
目錄
目錄
目錄
發行刊物
ABSTRACT
1 INTRODUCTION
2 RELATED WORK(相關工作
2.1 Spatial-temporal Forecasting(時空預測
2.2 Spatial-temporal Forecasting withIncomplete Data(不完全數據的時空預測
2.3 Graph Contrastive Learning(圖形對比學習
3 PROPOSED BASE MODEL(提出基本模型
3.1 Concepts and Problem Statement(概念和問題描述
3.2 Overview of Our Base Model(我們的基本模型概述
3.3 Sub-graph Masking(子圖掩蔽
3.4 Spatial-temporal Modelling(時空建模
3.5 Model Training and Testing(模型訓練和測試
?
4 PROPOSED FULL MODEL(提出的完整模型
4.1 Selective Masking(選擇性掩碼
4.2 Graph Contrastive Learning(圖形對比學習
5 EXPERIMENTS(實驗
5.1 Experimental Setup(實驗設置
5.2.1模型性能比較(go on
6 CONCLUSIONS AND FUTURE WORK(結論和未來的工作
發行刊物

ABSTRACT

時空預測在交通預測、空氣污染預測、人群流動預測等許多實際應用中發揮著重要作用。最先進的時空預測模型采用數據驅動的方法,并在很大程度上依賴于數據的可用性。當數據不完整時,這種模型會出現準確性問題,這在現實中很常見,因為部署和維護數據收集傳感器的成本很高。
(數據不完整性)

最近的一些研究試圖解決數據不完整的問題。他們通常假設某個感興趣的區域在短時間內或在較低的位置有一些數據可用性。在本文中,我們進一步研究了在沒有任何歷史觀測的情況下對感興趣區域進行時空預測,以解決區域發展不平衡、傳感器逐步部署或缺乏開放數據等情況。我們為該任務提出了一個名為STSM的模型。
已有研究:假設感興趣的區域附近有數據:短期或者鄰近位置
本文研究:要研究的區域沒有任何歷史觀測數據該怎么處理,提出的模型是STSM
摘要還提到沒有任何歷史數據的現實原因:區域發展不平衡、傳感器逐步部署或缺乏開放數據

該模型采用基于對比學習的方法,從已記錄數據的相鄰區域學習空間-時間模式。我們的關鍵見解是從與感興趣區域相似的位置學習,我們提出了一種選擇性掩蔽策略來進行學習。因此,我們的模型優于最先進的自適應模型,在交通和空氣污染物預測任務中始終減少誤差。
我們感興趣的位置還沒任何歷史數據,但它的鄰近位置有歷史數據
我們的想法:
- 從哪學習?①從感興趣的鄰近位置學習②從與感興趣的位置的相似位置學習
- 提出的學習策略:選擇性掩蔽??selective masking strategy
- 我們的模型是sota,針對交通預測任務和空氣污染任務
1 INTRODUCTION

時空預測是許多實際應用的重要組成部分,例如智能交通系統(ITS)和空氣質量監測系統。當前最先進的時空預測方法是數據驅動的。他們利用順序模型
重點研究的是:交通預測和空氣質量檢測(交通&空氣)
開始講現在的 sota

例如,一維卷積神經網絡(CNN)[20,22,31]或遞歸神經網絡(RNN)[16],以捕獲時間特征,以及空間模型,例如,圖神經網絡(GNN),其對空間關系進行建模[20,23,31]。
temporal features:時間特征
spatial:空間
CNN RNN 時間空間
GCN 空間

然而,由于傳感器的高部署和維護成本以及不穩定的傳輸介質,數據稀缺是普遍存在的。因此,開發一個能夠在沒有完整歷史數據的情況下進行快速預測的模型至關重要
提出問題:數據稀缺很常見(至于理由就是現實原因)
在沒有任何歷史數據的情況下預測

先前解決時空任務數據稀缺問題的嘗試分為兩類:(1)數據有時缺失[14,17,25,32,36]:由于復雜的環境和/或傳感器故障,或傳感器部署時間短,感興趣位置的觀測一直不完整;

散射)位置[1,30,39]:由于感興趣的位置沒有記錄歷史數據(例如,在這些位置沒有部署傳感器),因此缺少觀測結果。對于后一類,最近的研究重新審視了克里格[7]。其目的是通過插入未觀測位置的衍生數據,通過粗粒度觀測生成細粒度記錄。
注:數據缺失的兩種原因:
1,data missing at times :時間上的缺失? 傳感器安裝的時間短,采集數據不夠
2,data missing at?(scattering) locations:空間上的缺失 就沒安裝采集數據的傳感器
又著重說了,空間上的缺失,處理方法是 生成數據

最先進的模型[30,39]采用神經網絡作為解決方案。這兩個類別都假設了感興趣區域的一些可用數據,如圖1(a)和1(b)所示
注:
1,現在的sota是 神經網絡模型
2,不管是時間上的缺失還是空間上的缺失,都假定了 感興趣的區域有一些數據

(a)時間上的缺失
(b)空間上的缺失
(c)我們解決的問題:在連續的時間和空間上數據都缺失
圖1:問題設置比較。彩色地圖和灰色地圖分別表示觀測到和未觀測到的數據。我們的重點是案例(c)

現有研究沒有考慮“連續”數據稀缺的情況,即沒有任何數據觀測的所有位置都指向一個連續的子區域(即感興趣的區域沒有可用的數據),而區域邊界與有數據觀測的位置相鄰。

圖1(c)說明了這種情況,當(1)傳感器從一個地區逐漸部署到另一個地區時(香港觀察到了一種這種情況[25]),(2)一些地區沒有資源部署傳感器(例如,上海交通擁堵數據僅覆蓋核心城市地區[37]),或(3)各地區不愿意公開其數據(例如,Tom交通指數[27]沒有來自中國大陸的數據)。

為了填補這一空白,我們提出了一個新問題——在沒有歷史數據的情況下對感興趣區域進行時空預測。

這個新問題具有挑戰性,現有的基于克里格的方法[30,39]并不能直接解決這個問題。這是因為基于克里格方法的核心思想是根據有觀測的相鄰位置(或時間)對沒有觀測的位置進行數據插值,這在我們的設置中是不可用的。
注:
克里格方法根據有觀測的位置對沒有觀測的位置進行數據插值。
(為什么我們的問題不能用?)

