寫在前面
本系列推文為《R for Data Science (2e)》的中文翻譯版本。所有內容都通過開源免費的方式上傳至Github,歡迎大家參與貢獻,詳細信息見:
Books-zh-cn 項目介紹:
Books-zh-cn:開源免費的中文書籍社區
r4ds-zh-cn Github 地址:
https://github.com/Books-zh-cn/r4ds-zh-cn
r4ds-zh-cn 網站地址:
https://books-zh-cn.github.io/r4ds-zh-cn/
目錄
-
你將學到什么
-
本書的組織方式
-
你不會學習什么
-
先決條件
-
運行 R 代碼
-
致謝
-
版權所有
數據科學是一門令人興奮的學科,它可以讓您將原始數據轉化為容易理解的知識。《R for Data Science》的目標是幫助您學習 R 中最重要的工具,這些工具將使您能夠高效且可重復地進行數據科學分析,并在此過程中獲得一些樂趣😃。閱讀本書后,您將擁有使用 R 的最佳部分來應對各種數據科學挑戰的工具。
你將學到什么
數據科學是一個廣闊的領域,你不可能通過閱讀一本書來掌握它。本書旨在為您在最重要的工具和足夠的知識方面打下堅實的基礎,以便在必要時找到資源以了解更多信息。我們的典型數據科學項目步驟模型類似于 Figure 1。
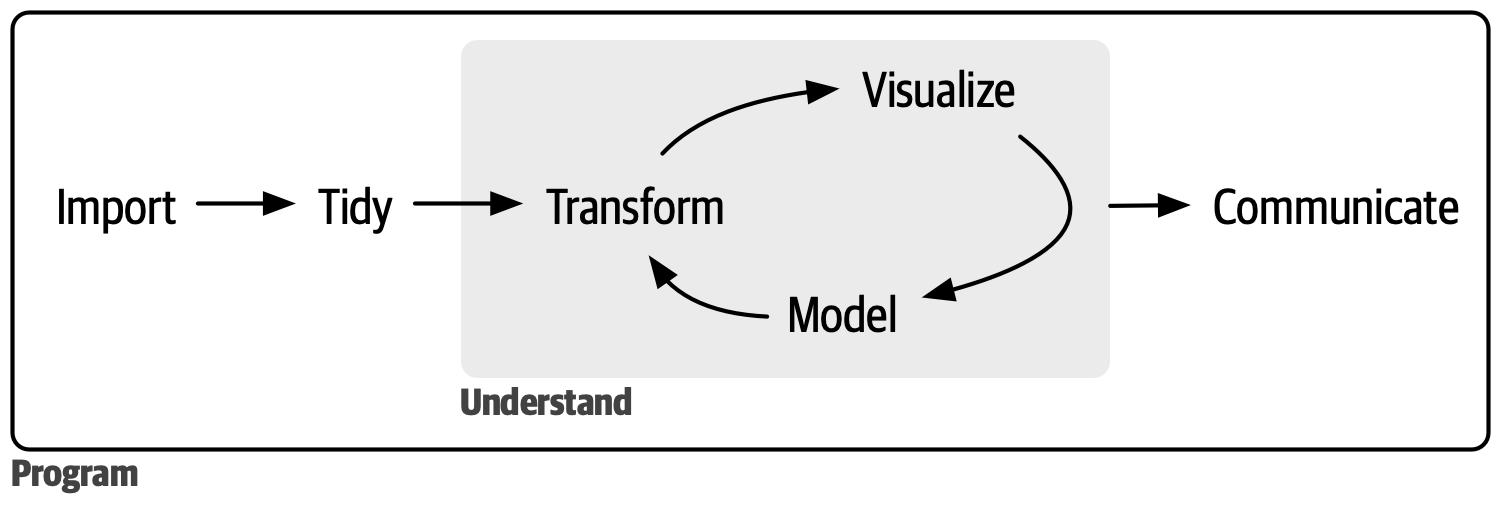
Figure 1: 在我們的數據科學過程模型中,您從數據導入(import)和整理(tidy)開始。接下來,您通過轉換(transform)、可視化(visualize)和建模(model)的迭代循環來了解您的數據。您完成這個過程是通過向其他人傳達(communicate)您的結果。
首先,您必須導入(import)你的數據到 R。這通常意味著您將存儲在文件、數據庫或 Web 應用程序編程接口(API)中的數據加載到 R 中的 data frame 中。如果您無法將數據導入 R,則無法對其進行數據科學處理!
