溫馨提示:
本篇文章已同步至"AI專題精講" TrOCR: 基于Transformer的光學字符識別方法,使用預訓練模型
摘要
文本識別是文檔數字化中的一個長期研究問題。現有方法通常基于CNN進行圖像理解,基于RNN進行字符級文本生成。此外,通常還需要另一個語言模型作為后處理步驟來提升整體準確率。本文提出了一種端到端的文本識別方法TrOCR,該方法使用預訓練的圖像Transformer和文本Transformer模型,統一采用Transformer架構進行圖像理解和wordpiece級別的文本生成。TrOCR模型結構簡單但效果顯著,可以通過大規模的合成數據進行預訓練,并在人工標注的數據集上進行微調。實驗表明,TrOCR模型在印刷體、手寫體以及自然場景文本識別任務上都優于當前最先進的模型。TrOCR模型與代碼已公開發布,地址為:https://aka.ms/trocr。
1. 引言
光學字符識別(OCR)是將打字、手寫或印刷文本圖像轉換為機器編碼文本的電子或機械過程,其數據來源可以是掃描文檔、文檔照片、場景照片,或圖像上疊加的字幕文本。典型的OCR系統包括兩個主要模塊:文本檢測模塊和文本識別模塊。文本檢測旨在定位文本圖像中的所有文本塊,可以是詞級別或行級別。文本檢測任務通常被視為目標檢測問題,可以使用如YoLOv5和DBNet(Liao et al. 2019)等常規目標檢測模型。而文本識別則旨在理解文本圖像內容,并將視覺信號轉錄為自然語言token。文本識別任務通常被建模為一個encoder-decoder問題,其中現有方法采用基于CNN的encoder進行圖像理解,采用基于RNN的decoder進行文本生成。本文聚焦于文檔圖像的文本識別任務,暫不涉及文本檢測,作為未來工作方向。
近年來文本識別的研究進展(Diaz et al. 2021)表明,采用Transformer(Vaswani et al. 2017)架構可帶來顯著性能提升。然而,現有方法仍以CNN作為backbone,并在其之上構建self-attention機制用于圖像理解。對于decoder,通常使用CTC(Connectionist Temporal Classification,Graves et al. 2006)結合外部字符級語言模型來提高整體準確率。盡管這種encoder-decoder混合方法取得了不錯的成果,但在利用預訓練CV和NLP模型方面仍存在提升空間:
1)現有方法中的網絡參數都是從頭開始在合成或人工標注數據集上訓練,未充分利用大規模預訓練模型;
2)隨著圖像Transformer的日益普及(Dosovitskiy et al. 2021; Touvron et al. 2021),特別是近年來的自監督圖像預訓練方法(Bao, Dong, and Wei 2021),一個自然而然的問題是:是否可以用預訓練的圖像Transformer取代CNN作為backbone,同時將其與預訓練的文本Transformer結合,用于同一個文本識別任務框架中。
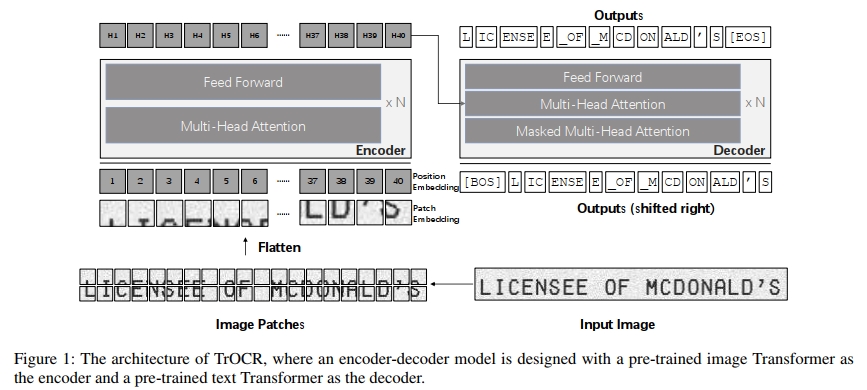
為此,我們提出了TrOCR,一種端到端的基于Transformer的OCR模型,用于結合預訓練的CV和NLP模型進行文本識別,如圖1所示。不同于現有的文本識別模型,TrOCR是一個結構簡單但有效的模型,不依賴CNN作為backbone。我們遵循(Dosovitskiy et al. 2021)的做法,首先將輸入文本圖像調整為384×384大小,然后將圖像劃分為一系列16×16的patch,這些patch作為圖像Transformer的輸入。標準的Transformer架構及其self-attention機制被用于encoder和decoder兩端,最終以wordpiece為單位生成識別文本。為了有效訓練TrOCR模型,其encoder可以用ViT風格的預訓練模型初始化(Dosovitskiy et al. 2021; Touvron et al. 2021; Bao, Dong, and Wei 2021),而decoder則可以用BERT風格的預訓練模型初始化(Devlin et al. 2019; Liu et al. 2019; Dong et al. 2019; Wang et al. 2020b)。因此,TrOCR具有以下三方面優勢:
第一,TrOCR使用了預訓練的圖像Transformer和文本Transformer模型,利用了大規模無標注數據進行圖像理解和語言建模,無需外部語言模型;
第二,TrOCR不依賴任何卷積網絡作為backbone,也不引入圖像特定的歸納偏置,使模型實現和維護都非常簡單;
第三,TrOCR在OCR基準數據集上的實驗結果表明,該模型在印刷體、手寫體及自然場景文本圖像識別方面均能達到當前最優性能,無需復雜的前后處理步驟。
此外,TrOCR也可以輕松擴展至多語言文本識別任務,僅需在decoder端使用多語言預訓練模型并擴展詞表即可。
本文的貢獻總結如下:
- 本文提出了TrOCR,一種結合預訓練CV和NLP模型的端到端Transformer文本識別OCR模型。據我們所知,這是首次在OCR文本識別任務中聯合利用預訓練圖像和文本Transformer。
- TrOCR基于標準的Transformer encoder-decoder模型架構實現,完全不依賴卷積結構,也不需要復雜的前/后處理步驟,性能達到SOTA水平。
- TrOCR模型與代碼已公開發布,地址為:
https://aka.ms/trocr。
2. TrOCR
2.1 模型架構
TrOCR 基于 Transformer 架構構建,包括用于提取視覺特征的 image Transformer 和用于語言建模的 text Transformer。我們在 TrOCR 中采用了標準的 Transformer 編碼器-解碼器結構。編碼器用于獲取圖像 patch 的表示,解碼器則在視覺特征和之前預測的引導下生成 wordpiece 序列。
編碼器
編碼器接收一個輸入圖像 ximg∈R3×H0×W0x_{img} \in \mathbb{R}^{3 \times H_0 \times W_0}ximg?∈R3×H0?×W0?,并將其調整為固定大小 (H,W)(H, W)(H,W)。由于 Transformer 編碼器無法直接處理原始圖像,除非將其轉化為一系列輸入 token,因此編碼器將輸入圖像劃分為 N=HW/P2N = HW/P^2N=HW/P2 個大小固定為 (P,P)(P, P)(P,P) 的正方形 patch,同時保證調整后的圖像寬度 WWW 和高度 HHH 能夠被 patch 大小 PPP 整除。隨后,這些 patch 會被展平為向量并線性投影為 DDD 維向量,也就是 patch embedding。DDD 是貫穿整個 Transformer 各層的隱藏維度大小。
與 ViT(Dosovitskiy et al. 2021)和 DeiT(Touvron et al. 2021)類似,我們保留了通常用于圖像分類任務的特殊 token “[CLS]”。“[CLS]” token 匯聚了所有 patch embedding 的信息,代表整個圖像。同時,在使用 DeiT 預訓練模型初始化編碼器時,我們也保留了輸入序列中的 distillation token,使模型能夠從教師模型中學習。這些 patch embedding 和兩個特殊 token 都根據其絕對位置賦予了可學習的一維位置編碼。
與 CNN 類網絡提取的特征不同,Transformer 模型不具有圖像特有的歸納偏置,而是將圖像作為一系列 patch 進行處理,這使得模型更容易對整個圖像或各個獨立 patch 分配不同的注意力。
Decoder
