一、魔塔社區免費服務器如何使用webui微調?
????????一上來我就得先記錄一下,使用魔塔社區的免費服務器的時候,因為沒有提供ssh而導致無法看到webui的遺憾如何解決的問題?

如果點這個鏈接無法彈出微調的webui,則可以在啟動webui的命令之前設置了一些環境變量。
CUDA_VISIBLE_DEVICES=0 GRADIO_SHARE=1 GRADIO_SERVER_PORT=7860 llamafactory-cli webui- 通過?
CUDA_VISIBLE_DEVICES=0,確保程序只使用編號為?0?的 GPU,避免占用其他 GPU 資源。 - 使用?
llamafactory-cli webui?啟動一個基于 Gradio 框架的 Web 用戶界面。 - 通過?
GRADIO_SHARE=1,生成一個公共 URL,允許其他人通過互聯網訪問你的 WebUI。 - 通過?
GRADIO_SERVER_PORT=7860,將 WebUI 的服務端口固定為?7860。?
【注】如果跳出來 Could not create share link. Missing file
那就按照它的提示,去下載這個文件,改名字,換路徑,并改成可執行。
無法創建共享鏈接。缺少文件:`/root/.cache/huggingface/gradio/frpc/frpc_linux_amd64_v0.3`。請檢查您的網絡連接。如果您的殺毒軟件阻止了該文件的下載,也可能導致此問題。您可以按照以下步驟手動安裝:1. 下載此文件:https://cdn-media.huggingface.co/frpc-gradio-0.3/frpc_linux_amd64
2. 將下載的文件重命名為:`frpc_linux_amd64_v0.3`
3. 將文件移動到以下位置:`/root/.cache/huggingface/gradio/frpc`
4. 給這個文件加上執行權限 chmod +x frpc_linux_amd64_v0.3二、llamafactory工程文件目錄里面都有是些什么?
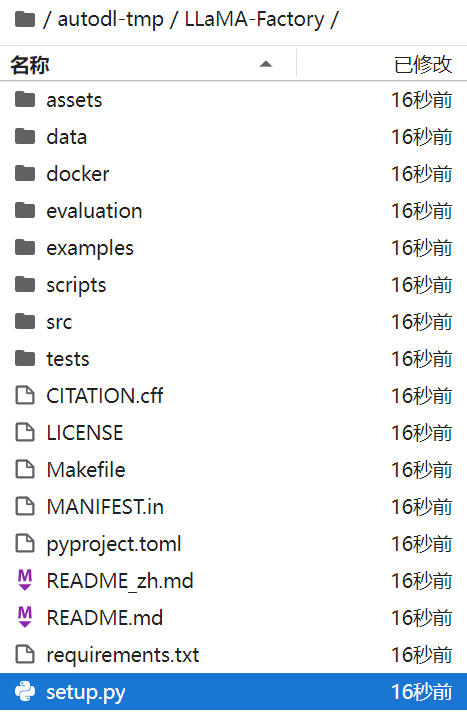
?“LLaMA-Factory”的項目目錄結構。以下是對各個文件夾和文件的簡要說明:
| 文件夾/文件 | 簡要說明 |
|---|---|
| assets | 通常用于存放項目的靜態資源,如圖片、樣式表等。 |
| data | 用于存放數據集或模型訓練所需的數據。 |
| docker | 包含與Docker相關的配置文件和腳本,用于容器化部署。 |
| evaluation | 可能包含評估模型性能的腳本和工具。 |
| examples | 示例代碼或使用案例,幫助用戶了解如何使用該項目。 |
| scripts | 腳本文件,自動化任務或輔助工具。 |
| src | 源代碼文件夾,存放項目的主程序代碼。 |
| tests | 測試文件夾,存放單元測試和其他測試腳本。 |
| CITATION.cff | 引用格式文件,指導如何正確引用此項目。 |
| LICENSE | 許可證文件,說明項目的使用許可條款。 |
| Makefile | 構建文件,定義了編譯和構建項目的規則。 |
| MANIFEST.in | Python打包工具(如setuptools)使用的文件,指定哪些文件應該被包含在發布包中。 |
| pyproject.toml | Python項目配置文件,用于管理項目依賴和構建設置。 |
| README.md | 項目的英文README文件,提供項目介紹和使用指南。 |
| README_zh.md | 項目的中文README文件,提供項目介紹和使用指南。 |
| requirements.txt | 列出項目運行所需的Python包及其版本。 |
| setup.py | Python項目的安裝腳本,用于打包和安裝項目。 |
三、webui里面的微調參數的都是什么意思??
