目錄
1.urllib庫
1.1.request模塊
1.1.1、urllib.request.urlopen() 函數
1.1.2.urllib.request.urlretrieve()?函數
1.2.?error模塊
1.3.?parse 模塊
2.?BeautifulSoup4庫
2.1.對象種類
2.2.對象屬性
2.2.1.子節點
2.2.2.父節點
2.2.3.兄弟節點
?2.2.4.回退和前進
2.3.對象方法
2.3.1.find_all()
2.3.2.find()
2.3.3.CSS選擇器查找
2.3.4.修改內容
2.4.輸出
2.4.1.格式化輸出
2.4.2.壓縮輸出
2.4.3.文本輸出
?3.re標準庫
大概會用到以下這些模塊
| 分類 | 庫名 | 主要用途 |
|---|---|---|
| 網絡請求 | requests | 同步HTTP請求 |
aiohttp | 異步HTTP請求 | |
| 動態渲染 | selenium | 瀏覽器自動化 |
playwright | 高性能無頭瀏覽器控制 | |
| 數據解析 | BeautifulSoup4 | HTML/XML解析 |
lxml | XPath/CSS選擇器解析 | |
re | 字符串正則匹配(文本清洗/數據提取) | |
| 爬蟲框架 | scrapy | 全功能爬蟲框架 |
| 反反爬 | fake-useragent | 隨機生成請求頭 |
1.urllib庫
?? Python3 中將 Python2 中的 urllib 和 urllib2 兩個庫整合為一個 urllib 庫,所以現在一般說的都是 Python3 中的 urllib 庫,它是python3內置標準庫,不需要額外安裝。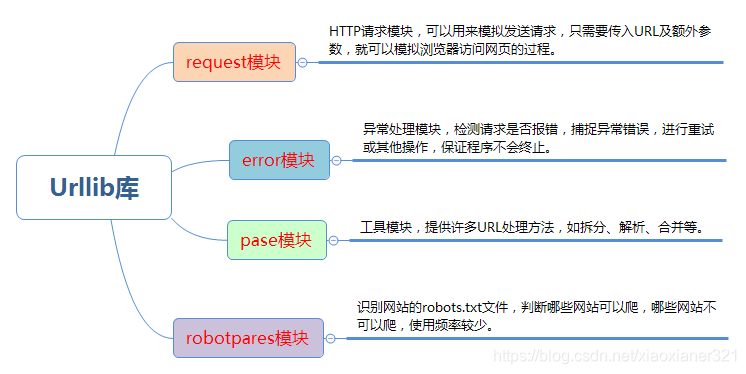
1.1.request模塊
?request模塊提供了最基本的構造 HTTP 請求的方法,利用它可以模擬瀏覽器的一個請求發起過程,同時它還帶有處理authenticaton(授權驗證),redirections(重定向),cookies(瀏覽器Cookies)以及其它內容。
1.1.1、urllib.request.urlopen() 函數
語法:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)參數說明:
url:請求的 url,也可以是request對象
data:請求的 data,如果設置了這個值,那么將變成 post 請求,如果要傳遞一個字典,則應該用urllib.parse模塊的urlencode()函數編碼;
timeout:設置網站的訪問超時時間句柄對象;
cafile和capath:用于 HTTPS 請求中,設置 CA 證書及其路徑;
cadefault:忽略*cadefault*參數;
context:如果指定了*context*,則它必須是一個ssl.SSLContext實例。urlopen() 返回對象HTTPResponse提供的方法和屬性:1)read()、readline()、readlines()、fileno()、close():對 HTTPResponse 類型數據進行操作;
2)info():返回 HTTPMessage 對象,表示遠程服務器 返回的頭信息 ;
3)getcode():返回 HTTP 狀態碼 geturl():返回請求的 url;
4)getheaders():響應的頭部信息;
5)status:返回狀態碼;
6)reason:返回狀態的詳細信息.案例一:使用urlopen()函數抓取百度
import urllib.request
url = "http://www.baidu.com/"
res = urllib.request.urlopen(url) # get方式請求
print(res) # 返回HTTPResponse對象<http.client.HTTPResponse object at 0x00000000026D3D00>
# 讀取響應體
bys = res.read() # 調用read()方法得到的是bytes對象。
print(bys) # <!DOCTYPE html><!--STATUS OK-->\n\n\n <html><head><meta...
print(bys.decode("utf-8")) # 獲取字符串內容,需要指定解碼方式,這部分我們放到html文件中就是百度的主頁# 獲取HTTP協議版本號(10 是 HTTP/1.0, 11 是 HTTP/1.1)
print(res.version) # 11# 獲取響應碼
print(res.getcode()) # 200
print(res.status) # 200# 獲取響應描述字符串
print(res.reason) # OK# 獲取實際請求的頁面url(防止重定向用)
print(res.geturl()) # http://www.baidu.com/# 獲取響應頭信息,返回字符串
print(res.info()) # Bdpagetype: 1 Bdqid: 0x803fb2b9000fdebb...
# 獲取響應頭信息,返回二元元組列表
print(res.getheaders()) # [('Bdpagetype', '1'), ('Bdqid', '0x803fb2b9000fdebb'),...]
