作業用到的知識:
1.Pytorch:
1. nn.Conv2d(二維卷積層)
作用:
對輸入的多通道二位數據(如圖像)進行特征提取,通過滑動卷積核計算局部區域的加權和,生成新的特征圖。
關鍵參數:
| 參數 | 類型 | 說明 | |
| in_channel | int | 輸入的通道NCHW中的C | 3(RGB圖像的通道) |
| out_channels | int | ?輸出的通道數(卷積核數量) | 64(生成64個特征圖) |
| kernel size | int/tuple | 卷積核尺寸 | 3(3X3)或(3,5) |
| stride | int/tuple | 卷積核滑動步長 | 2 |
| padding | int/tuple | 輸入邊緣填充像素數 | |
| dilation | int/tuple | 卷積核元素間距(擴張卷積) | 2 |
| groups | int | 分組卷積的數組 | groups= in_channels(深度可分離卷積) |
| bias | bool | 是否添加偏置項 | False(配合Batch Norm時使用) |
輸入輸出形狀
-
輸入:
(N, C_in, H_in, W_in) -
輸出:
(N, C_out, H_out, W_out) -
-
2. nn.BatchNorm2d
作用:
對每個通道的特征圖進行歸一化(均值歸零、方差歸一),加速訓練、緩解梯度消失/爆炸,并允許使用更大的學習率
| 參數 | 類型 | 說明 | 示例 |
| num_feature | int | C | 64 |
| eps | float | 數值穩定性系數(防止除以0) | 1e-5 |
| momentum | float | 更新運行均值/方差的動量系數 | 0.1 |
| affine | bool | 是否學習縮放因子 | True(默認啟用 |
-
輸入:
(N, C, H, W) -
輸出:
(N, C, H, W)(形狀不變) -
歸一化公式:
-
對每個通道獨立計算:
-
-
3?nn.ReLU(True)(修正線性單元激活函數)
作用
-
激活函數:引入非線性,使神經網絡能夠學習復雜的模式。
-
數學公式:
ReLU(x)=max?(0,x)-
輸入為負時輸出0,輸入為正時保持不變。
-
參數?inplace=True
-
功能:直接在輸入張量上進行修改(覆蓋原數據),節省內存。
-
為什么用ReLU?
-
稀疏性:負值歸零,使網絡更稀疏,提升計算效率。
-
緩解梯度消失:正區間的梯度恒為1,避免深層網絡梯度消失問題。
4.?nn.MaxPool2d(2, 2)(二維最大池化層)
作用
-
下采樣:降低特征圖的空間尺寸(高度和寬度),減少計算量。
-
保留顯著特征:取局部區域的最大值,保留最顯著的特征。
參數解析
-
kernel_size=2:池化窗口大小為2×2。 -
stride=2:窗口每次移動2步(水平和垂直方向)。 -
默認行為:
-
若未指定
padding,默認不填充(padding=0)。 -
若未指定
dilation,默認窗口連續無間隔。 -
輸出尺寸公式:?
-
-
為什么用最大池化?
-
平移不變性:對特征的位置變化更魯棒。
-
降維提速:減少后續層的計算量。
-
5. flatten和linear
| 組件 | 功能 | 關鍵參數 | 輸入輸出示例 |
|---|---|---|---|
nn.Flatten() | 將多維數據展平為一維向量 | start_dim,?end_dim | [2,3,4,4] → [2,48] |
nn.Linear | 線性變換(分類/回歸) (即? | in_features,?out_features | [2,48] → [2,10] |
-
nn.Flatten()?是連接卷積層和全連接層的橋梁,解決多維數據與一維輸入的維度不匹配問題。 -
nn.Linear?通過線性變換實現特征到目標的映射,是神經網絡的最終決策層。
6.Pytorch初始化方法
| 初始化方法 | 函數 | 適用場景 |
|---|---|---|
| Xavier 正態分布 | xavier_normal_ | tanh/sigmoid?激活 |
| He 正態分布(Kaiming) | kaiming_normal_ | ReLU/LeakyReLU?激活 |
| 均勻分布 | uniform_ | 簡單初始化 |
| 常數初始化 | constant_ | 特殊需求(如全零初始化) |
7. BCELoss ?損失函數
torch.nn.BCELoss()?是 PyTorch 中用于?二分類任務?的交叉熵損失函數,適用于模型輸出為?概率值(即屬于正類的概率)的場景:
核心公式與功能
1). 數學公式
對于每個樣本,損失計算為:
loss(x,y)=?[y?log(x)+(1?y)?log(1?x)]
-
x:模型輸出的概率值(需在?[0, 1]?范圍內)。
-
yy:真實標簽(取值為?0 或 1)
2). 功能
-
衡量?模型預測概率?與?真實標簽?之間的差距。
-
優化目標:使預測概率盡可能接近真實標簽。
3)使用步驟
模型輸出處理
確保模型最后一層使用?Sigmoid 激活函數,將輸出壓縮到?[0, 1]?區間:
model = nn.Sequential(nn.Linear(input_dim, 1),nn.Sigmoid() # 必須添加 Sigmoid )
計算損失
criterion = nn.BCELoss() output = model(x) # 輸出形狀 (N, *) loss = criterion(output, target)
4) 反向傳播
調用?loss.backward()?時,PyTorch 的 Autograd 系統自動執行以下操作:
-
計算損失對模型輸出的梯度:
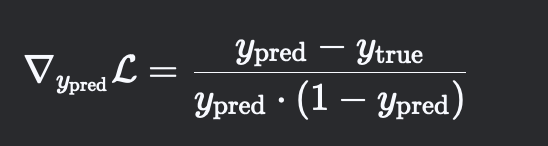
這一步由?