一旦您導入了數據,整理(tidy)它是一個好主意。整理數據意味著以與數據集語義匹配的方式存儲它,使其形式一致。簡而言之,當您的數據整潔時,每一列都是一個變量(variable),每一行都是一個觀察值(observation)。 整潔的數據很重要,因為一致的結構讓您可以專注于回答有關數據的問題,而不必糾結于讓數據適應不同的函數。
一旦您擁有了整潔的數據,下一個常見的步驟就是轉換(transform)它。轉換包括縮小感興趣的觀察范圍(例如一個城市中的所有人或過去一年中的所有數據)、創建現有變量的函數(例如根據距離和時間計算速度)和計算一組摘要統計量(例如計數或平均值)。整理(tidying)和轉換(transforming)一起被稱為梳理(wrangling),因為讓您的數據呈現出自然易于處理的形式通常感覺像一場戰斗!
一旦您擁有了您需要的整潔數據,就有兩個主要的知識生成引擎:可視化(visualization)和建模(modeling)。這兩者具有互補的優缺點,因此任何真正的數據分析都會在它們之間多次迭代。
可視化(Visualization)是一種基本的人類活動。好的可視化會向您展示您沒有預料到的東西或提出關于數據的新問題。好的可視化也可能暗示您提出了錯誤的問題或需要收集不同的數據。可視化可以讓您感到驚訝,但它們并不特別具有可擴展性,因為它們需要人類來解釋。
模型(Models)是可視化的補充工具。一旦您已經使問題足夠精確,就可以使用模型來回答它們。模型本質上是數學或計算工具,因此它們通常具有很好的可擴展性。即使它們沒有,購買更多計算機通常也比購買更多大腦便宜!但是每個模型都有假設,并且根據其本質,模型不能質疑自己的假設。 這意味著模型不能從根本上讓你感到驚訝。
數據科學的最后一步是溝通(communication),這是任何數據分析項目中絕對關鍵的部分。除非您也能將結果傳達給他人,否則無論您的模型和可視化做得多好都沒用。
所有這些工具都圍繞著編程(programming)。編程是一個跨領域的工具,在幾乎每個數據科學項目中都會使用到。您不需要成為專家程序員才能成為成功的數據科學家,但學習更多編程會得到回報,因為成為更好的程序員可以讓您自動化常見任務并更容易解決新問題。
在每個數據科學項目中,您都會使用這些工具,但它們對大多數項目來說還不夠。這里有一個粗略的 80/20 規則:使用本書中將學習到的工具,您可以解決每個項目約 80% 左右的問題,但需要其他工具來解決剩余 20% 左右。在本書中,我們將指引您了解更多資源。
本書的組織方式
數據科學工具的前面描述大致按照您在分析中使用它們的順序組織(當然,您會多次重復它們)。然而,根據我們的經驗,首先學習數據導入(importing)和整理(tidying)是次優的,因為 80% 的時間它是常規和無聊的,而另外 20% 的時間它是奇怪和令人沮喪的。這是開始學習新主題的糟糕地方! 相反,我們將從已經導入和整理過的數據的可視化(visualization)和轉換(transformation)開始。這樣,當您攝取并整理自己的數據時,您的動力將保持高漲,因為您知道痛苦是值得的。
在每一章中,我們都盡量遵循一致的模式:從一些激勵性的例子開始,以便您可以看到更大的圖景,然后深入細節。本書的每個部分都配有練習題,幫助您練習所學內容。盡管跳過練習可能很誘人,但沒有比在真實問題上練習更好的學習方法了。
你不會學習什么
本書沒有涵蓋幾個重要主題。我們認為,始終專注于基本要素非常重要,這樣您才能盡快啟動并運行。 這意味著本書無法涵蓋所有重要主題。