雖然把界面設置成中文,基本都能讀懂,但還是有必要對一些參數做點說明:
| 名字 | 解釋 | 補充 |
| 模型路徑 | 一般是服務器中存放模型的絕對路徑。也可以是huggingface上面的模型標識符。 | 建議自己下載到本地,然后用本地服務器的絕對路徑。 |
| 微調方法 | 常用就2個,LoRA和QLoRA | |
| 檢查點路徑 | 訓練過后保存模型權重的路徑,方便你做增量訓練 | |
| 量化等級 | 具體要損失多少精度,提升多少推理速度,常用有8bit、4bit量化等級 | |
| 量化方法 | 實現量化的具體技術,比如線性量化或非線性量化 | 一般使用bitstandbytes開源量化庫 |
| 對話模板 | 構建提示詞使用的模板,要和你想微調的模型保持一致 | |
| 日志間隔 | 默認是每5輪epoch保存一次日志 | |
| 保存間隔 | 默認是每100epoch保存一次模型權重 | 會在每次保存權重之前,去跑一次驗證 |
| 輸出路徑 | 輸出路徑就是保存你訓練好的LoRA模型參數的路徑。 | 一般是在一個叫做save/模型名字/lora下面,用chekpoint來命名,LoR模型無法單獨使用 |
| 配置路徑 | 配置路徑的意思就是webui設置好的參數,生產一個yaml文件,可以用這個文件去等效的用在命令行中做微調訓練 | 將webui的配置保存成一個yaml |
| 驗證集比例 | 在每一次保存權重之前做驗證的時候用到 | |
| 量化數據集 | 用來衡量量化前后 | |
| LoRA秩 | LoRA訓練中的秩大小,影響LoRa訓練中自身數據對模型作用程度,秩越大作用越大,需要依據數據量選擇合適的秩。 | 一般設置在32到128之間,默認是8 |
| LoRA縮放系數 | LoRa訓練中的縮放系數,用于調整初始化訓練權重,使其與預訓練權重接近或保持一致。 | 一般是LoRA秩的兩倍,一般設置個128、256 |
| 截斷長度 | 單個訓練數據樣本的最大長度,超出配置長度將自動截斷。 | |
| 批處理大小 | 批次大小代表模型訓練過程中,模型更新模型參數的數據步長,模型每看多少數據即更新一次模型參數。 | 合適的batch size可以加速訓練 |
| deepspeed stage | 選擇分布式多卡訓練的模式 | 有三種模式,一般用第二種 |
| deepspeed offload | 將一部分數據從顯存放到內存中 | 會很耗時間 |
四、直接使用webchat來和指定模型對話
????????雖然可以在webui的chat中和指定的模型去對話。但llamafactory還單獨給了一個命令,能夠起一個webchat來加載模型進行對話。
llamafactory-cli webchat --model_name_or_path MODEL_NAME_OR_PATH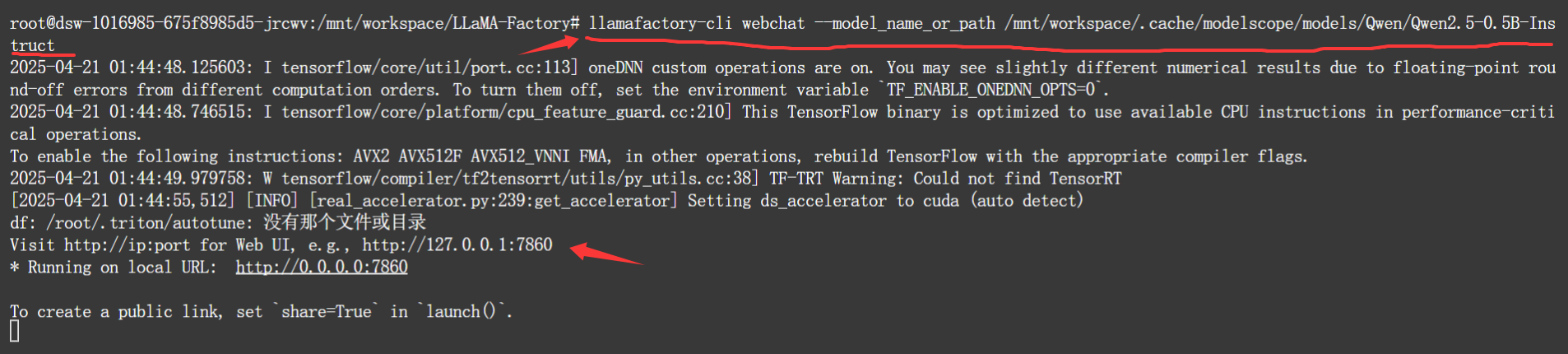
五、使用cli train進行黑窗口微調訓練的時候如何配置訓練參數?
