創建數據庫
語法很簡單, 主要是看看選項(與編碼相關的):
CREATE DATABASE [IF NOT EXISTS] db_name [create_specification [,
create_specification] ...]
create_specification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name1. 語句中大寫的是關鍵字
2. [] 內的是可選項
3.??CHARACTER SET: 指定數據庫采用的字符集
4.?COLLATE: 指定數據庫字符集的校驗規則
1. 創建一個數據庫最簡單的命令為: create database db_name; --本質是在/var/lib/mysql/下創建一個目錄:
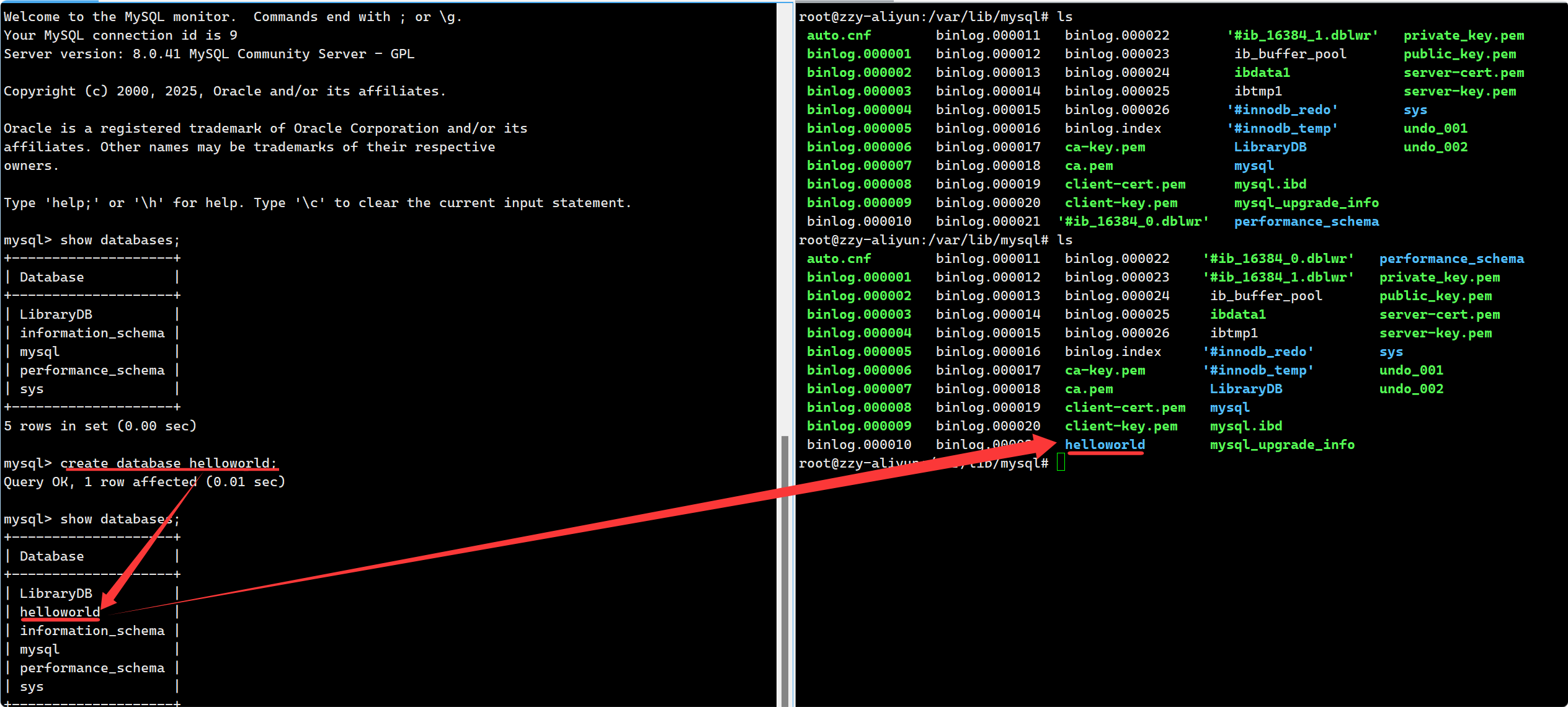
反過來, 在 mysql5.5下, 手動在該目錄下創建一個目錄, mysql 可以查詢到對應目錄名的數據庫. 但不應該這樣創建數據庫. 在 mysql 8 這樣做就不行了, 因為它采用 data dictionary(數據字典)去維護數據庫.