建模
建模對于數據科學非常重要,但這是一個很大的主題,不幸的是,我們沒有足夠的空間來給予它應有的覆蓋。要了解更多關于建模的信息,我們強烈推薦我們的同事 Max Kuhn 和 Julia Silge 撰寫的 Tidy Modeling with R。這本書將教您 tidymodels 系列包,正如您從名稱中猜到的那樣,它們與我們在本書中使用的 tidyverse 包共享許多約定。
大數據
這本書主要關注小型、內存中的數據集。這是一個正確的起點,因為除非您擁有小數據的經驗,否則您無法處理大數據。您將在本書的大部分內容中學習到的工具可以輕松處理數百兆字節的數據,并且只需一點注意,您通常可以使用它們來處理幾千兆字節的數據。我們還將向您展示如何從數據庫和 parquet 文件中獲取數據,這兩者都經常用于存儲大數據。您不一定能夠處理整個數據集,但這不是問題,因為您只需要一個子集或子樣本來回答您感興趣的問題。
如果您經常處理較大的數據(例如 10-100 GB),我們建議您了解更多關于 data.table 的信息。我們在這里不詳細講解是因為它使用與 tidyverse 不同的接口,并且需要您學習一些不同的約定。然而,它非常快速,并且性能回報值得投入一些時間來學習它,如果您正在處理大量數據。
Python, Julia, and friends 在這本書中,你不會學到任何關于 Python、Julia 或任何其他對數據科學有用的編程語言。這并不是因為我們認為這些工具不好。它們不是!而且實際上,大多數數據科學團隊使用多種語言混合,通常至少使用 R 和 Python。但是我們堅信最好一次掌握一個工具,而 R 是一個很好的起點。
先決條件
我們假設您已經知道一些東西,以便您能夠從這本書中獲得最大的收益。您應該具備一般的數字素養,并且如果您已經具備一些基礎編程經驗,那將會很有幫助。如果您以前從未編程過,您可能會發現 Garrett 的 Hands on Programming with R 是本書的一個有價值的補充。
要運行本書中的代碼,您需要四樣東西:R、RStudio、一個名為 tidyverse 的 R 包集合、少量其他包。包(Packages)是可復制 R 代碼的基本單元。它們包括可重用函數(functions)、描述如何使用它們的文檔(documentation)和示例數據。
R
要下載 R,請訪問 CRAN(comprehensive R archive network),https://cloud.r-project.org。每年都會發布一個新的 R 主要版本,每年還會有 2-3 個次要版本。定期更新是個好主意。升級可能有點麻煩,特別是對于需要重新安裝所有包的主要版本,但推遲只會使情況變得更糟。我們建議使用 R 4.2.0 或更高版本來閱讀本書。
RStudio
RStudio 是一個用于 R 編程的集成開發環境(IDE),您可以從 https://posit.co/download/rstudio-desktop/ 下載。RStudio 每年更新幾次,它會自動通知您新版本何時發布,因此無需再次檢查。定期升級以利用最新和最好的功能是個好主意。對于本書,請確保您至少擁有 RStudio 2022.02.0。
當您啟動 RStudio 時,Figure 2,您將在界面中看到兩個關鍵區域:控制臺窗格(console)和輸出窗格(output)。現在,您需要知道的是,在控制臺窗格中輸入 R 代碼并按回車鍵運行它。我們將一路學習!
