ChatPDF 知識庫
RAG檢索增強
由于訓練大模型非常耗時,再加上訓練語料本身比較滯后,所以大模型存在知識限制問題:
-
知識數據比較落后,往往是幾個月之前的;不包含太過專業領域或者企業私有的數據;
-
為了解決這些問題,就需要用到RAG了。
RAG原理
RAG 的核心原理是將檢索技術與生成模型相結合,結合外部知識庫來檢索相關信息來增強模型的輸出,其實就是給大模型掛一個知識庫
其核心工作流程分為三個階段:
- 接收請求: 首先,系統接收到用戶的請求(例如提出一個問題)
- 信息檢索?: 系統從一個大型文檔庫中檢索出與查詢最相關的文檔片段。這一步的目標是找到那些可能包含答案或相關信息的文檔。這里不一定是從向量數據庫中檢索,但是向量數據庫能反應相似度最高的幾個文檔(比如說法不同,意思相同),而不是精確查找
- 生成增強(A): 將檢索到的文檔片段與原始查詢一起輸入到大模型(如chatGPT)中,注意使用合適的提示詞,比如原始的問題是XXX,檢索到的信息是YY,給大模型的輸入應該類似于: 請基于YYY回答XXXX。
- 輸出生成(G): 大模型LLM 基于輸入的査詢和檢索到的文檔片段生成最終的文本答案,并返回給用戶
注意:知識庫不能寫在提示詞中,因為通常知識庫數據量都是非常大的,而大模型的上下文是有大小限制的,那怎么辦呢?
只要想辦法從龐大的知識庫中找到與用戶問題相關的一小部分,組裝成提示詞,發送給大模型就可以了;那么該如何從知識庫中找到與用戶問題相關的內容呢?
- 全文檢索?但在這里是不合適的,因為全文檢索是文字匹配,而這里要求的是內容上的相似度;
- 而要從內容相似度來判斷,這就不得不提到向量模型的知識了。
向量模型
向量是空間中有方向和長度的量,空間可以是二維,也可以是多維;向量既然是在空間中,那么兩個向量之間就一定能計算距離;
向量之間的距離一般有兩種計算方法:
歐幾里得距離
在n維空間中,兩點間的直線距離。它是兩點間最直接的距離測量方式。很適合用于RGB色彩空間中衡量兩種顏色之間的差異
顏色可以用 RGB 值表示,然后通過計算兩種顏色 RGB 值之間的歐幾里得距離來判斷它們的相似度。
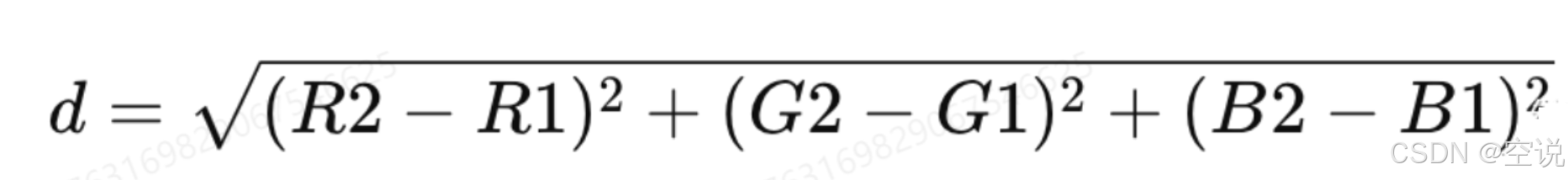
- R G B: 兩個顏色的 RGB 分量(紅色、綠色、藍色)
- d: 兩個顏色之間的歐幾里得距離。
- 距離越小,表示顏色越相似; 距離越大,表示顏色越不同
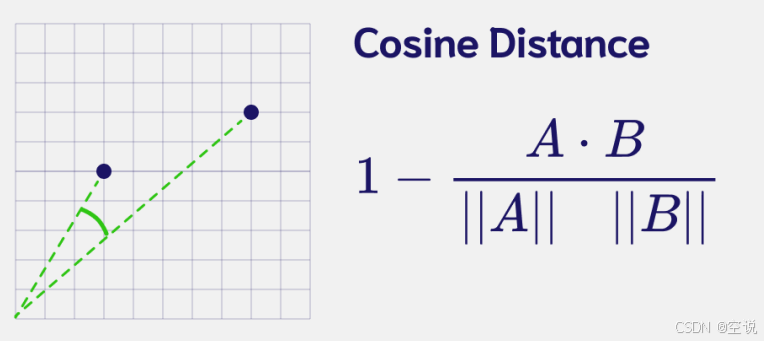
余弦相似度
通過比較兩個向量之間的夾角余弦值來衡量它們的方向是否相似,如果夾角余弦值越小,說明它們越相似,但這種方法不能考慮到向量的大小。
在顏色分析中,它可以用來比較顏色 色調的相似性,但是它對于亮度和飽和度的變化不敏感。
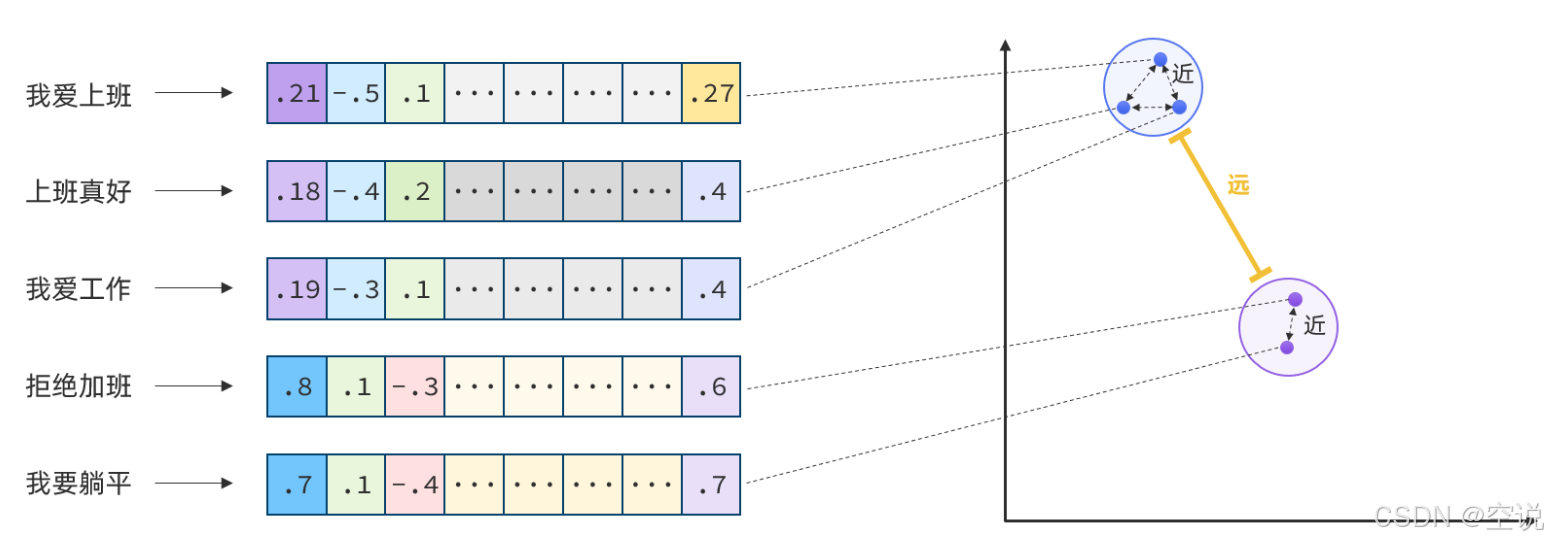
綜上,如果能把文本轉為向量,就可以通過向量距離來判斷文本的相似度了;
現在有不少的專門的向量模型,就可以實現將文本向量化。一個好的向量模型,就是要盡可能讓文本含義相似的向量,在空間中距離更近:
阿里云百煉平臺就提供了這樣的模型,用于將文本向量化:
這里選擇通用文本向量-v3,這個模型兼容OpenAI,所以我們依然采用OpenAI的配置;修改yml配置
spring:application:name: chart-robotai:ollama:# Ollama服務地址base-url: http://localhost:11434chat:# 模型名稱,可更改model: deepseek-r1:14boptions:# 模型溫度,值越大,輸出結果越隨機temperature: 0.8openai:base-url: https://dashscope.aliyuncs.com/compatible-modeapi-key: ${OPENAI_API_KEY} #API keychat:options:# 可選擇的模型列表 https://help.aliyun.com/zh/model-studio/getting-started/modelsmodel: qwen-plusembedding:options:model: text-embedding-v3 #通用文本向量-v3dimensions: 1024
向量模型測試
文本向量化以后,就可以通過向量之間的距離來判斷文本相似度;接下來,我們來測試下阿里百煉提供的向量大模型;
在項目中寫一個工具類,用以計算向量之間的歐氏距離和**余弦距離。**新建一個ai.util包,在其中新建一個VectorDistanceUtils類:
