二 kafka架構介紹
學習一個系統之前很重要的一點就是先了解這個系統整體的架構,這能夠使我們對整個系統有個總體的認識,清楚地知道這個系統有什么能力。這不僅幫助我們學習時快速定位到我們想要的內容,還能避免我們學習過程中在龐大的系統中迷失自己。所以首先我會介紹一下kafka的整體架構,包括這個kafka系統的整體架構,模塊組成,模塊的功能以及模塊之間關系,以及各個模塊之間是怎么共同構成這套系統的。kafka官方并不直接提供他們源碼的架構圖,模塊功能和邊界,所以這塊的內容是我根據kafka各模塊的功能,依賴關系自己組織起來的,并且對各模塊做了分層方便我們學習。
2.1 kafka架構和模塊
kafka4整體由21個模塊組成,但是kafka并不像spring那樣采用嚴格的分層架構,模塊的劃分設計主要還是為了盡可能復用代碼并且避免模塊直接引入其他不需要的代碼,然后很多kafka官方工具和客戶端/API的源碼也會放在單獨的模塊中管理。這里我們文章關心的主要kafka broker相關的源碼。對于客戶端,工具等的代碼不會做太多介紹。但是也有必要做一些簡單介紹提升我們對于kafka的整體認知,下面簡單貼一下kafka4.1的源碼,里面就能夠清楚地看到我們下面會說地21個模塊了。
盡管kafka沒有嚴格地對模塊進行分層,這里還是根據各個模塊的功能和依賴關系對各個模塊進行了歸類和分層。以下就是kafka的架構圖。
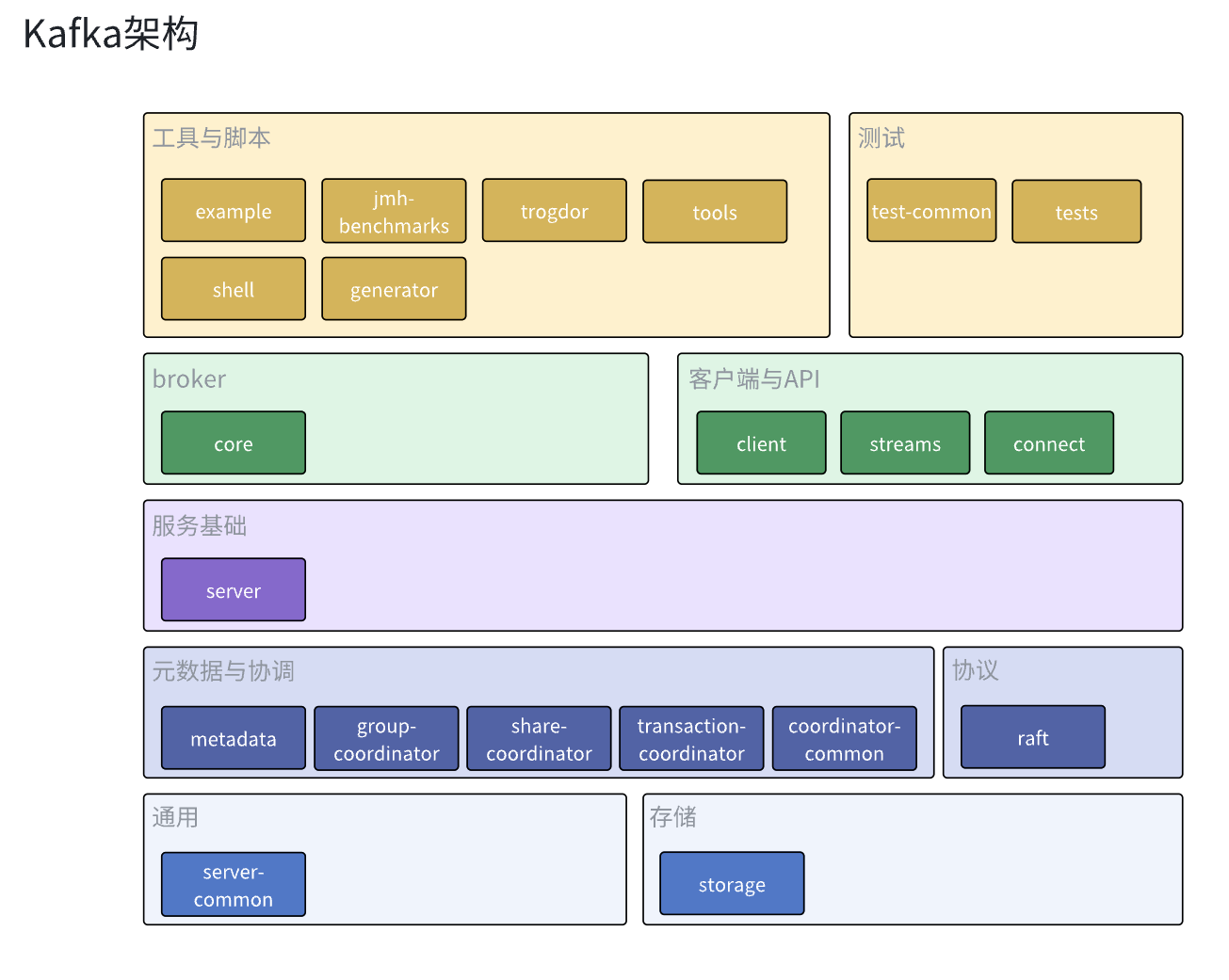
首先最底層的通用模塊就是server-common了,這個模塊主要負責定義kafka通用抽象,常量和封裝公共方法等,kafka服務的其他模塊都會依賴這個模塊減少代碼冗余,除此之外還有負責數據持久化的storage模塊。為其他模塊提供持久化數據的管理。
然后就是元數據于協調模塊,這些模塊主要封裝了集群內各broker,組內各消費者,事務內各生產者和broker的行為協調邏輯,實現broker分區分配,消費者分區分配和kafka事務的功能,之所以吧元數據和協調放在同一層,是因為metadata模塊既封裝了元數據相關的管理操作,也實現了集群內broker的協調邏輯,同時其他協調器也會依賴metadata模塊的元數據來完成自己的協調功能。如果單獨劃出元數據層的話,就會錯誤地忽略掉metadata模塊對集群broker協調作用。同時coordinator-common和share-coordinator模塊并不是獨立的協調器實現,它們只是封裝了協調器會用到的公共抽象和通用邏輯,減少代碼冗余。與元數據于協調模塊同層的就是負責實現kraft邏輯的raft模塊了,其實我們也可以認為它也是一個協調模塊,負責kraft集群內機器的協調管理。
再往上就是基礎服務模塊server了,很多可能被他的名字迷惑,覺得是在server里面完成的kafka broker的實現邏輯,其實這是錯誤的,server主要就是依賴于上面的模塊實現了服務通用功能,這些功能并不是Kafka專有的,其他大多數服務都有這些功能,比如服務埋點和監控,配額管理,副本管理等,Kafka把這些邏輯抽離出到server模塊上,讓core模塊能夠專心實現Kafka核心的功能。
然后就到了我們的核心模塊core了,它依賴其他模塊實現了kafka的broker,存放broker的入口程序和核心邏輯,也會調用其他模塊完成broker整體的工作。kafka的核心組件acceptor,processor,handler,kafkaApis,requestchannel都是在這里定義和實現的。