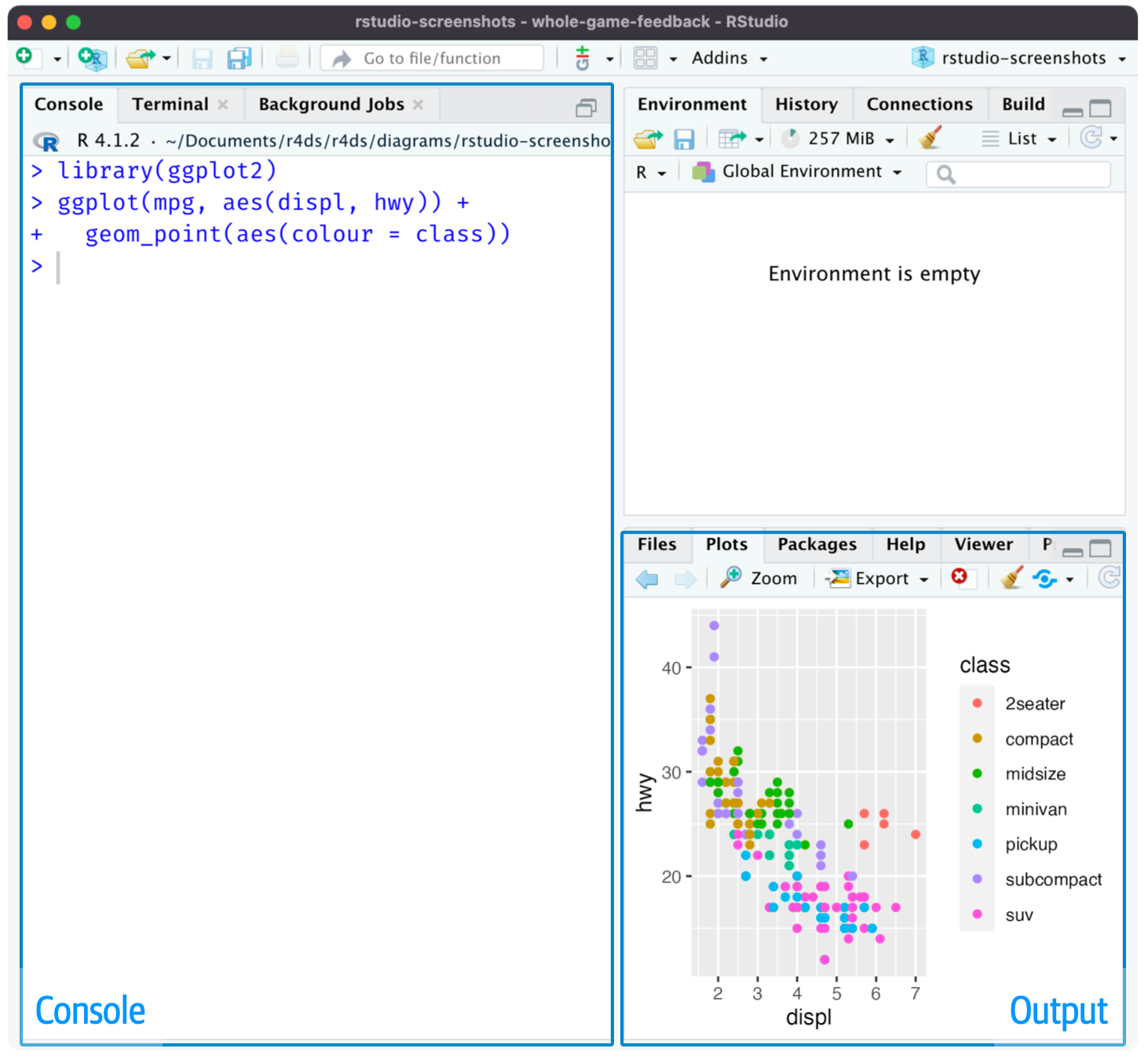
Figure 2: RStudio IDE 有兩個關鍵區域:在左側的控制臺窗格中鍵入 R 代碼,并在右側的輸出窗格中查找繪圖。
The tidyverse
您還需要安裝一些 R 包。R 包(package)是一個函數、數據和文檔的集合,它擴展了基礎 R 的功能。使用包是成功使用 R 的關鍵。您將在本書中學習的大多數包都是所謂的 tidyverse 的一部分。tidyverse 中的所有包都共享一種數據和 R 編程的共同哲學,并且設計為協同工作。
您可以使用一行代碼安裝完整的 tidyverse:
install.packages("tidyverse")
在您的計算機上,在控制臺(console)中輸入該行代碼,然后按回車鍵運行它。R 將從 CRAN 下載包并將它們安裝到您的計算機上。
在您使用 library() 加載包之前,您將無法使用包中的函數、對象或幫助文件。安裝包后,您可以使用 library() 函數加載它:
library(tidyverse)
#>?──?Attaching?core?tidyverse?packages?─────────────────────?tidyverse?2.0.0?──
#>???dplyr?????1.1.4???????readr?????2.1.5
#>???forcats???1.0.0???????stringr???1.5.1
#>???ggplot2???3.5.2???????tibble????3.3.0
#>???lubridate?1.9.4???????tidyr?????1.3.1
#>???purrr?????1.0.4?????