public class VectorDistanceUtils {// 私有構造函數:防止該工具類被實例化。private VectorDistanceUtils() {}// 浮點數計算精度閾值,用于判斷浮點數是否接近零。private static final double EPSILON = 1e-12;/*** 計算歐氏距離(Euclidean Distance)* 歐氏距離是兩個向量之間的直線距離,常用于衡量多維空間中兩點的距離。* @param vectorA 向量A(非空且與B等長)* @param vectorB 向量B(非空且與A等長)*/public static double euclideanDistance(float[] vectorA, float[] vectorB) {// 校驗輸入向量的合法性validateVectors(vectorA, vectorB);double sum = 0.0; // 用于累加差值平方for (int i = 0; i < vectorA.length; i++) {double diff = vectorA[i] - vectorB[i]; // 計算對應維度上的差值sum += diff * diff; // 累加差值的平方}return Math.sqrt(sum); // 返回平方和的平方根,即歐氏距離}/*** 計算余弦距離(Cosine Distance)* 余弦距離基于余弦相似度計算,表示兩個向量在方向上的差異。距離范圍為[0, 2],* 其中0表示完全相同,2表示完全相反。*/public static double cosineDistance(float[] vectorA, float[] vectorB) {// 校驗輸入向量的合法性validateVectors(vectorA, vectorB);double dotProduct = 0.0; // 點積double normA = 0.0; // 向量A的模double normB = 0.0; // 向量B的模// 遍歷向量的每個維度,計算點積和模的平方for (int i = 0; i < vectorA.length; i++) {dotProduct += vectorA[i] * vectorB[i]; // 點積累加normA += vectorA[i] * vectorA[i]; // A模的平方累加normB += vectorB[i] * vectorB[i]; // B模的平方累加}// 計算向量的模normA = Math.sqrt(normA);normB = Math.sqrt(normB);// 如果任意一個向量為零向量,則無法計算余弦距離,拋出異常if (normA < EPSILON || normB < EPSILON) {throw new IllegalArgumentException("Vectors cannot be zero vectors");}// 計算余弦相似度,確保結果在[-1, 1]范圍內(處理浮點誤差)double similarity = dotProduct / (normA * normB);similarity = Math.max(Math.min(similarity, 1.0), -1.0);// 余弦距離 = 1 - 相似度,范圍為[0, 2]return 1.0 - similarity;}/*** 參數校驗統一方法* 確保輸入向量滿足以下條件:* 1. 不為空(null);* 2. 長度相等;* 3. 非空數組。*/private static void validateVectors(float[] a, float[] b) {if (a == null || b == null) {throw new IllegalArgumentException("Vectors cannot be null");}if (a.length != b.length) {throw new IllegalArgumentException("Vectors must have same dimension");}if (a.length == 0) {throw new IllegalArgumentException("Vectors cannot be empty");}}
}
由于SpringBoot的自動裝配能力,剛才配置的向量模型可以直接使用;
@SpringBootTest
...
