排序
1. 排序的概念
排序:所謂排序,就是使一串記錄,按照其中的某個或某些些關鍵字的大小,遞增或遞減的排列起來的操作。
2. 常見的排序算法
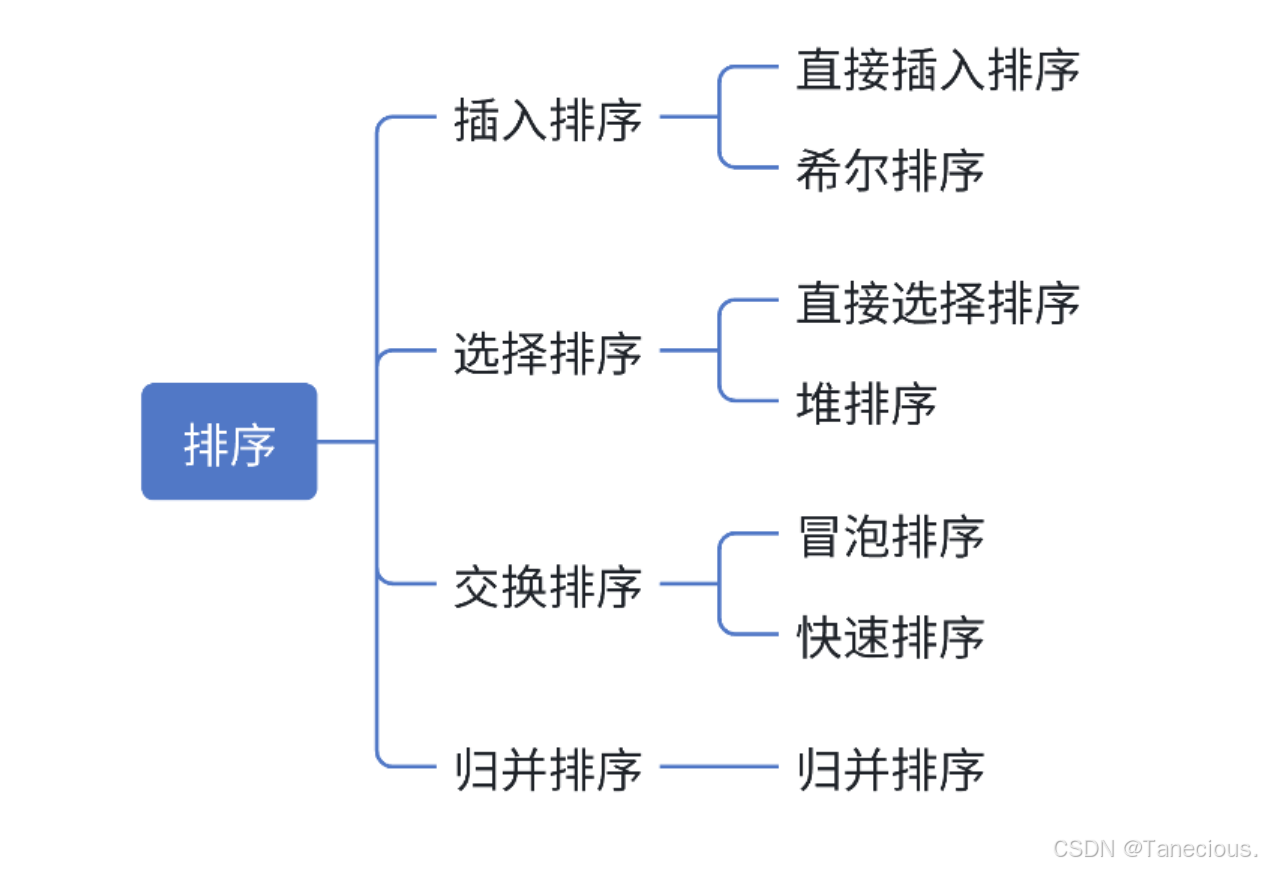
3. 實現常見的排序算法
以下排序算法均是以排升序為示例。
3.1 插入排序
基本思想:
排序是一種簡單的插入排序法,其基本思想是:把待排序的記錄按其關鍵碼值的大小逐個插入到一個已經排好序的有序序列中,直到所有記錄插入完為止,得到一個新的有序序列。
這種思想類似于玩撲克牌的時候,將牌按一定順序排好。

3.1.1 直接插入排序
3.1.1.1 代碼示例
//直接插入排序(從大到小)n表示數組有效數據個數
void InsertSort(int* arr, int n)
{for (int i = 0; i < n - 1; i++){int end = i;//從首元素開始記錄有序序列的最后一個元素的下標int tmp = arr[end + 1];//待插入的元素//確保end在有序區間范圍內,不能越界 while (end >= 0){//比較有序區間數據,tmp數據小if (arr[end] > tmp){//有序空間數據移動,尋找空間插入數據arr[end + 1] = arr[end];//繼續向前尋找合適數據end--;}//比較有序區間數據,tmp數據大else{//直接跳出循環,將tmp數據插入到end+1下標處break;}}arr[end + 1] = tmp;//代碼執行到此位置有兩種情況://1.待插入元素找到應插入位置(break跳出循環到此)。//2.待插入元素比當前有序序列中的所有元素都小(while循環結束后到此)。}
}
時間復雜度: O ( N 2 ) O ( N^2 ) O(N2)(最差情況,數組為降序)??空間復雜度: O ( 1 ) O ( 1 ) O(1)
3.1.1.2 代碼詳解
-
函數參數:
int* arr:需要排序的數組的數組名(數組的首元素地址)int n:數組中有效元素的個數
-
外層for循環:
for (int i = 0; i < n - 1; i++)- 外層的for循環表示,控制end的下標需要遍歷數組中的每個數據,每個數據均需要參與比較。
- 這里的循環邊界是tmp不能越界,所以tmp最大值為 n ? 2 n-2 n?2,所以 i < n ? 1 i<n-1 i<n?1為邊界
-
臨時變量的創建:
int end:用于表示有序數組中的最后一位數據的下標,從首元素開始。int tmp:將待插入元素拷貝一份。存在有序數組后移覆蓋掉待插入元素的情況。
-
內層while循環:
while (end >= 0)- 內層的while循環表示,要保證end在有序數組的范圍內,不可以越界。
-
if判斷語句
- 如果此時以
end為下標的數組數據 大于待插入數據,則將以end為下標的數組數據先后移(注意:這里是通過end+1的方式實現數據的后移,此時end的位置并沒有改變),在將end--,在比較前面較小的有序數據。 - 如果此時以
end為下標的數組數據小于待插入數據,則需要在end后面一個位置插入此數據,并也不需要再與有序數組中的數據比較,故跳出循環。
- 如果此時以
-
插入數據
arr[end + 1] = tmp- 代碼執行到此位置有兩種情況:
- 待插入元素找到應插入位置(break跳出循環到此)。
- 待插入元素比當前有序序列中的所有元素都小(while循環結束后到此)。
3.1.2 希爾排序
3.1.2.1 思路詳解
相關介紹
希爾排序是按其設計者希爾的名字命名的,該算法由希爾1959年公布。他對普通直接插入排序的時間復雜度進行分析,得出了以下結論:
- 直接插入排序的時間復雜度最壞情況下為 O ( N 2 ) O(N^2) O(N2),此時待排序列為逆序,或者說接近逆序。
- 直接插入排序的時間復雜度最好情況下為 O ( N ) O(N) O(N),此時待排序列為升序,或者說接近升序。
是否可以有一種算法,可以規避掉直接插入排序的最壞的逆序情況,這樣的話就可以大幅降低直接插入排序的復雜度了。
**規避掉逆序情況的方式:**先將待排序的數據進行預排序,使代排序列就接近有序,再對此序列進行一次直接插入排序,此時因為一定不是逆序序列,所以對于直接插入排序的復雜度就一定小于 O ( N 2 ) O(N^2) O(N2)。
基本思想:
-
希爾排序的核心思想:先用較大間距進行局部排序,逐漸縮小間距提高整體有序性,最終用間距為1的插入排序完成,這樣效率比普通插入排序高很多。
-
因為希爾排序又被成為縮小增量排序。
- 先選定一個小于N的整數gap(步長)作為第一增量,然后將所有距離為gap的元素分在同一組,并對每一組的元素進行直接插入排序。然后再取一個比第一增量小的整數作為第二增量,重復進行上述操作…
- 當增量的大小減到1時,就相當于整個序列被分到一組,進行一次直接插入排序,排序完成。
補充
-
問題1:為什么要讓gap由小到大?
因為當gap(步長)越大,數據間隔越大,數據移動的越快。前期讓gap較大,可以讓數據更快移動到自己對應位置附近,減少數據的挪動次數,減少復雜度。
-
問題2:gap的值應該應該如何選取?
