多線程編程在現代軟件開發中扮演著至關重要的角色,它能夠顯著提升應用程序的性能和響應能力。通過合理利用異步線程、多線程以及線程池等技術,我們可以更高效地處理復雜任務,優化系統資源的使用。同時,在實際應用中,我們也需要應對諸如并發沖突、線程池鎖等問題,并結合設計模式、函數式編程等理念,確保在業務開發流程中安全、有效地運用這些技術。接下來,讓我們深入探討多線程編程的各個方面,從基礎概念到高級應用,逐步揭示其在現代軟件開發中的核心價值。
一、多線程基礎
1.1 多線程概述
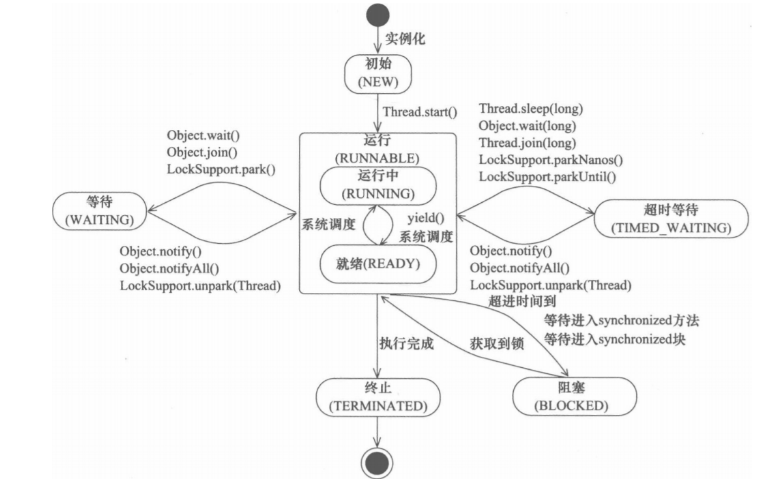
多線程(multithreading)是指從軟件或者硬件上實現多個線程并發執行的技術。線程是操作系統進行運算調度的最小單位,它存在于進程之中并作為進程中的實際運作單位 。一個進程可以包含多個線程,這些線程共享進程的資源,如內存空間、文件描述符等,每個線程代表進程中的一個單一順序控制流,允許進程并發執行不同的任務。
多線程技術的出現,主要是為了解決傳統進程模型在并發處理上的一些不足。在早期,進程作為操作系統中能獨立運行的基本單位,擁有獨立資源,但其創建、撤銷、調度切換以及同步與通信等操作需要系統付出較大的時空開銷,并且進程切換頻率不宜過高,這限制了程序的并發程度 。而線程作為比進程更小的能獨立運行的基本單位,在同一進程內的線程切換開銷遠小于進程切換,能夠更高效地實現并發執行,提升系統內程序的并發程度和吞吐量。
從發展歷程來看,多線程技術自20世紀50年代起就已萌芽,早期的NBS SEAC(1950年)和DYSEAC(1954年)等雙線程系統開啟了基本的并行處理能力。隨后,Lincoln Labs TX - 2等系統能支持多達33個線程,到了60年代,CDC 6600和IBM ACS - 360等系統通過引入多線程提升了硬件資源利用率。在后續的幾十年里,HEP、Xerox Alto、Transputer等項目不斷推動多線程技術的發展,2000年代,隨著Intel Pentium 4 HT等支持超線程技術的處理器推出,多線程技術逐漸成熟并廣泛應用 。
1.2 多線程的優勢
1.2.1 提高CPU利用率
在單線程程序中,如果程序需要進行大量的I/O操作(如文件讀寫、網絡請求等),CPU在等待I/O操作完成的過程中會處于空閑狀態,造成資源浪費。而多線程可以充分利用CPU的空閑時間 。例如,一個下載工具使用多線程同時下載多個文件,當一個線程在等待網絡數據傳輸時,操作系統可以調度其他線程繼續執行計算任務或者處理其他下載請求,使得CPU的利用率接近100%,從而大大提高了程序的整體執行效率。
1.2.2 增強程序響應性
對于一些包含用戶界面的應用程序,單線程模式下如果執行一個耗時較長的任務,整個程序界面會處于阻塞狀態,無法響應用戶的操作,嚴重影響用戶體驗。采用多線程技術,可以將耗時任務放在后臺線程執行,主線程專注于處理用戶界面的交互,保持界面的流暢響應 。比如瀏覽器在渲染頁面時,使用多線程可以讓用戶在頁面加載過程中仍然能夠滾動頁面、點擊鏈接等,提升了用戶體驗。
1.2.3 實現多核并行計算
隨著硬件技術的發展,多核處理器已經成為主流。單線程程序只能利用一個CPU核心,而多線程程序可以將任務拆分為多個子任務,每個子任務由一個線程負責,并在不同的CPU核心上并行執行 。例如,視頻編碼軟件使用多線程并行處理不同幀的編碼工作,相較于單線程處理,速度會顯著提升,能夠充分發揮多核處理器的性能優勢。
1.3 多線程帶來的挑戰
1.3.1 并發沖突
由于多個線程共享進程的資源,當多個線程同時訪問和修改共享資源時,就可能出現并發沖突問題 。例如,兩個線程同時對一個共享的變量進行累加操作,由于線程執行的順序不確定性,可能導致最終的結果與預期不符。這是因為在多線程環境下,CPU可能在一個線程執行完讀取變量值但還未完成累加操作時,切換到另一個線程執行相同的操作,造成數據不一致。
1.3.2 線程安全問題
線程安全問題是并發沖突的一種具體表現形式。一個類或者一段代碼在多線程環境下能夠正確執行,并且不會因為多線程的并發訪問而產生錯誤的結果,那么它就是線程安全的 。反之,如果在多線程訪問時會出現數據錯誤、邏輯混亂等問題,就存在線程安全隱患。例如,一個非線程安全的計數器類,在多線程環境下進行計數操作時,可能會出現計數不準確的情況。
1.3.3 死鎖
死鎖是多線程編程中一種較為嚴重的問題,當兩個或多個線程相互等待對方釋放資源,而導致所有線程都無法繼續執行時,就發生了死鎖 。例如,線程A持有資源1并等待獲取資源2,而線程B持有資源2并等待獲取資源1,此時兩個線程都在等待對方釋放資源,形成了死鎖,程序將陷入無限期的等待狀態。
1.3.4 性能開銷
雖然多線程可以提高程序的執行效率,但過多的線程也會帶來性能開銷 。線程的創建、銷毀以及線程上下文的切換都需要消耗系統資源。如果線程數量過多,線程切換過于頻繁,反而會占用大量的CPU時間,導致程序性能下降。此外,為了保證線程安全,對共享資源進行同步操作(如加鎖)也會增加一定的性能開銷。

二、線程池深入解析

2.1 線程池的概念與作用
線程池(Thread pool)是多個線程的集合,它通過一定邏輯決定如何為線程分配工作 。在并發編程領域,線程池技術的引入主要是為了優化性能和簡化線程管理。傳統的多線程編程中,頻繁地創建和銷毀線程會大量消耗系統資源,而且不當的操作可能引發安全隱患。線程池通過線程的復用,顯著降低了這些開銷 。
線程池采用預創建的技術,在應用程序啟動后,會立即創建一定數量的線程(N)放入空閑隊列中。這些線程處于阻塞狀態,不消耗CPU,但占用較小的內存空間。當有任務要執行時,線程池分配池中的一個工作者線程執行任務,并在任務結束后解除分配,使該線程在下次請求額外工作時可用 。
例如,在一個Web服務器中,如果每次有新的HTTP請求都創建一個新線程來處理,當并發請求量較大時,頻繁的線程創建和銷毀操作會嚴重影響服務器的性能。而使用線程池,預先創建一定數量的線程,當請求到來時,從線程池中獲取一個空閑線程來處理請求,請求處理完成后線程返回線程池,這樣可以大大提高服務器的響應速度和吞吐量。
2.2 線程池的組成部分
2.2.1 線程池管理器(ThreadPoolManager)
線程池管理器負責創建并管理線程池,包括創建線程池、銷毀線程池和添加新任務 。它將工作線程放于線程池內,監控線程池的狀態(如線程數量、任務隊列長度等),并根據一定的策略來決定是否創建新線程、從任務隊列中獲取任務分配給線程執行等操作。在Java中,ThreadPoolExecutor類就承擔了線程池管理器的角色,它提供了豐富的方法和參數來配置和管理線程池。
2.2.2 工作線程(WorkThread)
工作線程是指線程池中實際執行任務的線程 。線程池中的線程在沒有任務時處于等待狀態,可以循環地執行任務。當線程池管理器分配任務給工作線程時,工作線程從等待狀態變為運行狀態,執行任務。任務執行完畢后,工作線程又回到等待狀態,等待下一個任務的分配。每個工作線程在執行任務時,需要注意線程安全問題,避免對共享資源的并發訪問沖突。
2.2.3 任務接口(Task)
任務接口規定了每個任務必須實現的方法,以供工作線程調度任務的執行 。它主要規定了任務的入口、任務執行完后的收尾工作、任務的執行狀態等。在Java中,任務通常通過實現Runnable接口或Callable接口來定義。Runnable接口的run方法定義了任務的具體執行邏輯,而Callable接口的call方法不僅可以定義任務執行邏輯,還可以返回任務執行的結果。
2.2.4 任務隊列
任務隊列提供一種緩沖機制,將沒有處理的任務放在任務隊列中 。當線程池中的工作線程都在忙碌時,新提交的任務會被放入任務隊列等待執行。任務隊列通常是一個阻塞隊列(BlockingQueue),它能夠在隊列滿時阻塞新任務的插入,在隊列空時阻塞任務的獲取,從而保證線程安全。常見的阻塞隊列有ArrayBlockingQueue(基于數組的有界阻塞隊列)、LinkedBlockingQueue(基于鏈表的無界阻塞隊列)等。
2.3 線程池的工作原理
當向線程池提交一個任務時,線程池的處理流程如下(以Java的ThreadPoolExecutor為例),如圖1所示:
- 判斷核心線程數:線程池內部會獲取當前活躍線程的數量(activeCount),判斷其是否小于核心線程數(corePoolSize) 。如果是,線程池會使用全局鎖鎖定線程池(這是為了保證線程安全,避免多個線程同時創建線程導致混亂),創建一個新的工作線程來處理該任務,任務處理完成后釋放全局鎖。
- 任務入隊列:如果當前活躍線程數量大于等于核心線程數,線程池會判斷任務隊列是否已滿 。如果任務隊列未滿,直接將任務放入任務隊列。此時,工作線程會從任務隊列中獲取任務并執行。在這一步驟中,由于不需要創建新線程,并且任務隊列的操作通常是線程安全的,所以效率相對較高(前提是線程池已經預熱,即內部線程數量大于等于corePoolSize)。
- 判斷最大線程數:如果任務隊列已滿,線程池會進一步判斷當前活躍線程數量是否小于最大線程數(maxPoolSize) 。如果是,線程池會再次使用全局鎖鎖定線程池,創建一個新的工作線程來處理任務,任務處理完成后釋放全局鎖。
- 拒絕策略:如果當前活躍線程數量已經達到最大線程數,并且任務隊列也已滿,此時線程池無法再接受新任務,將采用飽和處理策略(即拒絕策略)來處理該任務 。常見的拒絕策略有AbortPolicy(直接拋出異常,拒絕任務)、CallerRunsPolicy(由提交任務的線程來執行任務)、DiscardPolicy(直接丟棄任務,不做任何處理)、DiscardOldestPolicy(丟棄任務隊列中最老的任務,然后嘗試提交當前任務)。
2.4 線程池的配置規則
2.4.1 核心線程數(corePoolSize)
核心線程數是線程池中始終保持存活的線程數量,即使這些線程處于空閑狀態,除非設置了allowCoreThreadTimeOut(允許核心線程超時),否則也不會被回收 。合理設置核心線程數非常關鍵,它應該根據任務的類型和系統的資源情況來確定。對于I/O密集型任務,由于線程大部分時間在等待I/O操作完成,CPU利用率較低,此時可以適當增加核心線程數,以便在等待I/O時能夠有更多的線程去執行其他任務。例如,在一個網絡爬蟲程序中,大量的時間花費在等待網絡響應上,核心線程數可以設置為CPU核心數的2 - 3倍。而對于CPU密集型任務,線程主要進行計算操作,CPU利用率較高,核心線程數一般設置為CPU核心數即可,以避免過多的線程競爭CPU資源導致性能下降。