我們在 TrOCR 中使用原始的 Transformer decoder。標準的 Transformer decoder 同樣由一組結構相同的層堆疊而成,其結構與 encoder 中的層相似,唯一的區別是 decoder 在多頭自注意力和前饋網絡之間插入了“encoder-decoder attention”,以便對 encoder 的輸出施加不同的注意力。在 encoder-decoder attention 模塊中,key 和 value 來自 encoder 的輸出,而 query 來自 decoder 的輸入。此外,decoder 在自注意力中使用 attention masking,以防止其在訓練過程中獲取超過預測階段的信息。由于 decoder 的輸出相較于輸入會右移一個位置,因此 attention mask 需要確保第 i 個位置的輸出只能關注前面的輸出,即位置小于 i 的輸入。
hi=Proj(Emb(Tokeni))h _ { i } = P r o j ( E m b ( T o k e n _ { i } ) ) hi?=Proj(Emb(Tokeni?))
σ(hij)=ehij∑k=1Vehikforj=1,2,…,V\sigma ( h _ { i j } ) = \frac { e ^ { h _ { i j } } } { \sum _ { k = 1 } ^ { V } e ^ { h _ { i k } } } \; \; \; f o r \; j = 1 , 2 , \ldots , V σ(hij?)=∑k=1V?ehik?ehij??forj=1,2,…,V
decoder 的 hidden states 通過一個線性層從模型維度投影到詞表大小 VV 的維度上,然后通過 softmax 函數計算出詞表上的概率分布。我們使用 beam search 獲取最終輸出。
2.2 模型初始化
encoder 和 decoder 均由在大規模有標簽和無標簽數據集上預訓練的公開模型初始化。
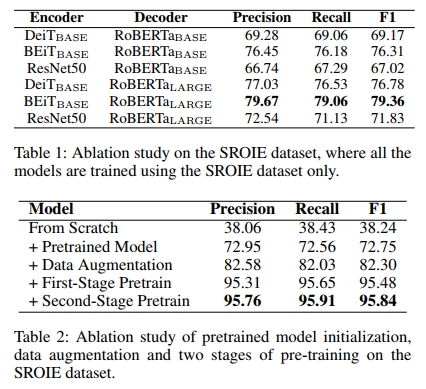
Encoder Initialization
TrOCR 模型中的 encoder 初始化采用了 DeiT(Touvron et al. 2021)和 BEiT(Bao, Dong, and Wei 2021)模型。DeiT 使用 ImageNet(Deng et al. 2009)作為唯一的訓練集來訓練圖像 Transformer。作者嘗試了不同的超參數和數據增強方法,以提升模型在數據利用方面的效率。此外,他們將一個強大的圖像分類器的知識蒸餾到初始 embedding 中的 distillation token,從而在效果上達到了與 CNN 模型競爭的水平。
參考 Masked Language Model 的預訓練任務,BEiT 提出了 Masked Image Modeling 任務用于預訓練圖像 Transformer。每張圖像會被轉化為兩個視角:圖像 patch 和視覺 token。他們使用離散 VAE(Ramesh et al. 2021)的 latent code 將原始圖像 token 化為視覺 token,隨機遮蓋一些圖像 patch,并訓練模型恢復原始的視覺 token。BEiT 的結構與圖像 Transformer 相同,但相比 DeiT 不包含 distillation token。
Decoder Initialization
我們使用 RoBERTa(Liu et al. 2019)和 MiniLM(Wang et al. 2020b)模型來初始化 decoder。總體上,RoBERTa 是對(Devlin et al. 2019)的復現研究,系統評估了許多關鍵超參數和訓練數據規模對性能的影響。基于 BERT,RoBERTa 移除了 next sentence prediction 目標,并動態改變了 Masked Language Model 的掩碼模式。