例如,早期的模型IGNNK[30]將感興趣的區域表示為圖,并利用GNN進行克里格。它報告說,在我們的設置中,性能顯著下降(詳見第5.2節),因為當一個位置的本地鄰居沒有歷史觀測來幫助推斷數據時,GNN就會變得無效。
注:
我們研究的位置:是鄰居也沒有歷史觀測的。(啊?6

最先進的克里格模型INCREASE[39]也使用了基于圖的區域表示。它提前聚合了最近鄰居的信息

然后使用GRU(這是一種RNN)來捕獲數據的時間相關性。該模型未能利用圖的全局特征,因為它只考慮最近的鄰居。

我們提出了一種具有選擇任務策略的時空預測模型,稱為STSM,以使我們能夠從與感興趣區域相似的位置中學習,并在沒有觀測的情況下預測感興趣區域。我們屏蔽子區域(靠近感興趣區域并有歷史數據)的觀測數據,并訓練STSM對子區域進行預測。

spatial-temporal forecasting model with a selective masking strategy 選擇性掩蔽策略的時空預測模型
我的理解:
?當前位置沒有觀測數據,鄰近位置有觀測數據,我們的把鄰近位置的觀測數據隱藏,并用STSM預測,當成訓練數據

然后,在測試時,我們利用感興趣區域和訓練中使用的子區域之間的相似性來預測感興趣區域
挖掘相似性(感興趣+子區域)→預測(感興趣)

與使用隨機掩蔽的現有研究[30]不同,STM結合了選擇性掩蔽模塊來掩蔽與感興趣區域更相似的子區域。這種策略使STSM更容易將其預測能力從掩蔽子區域擴展到感興趣的區域。
隱蔽策略:掩蔽子區域,什么樣的子區域:與感興趣的區域相同的區域
子區域是鄰近區域把?
掩蔽了再訓練,學習的模型也就可以捕捉從掩蔽到感興趣的變化趨勢

選擇性掩蔽模塊融合區域特征、道路網絡特征和空間距離,以計算掩蔽子區域(即掩蔽位置)和感興趣區域(即未觀測位置)之間的相似性得分。相似性得分標準化為[0,1]的范圍,并用作描述要屏蔽的子區域(或位置)的概率。
掩蔽位置有沒有觀測數據?我覺得有。
特征:①區域特征②路網特征③空間距離→計算感興趣位置和掩蔽位置的相似性

此外,我們使用觀測位置的歷史數據來生成未觀測位置和主題位置的偽觀測值,這使得能夠計算基于時間相似性的鄰接矩陣,即,我們在觀測位置和具有高時間相似度的未觀測位置之間建立鏈接。這有助于識別更多相似的鄰居。

總體而言,本文做出了以下貢獻:
? 我們提出了一種新的時空預測任務——無歷史觀測區域的預報。這項任務可用于解決區域發展不平衡和缺乏開放數據的問題

- 我們設計了一個選擇性掩蔽模塊,以指導我們的模型STSM掩蔽與未觀測區域具有高度相似性的觀測位置,從而使STSM能夠對未觀測區域進行廣義預測。
- 我們設計了一個有效的偽觀測生成策略,并計算了一個基于時間鄰接矩陣的onit,以幫助識別信息量更大的鄰居并提高模型的學習效率

- 大量實驗表明,就預測精度而言,我們的模型優于我們適應這一新問題的最先進模型
2 RELATED WORK(相關工作
2.1 Spatial-temporal Forecasting(時空預測

目前最先進的時空預測模型主要基于深度神經網絡。DCRNN[16]引入了一種擴散卷積遞歸神經網絡來對位置之間的空間相關性進行建模,并采用門控遞歸單元(GRU)來對時間相關性進行建模。GRU和其他RNN模型具有遞歸結構,其在模型運行時間和建模較長序列的有效性方面受到影響

為了克服這一限制,GraphWaveNet[31]利用一維時間卷積模塊來捕捉時間相關性。此外,注意力機制[33]被廣泛用于時空預測[6,8,10,38]。最近的一系列研究進一步將異構關系嵌入到鄰接矩陣中,包括時間相似性[15,22]和嵌入

相似性[20]。一些研究[11-13,18]采用自我監督學習來增強時空模式表征。同時,DeepSTUQ[21]在預測流量時考慮了預測的不確定性。這些模型假設歷史數據完全可用,當數據不完整時,學習能力會受到影響
2.2 Spatial-temporal Forecasting withIncomplete Data(不完全數據的時空預測

從數據的角度來看,現有的不完全數據時空預測方法可分為兩類:時間上的數據缺失和(散射)位置上的數據丟失。
又在強調:時間上的缺失和(一些零星地點的)缺失

數據有時缺失:感興趣位置的觀測始終不完整。對于這一類別,一類主要研究集中在惡劣環境[14,17]引起的隨機或連續數據丟失,例如極端天氣或傳輸設備問題。生成對抗性網絡(GAN)被應用于解決這個問題[32,36]。另一項研究[25]將遷移學習用于傳感器僅在短時間內(例如10天)部署的環境
惡劣天氣導致數據 時間上的 缺失
觀測時間上的缺失solve:生成對抗網和遷移學習

(散射)位置的數據丟失:一些感興趣的位置根本沒有觀測結果。考慮到這種設置的問題,即克里格[7],旨在通過粗粒度記錄來估算細粒度記錄,這是為了恢復未觀測到的位置的信號。高斯過程回歸[29]是一種經典的解決方案,但效率低,可擴展性差。張量/矩陣補全算法[2,24,41]在大型數據集上顯示出更好的效率。它們結合了低階結構和正則化,以保持局部和全局的一致性。大多數張量/矩陣完成算法都是轉導的。如果沒有重新培訓,他們就無法處理感興趣的新地點。
地點上的缺失:Kriging

最近的研究[30,39]提出了歸納結構。例如,IGNNK[30]利用GNN的誘導性質和1-D CNN來記錄未觀察到的位置。該模型很難處理高數據丟失率,因為從鄰域中幾乎沒有信息可供學習。INCREASE[39]采用RNN進行歸納插補。該方法使用異構關系進行更準確的估計,同時難以捕獲全局時空模式。
2.3 Graph Contrastive Learning(圖形對比學習

我們提出的STSM基于對比學習,特別是圖形對比學習(GCL),它將對比學習應用于圖形數據。對比學習的基本思想是最大限度地提高正樣本之間的相似度,同時最小化負樣本之間的相似性

一系列研究[34,35,42]集中于生成正樣本和負樣本的圖擴充模塊。例如,GraphCL[35]引入了四種增強方法,如節點丟棄和邊緣擾動,以創建正圖對。后來,GCA[42]和JOAO[34]通過考慮節點權重和邊權重來改進增廣策略。此外,一些研究[23,28]旨在最大化不同尺度的圖輸入之間的相互信息,例如節點與圖。

一些研究[5,18]將GCL引入空間學習任務。例如,SARN[5]通過對比學習學習道路網絡嵌入,STGCL[18]應用GCL來預測交通流量,并提供完整的數據。與STGCL不同,我們的模型可以處理完整的數據,因為所提出的選擇性掩蔽模型可以基于

