文章目錄
- 一、手寫數字識別的本質與挑戰
- 二、使用步驟
- 1.導入torch庫以及與視覺相關的torchvision庫
- 2.下載datasets自帶的手寫數字的數據集到本地
- 三、完整代碼展示
一、手寫數字識別的本質與挑戰
手寫數字識別的核心是:從二維像素矩陣中提取具有判別性的特征,區分 0-9 這 10 個類別。其難點包括:
手寫風格多樣性:不同人書寫的數字(如 “3” 可能有開口或閉口)、筆畫粗細、傾斜角度差異大。
位置與尺度變化:數字在圖像中的位置(偏上 / 偏下)、大小可能不一致(如 MNIST 數據集中數字存在輕微平移)。
噪聲與形變:實際場景中可能存在筆畫斷裂、污漬等噪聲,或掃描時的圖像模糊。
傳統方法(如 SVM、KNN)依賴人工設計特征(如 HOG、SIFT、幾何矩),需專家經驗且泛化能力有限;而 CNN 通過自動化特征學習 + 結構化歸納偏置,天然適配這些挑戰。
二、使用步驟
1.導入torch庫以及與視覺相關的torchvision庫
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
2.下載datasets自帶的手寫數字的數據集到本地
"""下載測試數據集(包含圖片和標簽)"""training_data=datasets.MNIST(root='../data',train=True,download=True,transform=ToTensor()
)"""下載測試數據集(包含訓練圖片+標簽)"""test_data=datasets.MNIST(root='../data',train=False,download=True,transform=ToTensor()
)
3、將下載的數據集打包
train_dataloder=DataLoader(training_data,batch_size=64)
test_dataloder=DataLoader(test_data,batch_size=64)
4、指定數據訓練的設備
device="cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"print(f"{device}device")
5、定義神經網絡框架和前向傳播
class NeurakNetwork(nn.Module): #通過調用類的形式來使用神經網絡,神經網絡的模型nn.moudledef __init__(self):super().__init__() #繼承父類的初始化self.flatten=nn.Flatten() #將二位數據展成一維數據self.hidden1=nn.Linear(28*28,128) #第一個參數時有多少個神經元傳進來,第二個參數是有多少個數據傳出去self.hidden2=nn.Linear(128,256)self.out=nn.Linear(256,10) #輸出必須與標簽類型相同,輸入必須是上一層神經元的個數def forward(self,x): #前向傳播,指明數據的流向,使神經網絡連接起來,函數名稱不能修改x=self.flatten(x)x=self.hidden1(x)x=torch.relu(x) #激活函數,torch使用relu或者tanh函數作為激活函數x=self.hidden2(x)x=torch.relu(x)x=self.out(x)return x
6、初始化神經網絡并將模型加載到設備中
model = NeurakNetwork().to(device) #將剛剛定義的模型傳入到GPU中7、定義模型訓練的函數
def train(dataloader,model,loss_fn,optimizer):model.train() #告訴模型,即將開始訓練,其中的w進行隨機化操作,已經更新w,在訓練過程中,w會被修改"""pytorch提供兩種方式來切換訓練和測試的模式,分別是model.train()和model.eval()一般用法是,在訓練開始之前寫上model.train(),在測試時寫上model.eval()"""batch_size_num=1for X,y in dataloader: #其中batch為每一個數據的編號X,y=X.to(device),y.to(device) #將訓練數據集和標簽傳入cpu和gpupred=model.forward(X)loss=loss_fn(pred,y) #通過交叉熵損失函數計算loss#Backpropagation 進來一個batch的數據,計算一次梯度,更新一次網絡optimizer.zero_grad() #梯度值清零loss.backward() #反向傳播計算得到的每個參數的梯度值woptimizer.step() #根據梯度更新網絡w參數loss_value=loss.item() #從tensor數據中提取數據出來,tensor獲取損失值if batch_size_num%100==0:print(f"loss:{loss_value:>7f}[number:{batch_size_num}]")batch_size_num+=1
8、定義測試的函數
def test(dataloader,model,loss_fn):size=len(dataloader.dataset)num_batches=len(dataloader)model.eval()test_loss,correct=0,0with torch.no_grad():for X,y in dataloader:X,y=X.to(device),y.to(device)pred=model.forward(X)test_loss+=loss_fn(pred,y).item()correct +=(pred.argmax(1)==y).type(torch.float).sum().item()a=(pred.argmax(1)==y)b=(pred.argmax(1)==y).type(torch.float)test_loss/=num_batchescorrect/=sizeprint(f"Test result:\n Accurracy:{(100*correct)}%,AVG loss:{test_loss}")9、初始化損失函數創建優化器
loss_fn=nn.CrossEntropyLoss() #創建交叉熵損失函數對象,適合做多分類optimizer=torch.optim.SGD(model.parameters(),lr=0.01) #創建優化器,使用SGD隨機梯度下降10、調用訓練和測試的函數,完成訓練一次測試一次
train(train_dataloder,model,loss_fn,optimizer) #訓練一次完整的數據,多輪訓練
test(test_dataloder,model,loss_fn)
11、訓練20輪,測試一次
epochs=20
for epoch in range(epochs):train(train_dataloder,model,loss_fn,optimizer)print(f"epoch{epoch}")
test(test_dataloder,model,loss_fn)
