文章目錄
- 一、TensorFlow安裝
- 二、張量、變量及其操作
- 1、張量Tensor
- 2、變量
- 三、tf.keras介紹
- 1、使用tf.keras構建我們的模型
- 2、激活函數
- 1、sigmoid/logistics函數
- 2、tanh函數
- 3、RELU函數
- 4、LeakReLu
- 5、SoftMax
- 6、如何選擇激活函數
- 3、參數初始化
- 1、bias偏置初始化
- 2、weight權重初始化
- 1、隨機初始化
- 2、標準初始化
- 3、Xavier初始化
- 4、He初始化
- 4、神經網絡構建
- 1、通過Sequential構建
- 2、function api方式構建
- 3、Model子類構建方式
- 5、神經網絡的優缺點
一、TensorFlow安裝
# 1、非GPU版本安裝
pip3 install tensorflow==2.3.0# 2、GPU版本安裝
pip3 install tensorflow-gpu==2.3.0
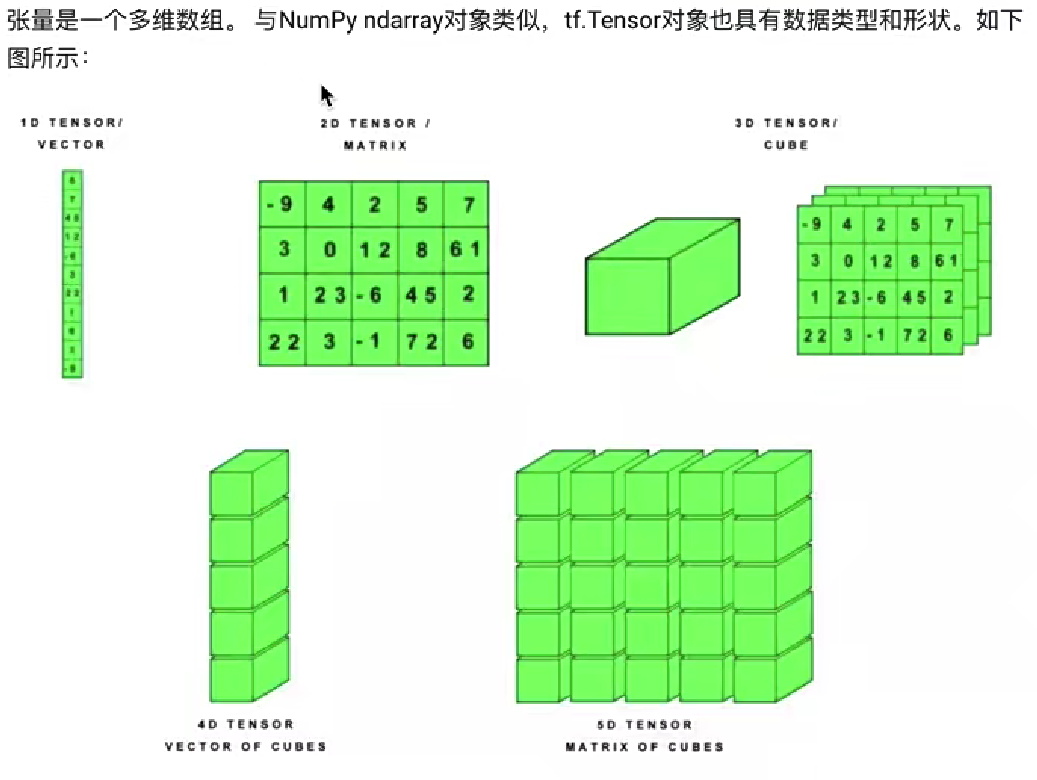
二、張量、變量及其操作
1、張量Tensor
import tensorflow as tf
import numpy as np# 創建基礎的張量
## 1.創建int32類型的0維張量,即標量
rank_0_tensor = tf.constant(4)
print(rank_0_tensor)## 2.創建float32類型的1維張量
rank_1_tensor = tf.constant([2.0, 3.0, 4.0])
print(rank_1_tensor)## 3.創建float16類型的二維張量
rank_2_tensor = tf.constant([[1, 2],[3, 4],[5, 6]
], dtype=tf.float16)
print(rank_2_tensor)## 4.將張量轉化為ndarray
np1 = np.array(rank_2_tensor)
print(np1)np2 = rank_2_tensor.numpy
print(np2)# 張量常用函數
a = tf.constant([[1, 2],[3, 4]
])
b = tf.constant([[1, 1],[1, 1]
])
print(tf.add(a, b)) # 計算張量元素的和
print(tf.multiply(a, b)) # 計算張量元素的乘積
print(tf.matmul(a, b)) # 計算張量矩陣的乘法# 聚合運算
c = tf.constant([[4.0, 5.0],[10.0, 1.0]
])
print(tf.reduce_max(c)) # 最大值
print(tf.reduce_mean(c)) # 平均值
print(tf.reduce_sum(c)) # 求和
print(tf.reduce_min(c)) # 最小值
print(tf.argmax(c)) # 最大值索引
print(tf.argmin(c)) # 最小值索引
2、變量