觀察到的和未觀察到的位置之間的異質相似性。
3 PROPOSED BASE MODEL(提出基本模型

我們從我們提出的模型的一個基本版本開始,命名為dSTSM RNC(圖2)。我們首先定義了基本概念和我們研究的問題。然后,我們介紹了我們的基本模型及其訓練和測試程序。
3.1 Concepts and Problem Statement(概念和問題描述

區域和區域圖。我們將區域表示為圖𝐺=(𝑉,𝐸). 圖頂點的集合𝑉代表𝑁興趣在區域中的位置(感興趣區域的N個位置),以及圖的邊集𝐸表示位置之間的連接。圖表𝐺有一個特征矩陣L∈R𝑁×𝐹對于位置,其中𝐹是位置特征的維度。位置的特征由兩部分組成,即區域信息和道路網絡信息,將在第4.1節中詳細介紹。

對于每個位置𝑣𝑖∈𝑉,𝑥𝑡𝑖∈R𝐶代表觀察結果𝑣𝑖在時間步長𝑡, 哪里𝐶是不同類型觀測的數量,例如交通速度、PM2.5等。

觀察到和未觀察到的區域。區域圖𝐺可以根據子區域的觀測可用性,即觀測區域和未觀測區域,進一步劃分為兩個相鄰的子區域。這兩個區域中的位置分別被稱為觀測位置(即有觀測)和未觀測位置(如無觀測)。我們使用𝑅𝑜表示包含所有且僅包含觀測到的位置的區域。同樣,我們使用𝑅𝑢表示包含所有且僅包含未知位置的區域。

這兩個區域彼此不重疊。,𝑅𝑜∩𝑅𝑢=𝜙. 我們使用𝐺𝑜=(𝑉𝑜,𝐸𝑜)表示觀察到的位置上的圖形,其中𝑉𝑜?𝑉表示觀測位置的集合,以及𝐸𝑜?𝐸∩ (𝑉𝑜×𝑉𝑜)表示上的邊的集合𝑉𝑜. Weuse𝑁𝑜表示的大小𝑉𝑜. 類似地,我們定義了未觀測位置上的圖形,表示為𝐺𝑢, 然后是節點𝑉𝑢(及其大小𝑁𝑢) 和邊緣𝐸𝑢在這張圖上。注意,𝑁=𝑁𝑜+𝑁𝑢;十、𝑡𝐺𝑜=(𝑥𝑡1.𝑥𝑡𝑁𝑜) ∈R𝑁𝑜×𝐶表示對中觀察到的位置的觀察𝐺𝑜按時間步長𝑡; 和Plot X𝑡𝐺𝑢=(?𝑥𝑡1.?𝑥𝑡𝑁𝑢) ∈R𝑁𝑢×𝐶表示中未服務位置的估計值𝐺𝑢在時間步長𝑡

問題定義。給定一個區域圖𝐺如上所述,具有位置特征L將過去的觀測結果降落在觀測到的位置上一段時間窗口𝑇, 我們的目標是學習一個函數𝑓預測未來未觀測到的位置的值𝑇′時間步長.
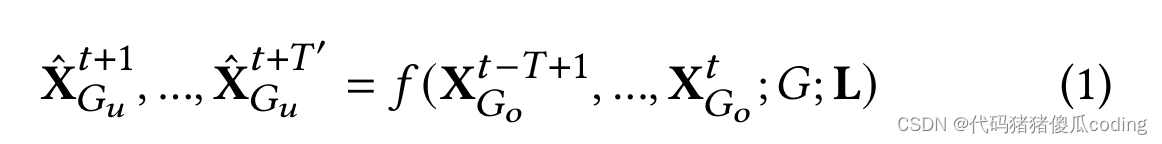
3.2 Overview of Our Base Model(我們的基本模型概述

接下來,我們提出了一個基本模型(即第5.2.2節中的STSM-RNC),該模型直接將時空建模與隨機子圖掩碼相結合,以預測沒有觀測的區域,如圖2所示。STSM-RNC的主要思想是學習一個模型,該模型可以通過子圖來預測觀測結果(例如,交通速度或PM2.5),并將這種能力擴展到未觀測到的位置的預測。

我們將那些未觀測到的位置的完整圖表示為𝐺. 我們屏蔽的位置的子集𝐺𝑜生成maskedview𝐺𝑚𝑜(第3.3節)。根據先前的研究[9,16],我們使用基于時間相似性的鄰接矩陣和基于空間的鄰接矩陣


用于空間相關性建模的鄰接矩陣。為了計算未觀測到的位置的時間相似性,我們首先計算所有未觀測到位置的偽觀測值。然后,我們使用動態時間扭曲(DTW)[3,15]來計算所有觀測到的位置之間的時間相似性,以及觀測到的和未觀測到的地點之間的時間類似性。對于每個模型訓練歷元中的掩蔽位置,我們計算它們的偽觀測值,并計算掩蔽位置和觀測位置之間的速度相似性。

經過這些步驟,我們得到了X𝑡?𝑇+1.𝑡𝐺𝑚𝑜和X𝑡?𝑇+1.𝑡𝐺𝑚分別用于訓練和測試,其中bothX𝑡?𝑇+1.𝑡𝐺𝑚𝑜和X𝑡?𝑇+1.𝑡𝐺𝑚包含中屏蔽或未觀測位置的偽觀測值𝐺𝑜或𝐺

我們喂養X𝑡?𝑇+1.𝑡𝐺𝑚𝑜轉換為時空建模模塊以生成預測結果X𝑡+1.𝑡+𝑇′𝐺𝑚𝑜(第3.4節),并將預測和基本事實之間的均方誤差計算為預測損失,以優化時空模型。在模型被訓練后,我們饋送X𝑡?𝑇+1.𝑡𝐺𝑚進入模型,以獲得對未觀測位置的預測(第3.5節
3.3 Sub-graph Masking(子圖掩蔽

STSM-RNC在訓練過程中學習預測掩蔽位置的值,然后將此能力擴展到在測試中預測未觀測位置的值。為了模擬我們關注的沒有數據觀測的連續區域的設置,我們屏蔽了由每個選定位置及其1跳鄰居形成的子圖,而不是一組散射位置。

