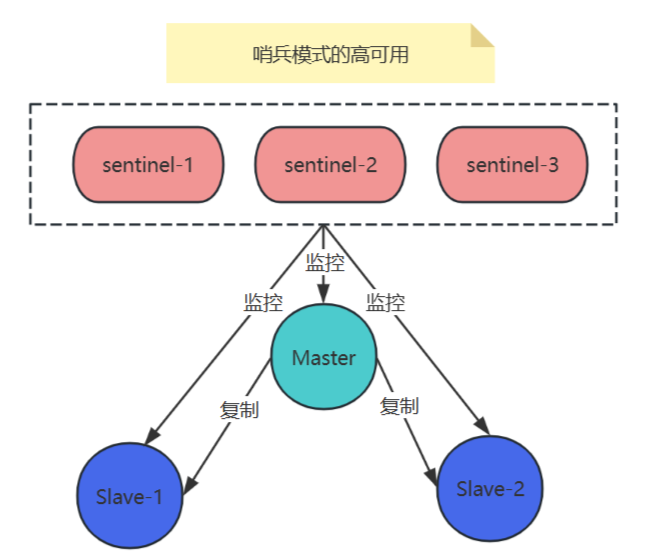
Redis主從模式雖然支持數據備份與讀寫分離,但存在三大核心缺陷:1. 故障切換依賴人工(主節點宕機需手動提升從節點);2. 監控能力缺失(無法自動檢測節點異常);3. 腦裂風險(網絡分區可能導致雙主數據沖突)。這些缺陷使得系統可用性難以保障,尤其在分布式場景下隱患顯著。
為此引入Redis哨兵模式:通過獨立部署的哨兵集群(至少3節點)實現:
- 實時監控:多哨兵協同檢測節點健康狀態
- 自動故障轉移:主節點宕機時,基于Raft算法選舉新主并同步拓撲
- 防腦裂機制:客觀下線判斷(需多數哨兵達成共識)避免誤判
哨兵模式將故障恢復時間從人工介入的分鐘級壓縮至秒級,構建了完整的高可用體系。
三大定時監控任務
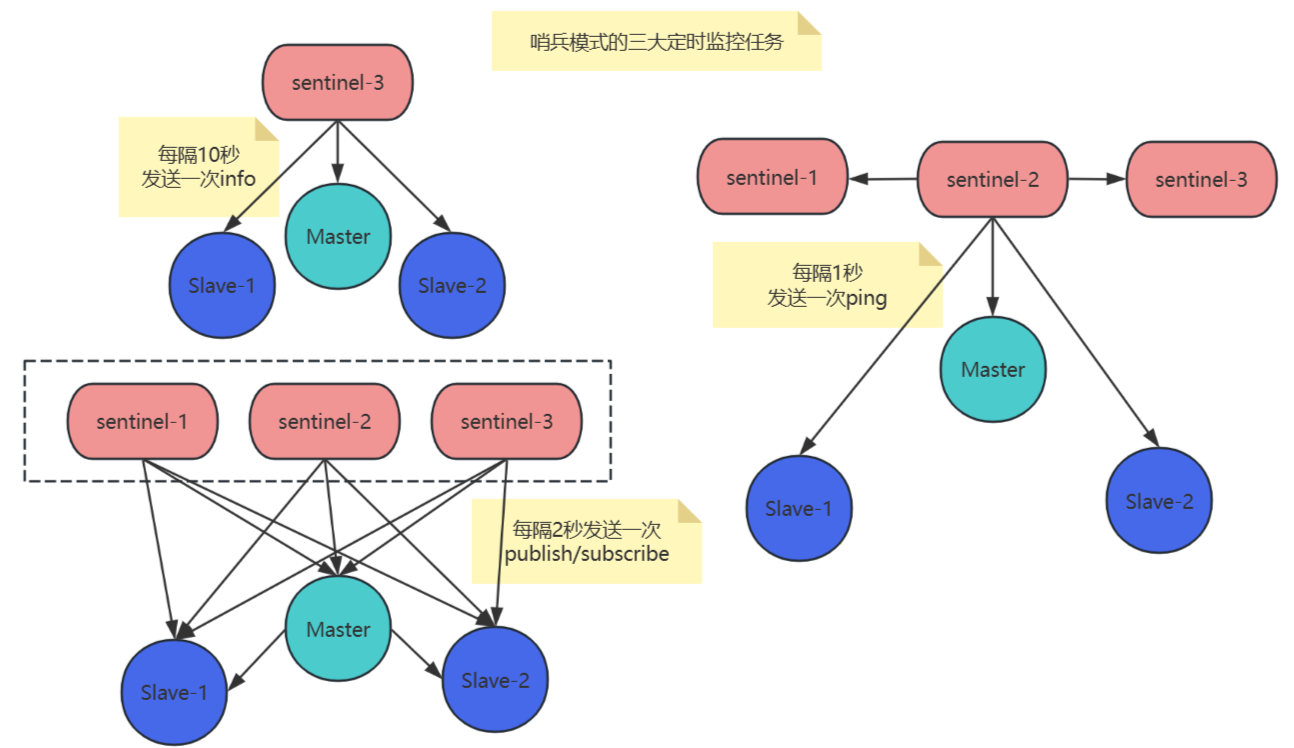
信息同步任務(10秒/次)
作用:通過INFO命令獲取Redis集群的實時拓撲結構,包括主從節點的角色變化、新增從節點發現等。該任務是哨兵感知集群動態的基礎。
技術實現:
- 每個哨兵節點每10秒向主節點發送
INFO命令,主節點返回包含從節點列表的響應 - 根據響應更新本地拓撲信息,并與從節點建立連接
- 發現新從節點時,自動將其納入監控范圍
狀態廣播任務(2秒/次)
作用:通過Redis的發布訂閱機制,實現哨兵節點間的狀態同步與協作,具體包括:
- 交換節點狀態判斷:廣播當前哨兵對主節點是否下線的判斷結果
- 發現新哨兵節點:通過解析
__sentinel__:hello頻道的消息,動態加入新哨兵到集群 - 觸發Leader選舉:當檢測到主節點異常時,通過消息觸發Raft選舉流程
技術實現:
- 哨兵節點既是發布者(發送自身狀態),也是訂閱者(接收其他哨兵狀態)
- 使用Redis的
PUBLISH/SUBSCRIBE機制,避免直接節點間通信的復雜性
心跳檢測任務(1秒/次)
作用:通過PING命令實現節點存活檢測,觸發主觀下線(SDOWN)判斷流程。
技術實現:
- 每1秒向所有主/從節點及哨兵節點發送
PING命令 - 若節點在
down-after-milliseconds(默認30秒)內未響應,標記為主觀下線 - 當主節點被標記為主觀下線時,啟動客觀下線(ODOWN) 投票
下線流程
Redis Sentinel的下線流程分為主觀下線和客觀下線兩個核心階段,最終觸發故障轉移。
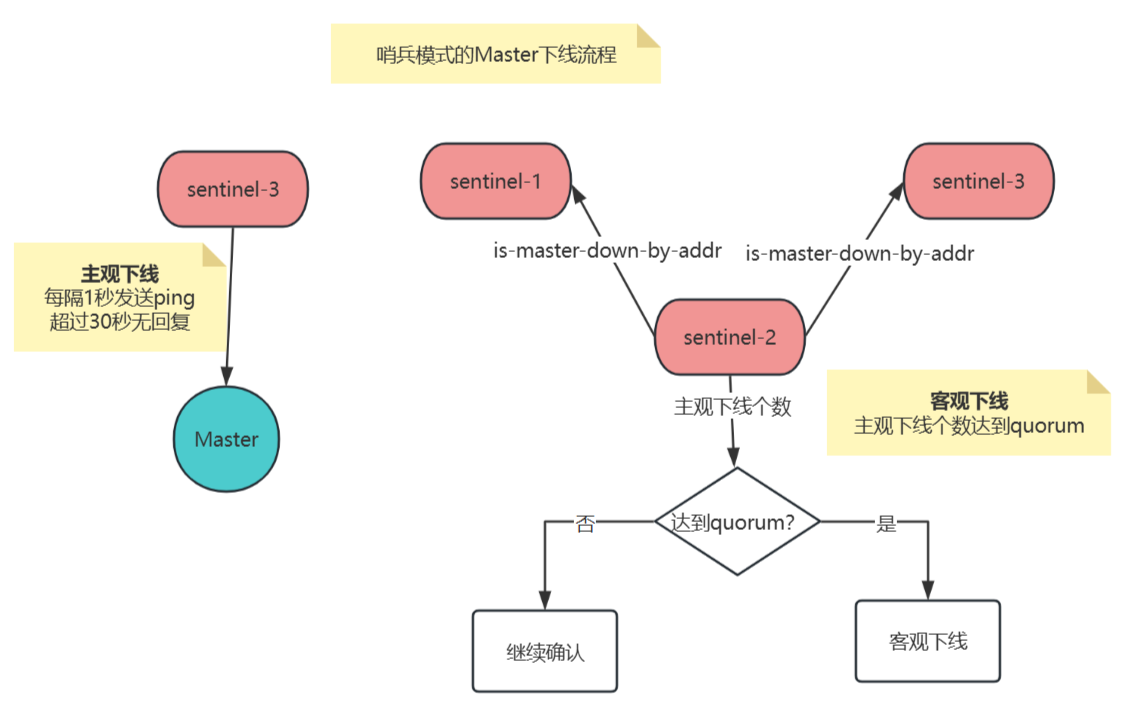
主觀下線(SDOWN)
主觀下線:Subjectively Down,簡稱SDOWN。