一般情況下,取序列的一半作為增量,然后依次減半,并確保最終增量可以減為1。
具體示例:
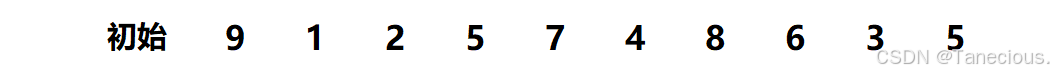
? 首先對這10個亂序數組作為示例進行排序,用序列長度的一半作為第一次增量,也就是gap = 10/2 = 5,因此此時相隔距離為5的數據被分為一個**(共分了5組,每組有2個元素),然后對這5組在組內進行直接插入排序**,調整數據順序。
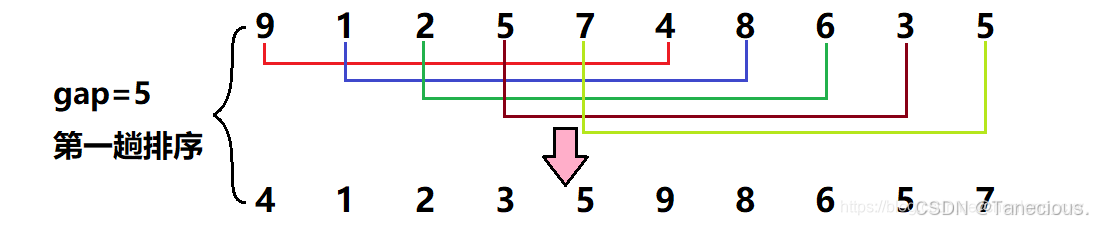
? 經過第一次調整之后,可以大致看出新的序列大體呈現左邊為小數據,右邊為大數據的規律。之后繼續進行第二次調整,此時gap的值對半gap = 5/2 = 2,此時相隔距離為2的元素被分為一組**(共分了2組,每組有5個元素)**,然后再對這2組數據在組內進行直接插入排序,調整數據順序。
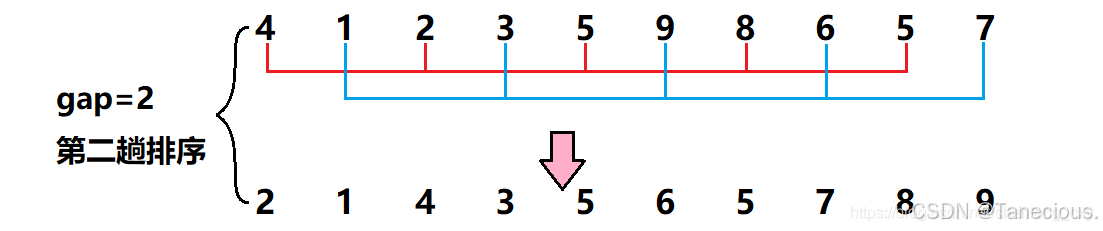
? 此時再將gap的值對半,gap = 2/2 = 1,此時gap減為1,即整個序列被分為一組,進行一個直接插入排序。
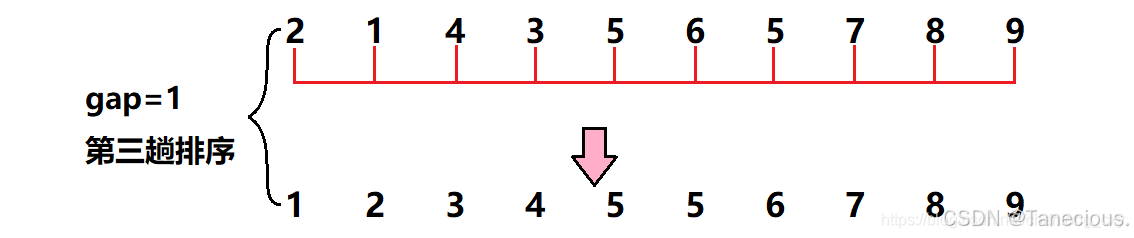
? 這樣就利用希爾排序完成了以上序列的排序方法,其中前兩趟為希爾排序的預排序,最后一趟是希爾排序的直接排序。
3.1.2.2 示例代碼
//希爾排序
void ShellSort(int* arr, int n)
{//定義步長int gap = n;//6//控制排序次數,調整步長while (gap > 1){gap = gap / 3 + 1;//保證最后一次gap一定為1//遍歷被步長分隔的數組內部的數據for (int i = 0; i < n - gap; i++){int end = i;//n-gap-1int tmp = arr[end + gap];//防止end越界while (end >= 0){//進行元素的比較和交換if (arr[end] > tmp){arr[end + gap] = arr[end];end -= gap;}else {break;}}arr[end + gap] = tmp;//代碼執行到此位置有兩種情況://1.待插入元素在組中找到應插入位置(break跳出循環到此)。//2.待插入元素比當前組中的有序序列中的所有元素都小(while循環結束后到此)。 }}
}
平均時間復雜度大約為: O ( N 1.3 ) O(N^{1.3}) O(N1.3)??空間復雜度: O ( 1 ) O ( 1 ) O(1)
3.1.2.2 代碼詳解
-
函數參數與步長定義
-
int* arr:需要調整的序列所屬數組的數組名 -
int n:數組中有效元素的個數 -
int gap = n;:步長的定義,一般初始值即為n,在后續排序會先折半
-
-
外層while循環
- 先由
gap = gap / 3 + 1;語句,對初始化的gap值進行調整,便于后續使用 - 再有外層while循環控制整體排序的次數
- 先由
-
內層for循環
- 在
arr數組中的序列已經被gap切分之后,由for循環遍歷各個組中的數據 - 同時定義
end與tmp,含義與直接插入排序中一樣 - for循環的截止條件還是需要防止tmp的下標越界,所以為 i < n ? g a p i < n - gap i<n?gap
- 在
-
算法核心實現
- 插入算法的核心實現邏輯
- 由外層while循環控制end遍歷該組數據中的每個數據
- if判斷語句,實現數據比較與交換的功能
3.2 選擇排序
基本思想:
每一次從待排序的數據元素中選出最小(或最大)的一個元素,存放在序列的起始位置,直到全部待排序的數據元素排完。
3.2.1 直接選擇排序
3.2.1.1 代碼示例
//直接選擇排序
void SelectSort(int* arr, int n)
{//起始位置元素下標int begin = 0;//結尾位置元素下標int end = n - 1;//開始從數組兩頭遍歷數組while (begin < end){//最大最小值初始狀態都定義在首元素處int mini = begin, maxi = begin;//在begin~end未排序區間之間,進行比較for (int i = begin; i <= end; i++){if (arr[i] > arr[maxi]) {//確定未排序區間中的最大數,并將maxi指向他maxi = i;}if (arr[i] < arr[maxi]){//確定未排序區間中的最小數,并將mini指向他mini = i;}}//mini和begin交換,maxi和end交換//避免maxi begin指向同一個位置,造成maxi mini互換兩次,相當于沒換if (maxi == begin){maxi = mini;}Swap(&arr[mini], &arr[begin]);Swap(&arr[maxi], &arr[end]);//調整無序序列下標++begin;--end;}
}
時間復雜度: O ( N 2 ) O(N^2) O(N2)??空間復雜度: O ( 1 ) O(1) O(1)
3.2.2 堆排序
? 這里的堆排序在前面堆的數據結構類型有過相關介紹。所以要想學習到堆排序,首先需要了解堆的向下調整算法,因為堆排序的核心就是先利用無序序列建堆,再利用堆的向下調整算法將堆構造成小根堆(以排升序為例),再將堆頂數據不斷出堆即可。
3.2.2.1 思路詳解
首先,拿到一個無序序列先將此序列依照堆的向下調整算法建堆。
向下調整算法的介紹:
在使用堆的向下調整算法的使用前提:
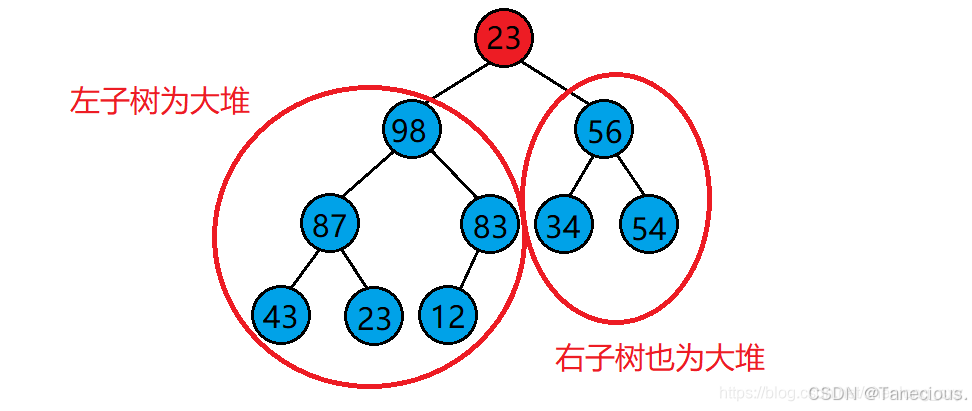
- 若想將其調整為小堆,那么根結點的左右子樹必須都為小堆。(排降序用小堆)
- 若想將其調整為大堆,那么根結點的左右子樹必須都為大堆。(排升序用大堆)
堆的向下調整算法的基本思想:
- 從根結點處的數據開始操作,選出根結點左右孩子中值較大的那一個。
- 讓較大的孩子與其父親進行比較
- 若孩子結點比父親結點大,則該孩子結點與父親結點的位置進行交換,并將原來大孩子的位置作為新的父親結點(根結點)繼續遍歷向下調整。
- 若孩子結點比父親結點小,則不需要處理,整個樹已經是大堆了。
//堆的向下調整算法(以建大堆為例) //end表示數組中最后一個有效數據的下表,也就是size-1 //該函數第一個參數表示要操作的數組,后兩個表示數組有效數據的下標0~end(size - 1) AdjustDown(HPDataType* arr, int parent, int end) {int child = parent * 2 + 1;//當子節點移動到末尾結束循環while (child <= end){ //補充:小堆找左右孩子最小的;大堆找左右孩子最大的//找左右孩子最大的,準備與父節點交換位置//注意越界問題,數組下標不可以大于最后一位數據的下標if (child + 1 >= end && arr[child] < arr[child + 1]){//右孩子更大,改變child的值child++;}//交換位置if (arr[child] > arr[parent]){Swap(&arr[child], &arr[parent]);//坐標變換繼續調整數據parent = child;child = parent * 2 + 1;}//換到中間位置已經形成堆結構else{break;}} }
問題1:上面的基本思想是建立在左右子樹均為大堆或者小堆的基礎上,那么如何將一個任意樹調整成堆呢(建堆過程)?
