目? 錄
一、實驗目的
二、實驗環境
三、實驗內容與完成情況
3.1 Spark讀取文件系統的數據。
3.2 編寫獨立應用程序實現數據去重。
3.3 編寫獨立應用程序實現求平局值問題。
四、問題和解決方法
五、心得體會
一、實驗目的
????????1. 掌握使用 Spark 訪問本地文件和 HDFS 文件的方法。
????????2. 掌握 Spark 應用程序的編寫、編譯和運行方法。
二、實驗環境
????????1. 硬件要求:筆記本電腦一臺
????????2. 軟件要求:VMWare虛擬機、Ubuntu 18.04 64、JDK1.8、Hadoop-3.1.3、Hive-3.1.2、Windows11操作系統、Eclipse、Flink-1.9.1、IntelliJ IDEA、Spark-2.4.0
三、實驗內容與完成情況
3.1 Spark讀取文件系統的數據。
????????在 Linux 系統中安裝 IntelliJ IDEA,然后使用 IntelliJ IDEA 工具開發 WordCount 程序,并打 包成JAR 文件,提交到 Flink 中運行。
????????(1)在 spark-shell 中讀取 Linux 系統本地文件“/home/hadoop/test.txt”,然后統計出文件的行數。
????????①下載spark壓縮包并使用如下語句將對應的壓縮包解壓到/usr/local的文件目錄下:
sudo tar -zxf ./spark-2.4.0-bin-without-hadoop.tgz -C /usr/local
????????②使用如下語句將解壓后的文件夾“spark-2.4.0-bin-without-hadoop”重命名為“spark”:
sudo mv ./spark-2.4.0-bin-without-hadoop/ ./spark

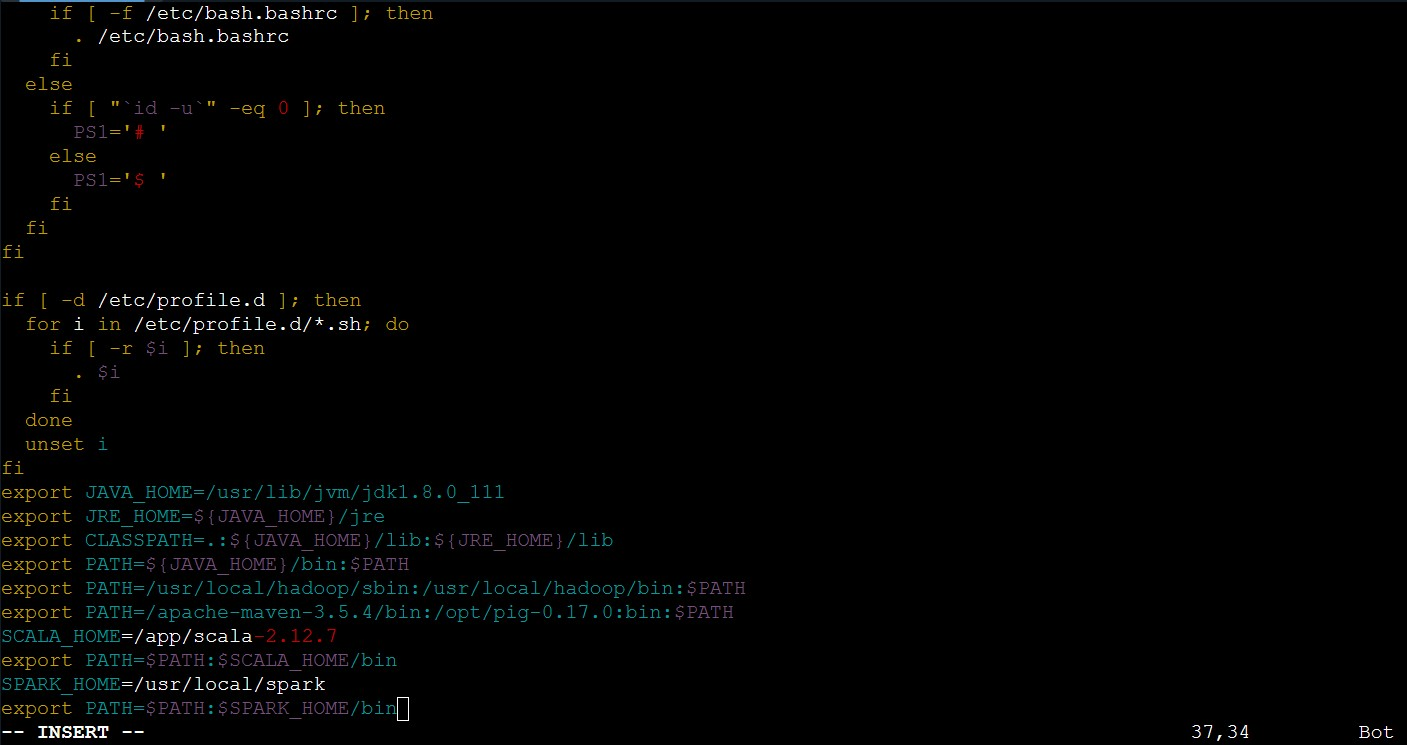
????????③使用如下語句修改spark的配置文件信息:
vim /etc/profile
????????④使用如下語句讓剛修改完的配置信息立即生效:
source /etc/profile

