找出所有有效數據,要求電話號碼為11位,但只要列中沒有空值就算有效數據。
按地址分類,輸出條數最多的前20個地址及其數據。
代碼講解:
導包和聲明對象,設置Spark配置對象和SparkContext對象。
使用Spark SQL語言進行數據處理,包括創建數據庫、數據表,導入數據文件,進行數據轉換。
篩選有效數據并存儲到新表中。
按地址分組并統計出現次數,排序并輸出前20個地址。
代碼如下
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSessionobject Demo {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Demo")val spark = SparkSession.builder().enableHiveSupport().config("spark.sql.warehouse.dir", "hdfs://node01:9000/user/hive/warehouse").config(sparkConf).getOrCreate()spark.sql(sqlText = "create database spark_sql_2")spark.sql(sqlText = "use spark_sql_2")//創建存放原始數據的表spark.sql("""|create table user_login_info(data string|row format delimited|""".stripMargin)spark.sql(sqlText = "load data local inpath 'Spark-SQL/input/user_login_info.json' into table user_login_info")//利用get_json_object將數據做轉換spark.sql("""|create table user_login_info_1|as|select get_json_object(data,'$.uid') as uid,|get_json_object(data,'$.phone') as phone,|get_json_object(data,'$.addr') as addr from user_login_info|""".stripMargin)spark.sql(sqlText = "select count(*) count from user_login_info_1").show()//獲取有效數據spark.sql("""|create table user_login_info_2|as|select * from user_login_info_1|where uid != ' ' and phone != ' ' and addr != ' '|""".stripMargin)spark.sql(sqlText = "select count(*) count from user_login_info_2").show()//獲取前20個地址spark.sql("""|create table hot_addr|as|select addr,count(addr) count from user_login_info_2|group by addr order by count desc limit 20|""".stripMargin)spark.sql(sqlText = "select * from hot_addr").show()spark.stop()}}
Spark Streaming介紹
Spark Streaming概述:
用于流式計算,處理實時數據流。
支持多種數據輸入源(如Kafka、Flume、Twitter、TCP套接字等)和輸出存儲位置(如HDFS、數據庫等)。