BCELoss?的反向函數自動實現。 -
梯度反向傳播到前一層:
-
如果模型輸出?ypredypred??是 Sigmoid 的輸出,梯度會繼續反向傳播到 Sigmoid 的輸入?zz(即線性層的輸出)。
-
根據鏈式法則,梯度在 Sigmoid 層被修正為?
 。
。
-
-
更新模型參數:
-
梯度從 Sigmoid 層傳播到線性層的權重和偏置。
-
優化器(如?
optimizer.step())根據梯度更新參數。
-
python:
1.np.random.permutation
np.random.permutation?是 NumPy 中用于生成隨機排列的函數。它可以對數組元素進行隨機打亂,或生成一個范圍序列的隨機排列。以下是具體用法和場景:
功能概述
-
輸入為整數?
n:生成?[0, 1, 2, ..., n-1]?的隨機排列。 -
輸入為數組:返回數組元素的隨機排列(不修改原數組)。
-
與?
np.random.shuffle?的區別:shuffle?直接修改原數組,而?permutation?返回新數組,原數組不變。
1). 生成整數序列的隨機排列
import numpy as np# 生成 0-4 的隨機排列
arr = np.random.permutation(5)
print(arr) # 輸出示例:[3 1 4 0 2]2). 打亂數組元素的順序
original = np.array([10, 20, 30, 40, 50])
shuffled = np.random.permutation(original)
print("原數組:", original) # 原數組: [10 20 30 40 50]
print("打亂后:", shuffled) # 打亂后: [30 10 50 40 20]2. os.path.join
os.path.join(data_path, 'cats')作用:將?
data_path(基礎路徑)與子目錄?cats?拼接成完整路徑。
os.listdir(os.path.join(data_path, 'cats'))作用:獲取?
cats?目錄下的所有條目(文件和子目錄)名稱列表。
sorted(...)
作用:對?
os.listdir?返回的列表按字母順序升序排列。
執行結果:
cat_dirs:排序后的?cats?目錄內容列表,如?['cat1.jpg', 'cat2.jpg', 'subfolder']。
dog_dirs:排序后的?dogs?目錄內容列表,如?['dog1.jpg', 'dog2.jpg']。
?3.np.expand_dims?的作用
-
功能:在指定軸(
axis)插入一個新維度,擴展數組的形狀。 -
語法:
python
復制
np.expand_dims(arr, axis)
Pytorch實現基本的CNN和實驗結果
1. 獲取數據集:
import kagglehub
import shutil# Download latest version
path = kagglehub.dataset_download("fusicfenta/cat-and-dog")# 自定義目標路徑
custom_path = "/Users/hailie/Desktop/小蘭/hailie/study/AI/DL/coursera作業/DL_homework_self/CNN/"# 將文件移動到自定義路徑
shutil.move(path, custom_path)print("數據集已移動到:", custom_path)import os
from typing import Tuple
import cv2
import numpy as npdef load_set(data_path: str, cnt: int, img_shape: Tuple[int,int]):cat_dirs = sorted(os.listdir(os.path.join(data_path, 'cats')))dog_dirs = sorted(os.listdir(os.path.join(data_path, 'dogs')))images = []for i, cat_dir in enumerate(cat_dirs):if i >= cnt:breakname = os.path.join(data_path, 'cats', cat_dir)cat = cv2.imread(name)images.append(cat)for i, dog_dir in enumerate(dog_dirs):if i >= cnt:breakname = os.path.join(data_path, 'dogs', dog_dir)dog = cv2.imread(name)images.append(dog)for i in range(len(images)):images[i] = cv2.resize(images[i],img_shape)images[i] = images[i].astype(np.float32) /255.0return np.array(images) def get_cat_set(data_path: str,img_shape: Tuple[int, int] = (224, 224),train_size = 1000,test_size = 200)->Tuple[np.ndarray, np.ndarray, np.ndarray, np. ndarray]:train_X = load_set(os.path.join(data_path,'training_set'),train_size,img_shape)test_X= load_set(os.path.join(data_path,'test_set'),test_size,img_shape)train_Y = np.array([1]* train_size + [0] * train_size)test_Y = np.array([1] * test_size + [0] * test_size)train_X = np.reshape(train_X,(-1,3,*img_shape))test_X = np.reshape(test_X,(-1,3,*img_shape))return train_X, np.expand_dims(train_Y,1), test_X, np.expand_dims(test_Y,1)
train_X = np.reshape(train_X, (-1, 3, *img_shape) test_X = np.reshape(test_X, (-1, 3, *img_shape)
-
輸入數據?
train_X/test_X:通過?reshape?調整形狀為?NCHW?格式。-
-1:自動推斷批次數?N(保持總數據量不變)。 -
3:通道數(例如 RGB 圖像的通道數)。 -
*img_shape:展開圖像的高度和寬度(例如?img_shape = (32, 32)?→?32, 32)。 -
示例:
原始形狀為?(N, H, W, 3)(NHWC) → 調整后為?(N, 3, H, W)(NCHW)
-
?
?