觸發條件:單個Sentinel節點通過心跳檢測(PING命令)發現主節點或從節點無響應,且超時時間超過配置的down-after-milliseconds閾值(默認30秒)。
技術細節:
- Sentinel每秒向所有主、從節點發送
PING命令,若節點在超時時間內未返回有效響應(如PONG),則標記為主觀下線。 - 有效響應包括
PONG、LOADING、MASTERDOWN;無效響應或無響應則觸發判斷。
特點:
- 僅代表單個Sentinel的局部判斷,可能存在誤判(如網絡抖動)。
- 從節點被標記為主觀下線后不會觸發后續流程,僅主節點需進入客觀下線階段。
客觀下線(ODOWN)
客觀下線:Objectively Down,簡稱ODOWN。
觸發條件:當足夠數量的Sentinel節點(由quorum參數決定)均認為主節點主觀下線時,主節點被標記為客觀下線,成為故障轉移的觸發條件。
技術細節:
- 協商機制:首個標記主節點主觀下線的Sentinel會通過
SENTINEL is-master-down-by-addr命令向其他Sentinel發起投票請求。 - 投票規則:需滿足
quorum值(如配置為2,則至少2個Sentinel投票確認主節點下線)。 - 防誤判:多數哨兵達成共識可降低因網絡問題導致的誤判概率。
關鍵參數:quorum在配置文件中通過sentinel monitor <master> <ip> <port> <quorum>定義,通常建議為哨兵節點數/2 +1。
選舉領頭哨兵(Leader Sentinel)
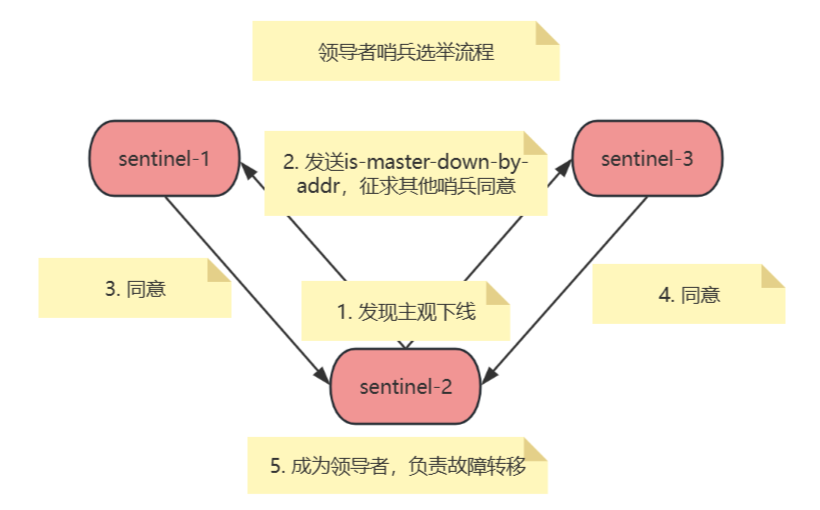
觸發條件:主節點被標記為客觀下線后,Sentinel集群需通過Raft算法選舉一個領頭哨兵來執行故障轉移。
選舉規則:
- 候選資格:僅發起客觀下線投票的Sentinel可成為候選者。
- 投票機制:每個Sentinel僅能投一票(可投給自己或他人)。候選者需同時滿足:獲得半數以上Sentinel的投票和得票數≥
quorum值。 - 超時重試:若選舉失敗,等待隨機時間后重新發起投票。
is-master-down-by-addr命令說明:
SENTINEL is-master-down-by-addr <ip> <port> <current_epoch> <runid>
- ip & port:目標主節點地址。
- current_epoch:當前配置紀元(用于防止舊消息干擾)。
- runid:
- runid=*:僅詢問其他哨兵是否同意主節點下線(用于客觀下線判定)。
- runid=哨兵自身ID:請求其他哨兵投票支持自己成為故障轉移的領導者。
故障轉移流程
