1. 數據集和任務部分
SimVG用的六個數據集:RefCOCO/+/g, ReferIt, Flickr30K, and GRefCOCO
| 數據集名稱 | 圖像數量 | 參照表達式數量 | 參照對象實例數 | 語言特性 | 主要任務 |
|---|---|---|---|---|---|
| RefCOCO | 19,994 | 142,209 | 50,000 | ?基于 MS COCO 圖像,采用 ReferItGame 收集的指代表達數據集。表達通常簡短,包含位置詞,適用于實時交互場景 | 指代表達理解、分割、視覺指引 |
| RefCOCO+ | 19,994 | 141,564 | 50,000 | 在 RefCOCO 的基礎上,禁止使用位置詞,強調對象的外觀/屬性特征,挑戰模型在無位置信息下的識別能力。? | 外觀驅動的指代表達理解與分割 |
| RefCOCOg | 25,799 | 95,010 | 49,822 | ?有兩個分區(Google和umd),這里是由 Google split,表達更長,描述更詳細,適合研究復雜關系建模和自然語言理解。 | 自然語言理解、復雜關系建模 |
| gRefCOCO | 19,994 | 278,232 | 60,287 | 部分單目標表達式繼承自 RefCOCOg,支持單目標、多目標和無目標的表達,適用于泛化指代表達理解(GREC)和分割(GRES)任務。該數據集旨在提高模型在復雜表達下的泛化能力。? | 泛化指代表達理解與分割(GREC/GRES) |
| ReferIt/ReferItGame | 20,000+ | 130,525 | 96,654 | 早期的指代表達數據集,基于 SAIAPR TC-12 圖像,表達自由,包含對背景和場景的描述。適用于區域定位和早期視覺指引研究 | 早期視覺指引、區域定位 |
| Flickr30K Entities | 31,783 | 158,000+ | 427,000 | 以短語作為語言查詢,而不是完整的句子。在 Flickr30K 數據集的基礎上,添加了實體標注和共指鏈,支持短語定位、圖文對齊和多模態檢索等任務。 | 短語定位、圖文對齊、多模態檢索 |
在RefCOCO和RefCOCO +遵循train / validation / test A / test B的拆分,RefCOCOg只拆分了train / validation集合。

The blue and red bounding boxes are correct and incorrect comprehension respectively, while the green boxes indicate the ground-truth regions.
藍色和紅色的邊框分別表示正確和錯誤的理解,而綠色的邊框則表示真實區域。

下圖中,紅色表示真實框,藍色表示預測框

評測指標
Precision@0.5 [Prec@0.5]: 對于REC和短語定位,我們使用Precision@0.5評估性能。如果預測框與ground-truth框的IoU大于0.5,則認為預測是正確的。
Precision@(F 1 _1 1?=1, IoU ≥ 0.5 \ge0.5 ≥0.5) [Prec@(F 1 _1 1?=1, IoU ≥ 0.5 \ge0.5 ≥0.5)]: 計算在IoU閾值為0.5時F 1 _1 1?得分為1的樣本百分比。如果一個預測邊界框與ground-truth邊界框匹配且IoU ≥ 0.5 \ge0.5 ≥0.5,則認為它是TP。如果多個預測邊界框與一個ground-truth邊界框匹配,則只有IoU最高的那個被視為TP,其余的為FP。沒有匹配預測邊界框的ground-truth邊界框為FN,而沒有匹配ground-truth邊界框的預測邊界框為FP。樣本的F 1 _1 1?得分計算公式為F 1 _1 1? = 2 T P 2 T P + F N + F P \frac{2TP}{2TP+FN+FP} 2TP+FN+FP2TP?。如果樣本的F 1 _1 1?得分為1,則認為樣本被成功預測。對于沒有目標的樣本,如果沒有預測邊界框,則F 1 _1 1?得分為1,否則為0。然后將成功預測樣本的比例計算為Precision@(F 1 _1 1?=1, IoU ≥ 0.5 \ge0.5 ≥0.5)。
N-acc: 無目標準確率 (N-acc) 評估模型識別沒有目標的樣本的能力。在一個無目標樣本中,沒有預測邊界框為TP,否則為FN。N-acc計算公式為 T P T P + F N \frac{TP}{TP+FN} TP+FNTP?,反映了模型在識別無目標樣本方面的性能。
- 核心概念:框和重疊度
- Ground-truth box (真實框): 這是“正確答案”,是人工標記的指代實例位置的框。
- Predicted box (預測框): 這是模型推理后自己畫出來的框。
- IoU (Intersection over Union,交并比): 這是衡量你的預測框畫得有多準的關鍵。它計算的是你的預測框和真實框“重疊區域”的大小除以它們“總共占有的區域”的大小。
IoU = 重疊區域面積 總區域面積(預測框與真實框的并集面積) \text{IoU} = \frac{\text{重疊區域面積}}{\text{總區域面積(預測框與真實框的并集面積)}} IoU=總區域面積(預測框與真實框的并集面積)重疊區域面積?
IoU 的值在 0 到 1 之間。IoU 越接近 1,說明你的預測框和真實框重疊得越多,畫得越準。IoU 為 0 表示完全沒有重疊,IoU 為 1 表示完全重合。
- Precision@0.5 [Prec@0.5]:以0.5重疊度為標準的準確率
- 這個指標關注的是模型“找對”的預測。
- 它設定了一個門檻:如果你的預測框和某個真實框的 IoU 大于 0.5,我們就認為這個預測是“正確的”(True Positive, TP 的一種判斷標準)。你的框至少要和指代實例的實際位置有超過一半的重疊,才算你找到了。
- Precision@0.5 是衡量在這種“大于0.5重疊”的條件下,模型預測的準確程度。它通常可以理解為:在模型所有聲稱找到了指代實例的預測中,有多少是真正找到了(IoU > 0.5)。(雖然原文沒有直接給出 Precision@0.5 的公式,但在檢測任務中,通常是 TP / (TP + FP),這里的 TP 就是指 IoU > 0.5 的預測。)
- Precision@(F 1 _1 1?=1, IoU ≥ 0.5 \ge0.5 ≥0.5) [Prec@(F 1 _1 1?=1, IoU ≥ 0.5 \ge0.5 ≥0.5)]:以IoU ≥ 0.5 \ge0.5 ≥0.5為標準,F 1 _1 1?得分為1的樣本比例
- 這個指標更嚴格,它不只看單個預測是否正確,而是看整個樣本(一張圖片)的指代定位任務完成得有多好。
- 這里引入了 TP, FP, FN 來衡量整個樣本的預測情況:
- TP (True Positive,真陽性): 模型成功找到并正確圈出了一個指代實例(預測框與真實框匹配且 IoU ≥ 0.5 \ge0.5 ≥0.5 )。如果一個真實框有多個預測框匹配,只算 IoU 最高的那個是 TP。
- FP (False Positive,假陽性): 模型圈了一個框,但那個位置根本沒有指代實例(預測框沒有匹配的真實框),或者它圈錯了(匹配的真實框已經被更高 IoU 的預測框“認領”了)。這是“誤報”。
- FN (False Negative,假陰性): 指代實例就在那里(有一個真實框),但模型沒有找到它(沒有預測框與它匹配)。這是“漏報”。
- F 1 _1 1? Score: 這是一個綜合 Precision(準確率,衡量誤報少不多)和 Recall(召回率,衡量漏報少不多)的指標。F 1 _1 1?得分高意味著模型既少誤報也少漏報。公式是 F 1 _1 1? = 2 T P 2 T P + F N + F P \frac{2TP}{2TP+FN+FP} 2TP+FN+FP2TP?。
- F 1 _1 1? = 1: 意味著完美!TP 很高,而 FP 和 FN 都為 0。也就是說,模型找到了所有的指代實例,而且一個多余的、錯的框都沒有畫。
- 指標含義: Precision@(F 1 _1 1?=1, IoU ≥ 0.5 \ge0.5 ≥0.5) 計算的是:在所有圖片中,有多少張圖片模型能夠完美地完成任務(即 F 1 _1 1? 得分為 1,基于 IoU ≥ 0.5 \ge0.5 ≥0.5 的判斷標準)。對于沒有指代實例的圖片,如果沒有畫任何框,F 1 _1 1? 也算 1;如果畫了框,F 1 _1 1? 算 0。這個指標衡量的是模型在多大程度上能夠在一個樣本內做到“一個不漏,一個不錯”。
- N-acc (No-target accuracy,無指代實例準確率):
-
這個指標專門關注那些圖片中根本沒有指代實例的情況。
-
模型的任務是識別出“這里什么都沒有”。
-
這里的 TP 和 FN 定義針對的是“沒有預測框”這個行為:
- TP (True Positive): 在一張沒有指代實例的圖片里,模型沒有畫任何框。這是正確的判斷。
- FN (False Negative): 在一張沒有指代實例的圖片里,模型畫了框。這是錯誤的判斷(誤以為有指代實例)。
-
指標含義: N-acc = T P T P + F N \frac{TP}{TP+FN} TP+FNTP?。這計算的是在所有沒有指代實例的圖片中,模型成功判斷出“沒有指代實例”的比例。它衡量模型識別空白場景的能力。
