一.網絡爬蟲庫
網絡爬蟲通俗來講就是使用代碼將HTML網頁的內容下載到本地的過程。爬取網頁主要是為了獲取網之間需要中的關鍵信息,例如網頁中的數據、圖片、視頻等。
?urllib庫:是Python自帶的標準庫,無須下載、安裝即可直接使用。urllib庫中包含大量的爬蟲功能,但其代碼編寫略微復雜。?? ?
requests庫:是Python的第三方庫,需要下載、安裝之后才能使用。由于requests庫是在urllib軍的基礎上建立的,它包含urllib庫的功能,這使得requests庫中的函數和方法的使用更加友好,因此requests庫使起來更加簡潔、方便。
scrapy庫:是Python的第三方庫,需要下載、安裝之后才能使用。scrapy庫是一個適用于專業應用程序允許用戶開發的網絡爬蟲庫。scrapy庫集合了爬蟲的框架,通過框架可創建一個專業爬蟲系統。
selenium庫:是Python的第三方庫,需要下載、安裝后才能使用。selenium庫可用于驅動計算機中的消覽器執行相關命令,而無須用戶手動操作。常用于自動驅動瀏覽器實現辦公自動化和Web應用程序測試。
二.requests庫和網頁源碼
1.requests庫的安裝
在命令提示符下執行以下命令:
pip install requests安裝完后可以使用命令查看庫信息:
pip show requests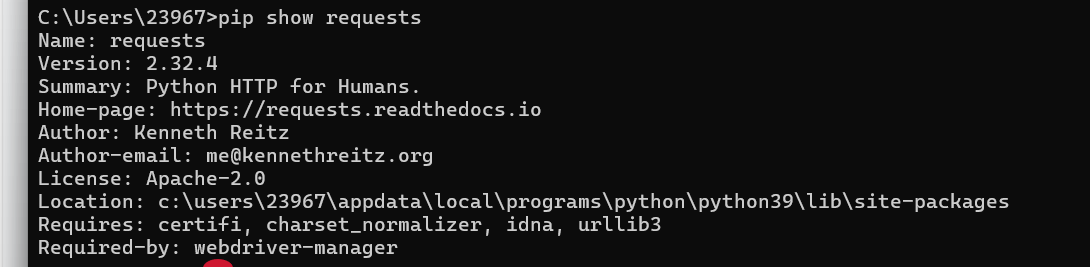
?2.網頁源碼
用戶在使用瀏覽器訪間網頁時,往往會忽視網頁的源代碼,而獲取網頁中的信息需要從源代碼出發。例如使用瀏覽器打開首頁,在網頁空白處單擊鼠標右鍵,選擇快捷菜單中的‘查看源碼’。

