6.1 實驗設置
測試平臺。我們使用阿里云上的16-GPU集群(包含4個GPU虛擬機,類型為ecs.gn7i-c32g1.32xlarge)。每臺虛擬機配備4個NVIDIA A10(24 GB)GPU(通過PCI-e 4.0連接)、128個vCPU、752 GB內存和64 Gb/s網絡帶寬。
模型。我們以流行的LLaMA模型族[57]為實驗對象。測試兩種規格:LLaMA-7B(單GPU運行)和LLaMA-30B(通過張量并行在單機4個GPU上運行)。模型采用常見的16位精度。我們基于的vLLM版本僅支持原始LLaMA(最大序列長度2k),但近期已有支持更長序列長度(4k至256k)的LLaMA變體[3,7,58,65]。由于這些變體的模型架構和推理性能與LLaMA基本相似,我們認為從系統角度而言,我們的結果能代表更多模型類型和更長序列長度范圍。
請求軌跡。與先前工作[34, 35, 67]類似,我們通過合成請求軌跡評估Llumnix的在線服務性能。
| 分布 | 平均值 | P50 | P80 | P95 | P99 |
|---|---|---|---|---|---|
| 真實 | |||||
| ShareGPT 輸入 | 306 | 74 | 348 | 1484 | 3388 |
| 輸出 | 500 | 487 | 781 | 988 | 1234 |
| BurstGPT 輸入 | 830 | 582 | 1427 | 2345 | 3549 |
| 輸出 | 271 | 243 | 434 | 669 | 964 |
| 生成 | |||||
| 短(S) | 128 | 38 | 113 | 413 | 1464 |
| 中(M) | 256 | 32 | 173 | 1288 | 4208 |
| 長(L) | 512 | 55 | 582 | 3113 | 5166 |
| 表1:評估中使用的序列長度(token數量)真實分布與生成分布。真實分布包含輸入(“In”)和輸出(“Out”)的長度。我們使用不同請求率(每秒請求數)的泊松分布和伽馬分布生成請求到達時間。對于伽馬分布,我們調整變異系數(CV)以控制請求的突發性。每個軌跡包含10,000個請求。我們選擇合適的請求率或CV范圍,使負載保持在合理區間:使用Llumnix時,P50請求幾乎無排隊延遲和搶占,P99請求的排隊延遲在幾十秒內。 |