三、完整代碼展示
"""手寫數字識別"""
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor"""下載測試數據集(包含圖片和標簽)"""training_data=datasets.MNIST(root='../data',train=True,download=True,transform=ToTensor()
)"""下載測試數據集(包含訓練圖片+標簽)"""test_data=datasets.MNIST(root='../data',train=False,download=True,transform=ToTensor()
)
print(len(training_data))"""展示手寫圖片,把訓練集中的前59000張圖片展示一下"""
from matplotlib import pyplot as plt
figure=plt.figure()
for i in range(9):img,label=training_data[i+59000]figure.add_subplot(3,3,i+1)plt.title(label)plt.axis("off")plt.imshow(img.squeeze(),cmap='gray')a=img.squeeze()
plt.show()train_dataloder=DataLoader(training_data,batch_size=64)
test_dataloder=DataLoader(test_data,batch_size=64)device="cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"print(f"{device}device")"""self參數理解:在類內部開辟出了一個共享空間,所有被定義在這片空間的參數都能夠使用self.參數名來調用"""class NeurakNetwork(nn.Module): #通過調用類的形式來使用神經網絡,神經網絡的模型nn.moudledef __init__(self):super().__init__() #繼承父類的初始化self.flatten=nn.Flatten() #將二位數據展成一維數據self.hidden1=nn.Linear(28*28,128) #第一個參數時有多少個神經元傳進來,第二個參數是有多少個數據傳出去self.hidden2=nn.Linear(128,256)self.out=nn.Linear(256,10) #輸出必須與標簽類型相同,輸入必須是上一層神經元的個數def forward(self,x): #前向傳播,指明數據的流向,使神經網絡連接起來,函數名稱不能修改x=self.flatten(x)x=self.hidden1(x)x=torch.relu(x) #激活函數,torch使用relu或者tanh函數作為激活函數x=self.hidden2(x)x=torch.relu(x)x=self.out(x)return xmodel = NeurakNetwork().to(device) #將剛剛定義的模型傳入到GPU中
print(model)def train(dataloader,model,loss_fn,optimizer):model.train() #告訴模型,即將開始訓練,其中的w進行隨機化操作,已經更新w,在訓練過程中,w會被修改"""pytorch提供兩種方式來切換訓練和測試的模式,分別是model.train()和model.eval()一般用法是,在訓練開始之前寫上model.train(),在測試時寫上model.eval()"""batch_size_num=1for X,y in dataloader: #其中batch為每一個數據的編號X,y=X.to(device),y.to(device) #將訓練數據集和標簽傳入cpu和gpupred=model.forward(X)loss=loss_fn(pred,y) #通過交叉熵損失函數計算loss#Backpropagation 進來一個batch的數據,計算一次梯度,更新一次網絡optimizer.zero_grad() #梯度值清零loss.backward() #反向傳播計算得到的每個參數的梯度值woptimizer.step() #根據梯度更新網絡w參數loss_value=loss.item() #從tensor數據中提取數據出來,tensor獲取損失值if batch_size_num%100==0:print(f"loss:{loss_value:>7f}[number:{batch_size_num}]")batch_size_num+=1def test(dataloader,model,loss_fn):size=len(dataloader.dataset)num_batches=len(dataloader)model.eval()test_loss,correct=0,0with torch.no_grad():for X,y in dataloader:X,y=X.to(device),y.to(device)pred=model.forward(X)test_loss+=loss_fn(pred,y).item()correct +=(pred.argmax(1)==y).type(torch.float).sum().item()a=(pred.argmax(1)==y)b=(pred.argmax(1)==y).type(torch.float)test_loss/=num_batchescorrect/=sizeprint(f"Test result:\n Accurracy:{(100*correct)}%,AVG loss:{test_loss}")loss_fn=nn.CrossEntropyLoss() #創建交叉熵損失函數對象,適合做多分類optimizer=torch.optim.Adam(model.parameters(),lr=0.01) #創建優化器,使用Adam優化器#params:要訓練的參數,一般傳入的都是model.parameters()
#lr是指學習率,也就是步長#loss表示模型訓練后的輸出結果與樣本標簽的差距,如果差距越小,就表示模型訓練越好,越逼近于真實的模型
train(train_dataloder,model,loss_fn,optimizer) #訓練一次完整的數據,多輪訓練
test(test_dataloder,model,loss_fn)epochs=20
for epoch in range(epochs):train(train_dataloder,model,loss_fn,optimizer)print(f"epoch{epoch}")
test(test_dataloder,model,loss_fn)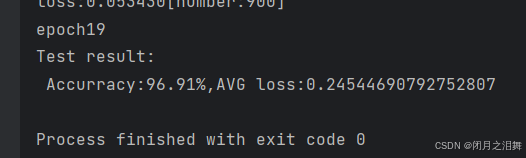
可以看到經過20輪的訓練模型的正確率為96.91%。




——大數據的意義與趨勢)
之三)













