📌 論文地址:Training language models to follow instructions with human feedback
💻 參考項目:instructGOOSE
📷 模型架構圖:
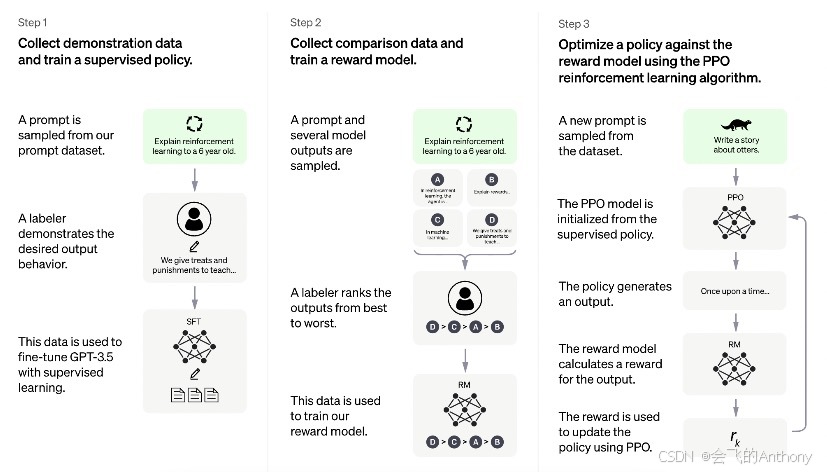
一、引言:為什么需要 InstructGPT?
????????傳統的語言模型往往依賴于“最大似然訓練”,學會如何生成符合語法的文本,但卻不一定符合人類的指令意圖。OpenAI 提出的 InstructGPT 是一種結合 人類反饋監督 + 強化學習(RLHF) 的新訓練范式,其目標是使語言模型更能“聽人話”。
????????????????InstructGPT 的三階段訓練流程如下:
-
SFT(Supervised Fine-tuning):使用人工標注的指令-回復數據進行有監督微調。
-
RM(Reward Modeling):讓人工對模型生成的多個候選回復打分,從而訓練一個獎勵模型。
-
PPO(Proximal Policy Optimization):使用 RL 算法訓練語言模型,使其生成的回復最大化獎勵模型的得分。
????????本篇將結合 instructGOOSE 項目,對上述三階段進行端到端復現,使用的數據集為 IMDb 影評文本,語言模型為 GPT-2。
二、準備工作:環境與設備
# 安裝依賴
# pip3 install instruct_gooseimport os
import torchfrom datasets import load_dataset
from torch.utils.data import DataLoader, random_split
from tqdm.auto import tqdm# 設置 GPU 設備(如使用 Colab 建議 comment 掉代理配置)
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
os.environ['http_proxy'] = 'http://192.41.170.23:3128'
os.environ['https_proxy'] = 'http://192.41.170.23:3128'device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Using device:", device)
三、加載 IMDb 數據集并構建 DataLoader
dataset = load_dataset("imdb", split="train")# 為演示快速收斂,僅使用前 10 條數據
dataset, _ = random_split(dataset, lengths=[10, len(dataset) - 10])train_dataloader = DataLoader(dataset, batch_size=4, shuffle=True)
四、加載 GPT-2 模型與 InstructGPT 工具鏈
from transformers import AutoTokenizer, AutoModelForCausalLM
from instruct_goose import Agent, RewardModel, RLHFTrainer, RLHFConfig, create_reference_modelmodel_name_or_path = "gpt2"# 加載主模型與獎勵模型
model_base = AutoModelForCausalLM.from_pretrained(model_name_or_path)
reward_model = RewardModel(model_name_or_path)# 加載 tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, padding_side="left")
tokenizer.pad_token = tokenizer.eos_token
eos_token_id = tokenizer.eos_token_id
五、創建 RL 模型代理與參考模型
# 構造 Agent(語言模型 + Value 網絡 + 采樣接口)
model = Agent(model_base)
ref_model = create_reference_model(model)
六、訓練配置與 RLHFTrainer 初始化
max_new_tokens = 20
generation_kwargs = {"min_length": -1,"top_k": 0.0,"top_p": 1.0,"do_sample": True,"pad_token_id": eos_token_id,"max_new_tokens": max_new_tokens
}config = RLHFConfig() # 可使用默認參數trainer = RLHFTrainer(model, ref_model, config)
七、基于 PPO 的 InstructGPT 強化訓練
from torch import optimoptimizer = optim.Adam(model.parameters(), lr=1e-3)
num_epochs = 3for epoch in range(num_epochs):for step, batch in enumerate(tqdm(train_dataloader)):# Step 1: 編碼輸入inputs = tokenizer(batch["text"],padding=True,truncation=True,return_tensors="pt")inputs = {k: v.to(device) for k, v in inputs.items()}# Step 2: 使用主模型生成回復response_ids = model.generate(inputs["input_ids"], attention_mask=inputs["attention_mask"],**generation_kwargs)response_ids = response_ids[:, -max_new_tokens:]response_attention_mask = torch.ones_like(response_ids)# Step 3: 拼接 query + response,使用 Reward Model 評估得分with torch.no_grad():input_pairs = torch.stack([torch.cat([q, r], dim=0)for q, r in zip(inputs["input_ids"], response_ids)]).to(device)rewards = reward_model(input_pairs)# Step 4: 計算 PPO 損失并反向傳播loss = trainer.compute_loss(query_ids=inputs["input_ids"],query_attention_mask=inputs["attention_mask"],response_ids=response_ids,response_attention_mask=response_attention_mask,rewards=rewards)optimizer.zero_grad()loss.backward()optimizer.step()print(f"[Epoch {epoch+1}] Loss = {loss.item():.4f}")
八、推理測試與結果展示
# 輸入一句文本進行測試
input_text = dataset[0]['text']
input_ids = tokenizer.encode(input_text, return_tensors="pt").to(device)output = model_base.generate(input_ids, max_length=256,num_beams=5, no_repeat_ngram_size=2,top_k=50, top_p=0.95, temperature=0.7
)generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print("🧠 模型生成結果:\n", generated_text)
九、總結
????????本篇我們復現了 InstructGPT 的核心訓練框架,依賴于三大模塊:
-
語言模型(GPT2);
-
獎勵模型(RewardModel);
-
強化訓練器(RLHFTrainer + PPO loss)。
????????通過引入人類反饋偏好作為優化目標,InstructGPT 展現出更強的任務理解與指令遵循能力,已經成為 ChatGPT 訓練體系的核心組成部分之一。
🔮 下一篇預告
????????📘《基于 Python 的自然語言處理系列(84):SFT原理與實踐》
如果你覺得這篇博文對你有幫助,請點贊、收藏、關注我,并且可以打賞支持我!
歡迎關注我的后續博文,我將分享更多關于人工智能、自然語言處理和計算機視覺的精彩內容。
謝謝大家的支持!

)

















