目錄
- 前言
- 1. Kafka:流數據的傳輸平臺
- 1.1 Kafka概述
- 1.2 Kafka的應用場景
- 1.3 Kafka的特點
- 2. HBase:分布式列式數據庫
- 2.1 HBase概述
- 2.2 HBase的應用場景
- 2.3 HBase的特點
- 3. Hadoop:大數據處理的基石
- 3.1 Hadoop概述
- 3.2 Hadoop的應用場景
- 3.3 Hadoop的特點
- 4. Flink:流數據處理的利器
- 4.1 Flink概述
- 4.2 Flink的應用場景
- 4.3 Flink的特點
- 5. Spark:高性能的大數據處理平臺
- 5.1 Spark概述
- 5.2 Spark的應用場景
- 5.3 Spark的特點
- 6. Lambda架構與Kappa架構:大數據處理架構的選擇
- 6.1 Lambda架構概述
- 6.2 Lambda架構的應用場景
- 6.3 Kappa架構概述
- 6.4 Kappa架構的應用場景
- 結語
前言
隨著信息技術的不斷發展,大數據已經成為推動社會各行各業進步的重要力量。無論是互聯網公司還是傳統企業,都在通過大數據技術實現對海量數據的存儲、處理和分析,以獲取有價值的商業洞察。大數據的技術生態系統極為復雜,其中包含了多個關鍵的技術工具和架構。本文將對大數據領域中的幾大核心技術——Kafka、HBase、Hadoop、Flink、Spark、Lambda架構與Kappa架構進行深入探討,幫助讀者更好地理解這些技術的作用、應用場景及其相互關系。
1. Kafka:流數據的傳輸平臺
1.1 Kafka概述
Apache Kafka 是一個分布式的流媒體平臺,主要用于構建實時數據管道和流應用。它可以處理大規模的、實時生成的消息數據,并且具備高吞吐量、低延遲和高可靠性等優點。Kafka的核心功能包括消息發布與訂閱、存儲、以及流數據處理,這使得它成為現代大數據架構中不可或缺的一部分。

1.2 Kafka的應用場景
Kafka通常用于實時數據的傳輸和流式處理,能夠為數據傳輸提供高效、穩定的支持。具體應用場景包括:
- 日志收集與傳輸:將應用程序、操作系統或硬件的日志數據實時傳輸到集中式存儲系統。
- 實時分析:將流數據傳遞給后端的實時分析平臺,以便快速獲取實時洞察。
- 事件驅動架構:Kafka作為事件消息的載體,支持微服務架構中各個服務之間的異步通信。
1.3 Kafka的特點
Kafka在處理大規模數據傳輸時,展現出了極高的性能和可靠性。它支持消息的持久化存儲,并能夠高效地處理海量的數據流。Kafka的分布式架構使得其具備極高的擴展性,可以根據需求靈活增加節點。
2. HBase:分布式列式數據庫
2.1 HBase概述
Apache HBase 是一個開源的、分布式的列式存儲數據庫,設計之初旨在為大規模的結構化數據提供高效的存儲和快速訪問。HBase基于Google的Bigtable架構,支持實時隨機讀寫操作,并能夠處理PB級的數據。
2.2 HBase的應用場景