print(res.getheaders()[0]) # ('Bdpagetype', '1')
# 獲取特定響應頭信息
print(res.getheader(name="Content-Type")) # text/html;charset=utf-8案例二:get請求
我們在http://httpbin.org/網站,發送一個get測試請求:
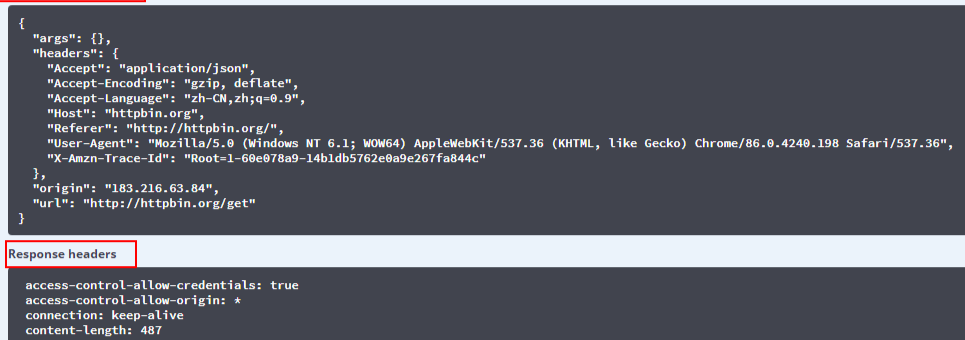
然后我們在使用python模擬瀏覽器發送一個get請求:
import urllib.request
# 請求的URL
url = "http://httpbin.org/get"
# 模擬瀏覽器打開網頁(get請求)
res = urllib.request.urlopen(url)
print(res.read().decode("utf-8"))?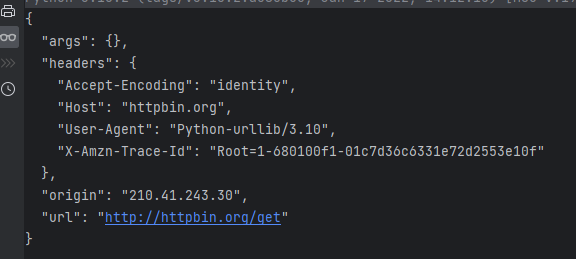
通過上面的案例,不難發現使用urllib發送的請求,比較不同的地方是:"User-Agent",使用urllib發送的會有一個默認的Headers:User-Agent: Python-urllib/3.8。所以遇到一些驗證User-Agent的網站時,有可能會直接拒絕爬蟲,因此我們需要自定義Headers把自己偽裝的像一個瀏覽器一樣。
?案例三:?偽裝Headers
我去爬取豆瓣網時:
import urllib.requesturl = "http://douban.com"
resp = urllib.request.urlopen(url)
print(resp.read().decode('utf-8'))返回錯誤:反爬蟲
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 418: HTTP 418? ? 客戶端錯誤響應代碼表示服務器拒絕。
?自定義Headers:
import urllib.requesturl = "http://douban.com"
# 自定義headers
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
}
req = urllib.request.Request(url, headers=headers)
# urlopen(也可以是request對象)
print(urllib.request.urlopen(req).read().decode('utf-8')) # 獲取字符串內容,需要指定解碼方式1.1.2.urllib.request.urlretrieve()?函數
??urlretrieve()函數的作用是直接將遠程的網頁數據htlm下載到本地
# 語法:
?
urlretrieve(url, filename=None, reporthook=None, data=None)
?
# 參數說明
?
url:傳入的網址
filename:指定了保存本地路徑(如果參數未指定,urllib會生成一個臨時文件保存數據)
reporthook:是一個回調函數,當連接上服務器、以及相應的數據塊傳輸完畢時會觸發該回調,我們可以利用這個回調函數來顯示當前的下載進度
data:指 post 到服務器的數據,該方法返回一個包含兩個元素的(filename, headers)元組,filename 表示保存到本地的路徑,header表示服務器的響應頭
?
import urllib.requesturl = "http://www.hao6v.com/"
filename = "C:\\pythonProject\\python爬蟲\\gyp.html"def callback(blocknum, blocksize, totalsize):"""@blocknum:目前為此傳遞的數據塊數量@blocksize:每個數據塊的大小,單位是byte,字節@totalsize:遠程文件的大小"""if totalsize == 0:percent = 0else:percent = blocknum * blocksize / totalsizeif percent > 1.0:percent = 1.0percent = percent * 100print("download : %.2f%%" % (percent))local_filename, headers = urllib.request.urlretrieve(url, filename, callback)
1.2.?error模塊
? ??urllib.error 模塊為 urllib.request 所引發的異常定義了異常類,基礎異常類是 URLError。
| 狀態碼 | 分類 | 定義 |
|---|---|---|
| 1xx | 信息響應 | |
| 100 | Continue | 服務器已接收請求頭,客戶端應繼續發送請求體 |
| 101 | Switching Protocols | 協議切換(如HTTP→WebSocket) |
| 2xx | 成功響應 | |
| 200 | OK | 請求成功,響應內容取決于請求方法(GET/POST等) |
| 201 | Created | 資源創建成功(常用于POST/PUT) |
| 204 | No Content | 無返回內容,但響應頭可能含元信息 |
| 3xx | 重定向 | |
| 301 | Moved Permanently | 資源永久重定向到新URI |
| 302 | Found | 資源臨時重定向(早期規范語義不明確,建議用307/308替代) |
| 304 | Not Modified | 資源未修改(緩存相關) |
| 4xx | 客戶端錯誤 | |
| 400 | Bad Request | 請求語法錯誤 |
| 403 | Forbidden | 服務器拒絕執行(無權限) |
| 404 | Not Found | 資源不存在 |
| 408 | Request Timeout | 請求超時 |
| 5xx | 服務器錯誤 | |
| 500 | Internal Server Error | 服務器內部錯誤(無具體信息) |
| 503 | Service Unavailable | 服務不可用(臨時過載或維護) |
| 504 | Gateway Timeout | 網關超時(上游服務器未響應) |
import urllib.request,urllib.errortry:url = "http://www.baidus.com"resp = urllib.request.urlopen(url)print(resp.read().decode('utf-8'))
# except urllib.error.HTTPError as e:
# print("請檢查url是否正確")
# URLError是urllib.request異常的超類
except urllib.error.URLError as e:if hasattr(e, "code"):print(e.code)if hasattr(e, "reason"):print(e.reason)?