-
Precision@0.5 看的是模型畫出來的單個框有多大比例是有效地找到了目標(重疊度超過0.5)。
-
Precision@(F 1 _1 1?=1, IoU ≥ 0.5 \ge0.5 ≥0.5) 看的是模型在多大比例的圖片上能夠完美地(既不漏也不錯地,基于0.5重疊度)完成指代檢測任務。這是一個更嚴格的整體任務完成度指標。
-
N-acc 專門評估模型在沒有目標出現時,能否正確地判斷出“什么都沒有”。
其他實驗細節
通用的模型描述:訓練 SimVG,對于 REC(指代表達式理解)和短語定位任務,訓練 30 個 epoch;對于 GREC 任務,訓練 200 個 epoch。所有這些訓練都使用批量大小為 32。遵循標準做法,圖像被調整大小至 640×640,并且所有數據集的語言表達式長度都被截斷至 20。對于預訓練階段,SimVG 訓練 30 個 epoch,然后進行額外的 10 個 epoch 的微調。預訓練實驗在 8 塊 NVIDIA RTX 3090 GPU 上運行。所有其他實驗在 2 塊 NVIDIA RTX 4090 GPU 上進行。
- 通用設置:
- 所有消融實驗使用 512×512 尺寸的圖像作為輸入。
- 所有訓練均不使用指數移動平均 (EMA) 策略。
- 基礎模型 (SimVG-base):
- 通用的模型描述適用于 SimVG-base 模型。
- 蒸餾參數設置為 λ 1 = 2 \lambda_1 = 2 λ1?=2 和 λ 2 = 1 \lambda_2 = 1 λ2?=1。
- 大型模型:
- 由于內存使用量較高,所有大型模型都使用大小為 4 的批量進行訓練。
- 解碼器的投影輸入維度從 768 增加到 1024。
- 其他設置(除批量大小、解碼器維度和 epoch 數外)與基礎模型保持一致。
- 蒸餾參數設置為 λ 1 = 1 \lambda_1 = 1 λ1?=1 和 λ 2 = 0.4 \lambda_2 = 0.4 λ2?=0.4。
- 訓練 Epoch 數調整:
- ViT-B 兩階段蒸餾實驗: 額外增加 20 個 訓練 epoch。
- 大型模型預訓練實驗 (如表 3):
- 總訓練 epoch 數從 30 減少到 20 (由于訓練成本增加)。
- Token 分支蒸餾 epoch 數從 20 減少到 10。
- SimVG 不同變體的結果獲取方式:
- SimVG-TB: 結果是通過在兩階段蒸餾過程中使用 DWBD 獲得的。
- SimVG-DB: 結果是通過使用 ground truth 監督解碼器分支 獲得的。
- 特定實驗設置:
- GREC 實驗: 將對象查詢 (Object Queries) 的數量設置為 10。
- 特別強調:
- 本文使用的 BEiT-3 預訓練模型未在用于本研究驗證的六個數據集上進行訓練。
2. 方法部分
將圖文理解與下游任務解耦
In this paper, we improve the performance of visual grounding by decoupling multi-modal fusion from downstream tasks into upstream VLP models
在本文中,我們通過將多模態融合從下游任務解耦到上游 VLP 模型中,提高了視覺 Grounding 的性能。
we re-examine the visual grounding task by decoupling image-text mutual understanding from the downstream task. We construct a simple yet powerful model architecture named SimVG, which leverages the existing research in multimodal fusion to fully explore the contextual associations between modalities
我們通過將圖像-文本相互理解與下游任務解耦,重新審視了視覺定位任務。我們構建了一個簡單而強大的模型架構,命名為 SimVG,它利用了多模態融合領域的現有研究,以充分探索不同模態之間的上下文關聯。
-
多模態融合 (Multi-modal fusion): 這是指將不同模態(這里主要是圖像和文本)的信息結合起來的過程。在視覺 Grounding 中,就是要融合圖像內容和文本描述,以便理解文本指的是圖像中的哪個物體。
-
下游任務 (Downstream tasks): 指的是我們最終要解決的特定問題,在這里就是視覺 Grounding 這個任務本身。模型的目標是根據圖像和文本,輸出目標物體的邊界框。
-
上游 VLP 模型 (Upstream VLP models): VLP 是 Vision-Language Pre-trained Models 的縮寫,即視覺-語言預訓練模型。這些模型通常是在大量的圖像-文本數據上進行預訓練的,學習圖像和文本之間的通用關系和表示。它們是“上游”的,因為它們的訓練發生在具體的下游任務(如視覺 Grounding)之前。VLP 模型本身就已經具備了一定的多模態融合和理解能力。
-
解耦 (Decoupling): 指的是將本來緊密聯系的兩部分分開。在這里,就是把“多模態融合”這個能力,從“視覺 Grounding 這個具體任務的模型”中分離開來。
傳統的視覺 Grounding 方法通常是在構建解決視覺 Grounding 任務的模型時,順便在模型的某些層里面進行圖像和文本的融合。這種融合是為了視覺 Grounding 這個特定任務而設計的,并且訓練時主要依賴視覺 Grounding 數據集。
在論文中提出的 SimVG中則不是這樣。它利用了已經預訓練好的、強大的 VLP 模型(也就是“上游 VLP 模型 [64]”)本身就具備的多模態融合能力。換句話說,模型不再自己從零開始或者用有限的數據學習如何融合圖像和文本,而是借用了上游 VLP 模型在大規模數據上學到的、更通用的融合能力。
通過這種方式,將多模態融合這個復雜的步驟,“解耦”出來,讓它主要由強大的上游 VLP 模型來完成,而不是讓下游的視覺 Grounding 模型自己負擔這個任務。這樣可以利用 VLP 模型在大規模預訓練中獲得的更強大和通用的多模態理解能力,從而提高視覺 Grounding 在處理復雜情況(比如長文本描述)時的性能。
就像是:
- 傳統方法:找一個普通的工人,教他怎么同時看圖和看文字來找東西(融合和下游任務是綁定的)。
- 新方法:找一個已經學會了如何很好地理解圖片和文字關系的專家(上游 VLP 模型),然后讓他在找東西這個具體任務上發揮這個能力(融合從下游任務中解耦出來,由專家來做)。
Unlike previous methods that guide a lightweight student model using a pre-trained teacher model, this paper introduces knowledge distillation during synchronous learning to enhance the performance of the lightweight branch.
與以往利用預訓練教師模型指導輕量級學生模型的方法不同,本文在同步學習過程中引入了知識蒸餾,以提升輕量級分支的性能。
在機器學習(特別是在深度學習模型訓練)的上下文中,“同步學習” (Synchronous Learning) 通常指的是 同時訓練模型或模型的多個組成部分(例如,不同的分支或多個獨立的模型),并且這些組成部分在訓練過程中 以協調一致的方式進行更新或交互。
這種蒸餾方法與傳統的順序訓練(比如,先完全訓練一個模型,再用它的輸出去訓練另一個模型)不同,同步學習意味著多個部分是 一起、并行 地進行訓練的。
“同步學習中的知識蒸餾” 意味著:
- 教師模型和學生模型(輕量級分支)是同時被訓練的。參數更新是同步進行的,或者至少它們的訓練過程是同時啟動并進行的,且通過知識蒸餾信號相互影響。(其實作者也有采用兩階段的蒸餾方法,即也會預先訓練一下教師模型)
- 在訓練的每一步或每隔一定的步數,教師模型會將其知識(通常是其輸出的概率分布,即軟目標)傳遞給學生模型。
- 學生模型的損失函數在包含自身對真實標簽的損失的同時,也包含了與教師模型輸出之間的蒸餾損失。
The decoder is divided into two branches: one is similar to the transformer decoder in DETR (decoder branch), and the other utilizes a lightweight MLP (token branch). The head is referred to as the “Distillation Head”. Unlike conventional prediction heads, to reduce the performance gap between the token and decoder branches, we employ a dynamic weight-balance distillation (DWBD) to minimize the performance difference between the two branches during synchronous learning.