2. create database if not exist db_name, 如果要創建的數據庫存在就不創建, 已經存在的數據庫沒有必要創建.

3.? 數據庫編碼問題, 創建數據庫時有兩個編碼集:?數據庫字符集和數據庫校驗集????????
1. 數據庫字符集(編碼集) 是 未來存儲數據用的字符集
2. 數據庫校驗集 是 為了支持數據庫進行字段比較所使用的編碼, 本質是一種讀取數據庫中數據所采用的編碼格式.
因此, 無論數據庫對數據做任何操作, 都必須保證操作和編碼是一致的.?
a.?當我們創建數據庫沒有指定字符集和校驗規則時, 系統使用默認字符集:?utf8, 校驗規則是:utf8_ general_ ci. 這里我們的 my.cnf 配置為了 character-set-server=utf8mb4, 所以 mysql 的默認字符集以及校驗規則為:?utf8mb4 和?utf8mb4_0900_ai_ci.
MySQL 在早期(如 5.5 及更早)中的
utf8實際指的是utf8mb3,它無法存儲某些 Unicode 字符,?utf8mb4 是UTF-8完全體, 支持所有 Unicode 字符(包括 emoji, 部分罕見漢字等)
查看系統默認字符集以及校驗規則:
show variables like 'character_set_database';
show variables like 'collation_database';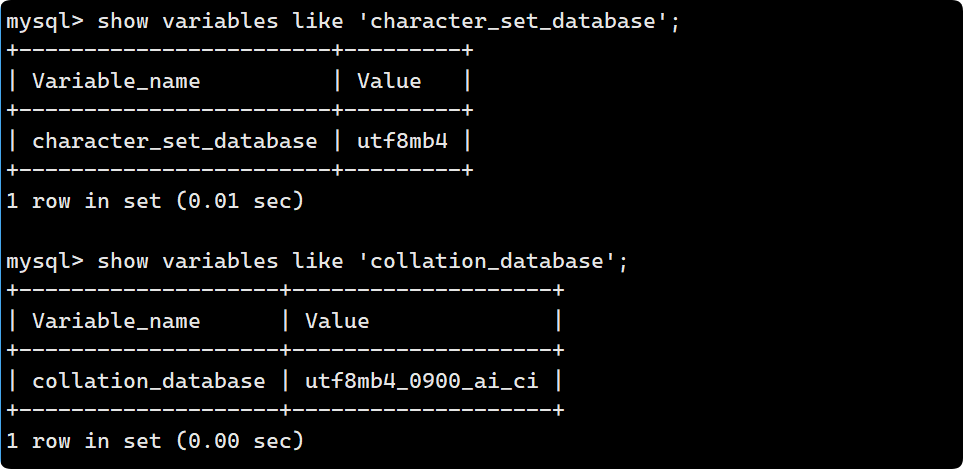