1.3.?parse 模塊
| 功能分類 | 函數 | 核心作用 |
|---|---|---|
| URL解析 | urlparse(url) | 將URL拆分為6組件(協議/域名/路徑等),保留參數分隔符;和& |
urlsplit(url) | 類似urlparse但不拆分參數分隔符,返回5組件 | |
urldefrag(url) | 分離URL中的片段標識(如#anchor) | |
| URL構建 | urlunparse(parts) | 將urlparse的6組件重組為完整URL |
urljoin(base, url) | 基于基URL合并相對路徑(智能處理./和../) | |
| 查詢參數處理 | urlencode(query_dict) | 將字典轉為URL查詢字符串(自動編碼特殊字符) |
parse_qs(query_str) | 將查詢字符串解析為字典(值類型為list) | |
parse_qsl(query_str) | 將查詢字符串解析為鍵值對列表(保留原始順序) |
2.?BeautifulSoup4庫
????????學了urllib標準庫之后,我們已經能爬到些比較正常的網頁源碼(html文檔)了,但這離結果還差一步——就是如何篩選我們想要的數據,這時候BeautifulSoup庫就來了,BeautifulSoup目前最新版本為BeautifulSoup4。
用于解析HTML和XML文檔的流行庫,它能夠從網頁中提取數據并生成易于遍歷的解析樹。
(官網文檔:Beautiful Soup 4.12.0 文檔 — Beautiful Soup 4.12.0 documentation)
soup = BeautifulSoup("<html>Hello</html>", "html.parser")參數解析:?
(1)markup
需要解析的HTML/XML文檔內容(字符串或文件對象)。
(2)解析器選擇(features?或第二參數)
| 解析器 | 安裝方式 | 特點 | 示例 |
|---|---|---|---|
"html.parser" | Python內置 | 速度中等,無依賴 | BeautifulSoup(html, "html.parser") |
"lxml" | pip install lxml | 最快,支持復雜文檔 | BeautifulSoup(html, "lxml") |
"html5lib" | pip install html5lib | 容錯性最強,速度慢 | BeautifulSoup(html, "html5lib") |
from bs4 import BeautifulSoup # 導入BeautifulSoup4庫# 未指定就使用html.parser這個python標準解析器 BeautifulSoup(markup, "html.parser") 未指定會產生警告 GuessedAtParserWarning: No parser was explicitly specified# BeautifulSoup 第一個參數接受:一個文件對象或字符串對象
soup1 = BeautifulSoup(markup=open("C:\\pythonProject\\python爬蟲\\gyp.html"), features="html.parser")
soup2 = BeautifulSoup("<html>hello python</html>") # 得到文檔的對象
print(type(soup2)) # <class 'bs4.BeautifulSoup'>
print(soup1) # <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" ....
print(soup2) # <html><head></head><body>hello python</body></html>2.1.對象種類
??BeautifulSoup將復雜HTML文檔轉換成一個復雜的樹形結構,每個節點都是Python對象,所有對象可以歸納為4種: Tag , NavigableString , BeautifulSoup , Comment 。
| 對象類型 | 關鍵屬性/方法 | 功能描述 | 注意事項 |
|---|---|---|---|
| Tag 標簽對象 | name(標簽名)attributes(屬性字典) | 表示HTML/XML文檔中的標簽節點,可獲取標簽名和屬性(如class、id等) | 通過遍歷或搜索文檔樹獲取,支持嵌套操作(如tag.contents?) |
| NavigableString | tag.string | 提取標簽對內的純文本內容(僅限直接包含的字符串) | 若標簽內含注釋或其他子標簽,需用.strings或.get_text()獲取完整文本 |
| BeautifulSoup | 文檔根對象 | 代表整個解析后的文檔,可視為特殊的Tag對象(包含<html>頂層標簽) | 初始化時需指定解析器(如lxml),支持全局搜索方法(如.find_all()) |
| Comment 對象 | 繼承自NavigableString | 處理HTML注釋內容(如<!-- comment -->),輸出時自動去掉注釋符號 | 需用type(tag.string)==bs4.Comment?判斷,避免誤將注釋當作普通文本處理 |
from bs4 import BeautifulSoup# 導入BeautifulSoup4庫
# python 標準解析器 未指定就使用這個 BeautifulSoup(markup, "html.parser")
soup2 = BeautifulSoup("<html>""<p class='boldest'>我是p標簽<b>hello python</b></p>""<!--我是標簽外部的內容注釋-->""<p class='boldest2'><!--我p標簽內的注釋-->我是獨立的p標簽</p>""<a><!--我a標簽內的注釋-->我是鏈接</a>""<h1><!--這是一個h1標簽的注釋--></h1>""</html>","html5lib") # 得到文檔的對象
# Tag 標簽對象
print(type(soup2.p)) # 輸出Tag對象<class 'bs4.element.Tag'>
print(soup2.p.name) # 輸出Tag標簽對象的名稱
print(soup2.p.attrs) # 輸出第一個p標簽的屬性信息:{'class': ['boldest']}
soup2.p['class'] = ['boldest', 'boldest1']
print(soup2.p.attrs) # {'class': ['boldest', 'boldest1']}# NavigableString 可以遍歷的字符串對象