????????⑤使用如下語句復制"spark-env.sh.template"文件的內容并將其存入到"spark-env.sh"文件中:
cp spark-env.sh.template spark-env.sh

????????⑥使用如下語句啟動spark進行實驗操作:
./sbin/start-all.sh

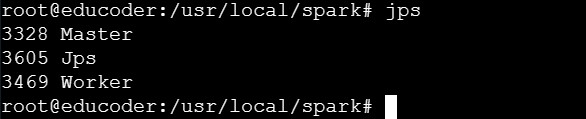
????????⑦使用如下語句進行進程信息查看:
jps
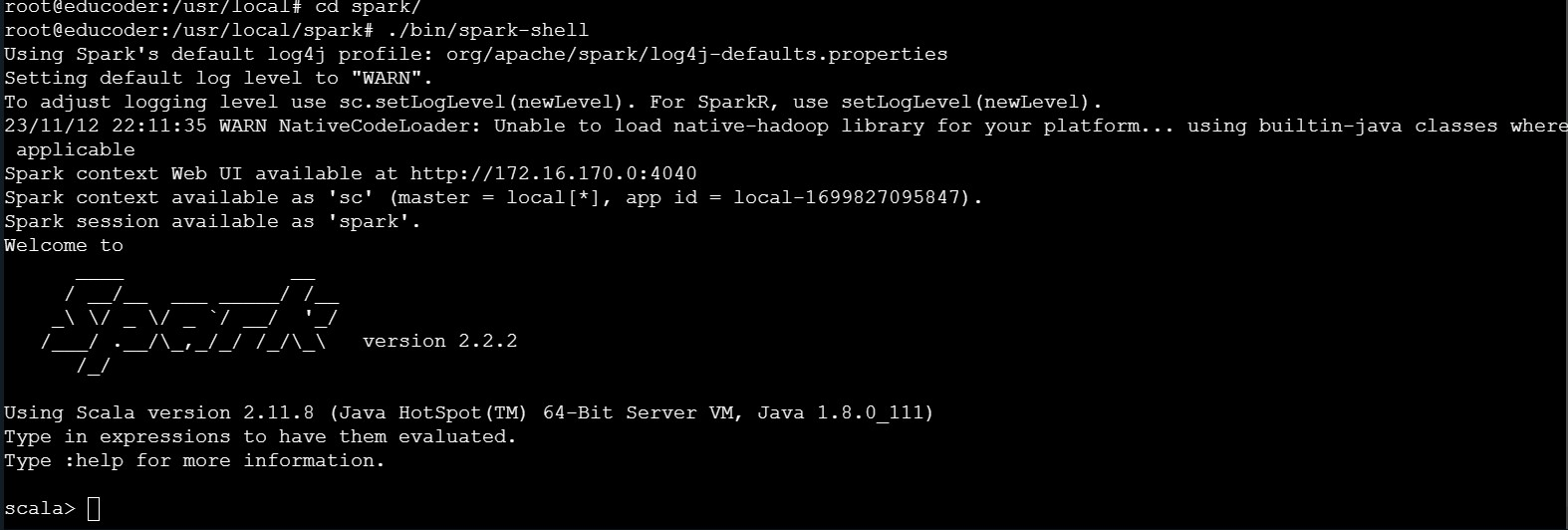
????????⑧使用如下語句完成spark-shell的啟動工作:
./bin/spark-shell
????????⑨使用如下語句讀取 Linux 系統本地文件“/home/hadoop/test.txt”:
cd /home/hadoop/test.txtval textFile=sc.textFile("file:///home/hadoop/test.txt")

????????⑩使用如下語句統計文件“/home/hadoop/test.txt”的行數:
textFile.count()

????????(2)在 spark-shell 中讀取 HDFS 系統文件“/user/hadoop/test.txt”(如果該文件不存在, 請先創建),然后統計出文件的行數。
????????①使用如下語句在HDFS上傳文件"1.txt",上傳完成后并進行查看是否成功完成上傳:
cd /usr/local/hadoophadoop fs -lshadoop fs -put 1.txthadoop fs -ls
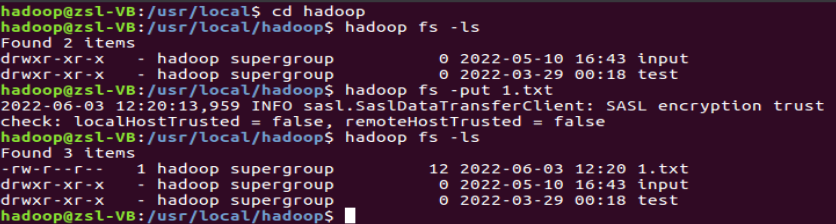
????????②使用如下語句讀取 Linux 系統HDFS系統文件“/user/hadoop/test.txt”:
val textFile=sc.textFile("hdfs://localhost:9000/user/hadoop/test.txt")