// 自動注入向量模型
@Autowired
private OpenAiEmbeddingModel embeddingModel;
@Test
void contextLoads() {// 1.測試數據// 1.1.用來查詢的文本,國際沖突String query = "global conflicts";// 1.2.用來做比較的文本String[] texts = new String[]{"哈馬斯稱加沙下階段停火談判仍在進行 以方尚未做出承諾","土耳其、芬蘭、瑞典與北約代表將繼續就瑞典“入約”問題進行談判","日本航空基地水井中檢測出有機氟化物超標","國家游泳中心(水立方):恢復游泳、嬉水樂園等水上項目運營","我國首次在空間站開展艙外輻射生物學暴露實驗",};// 2.向量化// 2.1.先將查詢文本向量化float[] queryVector = embeddingModel.embed(query);// 2.2.再將比較文本向量化,放到一個數組List<float[]> textVectors = embeddingModel.embed(Arrays.asList(texts));// 3.比較歐氏距離// 3.1.把查詢文本自己與自己比較,肯定是相似度最高的System.out.println(VectorDistanceUtils.euclideanDistance(queryVector, queryVector));// 3.2.把查詢文本與其它文本比較for (float[] textVector : textVectors) {System.out.println(VectorDistanceUtils.euclideanDistance(queryVector, textVector));}System.out.println("------------------");// 4.比較余弦距離// 4.1.把查詢文本自己與自己比較,肯定是相似度最高的System.out.println(VectorDistanceUtils.cosineDistance(queryVector, queryVector));// 4.2.把查詢文本與其它文本比較for (float[] textVector : textVectors) {System.out.println(VectorDistanceUtils.cosineDistance(queryVector, textVector));}
}
運行結果:
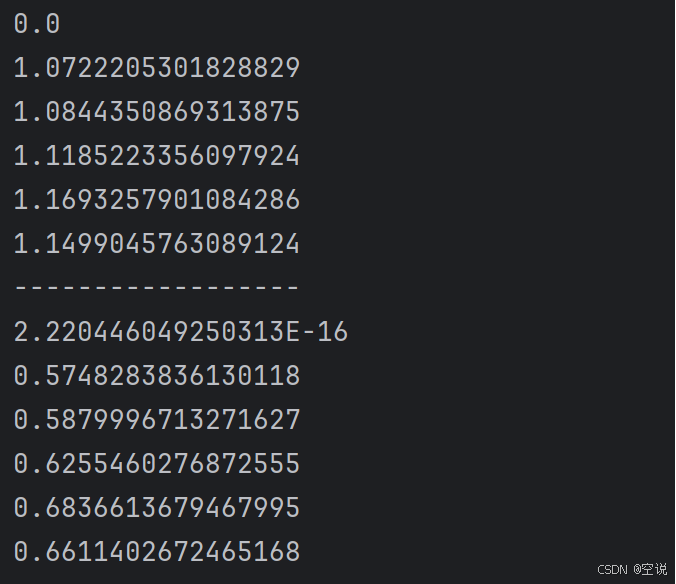
可以看到,向量相似度確實符合我們的預期。有了比較文本相似度的辦法,知識庫的問題就可以解決了;前面說了,知識庫數據量很大,無法全部寫入提示詞,而且龐大的知識庫中與用戶問題相關的其實并不多;
所以,我們需要想辦法從龐大的知識庫中找到與用戶問題相關的一小部分,組裝成提示詞,發送給大模型就可以了;
現但是新的問題來了:向量模型是生成向量的,如此龐大的知識庫,誰來從中比較和檢索數據呢? 這就需要用到向量數據庫了
向量數據庫
文本向量化
由于需要將已拆分的知識片段文本存儲向量庫,以便后續可以進行檢索,而向量庫存儲的數據是向量不是文本
因此需要將文本進行向量化,即將一個字符串轉換為一個N維數組,這個過程在自然語言處理(NLP)領域稱為文本嵌入
不同的LLM對于文本嵌入的實現是不同的,ChatGPT的實現是基于transformer架構的,相關實現存儲在服務端,每次嵌入都需要訪問OpenAI的HTTP接口。
通過下面的例子可以看到OpenAi使用的模型是:text-embedding-ada-002,向量的維度是:1536
OpenAiEmbeddingModel embeddingModel = new OpenAiEmbeddingModel.OpenAiEmbeddingModelBuilder().apiKey(API_KEY).baseUrl(BASE_URL).build();
log.info("當前的模型是: {}", embeddingModel.modelName());
String text = "兩只眼睛";
Embedding embedding = embeddingModel.embed(text).content();
log.info("文本:{}的嵌入結果是:\n{}", text, embedding.vectorAsList());
log.info("它是{}維的向量", embedding.dimension());
向量庫存儲
向量數據庫,也稱為向量存儲或向量搜索引擎,是一種專門設計用于存儲和管理向量(固定長度的數字列表)及其他數據項的數據庫。
這些向量是數據點在高維空間中的數學表示,其中每個維度對應數據的一個特征。向量數據庫的主要目的是通過近似最近鄰(ANN)算法實現高效的相似性搜索。
向量數據庫的主要作用有兩個:
- 存儲向量數據;
- 基于相似度檢索數據;
SpringAI支持很多向量數據庫,并且都進行了封裝,可以用統一的API去訪問:
- Azure Vector Search - The Azure vector store
- Apache Cassandra - The Apache Cassandra vector store
- Chroma Vector Store - The Chroma vector store
- Elasticsearch Vector Store - The Elasticsearch vector store
- GemFire Vector Store - The GemFire vector store
- MariaDB Vector Store - The MariaDB vector store
- Milvus Vector Store - The Milvus vector store
- MongoDB Atlas Vector Store - The MongoDB Atlas vector store