print(type(soup2.b.string)) # <class 'bs4.element.NavigableString'>
print(soup2.b.string) # hello python
print(soup2.a.string) # None 存在注釋或者其他標簽內容均無法獲取
print(soup2.b.string.replace_with("hello world")) # replace_with()方法可替換標簽中的內容
print(soup2.b.string) # hello world# BeautifulSoup 對象
print(type(soup2)) # <class 'bs4.BeautifulSoup'>
print(soup2) # <html><head></head><body><p class="boldest">我是p標簽<b>hello python</b></p><!--我是標簽外部的內容注釋--><p><!--我p標簽內的注釋-->我是獨立的p標簽</p></body></html>
print(soup2.name) # [document]# Comment 注釋及特殊字符串(是一個特殊類型的 NavigableString 對象)
print(type(soup2.h1.string)) # <class 'bs4.element.Comment'>
print(soup2.h1.string) # 這是一個h1標簽的注釋 (利用 .string 來輸出它的內容,注釋符被去除了,不是我們想要的)
print(soup2.h1.prettify()) # 會以特殊格式輸出:<h1> <!--這是一個h1標簽的注釋--> </h1>2.2.對象屬性
可以簡單理解爬取到的內容是樹狀圖:
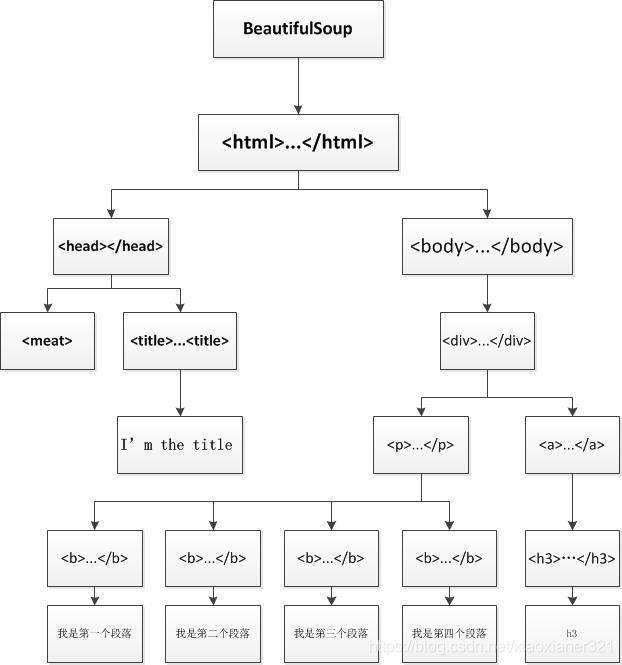
2.2.1.子節點
BeautifulSoup 對象常用屬性總結
| 屬性/方法 | 描述 | 使用場景與注意事項 |
|---|---|---|
| .tag | 獲取標簽名(如tag.name?返回'div') | 適用于快速識別標簽類型,但需注意某些標簽(如<br/>)可能無閉合標簽。 |
| .contents | 返回標簽的直接子節點列表(包括文本和標簽節點) | 需注意列表可能包含換行符等空白文本節點,可通過過濾NavigableString類型處理。 |
| .children | 生成器形式返回直接子節點(性能優于.contents) | 適合遍歷大量子節點時節省內存,但不可索引(需轉為列表)。 |
| .descendants | 遞歸生成所有子孫節點(深度優先遍歷) | 可用于爬取嵌套結構的完整內容(如表格內的所有文本),但需處理混合節點類型(注釋、字符串等)。 |
| .string | 提取標簽內唯一字符串子節點(無嵌套標簽) | 若標簽含多個子節點(如<p>Text<b>bold</b></p>),返回None,需改用.get_text()或.strings。 |
| .strings | 生成器形式返回標簽內所有字符串(保留空白) | 需手動去除換行符和縮進(如' '.join(tag.strings).strip()?)。 |
| .stripped_strings | 生成器形式返回標簽內字符串(自動去除空白) | 適用于清洗文本(如新聞正文提取),但可能合并相鄰空格(需根據需求調整)。 |
from bs4 import BeautifulSoupmarkup = '''<!DOCTYPE html>
<html><head><meta charset="UTF-8"><title>I’m the title</title></head><body><h1>HelloWorld</h1><div><div><p><b>我是一個段落...</b>我是第一段我是第二段<b>我是另一個段落</b>我是第一段</p><a>我是一個鏈接</a></div><div><p>picture</p><img src="example.png"/></div></div></body>
</html>'''
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup 對象
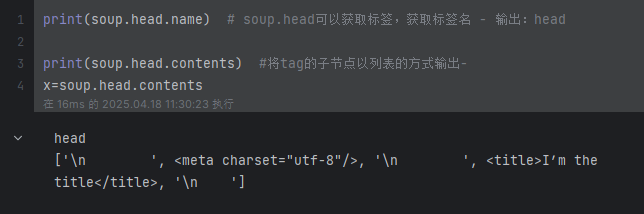
print(soup.head.name) # soup.head可以獲取標簽,獲取標簽名 - 輸出:head
print(soup.head.contents) # 將tag的子節點以列表的方式輸出--輸出:['\n ', <meta charset="utf-8"/>, '\n ', <title>I’m the title</title>, '\n ']
print(soup.head.contents[1]) # <meta charset="utf-8"/>
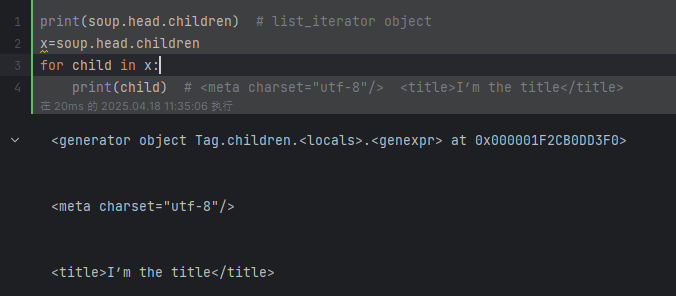
print(soup.head.children) # list_iterator object
for child in soup.head.children:print(child) # <meta charset="utf-8"/> <title>I’m the title</title>
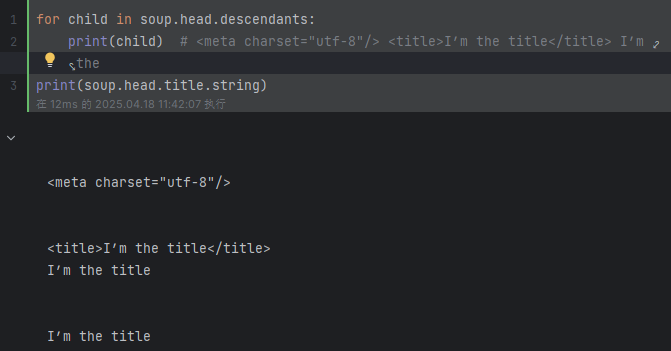
# 標簽中的內容其實也是一個節點 使用contents和children無法直接獲取間接節點中的內容,但是.descendants 屬性可以
for child in soup.head.descendants:print(child) # <meta charset="utf-8"/> <title>I’m the title</title> I’m the title
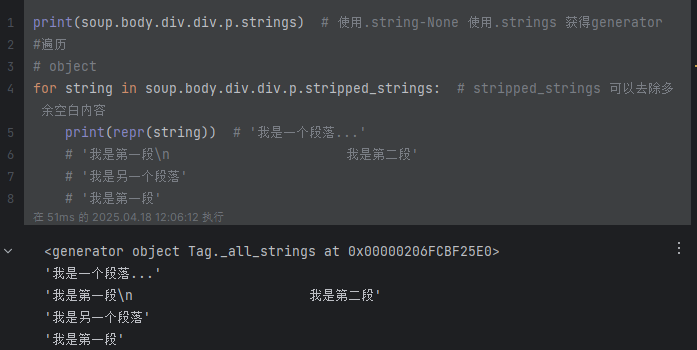
print(soup.head.title.string) # 輸出:I’m the title 注:title中有其他節點或者注釋都無法獲取print(soup.body.div.div.p.strings) # 使用.string-None 使用.strings 獲得generator object
for string in soup.body.div.div.p.stripped_strings: # stripped_strings 可以去除多余空白內容print(repr(string)) # '我是一個段落...'# '我是第一段\n 我是第二段'# '我是另一個段落'# '我是第一段'tag+contents:?