# 變量
var = tf.Variable([[1, 2],[3, 4]
])
print(var.shape) # 獲取變量的形狀
print(var.dtype) # 獲取變量中數據類型
print(var.numpy) # 轉化為ndarray
print(var.assign([[5, 6], [7, 8]])) # 修改變量值
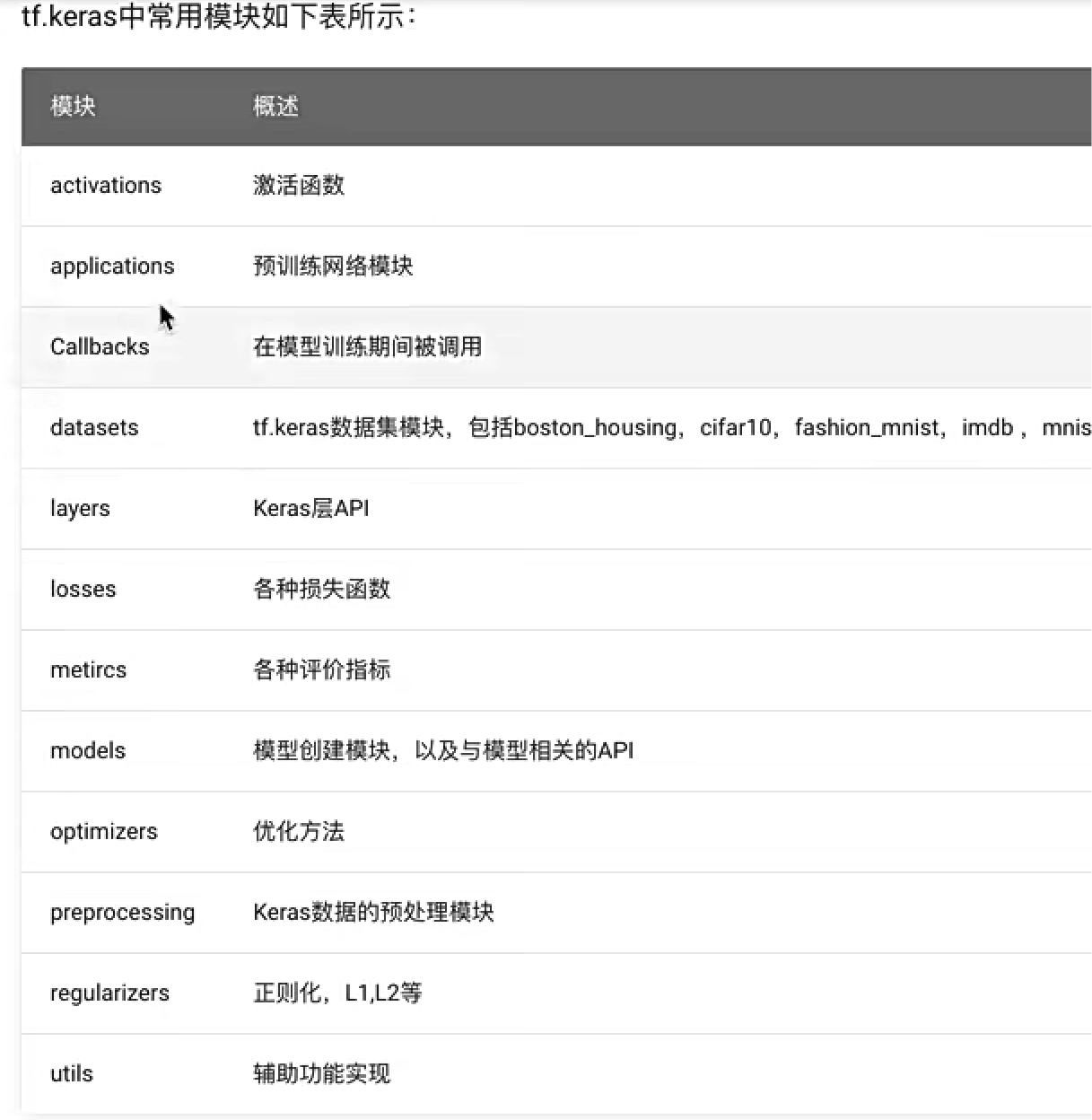
三、tf.keras介紹
1、使用tf.keras構建我們的模型
# 繪圖工具
import seaborn as sns
# 數組計算
import numpy as np
# sklearn相關工具
from sklearn.datasets import load_iris
# 劃分測試集和訓練集
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# 邏輯回歸
from sklearn.linear_model import LogisticRegressionCV
# tf.keras中使用的相關工具
# 用于模型搭建
from tensorflow.keras.models import Sequential
# 構建模型的層和激活工具
from tensorflow.keras.layers import Dense, Activation
# 數據處理的輔助工具
from tensorflow.keras import utils
# pandas工具,讓數據更好看
import pandas as pd# 1.使用sklearn獲取鳶尾花數據
iris = load_iris()
iris_d = pd.DataFrame(data=iris.data, columns=['sepal_length', 'sepal_width', 'petal_length', 'petal_width'])
# 設置其目標值為target_names
iris_d['species'] = iris['target_names'][iris['target']]
# 使用seaborn中的pairplot函數探索數據特征間的關系
sns.pairplot(iris_d, hue="species")# 使用sklearn實現# 所有的特征值
x = iris_d.values[:, :4]# 所有的目標值
y = iris_d.values[:, 4]# 利用train_test_split完成數據集劃分,測試集20%,訓練集80%
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0)# 特征預處理