然后就是kafka的客戶端,工具,腳本和測試模塊了,它們都相對比較獨立,都是kafka官方提供的方便我們使用,測試kafka的工具。當然kafka也有一些其他的社區維護的工具或者客戶端,這里我們就不做太多贅述了。
2.2 模塊功能
我們在這個小節會簡單介紹一下kafka各個模塊,盡管有些模塊并不是本文章的的內容,但是還是有必要對他們有個概念,這也能讓我們更加有底氣地打開kafka源碼。
2.2.1 基礎層
我們把kafka中提供基礎能力的模塊劃分為基礎層,基礎層的模塊為我們的kafka服務提供通用的抽象和一些常用功能的封裝。減少代碼冗余性。
server-common模塊
server-common?模塊為 Kafka 服務端(Broker)相關的多個子系統提供通用的基礎設施、工具類和抽象接口。主要就是將多處復用的通用邏輯抽取出來,避免出現代碼冗余,提升代碼的可維護性。
storage模塊
storage模塊是Kafka服務端消息持久化存儲的核心實現,為Kafka的高吞吐、高可靠消息存儲提供底層支撐。它實現了Kafka分區日志的寫入、讀取、分段、索引、清理、事務、快照等所有與磁盤存儲相關的功能,比如管理分區日志(Log)的寫入、讀取、分段、索引、清理、壓縮、刪除和消息的物理存儲、索引文件、事務索引、快照,支持日志的恢復、截斷、校驗、異常處理等等。
2.2.2?元數據與協調/協議層
元數據與協調模塊負責實現kafka體系內元數據的管理和節點之間的協調邏輯,比如協調消費者組里面的消費者分配某個topic的分區,協調多個broker怎么分配某個topic的分區,協調事務里面的生產者和broker的工作等等。
metadata模塊
metadata模塊是Kafka服務端集群元數據管理的核心實現,為Kafka的高可用、分布式一致性和動態擴展提供底層支撐。它實現了Kafka集群中所有元數據(如主題、分區、副本、Broker、控制器、ACL、特性等)的存儲、更新、分發和管理,以及Controller和Broker的注冊和心跳管理,Topic分區分配,遷移等一系列基于元數據的決策邏輯。Metadata模塊也是KRaft(Kafka Raft)架構下去中心化元數據管理的基礎,提供了KRaft相關元數據的管理,同時它也需要依賴raft模塊實現元數據的分布式一致性存儲和同步。是Kafka實現高可用和彈性伸縮的關鍵。
coordinator-common模塊
coordinator-common 模塊為 Kafka 中所有協調器模塊(比如消費組協調器Group?Coordinator和事務協調器Transaction?Coordinator)提供通用的抽象、工具和基礎設施,包括接口、抽象類、工具方法,以及協調器的通用配置、狀態管理和持久化等基礎能力。它并不直接實現消費組或事務協調的具體邏輯,而是作為消費組協調器Group Coordinator,事務協調器Transaction Coordinator等協調器模塊的公共支撐,避免重復實現。
share-coordinator模塊
