前言:Agent 具備自主性、環境感知能力和決策執行能力,能夠根據環境的變化自動調整行為,以實現特定的目標。
一、Agent 的原理
Agent(智能體)被提出時,具有四大能力 感知、分析、決策和執行。是一種能夠在特定環境中自主行動、感知環境、做出決策并與其他Agent或人類進行交互的計算機程序或實體。它們具備自主性、反應性、社交性和適應性等特點,能夠根據環境的變化調整自己的行為,以達到預設的目標。基于大模型構建的Agent,主要利用LLM進行進行語義理解和推理分析,結合任務分析能力通過外部工具Tool。利用RAG構建知識庫來創建Memory。
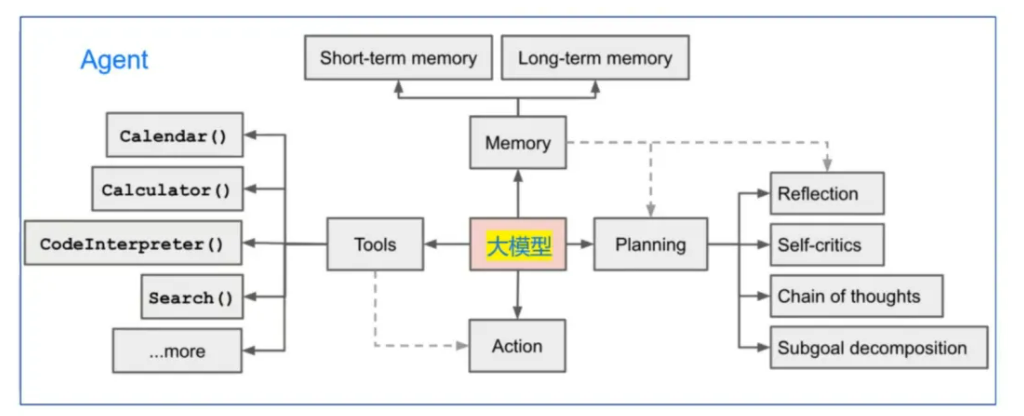
?1、Planning
類比人腦,通過對任務的拆解,分解為多個小任務,通過構思方案,分步驟操作,得到最終的答案即可終止。如:ReAct、CoT(思維鏈)。
2、Memory
模擬大腦的記憶功能,分為長期記憶和短期記憶。長期記憶為用戶行為特征、外部知識庫等,短期記憶為多輪對話形式存儲上下文,任務結束即可清理。
3、Tools
工具,顧名思義通過外部構建的工具輔助完成決策。如:代碼分析,網頁讀取,天氣查詢等。
4、Action
通過對Planning、Memory、Tools三者的調用,完成對用戶輸入的回答。如:智能查詢天氣預報,智能機器人抓取物體等。
二、具體案例(天氣查詢)
1.?Planning(規劃)
目標:明確任務需求,制定查詢計劃。
-
用戶輸入:用戶提出天氣查詢需求(例如:“今天北京的天氣怎么樣?”)。
-
任務拆解:
-
確定查詢地點(北京)、時間(今天)。
-
檢查是否需要更詳細的參數(如溫度單位、是否需要降水概率等)。
-
-
輸出:生成一個結構化查詢意圖,例如:
{"action": "weather_query","location": "北京","date": "今天","params": ["temperature", "weather_condition"]
}2.?Memory(記憶)
目標:利用歷史數據或上下文優化查詢。
-
短期記憶:檢查對話歷史中是否已有相關信息(例如用戶之前提過“北京”或“今天”)。
-
例:若用戶剛問過“上海天氣”,可確認是否需對比兩地天氣。
-
-
長期記憶:檢索用戶偏好(如用戶曾設置溫度單位為“攝氏度”)。
-
輸出:補充查詢參數,例如:
{"unit": "celsius","user_preference": "show_humidity"
}3.?Tools(工具)
目標:選擇并調用合適的天氣查詢工具。
-
工具匹配:識別可用工具(如?
WeatherAPI、OpenWeatherMap?等)。 -
工具參數:將規劃階段的意圖轉化為工具所需的輸入格式。
-
例:調用?
WeatherAPI?的請求參數:
-
weather_tool.query(location="北京", date="2023-11-20", unit="celsius")-
異常處理:準備備用工具或提示用戶補充信息(如地點模糊時詢問“您指的是北京市朝陽區嗎?”)。
4.?Action(執行)
目標:執行工具并返回用戶可理解的結果。
-
調用工具:發送請求至天氣 API,獲取原始數據。
-
示例 API 返回:
-
{"location": "北京","date": "2023-11-20","temperature": 15,"condition": "晴","humidity": "40%"
}-
結果格式化:將數據轉換為自然語言響應。
-
最終輸出:
“今天北京天氣晴朗,氣溫 15 攝氏度,濕度 40%。”
-
-
錯誤處理:如查詢失敗,反饋原因(如“網絡錯誤”或“地點不存在”
完整流程示例
-
用戶輸入:“今天北京濕度怎么樣?”