????????這個問題看上去很簡單,查一下官方文檔不就好咯~或者看看example里面的yaml例子唄!說的很好!我們先來學習一下這兩種方式:
(1)參考官方文檔的配置文件
想直接看官方文檔的請點擊這里:llamafactory SFT 訓練
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml????????通過上面這行命令來開始訓練,你會發現好簡單,但緊接著就困惑了ymal配置文件里面的key都有哪些呀?都是什么意思呢?其實這一部分的答案就在官方文檔中,官方貼心的給了一個小字提醒“重要訓練參數”,還列了個表格方便你查閱。我就不要臉的直接復制在下面:
| 名稱 | 描述 |
|---|---|
| model_name_or_path | 模型名稱或路徑 |
| stage | 訓練階段,可選: rm(reward modeling), pt(pretrain), sft(Supervised Fine-Tuning), PPO, DPO, KTO, ORPO |
| do_train | true用于訓練, false用于評估 |
| finetuning_type | 微調方式。可選: freeze, lora, full |
| lora_target | 采取LoRA方法的目標模塊,默認值為? |
| dataset | 使用的數據集,使用”,”分隔多個數據集 |
| template | 數據集模板,請保證數據集模板與模型相對應。 |
| output_dir | 輸出路徑 |
| logging_steps | 日志輸出步數間隔 |
| save_steps | 模型斷點保存間隔 |
| overwrite_output_dir | 是否允許覆蓋輸出目錄 |
| per_device_train_batch_size | 每個設備上訓練的批次大小 |
| gradient_accumulation_steps | 梯度積累步數 |
| max_grad_norm | 梯度裁剪閾值 |
| learning_rate | 學習率 |
| lr_scheduler_type | 學習率曲線,可選? |
| num_train_epochs | 訓練周期數 |
| bf16 | 是否使用 bf16 格式 |
| warmup_ratio | 學習率預熱比例 |
| warmup_steps | 學習率預熱步數 |
| push_to_hub | 是否推送模型到 Huggingface |
【注】關鍵的問題來了——如果我還想配置得更細來進行訓練呢?
(2)參考examples文件夾里面的yaml配置文件
# 全參數量微調的配置文件
LLaMA-Factory/examples/train_full# LoRA微調的配置文件
LLaMA-Factory/examples/train_lora# QLoRA微調的配置文件
LLaMA-Factory/examples/train_qlora????????配置文件的路徑我給大家列出來了。里面有很多配置文件供你參考。但正是因為太多了,我都分不清這些配置文件都對應什么作用呀!?