# transfer = StandardScaler()
transfer = MinMaxScaler((0, 1))
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)## 模型調優 - 交叉驗證、網格搜索
# 實例化估計器,CV這個估計器已經調過優了
lr = LogisticRegressionCV()
# 模型訓練
lr.fit(x_train, y_train)
# 模型評估
lr.score(x_test, y_test)# 使用tf.keras實現
# 1.生成目標值的熱編碼
def one_hot_encode(arr):# 獲取目標值中的所有類別進行熱編碼uniques, ids = np.unique(arr, return_inverse=True)return utils.to_categorical(ids, len(uniques))# 2.對目標值進行熱編碼
y_train_one = one_hot_encode(y_train)
y_test_one = one_hot_encode(y_test)# 3.模型構建
model = Sequential([# 隱藏層,輸入層,input_shape表示我們有幾個特征Dense(10, activation="relu", input_shape=(4,)),# 隱藏層Dense(10, activation="relu"),# 輸出層,3表示我們有幾種結果Dense(3, activation="softmax")
])# 4.模型預測與評估
## 4.1 模型編譯
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])## 4.2 模型訓練
# 類型轉換
x_train = np.array(x_train, dtype=np.float32)
x_test = np.array(x_test, dtype=np.float32)
model.fit(x_train, y_train_one, epochs=10, batch_size=1, verbose=1)## 4.3模型評估
loss, accuracy = model.evaluate(x_test, y_test_one, verbose=1)
print("loss: ", loss)
print("準確率:", accuracy)
2、激活函數
1、sigmoid/logistics函數
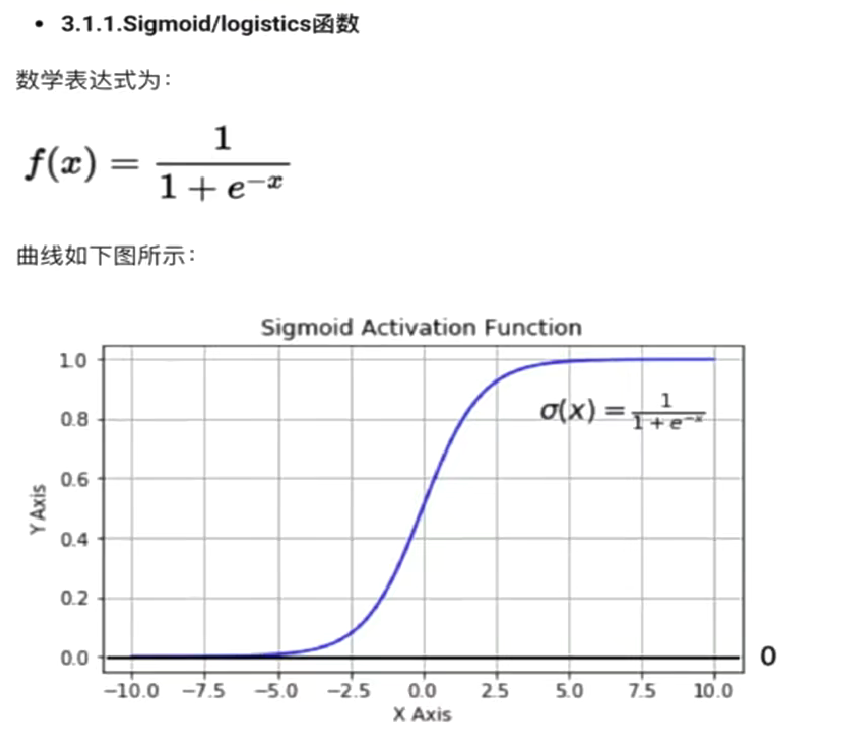

