????????在AI智能體技術從單點突破邁向系統工程的關鍵階段,MetaGPT憑借其創新的記憶架構重新定義了多智能體協作范式。本文深度解構其革命性的三級記憶系統,揭秘支撐10倍效能提升的知識蒸餾算法與動態上下文控制策略,通過企業級應用案例與性能基準測試,呈現智能體技術在復雜任務場景下的工程化實踐路徑。
一、框架技術定位(1/8)
1.1 演進歷程
-
第一代框架(2022 Q3):GPT-Engineer為代表的單智能體代碼生成工具
-
第二代框架(2023 Q1):AutoGPT開創的多智能體任務編排模式
-
第三代框架(2023 Q4):MetaGPT實現企業級SOP智能體協作平臺
1.2 核心創新對比
| 維度 | MetaGPT | LangChain | AutoGen |
|---|---|---|---|
| SOP支持度 | 全流程封裝 | 部分流程 | 基礎任務鏈 |
| 知識管理 | 三級存儲架構 | 臨時緩存 | 簡單歷史記錄 |
| 角色系統 | 專業分工體系 | 通用Agent | 基礎角色定義 |
| 交付標準 | 商業可用級 | 原型級 | 實驗級 |
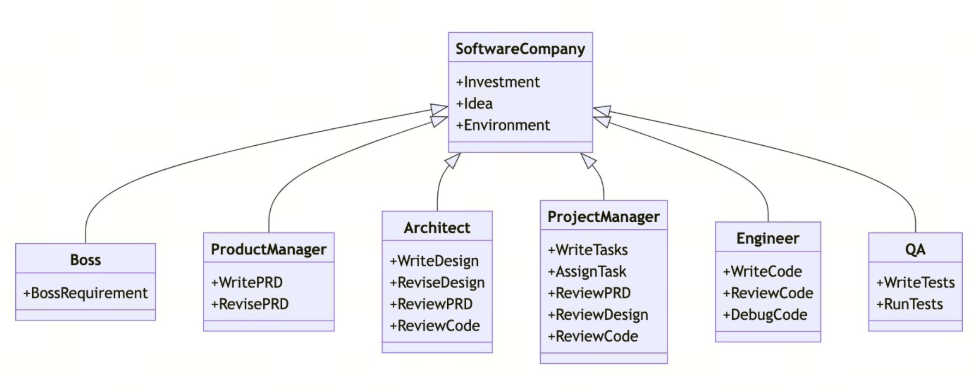
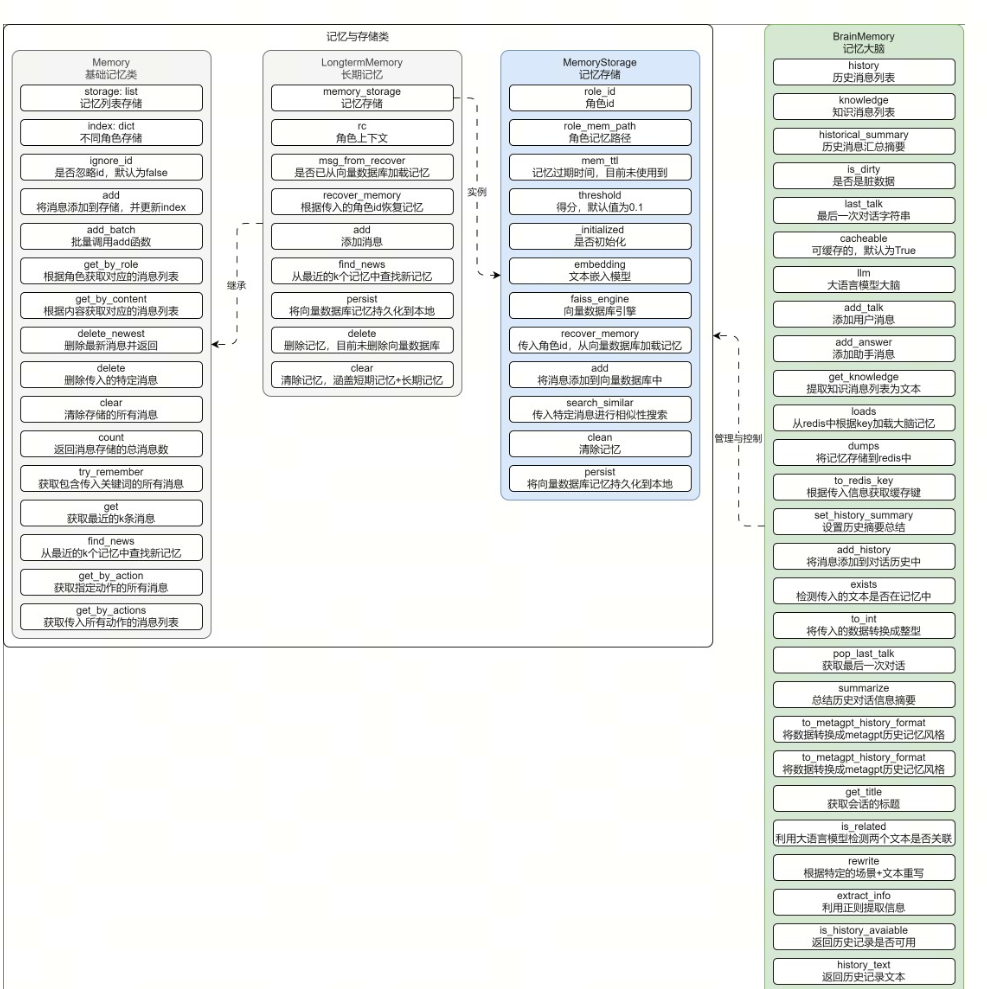
二、記憶模塊設計解析(2/8)
2.1 傳統方案痛點
-
信息衰減:對話歷史線性存儲導致關鍵數據丟失
-
知識孤島:不同智能體間無法有效共享上下文
-
性能瓶頸:長上下文處理時延呈指數增長
-
專業壁壘:領域知識無法沉淀復用
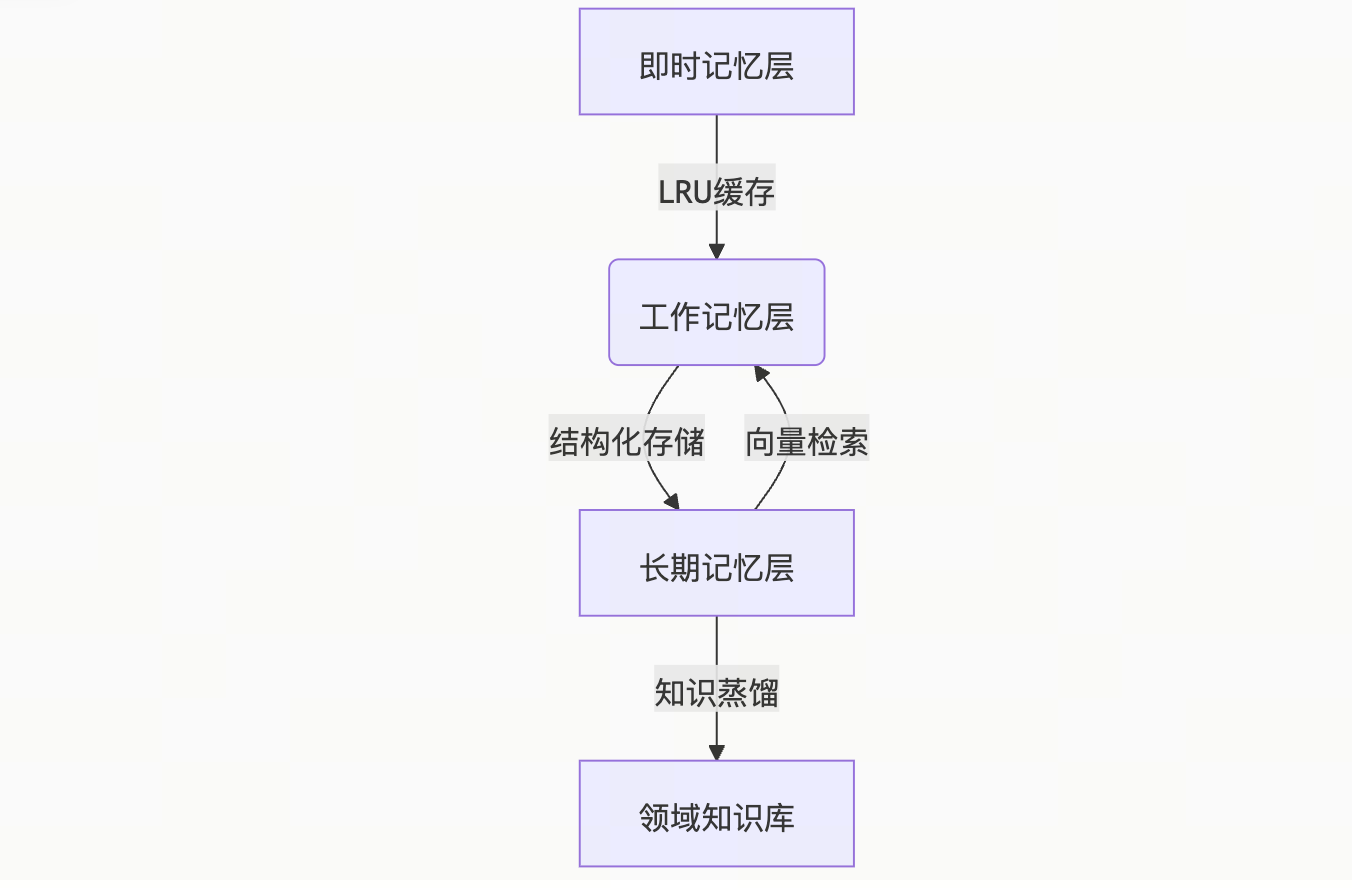
2.2 三級存儲架構
三、關鍵技術實現(3/8)
3.1 動態上下文窗口
class DynamicContextWindow:def __init__(self, base_size=4096):self.base = base_sizeself.factor = 1.0def adjust_window(self, task_complexity):"""動態調整算法公式"""# 