2. ?初始化模型:
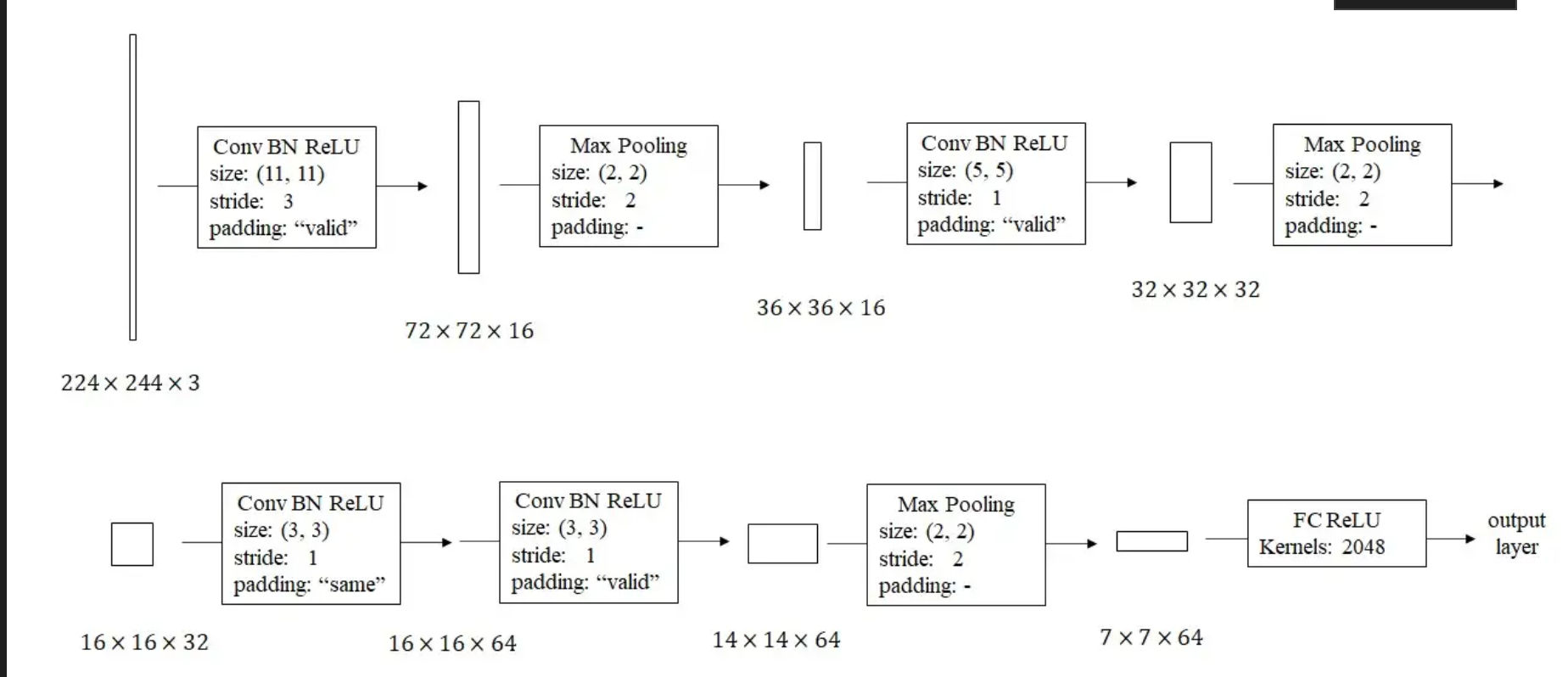
?
由于這個二分類任務比較簡單,我在設計時盡可能讓可訓練參數更少。剛開始用一個大步幅、大卷積核的卷積快速縮小圖片邊長,之后逐步讓圖片邊長減半、深度翻倍。
這樣一個網絡用PyTorch實現如下:
import torch
import numpy as np
import torch.nn as nn
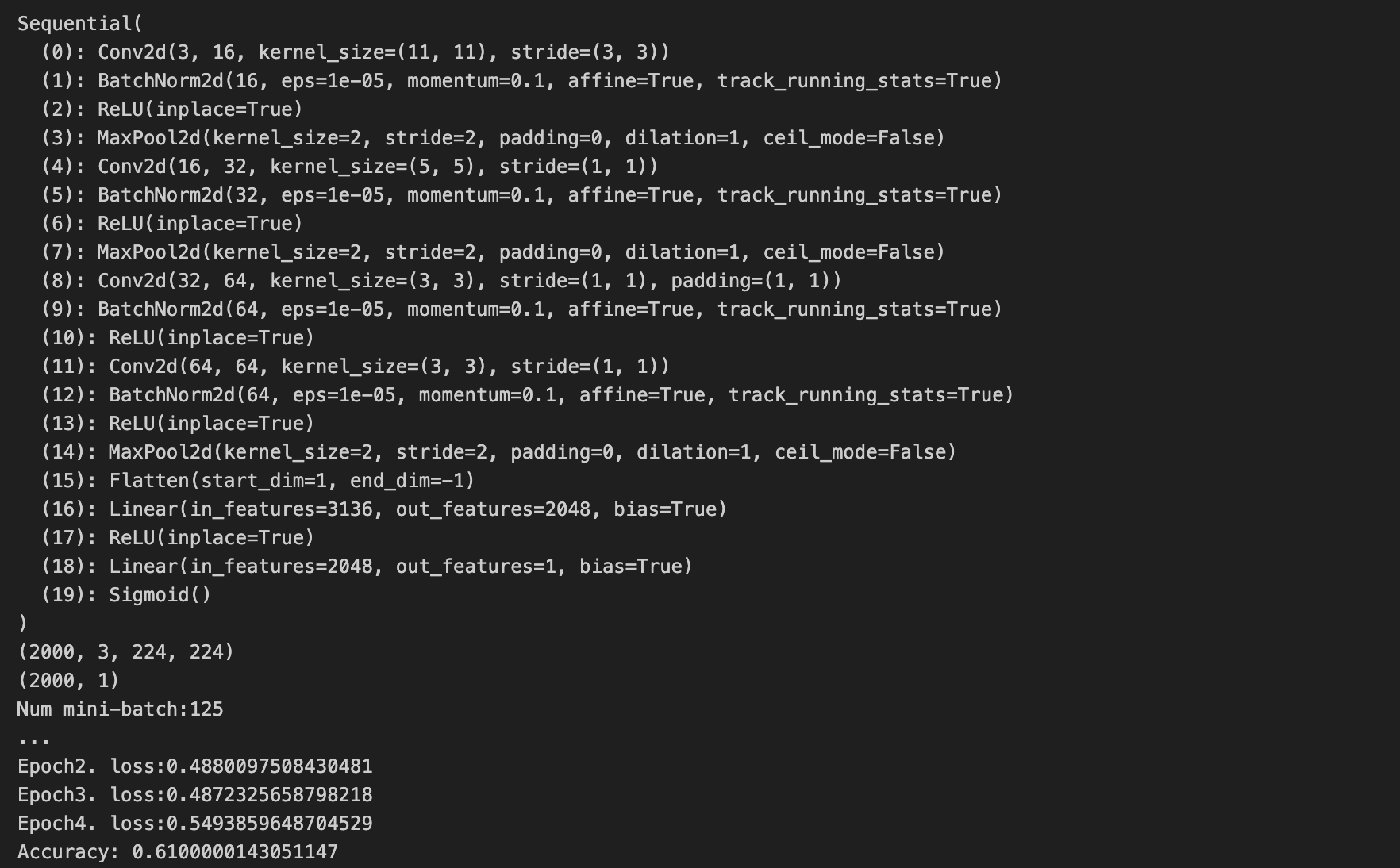
import mathdef init_model():model = nn.Sequential(nn.Conv2d(3,16,11,3),nn.BatchNorm2d(16),nn.ReLU(True), nn.MaxPool2d(2,2),nn.Conv2d(16,32,5),nn.BatchNorm2d(32),nn.ReLU(True),nn.MaxPool2d(2,2),nn.Conv2d(32,64,3,padding=1),nn.BatchNorm2d(64),nn.ReLU(True),nn.Conv2d(64,64,3),nn.BatchNorm2d(64),nn.ReLU(True),nn.MaxPool2d(2,2),nn.Flatten(),nn.Linear(3136,2048), nn.ReLU(True),nn.Linear(2048,1),nn.Sigmoid())def weights_init(m):if isinstance(m,nn.Conv2d):torch.nn.init.xavier_normal_(m.weight)m.bias.data.fill_(0)elif isinstance(m,nn.BatchNorm2d):m.weight.data.normal_(1.0,0.02) # 