? 只需要從倒數第一個非葉子結點開始執行堆的向下調整算法,從后往前按下標,依次為根結點去向下調整即可。
//建堆(向下調整算法建(調整)堆)
//(size-1-1)/2指的是最后一個非葉子結點的數組下標,i--不斷開始遍歷每個節點進行調整
for(int i = (size-1-1)/2; i >= 0; i--)
{AdjustDown(arr, i, size - 1);
}
**問題2:**那么堆建好后,如何進行堆排序呢?
- 將堆頂數據與堆的最后一個數據交換,然后對根結點位置進行一次堆的向下調整,但是調整時被交換到最后的那個最大的數不參與向下調整。
- 完成步驟1后,這棵樹除最后一個數之外,其余數又成一個大堆,然后又將堆頂數據與堆的最后一個數據交換,這樣一來,第二大的數就被放到了倒數第二個位置上,然后該數又不參與堆的向下調整……反復執行下去,直到堆中只有一個數據時便結束。此時該序列就是一個升序。
//堆排序(大堆 --- 升序)
//因為如果需要實現堆排序,這需要先創建堆結構存放n個數據,空間復雜度為O(n)
//現在需要讓堆排序空間復雜度為O(1),可以直接將對傳來的數組進行操作
void HeapSort(int* arr, int size)
{//建堆(向下調整算法建(調整)堆)//(size-1-1)/2指的是最后一個非葉子結點的數組下標,i--不斷開始遍歷每個節點進行調整for(int i = (size-1-1)/2; i >= 0; i--){AdjustDown(arr, i, size - 1);}//排升序 --- 大堆// 循環將堆頂數據跟最后位置(會發生變化,每交換一次位置-1)的數據交換int end = size - 1;//最后一個數據的下標//走到堆底則停止調整while (end > 0){Swap(&arr[0], &arr[end]);//交換,此時堆頂元素為一開始數組中的最后一個數據//向下調整堆(從0調整到end)AdjustDown(arr, 0, end);//數組中最后一個已經是最小,故排出排序范圍end--;}//排升序 --- 大堆 //排降序和升序邏輯一致,只需要更改AdjustDown和AdjustUp中的大小于號即可
}
時間復雜度: O ( N l o g N ) O(NlogN) O(NlogN)??空間復雜度: O ( 1 ) O(1) O(1)
補充:
- 因為堆的底層結構是數組,然后無論是堆的向下調整算法還是堆排序,都是直接對亂序數組進行直接操作,所以所謂的建堆,其實不是把數組中的數據一個個插入堆中,而是將已經存在在堆中但是是亂序的數據,重新調整排列,使其滿足大/小堆的結構。
3.3 交換排序
基本思想:
所謂交換,就是根據序列中兩個記錄鍵值的比較結果來對換這兩個記錄在序列中的位置。
交換排序的特點是:將鍵值較大的向序列的尾部移動,鍵值較小的記錄向序列的前部移動。
3.3.1 冒泡排序
3.3.1.1 示例代碼
//冒泡排序
//時間復雜度:0(N^2)
void BubbleSort(int* arr, int n)
{//外層循環控制整個排序過程的遍歷次數,確保每次排序(從亂序到有序算一次)數組中的每個數據都可以被遍歷for (int i = 0; i < n; i++){int exchange = 0;//記錄該趟冒泡排序是否進行過交換//內層循環負責在當前輪次中進行相鄰元素的比較和交換for (int j = 0; j < n - i - 1; j++){//升序if (arr[j] < arr[j + 1]){exchange = 1;Swap(&arr[j], &arr[j + 1]);}}if (exchange == 0)//該趟冒泡排序沒有進行過交換,已有序{break;}}
}時間復雜度: O ( N 2 ) O(N^2) O(N2)??空間復雜度: O ( 1 ) O(1) O(1)
3.3.1.2 思路詳解
利用兩層for循環實現遍歷次數的控制和每次遍歷的大小比較、元素交換,從而實現冒泡排序。
- 外層for循環:控制遍歷次數,一次調整好一個數據故遍歷n次。
- 內存for循環:在此次遍歷的亂序數組中,每兩個數據都比較,將大的放后面,直到將亂序序列中的最大值挑選出并放到最后一個數據位置。完成一個完整的內部循環,回到外層循環,
i++繼續開始新的遍歷。
3.3.2 快速排序(遞歸版)
快速排序是Hoare與1962年提出的一種二叉樹結構的交換排序方法。
基本思想:
? 任取待排序元素序列的某元素作為基準值,按照該排序碼將待排序集合分割成兩子序列,左子序列中所有元素均小于基準值,右子序列中所有元素均大于基準值,然后左右子序列重復該過程,直到所有元素都排序在對應位置上為止。
如何按照基準值將待排序列分為兩子序列,常見方法:
- Hoare版本
- 挖坑法
- lomuto前后指針法
以下不同版本的僅僅是利用不同的方式得到基準值下標并實現將基準值到達目標位置的子函數
_QuickSort的編寫方式的不同。
如上解釋,因為快速排序核心思想就是利用遞歸的方法遍歷整個亂序序列,所以其主函數框架在下面進行展示;至于子函數的三種實現方式,在下面會進行一一介紹。
QuickSort函數的實現
-
函數功能:
- 完成整個亂序序列的排序。
-
函數示例:
void QuickSort(int* arr, int left, int right) {//保證下標有效if (left >= right){return;}//[left,right]--->找基準值keyiint keyi = _QuickSort(arr, left, right);//左子序列:[left,keyi-1]QuickSort(arr, left, keyi - 1);//右子序列:[keyi+1,right]QuickSort(arr, keyi + 1, right); }時間復雜度: O ( N l o g N ) O(NlogN) O(NlogN) 空間復雜度: O ( N l o g N ) O(NlogN) O(NlogN)
-
邏輯補充:
- 首先保證函數參數的
left,right有意義。 - 用函數
_QuickSort,找到第一趟排序基準值,記錄下來,根據基準值的位置,將序列分成兩個子序列。 - 循環遞歸調用
QuickSort,遍歷左右子序列,直到序列有序。
- 首先保證函數參數的
3.3.2.1 Hoare版本
代碼思路:
-
_QuickSort函數的實現-
函數功能:
- 用于實現單趟排序,也就是調用一次此函數即
keyi可到達自己的目標位置。
- 用于實現單趟排序,也就是調用一次此函數即
-
函數參數:
- int arr*:待排序的數組
- int left, int right:數組中的待排區間的左右下標標記,后續
left從左向右走,right從右向左走
-
函數邏輯:
- 選取待排區間的最左側,作為基準值(
keyi),即int keyi = left; left右移一位,基準值不需要遍歷。即++left;- 開始遍歷
while (left <= right),因為一開始選擇最左邊的數據作為keyi,則需要right先走;若選擇最右邊的數據作為keyi,則需要left先走 - 在走的過程中,若
right遇到小于keyi的數,則停下,left開始走,直到left遇到一個大于keyi的數時,停止,將right和left下標所指向的數據交換;然后right再次開始走,如此進行下去,直到left和right最終相遇,此時將相遇點的內容與keyi交換即可。 - 同時此時交換后的基準值的位置,就是此數據在數組中應該所處的位置。
- 選取待排區間的最左側,作為基準值(
-
函數示例:
//QuickSort子函數,進行單趟的排序 int _QuickSort(int* arr, int left, int right) {//定義基準點int keyi = left;++left;while (left <= right){//right先走,找小于基準值的數while (left <= right && arr[right] > arr[keyi]){right--;}//left后走,找大于基準值的數while (left <= right && arr[left] < arr[keyi]){left++;}//right leftif (left <= right){Swap(&arr[left++], &arr[right--]);}}//right keyi交換Swap(&arr[keyi], &arr[right]);return right; } -
邏輯詳解:
-
while (left <= right):包含=是因為left和right相遇的位置的值可能比基準值要大,如果此時跳出循環交換基準值和right指向的值,此時基準值的左子樹中就存在一個大于基準值的值。 -