share-coordinator?模塊為?Kafka 中的多種協調器(如消費組協調器、事務協調器等)提供共享的實現基礎。它在coordinator-common的基礎上進一步抽象和復用協調器之間的通用行為或邏輯,比如封裝協調器Coordinator之間的通用實現,如狀態管理、持久化、協議處理等,提供協調器的抽象基類、接口和工具方法。便于不同類型的協調器共享代碼、減少代碼冗余。
group-coordinator模塊
group-coordinator模塊專門實現Kafka消費組協調器的全部功能。它負責管理消費組成員、分區分配、再平衡、消費位移提交等,包括實現管理消費組成員的加入、離開、心跳,實現分區分配、再平衡、消費位移提交與查詢,處理消費組相關的協議請求(如JoinGroup、SyncGroup、Heartbeat、OffsetCommit等)等的邏輯,是Kafka高可靠消費和負載均衡的核心。
注意group-coordinator模塊的分區分配是指把分區分配給消費者組的消費者,前面metadata模塊的分區分配是指把分區分配給不同broker,兩邊的工作職責不一樣,不要弄混。
transaction-coordinator模塊
transaction-coordinator模塊專門實現Kafka的事務協調器功能。它負責管理生產者的事務生命周期,實現冪等性、事務狀態機、事務超時、提交/中止等,實現了管理生產者事務的初始化、提交、終止,維護事務狀態機,處理事務超時、恢復,處理事務相關的協議請求(如InitProducerId、AddPartitionsToTxn、EndTransaction等)等邏輯,是Kafka支持Exactly Once語義的關鍵。
raft模塊
raft模塊是Kafka實現KRaft(Kafka Raft)協議的核心模塊,為Kafka集群提供分布式一致性、高可用和去中心化的元數據管理能力。它實現了Raft分布式一致性協議的全部核心機制,包括Raft協議實現(日志復制、選主(Leader Election)、日志提交、快照、成員變更等),分布式一致性保障,高可用與容錯,動態成員管理等等。除此之外raft模塊也為metadata、controller等模塊提供一致性存儲和同步能力,raft是KRaft架構下Kafka元數據存儲和同步的基礎。替代了原有的ZooKeeper方案
2.2.3?基礎服務模塊
服務基礎層的模塊負責提供kafka服務運行時需要的一些基礎能力,比如數據埋點和監控,權限控制,限流,這些能力雖然不是kafka的核心實現邏輯但是也是kafka運行必不可少的一部分。
server模塊
server模塊可以理解為core模塊的基礎設施庫,server模塊為Kafka Broker的主服務實現提供了大量的基礎能力和子系統實現,包括副本管理、分區分配、指標采集、配額管理、事務支持、延遲操作、日志控制等,這些能力一般是大多數平臺都具有的能力而不僅僅是kafka特有的,所以通過將這些通用能力抽離到server模塊,主服務實現可以更專注于流程控制和集成,提升了代碼的解耦性和可維護性。
2.2.4?broker實現層
這個就是kafka broker的核心邏輯的地方了
core模塊
core模塊是Kafka的核心實現模塊,主要負責Kafka服務端的啟動、運行、關閉等主流程控制。它包含了Kafka Broker的主入口、定義和實現了Server,Processor,RequestChannel,KafkaApis等實現Kafka功能的核心組件,實現了服務生命周期管理(啟動、關閉、異常處理等)、加載和解析服務端配置,請求的實際處理,服務指標監控等的邏輯。