?查看數據庫支持的字符集和字符集校驗規則:
show charset;
show collation;show charset 的部分條目:

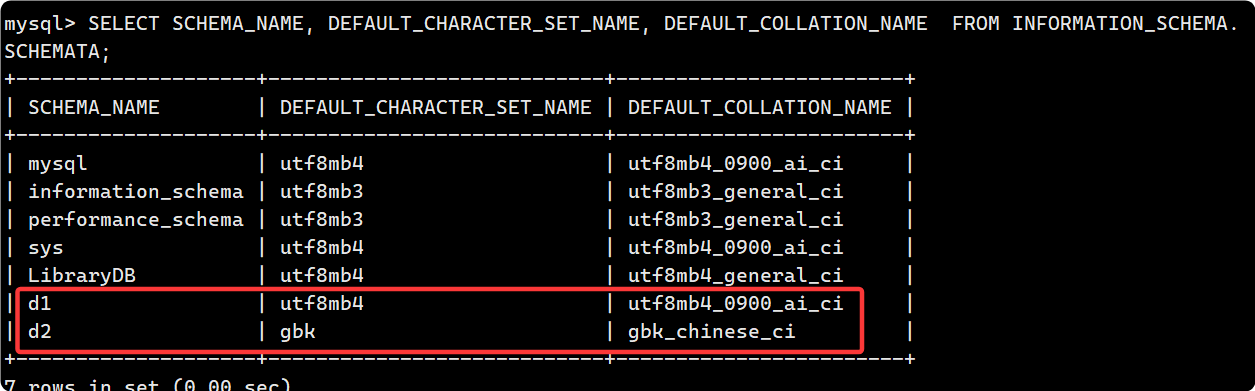
?b. 現在我們可以手動創建兩個數據庫:
create database d1;
create database d2 charset=gbk colloate gbk_chinese_ci;注意這里?charset=gbk?可以寫成 character set?gbk
了解: MYSQL 5.5?下可以通過 ?cat?/var/lib/mysql/db_name/db.opt 去查看數據庫的配置選項. 而MySQL 8.0 中, 關于數據庫的配置信息(如字符集和校驗規則)現在存儲在 數據字典表 mysql.schema 中,?該表存儲了數據庫的元數據:
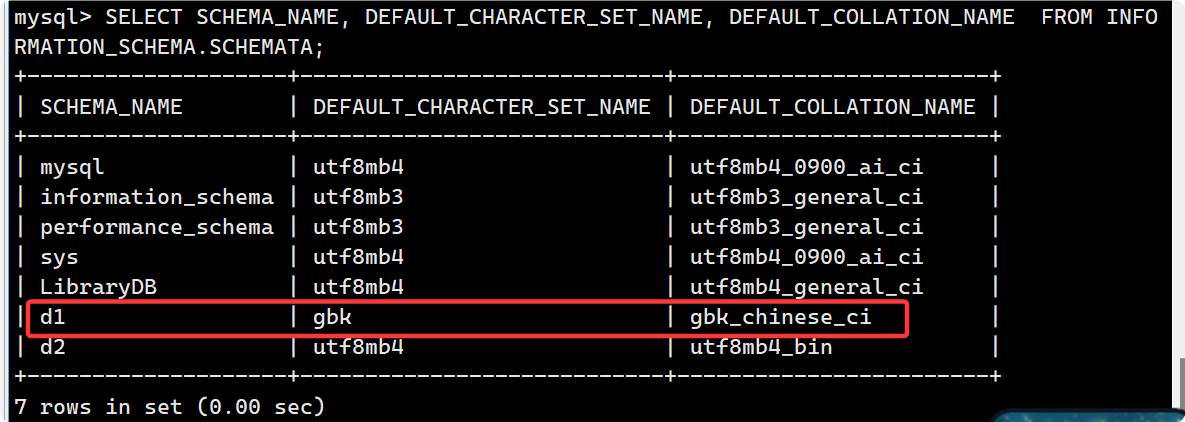
SELECT SCHEMA_NAME, DEFAULT_CHARACTER_SET_NAME, DEFAULT_COLLATION_NAME
FROM INFORMATION_SCHEMA.SCHEMATA;
INFORMATION_SCHEMA.SCHEMATA視圖專門用于存儲有關 所有數據庫(schema) 的信息?
