SGLang 推理框架核心組件解析:請求、內存與緩存的協同工作
在當今大語言模型(LLM)服務的浪潮中,高效的推理框架是決定服務質量與成本的關鍵。SGLang 作為一個高性能的 LLM 推理和部署庫,其內部精巧的設計確保了高吞吐量和低延遲。為了實現這一目標,SGLang 在其核心調度與內存管理機制中,通過一系列緊密協作的對象來處理用戶請求和優化計算資源,特別是對 KV 緩存的管理。在 SGLang 的調度批次(ScheduleBatch)中,reqs、req_to_token_pool、token_to_kv_pool_allocator 和 tree_cache 這四個關鍵字段,分別代表了從請求到底層緩存管理的不同層面,它們之間的協同關系構成了 SGLang 高效推理的基石。
請求的表示:Req 對象
一切處理始于請求。在 SGLang 中,每一個進入系統的用戶請求都被封裝成一個 Req 對象(位于 managers.schedule_batch.Req)。這個對象是請求在系統內流轉的基本單位,包含了與該請求相關的所有信息,例如請求的唯一標識符(rid)、輸入的文本序列(prompt)、生成的配置參數(如溫度、最大新 token 數)以及請求當前的狀態(如等待中、運行中、已完成)。
在 ScheduleBatch 中,reqs 字段是一個列表,容納了當前批次中所有正在被處理的 Req 對象。調度器根據一定的策略(如先到先服務、最長前綴匹配等)從等待隊列中挑選 Req 對象,將它們組合成一個 ScheduleBatch 進行統一處理。因此,reqs 字段是整個推理流程的入口,后續所有的內存分配和計算都圍繞著這個列表中的請求展開。
兩級內存池:從請求到物理內存的映射
為了高效管理 GPU 內存,尤其是占用巨大的 KV 緩存,SGLang 采用了一種精巧的兩級內存池機制。req_to_token_pool 和 token_to_kv_pool_allocator 正是這一機制的核心體現。
首先是 ReqToTokenPool(請求到 Token 池的映射)。這個組件在 ScheduleBatch 中表現為 req_to_token_pool 字段,其核心作用是建立每個請求(Req)與其包含的 token 在邏輯緩存池中位置的映射關系。它本質上可以理解為一個二維表,第一維由請求的池索引(req_pool_idx)確定,第二維則是該請求內部 token 的序列位置。表中的值是一個邏輯索引(out_cache_loc),指向該 token 在全局 Token 緩存池中的具體位置。通過這種方式,系統無需關心每個請求的具體 token 內容,只需通過索引就能快速定位其緩存信息。
比如下面這個就是一個ScheduleBatch批次有兩個Req請求時的情況(batch_size最大為48,但當前batch_size=2):
req_to_token字段的張量形狀:torch.Size([48, 131076])
{ 'size': 48, 'max_context_len': 131076, 'device': 'cuda', 'req_to_token': tensor([[1, 2, 3, ..., 0, 0, 0],[1, 8, 9, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],...,[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0]], device='cuda:0', dtype=torch.int32), 'free_slots': [2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47]}
接下來是 TokenToKVPoolAllocator(Token 到 KV 緩存池的分配器)。req_to_token_pool 提供的僅僅是邏輯位置,而 token_to_kv_pool_allocator 則負責將這個邏輯位置與 GPU 上的物理內存塊對應起來。它管理著一個巨大的、為所有請求共享的物理 KV 緩存池。當一個 token 需要被存儲時,token_to_kv_pool_allocator 會為其分配具體的內存地址。這個物理緩存池通常是三維或四維的結構,維度包括模型層數、注意力頭數量和頭維度等。當 req_to_token_pool 將一個請求的 token 映射到一個邏輯索引后,token_to_kv_pool_allocator 就利用這個索引,在物理池的相應位置存取實際的 Key-Value 向量數據。
