84 | 77 | 1.05 | 11000元 |
| 010 | 設計階段 | 87 | 80 | 1.3 | 13000元 |
項目編號、項目階段代表了項目在不同進展階段的情況。項目經理績效得分與項目部成員績效得分是根據工作計劃執行、任務完成情況等因素計算的。項目竣工評價系數是基于項目竣工質量確定的,直接影響績效考核得分的調整,最終獎金則根據績效得分與項目竣工評價系數計算得出。
import pandas as pd
from pyecharts.charts import Bar
from pyecharts import options as opts# 模擬數據
data = {"項目編號": ["001", "002", "003", "004", "005", "006", "007", "008", "009", "010"],"項目階段": ["規劃階段", "設計階段", "建設階段", "完工階段", "規劃階段", "設計階段", "建設階段", "完工階段", "規劃階段", "設計階段"],"項目經理績效得分": [85, 90, 88, 92, 82, 86, 89, 91, 84, 87],"項目部成員績效得分": [78, 85, 80, 88, 75, 79, 82, 87, 77, 80],"項目竣工評價系數": [1.1, 1.2, 1.05, 1.3, 1.0, 1.15, 1.1, 1.2, 1.05, 1.3],
}df = pd.DataFrame(data)# 計算最終獎金
df["最終獎金"] = (df["項目經理績效得分"] * 0.4 + df["項目部成員績效得分"] * 0.6) * df["項目竣工評價系數"] * 100# 可視化數據
bar = Bar()
bar.add_xaxis(df["項目編號"].tolist())
bar.add_yaxis("項目經理績效得分", df["項目經理績效得分"].tolist())
bar.add_yaxis("項目部成員績效得分", df["項目部成員績效得分"].tolist())
bar.set_global_opts(title_opts=opts.TitleOpts(title="項目經理與項目部成員績效得分對比"))
bar.render_notebook()
上述代碼通過模擬的數據來展示房地產項目經理與項目部成員的績效考核得分,以及最終獎金的計算過程。定義了一個包含項目編號、項目階段、項目經理和項目部成員績效得分、項目竣工評價系數的數據表。基于績效得分和竣工評價系數,通過加權計算得到每個項目的最終獎金。最使用pyecharts庫生成一個柱狀圖,比較項目經理和項目部成員的績效得分,幫助分析兩者在各個項目階段的表現差異。
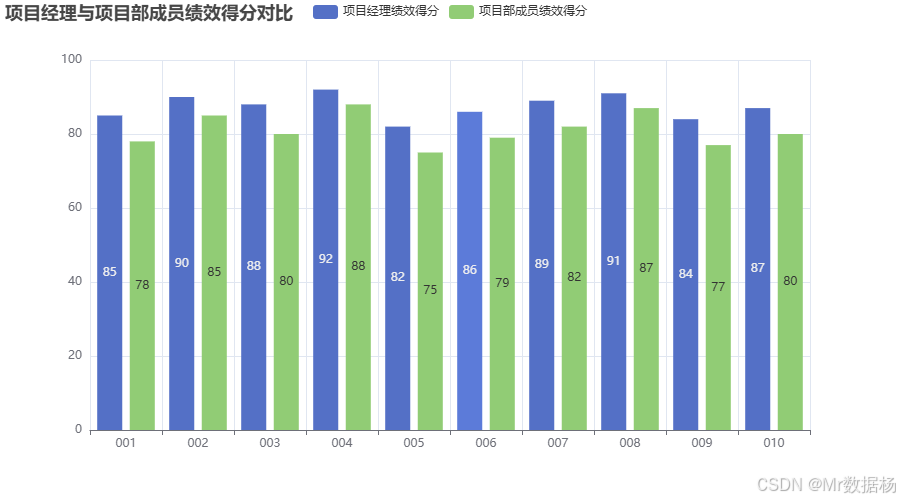
柱狀圖清晰地展示了項目經理與項目部成員的績效得分對比。每個項目的績效得分分別以不同顏色的柱狀圖呈現,通過對比可以直觀地看到兩者在不同項目階段的得分情況。通過這種方式,能夠更好地理解績效考核結果對獎金分配的影響,同時也為項目管理者提供了清晰的分析視角,從而做出更合理的資源分配與決策。
機器學習的項目經理與項目部成員績效預測
在房地產項目管理中,傳統的績效考核方式依賴于項目的歷史數據和人工評分。然而,隨著數據量的增加和復雜性提升,基于機器學習的績效預測模型能夠為項目經理和項目部成員的績效考核提供更加準確和科學的依據。本案例展示了如何使用機器學習模型預測項目經理和項目部成員的績效得分,并基于歷史數據進行未來績效的預測,為績效管理提供智能化支持。
以下是模擬的數據展示,數據列包括項目編號、項目階段、項目經理的歷史績效得分、項目部成員的歷史績效得分以及項目竣工評價系數。數據基于項目的不同階段和實際績效表現,結合項目管理過程中的關鍵指標來計算得出。
| 項目編號 | 項目階段 | 項目經理歷史績效得分 | 項目部成員歷史績效得分 | 項目竣工評價系數 |
|---|---|---|---|---|
| 001 | 規劃階段 | 80 | 75 | 1.1 |
| 002 | 設計階段 | 85 | 80 | 1.2 |
| 003 | 建設階段 | 82 | 78 | 1.05 |