默認簡單初始化m.bias.data.fill_(0)elif isinstance(m,nn.Linear):torch.nn.init.xavier_normal_(m.weight)m.bias.data.fill_(0)model.apply(weights_init)print(model)return modeltorch.nn.Sequential()用于創建一個串行的網絡(前一個模塊的輸出就是后一個模塊的輸入)。網絡各模塊用到的初始化參數的介紹如下:
Conv2d: 輸入通道數、輸出通道數、卷積核邊長、步幅、填充個數padding。BatchNormalization: 輸入通道數。ReLU: 一個bool值inplace。是否使用inplace,就和用a += 1還是a + 1一樣,后者會多花一個中間變量來存結果。MaxPool2d: 卷積核邊長、步幅。Linear(全連接層):輸入通道數、輸出通道數。
根據之前的設計,把參數填入這些模塊即可。
由于PyTorch在初始化模塊時不能自動初始化參數,我們要手動寫上初始化參數的邏輯。
在此之前,要先認識一下torch.nn.Module的apply函數。
model.apply(weights_init)PyTorch的模型模塊torch.nn.Module是自我嵌套的。一個torch.nn.Module的實例可能由多個torch.nn.Module的實例組成。model.apply(func)可以對某torch.nn.Module實例的所有某子模塊執行func函數。我們使用的參數初始化函數叫做weights_init,所以用上面那行代碼就可以初始化所有模塊。
其中,m就是子模塊的示例。通過對其進行類型判斷,我們可以對不同的模塊執行不同的初始化方式。初始化的函數都在torch.nn.init,這里用的是torch.nn.init.xavier_normal_。?
3. 準備優化器和loss?