?
?children:
?深度優先遍歷:descendants
?獲取標簽字符:string
2.2.2.父節點
| 屬性 | 描述 |
| .parent | 獲取某個元素的父節點 |
| .parents | 可以遞歸得到元素的所有父輩節點 |
from bs4 import BeautifulSoupmarkup = '''<!DOCTYPE html>
<html><head><meta charset="UTF-8"><title>I’m the title</title></head><body><h1>HelloWorld</h1><div><div><p><b>我是一個段落...</b>我是第一段我是第二段<b>我是另一個段落</b>我是第一段</p><a>我是一個鏈接</a></div><div><p>picture</p><img src="example.png"/></div></div></body>
</html>'''
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup 對象title = soup.head.title
print(title.parent) # 輸出父節點
# <head>
# <meta charset="utf-8"/>
# <title>I’m the title</title>
# </head>
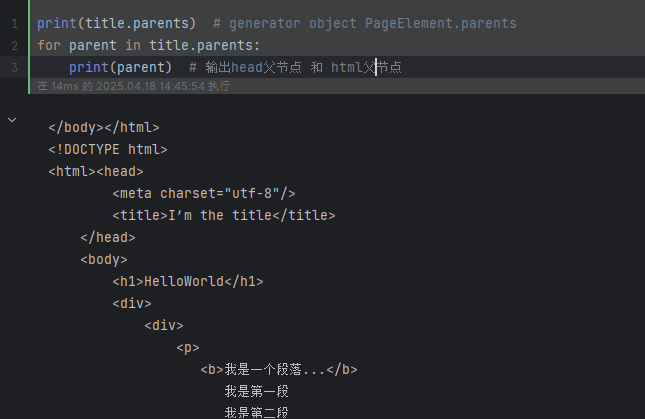
print(title.parents) # generator object PageElement.parents
for parent in title.parents:print(parent) # 輸出head父節點 和 html父節點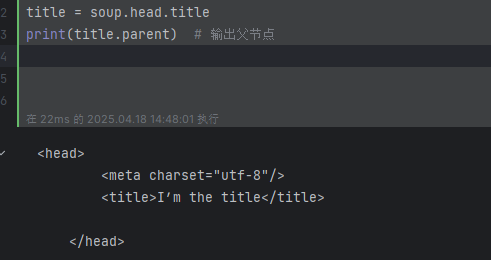
2.2.3.兄弟節點
| 屬性 | 描述 |
| .next_sibling | 查詢兄弟節點,表示下一個兄弟節點 |
| .previous_sibling | 查詢兄弟節點,表示上一個兄弟節點 |
| .next_siblings | 對當前節點的兄弟節點迭代輸出(下) |
| .previous_siblings | 對當前節點的兄弟節點迭代輸出(上) |
from bs4 import BeautifulSoupmarkup = '''<!DOCTYPE html>
<html><head><meta charset="UTF-8"><title>I’m the title</title></head><body><div><p><b id=“b1”>我是第一個段落</b><b id=“b2”>我是第二個段落</b><b id=“b3”>我是第三個段落</b><b id=“b4”>我是第四個段落</b></p><a>我是一個鏈接</a></div></body>
</html>'''
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup 對象
p = soup.body.div.p.b
print(p) # <b id="“b1”">我是第一個段落</b>
print(p.next_sibling) # <b id="“b2”">我是第二個段落</b>
print(p.next_sibling.previous_sibling) # <b id="“b1”">我是第一個段落</b>
print(p.next_siblings) # generator object PageElement.next_siblings
for nsl in p.next_siblings:print(nsl) # <b id="“b2”">我是第二個段落</b># <b id="“b3”">我是第三個段落</b># <b id="“b4”">我是第四個段落</b>?2.2.4.回退和前進
| 屬性 | 描述 |
| .next_element | 解析下一個元素對象 |
| .previous_element | 解析上一個元素對象 |
| .next_elements | 迭代解析元素對象 |
| .previous_elements | 迭代解析元素對象 |
from bs4 import BeautifulSoupmarkup = '''<!DOCTYPE html>
<html><head><meta charset="UTF-8"><title>I’m the title</title></head><body><div><p><b id=“b1”>我是第一個段落</b><b id=“b2”>我是第二個段落</b><b id=“b3”>我是第三個段落</b><b id=“b4”>我是第四個段落</b></p><a>我是一個鏈接<h3>h3</h3></a></div></body>
</html>'''
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup 對象
p = soup.body.div.p.b
print(p) # <b id="“b1”">我是第一個段落</b>
print(p.next_element) # 我是第一個段落
print(p.next_element.next_element) # <b id="“b2”">我是第二個段落</b>
print(p.next_element.next_element.next_element) # 我是第二個段落
for element in soup.body.div.a.next_element: # 對:我是一個鏈接 字符串的遍歷print(element)2.3.對象方法
?這里的搜索文檔,其實就是按照某種條件去搜索過濾文檔,過濾的規則,往往會使用搜索的API,或者我們也可以自定義正則/過濾器,去搜索文檔
2.3.1.find_all()
find_all( name , attrs , recursive , string , **kwargs ) | 參數/屬性 | 類型 | 作用 | 示例 |
|---|---|---|---|
name | 字符串/正則/列表/函數 | 指定標簽名稱(如?'div') | soup.find_all('p')?查找所有?<p>?標簽 |
attrs | 字典 | 通過屬性篩選(如?class、id) | soup.find_all(attrs={'class': 'header'})?匹配?class="header"?的標簽 |
recursive | 布爾值(默認?True) | 是否遞歸搜索子標簽。False?時僅搜索直接子節點 | soup.find_all('div', recursive=False)?僅查頂層?<div> |
string | 字符串/正則/函數 | 直接搜索標簽內的文本內容(非標簽本身) | soup.find_all(string='Hello')?查找文本為 "Hello" 的節點 |