while (left <= right && arr[right] > arr[keyi]):-
這里介紹了right停下的兩種原因:①檢查到小于基準值的值;②遍歷到left左邊。只要不是這兩種情況,right應該要不斷左移。
-
循環前面的限制原因同補充1,第二個限制條件不加
=,是為了解決在二分時,效率過低的問題。**eg:**待排序序列中全是同一個元素,這里若加上等號,right就會一直
--直到與left重合,但是此時交換基準值,才會移動一格子。無法實現有效的數據分割。即遇到
-
-
while (left <= right && arr[left] < arr[keyi]):-
這里介紹了left停下的兩種原因:①檢查到大于基準值的值;②遍歷到right右邊。只要不是這兩種情況,left應該要不斷右移。
-
循環前面的限制原因同補充1,第二個限制條件不加
=,是為了解決在二分時,效率過低的問題。
-
-
if (left <= right):經過上面兩層循環,此時left和right都已經停下,這里的停下有兩種情況:-
left和right沒有相遇,正常的交換調整數據,然后繼續移位遍歷
-
left和right相遇,先原地交換一下,然后在遍歷,使得
left > right,這樣一方面可以跳出while循環,表示已經完成一趟排序,還可以將right重新指向一個小于基準值的值,要不然如果相遇值大于大于或者等于基準值就跳出while循環就會造成基準值的左子樹中就存在一個大于基準值的值。
-
-
Swap(&arr[keyi], &arr[right]):將基準值keyi移到正確位置,此交換語句僅交換兩個數組中的數據,此時的keyi仍是左邊第一個數據的下標,right此時才是基準值數據的數組下標。 -
return right:函數的返回值是基準值所在下標。
-
-
3.3.2.2 挖坑版
代碼思路:
-
_QuickSort函數的實現-
函數示例:
//挖坑法 int _QuickSort2(int* arr, int left, int right) {// 挖坑+記錄基準值int hole = left;int key = arr[hole];//開始遍歷while (left < right){//right向左,找小while (left < right && arr[right] > key){--right;}arr[hole] = arr[right];hole = right;//left向右,找大while (left < right && arr[left] < key){++left;}arr[hole] = arr[left];hole = left;}//left和right相遇arr[hole] = key;//將基準值填入坑位return hole;//返回此時基準值下標 } -
邏輯詳解:
int hole = left; int key = arr[hole];:首先在left位置挖坑并將坑中的數值記錄下來,作為標準值。這里就像將left位置的土(數據),挖出裝進key的車上(基準值)。while (left < right):開始循環遍歷序列,直到left和right相遇。while (left < right && arr[right] > key):right循環遍歷,跳出循環有兩個情況:arr[right] <= key,檢測到小于等于基準值的數據,此時right停下,此時將arr[right]中的土(數據),挖出填到arr[hole]的坑中,在將此時下標right標記為新的坑。left = right,此時left和right相遇,停止遍歷,將相遇位置的土(數據),填到坑的位置上去,再將相遇位置標記為新的坑。
while (left < right && arr[left] < key):left循環遍歷語句,和上述邏輯一致,不做過多贅述。arr[hole] = key; return hole;:left和right相遇時的調整語句,將原先存在裝進key的車上的標準值的土,填入相遇位置的坑中。這個位置就是標準值的目標位置,最后將目標位置的返回回去。
-
3.3.2.3 lomuto前后指針法
基本步驟:
- 將序列最左邊數據作為基準值
key - 創建兩個指針,prev指向序列開頭,cur指針指向prev+1
- 若cur指向的內容小于key,則prev先移動一位并且不等于cur,然后交換prev和cur指針指向的內容,然后cur指針++;若cur指向的內容大于key,則cur指針直接++后移
- 如此進行下去,直到cur指針越界,此時將key和prev指針指向的內容交換即可
函數示例:
//lomuto前后指針法
int _QuickSort3(int* arr, int left, int right)
{//前后指針和基準值的初始化int prev = left, cur = left + 1;int key = left;//開始遍歷序列while (cur <= right){//cur的內容小于基準值并且prev+1不等于cur交換數據if (arr[cur] < arr[key] && ++prev != cur){Swap(&arr[cur], &arr[prev]);}//繼續后移遍歷cur++;}//將基準值移到目標位置Swap(&arr[key], &arr[prev]);return prev;
}
3.3.3 快速排序(非遞歸版)
? 因為快速排序是根據二叉樹結構的基礎上進行排序,所以就涉及了函數的遞歸思想,但是因為涉及函數遞歸就需要函數棧幀的創建,每創建一個函數棧幀就相當于將一個數據移動到目標位置。但是如果序列中數據極大,沒有那么大的空間創建足夠的函數棧幀,可能就會出現棧溢出的情況。
? 所以下面會介紹快速排序的非遞歸版本的相關內容。而非遞歸版本的快速排序需要借助數據結構:棧
? 因為上面已經將Hoare版本、挖坑法和前后指針法的單趟排序單獨封裝起來。此時只需要更改QuickSort函數的內部遞歸邏輯改為非遞歸邏輯,再在QuickSort函數內部調用單趟排序的函數即可。
基本步驟:
- 先將待排序列的第一個元素的下標和最后一個元素的下標入棧。
- 當棧不為空時,讀取棧中的信息(一次讀取兩個:一個是
begin,另一個是end),然后調用某一版本的單趟排序,排完后獲得了基準值的下標,然后判斷基準值的左序列和右序列是否還需要排序,若還需要排序**(左右序列區間有意義),就將相應序列的begin和end入棧;若不需排序了(左右序列區間無意義或者左右區間相同)**,就不需要將該序列的信息入棧。 - 反復執行步驟2,直到棧為空為止。
示例代碼:
//非遞歸版本快排
//--借助數據結構--棧
void QuickSortNonR(int* arr, int left, int right)
{ST st;STInit(&st);StackPush(&st, right);StackPush(&st, left);while (!StackEmpty(&st)){//取棧頂元素---取兩次int begin = StackTop(&st);StackPop(&st);int end = StackTop(&st);StackPop(&st);//[begin,end]---找基準值keyi = _QuickSort(arr, begin, end);//根據基準值劃分左右區間//左區間:[begin,keyi-1]//右區間:[keyi+1,end]if (keyi + 1 < end){StackPush(&st, end);StackPush(&st, keyi + 1);}if (keyi - 1 > begin){StackPush(&st, keyi - 1);StackPush(&st, begin);}}STDestroy(&st);
}
代碼詳解:
由遞歸版本代碼改為為非遞歸主要是對于左右序列的區間如何獲取的方式不同。
-
ST st;STInit(&st);STDestroy(&st);非遞歸版本需要借用數據結構–棧,創建棧、初始化棧、銷毀棧為固定操作。
-
StackPush(&st, right);StackPush(&st, left);將亂序區間的左右序列下標入棧。
-
while (!StackEmpty(&st)){}利用循環檢測棧里面有沒有有效區間的方式,代替函數的遞歸。
-
//取棧頂元素---取兩次int begin = StackTop(&st);StackPop(&st);int end = StackTop(&st);StackPop(&st);取兩次棧頂數據,作為單趟排序函數的左右區間參數。
-