?網頁中的源代碼形式與HTML代碼形式基本相同,我們可嘗試閱讀網頁中的源代碼通過源代碼可以輕松地獲取網頁中的文字、圖片、視頻等信息,還可以獲取圖片或視頻文件的url并將文件下載到本地。而一個網頁除了HTML代碼還包含JawaScript腳本語言代碼,JavaScript腳本語言使得瀏覽器可以解析和渲染網頁源代碼,使得用戶可以閱覽到圖形界面,而不是閱讀純文本代碼。網頁中有大量數據是包含會在JavaScript腳本語言代碼中的,而通過查看源代碼的方式是無法獲取這些數據的。網頁源代碼中是無法找到的,但可以通過檢查(在網頁空白處單擊鼠標右鍵,選擇快捷菜單中的檢查選項)找到相應的信息
?三.獲取網頁資源
requests庫具有獲取網頁內容和向網頁中提交信息的功能。
1.get()函數
在requests庫中獲取HTML網頁內容的方法是使用get()函數。其使用形式如下:?
get(url,params=None,**kwargs)參數url:表示需要獲取的HTML網址(也稱為url)。
參數params:表示可選參數,以字典的形式發送信息,當需要向網頁中提交查詢信息時使用。
參數**kwargs:表示請求采用的可選參數。
返回值:返回一個由類Response創建的對象。類Response位于requests庫的models.py文件中。
import requests
r = requests.get('https://www.ptpress.com.cn/')
print(r.text)
?2.get()搜索信息
當在網頁中搜索人民郵電出版社的某些指定信息時,輸入關鍵詞“Excel”時,從搜索結果網頁中可以看到當前頁面的網址為https://www.ptpress.com.cn/search?keyword=excel.其中https://www.ptpress.com.cn/為官網主頁,search表示搜索,keyword表示搜索的關鍵網(這里為?excel,表示需要搜索的關鍵詞為“excel”),“?”用于分隔search和keyword.在其他網頁中搜索也有與以上類似的效果,search或keyword可能會用其他字符表示,但基本形式是相同的。
import requests
r = requests.get('https://www.ptpress.com.cn/search?keyword=excel')
print(r.text)3.get()添加信息
get()函數中第2個參數params會以字典的形式在url后自動添加信息,需要提前將params定義為字典。示例代碼:
import requests
info ={'keyword':'excel' }
r = requests.get('https://www.ptpress.com.cn/search',params=info)
print(r.url)
print(r.text)第2行代碼建立字典info,包含一個鍵值對。
第3行代碼使用get()函數獲取網頁,由于get()中包含參數params,因此系統會自動在url后添加字典信息,形式為https://www.ptpress.com.cn/search?keyword=excel,該使用形式便于靈活設定需要搜索的信息,即可以添加或刪除字典信息。
第4行代碼輸出返回的Response對象中的url,即獲取網頁的url
4.返回Response對象
通過get()函數獲取HTML網頁內容后,由于網頁的多樣性,通常還需要對網頁返回的Response對象進行設置。Response屬性:
Response包含的屬性有status_code、headers、url、encoding、cookies等。
status_code(狀態碼):當獲取一個HTML網頁時,網頁所在的服務器會返回一個狀態碼,表明本次獲取網頁的狀態。例如訪問人民郵電出版社官網,當使用get()函數發出請求時,人民郵電出版社官網的服務器接收到請求信息后,會先判斷請求信息是否合理,如果請求合理則返回狀態碼200和網頁信息;如果請求不合理則返回一個異常狀態碼。
import requests
r = requests.get('https://www.ptpress.com.cn')
print(r.status_code)
if r.status_code==200:print(r.text)
else:print('本次訪問失敗')第3行代碼輸出Response對象返回的狀態碼。
第4行代碼用于判斷狀態碼是否為200,如果為200,則輸出獲取的網頁內容,否則表明訪問存在異常。
headers(響應頭):服務器返回的附加信息,主要包括服務器傳遞的數據類型、使用的壓縮方法、語言、服務器的信息、響應該請求的時間等。
url: 響應的最終url位置。
encoding:訪問r.text時使用的編碼。
cookies:服務器返回的文件。這是服務器為辨別用戶身份,對用戶操作進行會話跟蹤而存儲在用戶本地終端數據上的數據。
5.設置編碼
當訪問一個網頁時,如果獲取的內容是亂碼,這是由網頁讀取編碼錯誤導致的,可以通過設置requests.get(url)返回的Response對象的encoding='utf'-8來修改Response對象.text'文本內容的編碼方式。同時Response對象中提供了apparent_encoding()方法來自動識別網頁的編碼方式,不過由于此方法是由機器自動識別,因此可能會存在識別錯誤的情況。
如果要設置自動識別網頁的編碼方式,可以使用以下形式:
Response對象.encoding=Response對象.apparent_encoding
import requests
r = requests.get('https://www.baidu.com')
r.encoding = r.apparent_encoding
print(r.text)
6.返回網頁內容
Response對象中返回網頁內容有兩種方法,分別是text()方法和content()方法,其中text方法在前面的內容中有介紹,它是以字符串的形式返回網頁內容。而content()方法是以二進制的形式返回網頁內容常用于直接保存網頁中的媒體文件。
import requests
r = requests.get('https://cdn.ptpress.cn/uploadimg/Material/978-7-115-41359-8/72jpg/41359.jpg')
f2 = open('b.jpg','wb')
f2.write(r.content)
f2.close()第2行代碼使用get()方法訪問了圖片的url
第3行代碼使用open()函數創建了一個'b.jpg'文件,并且設置以二進制寫入的模式。? ? ??
第4行代碼將獲取的url內容以二進制形式寫入文件。
執行代碼后將在相應文件夾中存儲一張圖片,

6.小項目案例:實現處理獲取的網頁信息
?項目描述:使用get()函數獲取HTML網頁源代碼的目的在于讓獲取的信息為用戶所用。
項目任務?:新書快遞-人郵教育社區”網頁中上架了新書現,需要使用requests庫爬取當前網頁中所有新書的書名。
項目實現步驟:
步驟1,通過使用requests庫獲取“新書快遞-人郵教育社區”網頁的全部內容。
步驟2,從網頁中尋找到圖書名,為了確保獲取正確的圖書名,需要提前在網頁源代碼中尋找到圖書名并觀察它們的特點。其步驟為:首先進入網頁的源代碼頁面,其次觀察到所有新上架圖書的書名都在標簽<h4>中,且位于<h4>標簽的<a>標簽中,標簽中還存在屬性title。這些特點在整個HTML網頁源代碼中是獨一無二的。最后設計正則表達式,過濾開頭為title且結尾為</ a></h4>的字符串內容。
項目實現代碼:
import requests
import re
r = requests.get('https://www.ryjiaoyu.com/tag/details/7')
result = re.findall(r'title=(.+?)">(.+?)</a></h4>',r.text)
for i in range(len(result)):print('第',i+1,'本書: ',result[i][1])第3行代碼使用get()函數爬取“新書快遞-人郵教育社區”網頁。
第4行代碼使用正則表達式對r.text(網頁中的內容)進行查找,最終找出滿足正則表達式條件的語句


)








)




![[每日隨題10] DP - 重鏈剖分 - 狀壓DP](http://pic.xiahunao.cn/[每日隨題10] DP - 重鏈剖分 - 狀壓DP)