- Neo4j Vector Store - The Neo4j vector store
- OpenSearch Vector Store - The OpenSearch vector store
- Oracle Vector Store - The Oracle Database vector store
- PgVector Store - The PostgreSQL/PGVector vector store
- Pinecone Vector Store - PineCone vector store
- Qdrant Vector Store - Qdrant vector store
- Redis Vector Store - The Redis vector store
- SAP Hana Vector Store - The SAP HANA vector store
- Typesense Vector Store - The Typesense vector store
- Weaviate Vector Store - The Weaviate vector store
- SimpleVectorStore - A simple implementation of persistent vector storage, good for educational purposes
這些庫都實現了統一的接口:VectorStore,因此操作方式一模一樣,只要學會任意一個,其它就都不是問題;
注意:除了最后一個庫,其它所有向量數據庫都是需要安裝部署的,而且每個企業用的向量庫都不一樣。
SimpleVectorStore
- 最后一個
SimpleVectorStore向量庫是基于內存實現,是一個專門用來測試、教學用的庫,非常適合此處案例的使用; - 修改
CommonConfiguration,添加一個VectorStore的Bean
@Bean
public VectorStore vectorStore(OpenAiEmbeddingModel embeddingModel) {return SimpleVectorStore.builder(embeddingModel).build();
}
VectorStore接口
- 接下來就可以使用
VectorStore接口中的各種功能了,可以參考SpringAI官方文檔:Vector Databases :: Spring AI Reference; - 這是
VectorStore接口中聲明的方法:
public interface VectorStore extends DocumentWriter {default String getName() {return this.getClass().getSimpleName();}// 保存文檔到向量庫void add(List<Document> documents);// 根據文檔id刪除文檔void delete(List<String> idList);void delete(Filter.Expression filterExpression);default void delete(String filterExpression) {SearchRequest searchRequest = SearchRequest.builder().filterExpression(filterExpression).build();Filter.Expression textExpression = searchRequest.getFilterExpression();Assert.notNull(textExpression, "Filter expression must not be null");this.delete(textExpression);}// 根據條件檢索文檔@NullableList<Document> similaritySearch(String query);// 根據條件檢索文檔@NullableList<Document> similaritySearch(SearchRequest request);default <T> Optional<T> getNativeClient() {return Optional.empty();}
}
注意,VectorStore操作向量化的基本單位是Document,在使用時需要將自己的知識庫分割轉換為一個個的Document,然后寫入VectorStore;
那么問題來了,該如何把各種不同的知識庫文件轉為Document呢?
文件讀取和轉換
由于知識庫太大,所以要將知識庫拆分成文檔片段,然后再做向量化。而且SpringAI中向量庫接收的是Document類型的文檔,即我們處理文檔還要轉成Document格式
不過,文檔讀取、拆分、轉換的動作并不需要我們親自完成。在SpringAI中提供了各種文檔讀取的工具,可以參考官網:Spring AI Reference
比如PDF文檔讀取和拆分,SpringAI提供了兩種默認的拆分原則:
PagePdfDocumentReader:按頁拆分,推薦使用;ParagraphPdfDocumentReader:按pdf的目錄拆分,不推薦,因為很多PDF不規范,沒有章節標簽;
此處選擇使用PagePdfDocumentReader。首先,在pom.xml中引入依賴:
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>
然后就可以利用工具把PDF文件讀取并處理成Document了;
編寫一個單元測試
@Test