一般只用于輸出層的二分類
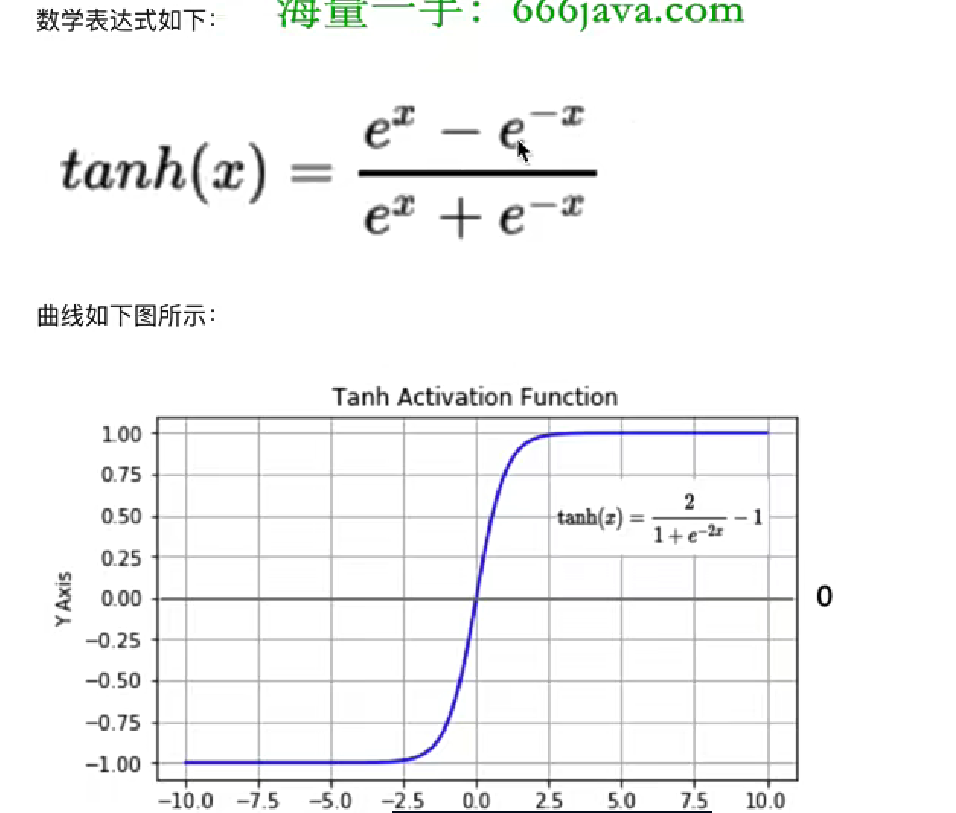
2、tanh函數

3、RELU函數
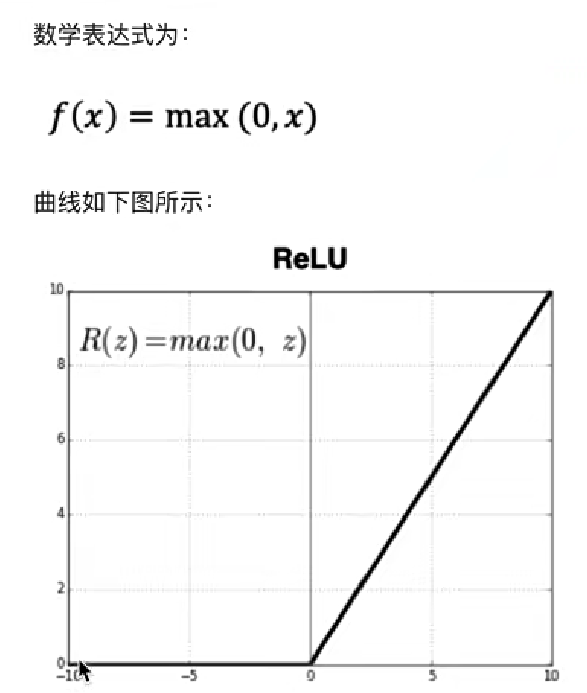


無腦使用RELU
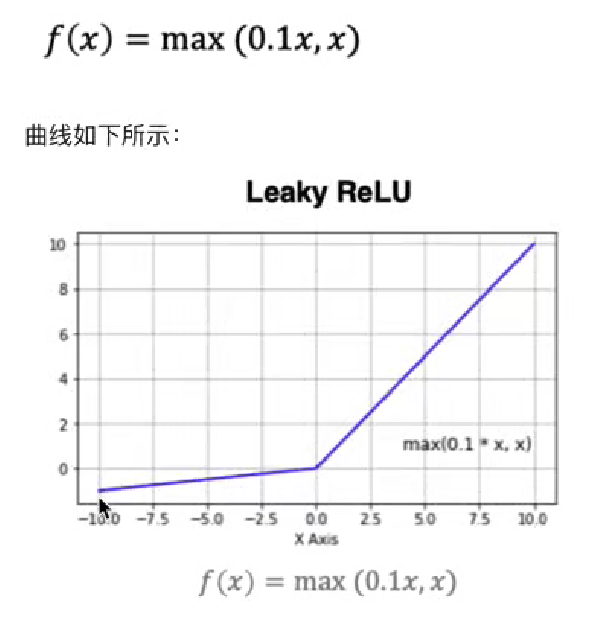