//[begin,end]---找基準值keyi = _QuickSort(arr, begin, end);參考上文三中單趟排序的子函數,任選一種單趟排序找基準值。
-
//根據基準值劃分左右區間//左區間:[begin,keyi-1]//右區間:[keyi+1,end]if (keyi + 1 < end){StackPush(&st, end);StackPush(&st, keyi + 1);}if (keyi - 1 > begin){StackPush(&st, keyi - 1);StackPush(&st, begin);}找到基準之后重新劃分左右區間。但是在插入棧之前需要保證兩個條件:
- 左右區間為有效區間,起點位置不能大于終點位置。
- 區間中數據必須大于一個,起點位置不能和終點位置相同。
3.3.4 快排的深入優化
3.3.4.1 三數取中選key
? 在快速排序中的每趟排序中,都是key占整個序列的位置,是影響快速排序效率最大的因素,將key越接近中間位置,則越可以增強快速快速排序的效率。因為這里引入了一個三數取中的思想解決這個問題。
基本思想:
所謂三數取中,就是取頭,中,尾三個元素,比較大小,選擇排在中間的數據作為基準值key。這執行快速排序,這就確保了所選取的數不會是序列中的最大或是最小值,這種算法可以一定程度提升快速排序的效率。
- 首先將此功能封裝為一個函數
GetMidIndex將待排數組和數組的最左邊數據下標和最后邊數組下標傳入函數。 - 再通過左右位置下標確定中間位置下標,之后利用
if-else,對三個數據進行比較,最后將大小處于中間的數據作為key返回。
// 快速排序--優化1---三數取中選key
int GetMidIndex(int* a, int left, int right)
{//獲取中間位置下標int mid = (left + right) / 2;//開始比較if (a[left] < a[mid]){if (a[mid] < a[right]){return mid;}else if (a[right] < a[left]){return left;}else{return right;}}else{if (a[mid] > a[right]){return mid;}else if (a[right] > a[left]){return left;}else{return right;}}
}
算法總結:
-
在調用這個函數之后,就可以將中間值的下標返回給快速排序,之后再將此數據與起始的最左側數據進行交換位置,之后進行正常的快速排序就可以了。此時的key就是
GetMidIndex函數的返回值了// 快速排序--遞歸法 void QuickSort(int* a, int begin, int end) {if (begin >= end){return;}int mid = GetMidIndex1(a, begin, end);Swap(&a[begin], &a[mid]); // 再交換中間值位置與最左邊位置int keyi = QuickSort(a, begin, end);// [beign,keyi-1] keyi [keyi+1,end]QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end); }
3.3.4.2 隨機數選取key
? 在選取key的時候已經有了上一個三數取中的思路,但是三數取中的思路可能有點死板,所取得值只能是固定位置,于是現在就有了基于三數取中的算法進行優化,即隨機數算key法。
基本思想:
? 隨機數選key的和基本思想和三數取中一致,只是mid的值并不是由(left + right)/2得來的,而是由隨機數生成而來,即 mid = left + (rand() % (right - left))。
示例代碼:
// 快速排序--優化2---隨機數選key
int GetMidIndex2(int* a, int left, int right)
{//隨機數獲取中間值下標int mid = left + (rand() % (right - left));if (a[left] < a[mid]){if (a[mid] < a[right]){return mid;}else if (a[right] < a[left]){return left;}else{return right;}}else{if (a[mid] > a[right]){return mid;}else if (a[right] > a[left]){return left;}else{return right;}}
}
3.3.4.3 三路劃分
? 在遞歸版的快速排序中,當待排序列中含有多個相同元素的時候,單純的使用普通的快速排序的優勢就不是那么明顯了。這時候使用三路劃分就可以很好的解決這個問題。
圖片理解:
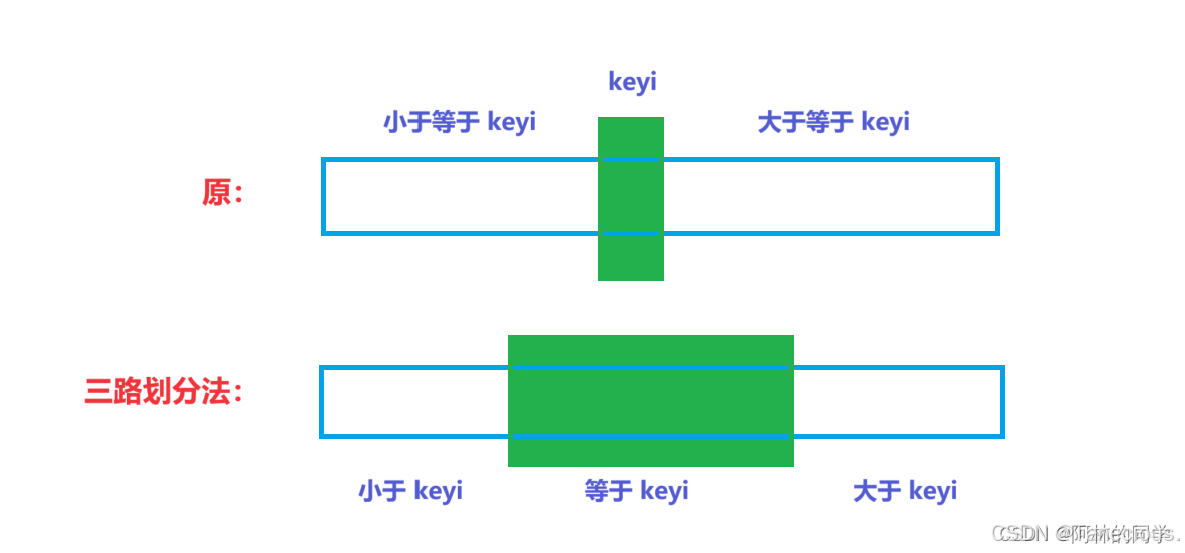
基本思想:
? 當面對有大量和key(基準值)相同的值的時候,三路劃分的核心思想有點類似于hoare的左右指針和lomuto的前后指針的結合。核心思想是把數組分為三段比key小的值,跟key相等的值,比key大的值,所以叫做三路劃分算法。結合下圖具體闡述實現思想:

- key默認取left位置的值。
- left指向區間最左邊,right指向區間最后面,cur指向left + 1的位置。
- 開始遍歷比較,調整序列
- 情況①:cur遇到比key小的值后跟left位置交換,換到左邊,然后left++,cur++
- 情況②:cur遇到比key大的值后跟right位置交換,換到右邊,然后right–
- 情況③:cur遇到跟key相等的值之后,cur++
- 直到cur > right結束
示例代碼:
// 快速排序--遞歸法---三路劃分法
//begin:待排序列最左側數據下標
//end:待排序列最右側數據下標
void QuickSort(int* a, int begin, int end)
{//保證序列有意義if (begin >= end){return;}//初始化int left = begin;int right = end;int key = a[left];int cur = left + 1;//開始遍歷比較while (cur <= right){//情況1:大的放到右邊,由于交換過來的cur不確定,故cur不移動,進行下一輪檢測if (a[cur] > key){Swap(&a[cur], &a[right]);--right;}//情況2:小的放左邊,此時的交換值是確定的,交換后left和cur均后移else if (a[cur] < key){Swap(&a[left], &a[cur]);++left;++cur;}//情況3:與key相等的值推到中間,cur繼續后移遍歷else{++cur;}}// 此時的區間:[begin,left-1][left,right][righ+1,end]//遞歸左右亂序序列QuickSort(a, begin, left - 1);QuickSort(a, right + 1, end);
}
算法總結:
? 三路劃分的算法思想在解決序列中包含多個重復數據的時候效率很好,其他場景就比較一般。但是三路劃分思路還是很有價值的,有些快排思想變形體,要用劃分去選數,他能保證和key相等的數都排到中間去,三路劃分的價值就可以提現出來了。
3.3.4.3 introsort的快速排序
? 快排是會受到數據樣本的分布和形態的影響的,所以經常有的時候遇到一些特殊數據的數組,如大量重復數據的數組,因為快排需要選key,每次key都選到重復數據就會導致key將序列分割的很偏,就會出現效率退化的問題。
? 無論是hoare、lomuto還是三路劃分他們的思想在特殊場景下效率會退化,比如在選key的時候大多數都選擇了接近最小或者最大值,導致劃分不均衡,效率退化。
? 因為以上情況的出現,所以introsort誕生了,introsort是由David Musser在1997年設計的排序算法,C++sgi STLsort中就是用的 introspectivesort (內省排序) 思想實現的。內省排序可以認為不受數據分布的影響,無論什么原因劃分不均勻,導致遞歸深度太深,他就是轉換堆排了,堆排不受數據分布影響。
基本思路:
- 如果快排遞歸深度太深**(sgi stl 中使用的是深度為2倍元素數量的對數值)**,也就是
depth大于 2 ? l o g n 2*logn 2?logn ,則說明在這種數據序列下,選key出現了問題,性能在快速退化,就不再進行快排分割遞歸了,改為堆排序。
示例代碼:
/*** Note: The returned array must be malloced, assume caller calls free().*///堆排序的實現
//交換函數
void Swap(int* x, int* y)
{int tmp = *x;*x = *y;*y = tmp;
}//堆的向下調整算法
void AdjustDown(int* a, int n, int parent)
{int child = parent * 2 + 1;while (child < n){// 選出左右孩?中?的那?個 if (child + 1 < n && a[child + 1] > a[child]){++child;}if (a[child] > a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}//實現堆排序
void HeapSort(int* a, int n)
{// 建堆 -- 向下調整建堆 for (int i = (n - 1 - 1) / 2; i >= 0; --i){AdjustDown(a, n, i);}int end = n - 1;while (end > 0){Swap(&a[end], &a[0]);AdjustDown(a, end, 0);--end;}
}//直接插入算法
void InsertSort(int* a, int n)
{for (int i = 1; i < n; i++){int end = i-1;int tmp = a[i];// 將tmp插?到[0,end]區間中,保持有序 while (end >= 0){if (tmp < a[end]){a[end + 1] = a[end];--end;}else{break;}}a[end + 1] = tmp;}
}//Introsort排序
void IntroSort(int* a, int left, int right, int depth, int defaultDepth)
{//保證序列有效if (left >= right)return;// 數組長度?于16的?數組,換為插?排序,簡單遞歸次數 if(right - left + 1 < 16){InsertSort(a+left, right-left+1);return; }// 當深度超過2*logN時改用堆排序 if(depth > defaultDepth){HeapSort(a+left, right-left+1);return;}depth++;//常規情況使用lomuto快速排序//下標初始化int begin = left;int end = right;// 隨機選key int randi = left + (rand() % (right-left + 1));Swap(&a[left], &a[randi]);//參量初始化int prev = left;int cur = prev + 1;int keyi = left;while (cur <= right){if (a[cur] < a[keyi] && ++prev != cur){Swap(&a[prev], &a[cur]);}++cur;}Swap(&a[prev], &a[keyi]);keyi = prev;//遍歷左右亂序序列// [begin, keyi-1] keyi [keyi+1, end]IntroSort(a, begin, keyi - 1, depth, defaultDepth);IntroSort(a, keyi+1, end, depth, defaultDepth);
}//快速排序入口函數
void QuickSort(int* a, int left, int right)
{//初始化參數int depth = 0; //參數int logn = 0; //數組大小 N 的對數(基數為2)int N = right-left+1;//數組大小//求數組長度N的是2的多少次方,求將數組放入二叉樹的層數for(int i = 1; i < N; i *= 2){logn++;}// introspective sort -- ?省排序 IntroSort(a, left, right, depth, logn*2);
}//對整數數組 nums 進行排序,并返回排序后的數組
int* sortArray(int* nums, int numsSize, int* returnSize)
{//隨機數取keysrand(time(0));QuickSort(nums, 0, numsSize-1);*returnSize = numsSize;return nums;
}
算法總結:
- 本質上就是根據數據的實時情況,選擇不同的排序算法,增強程序的效率和適應性。
3.4 歸并排序
基本思想:
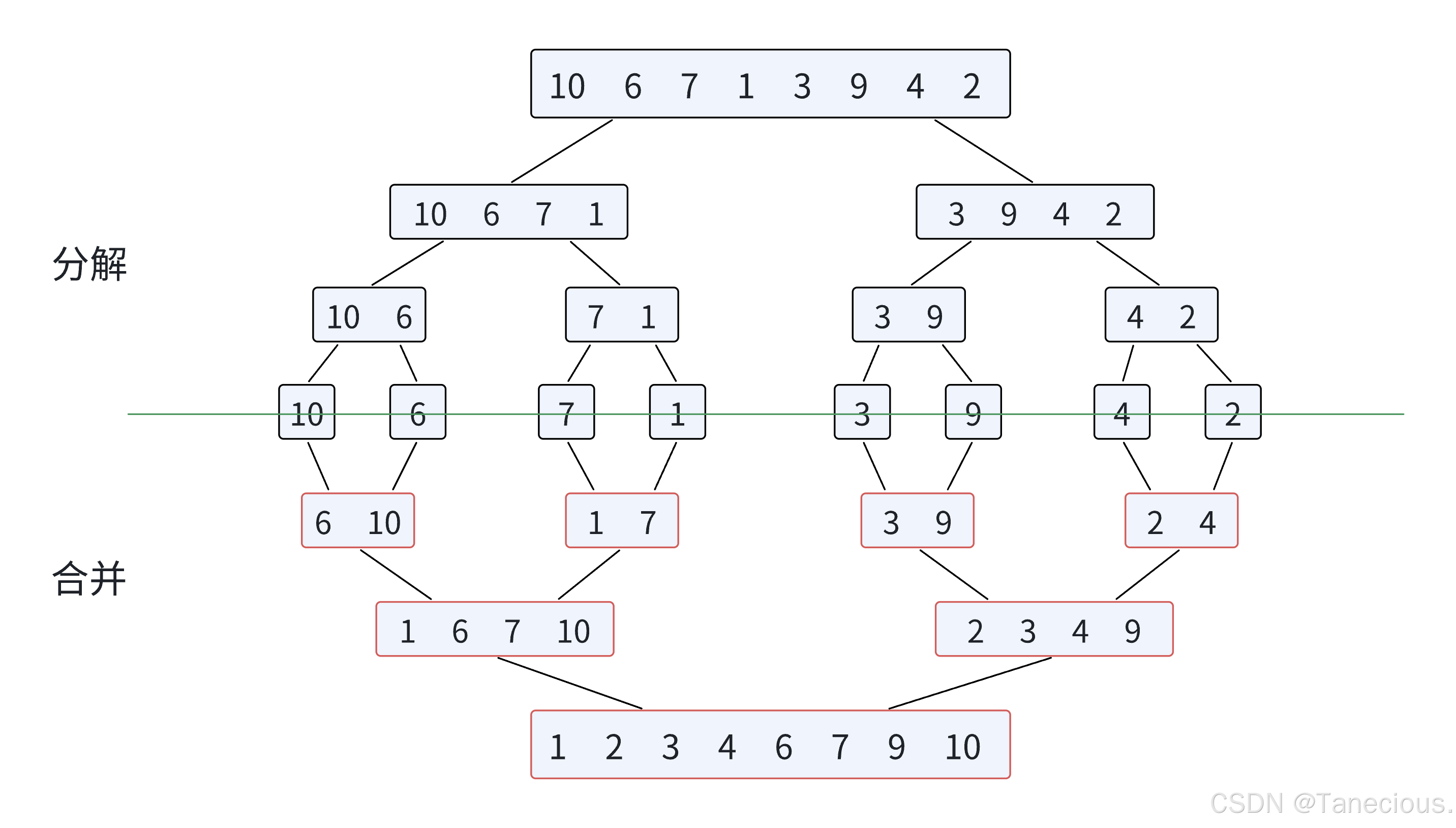
歸并排序(MERGE-SORT)是建立在歸并操作上的一種有效的排序算法,該算法是采用分治法(Divide and Conquer)的一個非常典型的應用。將已有序的子序列合并,得到完全有序的序列;即先使每個子序列有序,再使子序列段間有序。若將兩個有序表合并成一個有序表,稱為二路歸并。歸并排序核心步驟:
3.4.1 思路詳解
基本思想的核心總結:將已有序的子序列合并,從而得到完全有序的序列,即先讓每個子序列有序,再使子序列段間有序。
-
分解:
先將亂序序列通過 m i d = ( r i g h t + l e f t ) / 2 mid = (right + left)/2 mid=(right+left)/2 獲取中間位置的下標,將序列從中間
mid開始分為兩個序列,再不斷遞歸循環,直到將數據分為一個個零散的數據(此時這個數據可以看做一個left等于right的序列) -
合并:
每次合并都是兩個有序序列進行合并。
對于要合并的兩個序列用
begin1和end1、begin2和end2分別來表示這兩個序列的首位數據。之后再利用兩個序列的begin下標不斷遍歷序列按順序循環取出較小的數據,放入臨時數組tmp中,最后利用end作為截止循環的條件,最后將完整的有序數組tmp賦給arr。
3.4.2 示例代碼
//歸并排序
//子函數
void _MergeSort(int* arr,int left,int right,int* tmp)
{//非有效區間if (left >= right){return;}//找中間下標int mid = (left + right) / 2;//遞歸分割序列//左序列:[left,mid] 右序列:[mid+1,right]_MergeSort(arr, left, mid, tmp);_MergeSort(arr, mid + 1, right, tmp);//合并序列//左序列:[left,mid] 右序列:[mid+1,right]int begin1 = left, end1 = mid;int begin2 = mid + 1, end2 = right;//用于指示tmp數組數據下標int index = left;//合并兩個有序序列while (begin1 <= end1 && begin2 <= end2){if (arr[begin1] < arr[begin2]){tmp[index++] = arr[begin1++];}else {tmp[index++] = arr[begin2++];}}//要么begin1越界 要么begin2越界while (begin1 <= end1){tmp[index++] = arr[begin1++];}while (begin2 <= end2){tmp[index++] = arr[begin2++];}//把tmp中的數據拷貝回arr中for (int i = left; i < right; i++){arr[i] = tmp[i];}
}//主函數
void MergeSort(int* arr, int n)
{//動態創建一個臨時數組,用于排序int* tmp = (int*)malloc(sizeof(int) * n);//執行子函數_MergeSort(arr, 0, n - 1, tmp);free(tmp);
}
時間復雜度: O ( N l o g N ) O(NlogN) O(NlogN)??空間復雜度: O ( N ) O(N) O(N)
3.4.4 知識補充:文件排序
? 以上介紹了很多種排序算法,但是基本都是基于內排序,均是基于內存中的進行的,但是在排序中面對數量極多的序列,上述的排序算法都是無法實現的,但是歸并排序是可以實習的。
下面先簡單介紹一下內排序、外排序:
- **內排序:**數據量相對少一些,可以放到內存中進行排序。
- **外排序:**數據量較大,內存中放不下,數據只能放到磁盤文件中,需要排序。
基本思路:
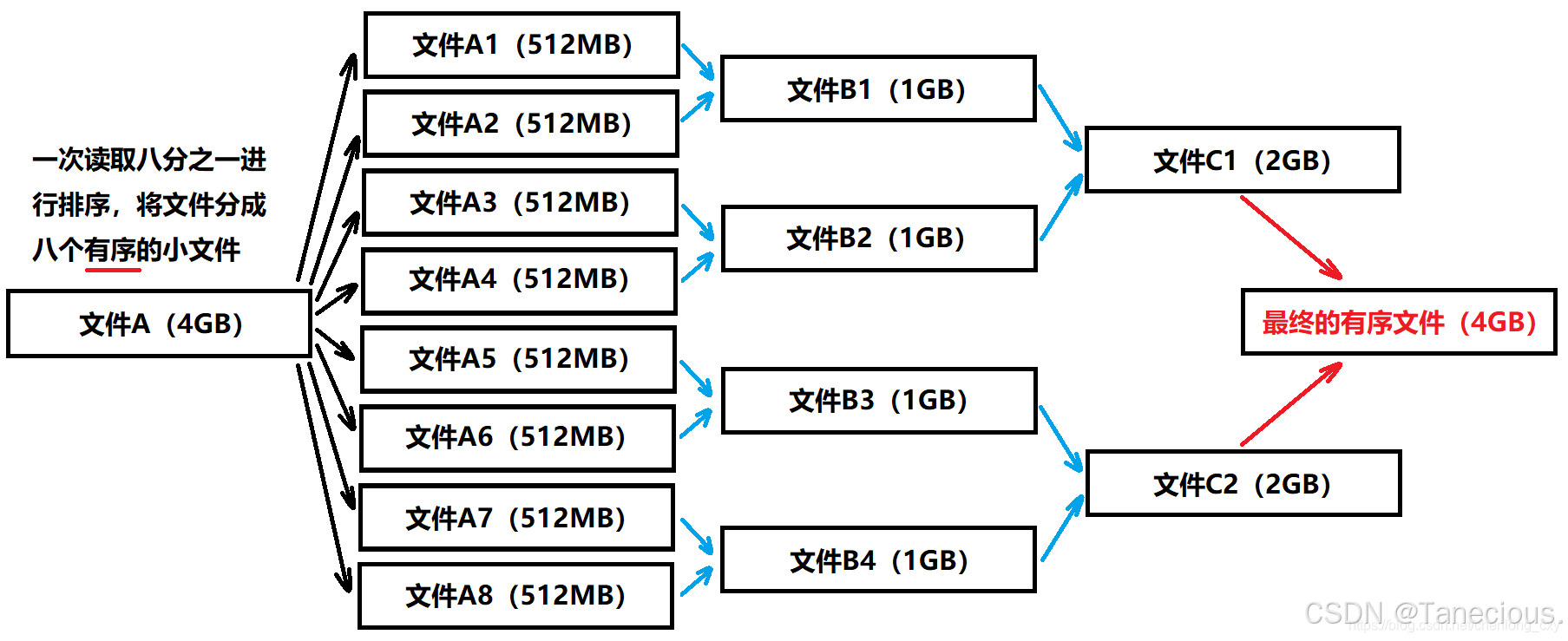
假設現在有10億個整數(4GB)存放在文件A中,需要我們進行排序,而內存一次只能提供512MB空間,歸并排序解決該問題的基本思路如下:
合并思路1:
- 每次從文件A中讀取八分之一,即512MB到內存中進行排序(內排序),并將排序結果寫入到一個文件中,然后再讀取八分之一,重復這個過程。那么最終會生成8個各自有序的小文件(A1~A8)。
- 對生成的8個小文件進行11合并,最終8個文件被合成為4個,然后再11合并,就變成2個文件了,最后再進行一次11合并,就變成1個有序文件了。
合并思路2:
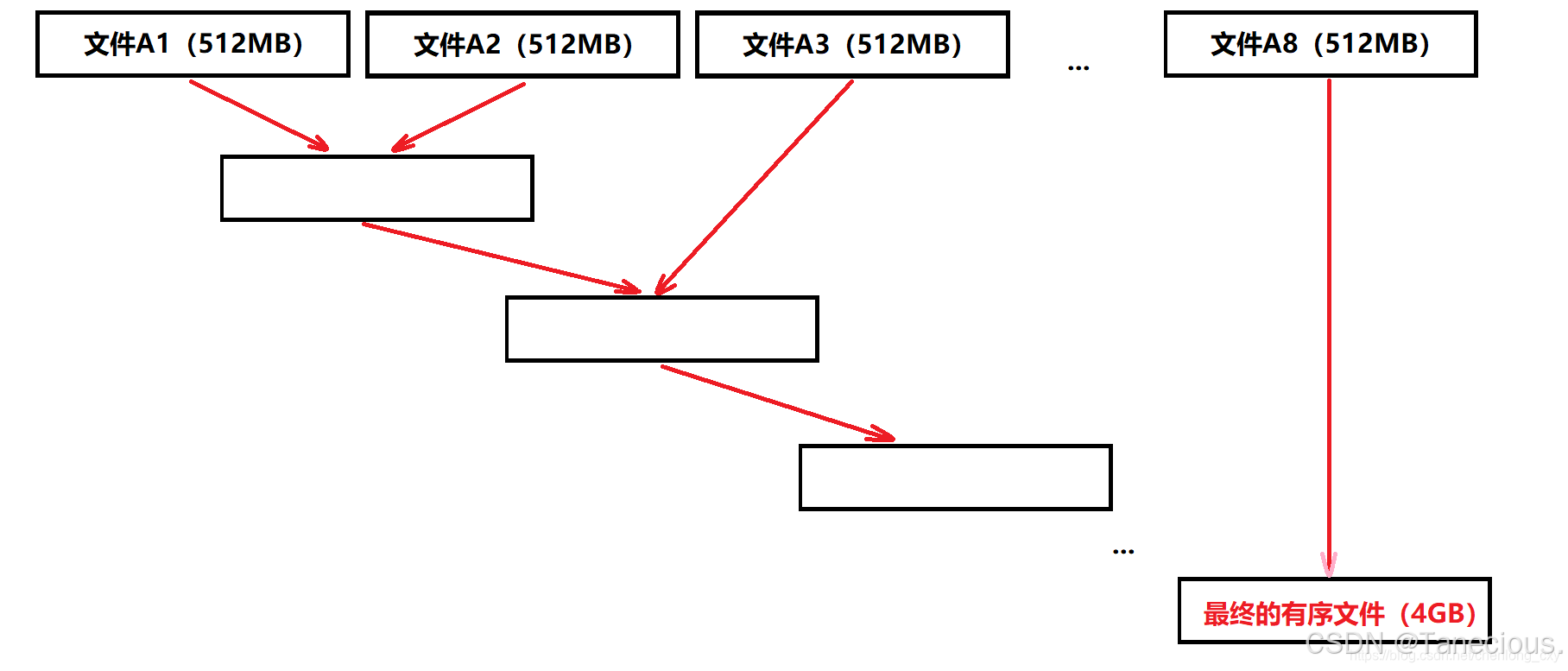
- 每次從文件A中讀取八分之一,即512MB到內存中進行排序(內排序),并將排序結果寫入到一個文件中,然后再讀取八分之一,重復這個過程。那么最終會生成8個各自有序的小文件(A1~A8)。
- 對生成的8小文件,按順序第一次先歸并排序前兩個小文件,形成一個新的文件,再將新的文件和第三個小文件進行歸并排序,不斷合并,最后變成一個有序文件。
示例代碼:
下面的示例代碼,是按照合并思路2編寫:
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<time.h>
#include<stdlib.h>// 創建N個隨機數,寫到文件中
void CreateNDate()
{// 創造一千萬個數據int n = 10000000;srand(time(0));const char* file = "data.txt";FILE* fin = fopen(file, "w");if (fin == NULL){perror("fopen error");return;}//將生成的一千萬個數據寫進“data.txt”for (int i = 0; i < n; ++i){int x = rand() + i;fprintf(fin, "%d\n", x);}fclose(fin);
}//作為qsort()函數的比較回調函數,用于控制qsort是排升序還是降序
int compare(const void* a, const void* b)
{return (*(int*)a - *(int*)b);
}//函數功能:從一個輸入文件讀取整數數據,將它們排序后寫入另一個文件
//函數參數:FILE* fout:輸入文件指針(從這里讀取數據)
// const char* file1:輸出文件名(排序后的數據將寫入此文件)
// 函數返回值:返回實際讀到的數據個數,沒有數據了,返回0
int ReadNDataSortToFile(FILE* fout, int n, const char* file1)
{int x = 0;//用于在內存中存放文件中的數據int* a = (int*)malloc(sizeof(int) * n);if (a == NULL){perror("malloc error");return 0;}// 想讀取n個數據,如果遇到文件結束(最后讀取的個數不滿n個),應該讀到j個int j = 0;for (int i = 0; i < n; i++){//將文件數據讀取到內存,并在內存申請的空間中進行排序if (fscanf(fout, "%d", &x) == EOF)break;a[j++] = x;}if (j == 0){free(a);return 0;}// 對內存中的數據進行排序,利用C語言內置qsort函數qsort(a, j, sizeof(int), compare);FILE* fin = fopen(file1, "w");if (fin == NULL){free(a);perror("fopen error");return 0;}// 寫回file1文件for (int i = 0; i < j; i++){fprintf(fin, "%d\n", a[i]);}free(a);fclose(fin);return j;
}//對文件進行排序歸并,將file1和file2歸并到mfile中
void MergeFile(const char* file1, const char* file2, const char* mfile)
{FILE* fout1 = fopen(file1, "r");if (fout1 == NULL){perror("fopen error");return;}FILE* fout2 = fopen(file2, "r");if (fout2 == NULL){perror("fopen error");return;}FILE* mfin = fopen(mfile, "w");if (mfin == NULL){perror("fopen error");return;}// 歸并邏輯int x1 = 0;int x2 = 0;//從兩個文件中不斷讀取數據int ret1 = fscanf(fout1, "%d", &x1);int ret2 = fscanf(fout2, "%d", &x2);//當兩個文件中有一個文件遇到文件末尾則跳出循環while (ret1 != EOF && ret2 != EOF){if (x1 < x2){fprintf(mfin, "%d\n", x1);ret1 = fscanf(fout1, "%d", &x1);}else{fprintf(mfin, "%d\n", x2);ret2 = fscanf(fout2, "%d", &x2);}}//文件2遇到文件末尾while (ret1 != EOF){fprintf(mfin, "%d\n", x1);ret1 = fscanf(fout1, "%d", &x1);}//文件1遇到文件末尾while (ret2 != EOF){fprintf(mfin, "%d\n", x2);ret2 = fscanf(fout2, "%d", &x2);}fclose(fout1);fclose(fout2);fclose(mfin);
}int main()
{//創造待排數據CreateNDate();//設置const char* file1 = "file1.txt";const char* file2 = "file2.txt";const char* mfile = "mfile.txt";//"data.txt"用于存儲創造了一千萬個數據FILE* fout = fopen("data.txt", "r");if (fout == NULL){perror("fopen error");return;}//從data.txt中分別讀取一百萬個數據放進file1和file2中int m = 1000000;ReadNDataSortToFile(fout, m, file1);ReadNDataSortToFile(fout, m, file2);//開始循環歸并文件while (1){//將file1和file2歸并到mfile中MergeFile(file1, file2, mfile);// 刪除file1和file2remove(file1);remove(file2);// 重命名mfile為file1,將mfile當做新的file1繼續循環rename(mfile, file1);// 當再去讀取數據,一個都讀不到,說明已經沒有數據了,說明已經歸并完成,歸并結果在file1int n = 0;//此語句的功能1:從原始數據文件data.txt中讀取新的數據塊創建新的file2,繼續與新的file1歸并//此語句的功能2:用來檢測是否已經到data.txt的數據末尾,看是否需要結束循環if ((n = ReadNDataSortToFile(fout, m, file2)) == 0)break;//調試語句,可以此處打斷點觀察最后一次不滿n個數據時的排序結果/*if (n < 100){int x = 0;}*/}return 0;
}
3.5 非比較排序
3.5.1 計數排序
計數排序又稱為鴿巢原理,是對哈希直接定址法的變形應用。操作步驟:
- 統計相同元素出現次數
- 根據統計的結果將序列回收到原來的序列中
3.5.1.1 圖片理解
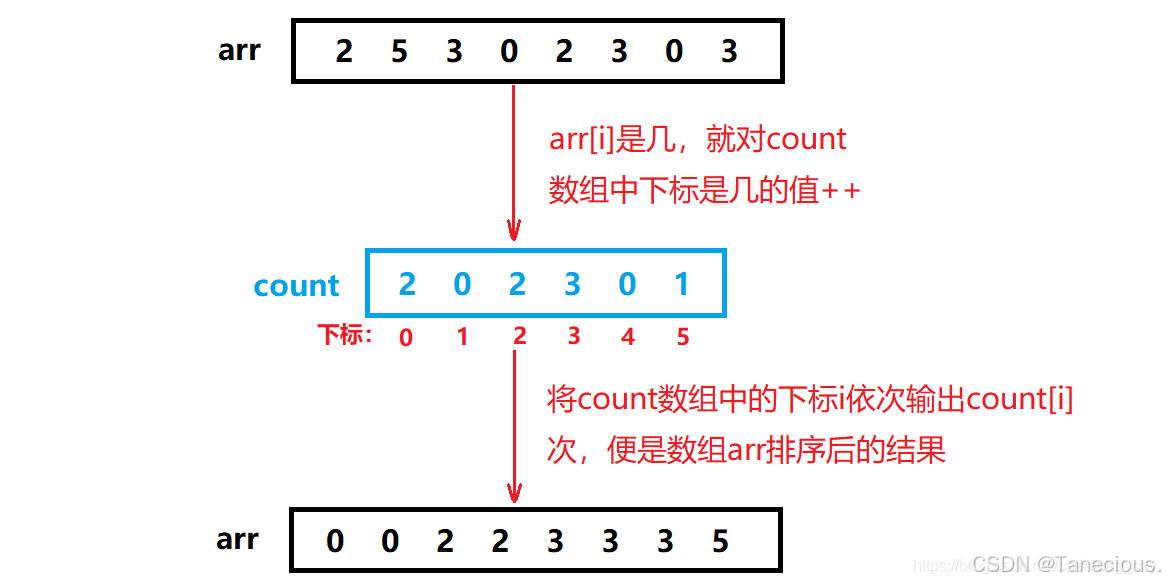
? 上圖這種映射關系是絕對映射,即arr數組中的元素是幾就在count數組中下標為幾的位置++,但這樣會造成空間浪費。例如,要將數組:1020,1021,1018,進行排序,難道需要開辟1022個整型空間嗎?
