1 背景
為滿足高效部署的需要,整合大量優化的tensor代數庫和運行時做為后端成為必要之舉。現在的深度學習后端可以分為兩類:1)算子庫(operator kernel libraries),為每個DL算子單獨提供高效地低階kernel實現。這些庫一般也支持算子融合,可以將多個算子按照融合規則組合為一個kernel實現。2)圖推理庫(graph inference libraries),將整個DL模型作為輸入并生成高效地運行時代碼。除了包含優化的算子庫,圖推理庫還可以處理跨kernel的優化如內存優化。
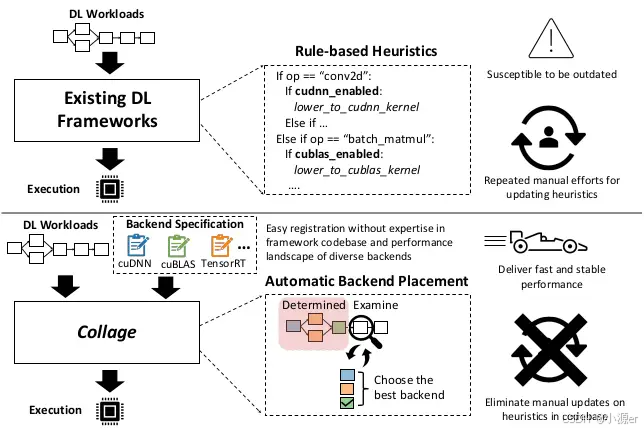
無縫整合后端面臨兩個挑戰,一是要為不同編程模型整合多種可用后端同時保證性能問題;二是優化后端的分配策略權衡每個后端的性能優勢。但是現有的框架都是基于規則的方式,按照固定的優先策略將每個算子降階到不同后端,如上圖所示。比如在Pytorch中卷積操作優先選擇cuDNN,矩陣乘優先選擇cuBLAS。手動地選擇后端,這會降低系統潛在性能,減緩不同層之間的連續性,并且開發者需要快速改變編碼規則適配新版本的代碼庫。并且即便對于同一類型的算子,最優后端也是依賴于硬件和算子配置的。
為解決這些問題,Collage提供了一個無縫的整合方案,通過提供有表達力的后端接口允許用戶精確地指定多種后端,并且Collage可以為給定模型自動搜尋最優的后端安置策略。
2 結構
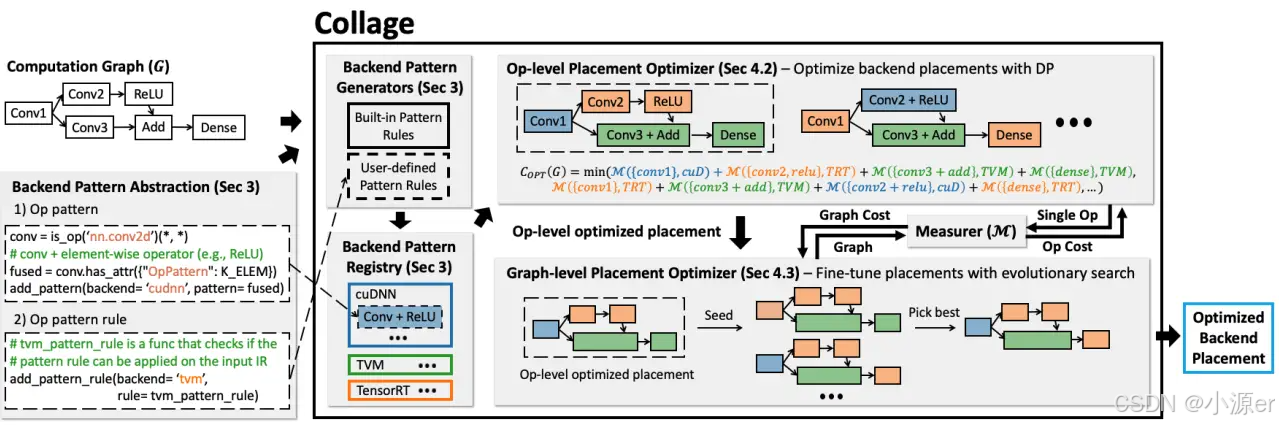
Collage包含兩個關鍵部分,一是提供了具有表達力的后端注冊接口來指定后端的能力,該能力基于支持的算子類型、配置信息和融合規則確定。該接口只需要理解提供的匹配語言即可。二是后端分配策略。Collage采用了兩階段的優化策略來處理operator kernel library 和graph inference library兩種類型后端的特征。該系統會將全部后端和硬件考慮在內,自動地匹配計算圖和后端算子pattern,找到最優的分配方案。
下圖列舉了Collage的整體結構,以DNN模型和可用的后端作為輸入,然后為底層硬件優化后端分配策略。這里考慮的是對于給定目標硬件選擇不同組后端,通過度量組件M來評估性能特點。
2.1 Backend pattern abstraction
準確的指定執行平臺對于發揮后端全部能力至關重要。后端模板(backend pattern)定義了一組算子和可以直接部署在各個后端的算子組合。然后Collage提供了一個兩階段的抽象,對于簡單的pattern,直接列舉出全部支持的算子pattern。對于復雜情況,用戶可以指定pattern創建規則,如指定簡單算子類型和復雜算子融合規則。當融合規則給定,整個計算圖上的滿足條件的模板都會被保存在后端模板注冊表中。

Collage的pattern是Relay Pattern Language的拓展,為所有支持的算子直接指定pattern。對于復雜情況難以直接指定的,可以通過pattern rule指定一組算子的融合規則。該規則可以通過python語法特性來表示。
對于每一個后端,用戶可以通過直接指定pattern和pattern rule來提供編程接口。如上圖所示,如果后端支持的算子有限,可以將所有pattern枚舉出來如3-12行代碼;對于復雜pattern,Collage的pattern生成器可以指定復雜規則如14-53行所示。生成器內部可以指定檢查器判斷約束條件(20-30行),可以以python代碼的形式指定融合規則(32-49行)。
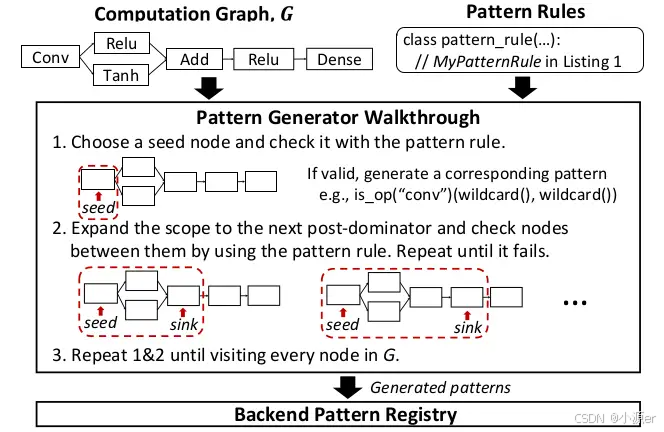
在確定好pattern后,Collage會搜索所有滿足條件的規則,并將這些規則實例添加到backend pattern registry中。上圖展示了搜索邏輯,pattern generator會按照pattern rule貪心地搜索。對于每個算子首先判斷是否可在后端執行,然后進一步向外擴展一步判斷是否滿足融合規則,一旦條件滿足則將對應pattern添加至pattern注冊表,然后進一步擴大一步匹配范圍。
2.2 Backend placement optimizer
當可用的模板注冊好后,Collage會采用一個兩階段的優化方法為當前執行環境找到一個最優的后端安置策略。首先,算子庫級的分配優化器會采用動態規劃算法為每個算子尋找最優的后端平臺,不需要考慮跨內核優化問題。其次,圖級分配優化器通過演化搜索算法找最優后端。該部分會考慮跨內核的優化,并作為算子級優化的補充。
2.2.1 問題定義