2.2.5?客戶端與API
這些嚴格意義不算是kafka服務里面的代碼,只是官方提供一些對接kafka服務的客戶端或者簡化kafka使用流程的依賴庫。除了官方提供的外我們也可以在社區里面找到很多好用的kafka客戶端或者調用框架。
clients模塊
clients模塊提供Kafka的Java客戶端實現,包括生產者,消費者,管理客戶端等,供外部應用集成以便于與kafka交互。比如業務服務在引入clients模塊后可以很方便地使用KafkaProducer給topic發送消息,使用KafkaConsumer接受并處理感興趣的topic的消息,使用AdminClient對kafka broker的主題、分區、ACL等進行管理,比如創建或刪除topic,獲取集群消息等等。
streams模塊
streams模塊就是對Kafka Streams的實現,Kafka Streams是Apache?Kafka官方提供的一個輕量級、分布式、高容錯的流處理庫,我們可以在Java應用中引入streams模塊后很方便地實現對Kafka數據流的實時處理、分析和計算。而且Kafka Streams也支持支持窗口、聚合、連接等流式操作。使用Kafka Streams我們能夠很方便地無縫對接Kafka數據進行實時的統計,監控,ETL,數據清洗,實時告警,風控等操作。
connect模塊
connect模塊實現了Kafka Connect框架,Kafka Connect是Apache Kafka官方提供的一個分布式、可擴展、可管理的數據集成框架。它的主要目標是簡化Kafka與外部系統(如數據庫、文件系統、云存儲、搜索引擎等)之間的數據同步和批量數據流轉,讓用戶無需編寫復雜的代碼就能實現數據的高效導入和導出。主要提供以下支持。
數據源(Source)到Kafka:自動化地將外部系統(如MySQL、PostgreSQL、Oracle、文件、云存儲等)中的數據批量導入Kafka Topic。
Kafka到數據匯(Sink):自動化地將Kafka Topic中的數據批量導出到外部系統(如Elasticsearch、HDFS、S3、數據庫等)
數據轉換與處理:支持在數據流轉過程中進行格式轉換、字段過濾、數據清洗等操作(通過Transform機制)。
分布式與容錯:支持分布式部署、自動負載均衡、任務容錯、狀態管理、動態擴縮容等
2.2.6 工具與腳本
這些是kafka官方提供的一些工具,用于幫助管理kafka或者做一些數據診斷,性能校驗,又或者是支持kafka提供的腳本等,這些工具有些是kafka內部開發人員會用的,有些是使用kafka運維或者開發人員會用到的,使用這些工具和腳本可以大大提高工作效率。
tools模塊
tools模塊是Kafka官方提供的命令行工具和測試工具的實現模塊,提供了Kafka的命令行工具、運維腳本、診斷工具等,主要用于Kafka集群的管理、運維、性能測試、功能驗證等,比如創建topic,管理ACL,測試生產者性能等,Kafka 在發行包的 bin 目錄下,提供了大量以?kafka-xxx.sh?命名的腳本,這些腳本本質上就是通過調用 tools 模塊來實現的功能。
shell模塊