解碼器被分為兩個分支:一個類似于 DETR 中的 Transformer 解碼器(稱為解碼器分支),另一個則使用輕量級 MLP(稱為 token 分支)。頭部被稱為“蒸餾頭”。與傳統的預測頭部不同,為了減少 token 分支和解碼器分支之間的性能差距,我們在同步學習過程中采用了一種動態權重平衡蒸餾(DWBD)來最小化兩個分支的性能差異。
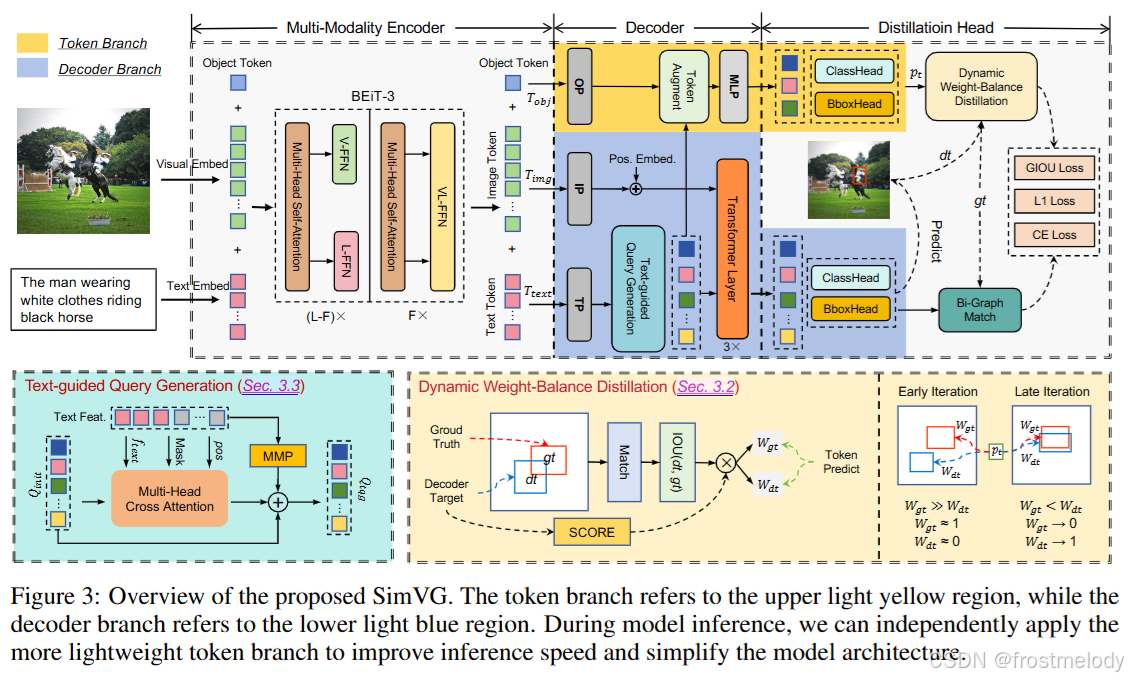
多模態編碼器

多模態編碼器: SimVG 的輸入包括一個圖像 I ∈ R 3 × H × W I \in \mathbb{R}^{3 \times H \times W} I∈R3×H×W 和一段描述文本 T ∈ Ω M = { t 1 , t 2 , . . . , t M } T \in \Omega^M = \{t^1, t^2, ..., t^M\} T∈ΩM={t1,t2,...,tM},其中 Ω \Omega Ω 表示詞匯集合。首先,使用視覺嵌入將圖像壓縮到原始尺寸的 1/32,得到 P i m g = { p 1 , p 2 , . . . , p N } P_{img} = \{p^1, p^2, ..., p^N\} Pimg?={p1,p2,...,pN}。然后將文本映射到向量空間 L t e x t = { l 1 , l 2 , . . . , l K } L_{text} = \{l^1, l^2, ..., l^K\} Ltext?={l1,l2,...,lK} 和一個文本填充掩碼 L m a s k = { l m 1 , l m 2 , . . . , l m K } L_{mask} = \{l^1_m, l^2_m, ..., l^K_m\} Lmask?={lm1?,lm2?,...,lmK?}。此外,我們定義一個可學習的對象 token T o b j T_{obj} Tobj? 作為 token 分支的目標特征。Transformer 的 query 和注意力填充掩碼可以生成為:
Query = { T o b j , p 1 , . . . , p N , l 1 , . . . , l K } \{T_{obj}, p^1, ..., p^N, l^1, ..., l^K\} {Tobj?,p1,...,pN,l1,...,lK},Mask = { T o b j m , p m 1 , . . . , p m N , l m 1 , . . . , l m K } \{T_{obj_m}, p^1_m, ..., p^N_m, l^1_m, ..., l^K_m\} {Tobjm??,pm1?,...,pmN?,lm1?,...,lmK?}。(1)
在圖像沒有填充的情況下, T o b j m T_{obj_m} Tobjm?? 和 { p m 1 , p m 2 , . . . , p m N } \{p^1_m, p^2_m, ..., p^N_m\} {pm1?,pm2?,...,pmN?} 被設置為 0。在獨立的編碼部分,FFN 采用圖像和文本模態之間不共享權重的設置,而其余部分與原始的 ViT 模型大致相同。
解碼器分支,Token分支,蒸餾頭

解碼器分支: 我們首先使用一個不共享權重的線性層,映射圖像 token T i m g ∈ R H 32 × W 32 × C T_{img} \in \mathbb{R}^{\frac{H}{32} \times \frac{W}{32} \times C} Timg?∈R32H?×32W?×C 和文本 token T t e x t ∈ R N t e x t × C T_{text} \in \mathbb{R}^{N_{text} \times C} Ttext?∈RNtext?×C 的通道維度。然后,在文本側,我們應用文本引導查詢生成(TQG)模塊,使預定義的對象查詢 Q o b j ∈ R N o b j × C Q_{obj} \in \mathbb{R}^{N_{obj} \times C} Qobj?∈RNobj?×C 與文本 token 進行交互。在圖像側,應用額外的全局位置編碼。最后,通過 Transformer 模塊執行交叉注意力交互。整個過程可以表示為:
Q d e c o d e r = MCA ( IP ( T i m g ) + pos , TQG ( TP ( T t e x t ) , Q o b j ) ) Q_{decoder} = \text{MCA}(\text{IP}(T_{img}) + \text{pos}, \text{TQG}(\text{TP}(T_{text}), Q_{obj})) Qdecoder?=MCA(IP(Timg?)+pos,TQG(TP(Ttext?),Qobj?)),(2)
其中 TP 和 IP 指文本投影和圖像投影。MCA 指多頭交叉注意力。pos 指位置編碼,它應用 2D 絕對正弦編碼。
Token 分支: 我們采用一個線性層 OP 來投影對象 token T o b j ∈ R 1 × C T_{obj} \in \mathbb{R}^{1 \times C} Tobj?∈R1×C,并使用 TQG 的結果來增強對象 token。最后,我們使用一個 MLP 層來進一步交互并豐富對象 token 的表示。這個分支的過程可以定義為:
Q t o k e n = MLP ( OP ( T o b j ) + TQG ( TP ( T t e x t ) , Q o b j ) ) Q_{token} = \text{MLP}(\text{OP}(T_{obj}) + \text{TQG}(\text{TP}(T_{text}), Q_{obj})) Qtoken?=MLP(OP(Tobj?)+TQG(TP(Ttext?),Qobj?))。(3)
蒸餾頭: 我們對解碼器分支采用與 DETR [2] 相同的匈牙利匹配。匹配成本包含三部分:二元交叉熵損失、L1 損失和 giou 損失 [54]。然而,為了進一步簡化推理流程,我們在整個訓練過程中使用解碼器分支作為教師來指導 token 分支的學習。因此,完整的損失可以表示為:
L t o t a l = L d e t ( p d , g t ) + L d w b d L_{total} = L_{det}(p_d, gt) + L_{dwbd} Ltotal?=Ldet?(pd?,gt)+Ldwbd?, L d e t = λ 1 L c e + λ 2 L l 1 + λ 3 L g i o u L_{det} = \lambda_1 \mathcal{L}_{ce} + \lambda_2 \mathcal{L}_{l1} + \lambda_3 \mathcal{L}_{giou} Ldet?=λ1?Lce?+λ2?Ll1?+λ3?Lgiou?,(4)
其中 λ 1 \lambda_1 λ1?, λ 2 \lambda_2 λ2?, 和 λ 3 \lambda_3 λ3? 分別設置為 1, 5, 和 2。 p d p_d pd? 指解碼器分支的預測。 L d w b d L_{dwbd} Ldwbd? 指動態權重平衡蒸餾損失,這將在下一部分解釋。
Dynamic Weight-Balance Distillation(DWBD)


為了使 SimVG 同時具有效率和有效性,引入了知識蒸餾,它利用解碼器分支的預測作為教師來指導 token 分支的預測。由于這兩個分支共享多模態編碼器的特征,使用傳統的知識蒸餾方法獨立訓練教師模型是不可行的。取而代之的是,我們對兩個分支采用了同步學習的方法。這種方法需要一個精妙的平衡,確保教師模型的性能不會受到影響,同時最大化知識從教師分支到學生分支的轉移。
核心思想:
- 用一個更強的分支(解碼器分支)來動態地指導一個更輕量的分支(token 分支)學習,讓它們在同步訓練中共同進步。
- 兩個學生同時學習,一個學得比較快(解碼器分支),另一個學得慢一些(token 分支)。DWBD 的目標就是讓學得快的學生在學習過程中,也能去輔導學得慢的學生。兩個分支共享前面的特征(多模態編碼器)
- 作者希望輕量的 token 分支也能學好,最好能接近復雜解碼器分支的性能。所以在它們一起訓練時,需要一種機制讓強的指導弱的。
DWBD 是怎么指導的?