4、LeakReLu
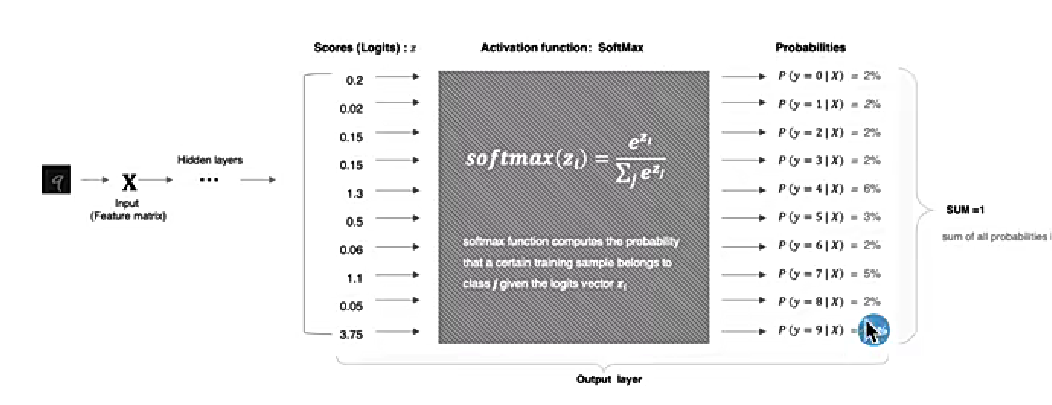
5、SoftMax
softmax用于多分類過程中,它是二分類函數sigmoid在多分類上的推廣,目的是將多分類的結果以概率的形式展示出來。
6、如何選擇激活函數