定義子圖。觀察到的位置的子圖由其1跳鄰居形成。我們基于空間鄰接矩陣a計算位置的1跳鄰居𝑠𝑔, 其由等式2定義,其中𝜖𝑠𝑔是一個超參數,并且𝑑𝑖𝑠𝑡(𝑐𝑖,𝑐𝑗)表示位置之間的距離𝑖和𝑗(𝑐𝑖和𝑐𝑗是它們的地理坐標。)出于效率考慮,我們在本文中使用歐幾里得距離,盡管也可以使用道路網絡距離。
一跳鄰居,子圖掩蔽,是我理解的意思?掩去了一級鄰近鄰居,保留二級鄰居
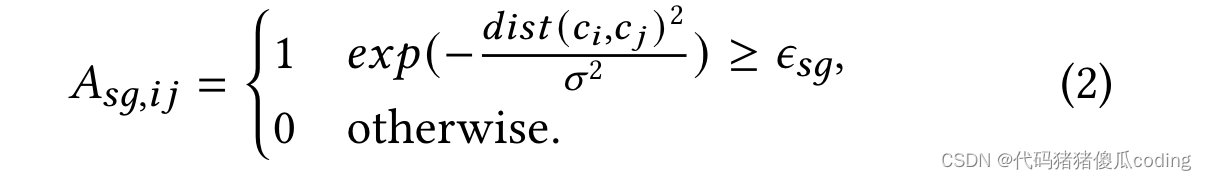

子圖屏蔽。我們使用掩蔽比率𝛿𝑚以定義要屏蔽的觀察位置的百分比。屏蔽的位置數預計為𝑁𝑜·𝛿𝑚. 由于每個位置的子圖可能具有不同的大小,STSM-RNC迭代并隨機選擇一個位置,并屏蔽該位置及其1跳鄰居,直到屏蔽位置的數量達到𝑁𝑜·𝛿𝑚.
3.4 Spatial-temporal Modelling(時空建模

我們的基礎模型STSM-RNC的時空建模模塊包含用于時間相關性建模的一維卷積網絡和用于空間相關性建模的圖卷積網絡(GCN)。時空建模模塊堆疊多個塊以計算最終輸出。圖3顯示了時空建模模塊的結構,并詳細說明了𝑙模塊的第個塊。每個區塊包含一個局部相關建模模塊和一個空間相關建模模塊。這兩個模塊在每個塊中是并行的。我們首先描述了時空建模模塊中的輸入特征和鄰接矩陣。然后,我們詳細介紹了時間和空間相關性建模模塊
基礎模型STSM-RNC的時空建模模塊? =
時間相關性建模的一維卷積網絡 + 用于空間相關性建模的圖卷積網絡(GCN)
時間建模居然用的卷積,不過一維卷積,可以的
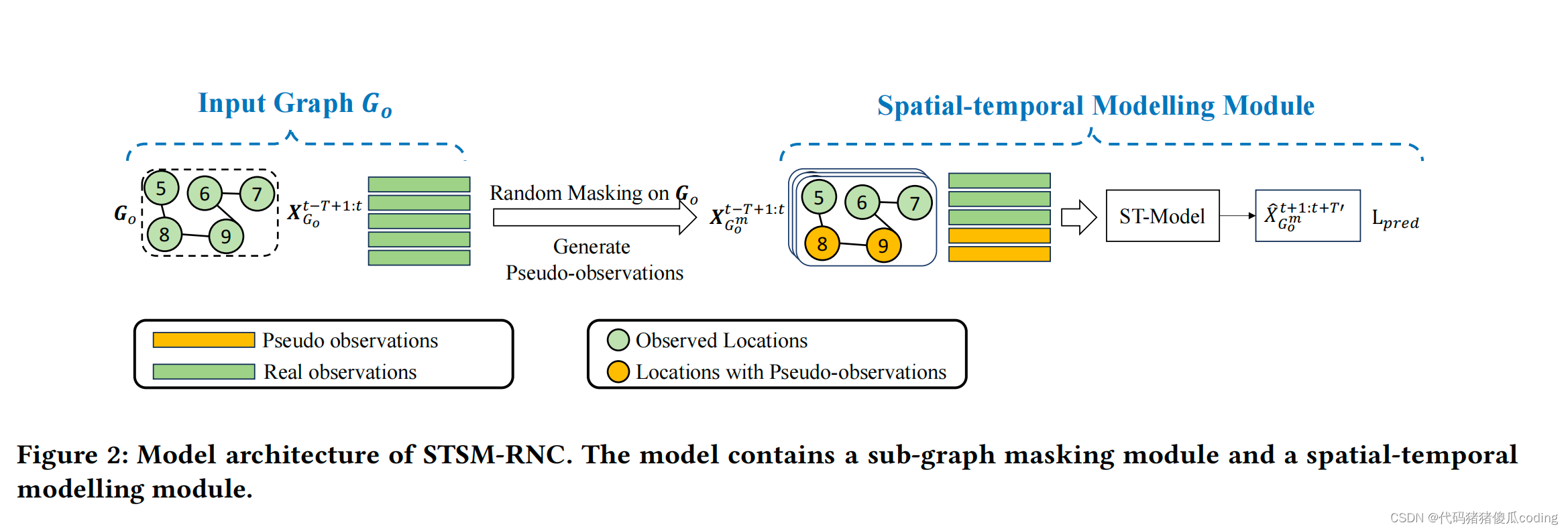
Figure 2:STSM-RNC的模型體系結構。該模型包含子圖掩蔽模塊和時空建模模塊

圖3:時空模型的結構

3.4.1.輸入特征和鄰接矩陣。STSM-RNC的輸入特征包括觀測位置的歷史觀測、未觀測和掩蔽位置的偽觀測以及用于指示一天中時間的時間注意力。此外,我們還為我們的模型中的GCN計算了兩種類型的鄰接矩陣。

我們計算的偽觀測值𝑖-真實觀測中未觀測到的或推測的位置𝑥𝑡𝑖=í𝑗∈𝑁𝑜𝛼𝑖,𝑗𝑥𝑡𝑗. 每個觀測位置的權重由其對位置的空間位置決定𝑖, 如等式3所定義
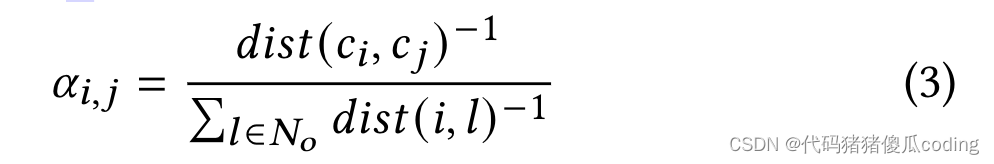

這一步驟可以基于其鄰居的位置將更多信息引入未被觀測或屏蔽的位置。
然后,我們建立了一個基于時間相似性的鄰接矩陣。我們遵循先前的工作[15],并采用DTW來計算時間相似性。由于偽觀測可以被視為具有噪聲的真實觀測,因此我們只在觀測位置之間以及從觀測位置到未觀測(屏蔽)位置建立聯系(即,在GCN訓練期間,未觀測位置不能直接將信息發送到觀測位置)。