-
Planning:解析出?
action=weather_query, location=北京, date=今天, params=[humidity]。 -
Memory:發現用戶偏好“顯示百分比”。
-
Tools:調用?
OpenWeatherMap?的濕度查詢接口。 -
Action:返回“今天北京濕度為 40%”。
三、具體實現
具體構建思路如下:
SimpleAgent/
├── SimpleAgent.py # 主代理類(入口)
├── llm/ # 語言模型模塊
│ ├── __init__.py # 初始化文件
│ └── base_model.py # 抽象模型基類
├── memory/ # 記憶管理模塊
│ ├── __init__.py
│ └── memory.py # 長短期記憶類
├── rag/ # 檢索增強生成模塊
│ ├── __init__.py
│ └── rag.py # RAG檢索生成模塊
├── tool/ # 工具模塊
│ ├── __init__.py
│ ├── calculator.py # 計算器工具
│ ├── weather.py # 天氣查詢工具
│ └── base_tool.py # 工具基類
└── callback/ # 回調處理模塊├── __init__.py└── event_handler.py # 事件處理回調llm /base_model.py? 主要調用大模型作為核心。用來回答基本問題
memory/memory.py 主要用來保存對話數據,主要做簡單的多輪對話
rag/rag.py 主要用來實現檢索功能來使用本地知識庫,使用langchain框架加載向量數據庫Faiss
tool/? 定義了工具基類,通過工具基類實現了calculator和weather 兩個工具。
主要解析SimpleAgent:
1、如何利用大模型理解用戶意圖
????????提示工程(Prompt Engineering)、語義相似度分析、意圖分類技術、多輪對話管理
? ? ? ? 推薦使用提示詞工程
請分析用戶意圖并選擇操作。可用工具:{tools_list}用戶輸入:{prompt}請返回嚴格的JSON格式:{{"tool": "工具名" | null,"action": "use" | "direct_response","params": "參數" | null,}}tool_list包含工具名和工具描述,如果用戶的需求工具可以實現,則通過工具調用,反之則用LLM直接回答。
print(agent.available_tools)
# 輸出: {'calculator': '數學計算器工具...', 'weather': '天氣查詢工具...'}2、如何定義工具和調用
2.1定義工具前,需要設置一個工具基類。
class Tool(ABC):"""工具基類"""def __init__(self):self._is_core = False # 是否為核心工具@property@abstractmethoddef name(self) -> str:"""工具名稱"""pass@abstractmethoddef use(self, params: Dict[str, Any]) -> Any:"""工具主邏輯Args:params: 參數字典Returns:執行結果"""pass2.2定義一個天氣查詢Tool
import requests
from typing import Dict, Anyclass Weather(Tool):"""天氣查詢工具,獲取指定城市的天氣信息"""@propertydef name(self) -> str:return "weather"def use(self, params: Dict[str, Any]) -> Dict:city = params.get("city", "北京")# 實際調用天氣APIresponse = requests.get(f"https://api.weather.com/{city}")return response.json()?2.3 工具的調用
直接調用
result = agent.tool_use(tool_name="weather",params={"expression": "北京"}
)通過LLM自動調度(用戶自然語言輸入 → Agent自動選擇工具 → 返回結果:)
response = agent.llm_tool_dispatcher("查詢北京的天氣")2.4 工具調用詳解
通過使用_llm_analyze_intent()生成如下的意圖結構化決策:
{"tool": "cweather","action": "use","params": {"expression": "北京"}
}通過tool_use()方法調用,得到反饋結果。將反饋結果推送大模型轉換為自然語言進行回復。
2.5 工具的添加
根據自己設置的base_tool來定義對應的工具(記得添加工具描述),然后在Agent中注冊該工具
3、如何設置本地知識庫(基于langchain)
3.1 文本文檔的處理
from langchain.document_loaders import (PyPDFLoader,Docx2txtLoader,UnstructuredFileLoader
)class DocumentLoader:"""支持多種格式的文檔加載器"""@staticmethoddef load(file_path: str):if file_path.endswith('.pdf'):loader = PyPDFLoader(file_path)elif file_path.endswith('.docx'):loader = Docx2txtLoader(file_path)else: # txt/html等loader = UnstructuredFileLoader(file_path)return loader.load()3.2. 向量數據庫配置