- 引入一個特殊的損失項 L d w b d L_{dwbd} Ldwbd?: DWBD 主要體現在總損失函數中多了一個 L d w b d L_{dwbd} Ldwbd? 項。這個項專門用來衡量 token 分支的學習是否得到了有效的指導。
- 兩種指導來源: L d w b d L_{dwbd} Ldwbd? 并不是只讓 token 分支模仿解碼器的預測,它結合了兩種信息:
- Token 分支預測 p t p_t pt? 對比 解碼器分支的“目標” ( d t dt dt) 的損失 L d e t ( p t , d t ) L_{det}(p_t, dt) Ldet?(pt?,dt)。這個“目標”是解碼器分支通過匈牙利匹配的方式找到的與地面真實匹配后的預測結果,可以看作是解碼器學習到的更精細、更接近目標的表示。
- Token 分支預測 p t p_t pt?對比 地面真實 g t gt gt的損失 L d e t ( p t , g t ) L_{det}(p_t, gt) Ldet?(pt?,gt)。這是最直接的標準答案。
- 動態權重平衡(Dynamic Weight-Balance)是關鍵: DWBD 的名字就包含了“動態權重平衡”。它不是簡單地將上面兩種損失相加,而是給它們乘以動態變化的權重 ( W d t W_{dt} Wdt? 和 W g t W_{gt} Wgt?)。
- L d w b d = γ 1 ( W d t × L d e t ( p t , d t ) ) + γ 2 ( W g t × L d e t ( p t , g t ) ) L_{dwbd} = \gamma_1(W_{dt} \times L_{det}(p_t, dt)) + \gamma_2(W_{gt} \times L_{det}(p_t, gt)) Ldwbd?=γ1?(Wdt?×Ldet?(pt?,dt))+γ2?(Wgt?×Ldet?(pt?,gt))
- W g t = 1 ? W d t W_{gt} = 1 - W_{dt} Wgt?=1?Wdt?
- γ 1 \gamma_1 γ1? 和 γ 2 \gamma_2 γ2? 是固定的系數(論文里設為 2 和 1),用來調整兩種損失項的整體比例。
因此,我們設計了一種動態權重平衡蒸餾(DWBD),其架構如圖 3 所示。我們將地面真實(ground truth)記為 y i y_i yi?,將 N q N_q Nq? 個解碼器預測集合記為 y ^ d = { y ^ i d } i = 1 N q \hat{y}^d = \{\hat{y}_i^d\}_{i=1}^{N_q} y^?d={y^?id?}i=1Nq??。為了在這兩個集合之間找到二分匹配,我們尋找一個具有最低成本的、 N q N_q Nq? 個元素的排列 σ ∈ Σ N q \sigma \in \Sigma_{N_q} σ∈ΣNq??:
σ ^ = ARGMIN σ ∈ Σ N q ∑ i N q L match ( y i , y ^ σ ( i ) d ) \hat{\sigma} = \text{ARGMIN}_{\sigma \in \Sigma_{N_q}} \sum_{i}^{N_q} \mathcal{L}_{\text{match}}(y_i, \hat{y}_{\sigma(i)}^d) σ^=ARGMINσ∈ΣNq???∑iNq??Lmatch?(yi?,y^?σ(i)d?),(5)
其中 L match ( y i , y ^ σ ( i ) d ) \mathcal{L}_{\text{match}}(y_i, \hat{y}_{\sigma(i)}^d) Lmatch?(yi?,y^?σ(i)d?) 是地面真實 y i y_i yi? 與索引為 σ ( i ) \sigma(i) σ(i) 的預測之間的成對匹配成本。配對后,下一步是評估解碼器分支在當前階段的理解能力。這是通過衡量解碼器目標 d t dt dt (解碼器分支的預測中,與某個地面真實(ground truth, g t gt gt)目標成功匹配(paired)的那個預測結果。)和地面真實 g t gt gt 的聯合目標框基于其配對的 IOU 的置信度來完成的:
W d t = 1 N g t ∑ i N g t [ IOU ( b t i , b σ ^ ( i ) d ) × SCORE ( p ^ σ ^ ( i ) d ) ] W_{dt} = \frac{1}{N_{gt}} \sum_{i}^{N_{gt}} [\text{IOU}(b_{ti}, b_{\hat{\sigma}(i)}^d) \times \text{SCORE}(\hat{p}_{\hat{\sigma}(i)}^d)] Wdt?=Ngt?1?∑iNgt??[IOU(bti?,bσ^(i)d?)×SCORE(p^?σ^(i)d?)],(6)
其中 N g t N_{gt} Ngt? 是地面真實框的數量,SCORE 表示從預測中提取的前景得分。 W d t W_{dt} Wdt? 可以看作當前階段解碼器分支能力的反映,值越高表示置信度越強。最后, L d w b d L_{dwbd} Ldwbd? 可以表達為:
L d w b d = γ 1 ( W d t × L d e t ( p t , d t ) ) + γ 2 ( W g t × L d e t ( p t , g t ) ) L_{dwbd} = \gamma_1(W_{dt} \times L_{det}(p_t, dt)) + \gamma_2(W_{gt} \times L_{det}(p_t, gt)) Ldwbd?=γ1?(Wdt?×Ldet?(pt?,dt))+γ2?(Wgt?×Ldet?(pt?,gt)), W g t = 1 ? W d t W_{gt} = 1 - W_{dt} Wgt?=1?Wdt?,(7)
權重 ( W d t W_{dt} Wdt?, W g t W_{gt} Wgt?) 是如何動態變化的?
- 衡量解碼器能力 W d t W_{dt} Wdt?: W d t W_{dt} Wdt? 是一個動態計算出來的數值,用來衡量解碼器分支在 當前訓練階段 的能力或置信度。它是根據解碼器的預測框與地面真實框的 IOU(交并比)和得分計算出來的。解碼器預測得越準、得分越高, W d t W_{dt} Wdt? 就越大,表示解碼器當前能力越強,越值得信任。
- 權重的含義:
- W d t W_{dt} Wdt? 越大,乘以它的項 ( W d t × L d e t ( p t , d t ) W_{dt} \times L_{det}(p_t, dt) Wdt?×Ldet?(pt?,dt)) 的權重就越大,這意味著 token 分支更多地跟著 解碼器目標 學習。
- W g t = 1 ? W d t W_{gt} = 1 - W_{dt} Wgt?=1?Wdt?。 W d t W_{dt} Wdt? 越大, W g t W_{gt} Wgt? 就越小。這意味著 token 分支跟著 地面真實 學習的權重會變小。
- 動態調整的過程:
- 訓練早期: 解碼器分支剛開始訓練,能力還比較弱, W d t W_{dt} Wdt? 會比較小, W g t W_{gt} Wgt? 會比較大。此時, L d w b d L_{dwbd} Ldwbd? 主要側重于 W g t × L d e t ( p t , g t ) W_{gt} \times L_{det}(p_t, gt) Wgt?×Ldet?(pt?,gt) 這一項,即 token 分支主要依靠 >地面真實 來學習。這是合理的,因為老師(解碼器)還不靠譜時,學生跟著標準答案學最保險。
- 訓練后期: 隨著訓練進行,解碼器分支的能力不斷增強, W d t W_{dt} Wdt? 會變大, W g t W_{gt} Wgt? 會變小。此時, L d w b d L_{dwbd} Ldwbd? 會逐漸側重于 W d t × L d e t ( p t , d t ) W_{dt} \times L_{det}(p_t, dt) Wdt?×Ldet?(pt?,dt) 這一項,即 token 分支更多地向 解碼器學到的精細目標 學習。這是知識蒸餾的核心,讓學生學習老師的知識。
其中 L d e t L_{det} Ldet? 的計算方式與公式 4 完全相同。 p t p_t pt? 指 token 分支的預測。本文中 γ 1 \gamma_1 γ1? 和 γ 2 \gamma_2 γ2? 分別設置為 2 和 1。根據設計,在網絡訓練的早期階段, W g t ? W d t W_{gt} \gg W_{dt} Wgt??Wdt?,整個 token 分支的訓練過程由地面真實指導。然而,在訓練的后期階段, W g t < W d t W_{gt} < W_{dt} Wgt?<Wdt?,來自解碼器目標的指導變得更加重要。這種在訓練過程中權重的動態調整是本文提出的 DWBD 的核心思想。我們將在 4.4.3 節中進一步分析 W d t W_{dt} Wdt? 和 L d w b d L_{dwbd} Ldwbd? 的變化。此外,為了進一步提升 token 分支的性能,我們采用了兩階段的蒸餾方法。在第一階段,我們單獨訓練解碼器分支。在第二階段,我們在同步學習的前提下對兩個分支應用 DWBD。
兩階段訓練的作用
論文提到使用了兩階段訓練:
- 第一階段: 單獨訓練解碼器分支。這可能是為了讓解碼器分支在開始同步訓練(第二階段)之前,就具備一定的基礎能力,不至于在第二階段一開始就是一個完全不懂的“弱雞老師”,這樣動態權重 W d t W_{dt} Wdt? 即使在早期也不會是零,能更好地啟動 DWBD 機制。
- 第二階段: 在同步學習的前提下,應用 DWBD 訓練兩個分支。
- 總結來說,DWBD 設計了一個巧妙的損失函數項,通過動態調整地面真實和解碼器分支目標這兩種指導信號的權重,使得輕量級分支能夠在同步訓練過程中,根據更強分支(解碼器)能力的提升,逐步從主要學習地面真實過渡到更多地學習更強分支提煉出的知識,從而實現有效的知識遷移和性能提升。
Text-guided Query Generation(TQG)

初始對象查詢 Q i n i t Q_{init} Qinit? 是使用可學習嵌入定義的,沒有任何先驗信息來指導它們。從宏觀角度看,視覺定位涉及使用文本作為查詢來定位圖像中的最佳區域。將文本嵌入到查詢中以自適應地提供先驗信息是一種可行的解決方案。因此,我們提出了一個文本引導查詢生成(TQG)模塊,用于生成帶有文本先驗信息(priors)的對象查詢。如圖 3 所示,通過 TQG 生成查詢的過程可以表達為:
Q t q g = MCA ( Q i n i t , f t e x t + pos , Mask ) + MMP ( f t e x t , Mask ) + Q i n i t (8) Q_{tqg} = \text{MCA}(Q_{init}, f_{text} + \text{pos}, \text{Mask}) + \text{MMP}(f_{text}, \text{Mask}) + Q_{init} \quad\text{(8)} Qtqg?=MCA(Qinit?,ftext?+pos,Mask)+MMP(ftext?,Mask)+Qinit?(8)
其中 f t e x t ∈ R K × C f_{text} \in \mathbb{R}^{K \times C} ftext?∈RK×C 是文本投影后的特征,Mask 與公式 1 一致,這里的 pos 是 1D 絕對正弦位置編碼。MMP 是使用 Mask 從 f t e x t f_{text} ftext? 中過濾出有效 token 并應用最大值操作的過程:MMP( f , m f, m f,m) = max ? i [ f i × ( ~ m i ) ] \max_i [f_i \times (\sim m_i)] maxi?[fi?×(~mi?)]。
核心思想:TQG 讓模型在尋找圖像中的目標之前,先通過文本描述來“理解”要找什么,并將這種理解融入到搜索目標用的“查詢”中。
簡單來說,TQG 就像一個“指示器生成器”。它接收一個通用的“去找東西”的請求(初始查詢),然后閱讀“要找什么東西”的說明書(文本特征),最后生成一個更具體的、帶著“去幫我找那個藍色的貓”指令的請求(TQG 生成的查詢),然后再把這個更智能的請求送去模型后面搜索圖片。** 這樣,模型在解碼階段使用這些文本引導過的查詢,就能更高效、更準確地找到與文本描述對應的目標物體。
什么是“對象查詢”(Object Queries)?
在一些現代的檢測模型(比如 DETR 及其變體,SimVG 參考了 DETR 的一些思想)中,模型不是直接在圖片的所有位置進行預測,而是使用一組特殊的向量,稱為“對象查詢”(Object Queries)。這些查詢向量可以看作是模型內部發出的“請幫我找一個潛在物體”的請求。解碼器部分會利用這些查詢去“掃描”圖像特征,并為每一個查詢預測一個可能的物體(它的位置、類別等)。
論文中提到,初始的對象查詢 Q i n i t Q_{init} Qinit? 只是簡單的、可學習的向量,它們本身不包含任何關于“要找什么”的先驗信息。它們是通用的“占位符”。
問題:視覺定位需要“文本先驗”
在視覺定位任務中,模型需要根據一段文本描述來找到圖片中對應的物體。這意味著文本描述本身就包含了關于目標物體的關鍵信息(比如物體的類型、顏色、位置關系等)。如果能把這些文本信息用到“對象查詢”中,讓查詢在去看圖片之前就帶著這些提示,豈不是更好?這就是“文本先驗”(text priors)的概念。
TQG 的作用:將文本信息注入查詢
TQG 模塊的目的就是解決上述問題:它接收初始的、不帶偏見的對象查詢 ( Q i n i t Q_{init} Qinit?),并利用文本描述的特征 ( f t e x t f_{text} ftext?),生成新的、帶有文本先驗信息、更有針對性的對象查詢 ( Q t q g Q_{tqg} Qtqg?)。
TQG 是怎么工作的
- 輸入: 初始對象查詢 ( Q i n i t Q_{init} Qinit?) 和文本的特征表示 ( f t e x t f_{text} ftext?,以及它的位置編碼 p o s pos pos 和掩碼 Mask)。
- 關鍵步驟:
- 交叉注意力 (MCA): TQG 使用一個多頭交叉注意力機制。這里的操作是讓 初始對象查詢 ( Q i n i t Q_{init} Qinit?) 去關注 文本特征 ( f t e x t + p o s f_{text} + pos ftext?+pos)。這就像讓那些通用的查詢“閱讀”一遍文本描述,從中提取與尋找目標相關的信息,并融入到查詢本身的表示中。掩碼 (Mask) 用于確保只關注有效的文本部分,忽略填充符。