????????③使用如下語句統計HDFS系統文件“/user/hadoop/test.txt”的行數:
textFile.count()
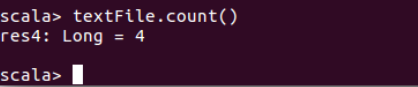
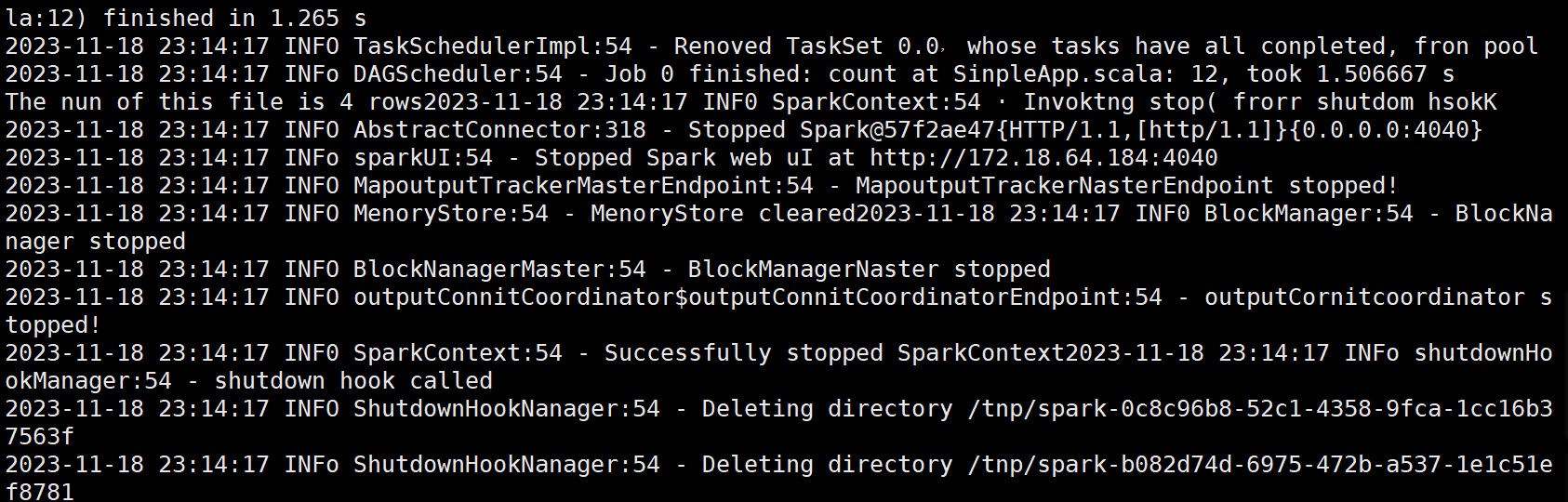
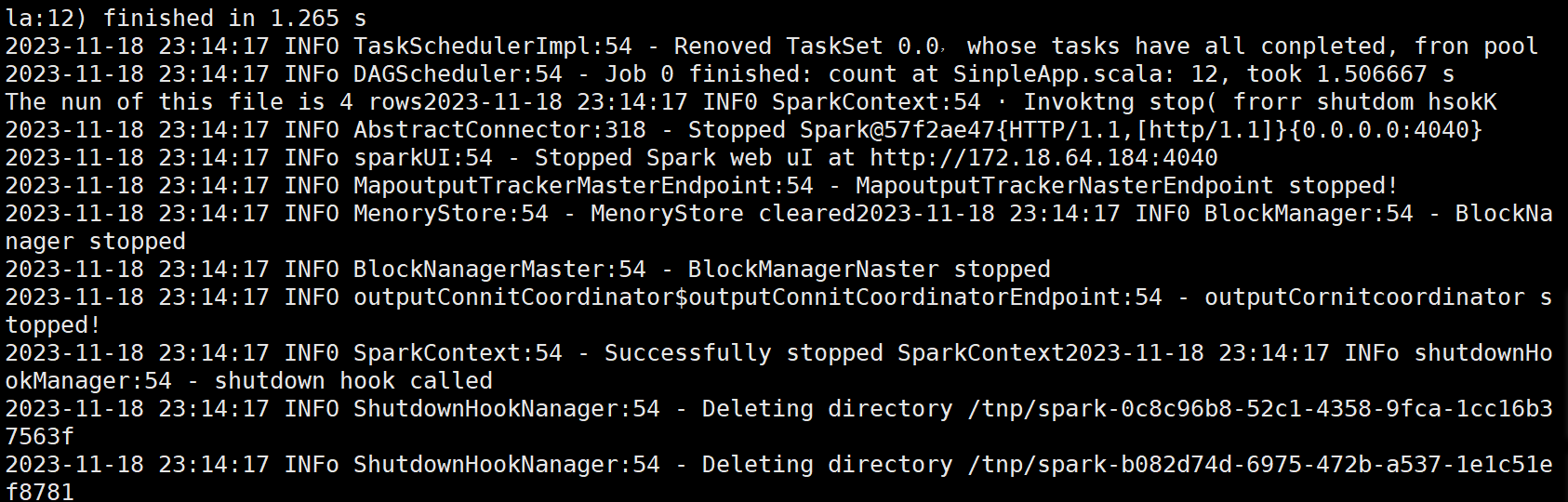
????????(3)編寫獨立應用程序(推薦使用 Scala 語言),讀取 HDFS 系統文件“/user/hadoop/test.txt”(如果該文件不存在,請先創建),然后統計出文件的行數;通過 sbt 工具將整個應用程 序編譯打包成 JAR 包,并將生成的 JAR 包通過 spark-submit 提交到 Spark 中運行命令。
????????①使用hadoop用戶名登錄Linux系統,打開一個終端在Linux終端中執行如下命令創建一個文件夾sparkapp作為應用程序根目錄:
cd ~mkdir ./sparkappmkdir -p ./sparkapp/src/main/scala