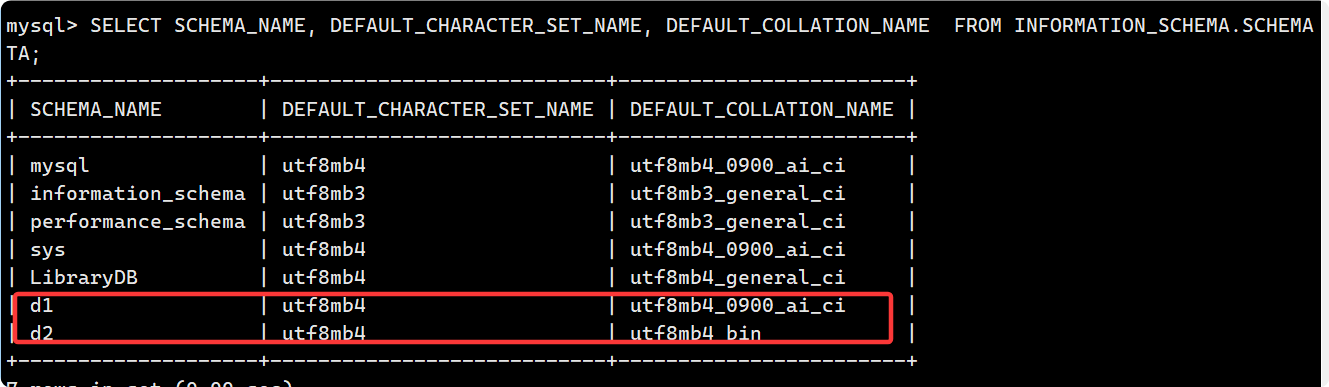
?c. 校驗規則對數據庫的影響
現在創建兩個數據庫d1 d2, 分別為 utf8mb4_0900_ai_ci 和 utf8mb4_bin, 前者不區分大小寫, 后者區分大小寫.?
一. SELECT顯式查詢以及結果
然后在數據庫插入幾個表供查詢演示.
1. d1 使用默認字符集 utf8mb4_0900_ai_ci 不區分大小寫:?
use d1
create table person(name varchar(20));
insert into person (name) values ('A');
insert into person (name) values ('a');
insert into person (name) values ('B');
insert into person (name) values ('b');
insert into person (name) values ('C');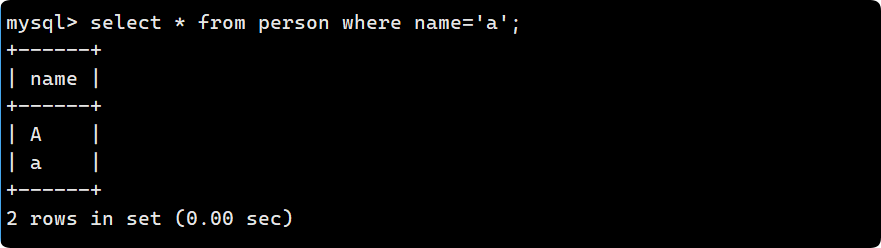
?2. d2 使用 utf8mb4_bin, 區分大小寫:
use d2
create table person(name varchar(20));
insert into person (name) values ('A');
insert into person (name) values ('a');
insert into person (name) values ('B');
insert into person (name) values ('b');
insert into person (name) values ('C');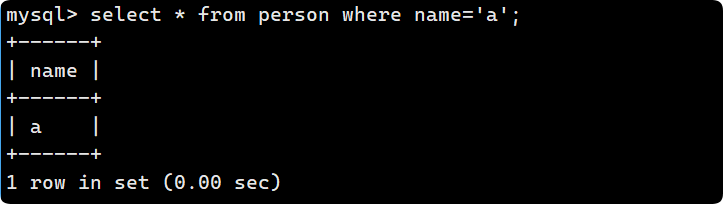
在使用數據庫前需要先 use db_name, 再建表. (對應系統級操作 cd dir_name, 相當于在指定目錄下創建文件需要先進入目錄),??