3、參數初始化
1、bias偏置初始化
直接初始化為0
2、weight權重初始化
1、隨機初始化
隨機初始化從均值為0,標準差是1的高斯分布中取樣,使用一些很小的值對參數w進行初始化
2、標準初始化
權重參數初始化從區間均勻隨機取值,即在(-1/根號d/,根號d/1)均勻分布中生成當前神經元的權重,其中d為每個神經元的輸入數量
3、Xavier初始化
該方法的基本思想是各層的激活值和梯度的方差在傳播過程中保持一致,也叫做Glorot初始化,在tf.keras中實現方法有兩種:
- 正態化Xavier初始化

- 標準化Xavier初始化

4、He初始化
he初始化,也稱為Kaiming初始化,他的基本思想是正向傳播時,激活值的方差保持不變;反向傳播時,關于狀態值的梯度的方差保持不變
- 正太化的he初始化

- 標準化的he初始化

4、神經網絡構建
1、通過Sequential構建
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers# 定義一個Sequential模型,包含3層
model = keras.Sequential([# 第一層:激活函數為relu,權重初始化為he_normallayers.Dense(3, activation="relu", kernel_initializer="he_normal", name="layer1", input_shape=(3, )),# 第二層:激活函數為relu,權重初始化為he_normallayers.Dense(2, activation="relu", kernel_initializer="he_normal", name="layer2"),# 第三次:激活函數為sigmoid,權重初始化和he_normallayers.Dense(2, activation="sigmoid", kernel_initializer="he_normal", name="layer3")
])model.summary()
2、function api方式構建

# 使用function api方式構建神經網絡
import tensorflow as tf
# 定義模型的輸入
inputs = tf.keras.Input(shape=(3,), name = 'input')
# 第一層:激活函數為relu,其他默認
x = tf.keras.layers.Dense(3, activation='relu', name='layer1')(inputs)
# 第二層:激活函數為relu,其他默認
x = tf.keras.layers.Dense(2, activation='relu', name='layer2')(x)
# 第三次:輸出層,激活函數為sigmoid
outputs = tf.keras.layers.Dense(2, activation='sigmoid', name='layer3')(x)
# 使用Model創建模型
model = tf.keras.Model(inputs = inputs, outputs=outputs, name='my_model')
model.summary()
3、Model子類構建方式
# 使用Model子類的方式構建神經網絡
import tensorflow as tfclass MyModel(tf.keras.Model):# 在init方法中定義網絡的層結構def __init__(self):super(MyModel, self).__init__()# 第一層:激活函數為relu,權重初始化為he_normalself.layer1 = tf.keras.layers.Dense(3, activation='relu', kernel_initializer='he_normal', name='layer1', input_shape=(3,))# 第二層:激活函數為relu,權重初始化為he_normalself.layer2 = tf.keras.layers.Dense(2, activation='relu', kernel_initializer='he_normal', name='layer2')# 第三次:激活函數為sigmoid,權重初始化為he_normalself.layer3 = tf.keras.layers.Dense(2, activation='sigmoid', kernel_initializer='he_normal', name='layer3')# 在call方法中完成前向傳播def call(self, inputs):x = self.layer1(inputs)x = self.layer2(x)return self.layer3(x)# 實例化model
model = MyModel()
# 設置一個輸入調用模型(否則無法使用summary方法)
x = tf.ones((1, 3))
y = model(x)
model.summary()
5、神經網絡的優缺點

 日常運維命令總結)








中變量值在控制臺輸出,查看?)
——創建,退出)



:InstructGPT 原理與實現)

)