2.4.2 最大線程數(maximumPoolSize)
最大線程數是線程池中允許存在的最大線程數量 。當任務隊列已滿,且當前活躍線程數量小于最大線程數時,線程池會創建新的線程來處理任務。最大線程數的設置需要考慮系統的硬件資源(如CPU、內存等)以及任務的并發程度。如果設置過大,可能會導致系統資源耗盡,出現性能問題甚至系統崩潰;如果設置過小,可能無法充分利用系統資源,影響程序的并發處理能力。一般來說,可以根據系統的CPU核心數、內存大小以及預估的最大并發任務數來綜合確定最大線程數。例如,在一個內存充足但CPU核心數有限的系統中,對于CPU密集型任務,最大線程數可以設置為CPU核心數的2倍左右;對于I/O密集型任務,可以適當增大,但也需要避免過度創建線程。
2.4.3 阻塞隊列(BlockingQueue)
阻塞隊列用于暫時存放接收到的異步任務 。當線程池的核心線程都在忙時,新的任務會被緩存在阻塞隊列中。阻塞隊列的選擇和配置對線程池的性能有重要影響。常見的阻塞隊列有ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue等。ArrayBlockingQueue是一個基于數組的有界阻塞隊列,它的大小在創建時就固定下來,使用它可以明確限制任務隊列的長度,防止任務隊列無限增長導致內存溢出 。LinkedBlockingQueue是一個基于鏈表的無界阻塞隊列(也可以創建有界的),它的容量可以根據需要自動擴展,但如果任務產生的速度遠大于線程處理的速度,可能會導致隊列占用大量內存。SynchronousQueue是一個特殊的隊列,它不存儲元素,每個插入操作必須等待另一個線程的移除操作,反之亦然,它適合于任務處理速度非常快的場景,能夠避免任務在隊列中積壓。
2.4.4 空閑線程的存活時間(keepAliveTime)
當線程數量超過核心線程數時,多余的空閑線程在終止前等待新任務的最長時間就是空閑線程的存活時間 。如果在這段時間內沒有新任務分配給這些空閑線程,它們將被銷毀,以釋放系統資源。keepAliveTime的設置需要考慮任務的到達頻率和處理時間。如果任務到達頻率不穩定,有時高有時低,可以適當設置較長的keepAliveTime,以便在任務高峰期過后,線程池中的線程不會立即被銷毀,當新的任務到來時可以快速復用這些線程,減少線程創建的開銷。相反,如果任務到達頻率較為穩定,且處理速度較快,可以適當縮短keepAliveTime,及時釋放空閑線程占用的資源。
2.4.5 時間單位(unit)
時間單位用于指定keepAliveTime的時間度量單位,常見的有TimeUnit.SECONDS(秒)、TimeUnit.MILLISECONDS(毫秒)等 。根據實際需求選擇合適的時間單位,確保keepAliveTime的設置符合任務處理的時間尺度。例如,如果任務的處理時間通常在毫秒級,那么使用TimeUnit.MILLISECONDS作為時間單位可以更精確地控制空閑線程的存活時間。
2.4.6 線程工廠(threadFactory)
線程工廠是一個工廠模式接口,用于創建新線程 。通過自定義線程工廠,可以對線程的創建過程進行定制,例如給線程設置有意義的名字、設置線程的優先級等。在Java中,可以通過實現ThreadFactory接口來創建自定義的線程工廠。例如:
public class CustomThreadFactory implements ThreadFactory {private int count = 1;@Overridepublic Thread newThread(Runnable r) {Thread thread = new Thread(r, "CustomThread - " + count);count++;// 可以在此設置線程的優先級等屬性return thread;}
}然后在創建線程池時使用自定義的線程工廠:
ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 4, 10, TimeUnit.SECONDS,new ArrayBlockingQueue<>(10),new CustomThreadFactory()
);這樣創建出來的線程都有自定義的名字,方便在調試和監控時進行區分。
2.4.7 拒絕策略(handler)
當工作隊列已滿且線程池中線程已達上限時,線程池需要采取一定的策略來處理新提交的任務,這就是拒絕策略 。常見的拒絕策略有:
- AbortPolicy:這是默認的拒絕策略,當任務無法被接受時,直接拋出
RejectedExecutionException異常 。這種策略適用于對任務執行非常嚴格,不允許任務丟失的場景。例如,在一個金融交易系統中,如果交易任務被拒絕,可能會導致嚴重的業務問題,此時可以使用AbortPolicy,讓系統管理員及時發現并處理問題。 - CallerRunsPolicy:當任務被拒絕時,由提交任務的線程來執行該任務 。這種策略可以降低新任務的提交速度,因為提交任務的線程需要等待任務執行完成才能繼續提交新任務。例如,在一個簡單的測試環境中,或者對任務執行的實時性要求不高,但又不希望任務丟失的情況下,可以使用
CallerRunsPolicy。 - DiscardPolicy:直接丟棄被拒絕的任務,不做任何處理 。這種策略適用于對任務執行結果不太關注,且任務量較大,允許部分任務丟失的場景。例如,在一些日志記錄系統中,如果日志記錄任務因為線程池繁忙而被拒絕,直接丟棄部分日志任務可能不會對系統的核心功能產生太大影響。
- DiscardOldestPolicy:丟棄任務隊列中最老的任務(即最先進入隊列的任務),然后嘗試提交當前任務 。這種策略假設新任務比老任務更重要,因此丟棄老任務來為新任務騰出空間。例如,在一個實時數據處理系統中,新的數據通常比舊數據更有價值,此時可以使用
DiscardOldestPolicy來確保新數據能夠被及時處理。
在實際配置中,拒絕策略的選擇需要根據業務的重要性、對任務丟失的容忍程度以及系統的負載情況來決定。例如,對于涉及資金交易的任務,不允許任務丟失,此時AbortPolicy可能是較好的選擇,因為它可以及時發現問題并進行處理;而對于一些非核心的統計任務,DiscardPolicy或DiscardOldestPolicy可能更為合適。
2.5 線程池鎖機制
在多線程環境下,線程池中的線程需要共享資源(如任務隊列、線程池狀態變量等),為了保證這些共享資源的線程安全,必須引入鎖機制。線程池鎖用于控制多個線程對共享資源的訪問,防止出現并發沖突。
2.5.1 線程池中的鎖類型
- 內部鎖(synchronized):Java中的
synchronized關鍵字是一種內置的鎖機制,它可以修飾方法或代碼塊。在ThreadPoolExecutor中,部分方法(如execute()、submit()等)的內部實現使用了synchronized來保證線程安全。例如,當線程池需要修改線程數量、任務隊列狀態等共享變量時,通過synchronized來確保同一時間只有一個線程能夠執行這些修改操作。 - 顯式鎖(Lock):
java.util.concurrent.locks.Lock接口提供了更靈活的鎖機制,相比synchronized,它具有可中斷、可超時獲取鎖、可嘗試獲取鎖等特點。在一些復雜的線程池場景中,顯式鎖可以提供更精細的控制。例如,在自定義線程池中,如果需要實現更復雜的同步邏輯(如讀寫分離鎖),可以使用ReentrantLock。
2.5.2 鎖的使用場景
- 任務隊列操作:當多個線程同時向任務隊列添加任務或從任務隊列獲取任務時,需要對任務隊列進行加鎖,以防止出現數據不一致的情況。例如,
ArrayBlockingQueue內部使用了ReentrantLock來保證隊列操作的線程安全。 - 線程池狀態修改:線程池的狀態(如
RUNNING、SHUTDOWN、STOP等)是一個共享變量,當線程池進行 shutdown、調整線程數量等操作時,需要通過鎖來保證狀態修改的原子性和可見性。 - 線程池統計信息更新:線程池中的一些統計信息(如已完成任務數、活躍線程數等)需要在多線程環境下準確更新,鎖機制可以確保這些統計信息的準確性。
2.5.3 鎖機制的性能影響
雖然鎖機制可以保證線程安全,但也會帶來一定的性能開銷。鎖的競爭會導致線程阻塞和上下文切換,降低程序的并發性能。因此,在設計線程池時,需要合理使用鎖機制,盡量減少鎖的競爭。
例如,ThreadPoolExecutor在設計時采用了分段鎖的思想,將線程池的狀態和線程數量用一個原子變量ctl來表示,通過位運算來分離狀態和數量信息,從而減少了鎖的競爭。此外,任務隊列的選擇也會影響鎖的性能,ConcurrentLinkedQueue是一種無鎖隊列,它通過CAS(Compare - and - Swap)操作來保證線程安全,在高并發場景下具有更好的性能。
下面是一個線程池鎖機制的時序圖,展示了兩個線程同時向任務隊列添加任務時,鎖的獲取和釋放過程:
sequenceDiagramparticipant Thread1participant Thread2participant TaskQueueparticipant LockThread1->>Lock: 嘗試獲取鎖Lock->>Thread1: 鎖獲取成功Thread1->>TaskQueue: 執行添加任務操作Thread1->>Lock: 釋放鎖Thread2->>Lock: 嘗試獲取鎖(此時鎖被Thread1持有,等待)Lock->>Thread2: 鎖獲取成功(Thread1釋放后)Thread2->>TaskQueue: 執行添加任務操作Thread2->>Lock: 釋放鎖時序圖說明:當Thread1和Thread2同時向任務隊列添加任務時,Thread1先獲取到鎖,執行添加任務操作,完成后釋放鎖。Thread2在嘗試獲取鎖時發現鎖被持有,進入等待狀態,直到Thread1釋放鎖后,Thread2才能獲取鎖并執行添加任務操作。通過鎖機制,保證了任務隊列操作的原子性,避免了并發沖突。