Spark Streaming特點:
易用性:支持Java、Python、Scala等編程語言,編寫實時計算程序如同編寫批處理程序。
容錯性:無需額外代碼和配置即可恢復丟失的數據,確保實時計算的可靠性。
整合性:可以在Spark上運行,允許重復使用相關代碼進行批處理,實現交互式查詢操作。
Spark Streaming架構:
驅動程序(StreamingContext)處理數據并傳給SparkContext。
工作節點接收和處理數據,執行任務并備份數據到其他節點。
背壓機制協調數據接收能力和資源處理能力,避免數據堆積和資源浪費。
Spark Streaming實操
詞頻統計案例:
使用ipad工具向999端口發送數據,Spark Streaming讀取端口數據并統計單詞出現次數。
代碼配置包括設置關鍵對象、接收TCP套接字數據、扁平化處理、累加相同鍵值對、分組統計詞頻。
啟動和運行:
啟動netpad發送數據,Spark Streaming每隔三秒收集和處理數據。
代碼中沒有顯式關閉狀態,流式計算默認持續運行,確保數據處理不間斷。
DStream創建
DStream創建方式:
RDD隊列:通過SSC創建RDD隊列,將RDD推送到隊列中作為DStream處理。
自定義數據源:下節課詳細講解。
RDD隊列案例:
循環創建多個RDD并推送到隊列中,使用Spark Streaming處理RDD隊列進行詞頻統計。
代碼包括配置對象、創建可變隊列、轉換RDD為DStream、累加和分組統計詞頻。
代碼如下
import org.apache.spark.SparkConfobject WordCount {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("streaming")val ssc = new StreamingContext(sparkConf,Seconds(3))val lineStreams = ssc.socketTextStream("node01",9999)val wordStreams = lineStreams.flatMap(_.split(" "))val wordAndOneStreams = wordStreams.map((_,1))val wordAndCountStreams = wordAndOneStreams.reduceByKey(_+_)wordAndCountStreams.print()ssc.start()ssc.awaitTermination()}}
結果展示:
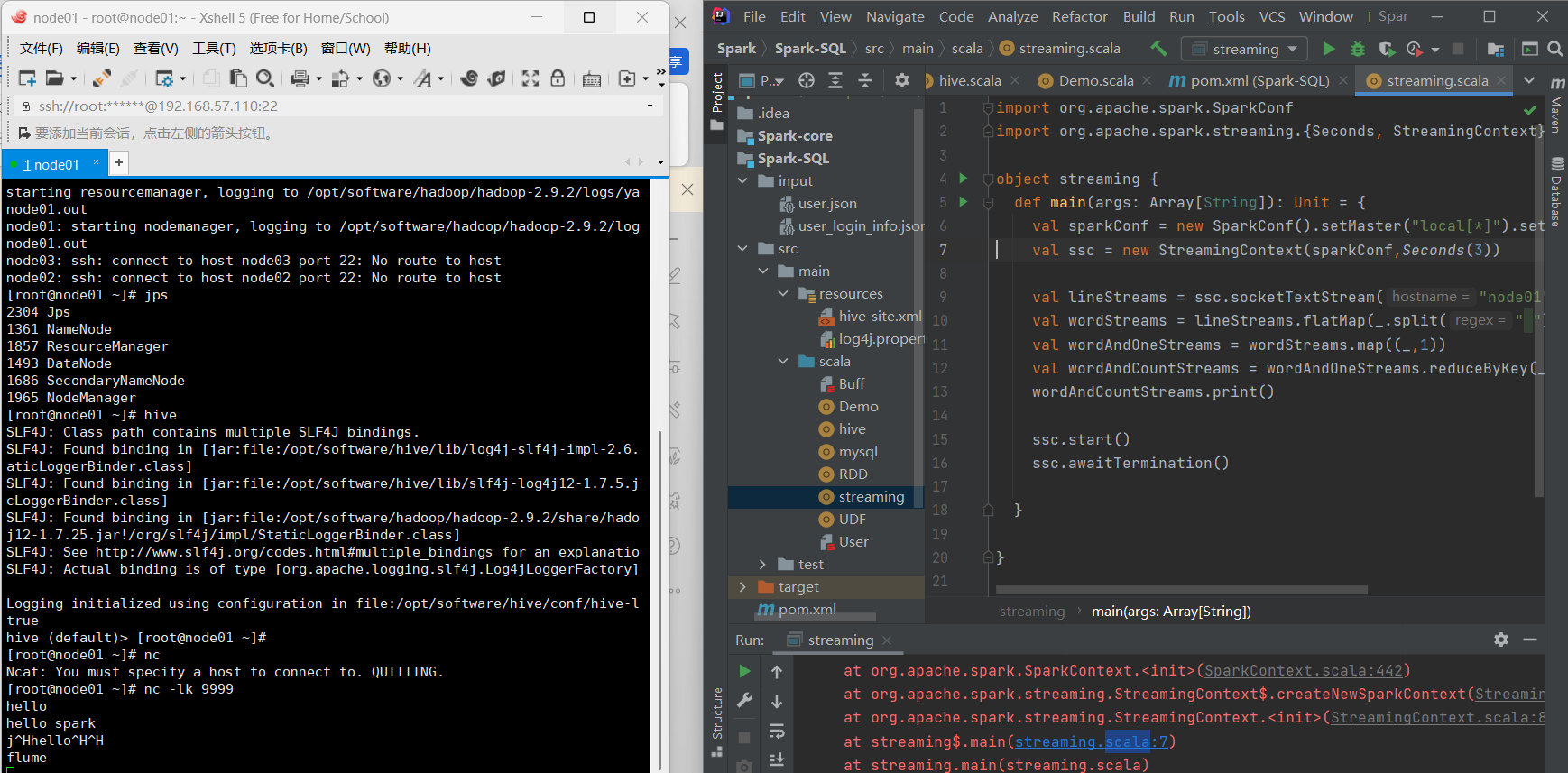
展示了詞頻統計的結果,驗證了Spark Streaming的正確性和有效性。
自定義數據源的實現
需要導入新的函數并繼承現有的函數。
創建數據源時需選擇class而不是object。
在class中定義on start和on stop方法,并在這些方法中實現具體的功能。
類的定義和初始化
類的定義包括數據類型的設定,如端口號和TCP名稱。
使用extends關鍵字繼承父類的方法。
數據存儲類型設定為內存中保存。
數據接收和處理
在on start方法中創建新線程并調用接收數據的方法。
連接到指定的主機和端口號,創建輸入流并轉換為字符流。
逐行讀取數據并寫入到spark stream中,進行詞頻統計。
數據扁平化和詞頻統計
使用block map進行數據扁平化處理。
將原始數據轉換為鍵值對形式,并根據相同鍵進行分組和累加。
輸出詞頻統計結果。
程序終止條件
設定手動終止和程序異常時的終止條件。
在滿足終止條件時輸出結果并終止程序。






:權衡數據運用,精準把握創業方向)

之旅——String類⑩)








顯示與設置詳解)

