最近用了一下RPA軟件,挑了影刀,發現很無腦也很簡單,其語法大概是JAVA和PYTHON的混合體,如果懂爬蟲的話,學這個軟件就快的很,看了一下官方的教程,對于有基礎的人來說很有點枯燥,但又不得不看,畢竟要按照RPA的思路操作就必須懂他們的設計思路;
優點:對于不是特別復雜的需求,很快能上手,相信大部分人爬電商數據,不涉及到點進詳情頁抓各種信息,只抓搜索結果頁面,就很簡單;
缺點:復雜的需求,例如抓詳情頁信息,抓不規律的網站,就很麻煩,嘗試過手動定位節點,軟件還是難以識別,能手動正則\XPATH定位的人,基本也懂爬蟲,當然像淘寶這種詳情頁信息,本身就不簡單,這也怪不得軟件;
例如抓淘寶的數據,如果是爬蟲,基本要用SELENIUM,會涉及到登錄驗證,翻頁和控制速度,要考慮的事情會比較多,也不能速度太快;
一、基本信息爬取和講解
但用RPA就十分簡單;
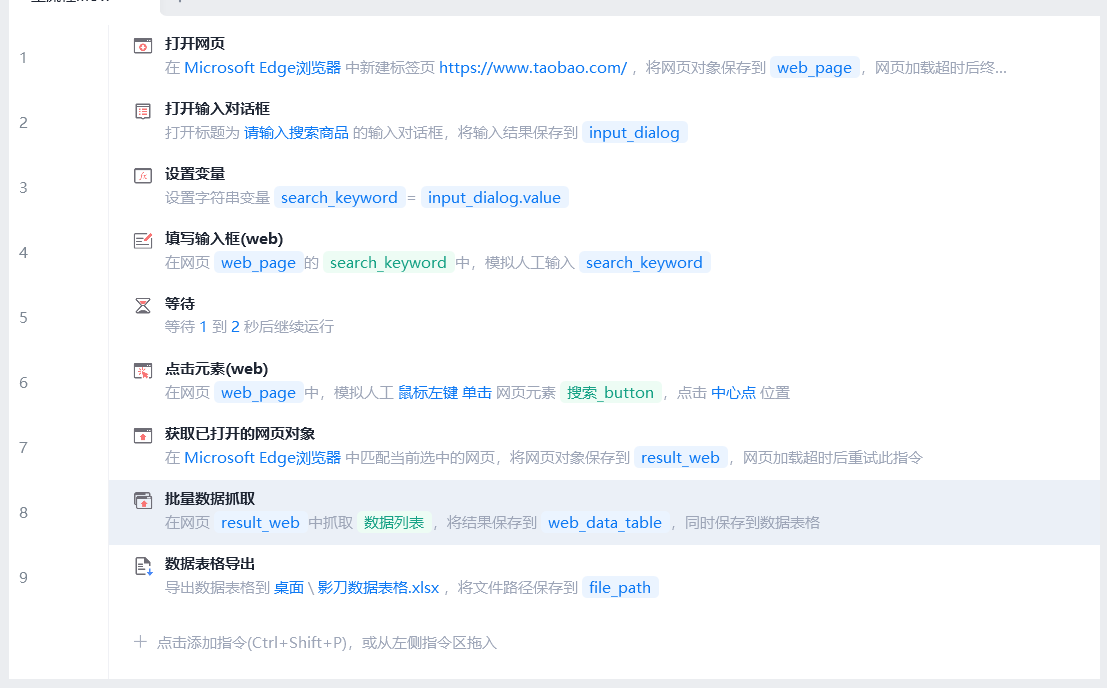
僅需要這幾個步驟即可:
1.打開網頁,以EDGE為例,并不是用的爬蟲常用的EdgeDriver的控制軟件,而是類似的,直接打開網頁,會用保存的Cookies,所以自己有賬號的話,并不需要登錄;
2.有時登錄后會碰到廣告,理論上要把iframe信息點個X,但實測,這廣告會馬上自動消失;此時我們在RPA軟件自帶的彈窗中,輸入關鍵詞;
3.將關鍵詞,保存為一個變量;
4.將變量輸入到淘寶的搜索欄;
5.隨機等1到2秒;
6.點搜索
7.搜索結果會彈出一個新網頁標簽,這一步獲取已打開的網頁對象,類似于selenium的這個操作;
driver.switch_to.window(driver.window_handles[-1])?8.批量抓取數據,這一步,將標題、價格、店鋪、銷量、宣傳tag等東西都抓到,再定位下一頁的位置,會自動抓取一頁的,當然懂爬蟲的會更清晰地知道自己想要什么;
正常情況下,某寶PC端一頁是48個數據,我以搜索顯卡為例,抓了10頁,發現每頁只有46個數據,經觀察,發現某寶前端經常改變;
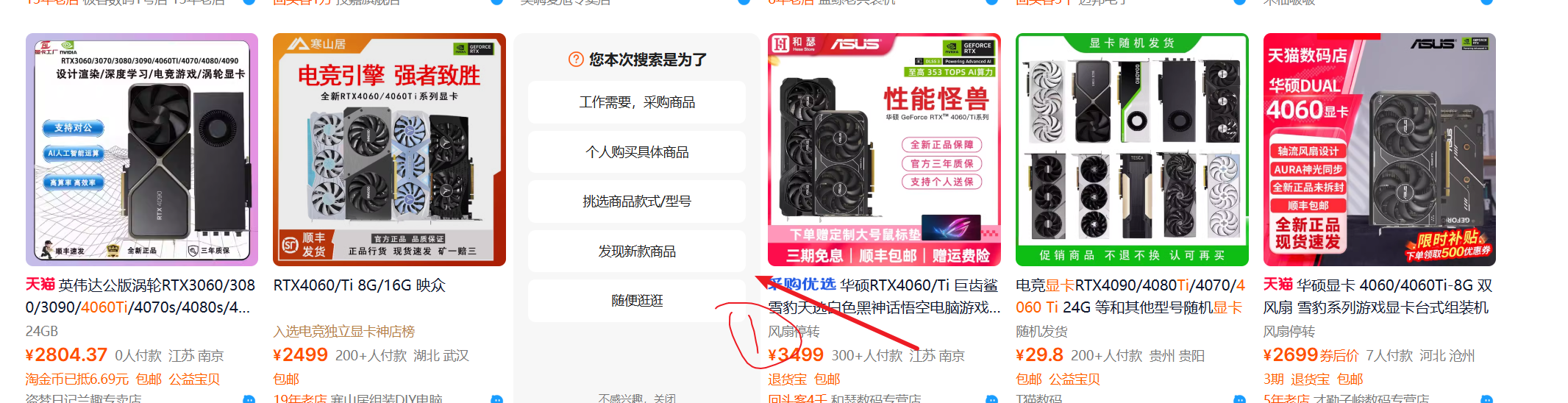
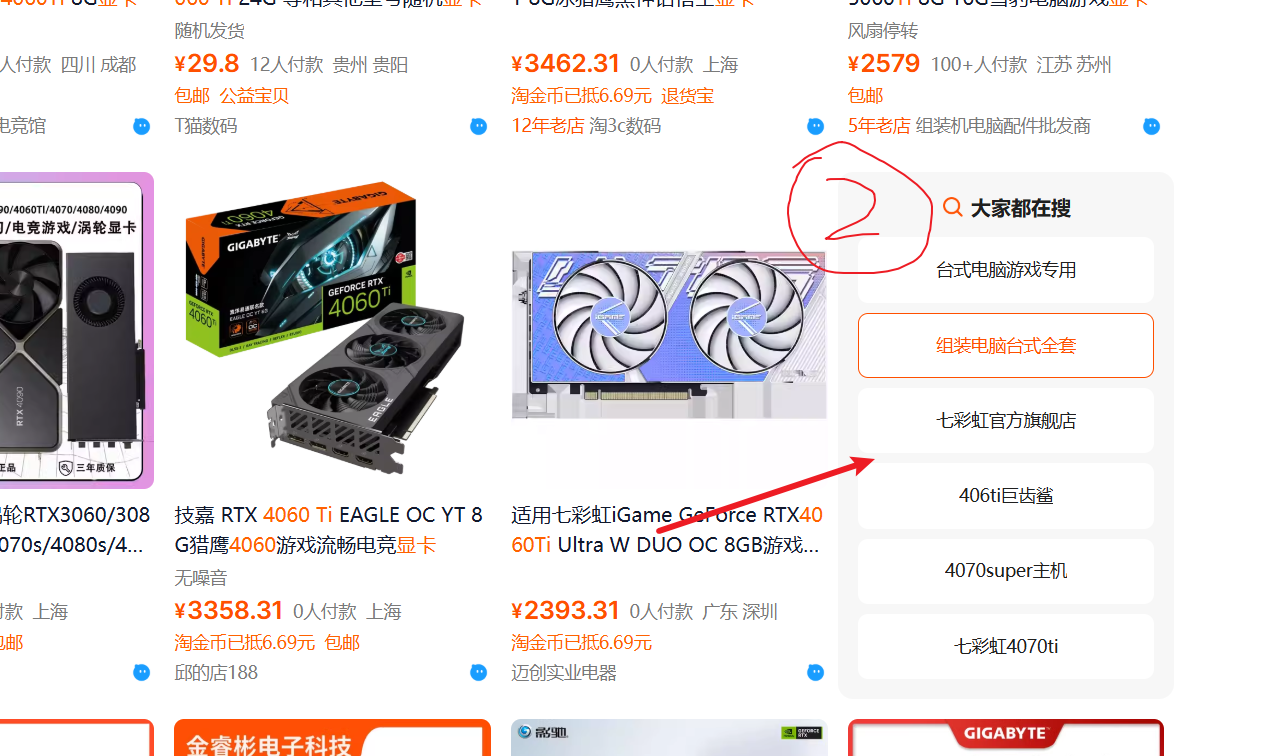
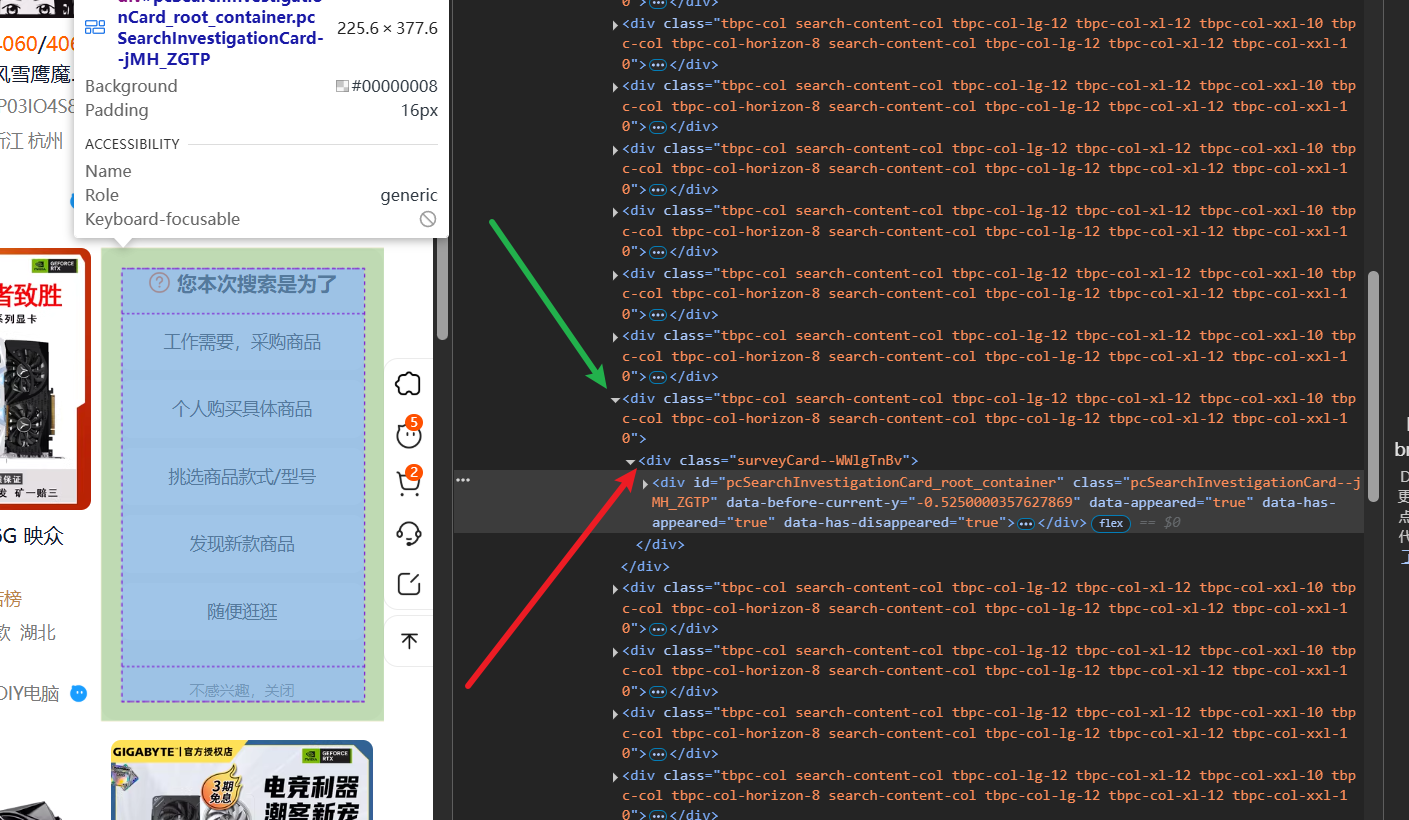
每一頁都有2個這東西,如果自己寫爬蟲的話,經常要考慮很多情況,沒想到影刀能自動剔除掉沒用的數據;
看了一下elements,兩個不要的東西的DIV并不相同,看來是在批量抓取數據的時候,選擇哪些數據比較關鍵,會一些爬蟲自然比較清楚怎么選;
9.最后保存到一個表格即可。
二、點進詳情頁
上面這一部分,我們只抓了基本信息,點進詳情頁的話,情況就復雜很多,那么用影刀的邏輯要大改;
我曾經就搞過詳情頁,后面發現太麻煩,詳情頁里面所需要的信息,基本就是不同SKU對應的價格,可參考
Selenium Python抓淘寶數據 基于手動登錄后_python 抓包淘寶 出現登錄驗證-CSDN博客







顯示與設置詳解)


 日常運維命令總結)








中變量值在控制臺輸出,查看?)