對于請求的輸入/輸出長度,我們使用兩個公開的ChatGPT-4對話數據集——ShareGPT (GPT4)[10]和BurstGPT (GPT4-Conversation)[62]——評估真實工作負載。考慮到Llumnix面向更多樣化的應用場景,我們還使用生成的冪律長度分布模擬長尾工作負載,混合高頻短序列(如聊天機器人、個人助手等交互式應用)和低頻長序列(如摘要或文章生成)。我們生成多個不同長尾程度和平均長度(128、256、512)的分布,如表1中的短(S)、中(M)、長(L)分布。這些分布的最大長度為6k,因此請求的總序列長度(輸入+輸出)在運行LLaMA-7B時不會超過A10 GPU的容量(13,616 tokens)。為觀察不同工作負載特征的性能,我們通過組合輸入和輸出的長度分布構建軌跡,包括S-S、M-M、L-L、S-L和L-S。
基線。我們將Llumnix與以下調度器對比。所有基線和Llumnix均使用vLLM作為底層推理引擎,以聚焦實例間請求調度的對比。
? 輪詢調度:一種均衡分發請求的簡單策略,是生產級服務系統的典型行為[4, 9, 47]。
? INFaaS++:優化版的INFaaS[53],一種先進的多實例服務調度器。我們評估其負載均衡調度和負載感知自動擴縮容策略。我們通過使其專注于LLM服務中的主導資源——GPU內存(包括排隊請求占用的內存以反映隊列壓力)對其進行改進。
? Llumnix-base:Llumnix的基礎版本,不區分優先級(所有請求視為同優先級),但啟用遷移等其他功能。
關鍵指標。我們重點關注請求延遲,包括端到端延遲、預填充延遲(首個生成token的延遲)和解碼延遲(自首個生成token至最后一個的平均延遲)。我們報告平均值和P99值。
6.2 遷移效率
我們首先評估Llumnix遷移機制的性能,包括對遷移請求引入的停機時間和對運行中請求的額外開銷。我們測試了1-GPU的LLaMA-7B和4-GPU的LLaMA-30B模型。針對每種模型,我們在兩臺不同機器上部署兩個實例。使用不同序列長度時,我們分別在兩個實例上運行總長度為8k的同一批請求。隨后將其中一個實例上的請求遷移至另一實例,并測量其停機時間及遷移期間兩個實例上運行批次的解碼速度。
我們比較了遷移期間的停機時間與兩種簡單方法:重新計算和使用Gloo阻塞式拷貝KV緩存(其他請求非阻塞)。如圖10(左)所示,遷移的停機時間隨序列長度增加幾乎保持恒定(約20-30毫秒),甚至短于單次解碼步驟。相比之下,基線方法的停機時間隨序列長度增加而增長,最高達到遷移的111倍。例如,對LLaMA-30B重新計算8k序列需3.5秒,相當于54個解碼步驟的服務停滯。我們還觀察到,所有序列長度的遷移僅需兩個階段,這是最小值。這是因為數據拷貝速度足夠快,且第一階段生成的新token數量較少。
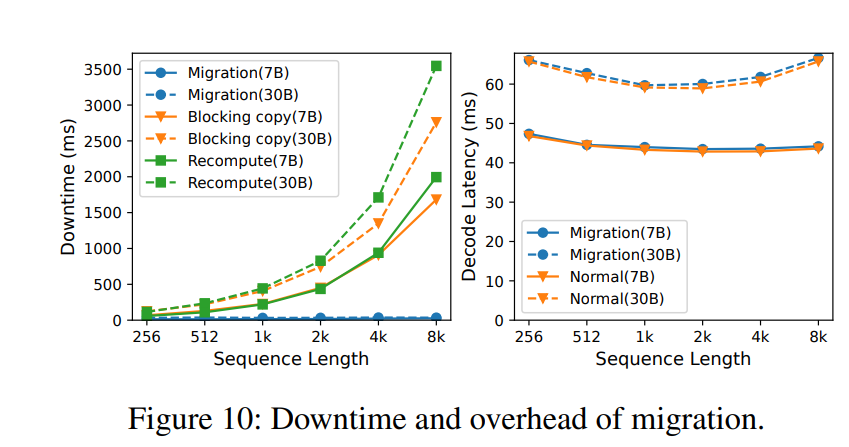
圖10(右)進一步比較了源實例在遷移期間與正常執行時的單步解碼時間(目標實例結果類似)。對于LLaMA-7B和LLaMA-30B,性能差異均不超過1%,表明遷移額外開銷可忽略不計。此外,此類額外開銷僅在實例上有請求被遷移(入或出)時存在。我們發現,在后續所有服務實驗中,每個實例上正在進行遷移的時間跨度平均占比僅為約10%。這意味著實際額外開銷更小,而遷移帶來的調度收益顯著,這一權衡是值得的。