#>?──?Conflicts?───────────────────────────────────────?tidyverse_conflicts()?──
#>???dplyr::filter()?masks?stats::filter()
#>???dplyr::lag()????masks?stats::lag()
#>???Use?the?conflicted?package?(<http://conflicted.r-lib.org/>)?to?force?all?conflicts?to?become?errors
這告訴您 tidyverse 加載了九個包:dplyr、forcats、ggplot2、lubridate、purrr、readr、stringr、tibble、tidyr。這些包被認為是 tidyverse 的核心(core),因為您將在幾乎所有分析中使用它們。
tidyverse 中的包變化相當頻繁。您可以通過運行 tidyverse_update() 查看更新是否可用。
Other packages
有許多其他出色的軟件包不屬于 tidyverse,因為它們解決了不同領域的問題,或者是基于一套不同底層原則設計的。這并不意味著它們更好或更差,只是使它們不同。換句話說,與 tidyverse 相補充的不是混亂的宇宙,而是許多其他相關軟件包的宇宙。隨著您在 R 中處理更多的數據科學項目,您將學習新的軟件包和關于數據的新思維方式。
在本書中,我們將使用許多 tidyverse 之外的軟件包。例如,我們將使用以下軟件包,因為它們為我們提供了有趣的數據集,以便我們在學習 R 的過程中進行實踐:
install.packages(c("arrow",?"babynames",?"curl",?"duckdb",?"gapminder",?"ggrepel",?"ggridges",?"ggthemes",?"hexbin",?"janitor",?"Lahman",?"leaflet",?"maps",?"nycflights13",?"openxlsx",?"palmerpenguins",?"repurrrsive",?"tidymodels",?"writexl"))
我們還將使用一系列其他包作為一次性示例。你現在不需要安裝它們,只要記住每當你看到這樣的報錯時:
library(ggrepel)
#>?Error?in?library(ggrepel)?:?there?is?no?package?called?‘ggrepel’
您需要運行 install.packages("ggrepel") 來安裝包。
運行 R 代碼
上一節向您展示了幾個運行 R 代碼的示例。書中的代碼如下所示:
1?+?2
#>?[1]?3
如果您在本地控制臺(console)中運行相同的代碼,它將如下所示:
>?1?+?2
[1]?3
有兩個主要的區別。在您的控制臺中,您在 > 之后輸入代碼,稱為提示符(prompt);我們在書中沒有顯示提示符。在書中,輸出用 #> 進行注釋;而在您的控制臺中,它直接出現在您的代碼之后。這兩個區別意味著如果您正在使用電子版的書,您可以輕松地將代碼從書中復制并粘貼到控制臺中。
在整本書中,我們使用一套一致的約定來引用代碼:
-
函數(Functions)以代碼字體顯示,并跟隨圓括號,例如
sum()或mean()。 -
其他 R objects(如數據或函數參數)以代碼字體顯示,不帶圓括號,例如
flights或x。 -
有時,為了清楚地表明一個對象來自哪個軟件包,我們會使用軟件包名稱后跟兩個冒號,例如
dplyr::mutate()或nycflights13::flights。這也是有效的 R 代碼。
致謝
這本書不僅僅是 Hadley、Mine、Garrett 的成果,而是與 R 社區中許多人進行的許多對話(面對面和在線)的結果。我們非常感謝與大家進行的所有對話;非常感謝你們!
版權所有
本書的在線版本可在 https://r4ds.hadley.nz 獲得。它將在實體書重印之間繼續發展。本書的源代碼可在 https://github.com/hadley/r4ds 獲取。這本書由 Quarto 提供支持,這使得編寫結合文本和可執行代碼的書籍變得容易。
-
如果您想全面了解 RStudio 的所有功能,請參閱 RStudio 用戶指南,網址為
https://docs.posit.co/ide/user。
--------------- 本章結束 ---------------
本期翻譯貢獻:
-
@TigerZ生信寶庫



---通信版(發送數據 、發送文件、數據轉換、清空發送區、打開/關閉文件),附源碼)
——從原理到實戰,涵蓋 LeetCode 與考研 408 例題)








進程)
功能到minishell)