二. SELECT 隱式排序以及結果(默認是升序)
不區分大小寫:?A 和 a 的值要比 B 和 b 小, 所以整體呈現A->B->C的順序:
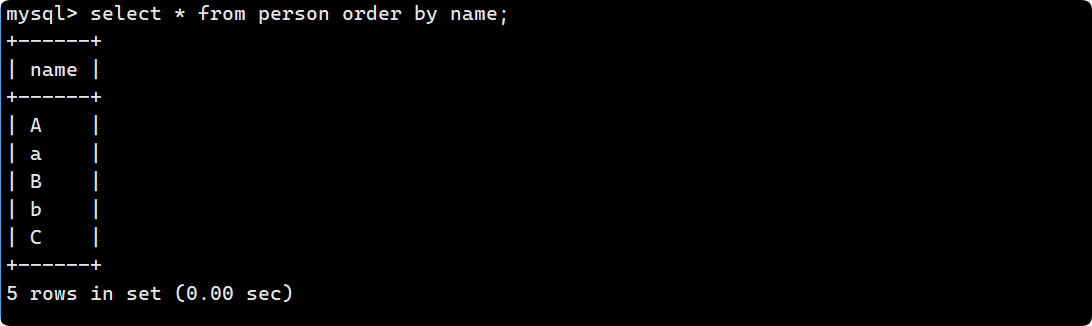
區分大小寫, 用 ASSIC 碼去進行比較, 小寫字母比大寫字母ASSIC碼要大, 因此為A->B->C->a->b:?
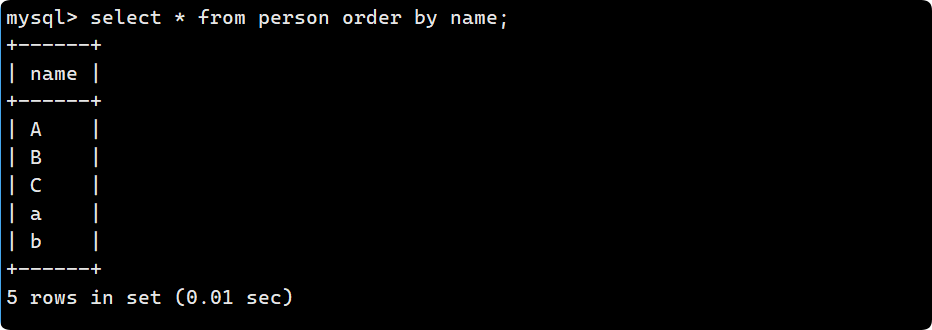
?結論: 校驗集會影響查詢結果, 無論是 顯式地用where去指定 還是 隱式的用order去排序.
操縱數據庫
MySQL 建議我們關鍵字(create select等)使用大寫, 但是不是必須的.
1. 查看數據庫, 經常用到:
show databases;2.?查看當前使用的是哪個數據庫:
select database();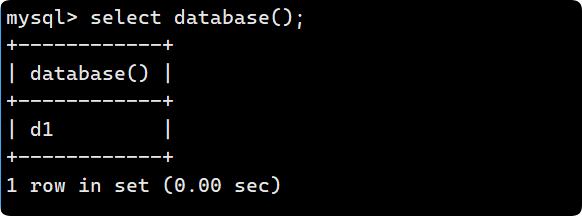
3.?修改數據庫
對數據庫的修改主要指的是修改數據庫的字符集, 校驗規則:
ALTER DATABASE db_name
[alter_spacification [,alter_spacification]...]