????????其實,人家倉庫里面早就考慮到你會懵逼,所以貼心的在README.md文件里面寫清楚了。這里拿最常用的LoRA舉例子。
| 任務類型 | 命令 |
|---|---|
| (增量)預訓練 | llamafactory-cli train examples/train_lora/llama3_lora_pretrain.yaml |
| 指令監督微調 | llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml |
| 多模態指令監督微調 | llamafactory-cli train examples/train_lora/qwen2vl_lora_sft.yaml |
| DPO/ORPO/SimPO 訓練 | llamafactory-cli train examples/train_lora/llama3_lora_dpo.yaml |
| 多模態 DPO/ORPO/SimPO 訓練 | llamafactory-cli train examples/train_lora/qwen2vl_lora_dpo.yaml |
| 獎勵模型訓練 | llamafactory-cli train examples/train_lora/llama3_lora_reward.yaml |
| PPO 訓練 | llamafactory-cli train examples/train_lora/llama3_lora_ppo.yaml |
| KTO 訓練 | llamafactory-cli train examples/train_lora/llama3_lora_kto.yaml |
| 預處理數據集 | llamafactory-cli train examples/train_lora/llama3_preprocess.yaml |
| 在 MMLU/CMMLU/C-Eval 上評估 | llamafactory-cli eval examples/train_lora/llama3_lora_eval.yaml |
(3)參考webui生成的配置命令
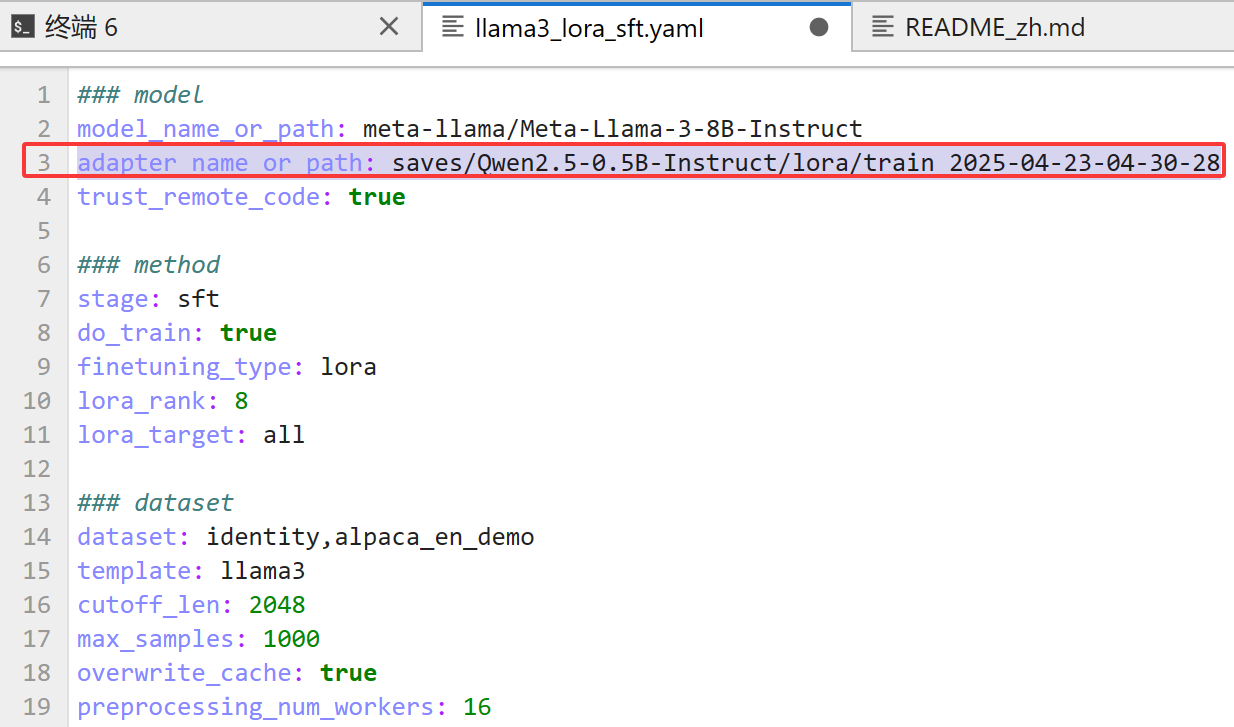
????????其實我最想講的是這個!比如我訓練到500輪保存了檢查點后想休息一下,下次接著訓練,但是我又不知道配置文件中怎么進行配置,才能實現接著上次的檢查點訓練。你或許會說你都有webui了為啥多次一舉?那就是有這樣的需求萬一無法使用webui,只能用黑窗口,但又不知道怎么配置。這時候你可以用另一臺可以使用webui的電腦,在webui上選好配置,然后生成
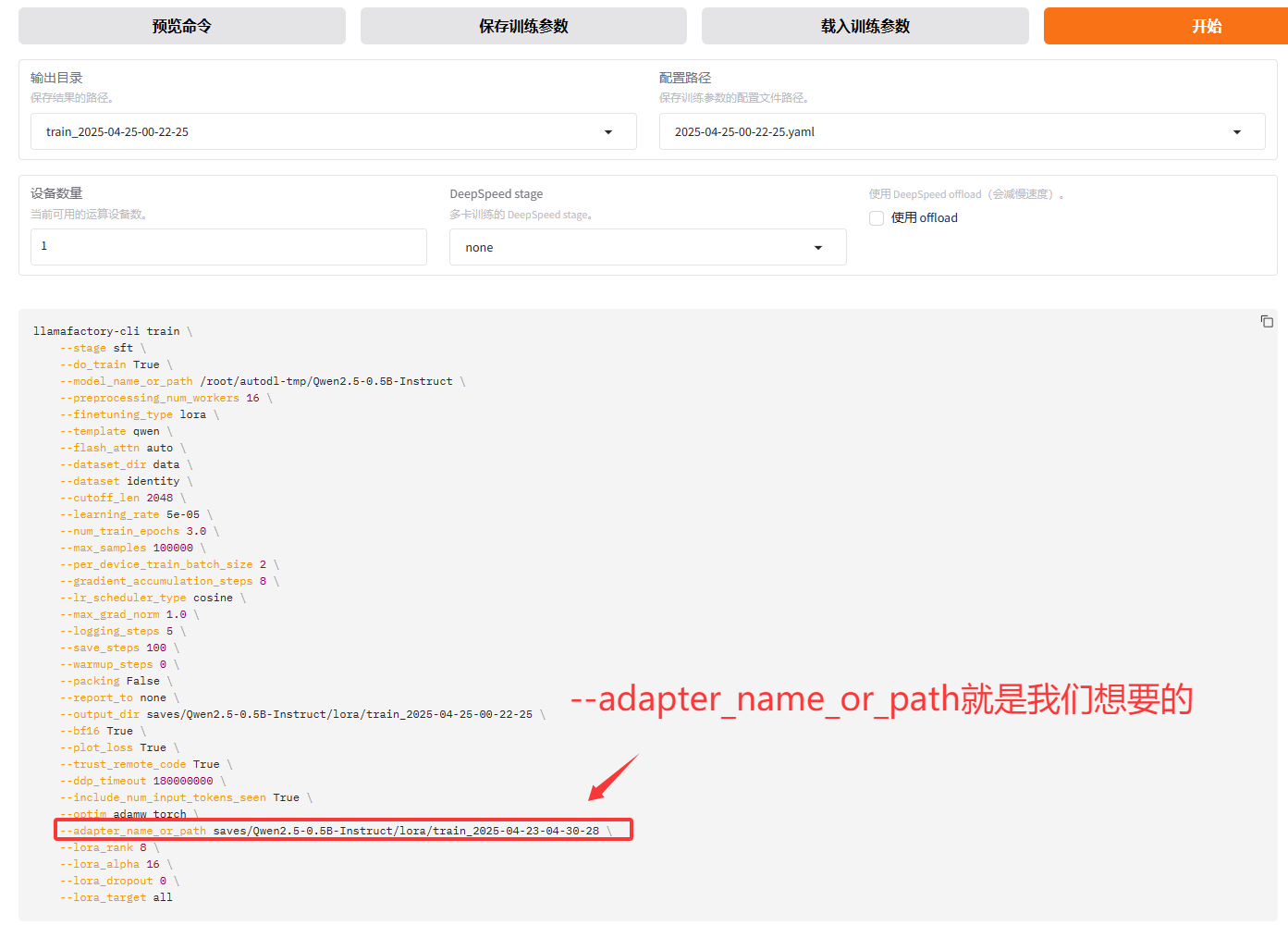
在去到配置文件中加上就行!
?后續持續更新有關使用llamafactory過程中的我覺得值得記錄的內容。?

)



)

)






:觀察者模式(Observer))