對于多個后端,Collage的目的是最大化利用可用后端發揮性能最大化。對于后端選擇問題,可以將計算圖記作G,后端pattern記作B,是一個算子和pattern對兒,p表示具體pattern,d表示后端的標識。p和d都不是唯一對應的,一個p可以在多個d中被滿足,一個d可以包含多個p,這樣p和d的組合可以唯一確定一個后端和pattern。
對于M個匹配的子圖和后端patern
,集合
可以表示計算圖G上的后端分配策略即將子圖
放置在
上,其中Cost(P(G))表示函數P(G)的執行時間。Collage的目的是通過最小化Cost(P(G))找到一個分配策略
。
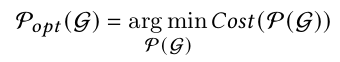
2.2.2 Op_level Placement Optimizer
首先,第一步是算子級的分配優化。其目的是將所有算子映射到可用后端的kernel實現集合上,不需要考慮cross-kernel的優化。通過這種簡化,在執行過程中,kernel的執行彼此是獨立的。
假設s1和s2是兩個不相交,互補的子圖,那么執行時間cost可以表示為
![]()
其中表示上下文的切換時間。
Collage采用動態規劃算法來優化算子級后端分配策略。根據上面的cost分解公式,可以將在整個計算圖上尋找最優分配策略縮小為在一系列子圖中找最優策略P(S)的總和。
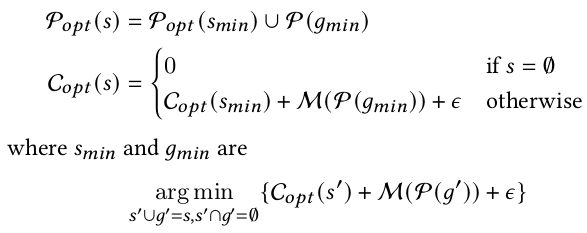
其中,s'表示已經評估過的子圖,g'表示待評估的子圖, M是評估方法。這里子圖的粒度是一個后端pattern,可以是一個單個算子,也可以是復合算子(多個算子)。因為算子都會降階為單個kernel,該方法就可以每次只評估單個kernel并將結果加到之前的評估結果中。
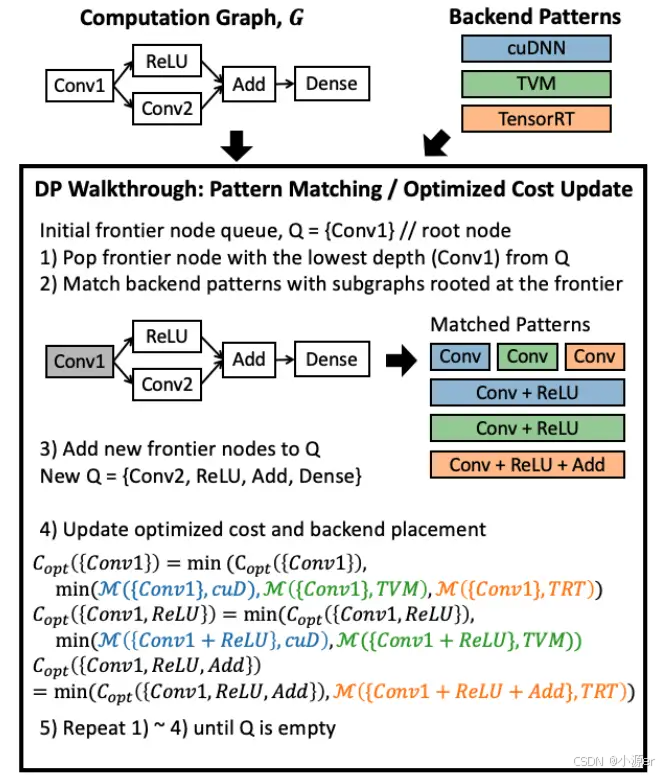
下圖展示了整個DP算法的流程。首先,將根節點添加進優先隊列并將該節點作為初始的前驅節點,前驅節點是指從所有根節點可達的未訪問的節點中路徑最短的那個節點。然后將該節點出隊,判斷是否有以該節點為根節點的pattern,一旦匹配上,則評估該子圖并添加新的前驅節點到隊列。當確定了最優安置策略后,按照優化公式更新cost。
具體來講,對于一個計算圖,輸入節點是root,作為隊列第一個元素。然后出隊,在所有注冊的pattern實例中,找以該節點為根節點的子圖組成集合S,元素形式是(si, bj),是一種分配策略,并將當前節點的前驅節點集合中所有沒有加入優先隊列的節點都加入隊列。然后利用cost函數一次評估所有S中的子圖策略,找到損失最小的的子圖策略。
下圖中3)步不對,應該是Q={Conv2, ReLU}。

2.2.3 Graph-level Placement Optimizer
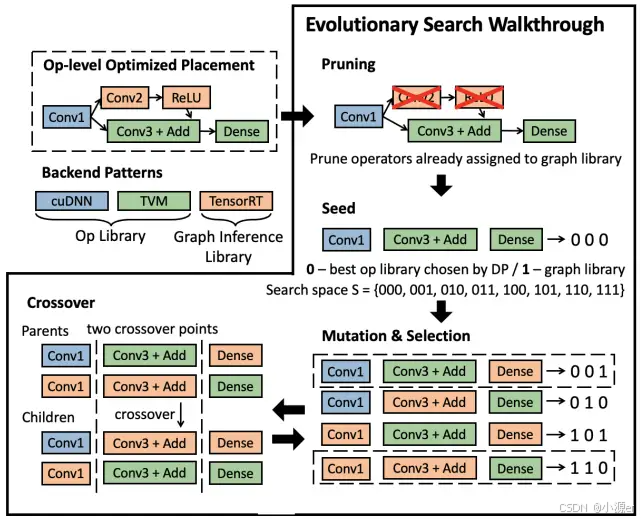
op-level分配策略優化是將kernel視作獨立的,忽視了圖推理庫中的cross-kernel優化如調度優化、內存優化等。因此,Collage引入了graph-level優化,在op-level基礎上進一步微調優化,其目的是識別沒有分配到圖推理庫,但是可以進行cross-kernel優化的算子,將這些算子放在圖推理庫中進行cross-kernel優化。
操作的難點在于找到這些算子。Collage首先在op-level優化的基礎上將已經分配到圖推理庫的算子進行剪枝,然后對于剩下的節點進行嘗試分配。為減少復雜性,這里對是否分配到圖推理庫進行區分,用0/1標注,1表示分配到圖推理庫中,0表示放在算子級推理庫中。然后采用的演化算法,多次的嘗試不同的策略調優結果。
3 工程細節
注意!!!由于本人目前還沒有徹底搞懂Collage的代碼實現邏輯,這里先簡單翻譯以下github上的解釋,等把源碼搞清楚了再回來填坑吧。
3.1 相關前導工作
1)[Cascading Scheduler](https://github.com/apache/tvm-rfcs/blob/main/rfcs/0037-arm-ethosu-cascading-scheduler.md)采用動態規劃找到TE子表達式最優的組合;引入了損失分析模型引導搜索;逐級調度TE子表達式,降低內存瓶頸。相較之Collage也采用了動態規劃,但找的是Relay子表達式的最優組合,然后用了更慢的評估方式引導搜索并且對TVM或BYOC工具鏈如何降級子圖沒有任何影響。
2)Universal modular Accelerator Interface?在現有和單獨的TVM BYOC、算子策略、算子調度、特定目標Pass和特定目標代碼生成擴展點的基礎上增加了一層。Collage目前僅依賴于全局模式注冊表和全局relay.ext.<toolchain>函數來與BYOC集成。