public void testVectorStore(){Resource resource = new FileSystemResource("中二知識筆記.pdf");// 1.創建PDF的讀取器PagePdfDocumentReader reader = new PagePdfDocumentReader(resource, // 文件源PdfDocumentReaderConfig.builder().withPageExtractedTextFormatter(ExtractedTextFormatter.defaults()).withPagesPerDocument(1) // 每1頁PDF作為一個Document.build());// 2.讀取PDF文檔,拆分為DocumentList<Document> documents = reader.read();// 3.寫入向量庫vectorStore.add(documents);// 4.構建一個搜索請求SearchRequest request = SearchRequest.builder().query("論語中教育的目的是什么").topK(1) //返回最相關的前 1 個結果.similarityThreshold(0.6) //只有相似度大于等于 0.6 的結果才會被返回.filterExpression("file_name == '中二知識筆記.pdf'").build();List<Document> docs = vectorStore.similaritySearch(request); //搜索if (docs == null) {System.out.println("沒有搜索到任何內容");return;}//遍歷搜索結果,打印每個文檔的相關信息for (Document doc : docs) {System.out.println(doc.getId());System.out.println(doc.getScore());System.out.println(doc.getText());}
}
注意:啟動測試之前,要將中二知識筆記.pdf文件放到工程目錄結構下;結果如下

RAG原理總結
目前已經有了以下這些工具
PDFReader:讀取文檔并拆分為片段;- 向量大模型:將文本片段向量化;
- 向量數據庫:存儲向量,檢索向量;
接下來梳理一下要解決的問題和解決思路:
- 要解決大模型的知識限制問題,需要外掛知識庫;
- 受到大模型上下文限制,知識庫不能直接拼接在提示詞中;
- 需要從龐大的外掛知識庫中找到與用戶問題相關的一小部分,再組裝成提示詞;
- 這些可以利用文檔讀取器、向量大模型、向量數據庫來解決;
- RAG要做的事情就是將知識庫分割==>利用向量模型做向量化==>存入向量數據庫==>查詢的時候去檢索;
- 每當用戶詢問AI時,將用戶問題向量化==>拿著問題向量==>去向量數據庫檢索最相關的片段
- 對話大模型:將檢索到的片段、用戶的問題一起拼接為提示詞==> 發送提示詞給大模型,得到響應。
目標
接下來就來實現一個非常火爆的個人知識庫AI應用——ChatPDF,原網站如下:
這個網站其實就是把個人的PDF文件作為知識庫,讓AI基于PDF內容來回答問題,對于大學生、研究人員、專業人士來說,非常方便。
PDF上傳下載向量化
既然是ChatPDF,即所有知識庫都是PDF形式的,由用戶提交給服務器。所以,需要先實現一個上傳PDF的接口,在接口中實現下列功能:
- 校驗文件格式是否為PDF;
- 保存文件信息;
- 保存文件(可以是oss或本地保存);
- 保存會話ID和文件路徑的映射關系(方便查詢會話歷史的時候再次讀取文件);
- 文檔拆分和向量化(文檔太大,需要拆分為一個個片段,分別向量化);
另外,將來用戶查詢會話歷史,還需要返回pdf文件給前端用于預覽,所以需要實現一個下載PDF接口,包含下面功能:
- 讀取文件
- 返回文件給前端
PDF文件管理
由于將來要實現PDF下載功能,就需要記住每一個chatId對應的PDF文件名稱;
所以定義一個類,記錄chatId與pdf文件的映射關系,同時實現基本的文件保存功能。在repository包中定義FileRepository接口
public interface FileRepository {/*** 保存文件,還要記錄chatId與文件的映射關系* @param chatId 會話id* @param resource 文件* @return 上傳成功,返回true; 否則返回false*/boolean save(String chatId, Resource resource);/*** 根據chatId獲取文件* @param chatId 會話id* @return 找到的文件*/Resource getFile(String chatId);
}
@Slf4j
@Component
@RequiredArgsConstructor
public class LocalPdfFileRepository implements FileRepository {private final VectorStore vectorStore; // 向量存儲組件// 會話id 與 文件名的對應關系,方便查詢會話歷史時重新加載文件private final Properties chatFiles = new Properties();/*** 保存資源到本地磁盤,并記錄會話 ID 與文件名的映射關系。*/@Overridepublic boolean save(String chatId, Resource resource) {// 1. 獲取文件名并檢查是否已存在String filename = resource.getFilename();File target = new File(Objects.requireNonNull(filename));if (!target.exists()) {try {// 將資源內容復制到目標文件Files.copy(resource.getInputStream(), target.toPath());} catch (IOException e) {log.error("Failed to save PDF resource.", e);return false;}}// 2. 保存會話 ID 與文件名的映射關系chatFiles.put(chatId, filename);return true;}/*** 根據會話 ID 獲取對應的文件資源。