HBase廣泛應用于需要存儲和訪問大量結構化數據的場景,如社交網絡、金融交易、電商平臺等。它能夠高效地處理需要高并發、低延遲的查詢需求。以下是一些典型的應用場景:
- 實時數據存儲:對于需要頻繁讀寫操作的數據集,HBase提供了快速的數據存儲和檢索能力。
- 物聯網數據存儲:在物聯網領域,大量的傳感器數據和設備日志需要以高效的方式存儲,HBase能夠滿足這些需求。
- 大數據分析:通過與Hadoop生態系統中的其他工具(如MapReduce、Hive)結合使用,HBase能夠支持復雜的大數據分析任務。
2.3 HBase的特點
HBase采用列式存儲模式,相比傳統的行式存儲,能夠更高效地存儲稀疏數據,并提升特定列的查詢性能。它支持分布式存儲,數據在多臺機器上分片存儲,并具有高容錯性。
3. Hadoop:大數據處理的基石
3.1 Hadoop概述
Hadoop是一個開源的分布式計算框架,旨在處理海量數據。它由HDFS(Hadoop Distributed File System)和MapReduce計算模型兩部分組成,前者負責數據的存儲,后者負責數據的計算。Hadoop具有良好的擴展性,能夠通過增加節點來提升計算和存儲能力。
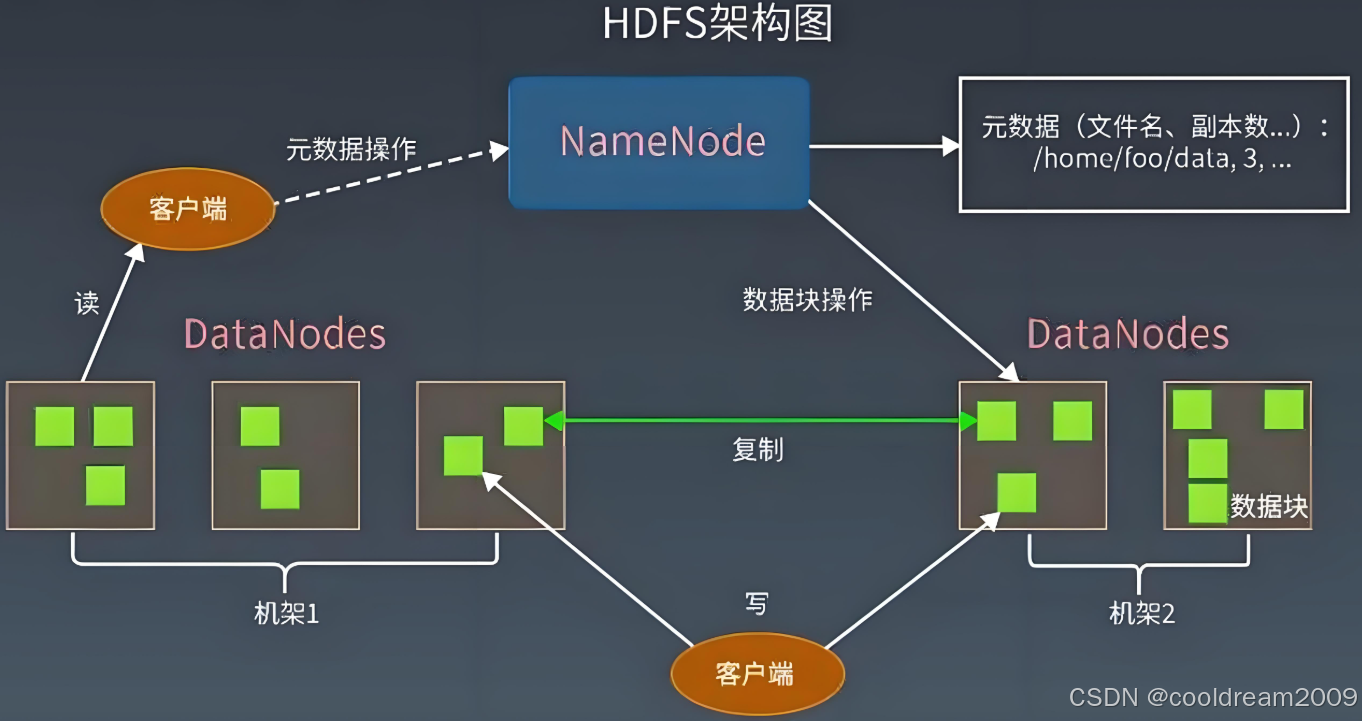
3.2 Hadoop的應用場景
Hadoop主要用于批量數據處理,是傳統大數據處理架構的核心。典型的應用場景包括:
- 批量數據處理:Hadoop適用于大規模的數據處理,尤其是需要長期存儲和處理的數據集。
- 數據倉庫:許多公司使用Hadoop作為數據倉庫的基礎架構,用于處理和分析大量的歷史數據。
- 數據分析與挖掘:Hadoop能夠處理復雜的分析任務,如數據清洗、數據轉換和數據整合。
3.3 Hadoop的特點
Hadoop能夠在分布式環境中高效地進行數據存儲和處理。HDFS能夠將大數據集分成多個數據塊并存儲在集群中,而MapReduce則負責并行處理這些數據塊,極大提高了處理效率。Hadoop支持橫向擴展,適用于大規模的數據分析。
4. Flink:流數據處理的利器
4.1 Flink概述
Apache Flink 是一個開源的分布式流處理框架,主要用于處理大規模、低延遲的實時數據流。Flink在設計上更加關注于流數據的處理,支持復雜的事件處理和實時數據分析。
4.2 Flink的應用場景
Flink廣泛應用于金融、電商、物聯網等領域,主要用于實時數據處理。以下是一些常見的應用場景:
- 實時數據監控:實時監控生產環境、網絡流量或金融交易等數據流,進行即時警報和響應。
- 實時推薦系統:通過分析用戶行為數據,實時生成推薦內容。
- 實時數據分析:分析實時產生的日志、傳感器數據等,提供即時決策支持。
4.3 Flink的特點
Flink支持低延遲、高吞吐量的實時數據處理,并且提供了強大的事件時間處理和水印機制。它可以處理無界數據流,并且支持事件驅動的計算模型,非常適合實時應用場景。
5. Spark:高性能的大數據處理平臺
5.1 Spark概述