- 文本特征聚合 (MMP): 還有一個 MMP 操作,它從文本特征中提取一個代表性的特征(通過對有效 token 進行最大值操作。最大值操作通常是沿著序列的維度進行的,也就是對所有有效 token 的 同一個維度 的值進行比較,選出最大的那個值。)。這可以看作是文本信息的一種全局或重點摘要。
- 輸出: 最終的文本引導查詢 ( Q t q g Q_{tqg} Qtqg?) 是由 初始查詢 ( Q i n i t Q_{init} Qinit?)、交叉注意力后得到的查詢(包含了從文本中提取的信息)以及 文本特征聚合結果 相加得到的(公式 8)。這意味著新的查詢結合了原始查詢的通用性、從文本中學習到的具體信息以及文本的概括性特征。
3. 實驗部分
主實驗
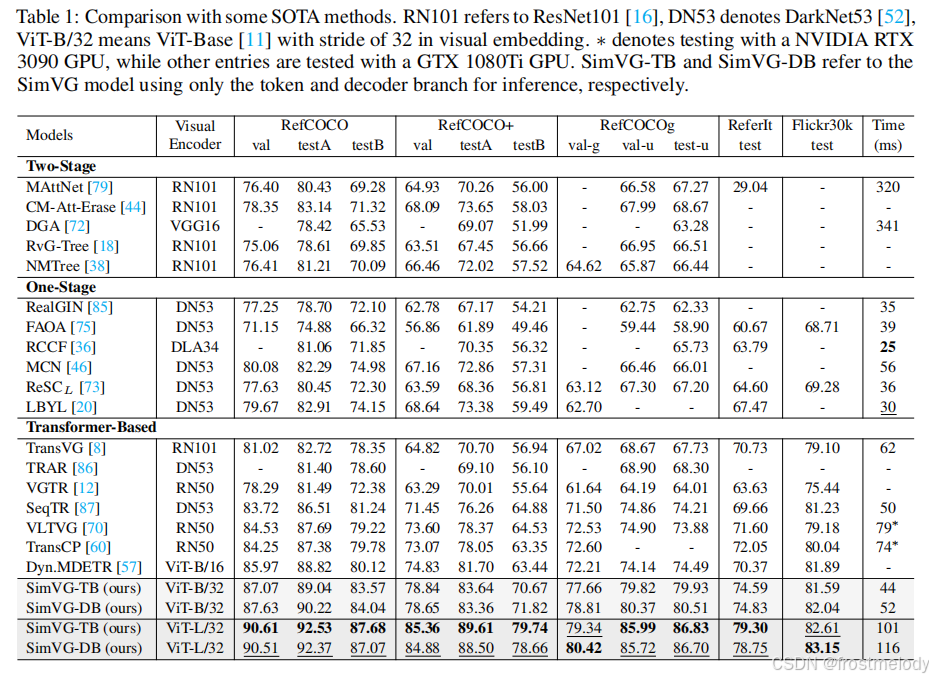
- SimVG 與六個主流數據集上的 SOTA(最先進)方法進行了比較。我們將 RefCOCO/+/g、ReferItGame 和 Flickr30K 數據集的結果合并呈現在表 1 中,而 GREC 的結果則在表 2 中報告。表 3 報告了在大型語料庫數據上進行預訓練的結果。
- 將模型從基礎版本擴展到大型版本,在所有數據集上都帶來了顯著提升。
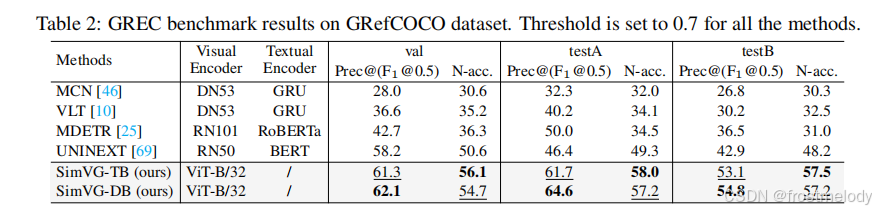
- SimVG 可以無縫擴展到 GREC 任務,無需任何網絡修改。如表 2 所示,SimVG 在 GRefCOCO 數據集上相較于現有公開可用方法實現了顯著提升,平均提高了 9 個百分點,超越了 UNINEXT
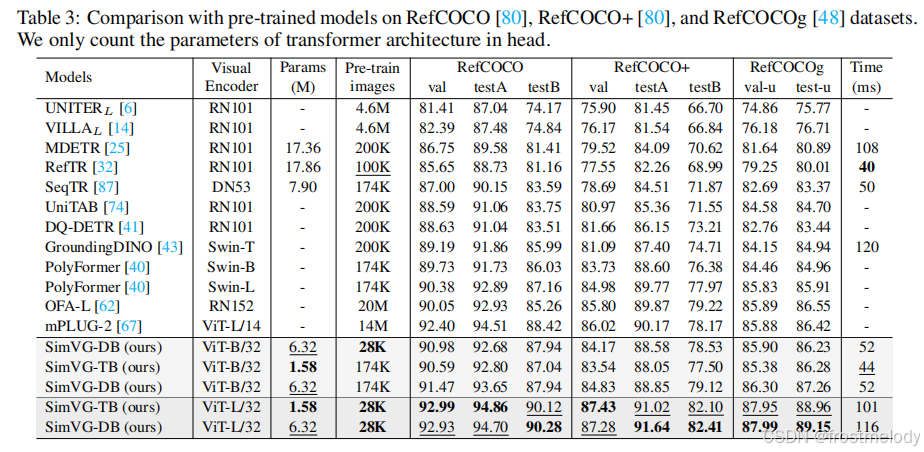
- 在大型圖文對語料庫上進行預訓練時,與大多數現有 SOTA 方法相比,SimVG 表現出更高的數據效率。盡管僅使用了 28K 張圖像,這比 MDETR少了近六倍,比 RefTR 少了三倍,SimVG 仍然達到了 SOTA 性能,大幅度超越了大多數現有方法。與 MDETR 相比,SimVG 平均提升了 5 個百分點;與最近的 SOTA 模型 GroundingDINO 相比,平均提升了 2 個百分點。此外,增加預訓練數據量進一步提升了性能。
- SimVG 在頭部應用了更輕量的 Transformer 結構。具體而言,SimVG-TB 僅使用 1.58 百萬參數,這比一些輕量級模型更小。最后,我們觀察到,將多模態編碼器從 ViT-B 擴展到 ViT-L 后,輕量級 token 分支的性能超越了其教師模型。我們假設,隨著模型規模的增大,解碼器分支性能的可靠性提高,有助于減輕錯誤標注 ground truth 數據的影響。這反過來又增強了 token 分支的泛化能力,進一步證明了 DWBD 方法的有效性。
消融實驗
1. Multi-Modality Encoder Architecture
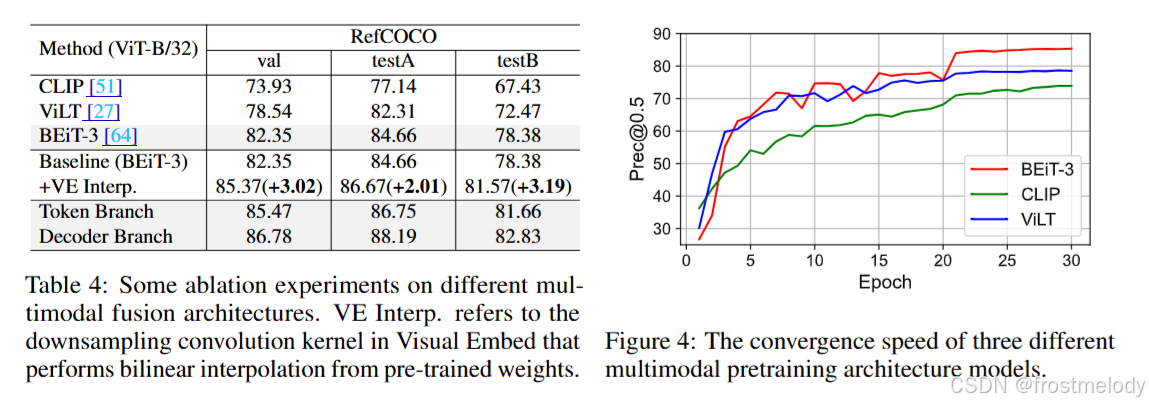
- 為了研究將多模態融合與視覺 grounding 解耦的優勢,我們設計了三種架構進行實驗驗證。為確保公平性,我們一致采用 ViT-B/32 模型進行特征提取,并使用 VGTR的頭部進行預測。“CLIP”代表一種典型的雙流多模態預訓練結構。“ViLT”代表一種單流多模態融合方法。“BEiT-3”代表一種帶有融合編碼器的雙流方法。實驗結果報告在表 4 中。像 ViLT 和 BEiT-3 這樣將多模態融合過程與下游任務解耦的方法,相較于采用多模態獨立編碼器架構的方法顯示出顯著提升。
- ViLT 和 BEiT-3 通過解耦多模態融合,表現出顯著加速的收斂。相比之下,盡管 CLIP 利用了大量的圖文數據進行預訓練,但它只進行跨模態對齊,而沒有整合圖像和文本模型的信息來獲得融合表示。
- 將原始視覺嵌入的步長從 16 增加到 32 并對卷積核應用雙線性插值,能夠顯著提升性能。這是因為雙線性插值在壓縮后保留了原始特征分布,從而加速了收斂。此外,來自解碼器和 token 分支的實驗結果揭示了顯著的性能差距,突顯了設計動態權重平衡蒸餾(dynamic weight-balance distillation)來緩解這種差異的必要性。
2. Text-guided Query Generation(TQG)
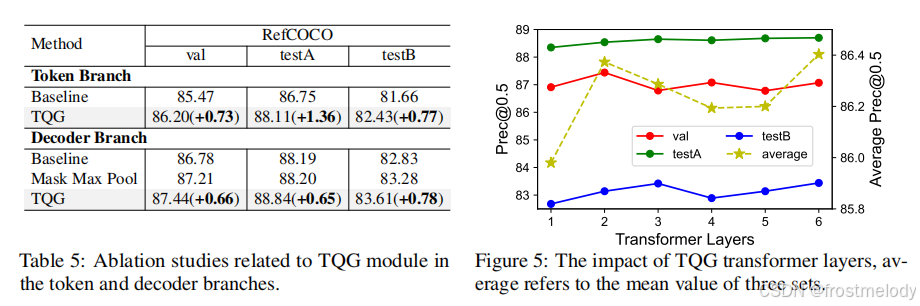
- 如表5所示,實驗結果表明,TQG模塊對token分支和解碼器分支都有明顯的積極影響,平均絕對提升了0.8個點。這種引導機制與DAB-DETR 的概念一致,后者將文本先驗注入查詢中,使其具備指向目標的特性。“Mask Max Pool”涉及使用文本掩碼選擇有效的文本token,然后執行最大池化以壓縮維度,如第3.3節所述。此外,圖5說明了transformer層對TQG的影響。采用2層transformer結構以平衡效率和性能。
3. Dynamic Weight-Balance Distillation(DWBD)
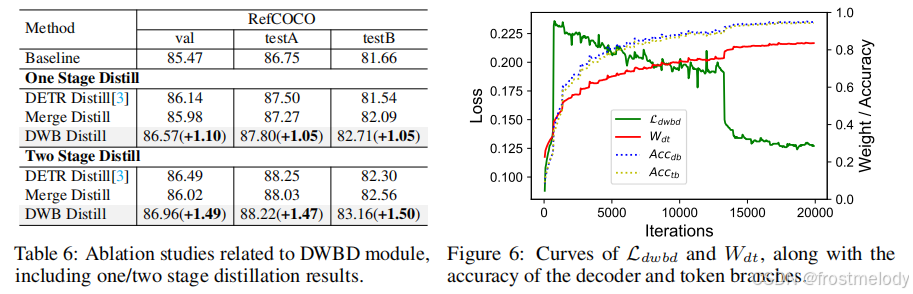
- 蒸餾實驗結果如表6所示,“DETR Distill”使用解碼器分支的預測作為教師進行學習。“Merge Distill”將ground truth與解碼器預測結合,使token分支能夠自適應地選擇匹配的目標。可以看出,所有這三種蒸餾方法都提高了token分支的性能,其中兩階段蒸餾方法進一步提升了其性能。最終,我們提出的DWBD相比基線平均提升了1.5個點。從表1和表3我們觀察到,當使用ViT-L作為教師模型時,輕量級的token分支在同步學習期間,在某些指標上的性能甚至可以超越解碼器分支。我們假設這主要是因為隨著教師認知能力的提高,token分支蒸餾了更魯棒的特征表示。此外,圖6展示了DWBD在訓練過程中的動態平衡過程。我們可以觀察到,隨著解碼器分支置信度的增加,Wdt的值相應升高,這表明解碼器分支為token分支提供了更多的指導。這種機制允許在ground truth和解碼器預測之間動態調整指導分布。
可視化實驗
- 作者從兩個角度對SimVG進行注意力分析,如圖7所示。首先,作者使用GradCAM可視化BEiT-3的多模態表示,生成熱力圖,揭示BEiT-3主要關注全局前景信息。此外,作者還可視化了解碼器的注意力圖,這些圖突出了模型對文本所提及區域的關注。

4. Limitations and Broader Impacts
- 我們的方法未能充分探索或利用特征中的層級信息。可以考慮采用類似ViTDet 中FPN等擴展特征層級的方法,以進一步增強模型捕獲不同尺度目標的能力。我們的方法不僅可以應用于檢測相關任務,還可以應用于分割相關任務。需要對更多的下游任務進行進一步驗證,以證明其穩定的有效性。
- 在使用這項技術時,需要進行進一步的研究和審慎的考慮,因為本文提出的方法依賴于從訓練數據集中提取的統計信息,這些數據集可能存在偏差,并可能導致負面的社會影響。
5. 其他知識附錄
附1:DETR 中的匈牙利匹配
在 DETR 中,匈牙利算法的主要作用是解決預測框與真實框的匹配問題,即在每個訓練步驟中如何正確地將模型輸出的預測框與真實標簽框進行匹配,以便進行有效的損失計算和梯度更新。具體來說,DETR 將目標檢測任務看作集合預測問題,對于一張圖片,固定預測一定數量的物體(原作是100個,在代碼中可更改),模型根據這些物體對象與圖片中全局上下文的關系直接并行輸出預測集,也就是 Transformer 一次性解碼出圖片中所有物體的預測結果。