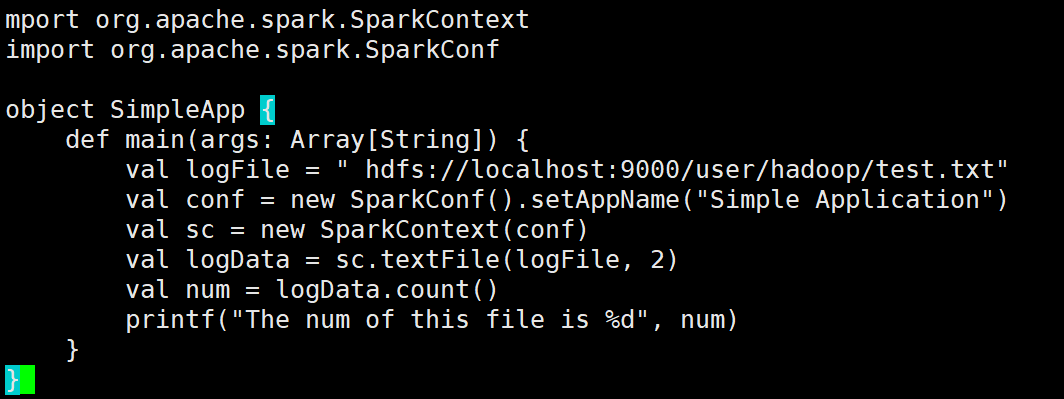
????????②將對應的應用程序代碼存放在應用程序根目錄下的“src/main/scala”目錄下,使用vim編輯器在“~/sparkapp/src/main/scala”下建立一個名為 SimpleApp.scala的Scala代碼文件:
import org.apache.spark.{SparkConf, SparkContext}object SimpleApp {def main(args: Array[String]) {// 正確的路徑:去掉路徑字符串中的多余空格val logFile = "hdfs://localhost:9000/user/hadoop/test.txt"// 設置SparkConfval conf = new SparkConf().setAppName("Simple Application")// 初始化SparkContextval sc = new SparkContext(conf)// 讀取文件并進行計算val logData = sc.textFile(logFile, 2)// 計算并輸出文件的行數val num = logData.count()printf("The num of this file is %d\n", num)// 關閉SparkContextsc.stop()}
}
????????③SimpleApp.scala程序依賴于Spark API,因此需要通過sbt進行編譯打包以后才能運行。 首先需要使用vim編輯器在“~/sparkapp”目錄下新建文件simple.sbt:
cd ~vim ./sparkapp/simple.sbt

????????④simple.sbt文件用于聲明該獨立應用程序的信息以及與 Spark的依賴關系,需要在simple.sbt文件中輸入以下內容:
name := "Simple Project"version := "1.0"scalaVersion := "2.11.12"libraryDependencies += "org.apache.spark" %% "spark-core" % "2.4.0"