6.3 服務性能
我們評估Llumnix在在線服務中的調度性能,使用16個LLaMA-7B實例(自動擴縮容功能僅在§6.5實驗中啟用)。
真實數據集。我們首先使用ShareGPT和BurstGPT軌跡(圖11的前兩行),
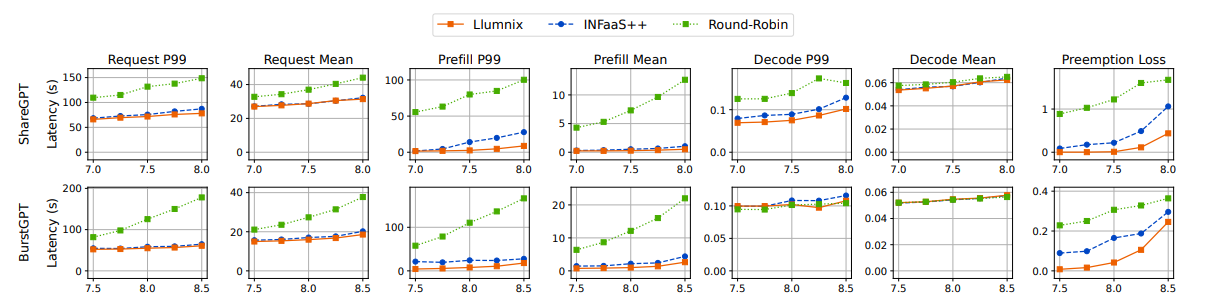
比較Llumnix與輪詢及INFaaS++的性能。Llumnix在端到端請求延遲上顯著優于基線方法,平均延遲最高提升2倍,P99延遲最高提升2.9倍。尤其值得注意的是,輪詢策略的性能始終遠低于INFaaS++和Llumnix:由于序列長度方差較大,單純均勻分發請求仍會導致負載不均衡,從而影響預填充和解碼延遲。
Llumnix在預填充延遲上相比輪詢實現顯著提升,平均延遲最高達26.6倍,P99延遲最高達34.4倍。這是由于輪詢可能將新請求分發至過載實例,導致較長的排隊延遲。通過負載均衡減少搶占,Llumnix將P99解碼延遲最高降低2倍。由于搶占導致的延遲懲罰被所有生成token分攤,這一提升幅度看似較小。然而,每次搶占發生時,都會造成突發性服務停滯,影響用戶體驗。圖11(最右側列)報告了搶占損失(所有請求的額外排隊和重計算時間均值)。Llumnix相比輪詢平均減少84%的搶占損失。這些結果凸顯了負載均衡在LLM服務中的重要性。在后續使用更高方差生成分布的實驗中,輪詢的延遲表現惡化至基線的兩個數量級。因此,為保持圖表清晰,后續實驗將省略輪詢,僅對比INFaaS++與Llumnix。
Llumnix在平均預填充延遲上超越INFaaS++最高達2.2倍,P99延遲最高達5.5倍,在P99解碼延遲上最高提升1.3倍,證明遷移機制在調度時負載均衡之外的額外收益。接下來,我們通過更多不同特征的軌跡進一步評估兩者的性能差異。
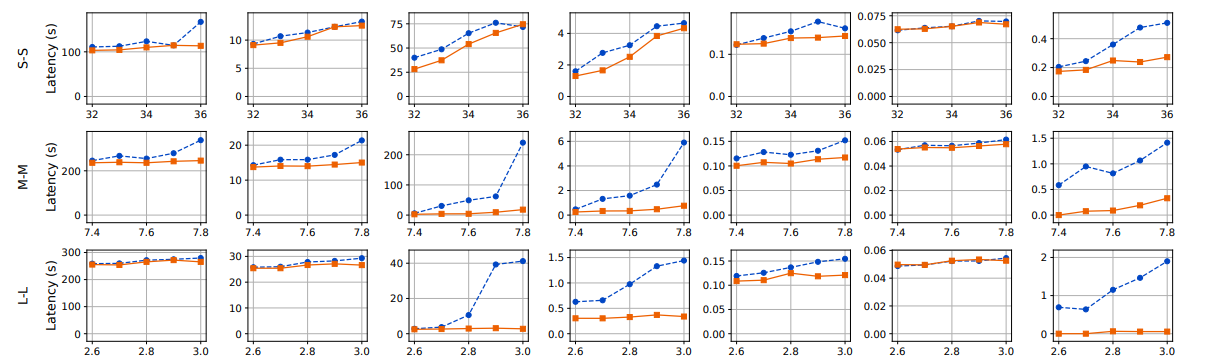
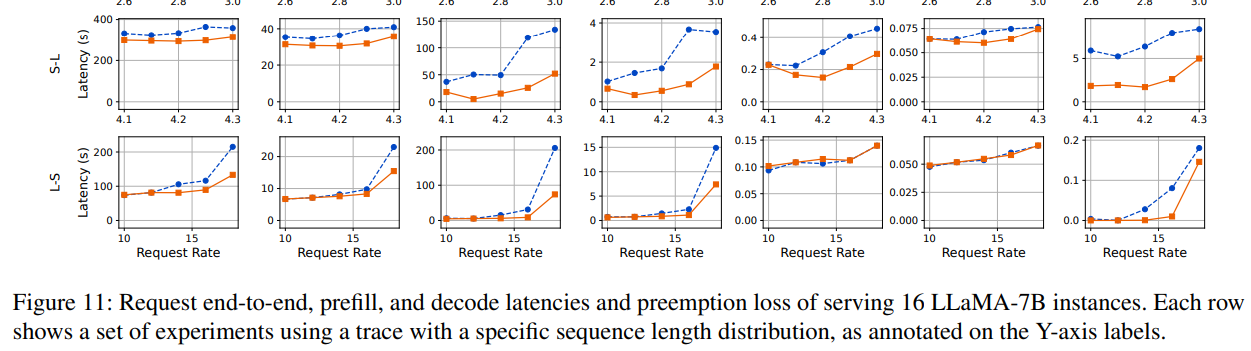
生成分布。我們使用多個生成分布(圖11的底部五行)比較Llumnix與INFaaS++。Llumnix在所有軌跡的端到端請求延遲上均表現更優,平均延遲最高提升1.5倍,P99延遲最高提升1.6倍。預填充延遲的改進更為顯著,平均延遲最高達7.7倍,P99延遲最高達14.8倍。盡管INFaaS++將請求分發至負載最低的實例,但由于碎片化問題(尤其是輸入較長的長尾請求),仍會出現較長的排隊延遲。Llumnix通過遷移實現碎片整理,從而減少此類排隊延遲,在輸入較長的軌跡中表現更優。