這樣,我們就避免了未觀察到(掩蔽)位置的嵌入污染觀察到的位置的嵌入。我們計算𝑞𝑘𝑘和𝑞𝑘𝑢最相似的觀測位置對以及觀測和未觀測(或掩蔽)位置對。我們建立了一個基于時間相似性的鄰接矩陣

在訓練過程中𝑑𝑡𝑤∈R𝑁×𝑁在測試過程中),為這些位置對分配1的邊緣權重,為其余位置對分配0的邊緣權重。由于在每個訓練時期中動態地掩蔽位置A𝑡𝑟𝑎𝑖𝑛𝑑𝑡𝑤在每個模型訓練時期更新。
它這里隨機化的思想還是比較有趣的,訓練數據多變,每次隨機mask節點

此外,我們使用時間注意力來捕捉周期性的拍頻,這會顯著影響時空數據的觀測值,例如高峰時間。給定記錄時空觀測的時間間隔的長度(例如,5分鐘),我們可以計算一天中的間隔數量,表示為𝑇𝑑. 現在,一天中的每個觀察間隔在[0,𝑇𝑑?1].給定長度的輸入𝑇, 我們計算一天嵌入的時間𝑇𝐸∈R𝑇, 其將間隔ID存儲在輸入時間窗口中。

例如𝑇𝐸=[0,1,2,3]表示一個輸入觀測序列,從一天的第一個間隔開始,到一天的第四個間隔結束。

附加時間嵌入𝑇𝐸對于模型輸入,我們首先投影TE𝑡?𝑇+1.𝑡∈R𝑁𝑜×𝑇×1輸入特征X𝑡?𝑇+1.𝑡∈R𝑁𝑜×𝑇×𝐶進入相同的潛在空間,然后將它們相乘,如方程4
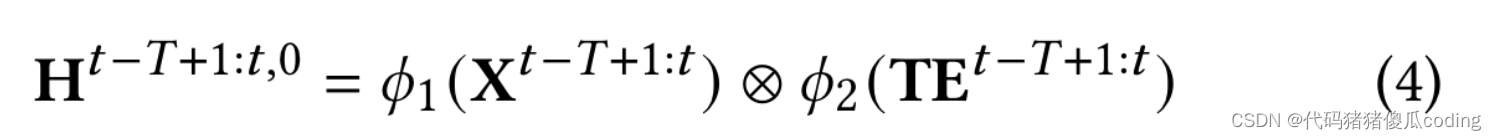

這里,X𝑡?𝑇+1.𝑡∈R𝑁𝑜×𝑇×𝐶是觀測圖的輸入觀測序列(即。𝐺𝑜或𝐺𝑚𝑜), while TE𝑡?𝑇+1.𝑡是響應時間嵌入;𝜙1(·)和𝜙2(·)是線性函數,它將輸入的觀測序列和時間嵌入到相同的潛在空間中進行逐元素乘法。我們現在獲得功能H𝑡?𝑇+1.𝑡,0∈R𝑁𝑜×𝑇×𝐶′, 作為時空模型的輸入。
該說不說,這數學符號的表達真的很規范

3.4.2時間相關建模.
1-D卷積神經網絡在時間特征建模方面表現出強大的性能。我們采用一維擴張卷積神經網絡來嵌入時間特征。為了便于演示,我們簡化了時空模型第一層的輸入特征的表示法


H巴拉巴拉的那個是上一層的輸出;
H𝑙𝑡𝑐𝑛∈R𝑁×𝑇×𝐶′,𝑙=1,2, . . .,𝐿第𝑙層的一維時間卷積網絡的輸出;
*𝑑𝑙表示堆疊一維相關時間卷積網絡,其中𝑑𝑙𝑗表示指數膨脹率,𝑑𝑙𝑗=2.𝑗.
為了保持時間序列表示的維數相同,我們使用零填充。
作用𝜎(·)是激活函數(例如ReLU或者sigmoid

3.4.3空間相關性建模。我們使用圖卷積網絡(GCN)來對空間相關性進行建模。GCN的基本思想是聚合來自鄰居的特征:


式中eA=A+I,andeD是對角矩陣。矩陣Z∈R𝑁×𝐶是輸入圖節點的特征。矩陣W∈R𝐶×𝐶′包含模型要學習的參數,其中𝐶是輸入維度和𝐶′是輸出維度。接下來,我們定義具有兩個平行GCN的GCN層,記作GCNL
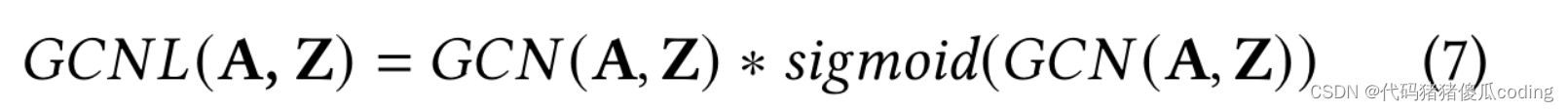
什么?eg7在哪里提到了?

我們堆疊GCN層來構建GCN塊。每個GCN層的輸出是下一個GCN層的輸入,如等式8所示,其中𝑞∈ 1.𝑘]. 第一層輸入為H𝑙,𝑡?𝑝,0𝑔𝑐𝑛,𝑟=H𝑙?1.𝑡?𝑝,哪里𝑝∈ [𝑇?1,0]和𝑟∈ {𝑠,𝑑𝑡𝑤}表示兩種類型的鄰接矩陣(即基于空間鄰近性的矩陣和基于空間相似性的矩陣)
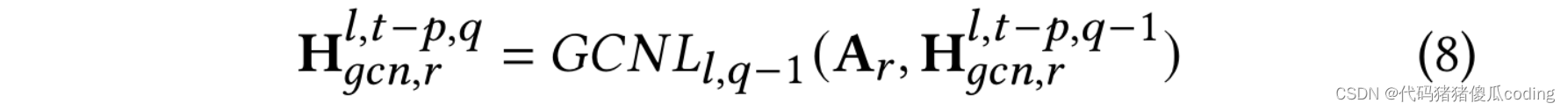