3.2 Collage的優缺點
1)Collage的優點:
- 延遲:與TVM原生、具有單個partition_for_<toolchain>調用的TVM或TensorRT等非TVM獨立編譯器相比,整體模型延遲可能會減少。
- 自動化:可以自動選擇啟用哪些BYOC工具鏈。
- 實現的經濟性和模塊化:以前分割需要MergeComposite/AnnotateTarget/MergeCompilerRegions/?PartitionGraph四個Pass,現在可以用一個CollagePartitioner替代
- Collage在標準ONNX和NVIDIA硬件選擇延遲上做到了10%的提升
- Collage不需要獨立于BYOC單獨為每個新硬件或模型創建pattern
- 相較于直接使用現有的partition_for_<toolchain>函數,多BYOC工具鏈,多Target的Collage效果不會太差。
2)Collage的缺點:
- 需要一些BYOC模板上的改變:TVM當前的BYOC集成接口將需要“lowering/codegen”函數注冊到全局函數名,其他的就取決于BYOC開發者了。而Collage要求基于pattern的BYOC集成將他們自己的pattern注冊到全局pattern表中。并且Collage要求BYOC lowering函數能生成一個可用的runtime::Module并且不需要任何額外的Pass。Collage還需要BYOC集成能正確判斷那些算子是pattern支持的或者在候選kernel中遇到不支持的算子能優雅地傳播錯誤而非簡單檢查錯誤。
- 非組合的BYOC工具鏈:BYOC分割函數通常運行全局pass將Relay計算圖轉化為一個更好對齊工具鏈的狀態。一般假設這些分割pass是專屬的,可以劃歸為全局配置或者劃歸為BYOC lowering/codegen函數或者劃歸為運行在CollagePartitioner之前的標準Relay優化pass。
- 較高的調優損失:很明顯,Collage需要評估分割結果的延時。因為TVM會對新的kernel觸發調度調優過程,這會嘗試上千次試驗,花費近幾個小時,因此需要調優日志減緩時間開銷。
- 任務提取VS調優:傳統TVM有三個階段,1)提取任務,即找到融合的子圖以調優,2)調優,即為這些子圖找到好的調度,3)編譯,重新編譯模型,從緩存中為所有選擇的子圖檢索調度。但在Collage的第二版實現中將三個階段進行折疊,把重點放在了評估候選項和調優的損失上,因為這些會影響最終的分割結果。
- 沒有非局部的優化:盡管Collage可以左右子圖或者工具鏈的選擇,但他無法影響子圖的參數或者結果,也無法改動IRModule。比如,Collage無法用來搜索layout的參數,內存的范圍以及量化范式的選擇。
- 依賴管理:目前,BYOC集成傾向于假設它們是唯一使用的非TVM工具鏈。因此,兩個工具鏈可能會引入無法滿足的運行時依賴關系。Collage沒有依賴或不兼容的概念,并且可能會試圖融合在生產中無法支持的候選內核。
- 可加性損失假設:根據這種設計,Collage假設運行候選分區的成本是累加的,再加上一個小的轉換損失。然而,緩存耗時可能會主導測量的延遲,特別是對于“輕量級”內核。
- 搜索空間受限:遍歷所有子圖的復雜度是O(n!),所以需要限制搜索。最簡單的方法就是將候選對象限制在只有幾個運算符的子圖中。這可能意味著在沒有探索到更快的候選者時已經產生了具有高最優性損失的分區。
- 脆弱的工具鏈:一些BYOC工具鏈本身就是獨立的編譯器,已經針對常見模型進行了調整,并包含全局標志來指導降低精度等優化。然而,Collage只會為這些工具鏈提供較小的子圖,從而使有限的搜索空間問題更加嚴重。
- 輕量級內核中的高方差:小內核可能具有高方差,因此使用哪個工具鏈的選擇可以是任意的。我們可能想i)驗證我們的方差估計器是否準確,ii)為估計的候選內核延遲選擇一個略高于50%的百分位數,iii)當測量的方差太高時,退回到硬編碼的優先級。
- 可解釋性:向用戶顯示每個內核的最終分區和估計時間很容易,但很難說明為什么在搜索過程中分區會勝過其他所有分區。
- 不包含partition_for_<toolchain>:我們沒有任何計劃來棄用每個提供partiion_for_<toolchain>函數的BYOC集成的現有模式。如果用戶心中有一個特定的工具鏈,那么顯式地創建分區既可以加快編譯速度,又可以包含Collage目前無法解釋的全局優化過程(例如強制執行特定的布局)。
3)TVM目前的特點:
- 貪心:只支持分割盡可能最大的子圖,不考慮時間代價。而Collage可以探索更多子圖,在混合工具鏈中,兩個小子圖可能比一個大子圖整體時延更低。