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISSclass VectorDB:"""基于FAISS的本地向量數據庫"""def __init__(self):self.embeddings = HuggingFaceEmbeddings(model_name="GanymedeNil/text2vec-large-chinese")def create_index(self, docs, save_path="vector_db"):db = FAISS.from_documents(docs, self.embeddings)db.save_local(save_path)return dbdef load_index(self, path):return FAISS.load_local(path, self.embeddings)?3.3完整RAG實現
class LocalKnowledgeBase:def __init__(self):self.vectordb = VectorDB()self.retriever = Nonedef build_knowledge_base(self, file_paths: list):"""構建知識庫"""all_docs = []for path in file_paths:docs = DocumentLoader.load(path)all_docs.extend(docs)self.vectordb.create_index(all_docs)print("知識庫構建完成")def load_existing_knowledge(self, db_path):"""加載已有知識庫"""self.retriever = self.vectordb.load_index(db_path)def query(self, question: str, top_k=3) -> list:"""檢索知識"""if not self.retriever:raise ValueError("請先加載知識庫")docs = self.retriever.similarity_search(question, k=top_k)return [doc.page_content for doc in docs]3.4 與Agent的交互
class EnhancedAgent(SimpleAgent):def __init__(self, *args, **kwargs):super().__init__(*args, **kwargs)self.knowledge_base = LocalKnowledgeBase()def rag_response(self, query: str) -> str:"""增強的RAG響應"""# 1. 檢索相關知識contexts = self.knowledge_base.query(query)# 2. 構造增強提示prompt = f"""基于以下上下文回答問題:{contexts}問題:{query}答案:"""# 3. 生成最終回復return self.generate_response(prompt)3.5 RAG 使用技巧
1、使用緩存或者保存為本地向量庫,方便以后的查詢
agent = EnhancedAgent("SmartBot")# 首次構建(耗時操作)
agent.knowledge_base.build_knowledge_base(["data/產品手冊.pdf","data/常見問題.docx"
])
# 后續使用直接加載
agent.knowledge_base.load_existing_knowledge("vector_db")from diskcache import Cachecache = Cache("query_cache")@cache.memoize(expire=3600)
def cached_query(question):return self.knowledge_base.query(question)2、采用混合查詢策略
def hybrid_search(query):# 語義檢索semantic_results = self.retriever.similarity_search(query)# 關鍵詞檢索keyword_results = self.retriever.search(query, search_type="mmr")return combine_results(semantic_results, keyword_results)3、關于知識庫的更新
def update_knowledge(file_path):new_docs = load_documents(file_path)self.retriever.add_documents(new_docs)self.retriever.save("vector_db")四、總結
基于大語言模型(LLM)的智能代理(Agent)實現,具有工具使用、記憶和檢索增強生成(RAG)能力。
核心組件
-
語言模型(LanguageModel):基礎的大模型接口
-
記憶系統(Memory):存儲對話歷史
-
工具系統(Tool):可擴展的工具框架
-
回調系統(CallbackHandler):事件處理機制
-
RAG系統:檢索增強生成功能
主要功能解析
1. 初始化與基礎功能
-
__init__?初始化代理名稱、語言模型、記憶、回調和工具系統 -
greet?簡單的問候功能 -
generate_response?基礎文本生成功能
2. 工具系統
-
_init_tools?初始化默認工具(計算器和天氣查詢) -
register_tool/unregister_tool?工具的動態注冊與卸載 -
tool_use?安全執行工具調用,帶超時控制和錯誤處理 -
available_tools?獲取可用工具清單
3. 意圖理解與調度
-
_llm_analyze_intent?核心意圖理解方法:-
構造包含可用工具信息的提示詞
-
要求LLM返回結構化JSON響應
-
使用正則表達式提取JSON結果
-
驗證結果結構有效性
-
-
llm_tool_dispatcher?主調度方法:-
如果有文件路徑,使用RAG處理
-
否則分析用戶意圖
-
根據意圖決定使用工具或直接響應
-
格式化工具結果為自然語言
-
4. RAG功能
-
rag?方法實現檢索增強生成:-
加載文檔
-
檢索相關信息
-
生成回答
-
5. 輔助功能
-
日志記錄
-
錯誤處理
-
回調系統(用于監控和擴展)
-
結果格式化
?完整代碼:https://github.com/rescal-xuan/SimpleAgent

:權衡數據運用,精準把握創業方向)

之旅——String類⑩)








顯示與設置詳解)


 日常運維命令總結)