我們使用𝑚𝑎𝑥(·)聚合GCN層的輸出以獲得第𝑙-th個GCN塊的輸出

就是說,你真的不覺得這個公式有點子復雜嘛哈哈哈哈笑薯我了
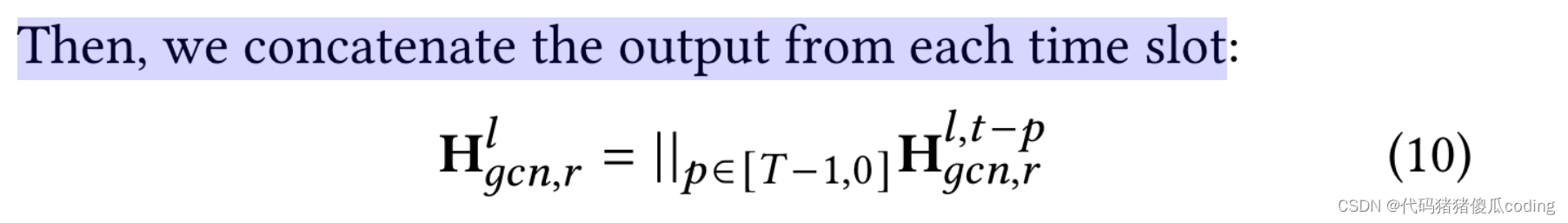
然后,我們關注每個時間間隙的輸出。

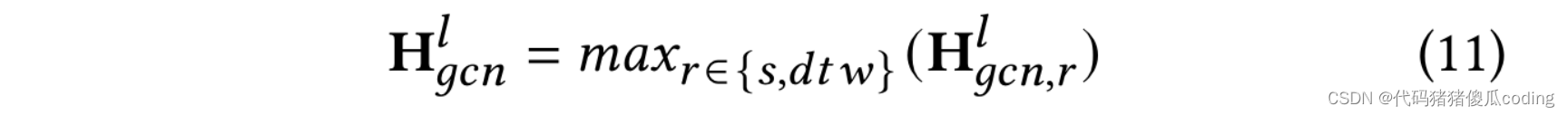
之后,我們使用𝑚𝑎𝑥(·)再次聚合對應于兩個不同鄰接矩陣的輸出,如等式11所示,以獲得的第𝑙-th層輸出。

我們遵循先前的研究[9,16],并采用具有不同閾值的等式2-𝜖𝑠計算基于空間的鄰接矩陣。同時,我們遵循另一項工作[15],采用DTW[3]來計算A𝑑𝑡𝑤, 如前所述。
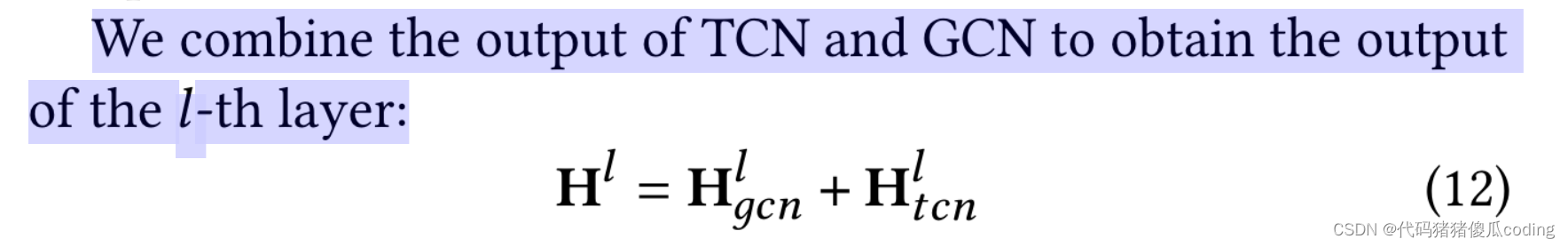
我們將TCN和GCN的輸出組合起來,以獲得第l層的輸出。
TCN哪里出現了?
組合輸出形式,可以的。四則遠算還有權重是個問題

最后,我們得到輸出H𝑡+1.𝑡+𝑇′,𝐿在𝐿-第h層遵循上述步驟和線性函數投影H𝑡+1.𝑡+𝑇′,𝐿到較低的維度(如等式13所示)

在這里𝜙3和𝜙4為線性函數,以及𝜎是一個激活函數𝑡+1.𝑡+𝑇′∈R𝑁𝑜×𝑇′×𝐶表示預測值
3.5 Model Training and Testing(模型訓練和測試

模型訓練:我們獲得預測值𝑡+1.𝑡+𝑇′𝐺𝑚𝑜論圖形觀𝐺𝑚𝑜這是通過子圖掩碼生成的。然后,我們計算預測值之間的均方誤差𝑥𝑡+𝑝′𝑖以及基本事實𝑥𝑡+𝑝′𝑖作為預測損失(Eq 18

模型測試:在模型測試過程中,我們首先計算未觀測到的位置的偽觀測值,并讓圖𝐺用偽觀測𝐺𝑚. 然后,我們利用這些偽觀測建立了基于時間相似性的鄰接矩陣。之后,我們提供特征X𝑡?𝑇+1.𝑡𝐺𝑚∈R𝑁×𝑇×𝐶
feed翻譯成 提供,或者理解成輸入特征

到訓練的模型中,以產生預測的觀測值𝑡+1.𝑡+𝑇′𝐺𝑚對于未觀測到的位置。
4 PROPOSED FULL MODEL(提出的完整模型

第3節介紹了我們的基本模型。在本節中,我們將介紹兩個模塊——選擇性掩蔽模塊和集中學習模塊,以增強我們提出的模型性能。這兩個模塊與我們的基本模型STSM-RNC一起形成了我們的完整模型STSM。圖4顯示了它的總體結構。
回想一下,我們的核心思想是學習一個模型,該模型可以將掩蔽位置的預測能力擴展到未觀測位置。
STSM的三方面構成:
- selective masking module(選擇性掩碼模塊)挺會形容。
- contrastivelearning module(對比學習模塊)
- STSM-RNC

STSM在全圖上性能的可推廣性𝐺取決于中屏蔽位置之間的相似性𝐺𝑚𝑜以及未觀測到的地點𝐺. 為了掩蓋與未觀測位置具有更高相似性的位置,我們提出了一個選擇性掩蔽模塊,以增強子圖掩蔽,利用觀測位置和未觀測位置之間的相似性來幫助預測未觀測位置的值(例如,交通速度或PM2.5)
兩個數據集:交通數據集&空氣質量數據集

該模塊利用區域信息和位置周圍的道路網絡信息以及空間距離來計算位置的掩蔽概率。我們在每個模型訓練中基于這樣的概率來掩蔽位置,以生成𝐺𝑚𝑜. 該模塊可以指導STSM學習預測與未觀測到的位置具有更高相似性的位置的值,從而增強模型的通用性。
說的是掩碼模塊
掩碼概率:區域信息 + 路網信息 + 空間距離

我們進一步設計了一個對比學習模塊,該模塊采用基于圖對比學習的方法,構建了圖的兩個視圖——一個視圖包含完整的空間-時間數據(原始視圖),另一個視圖則包含不完全的空間-時間數據(擴充視圖)。具有完整數據的視圖用于指導對具有不完整數據視圖的預測。