- 手動:目前,TVM用戶必須提交到BYOC工具鏈,并在主TVM編譯流開始之前調用相應的partition_for_<toolchain>函數。使用Collage,可以根據測量的延遲自動選擇工具鏈。Collage還將探索多個BYOC工具鏈以及TVM原生后端之間的混合和匹配。
3.3 早期的函數庫集成
TVM有兩種不同的方式使用外部內核庫即pattrn-based的BYOC方法和TVM的te.extern方法。
基于pattern的方法允許函數庫中的實現匹配一個或多個relay算子。比如在dnnl的實現中,pattern標簽與對應的dnnl函數實現相匹配,代碼位于python/tvm/relay/op/contrib/dnnl.py,用戶只需要調用MergeComposite/AnnotateTarget/PartitionGraph實現分割即可。注意,這里沒有方便的parition_for_dnnl函數。src/relay/backend/contrib/dnnl/codegen.cc中的BYOC函數relay.ext.dnnl會在全部的“Primitive”函數中調用“Composite”函數并基于“Composite”標簽分發函數。C代碼會映射到DNNL庫中并調用標準C編譯器生成runtime::Module。
對于TVM生成的內核函數是無法按照上述方法調用庫函數的。事實上每個庫函數都會具體調用到某個庫中單個具體的kernel上,這些kernel也可以被多個庫函數組合方式的調用。換句話說,TVM調用的外部庫可以是直接調用單個kernel實現功能,也可以是將外部庫的kernel作為TVM調用的函數的一部分。
te.extern方法只允許庫函數實現和relay 算子一一對應。但是這些庫可以作為TVM生成的大的kernel的一部分,常規的TVM調優策略可能會基于性能選擇庫。舉個例子,算子batch_matmul可以采用python/tvm/contrib/cublas.py中的策略,通過CuBLAS實現。當Target的libs屬性中出現cublas,代碼python/tvm/relay/op/strategy/cuda.py中的策略batch_matmul_stategy_cuda就會被激活,該策略會簡單調用src/runtime/contrib/cublas/cublas.cc中的PackedFunc函數tvm.contrib.cublas.batch_matmul作為TVM runtime的一部分。te.extern方法也支持集成微內核作為大relay算子TVM調度的一部分。
Collage可以和上述任何一種方法搭配。對于基于pattern的BYOC方法,Collage只需要帶有匹配編譯器屬性的Target即可。對于te.extern方法,Collage同樣不需要了解TVM分割會生成一個調度中包含鏈接庫調用的內核,只需要確保Target有適當的libs屬性即可。
為了確保Collage能無縫集成庫函數,需要滿足幾點:
需要支持匹配子圖的庫函數同時也要支持單個relay算子且允許在TVM生成的kernel中被調用的庫函數
- 避免對全量BYOC模板的需求,但保留BYOC類似的pattern機制
- 用選擇分割方式相同的方式選擇外部函數庫
一種可能的方式:
- 類似于te.extern,函數庫可以通過注冊PackedFunc方式在TVM runtime中使用
- 類似于pattern-based BYOC,標記的pattern可用于指定;relay算子如何映射到注冊的PackedFunc中
- 類似于BYOC自定義降階策略,當外部函數庫可用時通過編譯器名按照不同路徑降階
- 不同于BYOC自定義降階策略,對外部函數調用的重寫可以在TE或者TIR中進行,這樣可以整合到更大的TVM kernel中。
3.4 引導級解釋
Collage允許自動選擇BYOC工具鏈的分割以減小整體模型執行延遲。為了在編譯過程中使用Collage,需要在PassContext中添加標簽并在構建過程中引入Collage感知的target參數。如下,可以在編譯時用一系列NVIDIA的工具鏈或者庫。

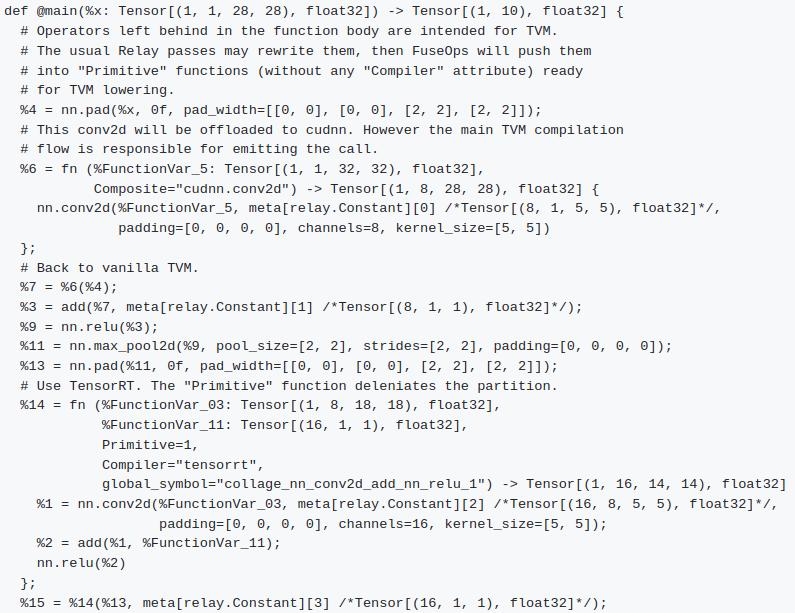
對于模型

經過CollagePartitioner Pass后,原來的全局函數main變為如下形式

3.5 引用級解釋