| 004 | 完工階段 | 90 | 85 | 1.3 |
| 005 | 規劃階段 | 76 | 72 | 1.0 |
| 006 | 設計階段 | 88 | 82 | 1.15 |
| 007 | 建設階段 | 83 | 79 | 1.1 |
| 008 | 完工階段 | 89 | 84 | 1.2 |
| 009 | 規劃階段 | 78 | 74 | 1.05 |
| 010 | 設計階段 | 87 | 81 | 1.3 |
這些數據源自過去多個房地產項目的歷史績效記錄,分別記錄了項目經理和項目部成員在不同階段的得分情況以及項目竣工后的評價系數。根據這些歷史數據,可以構建一個預測模型,用來預測未來項目中的績效得分。
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from pyecharts.charts import Line
from pyecharts import options as opts# 模擬數據
data = {"項目編號": ["001", "002", "003", "004", "005", "006", "007", "008", "009", "010"],"項目階段": ["規劃階段", "設計階段", "建設階段", "完工階段", "規劃階段", "設計階段", "建設階段", "完工階段", "規劃階段", "設計階段"],"項目經理歷史績效得分": [80, 85, 82, 90, 76, 88, 83, 89, 78, 87],"項目部成員歷史績效得分": [75, 80, 78, 85, 72, 82, 79, 84, 74, 81],"項目竣工評價系數": [1.1, 1.2, 1.05, 1.3, 1.0, 1.15, 1.1, 1.2, 1.05, 1.3],
}df = pd.DataFrame(data)# 特征與標簽
X = df[["項目經理歷史績效得分", "項目部成員歷史績效得分", "項目竣工評價系數"]]
y = df["項目經理歷史績效得分"] # 預測項目經理績效得分# 劃分訓練集與測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 訓練線性回歸模型
model = LinearRegression()
model.fit(X_train, y_train)# 預測
y_pred = model.predict(X_test)# 可視化預測結果
line = Line()
line.add_xaxis([str(i) for i in range(len(y_pred))])
line.add_yaxis("預測項目經理績效得分", y_pred.tolist())
line.add_yaxis("真實項目經理績效得分", y_test.tolist())
line.set_global_opts(title_opts=opts.TitleOpts(title="項目經理績效得分預測"))
line.render_notebook()
本代碼展示了如何利用歷史績效數據構建一個預測模型,以預測項目經理在未來項目中的績效得分。定義了包含項目經理、項目部成員的歷史績效得分和項目竣工評價系數的數據表。通過將數據劃分為訓練集和測試集,訓練了一個線性回歸模型,用于預測項目經理的績效得分。使用pyecharts生成了一個折線圖,比較了預測得分和真實得分,幫助分析模型的準確性。
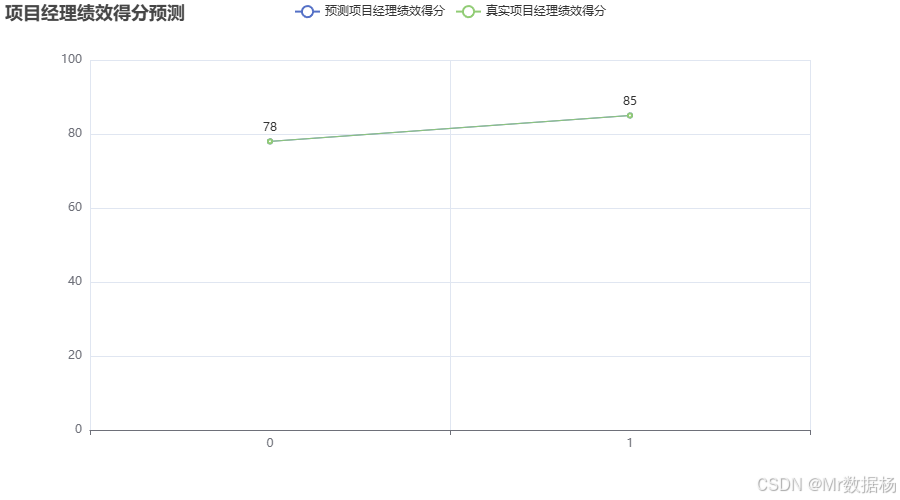
折線圖展示了預測的項目經理績效得分與真實的績效得分之間的差異。通過這種可視化方式,可以清楚地看到模型在預測中的表現,驗證其準確性。在圖表中,預測得分與真實得分的對比幫助判斷模型的有效性,進一步為項目績效考核的優化提供依據。這種方法能夠使項目管理人員更精準地預測未來項目中的關鍵績效指標,從而提前采取必要的管理措施。
深度學習的項目經理與項目部成員績效評估
在房地產項目管理中,深度學習能夠通過學習大量歷史數據中的復雜模式,為項目經理和項目部成員的績效評估提供強有力的支持。相比傳統的統計分析方法,深度學習模型可以從數據中挖掘出潛在的關聯性,從而更準確地進行績效評分。本案例展示了如何使用深度學習中的神經網絡模型,結合歷史數據對項目經理和項目部成員的績效進行評估,并通過訓練模型預測不同項目階段中的績效表現。