MiniLM 是對大型預訓練 Transformer 模型的壓縮版本,同時保留了 99% 的性能。與以往使用 soft target 概率或中間表示來指導 student 模型訓練的方法不同,MiniLM 通過蒸餾 teacher 模型最后一層 Transformer 的 self-attention 模塊進行訓練,并引入 teacher assistant 協助蒸餾。
將上述模型加載到 decoder 中時,其結構與目標結構并不完全匹配,因為這些模型本身僅為 Transformer 的 encoder 結構。例如,encoder-decoder attention 層在這些模型中是不存在的。為了解決這個問題,我們通過手動設置參數映射關系,將 RoBERTa 和 MiniLM 模型初始化到 decoder 上,對于缺失的參數則采用隨機初始化。
2.3 任務流程
在本工作中,文本識別任務的流程為:給定 textline 圖像,模型提取視覺特征,并根據圖像和已有上下文預測 wordpiece token。ground truth token 序列以 “[EOS]” token 結尾,表示句子的終止。在訓練過程中,我們將該序列整體向后偏移一個位置,并在開頭添加 “[BOS]” token 表示生成的開始。偏移后的 ground truth 序列被輸入到 decoder 中,其輸出通過與原始 ground truth 序列計算交叉熵損失進行監督。在推理階段,decoder 從 “[BOS]” token 開始,迭代生成輸出,每次將新生成的 token 作為下一步的輸入。
2.4 預訓練
我們在預訓練階段使用文本識別任務,因為該任務能夠使模型同時學習視覺特征提取和語言建模的能力。預訓練過程分為兩個階段,兩個階段所使用的數據集不同。在第一階段,我們合成了一個包含數億條打印 textline 圖像的大規模數據集,并在此數據集上對 TrOCR 模型進行預訓練。在第二階段,我們構建了兩個相對較小的數據集,分別對應于打印文本和手寫文本的下游任務,每個數據集包含數百萬條 textline 圖像。對于 scene text recognition 任務,我們使用已有的、被廣泛采用的合成 scene text 數據集。隨后,我們在這些任務特定的數據集上分別進行第二階段的預訓練,所有模型均由第一階段的模型進行初始化。
2.5 微調
除 scene text recognition 實驗外,預訓練后的 TrOCR 模型會在下游的文本識別任務上進行微調。TrOCR 模型的輸出基于 Byte Pair Encoding (BPE)(Sennrich, Haddow, and Birch 2015)和 SentencePiece(Kudo and Richardson 2018),不依賴于任何任務相關的詞表。
2.6 數據增強
我們利用數據增強來提升預訓練和微調數據的多樣性。對于打印體和手寫體數據集,使用六種圖像變換方式加上保留原圖,總共七種方式,分別為:隨機旋轉(-10 到 10 度)、高斯模糊、圖像膨脹、圖像腐蝕、縮放和加下劃線。我們對每個樣本以相同概率隨機決定采用哪一種圖像變換。對于 scene text 數據集,按照(Atienza 2021)的方法應用 RandAugment(Cubuk et al. 2020),其增強類型包括反色、彎曲、模糊、加噪、變形、旋轉等。
溫馨提示:
閱讀全文請訪問"AI深語解構" TrOCR: 基于Transformer的光學字符識別方法,使用預訓練模型









0718)
實驗操作 ---at和crontab以及系統級別的計劃任務)

和CLIPTextEncodeFlux的區別)
-菜單欄)

![Nuxt 4.0 深度解析:從架構革新到實戰遷移 [特殊字符]](http://pic.xiahunao.cn/Nuxt 4.0 深度解析:從架構革新到實戰遷移 [特殊字符])



---初級版(串口設置、初始化、打開/關閉、狀態顯示),附源碼)