Collage的實現主要在src/relay/collage/目錄下,tvm::relay::collage命名空間下,一小部分python幫助函數在python/tvm/relay/collage目錄下。如果PassConfig的relay.collage.enable_collage屬性為true,在所有Pass之前使用CollagePartitioner Pass,最終結果是所有全局函數中所有要在BYOC工具鏈處理的Relay子圖會被一個內聯的、帶有Compiler和global_symbol屬性的Primitive函數調用所替換。對于要傳遞到特定庫或者BYOC支持的函數上的Relay算子或者算子組,會被一個內聯的Composite函數調用替換掉。
CollagePartitioner四個階段:
階段一:掃描可用Target,構建一組可以描述如何找到可能分區的規則。涉及類:PartitionSpec和PartitionRule。
階段二:為全局函數構建數據流圖(對應類IndexedGraph<Expr>)。階段一中的規則會在數據流圖中匹配一遍,為每個target生成一組候選分割方案(對應類CandidatePartition),每個候選方案都可以高效描述全局函數中的一個子圖。
階段三:在搜索圖中尋找最短損失路徑。該搜索圖中每個搜索節點對應數據流圖中的一組被“覆蓋”的數據流節點,這些節點被分配到了從起始節點到當前節點的每條路徑上的候選分區中。起始節點是指“覆蓋”集是空的的搜索節點。結束節點是指“覆蓋”集合中包含所有數據流節點的搜索節點。
搜索邊X->Y:候選分區P與X的“覆蓋”節點沒有交集,Y的“覆蓋”節點是X和P的并集。為避免不必要的搜索空間拓展,后選集必須包含X中下一個還未被覆蓋的數據流節點。
邊損失:候選分區的評估延時加分區傳輸延遲。需要注意的是,盡管需要能夠提取候選子圖構建函數以評估,但是沒必要分割整個函數表達式。
階段四:根據最短路徑上的候選kernel分割函數體。該步驟和前三個階段是獨立的,也就是說可以在中間插入其他的優化過程。
3.5.1 核心數據結構
接下來先介紹重要的數據類型,然后再解釋這些階段。
Util Datatypes
PostDfsIndex:在整個Relay表達式后序dfs遍歷中,Relay子表達式的整型索引。如果索引i小于索引j,則表示索引j表示的子表達式不能影響到索引i對應子表達式的值。
DataflowGraph:IndexedGraph<Expr>的別名,用于管理Relay ExprNode到PostDfsIndex到DataflowGraph::Node的三路雙射關系。每個DataflowGraph::Node描述了子表達式的數據流輸入、輸出、指示器和反指示器。
IndexSet:PostDfsIndex索引的bit向量。用作數據流圖中任意數據流節點集合的壓縮表示。
Cost:一個雙精度浮點數,表示候選分區的損失,平均執行延遲的秒數。Cost可以是Unkown(NaN)表示一些啟發信息可以用于比較kernel損失。Cost可以是Invalid(inf)表示工具鏈不能編譯,運行候選kernel。
SubGraph
一個SubGraph是整個數據流圖的的任意子圖內的所有數據流節點的PostDfsIndex的IndexSet。SubGraph和PartitionRule是Collage的核心數據類型。下圖展示了數據流圖、索引和一個微型MNIST的子圖。
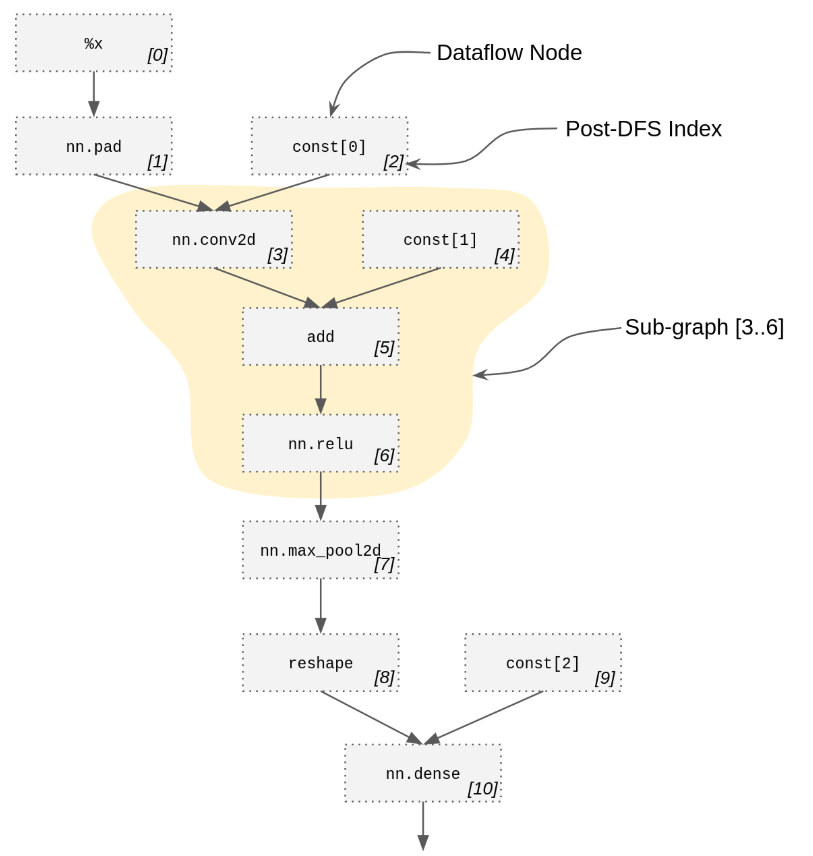
子圖可以用于表示分區/內核/組合函數,不需要承擔構建或者重寫表達式的代價。我們需要提取一個函數用于從重寫的整個Relay表達式中獨立地評估一個分區或者內核的延遲,因為在Collage完成搜索后只需要一個小的候選分區子集。
一個子圖會把整個表達式的每個數據流節點分類為子圖內或子圖外。很明顯,不是所有分割都是對的,比如一個內部節點無法通過一個外部節點到達另一個內部節點。所以我們提供了IsValid方法用于檢查合法性,提供SubGraphConfig用于控制使用那個合法的規則。
我們一般使用的是整個Relay表達式的DataflowGraph表示而不是表達式本身。我們使用后序深度優先遍歷索引唯一地引用表達式節點。
除了“內部”和“外部”,我們還有四種其他類型的數據流節點,它們都是由“內部”節點唯一確定的:
“入口”節點是指內部至少有一個外部數據流輸入的節點。
“退出”節點是指內部至少有一個外部數據流輸出的節點,或者在底層數據流圖中被視為“外部”的節點(例如,因為它們代表了整個函數的結果)。
“輸入”節點是指外部至少有一個數據流輸出的節點。
“輸出”節點是指外部至少有一個數據流輸入的節點。
有多個入口節點是有效的(我們可以為每個節點綁定一個參數)。有多個出口節點可能是有效的(我們可以構建一個所有這些出口節點的元組)。對于有助于其他內部節點的出口節點(即表示對中間結果的“點擊”)可能是有效的。