以下是模擬的數據展示,包含項目編號、項目階段、項目經理和項目部成員的歷史績效得分,以及項目竣工評價系數。通過這些數據,可以訓練神經網絡模型,以預測每個項目階段的績效表現。
| 項目編號 | 項目階段 | 項目經理歷史績效得分 | 項目部成員歷史績效得分 | 項目竣工評價系數 |
|---|---|---|---|---|
| 001 | 規劃階段 | 78 | 72 | 1.05 |
| 002 | 設計階段 | 82 | 77 | 1.1 |
| 003 | 建設階段 | 85 | 80 | 1.15 |
| 004 | 完工階段 | 90 | 85 | 1.2 |
| 005 | 規劃階段 | 76 | 70 | 1.0 |
| 006 | 設計階段 | 84 | 78 | 1.05 |
| 007 | 建設階段 | 88 | 82 | 1.1 |
| 008 | 完工階段 | 92 | 87 | 1.3 |
| 009 | 規劃階段 | 80 | 75 | 1.1 |
| 010 | 設計階段 | 86 | 80 | 1.15 |
數據源自多個房地產項目,記錄了項目經理和項目部成員在不同階段的績效表現。項目經理歷史績效得分和項目部成員歷史績效得分分別反映了兩者在各階段的工作質量、效率等指標,項目竣工評價系數則考慮了項目最終完成質量對績效的調整影響。
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import pandas as pd
from pyecharts.charts import Line
from pyecharts import options as opts# 模擬數據
data = {"項目編號": ["001", "002", "003", "004", "005", "006", "007", "008", "009", "010"],"項目階段": ["規劃階段", "設計階段", "建設階段", "完工階段", "規劃階段", "設計階段", "建設階段", "完工階段", "規劃階段", "設計階段"],"項目經理歷史績效得分": [78, 82, 85, 90, 76, 84, 88, 92, 80, 86],"項目部成員歷史績效得分": [72, 77, 80, 85, 70, 78, 82, 87, 75, 80],"項目竣工評價系數": [1.05, 1.1, 1.15, 1.2, 1.0, 1.05, 1.1, 1.3, 1.1, 1.15],
}df = pd.DataFrame(data)# 特征與標簽
X = df[["項目經理歷史績效得分", "項目部成員歷史績效得分", "項目竣工評價系數"]].values
y = df["項目經理歷史績效得分"].values # 預測項目經理績效得分# 數據標準化
scaler = StandardScaler()
X = scaler.fit_transform(X)# 劃分訓練集與測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 定義神經網絡模型
class SimpleNN(nn.Module):def __init__(self):super(SimpleNN, self).__init__()self.fc1 = nn.Linear(3, 16) # 輸入層:3個特征,隱藏層:16個神經元self.fc2 = nn.Linear(16, 8) # 隱藏層:8個神經元self.fc3 = nn.Linear(8, 1) # 輸出層:1個輸出(項目經理績效得分)def forward(self, x):x = torch.relu(self.fc1(x)) # 激活函數x = torch.relu(self.fc2(x))x = self.fc3(x)return x# 將數據轉換為tensor
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.float32).view(-1, 1)