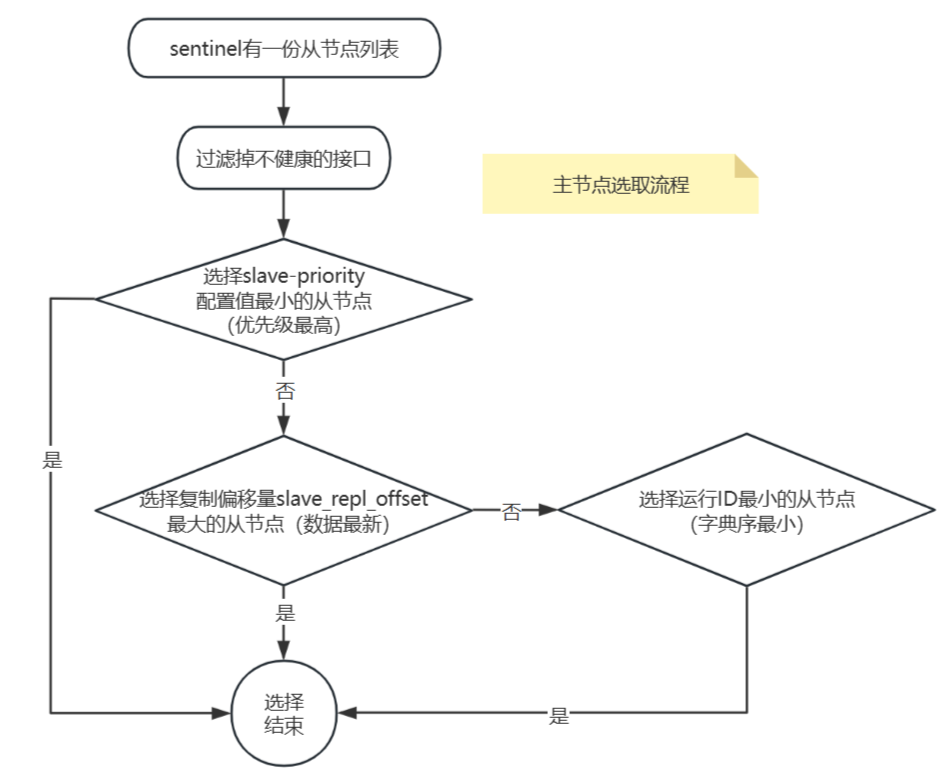
執行步驟:
- 篩選從節點:剔除網絡連接不穩定的從節點(如斷連次數超過
down-after-milliseconds*10閾值)。 - 打分規則(優先級排序):
- 第一輪:選擇
slave-priority配置值最小的從節點(優先級最高)。 - 第二輪:選擇復制偏移量(
slave_repl_offset)最大的從節點(數據最新)。 - 第三輪:選擇運行ID(
runid)最小的從節點(字典序最小)。
- 主從切換:
- 領頭Sentinel向新主節點發送
slaveof no one命令。 - 更新其他從節點指向新主節點,并通知客戶端新拓撲信息。
主從切換成功后,sentinel會在+switch-master頻道發發送主節點切換消息:
$ redis-cli -p 16381 subscribe +switch-master
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "+switch-master"
3) (integer) 1
1) "message"
2) "+switch-master"
3) "mymaster 127.0.0.1 6381 127.0.0.1 6382"
哨兵模式實戰部署
Redis節點規劃如下:
- Master: 127.0.0.1:6380
- Slave1: 127.0.0.1:6381(直連Master)
- Slave2: 127.0.0.1:6382(直連Master)
- Sentinel1:127.0.0.1:16380
- Sentinel2:127.0.0.1:16381
- Sentinel3:127.0.0.1:16382
在/test/目錄分別新建/test/6380、/test/6381、/test/6382三個目錄,用來存放redis的數據文件。然后在/test/目錄分別新建/test/16380、/test/16381、/test/16382三個目錄,用來存放sentinel的數據文件,這三個目錄下都新建redis.conf文件,內容如下:
# /test/16380/redis.conf
port 16380
sentinel monitor mymaster 127.0.0.1 6380 2# /test/16381/redis.conf
port 16381
sentinel monitor mymaster 127.0.0.1 6380 2# /test/16382/redis.conf
port 16382