三、并發沖突與解決方案
3.1 并發沖突的產生原因
并發沖突是指多個線程在同時訪問和修改共享資源時,由于執行順序的不確定性而導致的程序行為異常。其產生的主要原因包括以下幾個方面:
3.1.1 競態條件(Race Condition)
競態條件是指當多個線程同時訪問和修改同一個共享資源時,最終的結果依賴于線程執行的先后順序。例如,兩個線程同時對一個變量進行自增操作:
public class Counter {private int count = 0;public void increment() {count++;}public int getCount() {return count;}
}在單線程環境下,調用increment()方法1000次,count的值會正確地變為1000。但在多線程環境下,假設有兩個線程同時執行increment()方法,每個線程執行500次,最終的count值可能小于1000。這是因為count++操作并不是原子性的,它可以分解為三個步驟:讀取count的值、將值加1、將結果寫回count。當兩個線程交替執行這些步驟時,就可能出現數據覆蓋的情況。
例如:
- 線程A讀取
count的值為100。 - 線程B讀取
count的值為100。 - 線程A將值加1,得到101,寫回
count,此時count為101。 - 線程B將值加1,得到101,寫回
count,此時count仍為101。
原本兩個線程各執行一次自增操作,count應該增加2,但實際只增加了1,這就是競態條件導致的并發沖突。
3.1.2 內存可見性問題
內存可見性是指當一個線程修改了共享變量的值后,其他線程能夠立即看到該修改。在多線程環境下,由于CPU緩存、指令重排序等原因,可能導致線程對共享變量的修改無法被其他線程及時感知。
例如,在下面的代碼中:
public class VisibilityExample {private boolean flag = false;public void setFlag() {flag = true;}public void loopUntilFlag() {while (!flag) {// 空循環}}
}當線程A執行setFlag()方法將flag設置為true后,線程B執行loopUntilFlag()方法可能仍然會陷入無限循環。這是因為線程A對flag的修改可能只保存在CPU緩存中,而沒有及時刷新到主內存中,線程B讀取的flag值仍然是主內存中的舊值false。
3.1.3 原子性問題
原子性是指一個操作或一系列操作要么全部執行,要么全部不執行,不會被其他線程中斷。在多線程環境下,如果一個操作不具有原子性,就可能被其他線程打斷,導致數據不一致。
例如,前面提到的count++操作就不具有原子性,它可以被分解為讀取、修改、寫入三個步驟,在這三個步驟之間,可能有其他線程對count進行操作,從而導致結果錯誤。
3.2 并發沖突的解決方案
針對上述并發沖突的產生原因,可以采取以下解決方案:
3.2.1 同步機制
同步機制是保證多線程并發安全的最常用方法,它通過限制多個線程對共享資源的并發訪問,確保同一時間只有一個線程能夠執行特定的代碼塊或方法。
- synchronized關鍵字:
synchronized可以修飾方法或代碼塊,它能夠保證被修飾的部分在同一時間只有一個線程能夠執行。例如,將前面的Counter類中的increment()方法用synchronized修飾:
public class SynchronizedCounter {private int count = 0;public synchronized void increment() {count++;}public synchronized int getCount() {return count;}
}此時,increment()方法和getCount()方法都是同步方法,同一時間只有一個線程能夠執行它們,從而避免了競態條件和內存可見性問題。
- Lock接口:
Lock接口提供了比synchronized更靈活的同步機制,它允許手動獲取和釋放鎖,支持可中斷鎖、超時鎖等特性。ReentrantLock是Lock接口的一個常用實現類。例如,使用ReentrantLock來解決Counter類的并發問題:
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;public class LockCounter {private int count = 0;private Lock lock = new ReentrantLock();public void increment() {lock.lock();try {count++;} finally {lock.unlock();}}public int getCount() {lock.lock();try {return count;} finally {lock.unlock();}}
}在increment()和getCount()方法中,首先通過lock.lock()獲取鎖,然后執行操作,最后在finally塊中通過lock.unlock()釋放鎖。finally塊確保無論操作是否拋出異常,鎖都能被釋放,避免死鎖。
synchronized和Lock的區別如下表所示:
| 特性 | synchronized | Lock |
|---|---|---|
| 鎖的獲取 | 自動獲取 | 手動獲取(lock()方法) |
| 鎖的釋放 | 自動釋放(方法或代碼塊執行完畢或拋出異常時) | 手動釋放(unlock()方法,通常在finally塊中) |
| 可中斷性 | 不可中斷 | 可中斷(lockInterruptibly()方法) |
| 超時獲取 | 不支持 | 支持(tryLock(long time, TimeUnit unit)方法) |
| 公平鎖 | 非公平鎖 | 可指定為公平鎖或非公平鎖 |
| 條件變量 | 不支持 | 支持(通過newCondition()方法獲取Condition對象) |
3.2.2 原子類
Java中的java.util.concurrent.atomic包提供了一系列原子類,這些原子類通過CAS(Compare - and - Swap)操作來保證操作的原子性,避免了使用鎖機制帶來的性能開銷。
常見的原子類包括:
AtomicInteger:用于整數類型的原子操作。AtomicLong:用于長整數類型的原子操作。AtomicBoolean:用于布爾類型的原子操作。AtomicReference:用于對象引用類型的原子操作。
例如,使用AtomicInteger來解決Counter類的并發問題:
import java.util.concurrent.atomic.AtomicInteger;public class AtomicCounter {private AtomicInteger count = new AtomicInteger(0);public void increment() {count.incrementAndGet();}public int getCount() {return count.get();}
}AtomicInteger的incrementAndGet()方法通過CAS操作實現了原子性的自增,它的執行過程如下:
- 讀取當前
count的值。 - 計算自增后的值。
- 使用CAS操作將
count的值更新為自增后的值,如果CAS操作失敗(即count的值在讀取后被其他線程修改),則重復步驟1 - 3,直到CAS操作成功。
CAS操作是一種無鎖的原子操作,它不需要獲取鎖,因此在高并發場景下具有更好的性能。
3.2.3 volatile關鍵字
volatile關鍵字用于保證變量的內存可見性,它可以確保當一個線程修改了volatile變量的值后,其他線程能夠立即看到該修改。
例如,對于前面的VisibilityExample類,可以將flag變量聲明為volatile:
public class VolatileExample {private volatile boolean flag = false;public void setFlag() {flag = true;}public void loopUntilFlag() {while (!flag) {// 空循環}}
}當線程A執行setFlag()方法將flag設置為true后,flag的值會立即刷新到主內存中,線程B在讀取flag的值時會從主內存中獲取最新的值true,從而退出循環。
需要注意的是,volatile關鍵字只能保證內存可見性,不能保證原子性。例如,volatile int count = 0;,count++操作仍然不是原子性的,可能會出現并發沖突。因此,volatile通常用于修飾那些被多個線程讀取,但只被一個線程修改的變量,或者用于標記狀態的變量。
3.2.4 并發容器
Java中的java.util.concurrent包提供了一系列線程安全的并發容器,這些容器內部實現了同步機制或無鎖算法,能夠在多線程環境下安全地進行操作。
常見的并發容器包括:
ConcurrentHashMap:線程安全的哈希表,它采用分段鎖的思想,將哈希表分為多個段,每個段獨立加鎖,從而提高了并發性能。CopyOnWriteArrayList:線程安全的列表,它在修改操作時會創建一個新的數組副本,修改完成后再將引用指向新的數組,適合讀多寫少的場景。ConcurrentLinkedQueue:線程安全的隊列,它通過CAS操作實現了無鎖的并發訪問,適合高并發場景下的隊列操作。
例如,使用ConcurrentHashMap來存儲共享數據:
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;public class ConcurrentMapExample {private Map<String, Integer> map = new ConcurrentHashMap<>();public void add(String key, int value) {map.put(key, value);}public int get(String key) {return map.getOrDefault(key, 0);}
