從零開始構建微博爬蟲:實現自動獲取并保存微博內容
前言
在信息爆炸的時代,社交媒體平臺已經成為信息傳播的重要渠道,其中微博作為中國最大的社交媒體平臺之一,包含了大量有價值的信息和數據。對于研究人員、數據分析師或者只是想備份自己微博內容的用戶來說,一個高效可靠的微博爬蟲工具顯得尤為重要。本文將詳細介紹如何從零開始構建一個功能完善的微博爬蟲,支持獲取用戶信息、爬取微博內容并下載圖片。
項目概述
我們開發的微博爬蟲具有以下特點:
- 功能全面:支持爬取用戶基本信息、微博內容和圖片
- 性能優化:實現了請求延遲、自動重試機制,避免被封IP
- 易于使用:提供簡潔的命令行接口,支持多種參數配置
- 數據存儲:支持CSV和JSON兩種格式保存數據
- 容錯機制:完善的錯誤處理,增強爬蟲穩定性
- 自定義配置:通過配置文件靈活調整爬蟲行為
技術選型
在構建微博爬蟲時,我們使用了以下核心技術:
- Python:選擇Python作為開發語言,其豐富的庫和簡潔的語法使爬蟲開發變得簡單高效
- Requests:處理HTTP請求,獲取網頁內容
- Pandas:數據處理和導出CSV格式
- tqdm:提供進度條功能,改善用戶體驗
- lxml:雖然本項目主要使用API接口,但保留XML解析能力以備擴展
- 正則表達式:用于清理HTML標簽,提取純文本內容
系統設計
架構設計
微博爬蟲采用模塊化設計,主要包含以下組件:
- 配置模塊:負責管理爬蟲的各種參數設置
- 爬蟲核心:實現爬取邏輯,包括用戶信息獲取、微博內容爬取等
- 數據處理:清洗和結構化爬取到的數據
- 存儲模塊:將數據導出為不同格式
- 命令行接口:提供友好的用戶交互界面
數據流程
整個爬蟲的數據流程如下:
- 用戶通過命令行指定爬取參數
- 爬蟲初始化并請求用戶信息
- 根據用戶ID獲取微博內容列表
- 解析響應數據,提取微博文本、圖片URL等信息
- 根據需要下載微博圖片
- 將處理后的數據保存到本地文件
實現細節
微博API分析
微博移動版API是我們爬蟲的數據來源。與其使用復雜的HTML解析,直接調用API獲取JSON格式的數據更為高效。我們主要使用了以下API:
- 用戶信息API:
https://m.weibo.cn/api/container/getIndex?type=uid&value={user_id} - 用戶微博列表API:
https://m.weibo.cn/api/container/getIndex?type=uid&value={user_id}&containerid={container_id}&page={page}
這些API返回的JSON數據包含了我們需要的所有信息,大大簡化了爬取過程。
關鍵代碼實現
1. 初始化爬蟲
def __init__(self, cookie=None):"""初始化微博爬蟲:param cookie: 用戶cookie字符串"""self.headers = DEFAULT_HEADERS.copy()if cookie:self.headers['Cookie'] = cookieself.session = requests.Session()self.session.headers.update(self.headers)
使用requests.Session維持會話狀態,提高爬取效率,同時支持傳入cookie增強爬取能力。
2. 獲取用戶信息
def get_user_info(self, user_id):"""獲取用戶基本信息:param user_id: 用戶ID:return: 用戶信息字典"""url = API_URLS['user_info'].format(user_id)try:response = self.session.get(url)if response.status_code == 200:data = response.json()if data['ok'] == 1:user_info = data['data']['userInfo']info = {'id': user_info['id'],'screen_name': user_info['screen_name'],'followers_count': user_info['followers_count'],'follow_count': user_info['follow_count'],'statuses_count': user_info['statuses_count'],'description': user_info['description'],'profile_url': user_info['profile_url']}return inforeturn Noneexcept Exception as e:print(f"獲取用戶信息出錯: {e}")return None
通過API獲取用戶的基本信息,包括昵稱、粉絲數、關注數等。
3. 獲取微博內容
def get_user_weibos(self, user_id, pages=10):"""獲取用戶的微博列表:param user_id: 用戶ID:param pages: 要爬取的頁數:return: 微博列表"""weibos = []container_id = f"{CONTAINER_ID_PREFIX}{user_id}"for page in tqdm(range(1, pages + 1), desc="爬取微博頁數"):url = API_URLS['user_weibo'].format(user_id, container_id, page)# ... 請求和處理邏輯 ...
使用分頁請求獲取多頁微博內容,并添加進度條提升用戶體驗。
4. 圖片下載優化
def _get_large_image_url(self, url):"""將微博圖片URL轉換為大圖URL"""# 常見的微博圖片尺寸標識size_patterns = ['/orj360/', '/orj480/', '/orj960/', '/orj1080/', # 自適應尺寸'/thumb150/', '/thumb180/', '/thumb300/', '/thumb600/', '/thumb720/', # 縮略圖'/mw690/', '/mw1024/', '/mw2048/' # 中等尺寸]# 替換為large大圖result_url = urlfor pattern in size_patterns:if pattern in url:result_url = url.replace(pattern, '/large/')breakreturn result_url
微博圖片URL通常包含尺寸信息,我們通過替換這些標識,獲取原始大圖。
容錯和優化
在實際爬取過程中,我們實現了多種優化機制:
- 請求延遲:在每次請求之間添加延遲,避免請求過快被限制
- 自動重試:下載失敗時自動重試,提高成功率
- 異常處理:捕獲并處理各種異常情況,確保爬蟲穩定運行
- 圖片格式識別:自動識別圖片格式,正確保存文件
- 進度顯示:使用tqdm提供進度條,直觀顯示爬取進度
使用指南
安裝與配置
- 克隆項目并安裝依賴:
git clone https://github.com/yourusername/weibo-spider.git
cd weibo-spider
pip install -r requirements.txt
- 基本使用方法:
python main.py -u 用戶ID
- 高級選項:
# 使用cookie增強爬取能力
python main.py -u 用戶ID -c "你的cookie字符串"# 自定義爬取頁數
python main.py -u 用戶ID -p 20# 下載微博圖片
python main.py -u 用戶ID --download_images# 指定輸出格式
python main.py -u 用戶ID --format json
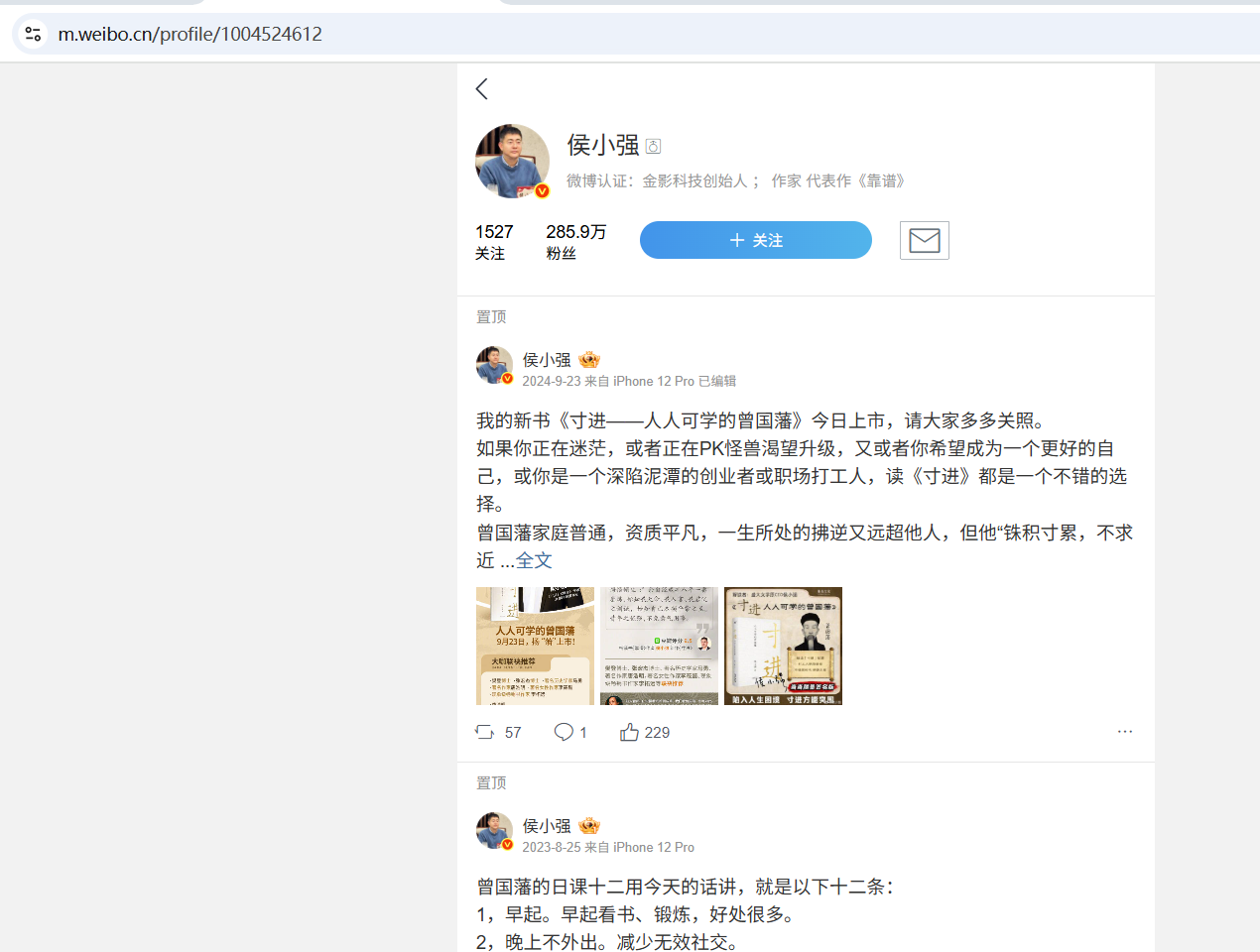
目標網頁:
爬取結果數據:

技術挑戰與解決方案
1. 反爬蟲機制應對
微博有一定的反爬蟲機制,主要體現在請求頻率限制和內容訪問權限上。我們通過以下方式解決:
- 添加合理的請求延遲,避免頻繁請求
- 支持傳入cookie增強權限
- 實現錯誤重試機制,提高穩定性
2. 圖片防盜鏈問題
微博圖片設有防盜鏈機制,直接訪問可能返回403錯誤。解決方案:
- 解析并轉換圖片URL,獲取原始鏈接
- 在請求頭中添加正確的Referer和User-Agent
- 實現多次重試,應對臨時失敗
3. 數據清洗
微博內容包含大量HTML標簽和特殊格式,需要進行清洗:
- 使用正則表達式去除HTML標簽
- 規范化時間格式
- 結構化處理圖片鏈接
未來改進方向
- 增加代理支持:支持代理池輪換,進一步避免IP限制
- 擴展爬取內容:支持爬取評論、轉發等更多內容
- 增加GUI界面:開發圖形界面,提升用戶體驗
- 數據分析功能:集成基礎的統計分析功能
- 多線程優化:實現多線程下載,提高爬取效率
結語
本文詳細介紹了一個功能完善的微博爬蟲的設計與實現過程。通過這個項目,我們不僅實現了微博內容的自動獲取和保存,也學習了爬蟲開發中的各種技術要點和最佳實踐。希望這個項目能對有類似需求的讀者提供幫助和啟發。
微博爬蟲是一個既簡單又有挑戰性的項目,它涉及到網絡請求、數據解析、異常處理等多個方面。通過不斷的優化和改進,我們可以構建出越來越強大的爬蟲工具,為數據分析和研究提供可靠的數據來源。
源碼獲取鏈接:源碼
聲明:本項目僅供學習和研究使用,請勿用于商業目的或違反微博用戶隱私和服務條款的行為。使用本工具時請遵守相關法律法規,尊重他人隱私權。

基礎知識③)





)



)

)