Apache Spark 是一個快速、通用的分布式計算框架,旨在提供比MapReduce更高效的數據處理能力。Spark通過內存計算顯著提升了處理速度,同時它也支持批處理、流處理和機器學習等多種數據處理模式。
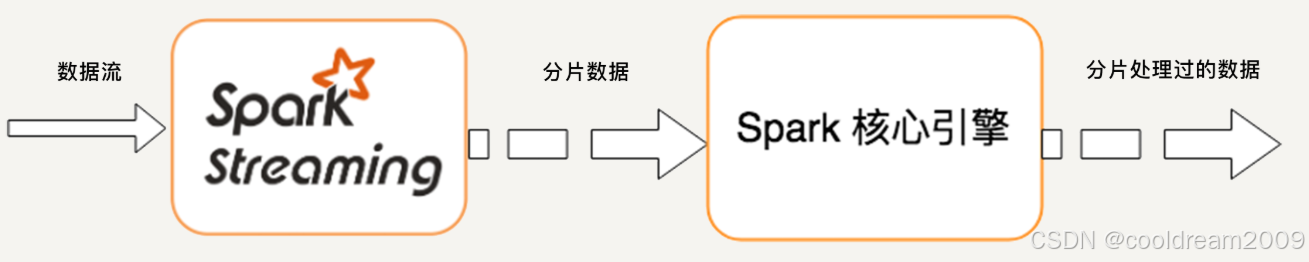
5.2 Spark的應用場景
Spark適用于多種大數據處理場景,特別是在需要高性能計算的任務中表現優異。常見的應用場景包括:
- 批量數據處理:Spark支持高效的批量數據處理,能夠快速完成大規模數據的計算任務。
- 流式數據處理:通過Spark Streaming,Spark能夠處理實時數據流并進行即時計算。
- 機器學習與圖計算:Spark提供了豐富的機器學習庫(MLlib)和圖計算庫(GraphX),適用于數據挖掘和智能分析。
5.3 Spark的特點
Spark的最大特點是支持內存計算,這使得它在處理大量數據時,比傳統的MapReduce更為高效。Spark具有豐富的API,支持Java、Scala、Python等多種編程語言,適用于各類大數據應用。
6. Lambda架構與Kappa架構:大數據處理架構的選擇
6.1 Lambda架構概述
Lambda架構是一種大數據處理架構,它通過結合批處理和實時處理來應對大數據中的復雜問題。Lambda架構將數據處理分為三個層次:批處理層、實時處理層和服務層。批處理層負責對歷史數據進行定期計算,實時處理層負責實時數據的處理,而服務層則合并來自這兩個層的數據,最終提供查詢接口。
6.2 Lambda架構的應用場景
Lambda架構適用于那些需要同時處理實時數據和批量數據的場景。常見的應用包括:
- 實時數據分析與歷史數據分析的結合:當需要既有實時分析結果,又要對歷史數據進行深度分析時,Lambda架構能夠提供兩者的統一解決方案。
- 日志處理與事件分析:許多企業使用Lambda架構來處理日志數據流和分析事件的趨勢。
6.3 Kappa架構概述
Kappa架構是對Lambda架構的簡化,它通過只使用一個流處理系統來處理所有數據。Kappa架構的核心思想是將所有數據流都視為流數據,不再區分批處理和實時處理。
6.4 Kappa架構的應用場景
Kappa架構適用于那些只需實時流處理的系統,特別是當數據處理任務可以通過流計算進行簡化時,Kappa架構更具優勢。常見應用場景包括:
- 實時數據處理與分析:實時處理和分析數據流,無需復雜的批處理過程。
- **事件驅動
的系統**:基于Kappa架構的系統通常用于處理大量事件流,如點擊流分析、傳感器數據等。
結語
大數據技術的快速發展,使得數據的存儲、處理和分析變得更加高效和靈活。從流處理平臺Kafka,到分布式存儲HBase,再到批量處理和流處理并重的Hadoop、Flink、Spark,最后到Lambda和Kappa架構的設計模式,每一項技術都在不斷推動大數據生態的進步。根據具體的應用場景選擇合適的技術組合,能夠幫助企業和開發者更好地應對大數據處理中的各種挑戰。隨著技術的不斷演進,我們也可以期待更高效、更智能的大數據處理架構的誕生。



