sentinel monitor mymaster 127.0.0.1 6380 2
三個sentinel數據目錄下的文件內容都差不多,只有端口不一樣,其中mymaster可以為任意的名字,一個sentinel可以對多個集群中的master節點進行監控,最后一個數字2的含義為3個節點中有2個節點(2票)判定master掛了就會開始自動故障轉移。
先啟動Master和2個Slave:
$ redis-server --dir /test/6380 --port 6380$ redis-server --dir /test/6381 --port 6381 --replicaof 127.0.0.1 6380$ redis-server --dir /test/6382 --port 6382 --replicaof 127.0.0.1 6380
然后啟動三臺sentinel(也可以使用單獨的redis-sentinel命令):
$ redis-server /test/16380/redis.conf --sentinel$ redis-server /test/16381/redis.conf --sentinel$ redis-server /test/16382/redis.conf --sentinel
從Sentinel1的日志中能發現,它能根據Master節點找到2個Slave,以及其他兩個Sentinel:
4922:X 16 Apr 2025 16:31:46.120 # Sentinel ID is ddb55a52514d296a3dca1123cfceaa309c134267
4922:X 16 Apr 2025 16:31:46.120 # +monitor master mymaster 127.0.0.1 6380 quorum 2
4922:X 16 Apr 2025 16:31:46.121 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6380
4922:X 16 Apr 2025 16:31:46.124 * +slave slave 127.0.0.1:6382 127.0.0.1 6382 @ mymaster 127.0.0.1 6380
4922:X 16 Apr 2025 16:31:51.117 * +sentinel sentinel 9cc17be7b7e700d2800751113c5b0dad0944650f 127.0.0.1 16381 @ mymaster 127.0.0.1 6380