為了更深入地研究內存碎片化問題,我們進一步以請求速率為7.5的M-M跟蹤實驗為例進行案例研究。我們將每個時刻的碎片化內存定義為:在無碎片化情況下,集群空閑內存中能夠滿足所有實例隊首阻塞請求需求的那部分內存。例如,若總空閑內存為8GB,存在三個各需3GB的隊首阻塞請求,則碎片化內存計為6GB,即若無碎片化時這6GB內存可滿足兩個排隊請求的需求。該指標反映了因碎片化導致的內存浪費程度。我們統計了碎片化內存在集群總內存中的占比。在上述示例中,若總內存為16GB,則占比為37.5%(6/16)。
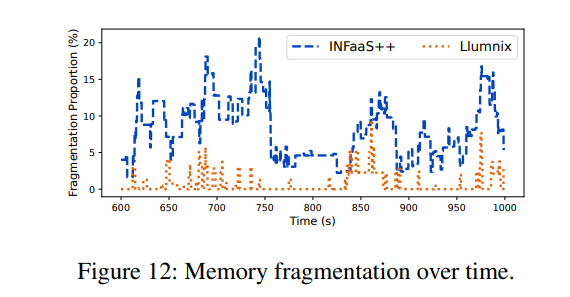
圖12展示了實驗期間繁忙時段的碎片化比例。我們觀察到INFaaS++的碎片化比例經常超過10%,造成大量集群內存浪費。相比之下,Llumnix的碎片化比例通常為0。在該時段內,Llumnix和INFaaS++的平均碎片化比例分別為0.7%和7.9%(降低92%),突顯了通過遷移進行碎片整理的效果。
通過減少搶占,Llumnix還將P99解碼延遲最高提升了2倍。盡管INFaaS++已通過調度負載均衡來減少搶占,但遷移通過響應實際序列長度(請求到達時未知)對此進行了補充。如圖11所示,Llumnix顯著降低了搶占損失,在多數情況下接近零。所有實驗的平均降幅為70.4%,相當于端到端請求延遲平均減少了1.3秒。
6.4 優先級支持
我們通過隨機選取10%的請求并為其分配高調度優先級和執行優先級,評估了Llumnix對優先級的支持能力。實驗采用短-短序列長度分布和Gamma到達分布的跟蹤數據。通過調整變異系數(CV)參數,展示突發工作負載和負載峰值對高優先級請求的干擾程度。我們根據經驗為高優先級請求設定1,600個token的目標內存負載,因為觀察到該負載可維持接近理想的解碼速度(參見圖4)。Llumnix將此目標負載轉換為高優先級請求對應的內存預留空間。我們將Llumnix與Llumnix-base進行對比,后者將所有請求視為相同優先級。
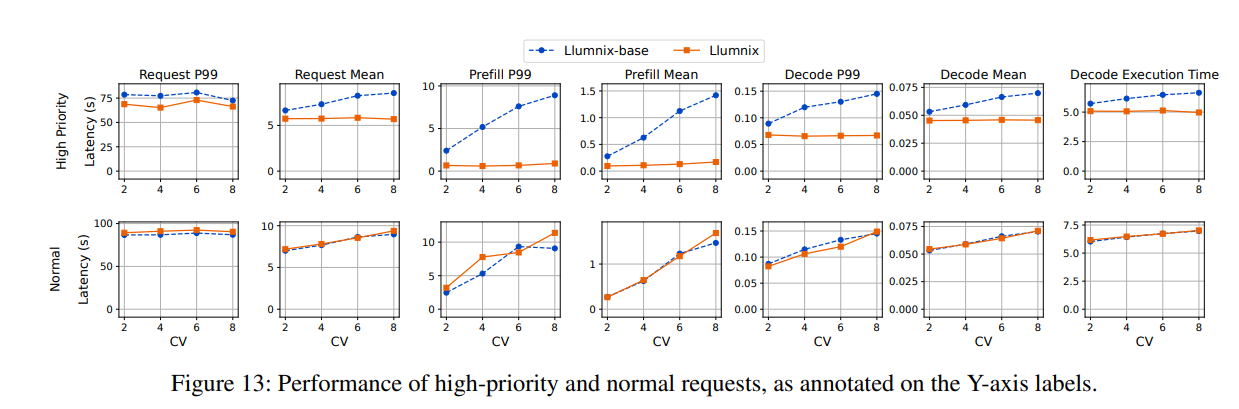
如圖13第一行所示,隨著CV值增加,Llumnix將高優先級請求的平均延遲改善了1.2倍至1.5倍。更高的CV值會導致更多高負載時段,若缺乏保護機制,高優先級請求可能遭受更嚴重的干擾。即使在更高CV值下,Llumnix仍能為高優先級請求提供穩定的延遲表現,體現了其對此類請求的隔離能力。這是因為Llumnix能通過動態為其騰出空間來應對變化的高優先級負載,而靜態資源預留等方法難以實現這一點。對于預填充延遲,Llumnix的平均延遲改善達2.9倍至8.6倍,P99延遲改善達3.6倍至10倍。這通過高調度優先級減少排隊延遲實現。Llumnix還將解碼延遲的平均值改善了1.2倍至1.5倍,P99延遲改善了1.3倍至2.2倍。這種提升源于通過降低實例負載和干擾加速解碼計算(最右側列顯示平均解碼計算時間有類似提升)。我們還注意到Llumnix保持了普通請求的性能(圖13第二行):Llumnix對普通請求的平均請求、預填充和解碼延遲分別最多增加4.5%、13%和2%。