alter_spacification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name將 mytest 數據庫字符集改成 gbk :
alter database mytest charset=gbk;

?4. 查詢當時創建數據庫時的創建語句:
show create database 數據庫名;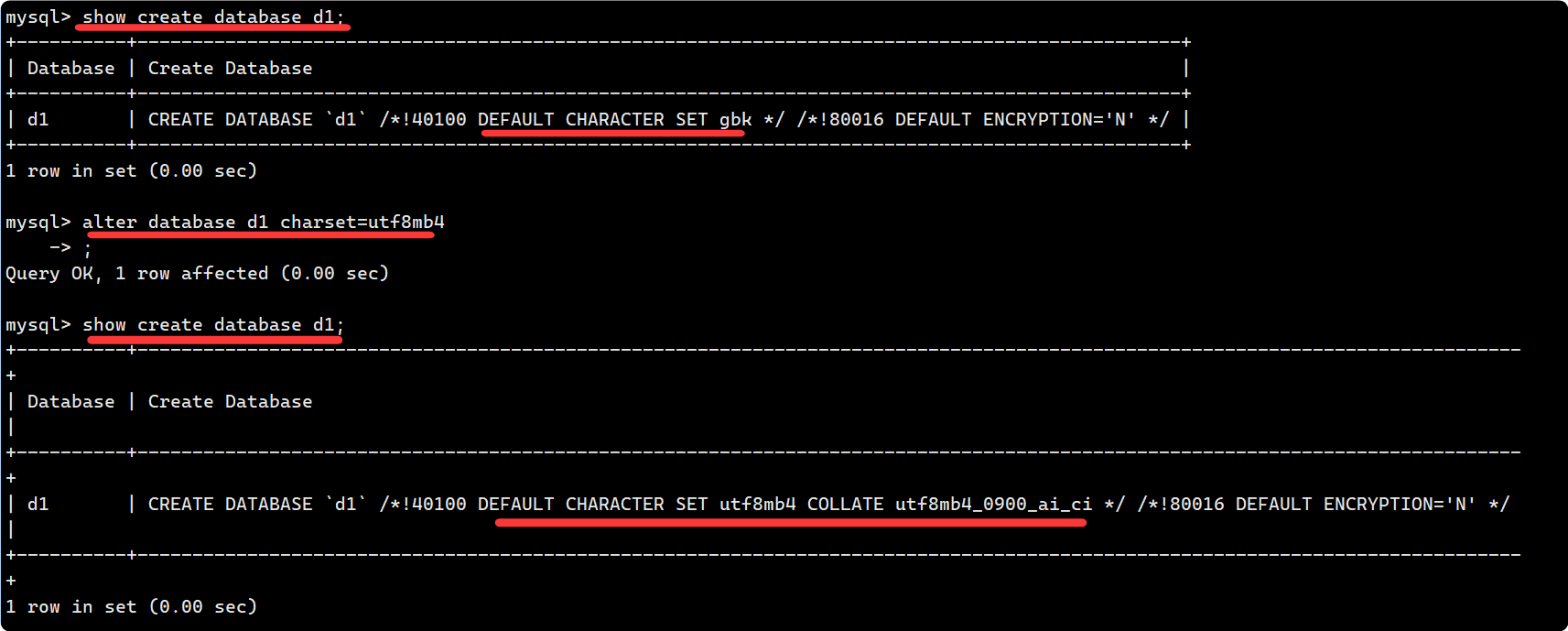
- 數據庫名字的反引號``, 是為了防止使用的數據庫名剛好是關鍵字.
- /*!40100 default.... */ 這個不是注釋, 表示當前 mysql 版本大于4.01版本, 就執行這句話.??
- alter 之后, show create database db_name; 也會相應更改
可以加上\G選項, 去掉多余的邊框, 只顯示有用信息, 后面show create table tb_name; 實用.?

5. 數據庫刪除
DROP DATABASE [IF EXISTS] db_name;?執行刪除之后的結果:
- 數據庫內部看不到對應的數據庫
- 對應的數據庫文件夾被刪除, 級聯刪除, 里面的數據表全部被刪
注意: 不要隨意刪除數據庫.
數據庫的備份和恢復
mysql 不提供直接對數據庫進行重命名, 也不要直接對數據庫對應的目錄文件重命名. 如果非要重命名, 方法是對數據庫進行備份, 然后把文件導入到新的數據庫中.