- 一對一匹配:?每個預測框最多對應一個真實目標,避免多個預測框指向同一個目標。
- 最小化總損失:?通過最優匹配,確保模型關注于最相關的預測與真實目標之間的關系。
- 簡化后處理:?由于匹配過程已經處理了重復預測的問題,DETR 不再需要傳統的非極大值抑制(NMS)步驟。
DETR模型看了一張圖片,然后它“猜”出了圖片里有哪些物體,比如猜出了3個物體(比如一個貓、一個狗、一個杯子)。但是,模型可能猜得不是那么準,比如它可能猜出了4個物體,或者只猜出了2個物體。而且,它猜出的物體位置和真實物體也不完全重合。現在的問題就是:如何把模型猜出的物體(比如4個)和圖片里真實存在的物體(比如3個)對應起來? 也就是說,我們要確定模型猜出的第1個物體對應的是真實的哪個物體?第2個對應哪個?以此類推。匈牙利匹配就是用來解決這個“對應”問題的工具。
1. 二分圖的概念:我們可以把這個問題畫成一個特殊的圖,叫做“二分圖”。
- 圖的一邊(比如左邊)代表模型猜出的所有物體(假設有N個)。
- 圖的另一邊(比如右邊)代表圖片里真實存在的所有物體(假設有M個)。
- 如果模型猜出的某個物體和真實的某個物體比較像(比如位置重疊比較多,或者類別相同),我們就在它們之間畫一條線,這條線代表一種“可能的對應關系”。這條線有一個“分數”,表示這種對應關系有多好(比如可以用IoU,即交并比來衡量)。
2. 匹配的目標:我們的目標是在這個圖上找到一種“最佳對應關系”。
- 每個模型猜出的物體最好能對應到一個真實的物體。
- 每個真實的物體最好能被一個模型猜出的物體對應到。
- 整體上,所有對應關系的“分數”加起來要盡可能大(或者說,對應關系要盡可能“好”)。
3. 匈牙利算法的作用:匈牙利算法就是專門解決這種“二分圖匹配”問題的數學方法。它會計算出一種最優的對應方案,告訴你模型猜出的第1個物體應該對應真實的哪個物體,第2個對應哪個,依次類推,使得整體匹配效果最好。
附2:GIOU
GIoU DIoU CIoU loss 損失函數
IoU、GIoU、DIoU、CIoU損失函數的那點事兒
GIoU(Generalized Intersection over Union) 是一種用于目標檢測任務的性能評估指標和損失函數,旨在改進傳統的 IoU(Intersection over Union),特別是在處理不重疊或形狀差異較大的邊界框時。GIoU 是 IoU 的一個泛化版本,通過引入最小外接矩形,能夠更全面地衡量預測框與真實框之間的相似度,包括重疊程度和相對位置關系,解決了 IoU 在非重疊情況下的局限性。
-
基本概念:
- IoU 是通過計算兩個邊界框(預測框和真實框)的交集面積與并集面積的比值來衡量它們的重疊程度。
- GIoU 在 IoU 的基礎上進行了擴展,引入了包含兩個邊界框的最小凸包(對于矩形框,就是最小外接矩形)的概念。
-
計算方法:
- 首先,計算兩個邊界框 A(預測框)和 B(真實框)的 IoU:
IoU(A, B) = Area(A ∩ B) / Area(A ∪ B)。 - 然后,找到同時包含 A 和 B 的最小凸包 C(最小外接矩形)。
- 最后,計算 GIoU:
GIoU(A, B) = IoU(A, B) - Area(C - (A ∪ B)) / Area(C)。或者更簡潔地表示為:GIoU(A, B) = IoU(A, B) - (Area(C) - Area(A ∪ B)) / Area(C)。
- 首先,計算兩個邊界框 A(預測框)和 B(真實框)的 IoU:
-
核心優勢:
- 衡量距離:與僅關注重疊區域的 IoU 不同,GIoU 不僅考慮了重疊部分,還考慮了兩個框之間的“距離”或“非重疊區域”。當兩個框完全不重疊時,GIoU 的值會小于 0,并且其值能反映它們相距多遠。
- 解決 IoU 梯度消失問題:當預測框和真實框完全不重疊時,IoU 為 0,如果用作損失函數會導致梯度消失,無法有效優化模型。GIoU 在這種情況下仍然可以提供有效的梯度信息,有助于模型學習。
- 更全面的評估:GIoU 能更好地反映兩個邊界框的整體重合程度,即使它們的形狀或方向差異較大。
附3:MMP操作的細節
假設我們有一段經過處理的文本序列及其特征,以及對應的掩碼:
文本序列:[“貓”, “坐”, “墊子”, “[PAD]”, “[PAD]”] (其中 “[PAD]” 是填充符)
對應的 掩碼 (Mask):[1, 1, 1, 0, 0] (1 表示有效 token,0 表示填充符)
假設每個 token 的 特征向量 是一個簡單的 3 維向量(實際模型中維度會高很多,例如 768 維):
- “貓” 的特征 f 1 f_1 f1?: [0.5, 0.1, 0.8]
- “坐” 的特征 f 2 f_2 f2?: [0.6, 0.9, 0.2]
- “墊子” 的特征 f 3 f_3 f3?: [0.7, 0.2, 0.5]
- “[PAD]” 的特征 f 4 f_4 f4?: [0.1, 0.1, 0.1] (填充符的特征值通常不重要,因為會被掩碼忽略)
- “[PAD]” 的特征 f 5 f_5 f5?: [0.0, 0.0, 0.0] (填充符的特征值通常不重要)
根據掩碼 [1, 1, 1, 0, 0],有效 token 是 “貓”, “坐”, “墊子”,它們對應的特征向量是 f 1 f_1 f1?, f 2 f_2 f2?, f 3 f_3 f3?。
“通過對有效 token 進行最大值操作”的意思是:我們只看 f 1 f_1 f1?, f 2 f_2 f2?, f 3 f_3 f3? 這三個向量,然后對它們的 每個維度 分別找出最大值。
- 看第一個維度: f 1 f_1 f1? 的第一個維度是 0.5, f 2 f_2 f2? 的第一個維度是 0.6, f 3 f_3 f3? 的第一個維度是 0.7。這三個值中的最大值是 max ? ( 0.5 , 0.6 , 0.7 ) = 0.7 \max(0.5, 0.6, 0.7) = 0.7 max(0.5,0.6,0.7)=0.7。
- 看第二個維度: f 1 f_1 f1? 的第二個維度是 0.1, f 2 f_2 f2? 的第二個維度是 0.9, f 3 f_3 f3? 的第二個維度是 0.2。這三個值中的最大值是 max ? ( 0.1 , 0.9 , 0.2 ) = 0.9 \max(0.1, 0.9, 0.2) = 0.9 max(0.1,0.9,0.2)=0.9。
- 看第三個維度: f 1 f_1 f1? 的第三個維度是 0.8, f 2 f_2 f2? 的第三個維度是 0.2, f 3 f_3 f3? 的第三個維度是 0.5。這三個值中的最大值是 max ? ( 0.8 , 0.2 , 0.5 ) = 0.8 \max(0.8, 0.2, 0.5) = 0.8 max(0.8,0.2,0.5)=0.8。
將每個維度的最大值組合起來,就得到了最終的結果向量: [0.7, 0.9, 0.8]。
這個結果向量就是一個單一的、固定長度的向量,它濃縮了有效文本(“貓 坐 墊子”)中在每個維度上最強的激活信息。在 TQG 中,這個向量會被用來幫助生成帶有文本先驗信息的查詢。
附4:多模態模型訓練常用的數據集

附5:We only count the parameters of transformer architecture in head?