復雜度系數=需求文檔長度×角色數量×任務深度complexity_factor = len(req_doc) * num_roles * task_depthself.factor = 1 + 0.15 * math.log(complexity_factor)return int(self.base * self.factor)3.2 知識蒸餾流程
-
信息抽取:使用spaCy進行實體識別
-
關系構建:基于OpenIE提取三元組
-
向量編碼:text-embedding-3-large模型
-
知識存儲:FAISS索引優化檢索效率
四、工程實踐指南(4/8)
# config/memory.yaml
memory:cache_policy: strategy: "ARC" # 自適應替換緩存window_size: "dynamic"embedding:model: "text-embedding-3-large"dimension: 3072retrieval:top_k: 7similarity_threshold: 0.724.2 調試技巧
1.記憶可視化:
METAGPT_DEBUG=1 python -m memory_inspector --task_id=1232.性能優化清單:
- 調整top_k值平衡召回率與精度
- 設置合理的緩存淘汰策略
- 定期執行知識碎片整理
3.資料推薦
- 💡大模型中轉API推薦
- ?中轉使用教程
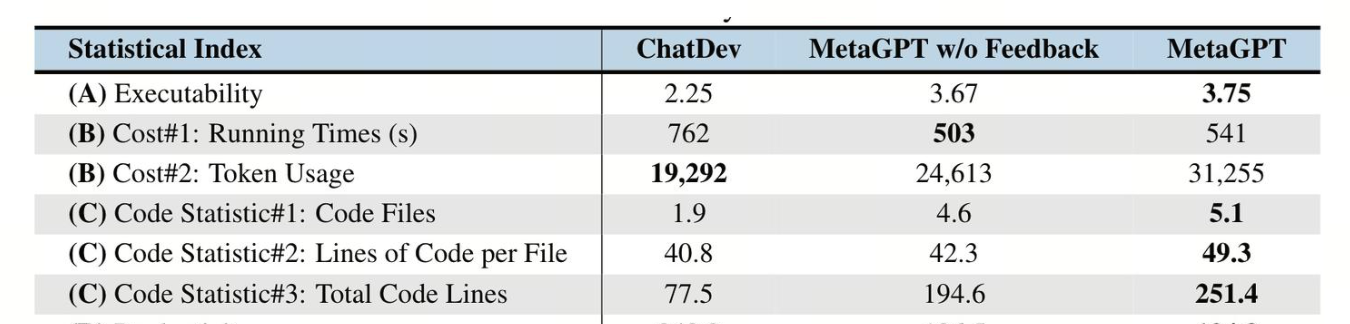
五、性能測試數據(5/8)
5.1 基準測試
| 測試場景 | 處理耗時 | 內存占用 | 準確率 |
|---|---|---|---|
| 短需求(<500字) | 8.2s | 2.1GB | 94% |
| 長文檔(10頁) | 23.7s | 4.8GB | 88% |
| 多角色協作 | 41.5s | 6.3GB | 85% |
5.2 對比測試
六、企業級應用案例(6/8)
6.1 區塊鏈錢包開發