子圖會在如下條件下關閉:
- 不相交的并集
- 由具有給定屬性的函數包裝。這可用于對“Composite”函數進行編碼,或在“Primitive”函數中表示候選內核。(通過將“包裝”和“聯合”結合起來,我們可以進行編碼,例如,“這個子圖應該放在一個原始函數內,這個原始函數本身可能會調用復合函數)。
- 替換,它允許一個子圖相對于一個數據流圖進行轉換,以匹配另一個(通常較小)數據流圖。
CandidatePartition
一個CandidatePartition對應一個SubGraph和Target。Collage的所有搜索和管理都是針對候選分區而言的。
PartitionRule
一個PartitionRule描述了如何為一個DataflowGraph找到一組CandidatePartitions。PartitionRule和SubGraph是Collage的核心數據類型。所有的分割規則都實現了如下方法:
virtual std::vector<CandidatePartition> AllCandidates(const DataflowGraph& dataflow_graph,const PartitionSpec& spec) const;
候選分區是允許折疊的,然后由Collage的搜索器找到一組可以覆蓋完整Relay表達式但沒有重疊的后選集。
目前有三種不同風格的分區:
- 對于基于pattern的BYOC集成,使用獨立的DFPattern來選擇Composite復合函數來卸載,這些函數會被分組到一個帶有Complier屬性的Primitive Relay函數中。
- 對于基于算子的BYOC集成,每個運算符名字表示要卸載的運算符,這些運算符又被分組到具有“Compiler”屬性的“Primitive”Relay函數中。
- 對于TVM,顯然所有Relay都可以進入一個分區,但是為了搜索效率,分區應該大致模仿Relay FuseOps。該過程在所有Relay運算符上使用“TOpPattern”(類型為OPPatternKind)屬性,以及一種運算符何時可以折疊到另一種運算符的規則(通常是通過將標量運算符從元素運算符移動到較早運算符的輸出位置)。這是作為一個獨立的分析來實現的,它使用“Primitive”函數對結果進行編碼。
為了便于外部庫集成,我們想從基于模式的BYOC集成中借用DFPattern和復合函數方法。但是我們想把這些復合函數放在任何“Primitive”函數之外,這樣庫調用就可以在更大的TVM內核中結束。
類似于DFPattern提供的基礎pattern規則和組合pattern規則,PartitionRule尋求相同的機制。新的基礎pattern規則可以直接在數據流圖上生成候選集;新的組合規則將找到的子規則組合為一組新的后選集合。下圖展示了數據流圖中一些base和combinator pattern。
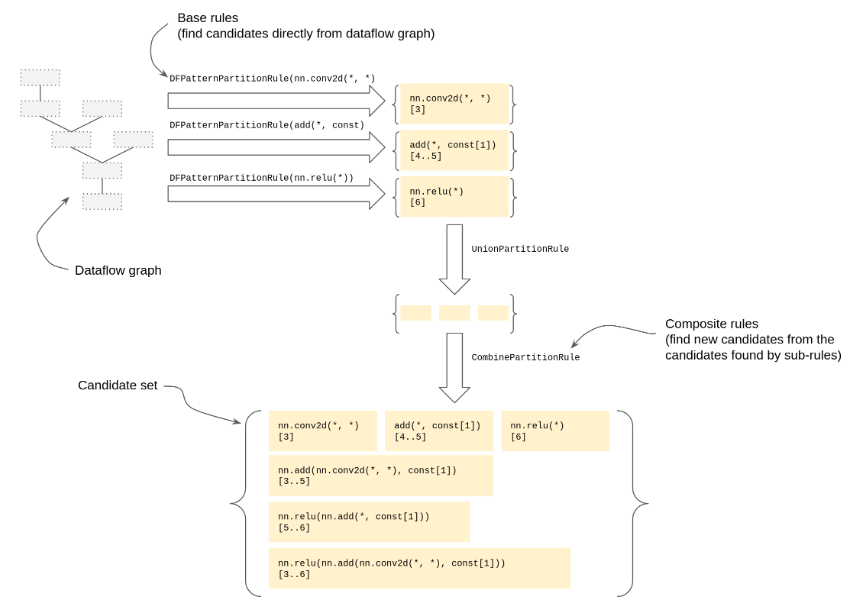
base rules是:
- DFPatternPartitionRule:給定一個DFPattern和表達式指示器,為每個匹配pattern和指示器的子圖生成一個候選結果。不同于PatternRewriter,候選結果可以重疊。
- OpPredicatePartitionRule:給定一個屬性名,為每個私有Relay算子生成一個候選結果。該算子要有匹配的屬性并為給定的子表達式返回true。
- OpCallByKindPartitionRule:為每個Relay算子提供TOpPattern屬性用于為每個對fusable Relay operator的調用生成候選結果。
combinator rules是:
- CompositePartitionRule:指示所有匹配子規則的子候選結果需要被一個"Composite"函數包裹。Composite的名字是rule的名字。用于指示Relay算子或算子組需要被映射到目標指定的算子上。
- PrimitivePartitionRule:指示所有匹配子規則的子候選結果需要被一個"Primitive"函數包裹,可能會帶一個額外的"Compiler"屬性。用于描述分區或內核。
- UnionPartitionRule:簡單地合并來自所有sub-rules的子候選結果。用于組合單獨的DFPatternPartitionRules。
- CombinePartitionRule:給定一個sub-rule和一組combiner rules,找到所有可能組合子候選結果的方式,生成更大的候選結果。需要注意的是子候選結果可能直接包含于結果中。combiner rules允許通過OpPatternKinds組合,將Relay算子調用的參數組合為元組。該規則旨在模擬TVM的FuseOps Pass,通過1)所有的候選結果都會被找到而非只有最大的那個;2)起始的候選結果可以被任何其他規則提供,3)依靠子圖有效性檢查來剔除不可行的候選者。