????????⑤為了保證sbt能夠正常運行,先執行如下命令檢查整個應用程序的文件結構:
cd sparkapp/find .
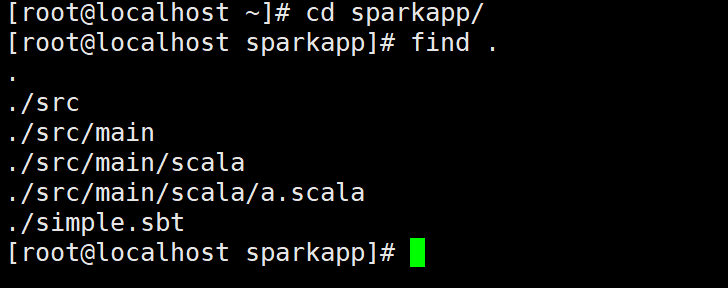
????????⑥通過如下代碼將整個應用程序打包成 JAR:
/usr/local/sbt/sbt package
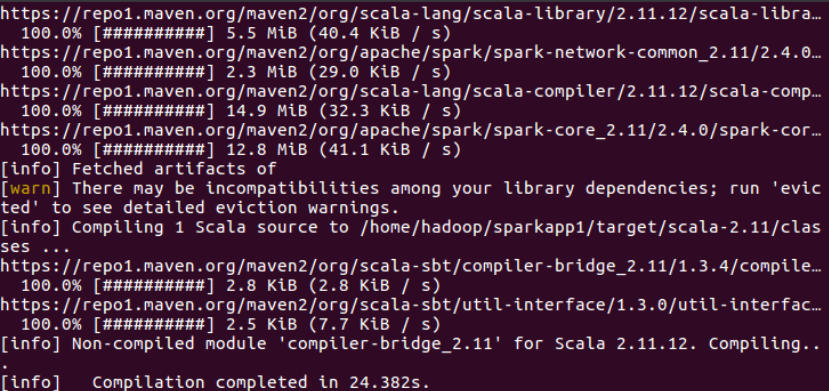
????????⑦生成的JAR包的位置為“~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar”,使用sbt打包得到的應用程序JAR包可以通過 spark-submit 提交到 Spark 中運行:
/usr/local/spark/bin/spark-submit --class "SimpleApp"~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar
3.2 編寫獨立應用程序實現數據去重。
????????對于兩個輸入文件 A 和 B,編寫 Spark 獨立應用程序(推薦使用 Scala 語言),對兩個 文件進行合并,并剔除其中重復的內容,得到一個新文件 C。下面是輸入文件和輸出文件的 一個樣例供參考。
????????輸入文件 A 的樣例如下:
20170101 x20170102 y20170103 x20170104 y20170105 z20170106 z
????????輸入文件 B 的樣例如下:
20170101 y20170102 y20170103 x20170104 z20170105 y
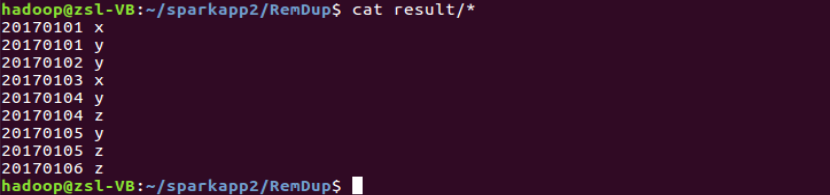
????????根據輸入的文件 A 和 B 合并得到的輸出文件 C 的樣例如下:
20170101 x20170101 y20170102 y20170103 x20170104 y20170104 z20170105 y20170105 z20170106 z
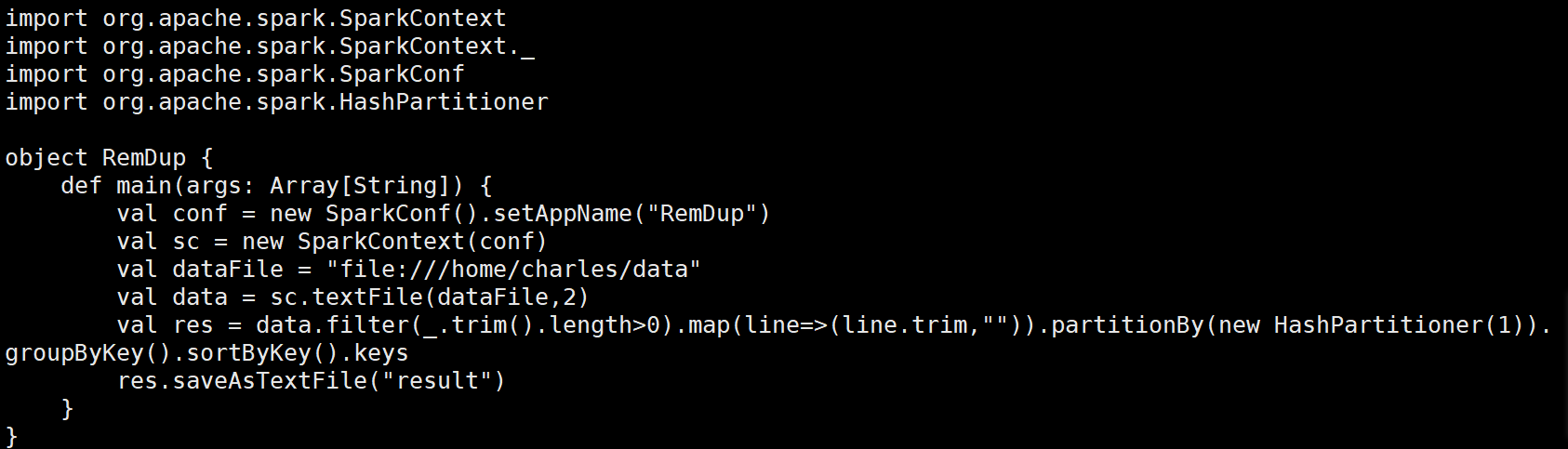
????????(1)在目錄/usr/local/spark/mycode/remdup/src/main/scala下新建一個remdup.scala,然后輸入如下代碼:
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.HashPartitionerobject RemDup {def main(args: Array[String]) {// 初始化SparkConf和SparkContextval conf = new SparkConf().setAppName("RemDup")val sc = new SparkContext(conf)// 輸入文件路徑val dataFile = "file:///home/charles/data"// 讀取文件并創建RDD,設置為2個分區val data = sc.textFile(dataFile, 2)// 處理數據:過濾空行,去除多余空格并進行分區和排序val res = data.filter(_.trim.length > 0) // 過濾空行.map(line => (line.trim, "")) // 每行生成鍵值對(鍵為去除空格的行內容,值為空字符串).partitionBy(new HashPartitioner(1)) // 使用HashPartitioner進行分區.groupByKey() // 根據鍵進行分組.sortByKey() // 按照鍵進行排序.keys // 只保留鍵(去除重復行)// 將結果保存到文件res.saveAsTextFile("result")// 停止SparkContextsc.stop()}
}
????????(2)在目錄/usr/local/spark/mycode/remdup目錄下新建simple.sbt,然后輸入如下代碼:
name := "Simple Project"version := "1.0"scalaVersion := "2.11.12"libraryDependencies += "org.apache.spark" %% "spark-core" % "2.4.0"