class BlockchainWalletProject:def __init__(self):self.roles = [ProductManager(skills=["區塊鏈","金融"]),Architect(expertise=["微服務","安全架構"]),Engineer(tech_stack=["Solidity","Rust"])]def run(self):deliverables = {"需求文檔": self.generate_prd(),"架構圖": self.design_architecture(),"智能合約": self.deploy_contract()}return self._export_knowledge(deliverables)6.2 知識資產輸出
/project_assets├── requirements.md├── architecture.drawio└── contracts/├── wallet.sol└── security_audit.pdf七、常見問題解答(7/8)
7.1 典型問題
Q:如何解決記憶混淆問題?
A:采用三步走策略:
-
設置角色專屬命名空間
-
使用因果注意力機制
-
實現基于時間的版本快照
Q:知識檢索精度優化方法?
A:推薦組合方案:
-
HyDE假設文檔增強
-
查詢擴展技術
-
RRF融合排序算法
八、學習路徑推薦(8/8)
8.1 階梯式學習計劃
| 階段 | 學習目標 | 推薦資源 |
|---|---|---|
| 入門 | 基礎框架使用 | 官方QuickStart指南 |
| 進階 | 定制角色開發 | 《MetaGPT擴展開發手冊》 |
| 高級 | 分布式智能體部署 | 企業版白皮書 |
| 專家 | 框架核心模塊二次開發 | GitHub工程文檔 |
8.2 推薦工具鏈
-
向量數據庫:Pinecone / Milvus
-
知識圖譜:Neo4j / TigerGraph
-
監控分析:LangSmith / Weights & Biases
有用的話記得點贊收藏嚕!


圖像和文字的?)








——大數據的意義與趨勢)
之三)