- OnlyValidPartitionRule:給定一個SubGraphConfig,忽略具有“無效”子圖的候選者。用于限制最大候選深度、獨立輸出的數量以及是否允許中間“taps”。
- HostPartitionRule:為所有Relay表達式生成候選表達式,這些表達式可以“留下”供主機執行(例如在VM上)。這條規則讓我們將特殊情況處理從核心搜索算法中轉移到一條簡單的規則中。
對于不同的分割場景,有一些經典的PartitionRules組合方式(這些組合可能是在phase1,檢查Target和BYOC注冊時生成的):
- 基于經典算子標識符的BYOC,聯合AnnotateTarget/MergeCompilerRegions/PartitionGraph這些Pass(如tensorrt.py)。
PrimitivePartitionRuleOnlyValidPartitionRuleCombinePartitionRule (with a join-anything combiner rule)OpPredicatePartitionRule- 經典基于pattern的BYOC,聯合MergeComposite/AnnotateTarget/PartitionGraph?passes (如cutlass.py)
PrimitivePartitionRuleOnlyValidPartitionRuleCombinePartitionRule (with join-anything combiner rule)UnionPartitionRuleCompositePartitionRule(label1)DFPatternPartitionRule(pattern1):CompositePartitionRule(labeln)DFPatternPartitionRule(patternn)
- CompositePartitionRule/DFPatternPartitionRule組合在pattern表中為每個實體重復出現
CompositePartitionRule(rule_name="cutlass.conv2d_bias_residual_multiply_relu"sub_rule=DFPatternPartitionRule(pattern=CallPatternNode(Op(nn.relu), [AltPattern(CallPatternNode(Op(multiply), [CallPatternNode(AltPattern(Op(add) | Op(nn.bias_add)),[CallPatternNode(Op(nn.conv2d), [*, *]), *]),*]) |CallPatternNode(Op(multiply),[*, CallPatternNode(AltPattern(Op(add) | Op(nn.bias_add)),[CallPatternNode(Op(nn.conv2d), [*, *]), *])]))])))- 考慮這些子表達式的庫實現”,使用DFPatterns來挑選支持哪些Relay運算符
OnlyValidPartitionRuleCombinePartitionRule (with default TVM combiner rules)UnionPartitionRuleOpCallByKindPartitionRuleCompositePartitionRule(lable1)DFPatternPartitionRule(pattern1):CompositePartitionRule(lablen)DFPatternPartitionRule(patternn)- 經典TVM FuseOps
PrimitivePartitionRuleOnlyValidPartitionRuleCombinePartitionRule (with default TVM combiner rules)OpCallByKindPartitionRule- 僅僅融合我讓你融合的,使用DFPattern直接選擇候選結果
PrimitivePartitionRuleOnlyValidPartitionRuleUnionPartitionRuleDFPatternPartitionRule(pattern1):DFPatternPartitionRule(patternn)