- Head (頭部): 在深度學習模型中,“頭部”通常指模型末端負責執行特定任務(比如分類、檢測、定位等)的層或模塊。它接收主干網絡(backbone)提取的特征,并輸出最終結果。
- Transformer architecture in head: 這指的是模型頭部中使用了 Transformer 結構的那些部分。
作者在報告模型的參數數量時(前面提到 SimVG-TB 只有 1.58 百萬參數),他們沒有計算整個模型的參數(包括主干網絡等),而是只統計了位于模型“頭部”并且采用了 Transformer 結構的那些層的參數。
附6:將原始視覺嵌入的步長從 16 增加到 32 并對卷積核應用雙線性插值,能夠顯著提升性能
僅僅增加步長(進行壓縮)可能不夠,如果在進行這種“步長增加”導致的壓縮轉換時,同時使用一種基于雙線性插值原理的方法來處理卷積過程,那么最終模型的性能會顯著提升。原因正如原文后面解釋的:“這是因為雙線性插值在壓縮后保留了原始特征分布,從而加速收斂。” 也就是說,這種結合雙線性插值的處理方式,使得用更大步長(32)生成的視覺嵌入,雖然數量少了,但質量更高,更好地代表了原始圖像的信息,因此對后續任務更有利,不僅能提升最終性能,還能加速訓練收斂。
- 雙線性插值 (Bilinear Interpolation):
- 這是一種常用的圖像縮放或采樣的方法。
- 它的基本思想是,當你需要計算新圖像(或者縮放后的特征圖)上一個點的值時,不是簡單地取原始圖像最近的一個點(最近鄰插值),而是根據這個點在原始圖像中四個最近鄰點的位置和值,進行加權平均來計算。
- 雙線性插值計算出的值更平滑,能更好地保留原始圖像的細節和過渡,避免縮放時出現鋸齒狀或塊狀的偽影。
- 卷積核 (Convolutional Kernel):
- 卷積核是一個小的權重矩陣,在卷積操作中用于掃描輸入特征圖。它定義了如何將輸入區域的信息聚合成一個輸出值。
作者在提取圖像最初的特征向量時,改變了提取的方式:增加了提取的“步子”大小(從 16 到 32,即減少了提取的向量數量),但為了彌補信息損失,同時使用了雙線性插值這種更精細平滑的方式來處理提取過程。結果是,雖然提取的向量變少了,但因為提取得更“聰明”(用了雙線性插值),反而讓模型性能變好了。
- 原始視覺嵌入 (Original visual embedding): 這是指模型最開始處理圖像的方式。在 ViT 模型中,通常是將圖像分割成小塊(patch),然后將每個小塊轉換成一個向量(embedding)。這個過程通常涉及一個卷積操作來完成。
- 步長 (Stride): 這個“步長”是指在生成這些視覺嵌入時,卷積核(或 patch 提取窗口)在圖像上移動的距離。
- 步長 16 意味著窗口每次移動 16 個像素。
- 步長 32 意味著窗口每次移動 32 個像素。
- 步長從 16 增加到 32 的影響: 增加步長意味著在相同大小的圖像上,提取的視覺嵌入(或 patch)的數量會減少。比如,如果 patch 大小是 32x32,步長 16 會導致 patch 之間有重疊(小于卷積核窗口大小 32x32),提取的 token 更多;步長 32 則可能沒有重疊,提取的 token 數量會減少。這是一種空間上的降采樣或壓縮,會減少模型處理的 token 數量,可能加快速度,但也可能丟失信息。
對卷積核應用雙線性插值”這句話,聽起來有點不尋常,因為雙線性插值通常是應用于數據(像素值或特征值),而不是直接應用于卷積核的權重本身。結合之前的上下文(步長從 16 增加到 32,這是壓縮/降采樣的過程),這句話更可能是指:
在執行那個將原始圖像(或初步特征)轉換為步長為 32 的視覺嵌入的卷積操作時,這個卷積過程(或者說這個卷積核的設計/作用方式)融入了雙線性插值的原理。
這可能意味著以下幾種情況(或它們的組合):
- 卷積核權重的生成或設計方式借鑒了插值原理: 卷積核的權重值不是隨機初始化或簡單學習,而是根據某種插值(類似于雙線性插值)的數學函數來預設或影響。這樣,卷積核在處理輸入區域時,就傾向于以一種平滑、插值式的方式來聚合信息。
- 卷積操作本身被修改以執行插值式采樣: 雖然表面是卷積,但底層的實現機制在從輸入區域采樣并聚合時,使用了類似于雙線性插值加權平均的邏輯。當步長增加(導致輸入區域被壓縮到更少的輸出點)時,這種插值式的聚合可以確保每個輸出點更平滑地代表它對應的更大輸入區域的信息。
就像前面提到的,增加步長(從 16 到 32)是一種壓縮。如果只是簡單地跳著采樣或進行普通的卷積,可能會丟失很多細節或引入采樣誤差。應用雙線性插值原理,即使是在壓縮過程中,也能更“聰明”地聚合信息。它能幫助:
- 保留更多的原始特征分布信息: 使得壓縮后的特征(步長為 32 的視覺嵌入)更好地反映原始圖像區域的面貌。
- 使特征過渡更平滑: 避免了因為大步長導致的突變或信息斷層。
通過這種方式(增加步長進行壓縮 + 應用雙線性插值原理進行高質量聚合),模型能夠在處理更少的 token(因為步長大了)的同時,依然獲得高質量的視覺嵌入,從而顯著提升后續任務(如視覺 grounding)的性能,并加速模型收斂。
附7:各backbone模型比較
| 模型 | 參數量(M) | 主要架構 |
|---|---|---|
| DLA-34 | 15.7 | 34 層深度層聚合網絡,通過 Iterative Deep Aggregation(IDA)與 Hierarchical Deep Aggregation(HDA)節點融合不同深度特征,使用基本卷積塊 |
| DarkNet-53 | 41.6 | 53 層 DarkNet 主干,交替使用 1×1 和 3×3 卷積并配以殘差連接,開始是用于 YOLOv3 |
| ResNet-101 | 45.0 | 101 層殘差網絡,采用 Bottleneck 殘差塊(1×1 → 3×3 → 1×1 卷積),堆疊于 conv2_x(3 塊)、conv3_x(4 塊)、conv4_x(23 塊)、conv5_x(3 塊)中 |
| ResNet-152 | 60.0 | 152 層深度殘差網絡,同樣基于三層 Bottleneck 結構,按 conv2_x(3 塊)、conv3_x(8 塊)、conv4_x(36 塊)、conv5_x(3 塊)堆疊 |
| ViT-B/32 | 88.0 | Vision Transformer Base:12 層自注意力編碼器,隱藏維度 768,MLP 隱層 3072,12 個頭,Patch 大小 32,添加 CLS token 與位置嵌入 |
| CLIP-ViT-Base | 88.0 | 基于 ViT-B/32,外加 512 維投影頭將視覺 CLS token 映射到多模態對齊空間,用于圖文對比學習 |
| Swin-B | 88.0 | 層級化 Shifted-Window Transformer:Patch 分區(4×4 卷積),4 個階段深度 [2,2,18,2],Embed dims [96,192,384,768],Window 大小 7,MLP ratio 4,GELU + LayerNorm |
| VGG16 | 138.0 | 13 層 3×3 卷積(通道依次為 64,64 → 128,128 → 256×3 → 512×3 → 512×3)、5 個 2×2 池化,末尾 3 層全連接(4096→4096→1000) |
| Swin-L | 197.0 | 更大版 Swin:Patch 分區(4×4 卷積),4 個階段深度 [2,2,18,2],Embed dims [192,384,768,1536],Heads [6,12,24,48],Window 大小 7,MLP ratio 4 |
| CLIP-ViT-Large | 307.0 | 基于 ViT-L/14,外加 512 維投影頭,同樣用于多模態對比訓練 |
| ViT-L/32 | 307.0 | Vision Transformer Large:24 層自注意力編碼器,隱藏維度 1024,MLP 隱層 4096,16 個頭,Patch 大小 32 |

)






spark和Hadoop的區別)








:權衡數據運用,精準把握創業方向)

之旅——String類⑩)