6.5 自動擴展
我們通過使用更大范圍的請求速率和Gamma變異系數(CVs)來評估Llumnix的自動擴展能力,以展示其對負載變化的適應性。默認情況下,Llumnix使用[10, 60]的擴展閾值范圍,即當平均空閑度(freeness)低于10或高于60時,Llumnix會擴展或縮減實例;需注意,該指標表示在當前批次下實例仍可運行的最大解碼步數。我們讓INFaaS++使用相同的擴展策略,因此Llumnix和INFaaS++的實例擴展激進程度一致。實驗中最大實例數設為16,并采用長-長序列長度分布。
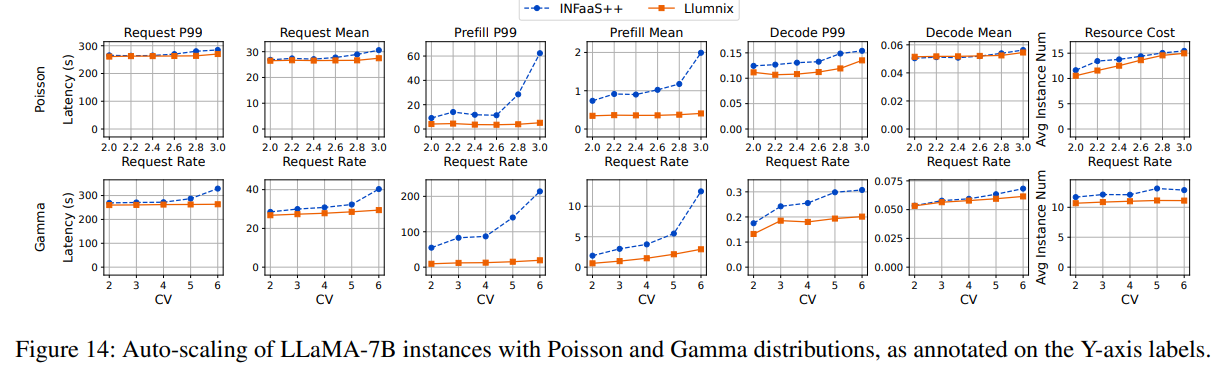
我們首先基于泊松分布調整請求速率。如圖14第一行所示,Llumnix在所有請求速率下均實現了延遲改善,例如P99預填充延遲最高提升12.2倍。我們還以平均使用實例數衡量資源成本(見最右側列)。Llumnix通過更快速地飽和或釋放實例來提高自動擴展效率,從而節省高達16%的成本。此外,我們通過Gamma分布的不同變異系數測試了不同工作負載突發性(請求速率=2)。如第二行所示,Llumnix在延遲和成本方面表現類似改進,例如P99預填充延遲最高提升11倍,成本節省18%。
最后,我們通過分析Llumnix需要多激進地擴展實例以維持特定延遲目標(如給定的P99預填充延遲)來評估其成本效率。我們調整擴展閾值t,擴展范圍設為[t, t+50]。t值越高,表示Llumnix傾向于使用更多實例。
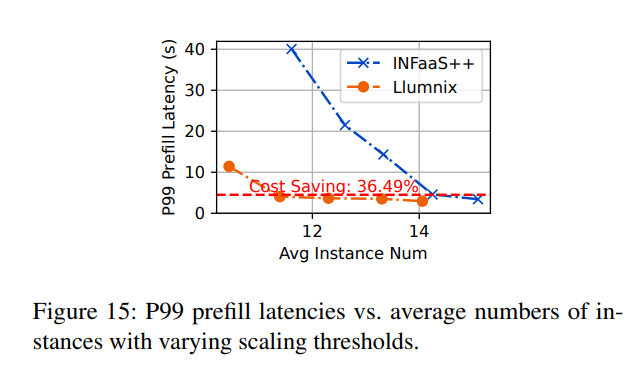
圖15展示了不同擴展閾值下的P99預填充延遲和成本。觀察發現,由于遷移減少排隊延遲的能力與更高的自動擴展效率的結合,Llumnix在實現相似P99預填充延遲(約5秒,紅色虛線)的同時,相比INFaaS++節省了36%的成本。
6.6 調度可擴展性
我們通過調度壓力測試評估Llumnix在64個LLaMA-7B實例下的可擴展性,測試使用更高的請求速率。由于該集群規模超過我們的測試平臺容量,我們通過離線測量A10 GPU在不同序列長度和批量大小下的表現,將vLLM中的真實GPU執行替換為簡單的休眠命令(sleep command)。我們通過擴展vLLM調度器以集中管理所有實例的請求,構建了一個簡單的集中式調度器作為基線。測試中,請求的輸入和輸出長度均為64個token,且請求速率逐步增加。
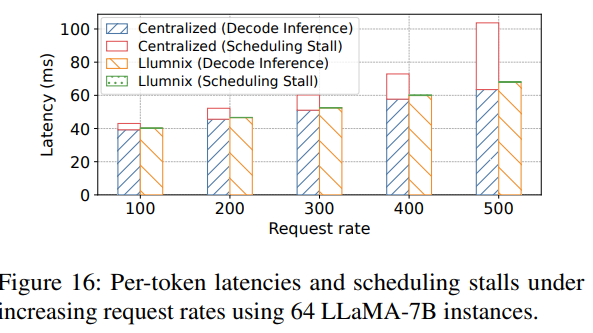