}ConcurrentHashMap的put()和get()方法都是線程安全的,多個線程可以同時對其進行操作,而不需要額外的同步措施。
下面是一個并發沖突解決方案的時序圖,展示了使用synchronized關鍵字解決count++操作并發沖突的過程:
sequenceDiagramparticipant Thread1participant Thread2participant Counterparticipant SynchronizedLockThread1->>SynchronizedLock: 嘗試獲取鎖SynchronizedLock->>Thread1: 鎖獲取成功Thread1->>Counter: 執行count++操作(讀取count=100,修改為101,寫入)Thread1->>SynchronizedLock: 釋放鎖Thread2->>SynchronizedLock: 嘗試獲取鎖(此時鎖被Thread1持有,等待)SynchronizedLock->>Thread2: 鎖獲取成功(Thread1釋放后)Thread2->>Counter: 執行count++操作(讀取count=101,修改為102,寫入)Thread2->>SynchronizedLock: 釋放鎖時序圖說明:Thread1先獲取到synchronized鎖,執行count++操作,將count從100增加到101,然后釋放鎖。Thread2在嘗試獲取鎖時需要等待,直到Thread1釋放鎖后才能獲取鎖,執行count++操作,將count從101增加到102。通過synchronized鎖,保證了count++操作的原子性,避免了并發沖突。
四、實際開發中線程池可能產生的問題及解決方案
4.1 線程泄漏
線程泄漏是指線程池中的線程在完成任務后沒有被正確回收,導致線程池中的線程數量逐漸增加,最終耗盡系統資源。
4.1.1 線程泄漏的產生原因
- 任務執行時間過長:如果線程池中的線程執行的任務需要很長時間才能完成,甚至陷入無限循環,這些線程將一直處于運行狀態,不會被回收,導致線程池中的可用線程數量逐漸減少。
- 線程阻塞未釋放:線程在執行任務時,如果因為等待某個資源(如鎖、網絡連接等)而進入阻塞狀態,且該資源永遠無法獲得,線程將一直處于阻塞狀態,無法繼續執行其他任務,也無法被回收。
- 異常未處理:如果線程在執行任務時拋出未捕獲的異常,線程將終止,但線程池可能不會及時創建新的線程來替代它,導致線程池中的線程數量逐漸減少。
4.1.2 線程泄漏的避免與解決方案
- 設置合理的任務超時時間:對于可能執行時間較長的任務,可以設置超時時間,當任務執行時間超過超時時間時,中斷任務并回收線程。例如,使用
Future和get()方法的超時參數:
ExecutorService executor = Executors.newFixedThreadPool(5);
Future<?> future = executor.submit(new LongRunningTask());
try {future.get(1, TimeUnit.MINUTES); // 等待任務執行完成,最多等待1分鐘
} catch (TimeoutException e) {future.cancel(true); // 超時后取消任務System.out.println("任務執行超時,已取消");
} catch (InterruptedException | ExecutionException e) {e.printStackTrace();
}- 避免線程無限阻塞:在編寫任務代碼時,要避免線程無限期地等待資源。對于可能無法獲取的資源,要設置合理的等待時間,并在等待超時后進行相應的處理(如重試、降級等)。例如,使用
Lock的tryLock()方法設置超時時間:
Lock lock = new ReentrantLock();
try {if (lock.tryLock(10, TimeUnit.SECONDS)) {// 獲取鎖成功,執行操作} else {// 獲取鎖超時,進行相應處理System.out.println("獲取鎖超時");}
} catch (InterruptedException e) {e.printStackTrace();
} finally {if (lock.isHeldByCurrentThread()) {lock.unlock();}
}- 捕獲并處理任務中的異常:在任務代碼中,要捕獲所有可能拋出的異常,并進行相應的處理,避免線程因為未捕獲的異常而終止。例如,在
Runnable的run()方法中添加異常處理:
executor.submit(new Runnable() {@Overridepublic void run() {try {// 任務執行代碼} catch (Exception e) {e.printStackTrace();// 異常處理邏輯}}
});- 監控線程池狀態:定期監控線程池的狀態,如線程數量、活躍線程數量、任務隊列長度等,當發現線程數量異常增加或減少時,及時進行排查和處理。可以通過
ThreadPoolExecutor的getPoolSize()、getActiveCount()、getQueue().size()等方法獲取線程池的狀態信息。
4.2 線程池過載
線程池過載是指線程池中的任務數量超過了其處理能力,導致任務隊列積壓,響應時間變長,甚至出現任務被拒絕的情況。
4.2.1 線程池過載的產生原因
- 任務提交速度過快:當任務提交的速度超過了線程池的處理速度時,任務會不斷積壓在任務隊列中,導致隊列長度逐漸增加。
- 任務執行時間過長:如果任務執行時間過長,線程池中的線程會被長時間占用,無法及時處理新的任務,導致任務隊列積壓。
- 線程池配置不合理:核心線程數、最大線程數、任務隊列大小等配置參數設置不合理,也可能導致線程池過載。例如,核心線程數和最大線程數設置過小,任務隊列設置過大,當任務量突然增加時,線程池無法快速創建足夠的線程來處理任務,導致任務隊列積壓。
4.2.2 線程池過載的避免與解決方案
- 合理配置線程池參數:根據任務的類型、執行時間、并發量等因素,合理配置線程池的核心線程數、最大線程數、任務隊列大小等參數。對于短期突發的任務,可以適當增大最大線程數和任務隊列大小;對于長期運行的任務,要保證核心線程數能夠滿足日常的任務處理需求。
- 控制任務提交速度:在任務提交端,可以通過限流等方式控制任務的提交速度,避免任務提交過快導致線程池過載。例如,使用
Semaphore來限制并發提交的任務數量:
Semaphore semaphore = new Semaphore(100); // 最多允許100個任務同時提交
ExecutorService executor = Executors.newFixedThreadPool(50);for (int i = 0; i < 1000; i++) {try {semaphore.acquire();executor.submit(new Runnable() {@Overridepublic void run() {try {// 任務執行代碼} finally {semaphore.release();}}});} catch (InterruptedException e) {e.printStackTrace();}
}- 使用拒絕策略進行降級處理:當線程池過載時,合理的拒絕策略可以避免系統崩潰,并進行降級處理。例如,使用
CallerRunsPolicy拒絕策略,讓提交任務的線程執行任務,從而減緩任務提交的速度;或者自定義拒絕策略,將被拒絕的任務保存到持久化存儲中,待線程池空閑時再進行處理。
RejectedExecutionHandler handler = new RejectedExecutionHandler() {@Overridepublic void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {// 自定義拒絕策略,如將任務保存到數據庫saveTaskToDatabase(r);}
};ThreadPoolExecutor executor = new ThreadPoolExecutor(5, 10, 1, TimeUnit.MINUTES,new ArrayBlockingQueue<>(100),handler
);- 任務拆分與優先級調度:將大型任務拆分為小型任務,提高任務的處理效率。同時,對任務進行優先級排序,讓重要的任務優先執行,確保核心業務的正常運行。例如,使用
PriorityBlockingQueue作為任務隊列,實現任務的優先級調度:
ExecutorService executor = new ThreadPoolExecutor(5, 10, 1, TimeUnit.MINUTES,new PriorityBlockingQueue<>(100, new TaskPriorityComparator())
);其中,TaskPriorityComparator是一個自定義的比較器,用于比較任務的優先級。
4.3 死鎖
死鎖是指兩個或多個線程相互等待對方釋放資源,而導致所有線程都無法繼續執行的狀態。
4.3.1 死鎖的產生條件
死鎖的產生需要滿足以下四個條件:
- 互斥條件:資源只能被一個線程持有,不能被多個線程同時持有。
- 持有并等待條件:線程在持有一個資源的同時,等待獲取其他資源。
- 不可剝奪條件:線程持有的資源不能被其他線程強行剝奪。
- 循環等待條件:多個線程之間形成一種循環等待資源的關系。
例如,線程A持有資源1,等待獲取資源2;線程B持有資源2,等待獲取資源1,此時就滿足了死鎖的四個條件,發生了死鎖。
4.3.2 死鎖的避免與解決方案
- 按順序獲取資源:將資源進行編號,規定線程必須按照編號從小到大的順序獲取資源,避免循環等待條件。例如,資源1編號為1,資源2編號為2,線程A和線程B都必須先獲取資源1,再獲取資源2,這樣就不會出現循環等待的情況。