增強視圖𝐺𝑚𝑜由選擇性掩蔽模塊生成。使用對比學習,我們學習了一個模型,它為兩個圖視圖生成相似的預測。然后將訓練后的模型應用于全圖𝐺以對未觀測到的位置進行預測。

我們喂養X𝑡?𝑇+1.𝑡𝐺𝑜和X𝑡?𝑇+1.𝑡𝐺𝑚𝑜進入所提出的時空建模模塊(如第3.4節所述),以獲得圖形表示Z𝑡+𝑇′𝐺𝑜和Z𝑡+𝑇′𝐺𝑚𝑜用于對比學習和生成預測結果X𝑡+1.𝑡+𝑇′𝐺𝑚𝑜.
當模型被訓練時,我們饋送X𝑡?𝑇+1.𝑡𝐺𝑚以獲得未觀測位置的預測(第3.5節)
4.1 Selective Masking(選擇性掩碼

STSM在訓練過程中學習預測掩蔽位置的值,然后在測試中擴展這一能力以預測未觀測位置的值。直觀地說,掩蔽位置和未觀測位置之間的相似性越高,訓練的模型就越容易對未觀測到的位置進行預測。我們計算這些1-跳子圖(在第3.3節中定義)和未觀測區域之間的相似性。之后,我們使用我們提出的選擇性掩蔽模塊來引導STSM掩蔽由觀測位置的子圖形成的子區域,這些子圖與未觀測區域最相似。從啟發性的角度來看,這種策略可以為未觀察到的區域中的位置帶來更準確的預測結果。
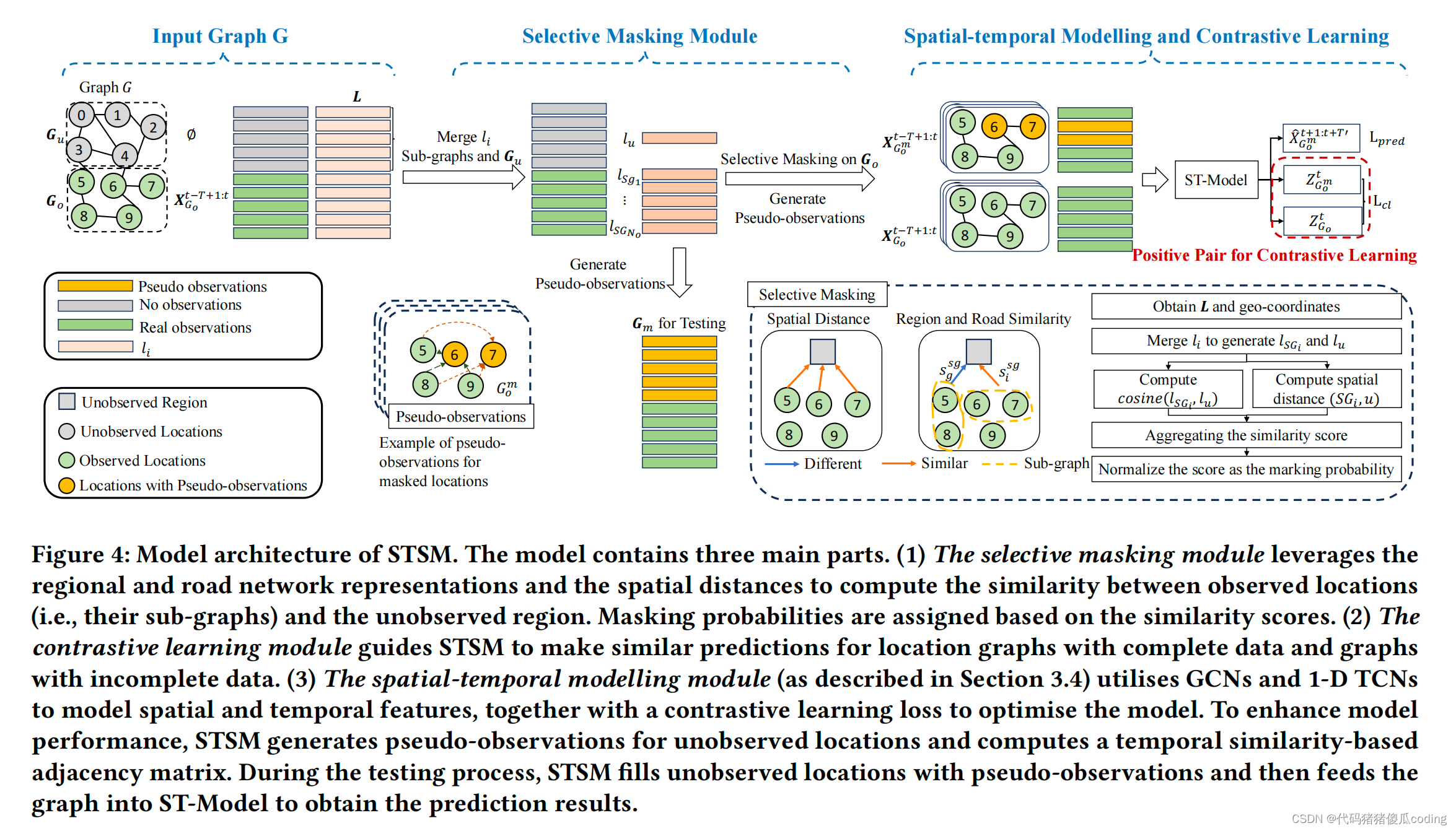 圖4:STSM的模型架構。該模型包括三個主要部分。
圖4:STSM的模型架構。該模型包括三個主要部分。
Model architecture of STSM. The model contains three main parts.
(1) 選擇性掩蔽模塊利用區域和道路網絡表示以及空間距離來計算觀察到的位置(即,它們的子圖)和未觀察到的區域之間的相似性。基于相似性得分來分配掩蔽概率。
(1) The selective masking module leverages the regional and road network representations and the spatial distances to compute the similarity between observed locations (i.e., their sub-graphs) and the unobserved region. Masking probabilities are assigned based on the similarity scores.
(2) 對比學習模塊指導STSM對具有完整數據的位置圖和具有不完整數據的圖進行相似的預測。(2) The contrastive learning module guides STSM to make similar predictions for location graphs with complete data and graphs with incomplete data.
(3) 時空建模模塊(如第3.4節所述)利用GCN和一維TCNsto對空間和時間特征進行建模,并結合對比學習損失來優化模型。為了提高模型性能,STSM為未觀測到的位置生成偽觀測值,并計算基于時間相似性的鄰近矩陣。
6,我有點好奇,它用啥畫的圖,數學符號的表示,技術路線都比較清晰。



子圖表示。為了測量子圖和由未觀測位置形成的區域之間的相似性,我們需要首先計算每個觀測位置的子圖的表示。我們用三個組件形成這樣的表示(即嵌入):