? 所以在計數排序中,一般使用相對映射。即**數組中的最小值就相對于count數組中的0下標,數組中的最大值就相對于count數組中的最后一個下標。**這樣,對于數組:1020,1021,1018,就只需要開辟用于儲存4個整型的空間大小了,此時count數組中下標為i的位置記錄的實際上是1018+i這個數出現的次數。
綜上所述:
- 絕對映射:count數組中下標為i的位置記錄的是arr數組中數字i出現的次數。
- 相對映射:count數組中下標為i的位置記錄的是arr數組中數字min+i出現的次數。
3.5.1.2 代碼示例
//計數排序
void CountSort(int* arr, int n)
{//根據最大值最小值確定數組大小(相對映射)int max = arr[0], min = arr[0];//打擂臺,遍歷數組確定最大值與最小值for (int i = 1; i < n; i++){if (arr[i] > max){max = arr[i];}if (arr[i] < min){min = arr[i];}}//確定數組大小,并申請對應空間int range = max - min + 1;int* count = (int*)malloc(sizeof(int) * range);if (count == NULL){perror("malloc fail!");exit(1);}//初始化range數組中所有的數據為0memset(count, 0, range * sizeof(int));//統計數組中每個數據出現的次數for (int i = 0; i < n; i++){count[arr[i] - min]++;}//取count中的數據,往arr中放int index = 0;for (int i = 0; i < range; i++){while (count[i]--){arr[index++] = i + min;}}
}
時間復雜度: O ( N + r a n g e ) O(N+range) O(N+range)??空間復雜度: O ( r a n g e ) O(range) O(range)
3.6 測試代碼:排序性性能的對比
為了更加直觀地顯示各個排序的性能和排序速度,下面的代碼通過生成十萬個隨機數,并利用上述排序算法對這個十萬個隨機數的亂序序列進行排序,并記錄下時間,打印在屏幕上。
// 測試排序的性能對?
void TestOP()
{ //生成十萬個隨機數srand(time(0)); const int N = 100000; //開辟承載十萬個隨機數的數組int* a1 = (int*)malloc(sizeof(int)*N); int* a2 = (int*)malloc(sizeof(int)*N); int* a3 = (int*)malloc(sizeof(int)*N); int* a4 = (int*)malloc(sizeof(int)*N); int* a5 = (int*)malloc(sizeof(int)*N); int* a6 = (int*)malloc(sizeof(int)*N); int* a7 = (int*)malloc(sizeof(int)*N); //將七個數組都變為同樣的內容,方便比較for (int i = 0; i < N; ++i) { a1[i] = rand(); a2[i] = a1[i]; a3[i] = a1[i]; a4[i] = a1[i]; a5[i] = a1[i]; a6[i] = a1[i];a7[i] = a1[i]; } //直接插入排序int begin1 = clock(); InsertSort(a1, N); int end1 = clock(); //希爾排序int begin2 = clock(); ShellSort(a2, N); int end2 = clock(); //直接選擇排序int begin3 = clock(); SelectSort(a3, N); int end3 = clock(); //堆排序int begin4 = clock(); HeapSort(a4, N); int end4 = clock(); //快速排序int begin5 = clock(); QuickSort(a5, 0, N-1); int end5 = clock(); //歸并排序int begin6 = clock(); MergeSort(a6, N); int end6 = clock(); //冒泡排序int begin7 = clock(); BubbleSort(a7, N); int end7 = clock();//顯示各個排序算法的時間printf("InsertSort:%d\n", end1 - begin1); printf("ShellSort:%d\n", end2 - begin2); printf("SelectSort:%d\n", end3 - begin3); printf("HeapSort:%d\n", end4 - begin4); printf("QuickSort:%d\n", end5 - begin5); printf("MergeSort:%d\n", end6 - begin6); printf("BubbleSort:%d\n", end7 - begin7); //釋放申請的空間free(a1); free(a2); free(a3); free(a4); free(a5); free(a6); free(a7);
}
4. 排序算法復雜度及穩定性分析
穩定性:假定在待排序的記錄序列中,存在多個具有相同的關鍵字的記錄,若經過排序,這些記錄的相對次序保持不變,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,則稱這種排序算法是穩定的;否則稱為不穩定的。
| 排序方法 | 平均情況 | 最好情況 | 最壞情況 | 輔助空間 | 穩定性 |
|---|---|---|---|---|---|
| 冒泡排序 | O ( n 2 ) O(n2) O(n2) | O ( n ) O(n) O(n) | O ( n 2 ) O(n2) O(n2) | O ( 1 ) O(1) O(1) | 穩定 |
| 直接選擇排序 | O ( n 2 ) O(n2) O(n2) | O ( n 2 ) O(n2) O(n2) | O ( n 2 ) O(n2) O(n2) | O ( 1 ) O(1) O(1) | 不穩定 |
| 直接插入排序 | O ( n 2 ) O(n2) O(n2) | O ( n ) O(n) O(n) | O ( n 2 ) O(n2) O(n2) | O ( 1 ) O(1) O(1) | 穩定 |
| 希爾排序 | O ( n l o g n ) ~ O ( n 2 ) O(n log n) \sim O(n2) O(nlogn)~O(n2) | O ( n l o g n ) ~ O ( n 2 ) O(n log n) \sim O(n2) O(nlogn)~O(n2) | O ( n 2 ) O(n2) O(n2) | O ( 1 ) O(1) O(1) | 不穩定 |
| 堆排序 | O ( n l o g n ) O(n log n) O(nlogn) | O ( n l o g n ) O(n log n) O(nlogn) | O ( n l o g n ) O(n log n) O(nlogn) | O ( 1 ) O(1) O(1) | 不穩定 |
| 歸并排序 | O ( n l o g n ) O(n log n) O(nlogn) | O ( n l o g n ) O(n log n) O(nlogn) | O ( n l o g n ) O(n log n) O(nlogn) | O ( n ) O(n) O(n) | 穩定 |
| 快速排序 | O ( n l o g n ) O(n log n) O(nlogn) | O ( n l o g n ) O(n log n) O(nlogn) | O ( n 2 ) O(n2) O(n2) | O ( l o g n ) ~ O ( n ) O(log n) \sim O(n) O(logn)~O(n) | 不穩定 |
本文中有多個插圖取自前輩2021dragon和愛寫代碼的搗蛋鬼
感謝前輩的知識分享,能讓我們這些后來者可以站在巨人的肩膀上不斷向前!!感謝閱讀!!



)
-Task2筆記)










核心操作與最佳實踐:深入解析與面試指南)


圖像和文字的?)