// 資源編號:resource1=1,resource2=2
class ResourceUser {public void useResources(Lock resource1, Lock resource2) {// 按順序獲取資源Lock firstLock = resource1;Lock secondLock = resource2;if (System.identityHashCode(resource1) > System.identityHashCode(resource2)) {firstLock = resource2;secondLock = resource1;}firstLock.lock();try {secondLock.lock();try {// 使用資源} finally {secondLock.unlock();}} finally {firstLock.unlock();}}
}- 定時釋放資源:在獲取資源時設置超時時間,當線程等待資源超過超時時間時,釋放已持有的資源,避免持有并等待條件。例如,使用
Lock的tryLock()方法設置超時時間:
Lock resource1 = new ReentrantLock();
Lock resource2 = new ReentrantLock();Thread threadA = new Thread(new Runnable() {@Overridepublic void run() {try {if (resource1.tryLock(10, TimeUnit.SECONDS)) {try {Thread.sleep(100); // 模擬持有資源1if (resource2.tryLock(10, TimeUnit.SECONDS)) {try {// 使用資源2} finally {resource2.unlock();}} else {// 獲取資源2超時,釋放資源1System.out.println("線程A獲取資源2超時,釋放資源1");}} finally {if (resource1.isHeldByCurrentThread()) {resource1.unlock();}}} else {System.out.println("線程A獲取資源1超時");}} catch (InterruptedException e) {e.printStackTrace();}}
});Thread threadB = new Thread(new Runnable() {@Overridepublic void run() {// 類似線程A的邏輯,先獲取資源2,再獲取資源1}
});threadA.start();
threadB.start();- 使用tryLock避免死鎖:在獲取多個資源時,使用
tryLock()方法嘗試獲取資源,如果獲取失敗,則釋放已持有的資源,并進行重試。 - 監控死鎖:使用工具(如JDK自帶的
jstack命令)監控線程狀態,及時發現死鎖。jstack命令可以生成線程的堆棧信息,通過分析堆棧信息可以找出死鎖的線程和相關資源。
例如,使用jstack <pid>命令(其中<pid>是Java進程的進程號)生成線程堆棧信息,在堆棧信息中查找deadlock關鍵字,即可發現死鎖的相關信息。
下面是一個死鎖產生和解決的時序圖:
sequenceDiagramparticipant ThreadAparticipant ThreadBparticipant Resource1participant Resource2Note over ThreadA,ThreadB: 死鎖產生過程ThreadA->>Resource1: 獲取Resource1Resource1->>ThreadA: 資源獲取成功ThreadB->>Resource2: 獲取Resource2Resource2->>ThreadB: 資源獲取成功ThreadA->>Resource2: 嘗試獲取Resource2(等待)ThreadB->>Resource1: 嘗試獲取Resource1(等待)Note over ThreadA,ThreadB: 發生死鎖Note over ThreadA,ThreadB: 死鎖解決過程(按順序獲取資源)ThreadA->>Resource1: 獲取Resource1(按順序先獲取編號小的資源)Resource1->>ThreadA: 資源獲取成功ThreadA->>Resource2: 獲取Resource2Resource2->>ThreadA: 資源獲取成功ThreadA->>Resource2: 釋放Resource2ThreadA->>Resource1: 釋放Resource1ThreadB->>Resource1: 獲取Resource1Resource1->>ThreadB: 資源獲取成功ThreadB->>Resource2: 獲取Resource2Resource2->>ThreadB: 資源獲取成功ThreadB->>Resource2: 釋放Resource2ThreadB->>Resource1: 釋放Resource1時序圖說明:在死鎖產生過程中,ThreadA獲取Resource1后等待獲取Resource2,ThreadB獲取Resource2后等待獲取Resource1,形成死鎖。在死鎖解決過程中,線程按照資源編號的順序獲取資源,ThreadA先獲取Resource1,再獲取Resource2,完成后釋放資源;ThreadB再按照同樣的順序獲取資源,避免了死鎖。
八、線程池與業務開發流程的結合
線程池作為并發處理的核心組件,需深度融入業務開發全流程(需求分析、設計、編碼、測試、上線、運維),確保技術選型與業務目標一致,避免為了“技術而技術”。
8.1 需求分析階段:明確并發場景
在需求分析階段,需識別業務中的并發場景、任務特性及性能目標,為線程池設計提供依據。
8.1.1 業務場景拆解
- 任務類型:區分I/O密集型(如訂單創建時調用支付接口)、CPU密集型(如促銷活動中的價格計算)、混合類型(如數據分析+結果存儲)。
- 并發量預估:根據業務規模(如日均訂單100萬,峰值QPS 1000)估算任務提交頻率、峰值并發量。
- 響應時間要求:核心業務(如支付回調處理)需毫秒級響應,非核心業務(如日志異步寫入)可容忍秒級延遲。
示例:電商訂單系統需求拆解
| 業務環節 | 任務類型 | 峰值并發量 | 響應時間要求 |
|---|---|---|---|
| 訂單創建 | I/O密集型(調用庫存、支付接口) | 500 TPS | < 500ms |
| 訂單分賬 | CPU密集型(計算商家分成) | 200 TPS | < 1000ms |
| 訂單日志 | I/O密集型(寫入數據庫) | 1000 TPS | < 3000ms |
8.1.2 技術選型決策
根據場景拆解結果,決定是否使用線程池及線程池類型:
- 若任務為串行依賴(如訂單創建→支付→發貨),且單任務耗時短(<10ms),無需使用線程池,同步執行更簡單。
- 若任務可并行(如批量推送訂單通知給多個用戶),且并發量高,必須引入線程池。
決策矩陣:
| 并發量 | 響應時間 | 是否使用線程池 | 推薦配置方向 |
|---|---|---|---|
| 低(<10 TPS) | 無嚴格要求 | 可選(簡化代碼) | 單線程池(core=1) |
| 中(10-1000 TPS) | 毫秒級 | 是 | 多線程池隔離(核心/非核心業務) |
| 高(>1000 TPS) | 亞毫秒級 | 是(結合分布式線程池) | 動態擴縮容+隊列限流 |
8.2 設計階段:線程池架構設計
設計階段需結合業務架構,確定線程池的數量、職責、配置及與其他組件的交互方式。
8.2.1 線程池隔離策略
根據“故障域隔離”原則,為不同業務模塊設計獨立線程池,避免跨模塊影響。
隔離維度:
- 業務模塊隔離:訂單線程池、商品線程池、用戶線程池。
- 任務優先級隔離:核心任務池(如支付回調)、普通任務池(如訂單詳情查詢)、低優先級任務池(如數據歸檔)。
示例:電商系統線程池架構
電商系統
├─ 核心業務線程池組
│ ├─ orderExecutor(訂單創建/支付)
│ ├─ inventoryExecutor(庫存扣減)
│ └─ paymentExecutor(支付處理)
├─ 非核心業務線程池組
│ ├─ logExecutor(日志寫入)
│ ├─ notifyExecutor(短信/推送通知)
│ └─ statisticExecutor(銷售統計)
└─ 公共線程池(僅用于臨時、低優先級任務)8.2.2 與業務組件的交互設計
線程池需與業務組件(如緩存、消息隊列、數據庫)協同,避免成為性能瓶頸。
示例:訂單創建流程與線程池交互
- 主線程接收訂單請求,參數校驗后提交核心任務到
orderExecutor。 orderExecutor的線程執行以下步驟:- 調用
inventoryExecutor扣減庫存(異步,等待結果)。 - 調用支付接口(同步,I/O阻塞)。
- 提交訂單數據到消息隊列(異步,無需等待)。
- 調用
- 任務完成后,通過
CompletableFuture回調通知主線程,返回結果。
時序圖:
sequenceDiagramparticipant 客戶端participant 主線程participant orderExecutor(線程1)participant inventoryExecutor(線程2)participant 支付接口participant 消息隊列客戶端->>主線程: 提交訂單請求主線程->>主線程: 參數校驗主線程->>orderExecutor(線程1): 提交訂單處理任務orderExecutor(線程1)->>inventoryExecutor(線程2): 提交扣減庫存任務inventoryExecutor(線程2)->>inventoryExecutor(線程2): 扣減庫存inventoryExecutor(線程2)-->>orderExecutor(線程1): 返回庫存扣減結果orderExecutor(線程1)->>支付接口: 調用支付接口(同步I/O)支付接口-->>orderExecutor(線程1): 返回支付結果orderExecutor(線程1)->>消息隊列: 異步發送訂單創建消息(無需等待)orderExecutor(線程1)-->>主線程: 返回訂單處理結果主線程-->>客戶端: 返回訂單ID說明:通過線程池拆分任務步驟,將可并行的操作(如庫存扣減)異步化,同步操作(如支付接口調用)放在同一線程執行,平衡效率與復雜度。