初始化完模型后,可以用下面的代碼初始化優化器與loss。
model = init_model(device)
optimizer = torch.optim.Adam(model.parameters(), 5e-4)
loss_fn = torch.nn.BCELoss()
torch.optim.Adam可以初始化一個Adam優化器。它的第一個參數是所有可訓練參數,直接對一個torch.nn.Module調用.parameters()即可一鍵獲取參數。它的第二個參數是學習率,這個可以根據實驗情況自行調整。
torch.nn.BCELoss是二分類用到的交叉熵誤差。這里只是對它進行了初始化。在調用時,使用方法是loss(input, target)。input是用于比較的結果,target是被比較的標簽。
4.訓練與推理
def train(model:nn.Module,train_X:np.ndarray,train_Y:np.ndarray,optimizer:torch.optim.Optimizer,loss_fn:nn.Module,batch_size:int,num_epoch: int):m = train_X.shape[0]#print("m:",m,"batch_size,",batch_size)print(train_X.shape) # (m, 3, 224, 224)print(train_Y.shape) # (m, 1)indices = np.random.permutation(m)num_mini_batch = math.ceil(m / batch_size)mini_batch_XYs = []shuffle_X = train_X[indices, ...]shuffle_Y = train_Y[indices, ...]for i in range(num_mini_batch):if i == num_mini_batch - 1:mini_batch_X = shuffle_X[i*batch_size:,...]mini_batch_Y = shuffle_Y[i*batch_size:,...]else:mini_batch_X = shuffle_X[i*batch_size: (i+1)*batch_size, ...]mini_batch_Y = shuffle_Y[i*batch_size: (i+1)*batch_size, ...]mini_batch_X = torch.from_numpy(mini_batch_X)mini_batch_Y = torch.from_numpy(mini_batch_Y).float()mini_batch_XYs.append((mini_batch_X,mini_batch_Y))print(f'Num mini-batch:{num_mini_batch}')for e in range(num_epoch):for mini_batch_X, mini_batch_Y in mini_batch_XYs:mini_batch_Y_hat = model(mini_batch_X)loss: torch.Tensor = loss_fn(mini_batch_Y_hat, mini_batch_Y)optimizer.zero_grad()loss.backward()optimizer.step()print(f'Epoch{e}. loss:{loss}')def evaluate (model: nn.Module,test_X:np.ndarray,test_Y: np.ndarray):test_X = torch.from_numpy(test_X)test_Y = torch.from_numpy(test_Y)test_Y_hat = model(test_X)predicts = torch.where(test_Y_hat>0.5,1,0)score = torch.where(predicts == test_Y, 1.0, 0.0)acc = torch.mean(score)print(f'Accuracy: {acc}')
在訓練時,我們采用mini-batch策略。因此,開始迭代前,我們要編寫預處理mini-batch的代碼?
這里還有一些有關PyTorch的知識需要講解。torch.from_numpy可以把一個NumPy數組轉換成torch.Tensor。由于標簽Y是個整形張量,而PyTorch算loss時又要求標簽是個float,這里要調用.float()把張量強制類型轉換到float型。同理,其他類型也可以用類似的方法進行轉換。
直接用model(x)即可讓模型model執行輸入x的前向傳播。
之后幾行代碼就屬于訓練的常規操作了。先計算loss,再清空優化器的梯度,做反向傳播,最后調用優化器更新所有參數。
train_X, train_Y, test_X, test_Y = get_cat_set('/Users/hailie/Desktop/小蘭/hailie/study/AI/DL/coursera作業/DL_homework_self/CNN/1/dataset',train_size=1000)cnn_model = init_model()
optimizer = torch.optim.Adam(cnn_model.parameters(), 5e-4)
loss_fn = torch.nn.BCELoss()
train(cnn_model, train_X,train_Y, optimizer, loss_fn, 16, 5)
evaluate(cnn_model, test_X, test_Y)5.實驗結果?
電腦資源受限,只跑了一點點
用Numpy復現一致的torch.conv2d
為了加深理解 下面用NumPy復現一致的torch.conv2d向前傳播
再回顧一下主要參數:
主要參數
-
in_channels?(int)
-
作用:輸入數據的通道數(例如,RGB 圖像為 3,灰度圖為 1)。
-
示例:
in_channels=3
-
-
out_channels?(int)
-
作用:輸出特征圖的通道數(即卷積核的數量)。
-
示例:
out_channels=64?表示生成 64 個特征圖。
-
-
kernel_size?(int 或 tuple)
-
作用:卷積核的尺寸。可以是單個整數(如?
3?表示 3×3)或元組(如?(3,5))。 -
示例:
kernel_size=3?或?kernel_size=(3,5)
-
-
stride?(int 或 tuple, 默認?
1)-
作用:卷積核的步長。控制輸出尺寸的縮小比例。
-
示例:
stride=2?或?stride=(2,1)
-
-
padding?(int 或 tuple, 默認?
0)-
作用:輸入數據的邊緣填充像素數。用于控制輸出尺寸。
-
示例:
padding=1?表示在四周各填充 1 行/列。
-
-
dilation?(int 或 tuple, 默認?
1)-
作用:卷積核元素的間距(擴張卷積)。增大感受野,不增加參數量。
-
示例:
dilation=2?時,3×3 卷積核的感受野等效于 5×5。 -
-
-
groups?(int, 默認?