????????(3)在目錄/usr/local/spark/mycode/remdup下執行如下命令打包程序:
sudo /usr/local/sbt/sbt package

????????(4)最后在目錄/usr/local/spark/mycode/remdup下執行如下命令提交程序,在目錄/usr/local/spark/mycode/remdup/result下即可得到結果文件:
/usr/local/spark/bin/spark-submit --class "RemDup"/usr/local/spark/mycode/remdup/target/scala-2.11/simple-project_2.11-1.0.jar
3.3 編寫獨立應用程序實現求平局值問題。
????????每個輸入文件表示班級學生某個學科的成績,每行內容由兩個字段組成,第一個是學生 名字,第二個是學生的成績;編寫 Spark 獨立應用程序求出所有學生的平均成績,并輸出到 一個新文件中。下面是輸入文件和輸出文件的一個樣例供參考。
????????Algorithm 成績:
小明 92小紅 87小新 82小麗 90
????????Database 成績:
小明 95小紅 81小新 89小麗 85
????????Python 成績:
小明 82小紅 83小新 94小麗 91
????????平均成績如下:
(小紅,83.67)(小新,88.33)(小明,89.67)(小麗,88.67)
????????(1)在目錄/usr/local/spark/mycode/avgscore/src/main/scala下新建一個avgscore.scala,然后輸入如下代碼:
import org.apache.spark.{SparkConf, SparkContext}
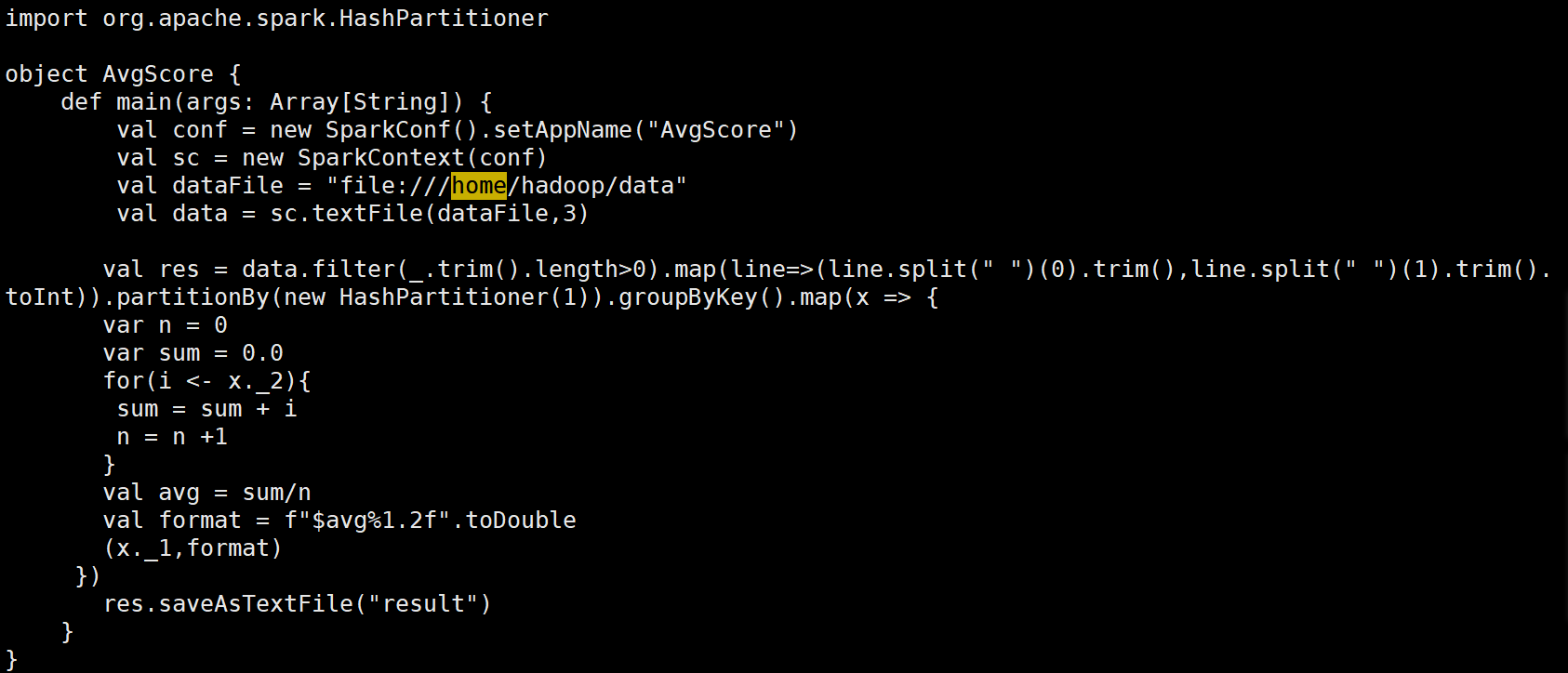
import org.apache.spark.HashPartitionerobject AvgScore {def main(args: Array[String]) {// 初始化SparkConf和SparkContextval conf = new SparkConf().setAppName("AvgScore")val sc = new SparkContext(conf)// 輸入文件路徑val dataFile = "file:///home/hadoop/data"// 讀取文件并創建RDD,設置為3個分區val data = sc.textFile(dataFile, 3)// 處理數據:過濾空行,拆分數據并轉為鍵值對val res = data.filter(_.trim.length > 0) // 過濾空行.map(line => {val parts = line.split(" ")(parts(0).trim, parts(1).trim.toInt) // 鍵為學生名字,值為成績}).partitionBy(new HashPartitioner(1)) // 使用HashPartitioner進行分區.groupByKey() // 根據鍵(學生名字)進行分組.map(x => {var n = 0var sum = 0.0// 計算每個學生的總成績和數量for (i <- x._2) {sum += in += 1}// 計算平均成績val avg = sum / n// 格式化平均成績到兩位小數val format = f"$avg%1.2f"(x._1, format) // 返回學生名字和格式化后的平均成績})// 將結果保存到文件res.saveAsTextFile("result")// 停止SparkContextsc.stop()}
}
????????(2)在目錄/usr/local/spark/mycode/avgscore目錄下新建simple.sbt,然后輸入如下代碼:
name := "Simple Project"version := "1.0"scalaVersion := "2.11.12"libraryDependencies += "org.apache.spark" %% "spark-core" % "2.4.0"