如圖16所示,隨著請求速率提升,基線方案在每次迭代的推理計算期間遭遇長達40毫秒的調度停滯,導致整體速度下降1.7倍。此類停滯源于實例與集中式調度器之間的通信——同步請求狀態和調度決策的過程在高負載下成為瓶頸。相比之下,Llumnix即使在高請求速率下仍表現出接近零的調度停滯,展現了其分布式調度架構的可擴展性。Llumnix將實例內的調度邏輯卸載并分布到各個"llumlet"中,使其與全局調度并行且異步執行。此外,llumlet僅上報實例級指標,而非每個請求的精確狀態,從而進一步提升了通信效率。
7 相關工作
LLM推理。隨著Transformer模型在模型服務中的重要性日益凸顯,近期工作如FasterTransformer[46]、TurboTransformer[25]、LightSeq[61]和FlashAttention[21, 22]通過優化GPU內核以提升推理性能。SpotServe[41]利用可搶占實例支持LLM推理,以提高成本效率。FastServe[63]采用搶占式時間切片方法優化請求完成時間。AlpaServe[35]通過流水線并行技術降低突發工作負載的服務延遲。為進一步提升GPU利用率和服務吞吐量,Orca[67]提出迭代級調度(在近期研究及本文中被稱為連續批處理)和選擇性批處理,而vLLM[34]則通過PageAttention優化內存使用。[55]提出在LLM實例上對請求進行公平調度。先前工作主要聚焦于單實例服務,因此與Llumnix形成互補。Llumnix探索了部署多實例LLM服務的挑戰與機遇。KV緩存的關鍵追加-only特性被用于在推理引擎中實現請求遷移能力。該機制開辟了廣闊的策略設計空間,以提供優先級和性能隔離、提升內存效率,并支持實例自動擴展。我們還計劃探索跨實例全局調度與實例內本地調度技術(如搶占式[63]和公平[55]調度)之間的相互作用,作為未來工作。
請求調度。為支持深度學習模型部署,已提出多種系統(如Clipper[19]、Nexus[54]、DVABatch[20]和TritonServer[47])以優化DNN推理服務的請求調度。為滿足DNN推理請求的服務等級目標(SLO),Clockwork[29]利用傳統DNN的執行可預測性,而Reef[33]和Shepherd[68]通過搶占機制優先處理高優先級請求。AlpaServe[35]采用基于隊列長度的簡單負載均衡分發策略。這些工作主要針對傳統DNN模型服務,其中單個請求僅需對模型進行一次性推理。然而,LLM推理服務需要對模型進行不可預測迭代次數的自回歸計算,并引入中間狀態(即KV緩存),展現出全新特性。DeepSpeed-MII[4]雖針對多實例LLM服務,但采用忽略LLM特性的簡單輪詢分發策略。Llumnix更進一步,通過整合請求遷移確保高吞吐量和低延遲,為優先級請求提供SLO,并通過統一的負載感知動態調度策略實現資源效率的實例自動擴展。