數據庫遷移
數據庫在兩個機器上轉移很容易, 只需要將備份文件交給另一臺機器, 然后還原即可.?
1. 備份要使用 mysql 提供的工具去備份,? 備份成功之后, 會生成一個指定的備份文件, 圖中為d1.sql:
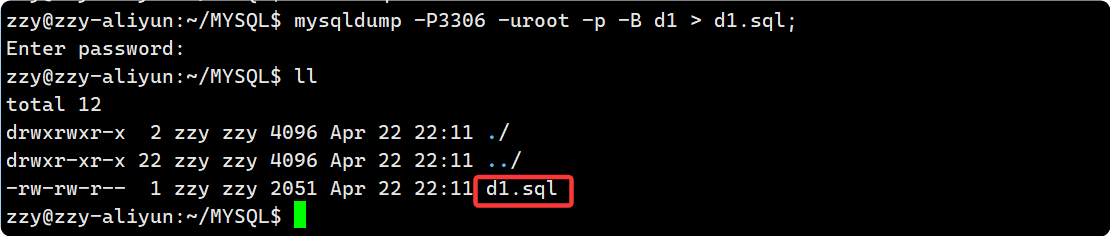
?2. 刪掉d1數據庫之后, 再在mysql環境下用 source 命令還原回去:
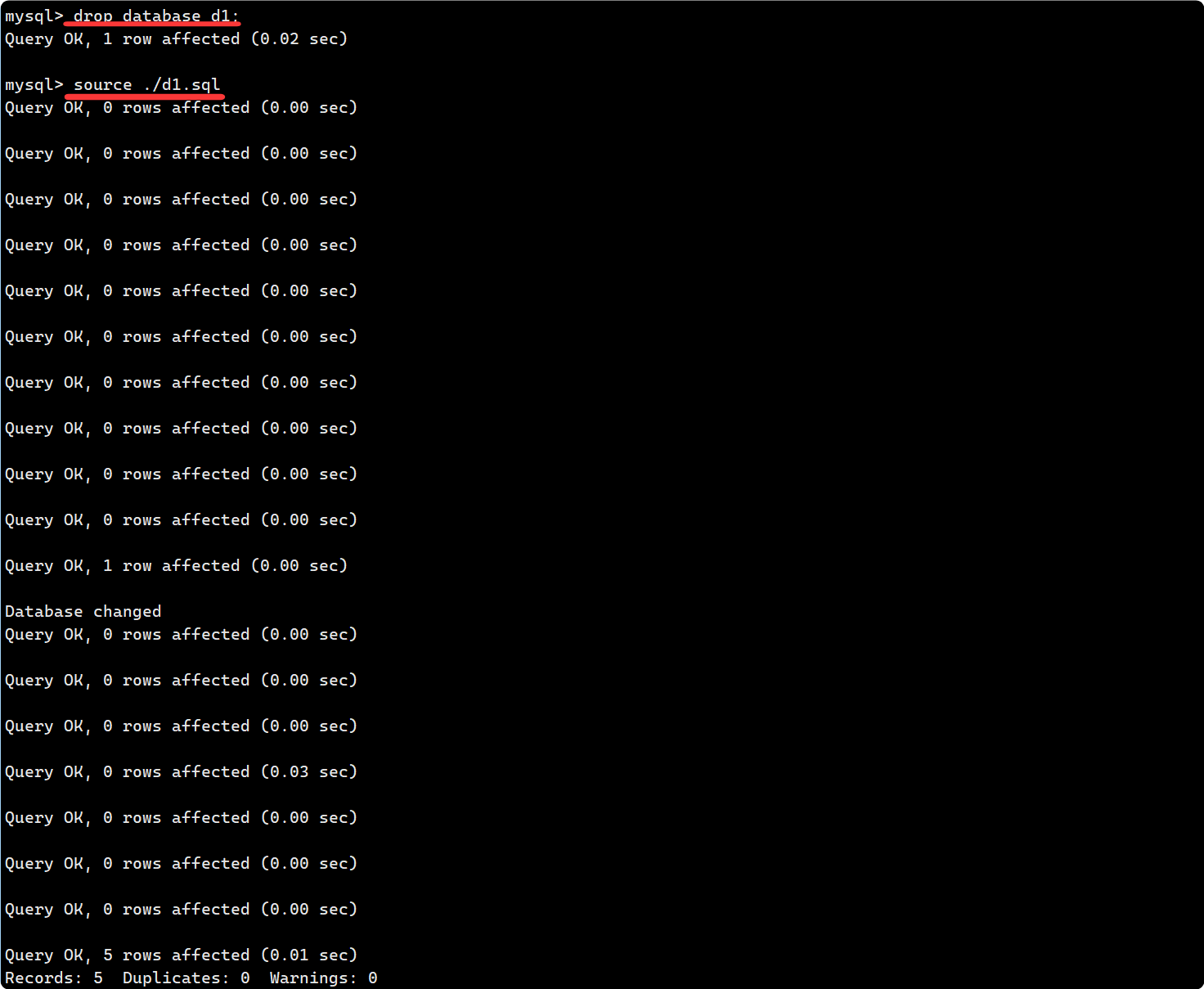
3. 由于 d1.sql 備份文件中備份的是關于該數據庫曾經的所有操作, 所以會依次執行 d1.sql 中保存的操作.?
數據庫重命名
如果備份一個數據庫時, 沒有帶上 -B 參數, 在恢復數據庫時, 需要:
1. 先創建空數據庫, 自己命名
2.?使用數據庫
3. 直接輸入 source 來還原
本質是因為沒有 -B 的參數, 備份的文件中就不會有第一行 create database db_name 語句, 只會保留一些表信息. 因此需要自己創建一個數據庫并命名.
備份表和多個數據庫?