*/@Overridepublic Resource getFile(String chatId) {// 根據會話 ID 查找文件名String filename = chatFiles.getProperty(chatId);if (filename == null) {log.warn("No file found for chatId: {}", chatId);return null;}return new FileSystemResource(filename);}/*** 初始化方法,在 Spring 容器啟動時執行。* 加載 `chat-pdf.properties` 文件中的會話 ID 映射關系,* 并加載 `chat-pdf.json` 中的向量數據。*/@PostConstructprivate void init() {// 加載會話 ID 映射關系FileSystemResource pdfResource = new FileSystemResource("chat-pdf.properties");if (pdfResource.exists()) { //如果文件存在try (BufferedReader reader = new BufferedReader(new InputStreamReader(pdfResource.getInputStream(), StandardCharsets.UTF_8))) {chatFiles.load(reader); //加載chatFiles到本地文件} catch (IOException e) {throw new RuntimeException("Failed to load chat-pdf.properties", e);}}// 加載向量存儲數據FileSystemResource vectorResource = new FileSystemResource("chat-pdf.json");if (vectorResource.exists()) {SimpleVectorStore simpleVectorStore = (SimpleVectorStore) vectorStore;try {simpleVectorStore.load(vectorResource);} catch (Exception e) {throw new RuntimeException("Failed to load chat-pdf.json", e);}}}/*** 銷毀方法,在 Spring 容器關閉時執行。* 持久化會話 ID 映射關系和向量存儲數據到磁盤。*/@PreDestroyprivate void persistent() {try {// 持久化會話 ID 映射關系try (FileWriter writer = new FileWriter("chat-pdf.properties")) {chatFiles.store(writer, "Persisted at " + LocalDateTime.now());}// 持久化向量存儲數據SimpleVectorStore simpleVectorStore = (SimpleVectorStore) vectorStore;simpleVectorStore.save(new File("chat-pdf.json"));} catch (IOException e) {throw new RuntimeException("Failed to persist data", e);}}
}
此處選擇了基于內存的SimpleVectorStore,重啟就會丟失向量數據。所以這里是將pdf文件與chatId的對應關系、VectorStore都持久化到了磁盤;
實際開發中,如果選擇了RedisVectorStore,或者CassandraVectorStore,則無需自己持久化。但是chatId和PDF文件之間的對應關系,還是需要自己維護的。
上傳文件相應結果
由于前端文件上傳給后端后,后端需要返回響應結果,在ai.entity.vo中定義一個Result類:
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
public class Result {private Integer ok;private String msg;private Result(Integer ok, String msg) {this.ok = ok;this.msg = msg;}public static Result ok() {return new Result(1, "ok");}public static Result fail(String msg) {return new Result(0, msg);}
}
文件上傳下載
在ai.controller中創建一個PdfController:
@Slf4j
@RequiredArgsConstructor //配合final實現自動注入
@RestController
@RequestMapping("/ai/pdf")