**kwargs | 關鍵字參數 | 簡化屬性篩選語法(等效于?attrs) | soup.find_all(class_='header')?匹配?class="header" |
| 返回值 | ResultSet(類列表) | 返回所有匹配的標簽或文本節點的集合,若無結果則返回空列表?[] | results = soup.find_all('a')?獲取所有?<a>?標簽 |
from bs4 import BeautifulSoup
import remarkup = '''<!DOCTYPE html>
<html><head><meta charset="UTF-8"><title id="myTitle">I’m the title</title></head><body><div><p><b id=“b1” class="bcl1">我是第一個段落</b><b>我是第二個段落</b><b id=“b3”>我是第三個段落</b><b id=“b4”>我是第四個段落</b></p><a href="www.temp.com">我是一個鏈接<h3>h3</h3></a><div id="dv1">str</div></div></body>
</html>'''
# 語法:find_all( name , attrs , recursive , string , **kwargs )
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup 對象
# 第一個參數name,可以是一個標簽名也可以是列表
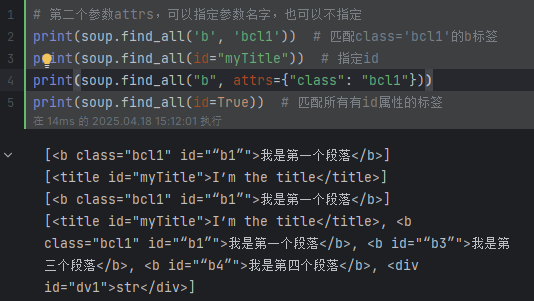
print(soup.findAll('b')) # 返回包含b標簽的列表 [<b id="“b1”">我是第一個段落</b>, <b id="“b2”">我是第二個段落</b>, <b id="“b3”">我是第三個段落</b>, <b id="“b4”">我是第四個段落</b>]
print(soup.findAll(['a', 'h3'])) # 按列表匹配多個 [<a href="www.temp.com">我是一個鏈接<h3>h3</h3></a>, <h3>h3</h3>]# 第二個參數attrs,可以指定參數名字,也可以不指定
print(soup.findAll('b', 'bcl1')) # 匹配class='bcl1'的b標簽[<b class="bcl1" id="“b1”">我是第一個段落</b>]
print(soup.findAll(id="myTitle")) # 指定id [<title id="myTitle">I’m the title</title>]
print(soup.find_all("b", attrs={"class": "bcl1"})) # [<b class="bcl1" id="“b1”">我是第一個段落</b>]
print(soup.findAll(id=True)) # 匹配所有有id屬性的標簽# 第三個參數recursive 默認True 如果只想搜索tag的直接子節點,可以使用參數 recursive=False
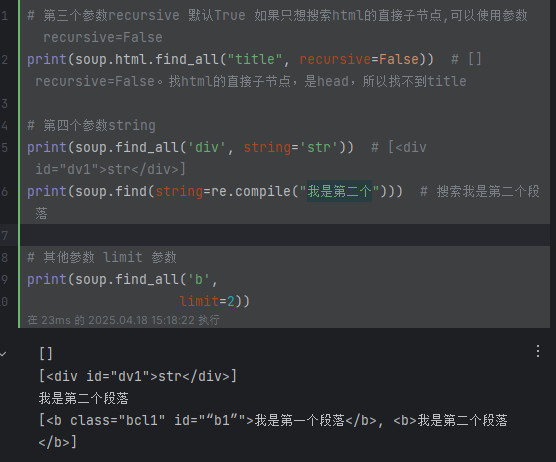
print(soup.html.find_all("title", recursive=False)) # [] recursive=False。找html的直接子節點,是head,所以找不到title# 第四個參數string
print(soup.findAll('div', string='str')) # [<div id="dv1">str</div>]
print(soup.find(string=re.compile("我是第二個"))) # 搜索我是第二個段落# 其他參數 limit 參數
print(soup.findAll('b', limit=2)) # 當搜索到的結果數量達到 limit 的限制時,就停止搜索返回結果,[<b class="bcl1" id="“b1”">我是第一個段落</b>, <b>我是第二個段落</b>]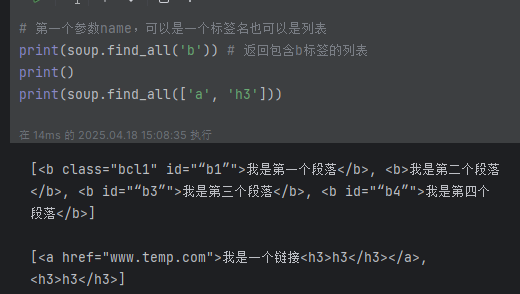
2.3.2.find()
? find()與find_all() 的區別是 find_all() 方法的返回結果是值包含一個元素的列表,而 find() 方法直接返回結果(即找到了就不再找,只返第一個匹配的),find_all() 方法沒有找到目標是返回空列表, find() 方法找不到目標時,返回 None。
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup 對象
# 第一個參數name,可以是一個標簽名也可以是列表
print(soup.find('b')) # 返回<b class="bcl1" id="“b1”">我是第一個段落</b>,只要找到一個即返回# 第二個參數attrs,可以指定參數名字,也可以不指定
print(soup.find('b', 'bcl1')) # <b class="bcl1" id="“b1”">我是第一個段落</b>
print(soup.find(id="myTitle")) # <title id="myTitle">I’m the title</title>
print(soup.find("b", attrs={"class": "bcl1"})) # <b class="bcl1" id="“b1”">我是第一個段落</b>
print(soup.find(id=True)) # 匹配到第一個<title id="myTitle">I’m the title</title># 第三個參數recursive 默認True 如果只想搜索tag的直接子節點,可以使用參數 recursive=False
print(soup.html.find("title", recursive=False)) # None recursive=False。找html的直接子節點,是head,所以找不到title# 第四個參數string
print(soup.find('div', string='str')) # [<div id="dv1">str</div>]
print(soup.find(string=re.compile("我是第二個"))) # 我是第二個段落find匯總
| 方法分類 | 方法名 | 功能描述 |
|---|---|---|
| 父節點搜索 | find_parents() | 搜索當前節點所有符合條件的父輩節點(包括直接父節點和更上層祖先) |
find_parent() | 搜索當前節點第一個符合條件的直接父節點 | |
| 后續兄弟節點搜索 | find_next_siblings() | 返回當前節點后所有符合條件的兄弟節點(同層級) |