另外, 我們如果備份的不是整個數據庫, 而是其中的若干張表.?
mysqldump -u root -p 數據庫名 表名1 表名2 > 備份文件路徑?同時備份多個數據庫:?
mysqldump -u root -p -B 數據庫名1 數據庫名2 ... > 數據庫存放路徑查看連接情況
show processlist;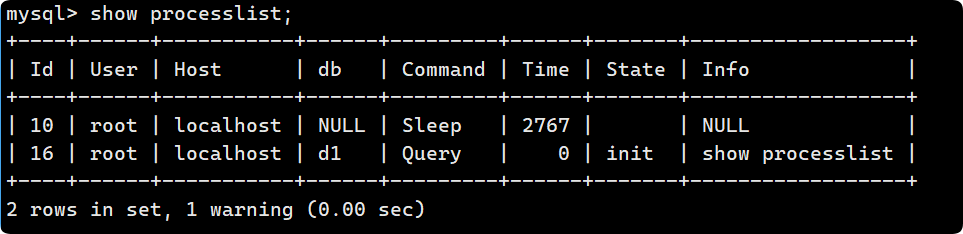 ?可以告訴我們當前有哪些用戶連接到我們的MySQL, 如果查出某個用戶不是你正常登陸的, 很有可能你的數據庫被人入侵了. 以后大家發現自己數據庫比較慢時, 可以用這個指令來查看數據庫連接情況.
?可以告訴我們當前有哪些用戶連接到我們的MySQL, 如果查出某個用戶不是你正常登陸的, 很有可能你的數據庫被人入侵了. 以后大家發現自己數據庫比較慢時, 可以用這個指令來查看數據庫連接情況.
總結
數據庫的名稱不要輕易改, 數據庫不要輕易刪除, 因為上層應用依賴數據庫且認定改數據庫的名稱, 改動會出錯.











)


)
)



)