1)-
作用:分組卷積的組數。
groups=in_channels?時為深度可分離卷積。 -
約束:
in_channels?和?out_channels?必須能被?groups?整除。 -
示例:
groups=2?表示將輸入和輸出的通道分為 2 組獨立卷積。 -
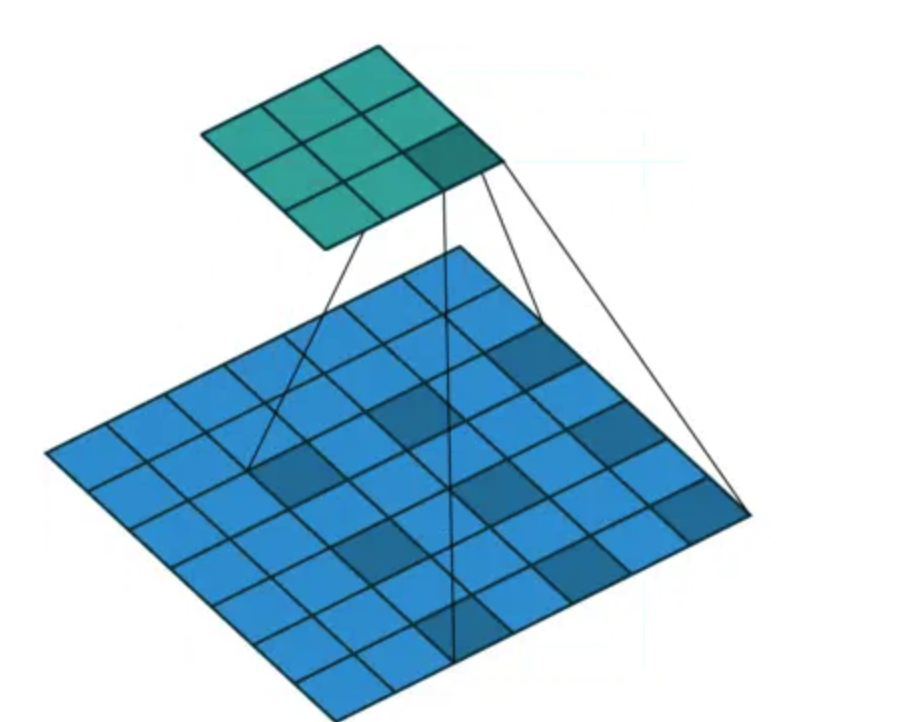
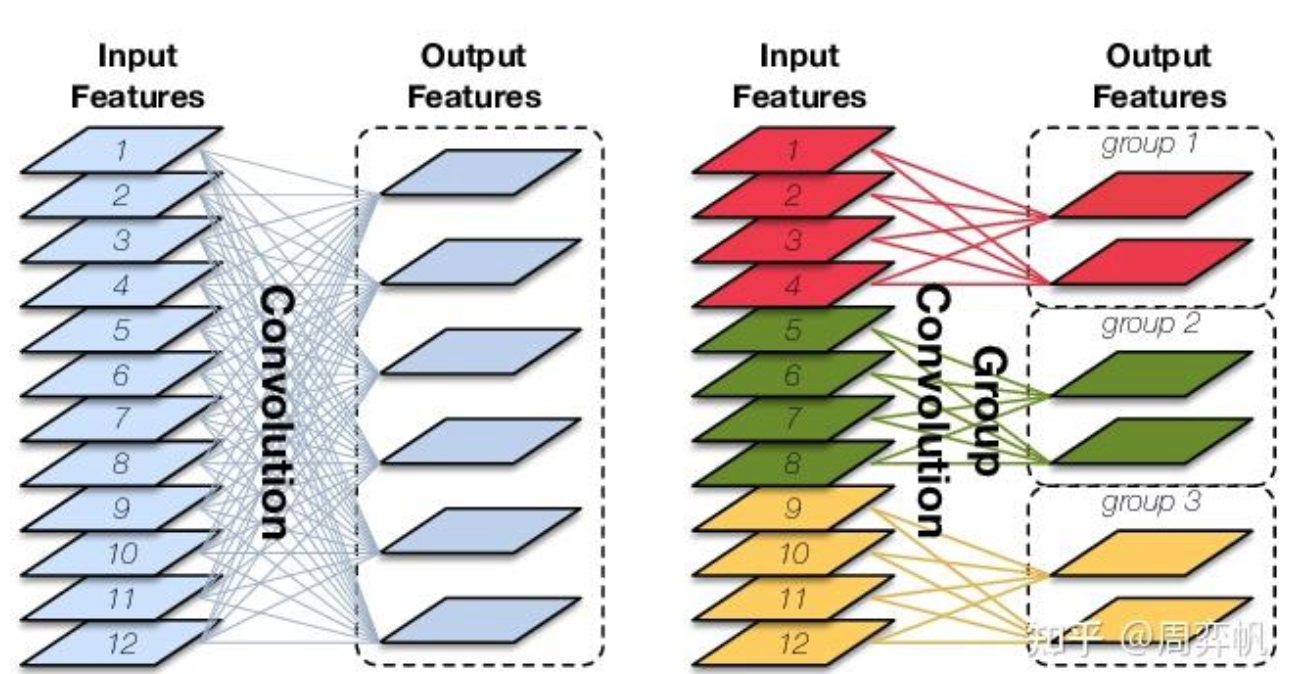
下圖展示了輸入通道數12,輸出通道數6的卷積在兩種不同groups下的情況。左邊是group=1的普通卷積,右邊是groups=3的分組卷積。在具體看分組卷積的介紹前,
-
-
-
bias?(bool, 默認?
True)-
作用:是否添加偏置項。若后續接 BatchNorm 層,通常設為?