????????(3)在目錄/usr/local/spark/mycode/avgscore下執行如下命令打包程序:
sudo /usr/local/sbt/sbt package

????????(4)最后在目錄/usr/local/spark/mycode/avgscore下執行下面命令提交程序,在目錄/usr/local/spark/mycode/avgscore/result下即可得到結果文件:
/usr/local/spark/bin/spark-submit --class "AvgScore"/usr/local/spark/mycode/avgscore/target/scala-2.11/simple-project_2.11-1.0.jar

四、問題和解決方法
????????1. 實驗問題:Spark的配置可能變得很復雜,尤其是當涉及到不同的集群管理器、存儲系統和應用需求時。
解決方法:仔細閱讀Spark官方文檔,并理解各種配置選項含義,根據應用需求和集群環境,選擇正確配置選項并進行適當調整。
????????2. 實驗問題:在Spark實驗中,數據清洗、轉換和聚合較為繁瑣。
解決方法:使用Spark提供的豐富數據處理功能,例如DataFrame API和Transformations、Actions操作,通過使用這些功能,可以輕松地處理數據并對其進行各種操作。
????????3. 實驗問題:用spark讀取本地文件并統計文件內容行數時報出IllegalArgumentException(非法參數異常)。
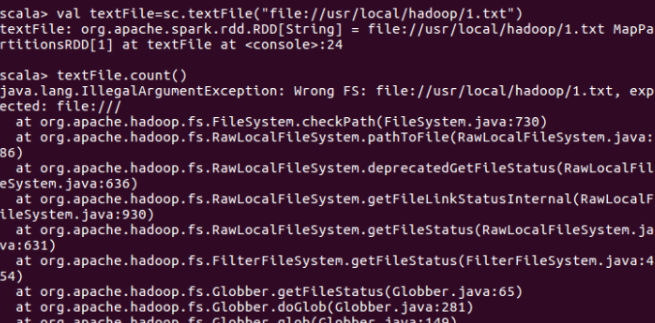
解決方法:由于file:///少打了一個/,spark讀取本地文件的url路徑有問題,正確的應該是valtextFile=sc.textFile("file:///usr/local/hadoop/1.txt")。
????????4. 實驗問題:用spark讀取hdfs文件系統中的文件并統計文件內容行數時報出InvalidInput Exception(無效輸入異常),并提示輸入路徑不存在。
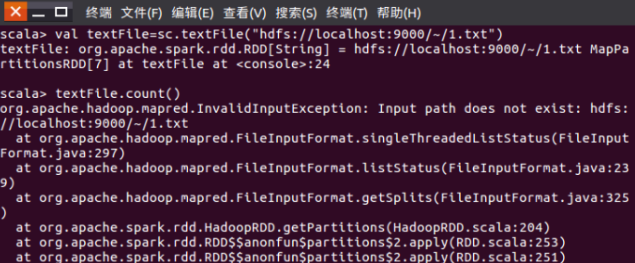
解決方法:讀取hdfs文件的url路徑有問題,hdfs文件系統的根目錄不是~,而應該是/user/hadoop,其中hadoop是用戶名。
????????5. 實驗問題:編寫spark獨立應用程序并實現數據去重時,程序運行報出異常:java.net.URI SyntaxException: Illegal character in scheme name at index 0。
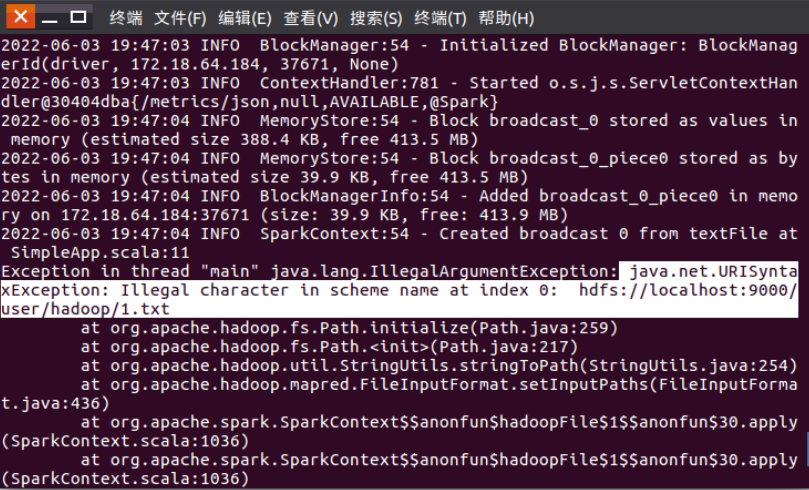
解決方法:代碼中獲取hdfs文件的地址URL前面有空格,就會報錯java.net.URISyntaxException:Illegal character in scheme name at index 0,刪掉空格就好了。
????????6. 實驗問題:隨著Spark版本更新,一些功能和API會發生變化,導致與舊版本不兼容。
解決方法:了解Spark版本之間差異并適應新API和功能通過仔細閱讀官方文檔并參考示例代碼,可以更好地適應新版本Spark并利用其提供的新功能。