8.3 編碼階段:規范線程池使用
編碼階段需遵循線程池使用規范,確保代碼可讀性、可維護性,避免隱蔽的并發問題。
8.3.1 線程池實例管理
- 單例模式:線程池實例全局唯一,避免重復創建(如通過Spring的
@Bean注入)。 - 命名規范:線程池及線程名需包含業務標識(如
orderProcessPool、order-thread-1),便于日志追蹤。
示例:Spring環境下的線程池配置
@Configuration
public class ThreadPoolConfig {// 訂單處理線程池@Bean("orderExecutor")public ExecutorService orderExecutor() {ThreadFactory threadFactory = new ThreadFactory() {private AtomicInteger counter = new AtomicInteger(1);@Overridepublic Thread newThread(Runnable r) {Thread thread = new Thread(r);thread.setName("order-thread-" + counter.getAndIncrement());thread.setDaemon(false); // 核心業務線程非守護線程return thread;}};return new ThreadPoolExecutor(10, // 核心線程數(根據預估并發量)20, // 最大線程數60, TimeUnit.SECONDS,new ArrayBlockingQueue<>(1000), // 有界隊列,避免OOMthreadFactory,new ThreadPoolExecutor.CallerRunsPolicy() // 拒絕策略:調用者執行,平抑流量);}// 日志處理線程池@Bean("logExecutor")public ExecutorService logExecutor() {// 配置略(核心線程數可設為2,隊列容量更大)}
}8.3.2 任務提交與結果處理
- 避免匿名任務:將任務邏輯封裝為獨立類(如
OrderProcessTask),便于單元測試和代碼復用。 - 明確異常處理:任務中必須捕獲異常,避免線程因未處理異常而終止(線程池默認不會打印任務異常,需顯式處理)。
- 結果獲取方式:根據業務需求選擇
submit(Runnable)(無返回值)、submit(Callable)(有返回值,通過Future獲取)、CompletableFuture(異步鏈式調用)。
示例:訂單處理任務封裝
@Service
public class OrderService {@Autowired@Qualifier("orderExecutor")private ExecutorService orderExecutor;public CompletableFuture<OrderResult> createOrder(OrderRequest request) {// 使用CompletableFuture提交任務,支持異步回調return CompletableFuture.supplyAsync(() -> {try {// 任務邏輯:參數校驗→扣減庫存→創建訂單→發送通知return processOrder(request);} catch (Exception e) {// 顯式捕獲異常,記錄日志log.error("訂單處理失敗", e);throw new CompletionException("訂單創建失敗", e); // 包裝為CompletionException}}, orderExecutor);}private OrderResult processOrder(OrderRequest request) {// 具體業務邏輯}
}說明:使用CompletableFuture.supplyAsync提交任務,既利用了線程池的并發能力,又支持鏈式調用(如thenApply處理結果、exceptionally處理異常),代碼更簡潔。
8.4 測試階段:驗證并發正確性
線程池相關代碼需通過多維度測試(單元測試、并發測試、性能測試)驗證正確性,避免上線后暴露問題。
8.4.1 單元測試:驗證任務邏輯
針對任務類編寫單元測試,確保單線程下邏輯正確(并發問題往往源于單線程邏輯漏洞)。
示例:OrderProcessTask單元測試
public class OrderProcessTaskTest {@Testpublic void testProcessOrder() {// 模擬依賴(如庫存服務返回可用)InventoryService mockInventory = Mockito.mock(InventoryService.class);when(mockInventory.deduct(anyString(), anyInt())).thenReturn(true);OrderProcessTask task = new OrderProcessTask(mockInventory, new OrderRequest("item1", 1));OrderResult result = task.call(); // 直接調用任務的call方法(單線程)assertTrue(result.isSuccess());assertEquals("ORDER123", result.getOrderId());}
}8.4.2 并發測試:驗證線程安全
使用工具(如JUnit + CountDownLatch)模擬多線程并發場景,驗證共享資源操作的線程安全。
示例:并發創建訂單測試
@Test
public void testConcurrentOrderCreate() throws InterruptedException {int threadCount = 100; // 模擬100個并發請求CountDownLatch latch = new CountDownLatch(threadCount);OrderService orderService = new OrderService();AtomicInteger successCount = new AtomicInteger(0);for (int i = 0; i < threadCount; i++) {new Thread(() -> {try {CompletableFuture<OrderResult> future = orderService.createOrder(new OrderRequest("item1", 1));OrderResult result = future.get();if (result.isSuccess()) {successCount.incrementAndGet();}} catch (Exception e) {e.printStackTrace();} finally {latch.countDown();}}).start();}latch.await(); // 等待所有線程完成System.out.println("成功訂單數:" + successCount.get());assertEquals(threadCount, successCount.get()); // 驗證無失敗(假設庫存充足)
}8.4.3 性能測試:驗證配置合理性
使用JMeter、Gatling等工具模擬高并發場景,測試線程池在不同配置下的性能指標(吞吐量、響應時間、錯誤率),優化參數。
測試場景:
- 基準測試:默認配置下,QPS 500時的響應時間(目標:< 200ms)。
- 壓力測試:逐步提升QPS至1000、2000,觀察線程池是否出現任務積壓、拒絕。
- 穩定性測試:持續1小時高并發(QPS 800),驗證線程池無內存泄漏、線程泄漏。
性能測試報告示例:
| 線程池配置(核心數/最大數/隊列) | QPS | 平均響應時間 | 95%響應時間 | 拒絕數 |
|---|---|---|---|---|
| 5/10/500 | 500 | 150ms | 200ms | 0 |
| 5/10/500 | 1000 | 500ms | 800ms | 100 |
| 10/20/1000 | 1000 | 200ms | 300ms | 0 |
結論:原配置(5/10/500)在QPS 1000時性能不達標,需調整為10/20/1000。
8.5 上線階段:灰度發布與流量控制
線程池相關功能上線時,需通過灰度發布、流量控制降低風險,避免直接全量上線導致的突發問題。
8.5.1 灰度策略
- 按流量比例:初期僅允許10%的流量進入新線程池邏輯,觀察指標(如拒絕率、響應時間)。
- 按業務維度:先在非核心業務(如測試環境、內部員工訂單)驗證,再推廣至核心業務。
示例:基于Spring Cloud Gateway的灰度路由
spring:cloud:gateway:routes:- id: order-service-new-threadpooluri: lb://order-servicepredicates:- Path=/order/create/**- Weight=group1, 10 # 10%流量路由到新線程池版本filters:- AddRequestHeader=X-Threadpool-Version, new- id: order-service-olduri: lb://order-servicepredicates:- Path=/order/create/**- Weight=group1, 90 # 90%流量路由到舊邏輯訂單服務根據X-Threadpool-Version頭決定是否使用新線程池:
@Service
public class OrderService {@Autowiredprivate ExecutorService newOrderExecutor;private ExecutorService oldOrderExecutor = Executors.newFixedThreadPool(5); // 舊線程池public CompletableFuture<OrderResult> createOrder(OrderRequest request, @RequestHeader(value = "X-Threadpool-Version", required = false) String version) {if ("new".equals(version)) {return CompletableFuture.supplyAsync(() -> processOrder(request), newOrderExecutor);} else {return CompletableFuture.supplyAsync(() -> processOrder(request), oldOrderExecutor);}}
}8.5.2 上線前應急預案
- 開關控制:通過配置中心(如Apollo)設置線程池功能開關,出現問題時可立即關閉,回退到舊邏輯。
- 資源預留:上線期間預留20%的服務器資源(CPU、內存),應對線程池可能的資源波動。
8.6 運維階段:持續監控與優化
上線后需持續監控線程池運行狀態,結合業務變化(如用戶量增長、新功能上線)動態優化配置。
8.6.1 日常監控
- 實時看板:通過Grafana展示線程池核心指標(活躍線程數、隊列長度、拒絕數),設置閾值告警(如隊列長度>80%時發送短信告警)。
- 日志分析:定期分析線程池相關日志(如任務執行耗時分布、異常類型),識別優化點(如某類任務耗時突增,可能是接口性能退化)。
8.6.2 定期優化
- 季度復盤:結合業務增長(如訂單量翻倍)重新評估線程池配置(如核心線程數是否需翻倍)。
- 技術迭代:跟進JDK版本更新(如JDK 21的虛擬線程),評估是否可替換傳統線程池,提升資源利用率。
九、生存級調優于落地:線程池的優先級原則
在業務開發中,“生存”(系統穩定運行)的優先級高于“落地”(新技術快速上線)。線程池作為并發處理的核心組件,需遵循“保守設計、漸進優化”原則,避免因過度設計導致系統復雜度過高,反而增加故障風險。
9.1 優先保證穩定性:避免過度優化
- 夠用就好:初期可使用簡單配置(如
Executors.newFixedThreadPool)滿足業務需求,而非上來就設計動態線程池、熔斷降級等復雜機制。 - 拒絕“炫技”:函數式編程、設計模式的結合需以簡化代碼為目標,而非增加復雜度(如簡單任務無需使用裝飾器模式包裝)。
反例:為一個日均100單的小電商系統設計動態擴縮容+熔斷+多線程池隔離的架構,導致開發周期延長,維護成本高。
正例:初期使用Executors.newCachedThreadPool(自動擴縮容),隨著業務增長逐步優化為自定義線程池+監控,按需迭代。
9.2 故障快速恢復:簡化問題定位
- 線程名可追溯:線程名需包含業務標識(如“pay-callback-thread-1”),避免默認的“pool-1-thread-1”,便于通過
jstack快速定位問題線程。 - 日志埋點清晰:任務提交、開始執行、完成、異常時均需記錄日志,包含線程池名稱、任務ID、耗時等信息:
public class TraceableTask implements Runnable {private String taskId;private Runnable task;private String poolName;public TraceableTask(String taskId, Runnable task, String poolName) {this.taskId = taskId;this.task = task;this.poolName = poolName;}@Overridepublic void run() {long start = System.currentTimeMillis();log.info("任務{}開始執行,線程池:{},線程:{}", taskId, poolName, Thread.currentThread().getName());try {task.run();log.info("任務{}執行完成,耗時:{}ms", taskId, System.currentTimeMillis() - start);} catch (Exception e) {log.error("任務{}執行異常,耗時:{}ms", taskId, System.currentTimeMillis() - start, e);}}
}// 使用可追蹤任務
executor.submit(new TraceableTask("ORDER123", () -> processOrder(), "orderExecutor"));說明:清晰的日志可快速定位任務執行鏈路,當系統出現延遲時,能立即判斷是線程池隊列積壓還是任務本身耗時過長。
9.3 漸進式落地:從“能用”到“好用”
線程池的優化需分階段進行,與業務增長同步:
| 階段 | 業務規模 | 線程池方案 | 核心目標 |
|---|---|---|---|
| 1. 初創期 | 低并發(<100 QPS) | Executors工具類創建線程池 | 快速上線,驗證業務 |
| 2. 成長期 | 中并發(100-1000 QPS) | 自定義線程池(有界隊列+合理拒絕策略)+ 基礎監控 | 保證穩定性,解決明顯瓶頸 |
| 3. 成熟期 | 高并發(>1000 QPS) | 動態線程池+熔斷降級+多池隔離+完善監控 | 提升資源利用率,應對流量波動 |
十、線程池與函數式編程的結合
Java 8引入的函數式編程(Lambda表達式、Stream API、CompletableFuture)為線程池的使用提供了更簡潔、靈活的方式,減少模板代碼,提升開發效率。
10.1 Lambda表達式:簡化任務定義
傳統線程池使用Runnable或Callable時需創建匿名內部類,代碼冗長;Lambda表達式可簡化任務定義,使代碼更緊湊。
示例:
- 傳統方式:
executor.submit(new Runnable() {@Overridepublic void run() {System.out.println("執行任務");}
});- Lambda方式:
executor.submit(() -> System.out.println("執行任務")); // 一行代碼完成任務提交說明:Lambda表達式自動推斷函數式接口(Runnable的run()方法),省去匿名類定義,使代碼更聚焦于任務邏輯。
10.2 CompletableFuture:異步任務鏈式調用
CompletableFuture是Java 8新增的異步編程工具,可與線程池結合實現任務的鏈式調用、結果聚合、異常處理等,簡化復雜并發場景的代碼。
10.2.1 基礎用法:異步任務提交
CompletableFuture.supplyAsync(有返回值)和runAsync(無返回值)可直接指定線程池:
ExecutorService executor = Executors.newFixedThreadPool(5);// 有返回值的異步任務
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {// 任務邏輯:模擬查詢商品信息try { Thread.sleep(100); } catch (InterruptedException e) {}return "商品A";
}, executor);// 任務完成后處理結果
future.thenAccept(product -> System.out.println("查詢結果:" + product));// 無返回值的異步任務
CompletableFuture.runAsync(() -> {System.out.println("異步記錄日志");
}, executor);10.2.2 鏈式調用:多任務依賴處理
CompletableFuture提供豐富的鏈式方法,處理任務間的依賴關系(如任務B依賴任務A的結果)。
示例:電商訂單創建流程(查詢商品→計算價格→創建訂單)
ExecutorService executor = Executors.newFixedThreadPool(5);// 1. 查詢商品信息
CompletableFuture<Product> productFuture = CompletableFuture.supplyAsync(() -> {System.out.println("查詢商品信息,線程:" + Thread.currentThread().getName());return new Product("商品A", 100.0); // 模擬查詢結果
}, executor);// 2. 計算價格(依賴商品信息)
CompletableFuture<Double> priceFuture = productFuture.thenApplyAsync(product -> {System.out.println("計算價格,線程:" + Thread.currentThread().getName());double discount = 0.9; // 假設折扣return product.getPrice() * discount;
}, executor);// 3. 創建訂單(依賴價格)
CompletableFuture<Order> orderFuture = priceFuture.thenApplyAsync(price -> {System.out.println("創建訂單,線程:" + Thread.currentThread().getName());return new Order("ORDER123", price);