shell模塊是Kafka官方實現的一個交互式命令行工具框架,用于以“類Unix?Shell”的方式管理和操作Kafka的元數據、集群狀態等。本質上就是一個Java實現的交互式命令行工具,根據輸入的命令通過Kafka的API與Broker或元數據服務通信,實現元數據的瀏覽、查詢、管理等功能。它提供了類似于文件系統shell(如bash、zsh)的交互體驗,操作對象是Kafka的元數據結構,支持常見的shell命令(如ls、cd、pwd、cat、tree、find、help、exit等),但這些命令操作的是Kafka的元數據樹,而不是文件系統。
generator模塊
generator模塊是Kafka源碼中的自動化代碼生成工具,主要用于根據協議、元數據、消息結構等描述文件,自動生成Kafka內部所需的Java類、協議實現、序列化/反序列化代碼、JSON轉換器等。比如根據kafka協議針對每種類型/版本的請求的字段生成對應的java類代碼,它是開發和構建階段的輔助工具,通常在Kafka源碼編譯、協議變更、自動化構建等場景下被調用,是Kafka開發和維護中提升效率的重要工具。
examples模塊
examples模塊為Kafka用戶和開發者提供了豐富的示例代碼,幫助大家快速上手Kafka的Producer、Consumer、Streams等API的使用方法。
jmh-benchmarks模塊
jmh-benchmarks?模塊是?Kafka?項目中的性能基準測試模塊,基于 JMH(Java Microbenchmark Harness)框架實現。它用于對 Kafka?的關鍵組件、算法、數據結構等進行微基準性能測試,幫助開發者評估和優化系統的性能瓶頸。比如提供 Kafka?相關代碼的微基準測試用例,評估不同實現、參數、配置下的性能表現。jmh-benchmarks?模塊僅用于開發和性能調優階段,不參與生產環境部署和主流程邏輯。
JMH(Java?Microbenchmark Harness)是?OpenJDK?官方的?Java 微基準測試框架,專門用于準確測量 Java?代碼的性能。它能有效避免JVM優化帶來的測試偏差,支持多線程、參數化、基準分組等高級特性。
trogdor模塊
trogdor 是 Kafka?官方自帶的集群壓力測試與故障注入工具模塊。它的主要目標是為?Kafka 集群提供自動化的性能壓測、穩定性測試和故障模擬能力,幫助開發者和運維人員在真實或準生產環境下評估 Kafka?的性能極限和容錯能力。trogdor 采用“協調器-代理(Coordinator-Agent)”架構,協調器負責任務的全局調度和監控,代理分布在各個節點上,負責實際執行測試任務。任務類型和參數高度可配置,支持自定義擴展。
2.2.7?測試
這部分主要用于kafka代碼測試相關
test-common模塊
test-common模塊的主要作用是為Kafka的各種測試用例提供通用的測試工具類、基類、mock實現、測試輔助方法等。避免在每個測試工程/目錄中重復實現通用的測試邏輯,提高測試代碼的復用性和維護性。
tests模塊
tests嚴格來說不是一個模塊,而是一個目錄,主要用于存放Kafka項目的各種測試用例、測試工具、測試腳本(python腳本),測試數據和配置,比如提供Kafka集群的自動化部署、啟動、關閉、清理等輔助腳本,測試數據生成、對比、校驗等工具,各種測試所需的配置文件、數據文件、模擬環境等等。它是Kafka保證高質量、高可靠性的重要基礎設施。













)
與定時爬取網站→郵件通知(價格監控原型))