4922:X 16 Apr 2025 16:31:53.329 * +sentinel sentinel 950c560895d65451db8b65ebc0a418feef21ba82 127.0.0.1 16382 @ mymaster 127.0.0.1 6380
Sentinel可以通過向Master發送info命令來找到其他Slave:
$ redis-cli -p 6380 info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6381,state=online,offset=5399,lag=0
slave1:ip=127.0.0.1,port=6382,state=online,offset=5399,lag=0
master_failover_state:no-failover
master_replid:1eeb77e6f1d2ca889541314746796ccb6efa4404
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:5399
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:5399
Sentinel是怎么找到其他Sentinel的呢,原來他們都在主節點和所有的從節點上訂閱了同一個頻道,并將自己的信息發送到頻道中,像一個聊天窗口一樣,可以使用下面的命令來查看他們的聊天內容:
$ redis-cli -p 6380 subscribe __sentinel__:hello
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "__sentinel__:hello"
3) (integer) 1
1) "message"
2) "__sentinel__:hello"
3) "127.0.0.1,16381,9cc17be7b7e700d2800751113c5b0dad0944650f,0,mymaster,127.0.0.1,6380,0"
1) "message"
2) "__sentinel__:hello"
3) "127.0.0.1,16382,950c560895d65451db8b65ebc0a418feef21ba82,0,mymaster,127.0.0.1,6380,0"
1) "message"
2) "__sentinel__:hello"
3) "127.0.0.1,16380,ddb55a52514d296a3dca1123cfceaa309c134267,0,mymaster,127.0.0.1,6380,0"
...