除多模型實例外,INFaaS[53]進一步支持跨多模型類型/變體的調度,綜合考量不同應用場景的性能與精度需求。這也是LLM的典型場景:例如針對特定任務的微調模型(如代碼生成[3, 13, 30]);或基座LLM不同規模或精度的變體([26,37,39])。我們計劃在后續工作中擴展Llumnix以支持多模型類型,綜合考量延遲/吞吐量與精度間的更大權衡空間。
隔離與碎片化。隔離與碎片化之間的權衡,或工作負載打包與分散之間的權衡,一直是經典的調度挑戰。具體而言,工作負載打包可提升資源利用率,但可能引發共置工作負載間的干擾;而分散工作負載雖提供更好隔離性,卻會增加資源碎片化。已有大量研究致力于在數據中心中更好地平衡大數椐作業和虛擬機的隔離與碎片化問題,通過識別工作負載的干擾敏感性并優化調度策略([16,18,23,24,27,31,32,40,60,66])。這一挑戰在深度學習工作負載的GPU集群中同樣存在。Amaral等提出了一種拓撲感知的放置算法,以解決多GPU服務器上深度學習訓練作業打包與分散的權衡[12]。Gandiva[64]則通過內省式作業遷移,應對不同作業對打包/分散的異構敏感性。由于不可預測的自回歸執行,LLM服務使這一挑戰更為復雜。Llumnix通過運行時請求遷移響應工作負載動態,以更好地協調這兩個目標。
遷移。Gandiva[64]在調度期間為深度學習訓練作業啟用內省式遷移。其利用深度學習固有的迭代特性,在最小工作集(即小批量邊界)上執行檢查點-恢復方法以遷移模型權重。盡管LLM推理同樣具有迭代性,但直接遷移請求的完整狀態不可接受,因為推理請求的延遲SLO至關重要。此外,每個請求的工作集與序列長度呈線性關系,而隨著上下文長度增加趨勢[49, 50],這一開銷可能顯著。Llumnix的遷移方法受虛擬機實時遷移[17]啟發:通過在LLM請求持續解碼時執行大部分遷移操作,Llumnix將遷移停機時間最小化,使成本不受序列長度影響而可忽略。
8 結論
Llumnix這一名稱蘊含了我們的愿景——以類Unix方式服務LLM。這一愿景源于觀察到LLM與現代操作系統具有共性,例如普適性、多租戶特性和動態性,因而面臨相似的需求與挑戰。本文通過借鑒傳統操作系統的經典設計理念,在LLM服務新場景中邁出重要一步:重新定義隔離性、優先級等經典抽象概念;通過推理請求遷移實現"上下文切換"這一核心方法;并利用遷移能力實現持續動態的請求重調度。這些設計的結合使Llumnix實現了更低的延遲、更高的成本效益以及差異化SLO支持,為LLM服務指明了新方向。




spark和Hadoop的區別)








:權衡數據運用,精準把握創業方向)

之旅——String類⑩)