}, executor);// 4. 處理最終結果
orderFuture.thenAccept(order -> {System.out.println("訂單創建完成:" + order);
});// 等待所有任務完成
orderFuture.join();時序圖:
sequenceDiagramparticipant 主線程participant 線程1(executor)participant 線程2(executor)participant 線程3(executor)主線程->>線程1: 提交查詢商品任務線程1->>線程1: 執行查詢,返回Product線程1-->>線程2: 觸發價格計算任務線程2->>線程2: 計算價格,返回Double線程2-->>線程3: 觸發創建訂單任務線程3->>線程3: 創建訂單,返回Order線程3-->>主線程: 觸發結果處理主線程->>主線程: 輸出訂單信息說明:通過thenApplyAsync實現任務的鏈式調用,每個步驟可指定線程池,任務自動按依賴順序執行,無需手動同步(如Future.get()阻塞)。
10.2.3 結果聚合:多任務并行執行
CompletableFuture.allOf(等待所有任務完成)和anyOf(等待任一任務完成)可聚合多個異步任務的結果。
示例:并行查詢商品和用戶信息,再合并結果
ExecutorService executor = Executors.newFixedThreadPool(5);// 查詢商品
CompletableFuture<Product> productFuture = CompletableFuture.supplyAsync(() -> {System.out.println("查詢商品");return new Product("商品A", 100.0);
}, executor);// 查詢用戶
CompletableFuture<User> userFuture = CompletableFuture.supplyAsync(() -> {System.out.println("查詢用戶");return new User("用戶1");
}, executor);// 等待兩個任務完成后合并結果
CompletableFuture<Void> combinedFuture = CompletableFuture.allOf(productFuture, userFuture).thenRunAsync(() -> {try {Product product = productFuture.get();User user = userFuture.get();System.out.println("合并結果:" + user.getName() + "購買了" + product.getName());} catch (Exception e) {e.printStackTrace();}}, executor);combinedFuture.join();時序圖:
sequenceDiagramparticipant 主線程participant 線程1(executor)participant 線程2(executor)participant 線程3(executor)主線程->>線程1: 提交查詢商品任務主線程->>線程2: 提交查詢用戶任務線程1->>線程1: 執行商品查詢線程2->>線程2: 執行用戶查詢線程1-->>主線程: 商品查詢完成線程2-->>主線程: 用戶查詢完成主線程->>線程3: 提交合并結果任務線程3->>線程3: 合并商品和用戶信息說明:allOf等待所有并行任務完成后再執行合并邏輯,充分利用線程池的并發能力,比串行執行節省時間(總耗時≈最長的單個任務耗時)。
10.2.4 異常處理:鏈式調用中的錯誤傳遞
CompletableFuture提供exceptionally、handle等方法處理任務異常,避免異常在異步鏈路中丟失。
示例:任務異常處理
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {if (true) {throw new RuntimeException("任務執行失敗");}return "成功結果";
}, executor)
.thenApply(result -> "處理:" + result) // 任務異常時,此步驟不執行
.exceptionally(ex -> {System.out.println("捕獲異常:" + ex.getMessage());return "默認結果"; // 異常時返回默認值
});System.out.println(future.join()); // 輸出:默認結果說明:exceptionally相當于異步版的catch,可捕獲鏈路中任意步驟的異常并返回降級結果,保證鏈路不中斷。
10.3 Stream并行流:簡化批量任務處理
Java 8的Stream API支持并行流(parallelStream()),內部使用Fork/Join池(ForkJoinPool.commonPool())實現批量任務的并行處理,適合數據集合的批量處理。
10.3.1 并行流與線程池的關系
- 并行流默認使用公共Fork/Join池,其線程數為
Runtime.getRuntime().availableProcessors() - 1。 - 可通過
ForkJoinPool的submit方法指定自定義線程池執行并行流,避免公共池被占滿。
示例:
// 自定義ForkJoinPool
ForkJoinPool forkJoinPool = new ForkJoinPool(5);// 使用自定義線程池執行并行流
forkJoinPool.submit(() -> {List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);list.parallelStream().map(i -> {System.out.println("處理" + i + ",線程:" + Thread.currentThread().getName());return i * 2;}).collect(Collectors.toList());
}).join();forkJoinPool.shutdown();輸出(線程名為自定義ForkJoinPool的線程):
處理3,線程:ForkJoinPool-1-worker-1
處理5,線程:ForkJoinPool-1-worker-3
處理2,線程:ForkJoinPool-1-worker-2
處理4,線程:ForkJoinPool-1-worker-4
處理1,線程:ForkJoinPool-1-worker-010.3.2 適用場景
并行流適合無狀態、純函數的批量處理(如數據轉換、過濾),不適合包含共享資源修改、I/O操作的場景(可能因線程安全問題或性能不佳)。
示例:并行流處理訂單列表
List<Order> orders = ...; // 1000個訂單
// 并行計算訂單總金額(無狀態操作)
double total = orders.parallelStream().mapToDouble(Order::getAmount).sum();
System.out.println("總金額:" + total);說明:計算總金額是純計算操作(無共享資源修改),并行流可利用多線程加速處理,比串行流效率更高(數據量越大,優勢越明顯)。
10.4 函數式編程的優勢總結
- 代碼簡潔:Lambda表達式、鏈式調用減少模板代碼,提升可讀性。
- 關注點分離:任務邏輯與并發控制(線程池、同步)分離,便于維護。
- 異步鏈路清晰:
CompletableFuture的鏈式調用使任務依賴關系可視化,比嵌套Future.get()更直觀。
十一、總結與展望
線程池作為多線程編程的核心技術,其合理使用能顯著提升系統并發能力,但也伴隨著資源管理、并發沖突等挑戰。本文從基礎概念、核心機制、風險控制、業務結合等維度系統梳理了線程池的知識體系,可總結為以下關鍵點:
11.1 核心結論
- 線程池本質:通過線程復用減少創建/銷毀開銷,通過隊列緩沖任務、拒絕策略保護系統,是平衡資源與性能的工具。
- 配置原則:根據任務類型(I/O/CPU密集)、并發量、響應時間需求配置核心參數(核心線程數、隊列、拒絕策略),無“萬能配置”,需結合業務調優。
- 風險控制:通過資源隔離、監控告警、熔斷降級建立防線,優先保證系統穩定,再追求性能優化。
- 業務結合:線程池需融入業務開發全流程,從需求分析階段識別并發場景,到運維階段動態優化,避免技術與業務脫節。
- 技術融合:結合函數式編程(
CompletableFuture)、設計模式(工廠、策略)可簡化代碼,提升開發效率,但需避免過度設計。
11.2 未來趨勢
- 虛擬線程(Virtual Threads):JDK 21引入的虛擬線程(輕量級線程,由JVM管理,而非OS)可大幅提升并發量(百萬級線程),未來可能部分替代傳統線程池,尤其適合I/O密集型場景。
- 云原生適配:在K8s等容器化環境中,線程池需與容器資源限制(CPU/內存配額)聯動,實現更精細的資源調度。
- AI輔助調優:通過機器學習分析線程池歷史指標(如隊列長度、響應時間),自動推薦最優配置,減少人工調優成本。
11.3 實踐建議
- 從小處著手:新手上手時可從
Executors工具類開始,逐步過渡到自定義線程池,積累調優經驗。 - 重視測試:并發問題隱蔽性強,需通過單元測試、壓力測試驗證線程安全與性能。
- 持續學習:跟進JDK新特性(如虛擬線程)、開源框架(如Netty的EventLoop)的線程管理實踐,拓寬技術視野。
線程池的學習不僅是技術細節的掌握,更是“平衡思維”的培養——在性能與穩定、簡潔與靈活、技術與業務之間找到最優解,這才是并發編程的核心素養。
Java 線程池與多線程并發編程實戰全解析:從異步任務調度到設計模式落地,200 + 核心技巧、避坑指南與業務場景結合 | Honesty Blog






|SVM-拉格朗日乘數法理解)




)




與賽題)