PartitionSpec
一個PartitionSpec是由一個PartitionRule和一個或多個Target組成的。
1)Phase1:
我們基于TVM構建以支持異構設備。可用的Targets是使用CompilationConfig從編譯配置信息中提取的。分析每個Target以確定如何構造一個PartitionRule,該規則會引導Collage為目標target選擇候選kernels。
- 如果Target有“partition_rule”屬性,直接使用即可。該方法允許用戶直接控制分區或融合。
- 如果Target有“compiler”屬性,并且全局pattern表中有該屬性值對應實體,假設Target表示要對應pattern-based BYOC集成。PartitionRule會導入所有BYOC pattern并自動對應起來。如果全局pattern中沒有對應實體,假設Target表示predicate-based BYOC集成如tensorrt,PartitionRule會搜索并分析謂詞和所有Relay算子的“target.<compiler>”屬性。
- 假設Target表示TVM原生target,PartitionRule會模仿Fuseps,但目前泛化到探索多個候選結果為可能的BYOC候選結果流出空間。
注意,為了確保該方法有效,我們需要多個Targets可以對應相同的DLDeviceKind。對于虛擬機,簡單將target參數從字典結構轉化為list并移除掉冗余的python預處理代碼。用戶可以使用on_device注釋約束子圖到具體的設備上。當Collage選擇候選分區時,需要確保選擇的候選Target是被PlanDevicesPass發掘的每條子表達式提純過的Target。比如,給定targets T和U,我們定義如果T有“compiler”或/且“partition_rule”屬性,U沒有這些屬性并且T和U在其他方面一致,則稱T提純(refine)U。
2)Phase2:
該階段最難的工作是PartitionRule的實現AllCandidates。主驅動程序只需按最小“內部”PostDfsIndex對所有找到的CandidatePartitions進行索引,以便在最短路徑搜索期間快速檢索。
3)Phase3:
最自然的方法就是通過Dijkstra算法找到最優分區。一個SearchState就是搜索圖上的一個節點,包含:
- 覆蓋到當前狀態的每條路徑上的候選結果的數據流節點的一個IndexSet。這是識別狀態的關鍵。
- 到當前狀態的最優路徑上的前一個SearchState
- 到當前狀態最優路徑的Cost,是Dijkstra優先隊列的順序
- 從上一個最優狀態到當前狀態轉化的CandidatePartition
起始狀態沒有覆蓋的節點,最終狀態包含所有覆蓋的節點。下圖為mini MNIST搜索圖中的一段:
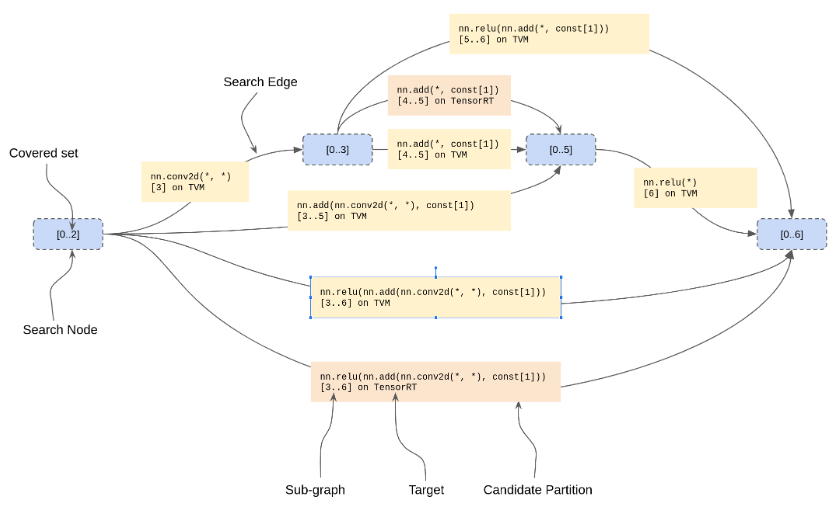
在擴展狀態時,我們可以選擇從Phase 2收集的任何CandidatePartition,只要它不與狀態的覆蓋集重疊。然而,應用候選C然后D的搜索路徑等價于應用D然后C的搜索路徑,因此我們只考慮與下一個尚未覆蓋的數據流節點相交的候選。對于每個這樣的候選,我們使用CostEstimator(帶有假定的緩存)來獲取候選的成本,構建后繼狀態,并以通常的方式“放松”后繼狀態。
HostPartitionRule用于允許某些數據流節點“留下”供主機執行。此階段的結果是一個Array<CandidatePartition>,如果需要,可以使用標準的TVM對象圖機制對其進行物化和恢復。mini-MNIST示例的最低成本路徑示例如下
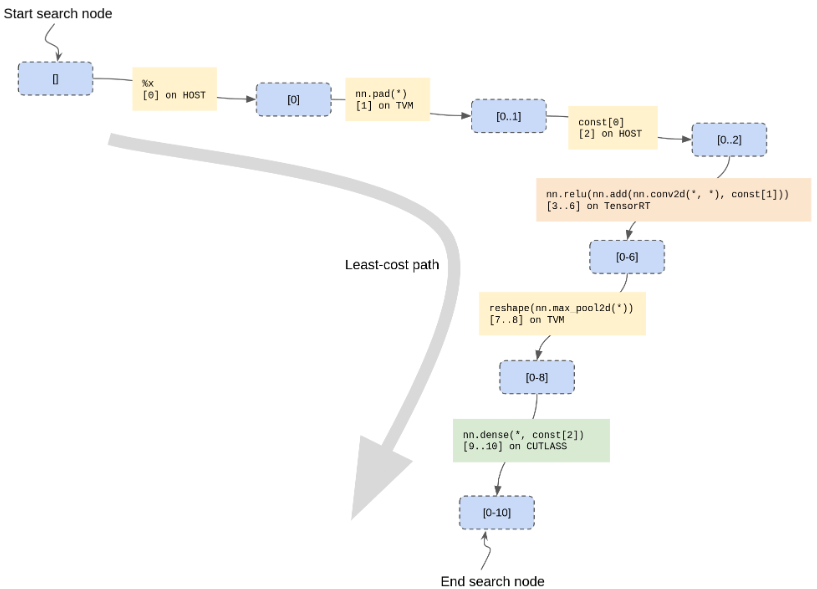
4)Phase4:
整個Relay表達式在最低成本路徑上的所有CandidatePartitions上“并行”分區。由于所有候選對象都是使用相對于原始數據流圖的子圖表示的,因此我們必須小心,不要在進行時使尚未分區的候選對象無效。按數據流順序反向工作可以避免這個問題。
4 參考
[2111.00655] Collage: Seamless Integration of Deep Learning Backends with Automatic Placement
https://github.com/apache/tvm-rfcs/blob/main/rfcs/0062-collage.md

)
)



)
-像 Arduino 一樣玩 FPGA)
——統計學解構材質與光影)





)

)


)