比如上面兩個批次的ScheduleBatch對應的TokenToKVPoolAllocator內容如下:
free_slots字段表示未分配的token緩存,形狀為:torch.Size([154788])
ipdb> batch.token_to_kv_pool_allocator.__dict__
{'size': 154801, 'dtype': torch.float16, 'device': 'cuda', 'page_size': 1,
'free_slots': tensor([ 15, 16, 17, ..., 154800, 154801, 7], device='cuda:0'),
'is_not_in_free_group': True, 'free_group': [],
'_kvcache': <sglang.srt.mem_cache.memory_pool.MHATokenToKVPool object at 0x7f3cdde850d0>}
前綴共享的利器:RadixCache
在多用戶、多請求的服務場景中,不同請求的輸入(prompt)往往有重疊的前綴。例如,多個用戶可能都在進行相似主題的問答。如果能復用這些相同前綴的 KV 緩存,將極大減少重復計算,提升系統吞吐量。這正是 RadixCache(基數緩存,在 ScheduleBatch 中體現為 tree_cache 字段)發揮作用的地方。
RadixCache 采用樹狀結構(Trie Tree 或稱前綴樹)來組織和存儲所有處理過的 token 的 KV 緩存。樹的每條邊代表一個 token ID,從根節點到任意節點的路徑就構成了一個 token 序列(即前綴)。每個節點則存儲著對應 token 的 KV 緩存的邏輯索引(out_cache_loc)。
當一個新的請求進入系統時,SGLang 會利用 RadixCache 查找其輸入序列的最長公共前綴。一旦找到匹配的前綴,該前綴對應的所有 token 的 KV 緩存就可以被直接復用,無需重新計算。系統只需從前綴結束的位置開始進行新的計算。這個過程涉及到與 ReqToTokenPool 和 TokenToKVPoolAllocator 的緊密交互:RadixCache 負責找到可復用的 token 及其邏輯索引,然后更新 req_to_token_pool,將當前請求的相應 token 位置指向這些已存在的邏輯索引。TokenToKVPoolAllocator 則根據這些邏輯索引提供對底層物理內存的訪問。
對于新生成的 token,RadixCache 也會將其插入到樹中,并由 TokenToKVPoolAllocator 為其分配新的緩存空間,從而不斷擴充可供復用的緩存池。
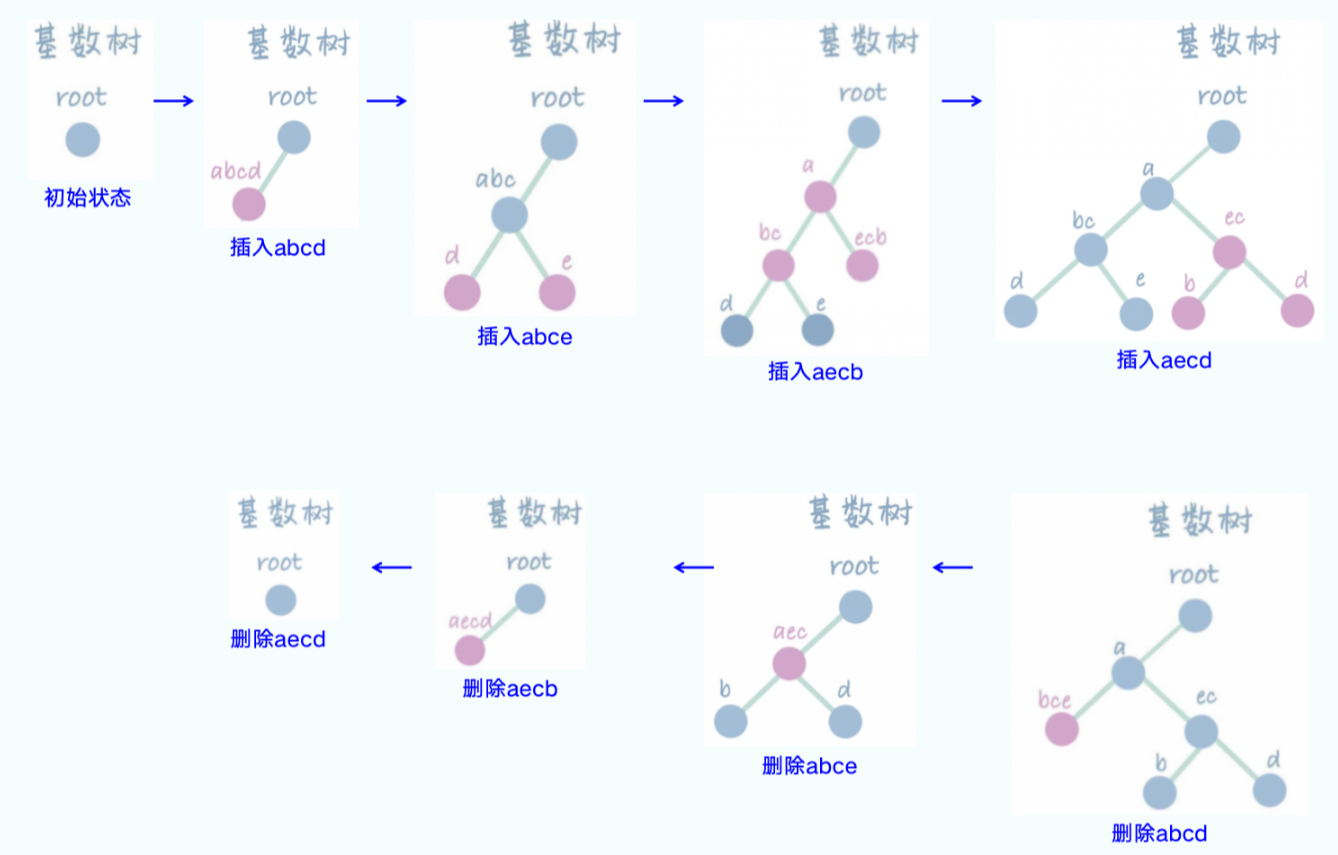
協同工作的流程
這四個組件在 ScheduleBatch 中的關系可以總結為一個清晰的流程:
- 請求聚合:調度器將多個
Req對象收集到ScheduleBatch的reqs字段中。 - 前綴匹配與復用:系統利用
tree_cache(RadixCache) 對reqs列表中的每個請求進行前綴匹配。對于匹配到的公共前綴,直接復用其在RadixCache中已有的 KV 緩存信息。 - 邏輯映射建立:
tree_cache將找到的或新創建的 token 的邏輯緩存索引(out_cache_loc)填充到req_to_token_pool中,從而建立了每個請求與其 token 邏輯緩存位置的映射。 - 物理內存分配與訪問:當模型需要進行注意力計算時,它會通過
req_to_token_pool獲取到所需 token 的邏輯索引,再由token_to_kv_pool_allocator將這些邏輯索引轉換為 GPU 上的物理內存地址,最終讀取或寫入實際的 Key-Value 數據。
通過 Req 對象對請求進行封裝,再經由 RadixCache 實現高效的前綴共享,最后通過 ReqToTokenPool 和 TokenToKVPoolAllocator 這兩級內存池完成從邏輯請求到物理內存的精確映射與管理,SGLang 構建了一個強大而高效的推理引擎。這四個組件環環相扣,共同確保了 GPU 資源的最大化利用和推理服務的高性能表現。



 v6.20.0.24 專業便攜版)







)

)