find_next_sibling() | 返回當前節點后第一個符合條件的兄弟節點 | |
| 前序兄弟節點搜索 | find_previous_siblings() | 返回當前節點前所有符合條件的兄弟節點(同層級) |
find_previous_sibling() | 返回當前節點前第一個符合條件的兄弟節點 | |
| 后續所有節點搜索 | find_all_next() | 返回文檔中當前節點之后所有符合條件的節點(不限于兄弟節點,跨層級) |
find_next() | 返回文檔中當前節點之后第一個符合條件的節點 | |
| 前序所有節點搜索 | find_all_previous() | 返回文檔中當前節點之前所有符合條件的節點(不限于兄弟節點,跨層級) |
find_previous() | 返回文檔中當前節點之前第一個符合條件的節點 |
2.3.3.CSS選擇器查找
soup.select()?方法概述
- 作用:通過 CSS 選擇器語法快速定位 HTML/XML 文檔中的標簽或節點。
- 返回值:返回一個?
ResultSet(類似列表的對象),包含所有匹配的節點。若無匹配則返回空列表?[]。 - 優勢:語法簡潔,支持復雜層級選擇(比?
find_all?更靈活)。
參數解析
select('selector')
- 唯一參數:字符串類型的 CSS 選擇器表達式。
- 支持的選擇器類型:
選擇器類型 示例 說明 標簽選擇器 'div'選擇所有? <div>?標簽類選擇器 '.header'選擇? class="header"?的標簽ID 選擇器 '#main'選擇? id="main"?的標簽層級選擇器 'div > p'選擇? <div>?直接子級的?<p>屬性選擇器 '[href]'?或?'[data-id="1"]'按屬性名或屬性值篩選 組合選擇器 'div.header, p#intro'多條件組合選擇(逗號分隔)
- 支持的選擇器類型:
from bs4 import BeautifulSoup
import remarkup = '''<!DOCTYPE html>
<html><head><meta charset="UTF-8"><title id="myTitle">I’m the title</title></head><body><div><p><b id=“b1” class="bcl1">我是第一個段落</b><b>我是第二個段落</b><b id=“b3”>我是第三個段落</b><b id=“b4”>我是第四個段落</b></p><a href="www.temp.com">我是一個鏈接<h3>h3</h3></a><div id="dv1">str</div></div></body>
</html>'''
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup 對象
print(soup.select("html head title")) # [<title id="myTitle">I’m the title</title>]
print(soup.select("body a")) # [<a href="www.temp.com">我是一個鏈接<h3>h3</h3></a>]
print(soup.select("#dv1")) # [<div id="dv1">str</div>]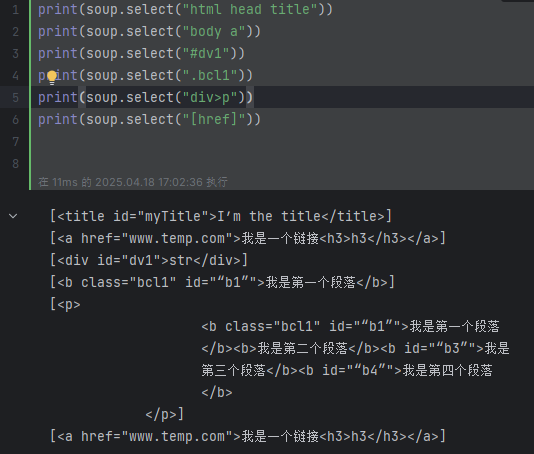
2.3.4.修改內容
?修改tag的名稱、屬性、內容
from bs4 import BeautifulSoupsoup = BeautifulSoup('<b class="boldest">Extremely bold</b>', "html5lib")
tag = soup.b
tag.name = "blockquote"
print(tag) # <blockquote class="boldest">Extremely bold</blockquote>tag['class'] = 'veryBold'
tag['id'] = 1
tag.string = "replace"tag.append(" append")#添加內容del tag['id'] # 刪除屬性添加非標簽內容:
from bs4 import BeautifulSoup, NavigableString, Commentsoup = BeautifulSoup('<div><b class="boldest">Extremely bold</b></div>', "html5lib")
tag = soup.div
new_string = NavigableString('NavigableString')
tag.append(new_string)
print(tag) # <div><b class="boldest">Extremely bold</b>NavigableString</div>new_comment = soup.new_string("Nice to see you.", Comment)
tag.append(new_comment)
print(tag) # <div><b class="boldest">Extremely bold</b>NavigableString<!--Nice to see you.--></div># 添加標簽,推薦使用工廠方法new_tag
new_tag = soup.new_tag("a", href="http://www.example.com")
tag.append(new_tag)
print(tag) # <div><b class="boldest">Extremely bold</b>NavigableString<!--Nice to see you.--><a href="http://www.example.com"></a></div>???把元素插入到指定的位置:
from bs4 import BeautifulSoupmarkup = '<a href="http://example.com/">I linked to <i>example.com</i></a>'
soup = BeautifulSoup(markup,"html5lib")
tag = soup.a
tag.insert(1, "but did not endorse ") # 和append的區別就是.contents屬性獲取不一致
print(tag) # <a href="http://example.com/">I linked to but did not endorse <i>example.com</i></a>
print(tag.contents) # ['I linked to ', 'but did not endorse ', <i>example.com</i>]將當前tag移除文檔樹,并作為方法結果返回:?