現在關閉Master節點,過了大概30s(由參數down-after-milliseconds決定),6381就稱為了master節點,可以從Sentinel的日志中查看自動故障轉移的大概過程。
Sentinel1:
4922:X 16 Apr 2025 16:34:02.955 # +sdown master mymaster 127.0.0.1 6380
4922:X 16 Apr 2025 16:34:03.043 # +new-epoch 1
4922:X 16 Apr 2025 16:34:03.051 # +vote-for-leader 950c560895d65451db8b65ebc0a418feef21ba82 1
4922:X 16 Apr 2025 16:34:03.680 # +config-update-from sentinel 950c560895d65451db8b65ebc0a418feef21ba82 127.0.0.1 16382 @ mymaster 127.0.0.1 6380
4922:X 16 Apr 2025 16:34:03.680 # +switch-master mymaster 127.0.0.1 6380 127.0.0.1 6381
4922:X 16 Apr 2025 16:34:03.680 * +slave slave 127.0.0.1:6382 127.0.0.1 6382 @ mymaster 127.0.0.1 6381
4922:X 16 Apr 2025 16:34:03.681 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6381
4922:X 16 Apr 2025 16:34:33.756 # +sdown slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6381
Sentinel2:
4927:X 16 Apr 2025 16:34:02.996 # +sdown master mymaster 127.0.0.1 6380
4927:X 16 Apr 2025 16:34:03.042 # +new-epoch 1
4927:X 16 Apr 2025 16:34:03.050 # +vote-for-leader 950c560895d65451db8b65ebc0a418feef21ba82 1
4927:X 16 Apr 2025 16:34:03.068 # +odown master mymaster 127.0.0.1 6380 #quorum 3/2
4927:X 16 Apr 2025 16:34:03.068 # Next failover delay: I will not start a failover before Wed Apr 16 16:40:03 2025
4927:X 16 Apr 2025 16:34:03.680 # +config-update-from sentinel 950c560895d65451db8b65ebc0a418feef21ba82 127.0.0.1 16382 @ mymaster 127.0.0.1 6380
4927:X 16 Apr 2025 16:34:03.680 # +switch-master mymaster 127.0.0.1 6380 127.0.0.1 6381
4927:X 16 Apr 2025 16:34:03.680 * +slave slave 127.0.0.1:6382 127.0.0.1 6382 @ mymaster 127.0.0.1 6381
4927:X 16 Apr 2025 16:34:03.680 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6381
4927:X 16 Apr 2025 16:34:33.739 # +sdown slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6381
Sentinel3:
4932:X 16 Apr 2025 16:34:02.959 # +sdown master mymaster 127.0.0.1 6380
4932:X 16 Apr 2025 16:34:03.022 # +odown master mymaster 127.0.0.1 6380 #quorum 2/2
4932:X 16 Apr 2025 16:34:03.022 # +new-epoch 1
4932:X 16 Apr 2025 16:34:03.022 # +try-failover master mymaster 127.0.0.1 6380
4932:X 16 Apr 2025 16:34:03.037 # +vote-for-leader 950c560895d65451db8b65ebc0a418feef21ba82 1
4932:X 16 Apr 2025 16:34:03.050 # 9cc17be7b7e700d2800751113c5b0dad0944650f voted for 950c560895d65451db8b65ebc0a418feef21ba82 1
4932:X 16 Apr 2025 16:34:03.052 # ddb55a52514d296a3dca1123cfceaa309c134267 voted for 950c560895d65451db8b65ebc0a418feef21ba82 1
4932:X 16 Apr 2025 16:34:03.104 # +elected-leader master mymaster 127.0.0.1 6380
4932:X 16 Apr 2025 16:34:03.105 # +failover-state-select-slave master mymaster 127.0.0.1 6380
4932:X 16 Apr 2025 16:34:03.158 # +selected-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6380