X_test_tensor = torch.tensor(X_test, dtype=torch.float32)
y_test_tensor = torch.tensor(y_test, dtype=torch.float32).view(-1, 1)# 初始化神經網絡模型
model = SimpleNN()# 定義損失函數和優化器
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 使用學習率調度器
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=100, gamma=0.1)# 訓練模型
epochs = 1000
for epoch in range(epochs):model.train()optimizer.zero_grad()y_pred = model(X_train_tensor)loss = criterion(y_pred, y_train_tensor)loss.backward()optimizer.step()scheduler.step()# 預測
model.eval()
y_pred_test = model(X_test_tensor).detach().numpy()# 可視化預測結果
line = Line()
line.add_xaxis([str(i) for i in range(len(y_pred_test))])
line.add_yaxis("預測項目經理績效得分",[round(i*100,2) for i in y_pred_test.flatten().tolist()])
line.add_yaxis("真實項目經理績效得分", y_test_tensor.flatten().tolist())
line.set_global_opts(title_opts=opts.TitleOpts(title="深度學習預測項目經理績效得分"))
line.render_notebook()
在本代碼中對房地產項目的歷史數據進行了標準化處理,以消除特征值之間的差異對模型訓練的影響。然后,定義了一個簡單的神經網絡模型,包含一個輸入層(3個特征),一個隱藏層(10個神經元)和一個輸出層(1個輸出:項目經理績效得分)。使用PyTorch的Adam優化器和均方誤差損失函數(MSELoss)來訓練模型。經過500次迭代后,模型能夠根據項目經理歷史績效得分、項目部成員歷史績效得分以及項目竣工評價系數來預測項目經理在新項目中的績效得分。最后,通過pyecharts生成一個折線圖,將預測得分與真實得分進行對比,幫助分析模型的表現。
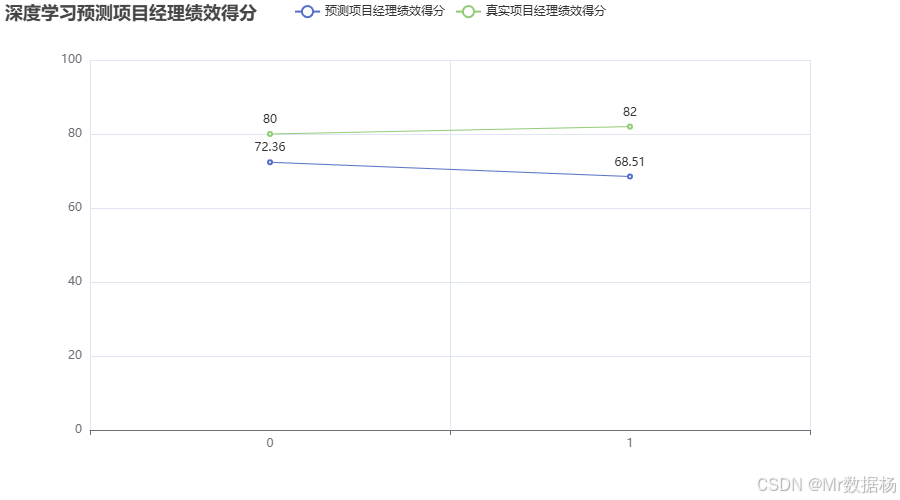
折線圖展示了通過深度學習模型預測的項目經理績效得分與真實得分之間的對比。通過這種方式,能夠直觀地了解模型預測的準確性。若預測結果與實際得分接近,說明模型具備較高的準確性。反之,可能需要進一步優化模型參數或嘗試其他深度學習架構。在項目管理過程中,使用這種深度學習方法能夠在大量歷史數據的支持下,更精準地預測項目經理在不同階段的績效表現,從而實現更科學的績效考核和獎勵分配。
總結
房地產項目的績效考核表通過對項目經理和項目部成員的工作計劃完成情況、工期控制、工程質量、安全生產等多個方面進行量化評估,旨在提高整體項目管理效率和項目質量控制。這些指標不僅幫助評估當前的項目管理能力,也為未來的優化提供了清晰的方向。各項KPI均依據實際的運營數據計算,通過與計劃目標的對比,來評判績效的達成度。通過這些指標,項目管理團隊能夠準確掌握自己的運營狀態,及時調整策略和工作重點,從而提升整體效能。
未來,可以通過進一步優化和細化各項KPI指標,結合先進的數據分析和預測技術,提升房地產項目的整體運營效率。例如,應用機器學習和深度學習技術,可以更準確地預測未來的項目成本和預算執行情況,從而更好地進行資源調配和項目決策。此外,通過不斷引入新技術和方法,如大數據分析和智能化管理系統,進一步提升績效考核的透明度和準確性,提高項目管理效率和項目質量控制。在實現這些目標的過程中,項目管理團隊需要持續關注市場變化和技術進步,靈活調整管理策略,保持競爭優勢。
:dp思想、基礎線性dp)



)

)


)



)
-Task2筆記)