public class PdfController {private final FileRepository fileRepository; //文件存儲組件private final VectorStore vectorStore; //向量存儲組件private final ChatClient pdfChatClient; //問答模型客戶端private final ChatHistoryRepository chatHistoryRepository; //會話歷史記錄/*** 對話*/@RequestMapping(value = "/chat", produces = "text/html;charset=utf-8")public Flux<String> chat(String prompt, String chatId) {// 1.找到會話文件Resource file = fileRepository.getFile(chatId);if (!file.exists()) {// 文件不存在,不回答throw new RuntimeException("會話文件不存在!");}// 2.保存會話idchatHistoryRepository.save("pdf", chatId);// 3.請求模型return pdfChatClient.prompt().user(prompt).advisors(a -> a.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId)).advisors(a -> a.param(FILTER_EXPRESSION, "file_name == '" + file.getFilename() + "'")).stream().content();}/*** 文件上傳*/@RequestMapping("/upload/{chatId}")public Result uploadPdf(@PathVariable String chatId, @RequestParam("file") MultipartFile file) {try {// 1. 校驗文件是否為PDF格式if (!Objects.equals(file.getContentType(), "application/pdf")) {return Result.fail("只能上傳PDF文件!");}// 2.保存文件boolean success = fileRepository.save(chatId, file.getResource());if (!success) {return Result.fail("保存文件失敗!");}// 3.寫入向量庫this.writeToVectorStore(file.getResource());return Result.ok();} catch (Exception e) {log.error("Failed to upload PDF.", e);return Result.fail("上傳文件失敗!");}}/*** 文件下載*/@GetMapping("/file/{chatId}")public ResponseEntity<Resource> download(@PathVariable("chatId") String chatId) throws IOException {// 1.讀取文件Resource resource = fileRepository.getFile(chatId);if (!resource.exists()) {return ResponseEntity.notFound().build();}// 2.文件名編碼,寫入響應頭String filename = URLEncoder.encode(Objects.requireNonNull(resource.getFilename()), StandardCharsets.UTF_8);// 3.返回文件return ResponseEntity.ok().contentType(MediaType.APPLICATION_OCTET_STREAM).header("Content-Disposition", "attachment; filename=\"" + filename + "\"").body(resource);}/*** 寫入向量庫*/private void writeToVectorStore(Resource resource) {// 1.創建PDF的讀取器PagePdfDocumentReader reader = new PagePdfDocumentReader(resource, // 文件源PdfDocumentReaderConfig.builder().withPageExtractedTextFormatter(ExtractedTextFormatter.defaults()).withPagesPerDocument(1) // 每1頁PDF作為一個Document.build());// 2.讀取PDF文檔,拆分為DocumentList<Document> documents = reader.read();// 3.寫入向量庫vectorStore.add(documents);}
}
上傳大小限制
SpringMVC有默認的文件大小限制,只有10M,很多知識庫文件都會超過這個值,所以我們需要修改配置,增加文件上傳允許的上限;
修改application.yaml文件,添加配置:
spring:servlet:multipart:# 單個文件的最大大小為100MBmax-file-size: 104857600# 整個請求的最大大小為100MBmax-request-size: 104857600
配置ChatClient
理論上來說,每次與AI對話的完整流程是這樣的:
- 將用戶的問題利用向量大模型做向量化
OpenAiEmbeddingModel; - 去向量數據庫檢索相關的文檔
VectorStore; - 拼接提示詞,發送給大模型;
- 解析響應結果;
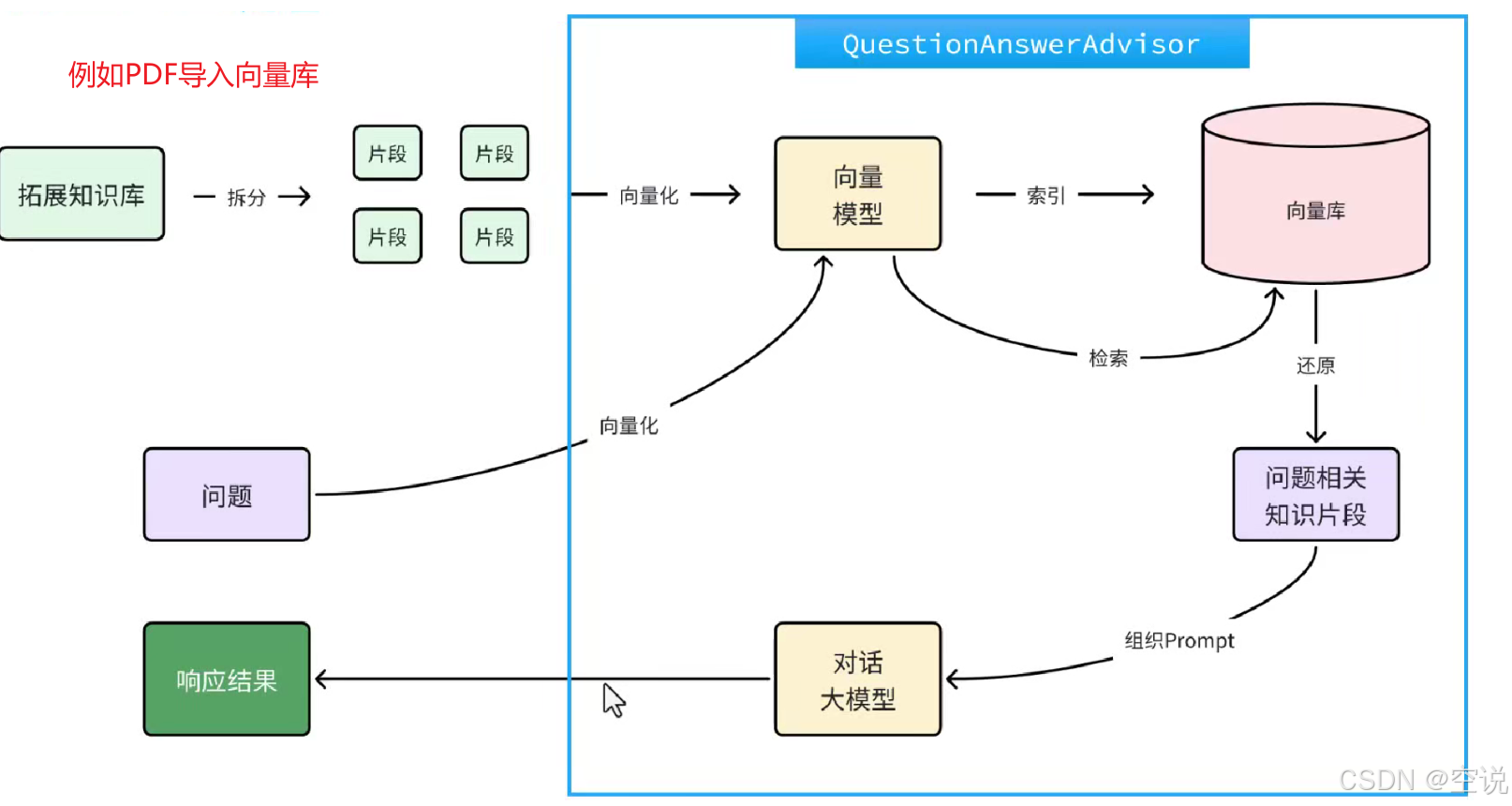
不過,SpringAI同樣基于AOP技術幫我們完成了全部流程,用的是一個名為QuestionAnswerAdvisor的Advisor。我們只需要把VectorStore配置到Advisor即可。在CommonConfiguration類中給ChatPDF也單獨定義一個ChatClient:
@Bean