????????7. 實驗問題:在Spark應用程序運行過程中,對其進行監控和調試是一項重要任務會面臨日志分析困難、任務跟蹤和性能分析等。
解決方法:使用Spark提供的監控工具和API,例如Spark UI、Event Tracker和Profiler等,通過這些工具和API,可以實時監控Spark應用程序狀態、跟蹤任務執行過程并分析性能瓶頸等。
五、心得體會
????????1、在這次實驗中我深刻體會到了數據去重的重要性,在處理和分析大規模數據時,數據去重能夠避免重復數據的干擾,提高數據的質量和準確性。例如在分析用戶行為或銷售數據時,如果存在大量的重復數據,將會對結果產生誤導。通過使用Spark的distinct()函數可以輕松地實現數據去重,并且在處理大規模數據時,去重操作能夠顯著提高計算效率和結果質量。此外數據去重還可以應用于數據清洗和預處理階段,在數據預處理時需要刪除無效、重復和不完整的數據,以便進行后續的數據分析和挖掘。通過使用Spark的distinct()函數可以快速地去除重復數據,并且對數據進行清洗和預處理,以便更好地探索和分析數據的規律和信息。
????????2、Spark是一個開源的大規模數據處理工具,具有高效、可擴展和易用的特點,通過使用Spark可以快速地讀取和處理大量數據,并且使用豐富的轉換和操作來分析和挖掘數據中的規律和信息。DataFrame提供了一種以表格形式組織數據的結構,可以方便地處理各種類型的數據。在處理和分析數據時,Spark提供了豐富的轉換和操作,例如可以使用map()函數對數據進行轉換,使用filter()函數對數據進行篩選,使用reduceByKey()函數對數據進行聚合操作。
????????3、使用Spark的read()函數來讀取不同格式的數據,使用DataFrame API提供的各種函數對數據進行處理和分析,使用select()函數選擇指定的列進行輸出,使用where()函數對數據進行篩選,使用groupBy()函數對數據進行分組和聚合操作,還可以使用DataFrame API提供的統計函數來計算數據的統計信息,如平均值、標準差、計數等。
????????4、合理地設置Spark的配置參數,以提高計算效率和減少資源浪費,選擇合適的轉換和操作來處理和分析數據以確保結果的準確性和可靠性。在分布式計算中,某些鍵值對的出現頻率可能遠高于其他鍵值對,導致數據分布不均衡,這會引發集群中的負載傾斜問題,影響計算性能和結果質量。為了避免數據傾斜對計算性能的影響,可以對數據進行預處理或使用應對數據傾斜的算法來解決問題。
????????5、DataFrame API提供了豐富的統計和分析函數,可以方便地對數據進行分組、聚合、過濾和排序等操作,通過使用DataFrame API可以快速地獲得數據的統計信息和分布情況,并且對數據進行更深入的挖掘和分析。可以使用groupBy()函數對數據進行分組操作,然后使用agg()函數對分組后的數據進行聚合操作。使用window()函數對數據進行窗口分析,以便更好地探索數據的趨勢和規律,窗口函數可以用于計算滑動平均值、累計和等動態變化的數據指標。
????????6、使用Spark進行數據處理具有高效處理大規模數據、簡單易用的API、靈活的數據處理方式、高效的資源利用率、穩定的計算性能等優點,這些優點使得Spark成為目前大規模數據處理領域中備受關注和常用的工具之一。





進程)
功能到minishell)











:TCP的粘包問題以及異常情況處理)