4932:X 16 Apr 2025 16:34:03.158 * +failover-state-send-slaveof-noone slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6380
4932:X 16 Apr 2025 16:34:03.216 * +failover-state-wait-promotion slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6380
4932:X 16 Apr 2025 16:34:03.625 # +promoted-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6380
4932:X 16 Apr 2025 16:34:03.625 # +failover-state-reconf-slaves master mymaster 127.0.0.1 6380
4932:X 16 Apr 2025 16:34:03.680 * +slave-reconf-sent slave 127.0.0.1:6382 127.0.0.1 6382 @ mymaster 127.0.0.1 6380
4932:X 16 Apr 2025 16:34:04.173 # -odown master mymaster 127.0.0.1 6380
4932:X 16 Apr 2025 16:34:04.686 * +slave-reconf-inprog slave 127.0.0.1:6382 127.0.0.1 6382 @ mymaster 127.0.0.1 6380
4932:X 16 Apr 2025 16:34:04.686 * +slave-reconf-done slave 127.0.0.1:6382 127.0.0.1 6382 @ mymaster 127.0.0.1 6380
4932:X 16 Apr 2025 16:34:04.738 # +failover-end master mymaster 127.0.0.1 6380
4932:X 16 Apr 2025 16:34:04.738 # +switch-master mymaster 127.0.0.1 6380 127.0.0.1 6381
4932:X 16 Apr 2025 16:34:04.738 * +slave slave 127.0.0.1:6382 127.0.0.1 6382 @ mymaster 127.0.0.1 6381
4932:X 16 Apr 2025 16:34:04.738 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6381
4932:X 16 Apr 2025 16:34:34.752 # +sdown slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6381
再去看一下sentinel的數據目錄的redis.conf文件的內容(sentinel會自動更新配置文件):
$ cat /test/16380/redis.conf
port 16380
sentinel monitor mymaster 127.0.0.1 6381 2
# Generated by CONFIG REWRITE
protected-mode no
user default on nopass ~* &* +@all
dir "/test"
sentinel myid ddb55a52514d296a3dca1123cfceaa309c134267
sentinel config-epoch mymaster 1
sentinel leader-epoch mymaster 1
sentinel current-epoch 1
sentinel known-replica mymaster 127.0.0.1 6380
sentinel known-replica mymaster 127.0.0.1 6382
sentinel known-sentinel mymaster 127.0.0.1 16381 9cc17be7b7e700d2800751113c5b0dad0944650f
sentinel known-sentinel mymaster 127.0.0.1 16382 950c560895d65451db8b65ebc0a418feef21ba82
最后再啟動原來關閉的Master節點,它會被sentinel監控到,然后成為6381的從節點。
關鍵配置參數說明
# 定義哨兵監控的主節點信息。
# quorum:觸發主節點客觀下線(ODOWN)所需的最小哨兵投票數。
# quorum通常設置為哨兵節點數的一半加一(如3哨兵時設為2),避免誤判。
sentinel monitor <master-name> <ip> <port> <quorum># 定義節點無響應多久后被標記為主觀下線(SDOWN)
sentinel down-after-milliseconds <master-name> <ms># 故障轉移后,允許同時從新主節點同步數據的從節點數量。
sentinel parallel-syncs <master-name> <num># 定義故障轉移各階段的最大超時時間
sentinel failover-timeout <master-name> <ms># 設置連接主節點和從節點的密碼
sentinel auth-pass <master-name> <password># 在NAT或Docker環境中,指定哨兵對外通信的IP和端口
sentinel announce-ip <ip>
sentinel announce-port <port> # 顯式聲明從節點地址,避免自動發現延遲
sentinel known-replica <master-name> <ip> <port># 定義故障事件觸發的報警腳本路徑
sentinel notification-script <master-name> <script-path>







:權衡數據運用,精準把握創業方向)

之旅——String類⑩)








顯示與設置詳解)