public ChatClient pdfChatClient(OpenAiChatModel model, ChatMemory chatMemory, VectorStore vectorStore) {return ChatClient.builder(model).defaultSystem("請根據上下文回答問題,遇到上下文沒有的問題,不要隨意編造。").defaultAdvisors(new SimpleLoggerAdvisor(),new MessageChatMemoryAdvisor(chatMemory), // 會話記憶new QuestionAnswerAdvisor( vectorStore, // 向量庫SearchRequest.builder() // 向量檢索的請求參數.similarityThreshold(0.6) // 相似度閾值.topK(2) // 返回的文檔片段數量.build())).build();
}
也可以自己自定義RAG查詢的流程,不使用Advisor,具體可參考官網
對話接口
最后,對接前端與大模型對話。修改PdfController,添加一個接口:
/*** 對話
*/
@RequestMapping(value = "/chat", produces = "text/html;charset=utf-8")
public Flux<String> chat(String prompt, String chatId) {// 1.找到會話文件Resource file = fileRepository.getFile(chatId);if (!file.exists()) {// 文件不存在,不回答throw new RuntimeException("會話文件不存在!");}// 2.保存會話idchatHistoryRepository.save("pdf", chatId);// 3.請求模型return pdfChatClient.prompt().user(prompt).advisors(a -> a.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId)).advisors(a -> a.param(FILTER_EXPRESSION, "file_name == '" + file.getFilename() + "'")).stream().content();
}
測試
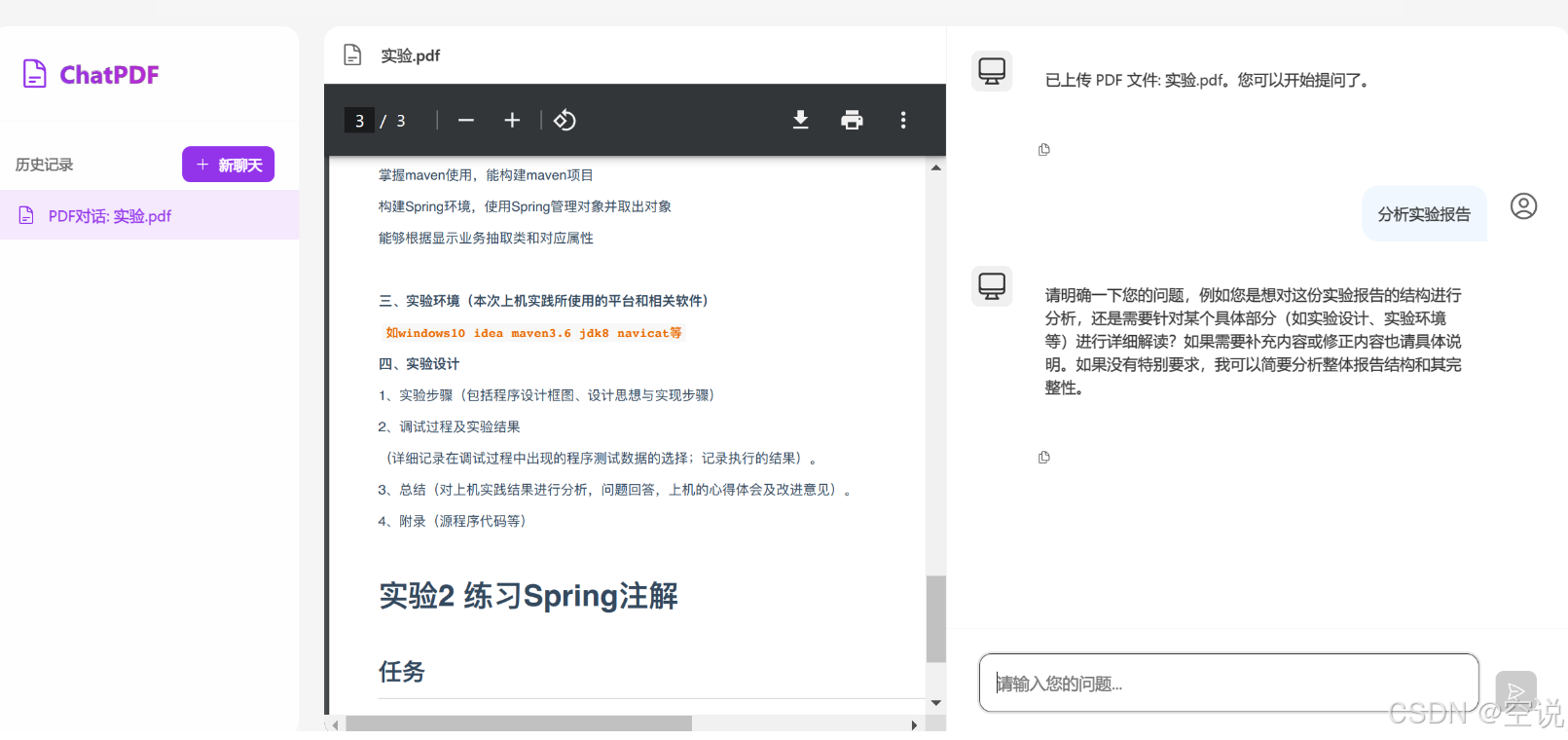
持久化VectorStore
SpringAI提供了很多持久化的VectorStore,下面以其中兩個為例來介紹:
- RedisVectorStore : 目前測試metafiled過濾有異常;
- CassandraVectorStore。
RedisVectorStore
- 需要安裝一個Redis Stack,這是Redis官方提供的拓展版本,其中有向量庫的功能;
- 可以使用Docker安裝:
docker run -d --name redis-stack -p 6379:6379 -p 8001:8001 redis/redis-stack:latest
#通過命令行訪問
docker exec -it redis-stack redis-cli
#也可以通過瀏覽器訪問控制臺:http://localhost:8001 ip換成自己配置的
在項目中引入RedisVectorStore的依賴:
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-redis-store-spring-boot-starter</artifactId>
</dependency>
在application.yml配置Redis:
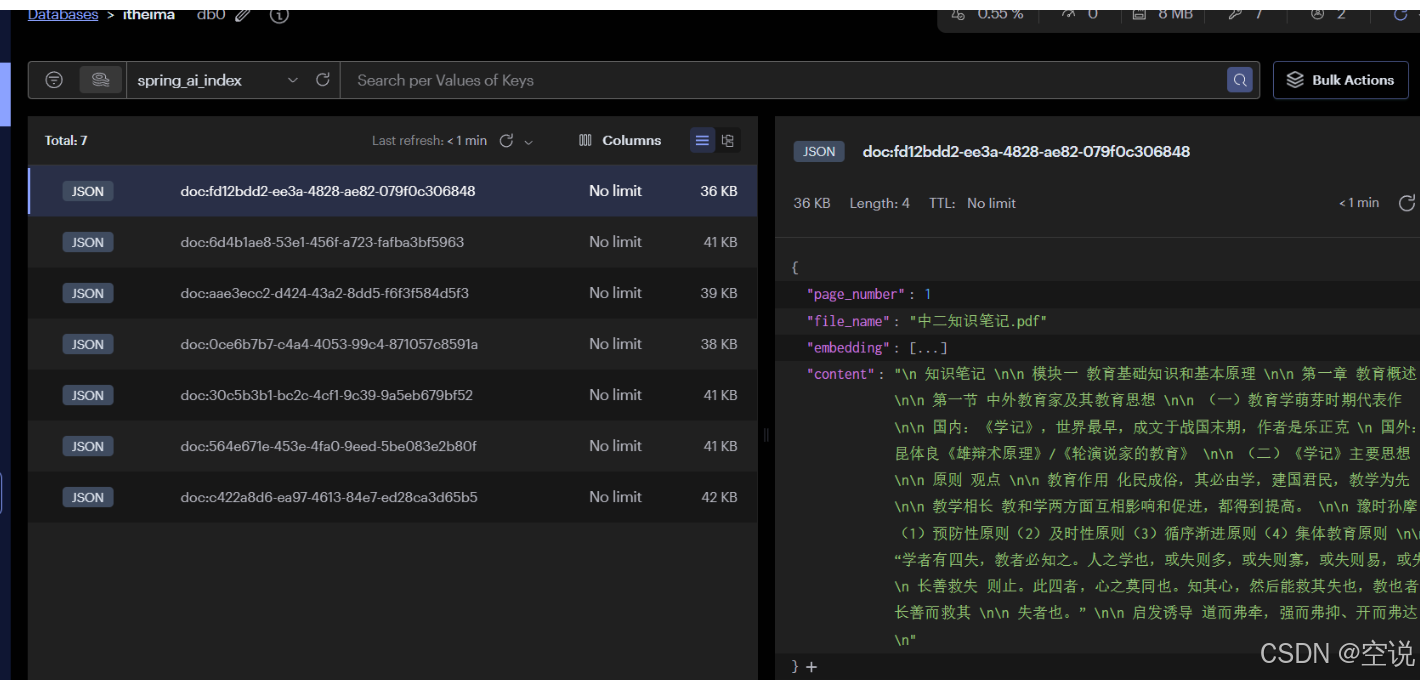
spring:ai:vectorstore:redis:index: spring_ai_index # 向量庫索引名initialize-schema: true # 是否初始化向量庫索引結構prefix: "doc:" # 向量庫key前綴data:redis:host: XXX # redis地址
接下來,無需聲明bean,直接就可以直接使用VectorStore了。
CassandraVectorStore
首先,需要安裝一個Cassandra訪問,使用Docker安裝:
docker run -d --name cas -p 9042:9042 cassandra
在項目中添加cassandra依賴:
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-cassandra-store-spring-boot-starter</artifactId>
</dependency>
配置Cassandra地址:
spring:cassandra:contact-points: xxx:9042local-datacenter: datacenter1
配置VectorStore:
public CassandraVectorStore vectorStore(OpenAiEmbeddingModel embeddingModel, CqlSession cqlSession) {return CassandraVectorStore.builder(embeddingModel).session(cqlSession).addMetadataColumn(new CassandraVectorStore.SchemaColumn("file_name", DataTypes.TEXT, CassandraVectorStore.SchemaColumnTags.INDEXED)).build();
}



)


![[密碼學基礎]國密算法深度解析:中國密碼標準的自主化之路](http://pic.xiahunao.cn/[密碼學基礎]國密算法深度解析:中國密碼標準的自主化之路)
 TCP/IP協議)



![【白雪講堂】[特殊字符]內容戰略地圖|GEO優化框架下的內容全景布局](http://pic.xiahunao.cn/【白雪講堂】[特殊字符]內容戰略地圖|GEO優化框架下的內容全景布局)


,多步能力協議(MCP) 和 A2A的區別)