False。 -
示例:
bias=False
-
向前傳播
import numpy as np
import pytest
import torchdef conv2d(input: np.ndarray,weight: np.ndarray,stride: int,padding: int,dilation: int,groups: int,bias:np.ndarray = None)->np.ndarray:#Args:#input (np.ndarray): The input NumPy array of shape (H, W, C).#weight (np.ndarray): The weight NumPy array of shape# (C', F, F, C / groups).#stride (int): Stride for convolution.#padding (int): The count of zeros to pad on both sides.#dilation (int): The space between kernel elements.#groups (int): Split the input to groups.#bias (np.ndarray | None): The bias NumPy array of shape (C').h_input, w_input, c_input = input.shapec_o, f, f_2, c_k = weight.shapeassert(f==f_2)assert(c_input % groups == 0)assert(c_o % groups ==0)assert(c_input // groups == c_k)if bias is not None:assert(bias.shape[0] == c_o)f_new = f + (f-1) * (dilation -1)weight_new = np.zeros((c_o, f_new, f_new, c_k), dtype=weight.dtype)for i_c_o in range(c_o):for i_c_k in range(c_k):for i_f in range(f):for j_f in range(f):i_f_new = i_f * dilationj_f_new = j_f * dilation weight_new [i_c_o, i_f_new, j_f_new, i_c_k] = weight[i_c_o,i_f,j_f,i_c_k]input_pad = np.pad(input, [(padding, padding),(padding, padding),(0,0)])def cal_new_sidelength(size, stride,f, padding):return ((size + 2*padding - f) // stride) +1h_output = cal_new_sidelength(h_input, stride, f_new, padding)w_output = cal_new_sidelength(w_input, stride, f_new, padding)output = np.empty((h_output, w_output,c_o), dtype=input.dtype)c_o_per_group = c_o // groupsfor i_h in range(h_output):for i_w in range(w_output):for i_c in range(c_o):i_g = i_c//c_o_per_groupvert_start = i_h * stridevert_end = vert_start + f_newhoriz_start = i_w * stridehoriz_end = horiz_start + f_newchannel_start = c_k * i_gchannel_end = c_k * (i_g + 1)input_slice = input_pad[vert_start : vert_end,horiz_start:horiz_end,channel_start:channel_end]kernel_slice = weight_new[i_c]output[i_h,i_w,i_c] = np.sum(input_slice * kernel_slice)if bias:output[i_h,i_w,i_c] += bias[i_c]return output@pytest.mark.parametrize('c_i, c_o', [(3, 6), (2, 2)])
@pytest.mark.parametrize('kernel_size', [3, 5])
@pytest.mark.parametrize('stride', [1, 2])
@pytest.mark.parametrize('padding', [0, 1])
@pytest.mark.parametrize('dilation', [1, 2])
@pytest.mark.parametrize('groups', ['1', 'all'])
@pytest.mark.parametrize('bias', [False])
def test_conv(c_i: int, c_o: int, kernel_size: int, stride: int, padding: str,dilation: int, groups: str, bias: bool):if groups == '1':groups = 1elif groups == 'all':groups = c_iif bias:bias = np.random.randn(c_o)torch_bias = torch.from_numpy(bias)else:bias = Nonetorch_bias = Noneinput = np.random.randn(20, 20, c_i)weight = np.random.randn(c_o, kernel_size, kernel_size, c_i // groups)torch_input = torch.from_numpy(np.transpose(input, (2, 0, 1))).unsqueeze(0)torch_weight = torch.from_numpy(np.transpose(weight, (0, 3, 1, 2)))torch_output = torch.conv2d(torch_input, torch_weight, torch_bias, stride,padding, dilation, groups).numpy()torch_output = np.transpose(torch_output.squeeze(0), (1, 2, 0))numpy_output = conv2d(input, weight, stride, padding, dilation, groups,bias)assert np.allclose(torch_output, numpy_output)input的形狀是(H,W,C)卷積核組weight形狀是(C',H,W,C_k), ?其中C_k = C/groups。同時 C'也必須能夠被groups整除。bias形狀是C'。
空洞卷積可以用卷積核擴充實現。因此,在開始卷積之前,可以先預處理好擴充后的卷積核。我們先算好擴充后卷積核的形狀,并創建好新的卷積核,最后用多重循環給新卷積核賦值。
f_new = f + (f - 1) * (dilation - 1)weight_new = np.zeros((c_o, f_new, f_new, c_k), dtype=weight.dtype)for i_c_o in range(c_o):for i_c_k in range(c_k):for i_f in range(f):for j_f in range(f):i_f_new = i_f * dilationj_f_new = j_f * dilationweight_new[i_c_o, i_f_new, j_f_new, i_c_k] = \weight[i_c_o, i_f, j_f, i_c_k]?
@pytest.mark.parametrize用于設置單元測試參數的可選值。我設置了6組參數,每組參數有2個可選值,經過排列組合后可以生成2^6=64個單元測試,pytest會自動幫我們執行不同的測試。
向后傳播
向前傳播時,我們遍歷輸出圖像的每一個位置,選擇該位置對應的輸入圖像切片和卷積核,做一遍乘法,再加上bias。
其實,一輪運算寫成數學公式的話,就是一個線性函數y=wx+b。對w, x, b求導非常簡單:
dw_i = x * dy
dx_i = w * dy
db_i = dy
在反向傳播中,我們只需要遍歷所有這樣的線性運算,計算這輪運算對各參數的導數的貢獻即可。最后,累加所有的貢獻,就能得到各參數的導數。當然,在用代碼實現這段邏輯時,可以不用最后再把所有貢獻加起來,而是一算出來就加上。
dw += x * dy
dx += w * dy
db += dy這里要稍微補充一點。在前向傳播的實現中,我加入了dilation, groups這兩個參數。為了簡化反向傳播的實現代碼,只展示反向傳播中最精華的部分,我在這份卷積實現中沒有使用這兩個參數。
?