from bs4 import BeautifulSoupmarkup = '<a href="http://example.com/">I linked to <i>example.com</i></a>'
soup = BeautifulSoup(markup, "html5lib")
a_tag = soup.a
print(a_tag)#<a href="http://example.com/">I linked to <i>example.com</i></a>
i_tag = soup.i.extract()print(a_tag) # <a href="http://example.com/">I linked to </a>
print(i_tag) # <i>example.com</i> 我們移除的內容| 方法 | 功能描述 | 示例代碼 | 輸出結果 | 關鍵區別 |
|---|---|---|---|---|
decompose() | 完全移除并銷毀節點,不可恢復 | soup.i.decompose()print(a_tag) | <a href="...">I linked to </a> | 永久性刪除,內存中不再存在 |
replace_with() | 用新節點/文本替換原節點,保留文檔結構 | new_tag = soup.new_tag("b")new_tag.string = "example.net"soup.a.i.replace_with(new_tag) | <a href="...">I linked to <b>example.net</b></a> | 可靈活替換為任意節點類型(標簽/文本/注釋等) |
unwrap() | 移除當前標簽,但保留其內容(解包操作) | a_tag.i.unwrap()print(a_tag) | <a href="...">I linked to example.com</a> | 僅去除標簽外殼,內容提升到父層級 |
wrap() | 用新標簽包裹指定內容(反向操作) | soup2.p.string.wrap(soup2.new_tag("b"))print(soup2.p) | <p><b>I wish I was bold.</b></p> | 常用于添加格式化標簽(如加粗/高亮) |
2.4.輸出
2.4.1.格式化輸出
prettify()?方法將Beautiful Soup的文檔樹格式化后以Unicode編碼輸出,每個XML/HTML標簽都獨占一行。
from bs4 import BeautifulSoupmarkup = '<a href="http://example.com/">I linked to <i>example.com</i></a>'
soup = BeautifulSoup(markup, "html5lib")
print(soup) # <html><head></head><body><a href="http://example.com/">I linked to <i>example.com</i></a></body></html>
print(soup.prettify()) #<html># <head># </head># <body># <a href="http://example.com/"># I linked to# <i># example.com# </i># </a># </body># </html>2.4.2.壓縮輸出
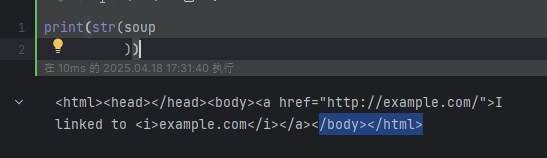
果只想得到結果字符串,不重視格式,那么可以對一個?BeautifulSoup?對象或?Tag?對象使用Python的str()?方法。
2.4.3.文本輸出
如果只想得到tag中包含的文本內容,那么可以調用?get_text()?方法。
from bs4 import BeautifulSoupmarkup = '<a href="http://example.com/">I linked to <i>example.com</i>點我</a>'
soup = BeautifulSoup(markup, "html5lib")
print(soup)
print(str(soup))
print(soup.get_text())?
?3.re標準庫
? BeautifulSoup庫,重html文檔中篩選我們想要的數據,但這些數據可能還有很多更細致的內容,比如,我們取到的是不是我們想要的鏈接、是不是我們需要提取的郵箱數據等等,為了更細致精確的提取數據,那么正則來了。
? ? 正則表達式(英語:Regular Expression,在代碼中常簡寫為regex、regexp或RE),是計算機科學的一個概念。正則表達式使用單個字符串來描述、匹配一系列匹配某個句法規則的字符串。在其他語言中,我們也經常會接觸到正則表達式。 ? ?
| 方法/概念 | 代碼示例 | 關鍵說明 |
|---|---|---|
| re.compile() | pat = re.compile('\d{2}') | 預編譯正則模式,匹配連續2位數字 |
| search() | pat.search("12abc") | 在任意位置搜索首次匹配,成功返回Match對象 |
| match() | pat.match('1224abc') | 僅從字符串起始位置匹配,成功返回Match對象 |
| findall() | re.findall(r'apple',s)re.findall(r'apple',s,re.I) | 默認區分大小寫,re.I標志忽略大小寫 |
| sub()替換 | re.sub('a','A','abcdacdl') | 將所有小寫a替換為大寫A |
import re# 創建正則對象
pat = re.compile('\d{2}') #出現2次數字的
# search 在任意位置對給定的正則表達式模式搜索第一次出現的匹配情況
s = pat.search("12abc")
print(s.group()) # 12# match 從字符串起始部分對模式進行匹配
m = pat.match('1224abc')
print(m.group()) # 12# search 和 match 的區別 匹配的位置不也一樣
s1 = re.search('foo', 'bfoo').group()
print(s1) # foo
try:m1 = re.match('foo','bfoo').group() # AttributeError
except:print('匹配失敗') # 匹配失敗# 原生字符串(\B 不是以py字母結尾的)
allList = ["py!", "py.", "python"]
for li in allList:# re.match(正則表達式,要匹配的字符串)if re.match(r'py\B', li):print(li) # python# findall()
s = "apple Apple APPLE"
print(re.findall(r'apple', s)) # ['apple']
print(re.findall(r'apple', s, re.I)) # ['apple', 'Apple', 'APPLE']# sub()查找并替換
print(re.sub('a', 'A', 'abcdacdl')) # AbcdAcdl
?






)


)
)



)
-像 Arduino 一樣玩 FPGA)
——統計學解構材質與光影)