from typing import Dict, Tupleimport numpy as np
import pytest
import torchdef conv2d_forward(input: np.ndarray, weight: np.ndarray, bias: np.ndarray,stride: int, padding: int) -> Dict[str, np.ndarray]:"""2D Convolution Forward Implemented with NumPy.Args:input (np.ndarray): The input NumPy array of shape (H, W, C).weight (np.ndarray): The weight NumPy array of shape(C', F, F, C).bias (np.ndarray | None): The bias NumPy array of shape (C').Default: None.stride (int): Stride for convolution.padding (int): The count of zeros to pad on both sides.Outputs:Dict[str, np.ndarray]: Cached data for backward prop."""h_i, w_i, c_i = input.shapec_o, f, f_2, c_k = weight.shapeassert (f == f_2)assert (c_i == c_k)assert (bias.shape[0] == c_o)input_pad = np.pad(input, [(padding, padding), (padding, padding), (0, 0)])def cal_new_sidelngth(sl, s, f, p):return (sl + 2 * p - f) // s + 1h_o = cal_new_sidelngth(h_i, stride, f, padding)w_o = cal_new_sidelngth(w_i, stride, f, padding)output = np.empty((h_o, w_o, c_o), dtype=input.dtype)for i_h in range(h_o):for i_w in range(w_o):for i_c in range(c_o):h_lower = i_h * strideh_upper = i_h * stride + fw_lower = i_w * stridew_upper = i_w * stride + finput_slice = input_pad[h_lower:h_upper, w_lower:w_upper, :]kernel_slice = weight[i_c]output[i_h, i_w, i_c] = np.sum(input_slice * kernel_slice)output[i_h, i_w, i_c] += bias[i_c]cache = dict()cache['Z'] = outputcache['W'] = weightcache['b'] = biascache['A_prev'] = inputreturn cachedef conv2d_backward(dZ:np.ndarray,cache:dict[str:np.ndarray],stride:int,padding:int)->Tuple[np.ndarray,np.ndarray,np.ndarray]:Z = cache['Z']W = cache['W']b = cache['b']A_prev = cache['A_prev']dW = np.zeros(W.shape)db = np.zeros(b.shape)dA_prev = np.zeros(A_prev.shape)A_prev_pad = np.pad(A_prev, [(padding,padding),(padding,padding),(0,0)])dA_prev_pad = np.pad(dA_prev, [(padding,padding),(padding,padding),(0,0)])h_o,w_o,c_o_2 = dZ.shapec_o,f,f_2,c_k = W.shape_,_,c_i = A_prev.shapeassert (f == f_2)assert (c_i == c_k)assert (c_o == c_o_2)for i_h in range(h_o):for i_w in range(w_o):for i_c in range(c_o):vert_start = i_h * stridehoriz_start = i_w * stridevert_end = vert_start + fhoriz_end = horiz_start + finput_slice = A_prev_pad[vert_start:vert_end,horiz_start:horiz_end,:]dW[i_c] += input_slice * dZ[i_h,i_w,i_c]dA_prev_pad[vert_start:vert_end, horiz_start:horiz_end,:] +=W[i_c] *dZ[i_h,i_w,i_c]db[i_c] += dZ[i_h,i_w,i_c]if padding > 0:dA_prev = dA_prev_pad[padding:-padding, padding:-padding, :]else:dA_prev = dA_prev_padreturn dW, db, dA_prev@pytest.mark.parametrize('c_i, c_o', [(3, 6), (2, 2)])
@pytest.mark.parametrize('kernel_size', [3, 5])
@pytest.mark.parametrize('stride', [1, 2])
@pytest.mark.parametrize('padding', [0, 1])
def test_conv(c_i: int, c_o: int, kernel_size: int, stride: int, padding: str):# Preprocessinput = np.random.randn(20, 20, c_i)weight = np.random.randn(c_o, kernel_size, kernel_size, c_i)bias = np.random.randn(c_o)torch_input = torch.from_numpy(np.transpose(input, (2, 0, 1))).unsqueeze(0).requires_grad_()torch_weight = torch.from_numpy(np.transpose(weight, (0, 3, 1, 2))).requires_grad_()torch_bias = torch.from_numpy(bias).requires_grad_()# forwardtorch_output_tensor = torch.conv2d(torch_input, torch_weight, torch_bias,stride, padding)torch_output = np.transpose(torch_output_tensor.detach().numpy().squeeze(0), (1, 2, 0))cache = conv2d_forward(input, weight, bias, stride, padding)numpy_output = cache['Z']assert np.allclose(torch_output, numpy_output)# backwardtorch_sum = torch.sum(torch_output_tensor)torch_sum.backward()torch_dW = np.transpose(torch_weight.grad.numpy(), (0, 2, 3, 1))torch_db = torch_bias.grad.numpy()torch_dA_prev = np.transpose(torch_input.grad.numpy().squeeze(0),(1, 2, 0))dZ = np.ones(numpy_output.shape)dW, db, dA_prev = conv2d_backward(dZ, cache, stride, padding)assert np.allclose(dW, torch_dW)assert np.allclose(db, torch_db)assert np.allclose(dA_prev, torch_dA_prev)


--- Day 4)




)
)









)