(1) 興趣點(POI)特征。對于每個觀察到的位置,我們繪制一個以半徑為中心的圓𝑟(系統參數),并從OpenStreetMap[19]收集電路內的所有POI。我們將POI分類為Γ類(參見表1)。

子圖嵌入的POI特征組件,表示為𝑙𝑝𝑜𝑖𝑖∈Γ,是保持每個類別的POI的計數的一個向量。我們進一步從OpenStreetMap[19]中獲得圓形區域中建筑的層數和公園的面積,以表示子圖的繁榮程度,如𝑙𝑠𝑐𝑎𝑙𝑒𝑖∈例如,具有60級建筑的子圖(即局部區域)比僅具有4級建筑的子圖更繁榮。

我們連結𝑙𝑝𝑜𝑖𝑖和𝑙𝑠𝑐𝑎𝑙𝑒獲得子圖的區域嵌入,表示為𝑙𝑟𝑒𝑔𝑖𝑜𝑛𝑖=[𝑙𝑝𝑜𝑖𝑖||𝑙𝑠𝑐𝑎𝑙𝑒𝑖] ∈RΓ+,其中||表示連結

(2) 路網特點。我們選擇該位置最近的道路。為了表示與子圖相對應的道路網絡,我們使用4維向量𝑙 𝑟𝑜𝑎𝑑𝑖∈R4(終于看懂了一個數學符號!)其中的維度有:高速公路等級、最大速度、is_oneway和車道數

最后,我們將位置的區域表示和拓撲網絡表示連接起來𝑖以形成其嵌入。,𝑙𝑖=[𝑙𝑟𝑒𝑔𝑖𝑜𝑛𝑖||𝑙𝑟𝑜𝑎𝑑𝑖] ∈Γ+5。位置子圖的嵌入𝑖, 記為𝑙𝑆𝐺𝑖, 被計算為子圖中所有位置的嵌入的平均嵌入。,𝑙𝑆𝐺𝑖=1.𝑉𝑆𝐺𝑖|í𝑗∈𝑉𝑆𝐺𝑖𝑙𝑗.

子圖和未觀測區域之間的相似性。按照同樣的策略,我們可以計算一個嵌入ding𝑙𝑢通過對所有未觀測到的位置的em層理取平均值來獲得完整的未觀測到區域。然后,位置子圖之間的相似性𝑖并且未觀測區域被計算為兩個嵌入的余弦相似性。,即𝑠𝑔𝑖=𝑐𝑜𝑠𝑖𝑛𝑒(𝑙𝑆𝐺𝑖,𝑙𝑢)), 與空間接近度相結合𝑠𝑝𝑠𝑔𝑖=1.𝑑𝑖𝑠𝑡(𝑐𝑖,𝑐𝑢)指導掩蔽過程。

我們計算所有子圖和未觀察區域之間的嵌入相似性,表示為𝑆𝑠𝑔=[𝑠𝑠𝑔1.𝑠𝑠𝑔𝑁𝑜], 和空間接近度𝑆𝑃𝑠𝑔=[𝑠𝑝𝑠𝑔1.𝑠𝑝𝑠𝑔𝑁𝑜]

子圖屏蔽。我們使用掩蔽比率𝛿𝑚以定義待掩蔽的觀察到的位置的百分比。由于每個位置的子圖可能具有不同的大小,我們計算所有子圖的平均大小,表示為𝛿𝑠=1.𝑁𝑜í𝑖∈𝑁𝑜|𝑉𝑆𝐺𝑖|.如果我們屏蔽具有相同概率的子圖𝛿𝑚𝑠=𝛿𝑚/𝛿𝑠,屏蔽的位置的最終數量預計為𝑁𝑜·𝛿𝑚.由于我們想要使用相似性來引導STSM來屏蔽ob服務的位置,

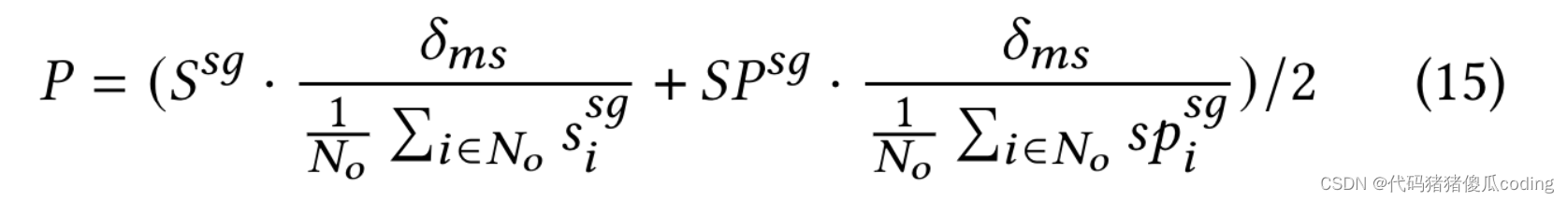
我們把相似之處結合起來𝑆𝑠𝑔, 空間近似性𝑆𝑃𝑠𝑔以及子圖掩蔽比𝛿𝑚𝑠以計算每個位置的掩蔽概率,如等式15所示。該方程歸一化𝑆𝑠𝑔和𝑆𝑃𝑠𝑔讓他們有貢獻。

子圖的大小和圖的大小𝐺影響價值𝑝𝑖∈𝑃. 當它們很大時,𝑝𝑖可以變得非常小,使得所有子圖都具有非常接近的概率值。為了解決這個問題,我們只保留頂部-𝐾最相似的子圖,并將其余子圖的相似性值設置為0,其中𝐾是一個超參數。

這種策略減少了圖中可以屏蔽的子圖的數量。然后,我們掩蓋

基于掩蔽概率的子圖更類似于未觀測區域𝜌𝑖, 來自伯努利分布𝜌𝑖~𝐵𝑒𝑟𝑛(𝑝𝑖)生成具有遮罩位置的圖形(𝐺𝑚𝑜)
4.2 Graph Contrastive Learning(圖形對比學習

根據第4.1節,我們使用𝐺𝑜(即,具有完整數據的圖)以生成圖𝐺𝑚𝑜具有不完整數據(即具有掩蔽位置的圖形)。圖表𝐺𝑚𝑜可以被視為𝐺𝑜具有擾動(即,𝐺𝑚𝑜和𝐺𝑜是觀測圖的兩個視圖,以及𝐺𝑚𝑜是的擴充𝐺𝑜). 指導STSM在𝐺𝑚𝑜和𝐺𝑜, 我們將對比學習應用于圖的這兩個視圖的訓練過程中。

STSM采用圖級對比學習。我們使用原始圖𝐺𝑜來解釋我們的圖表示生成步驟。首先,[X]𝑡?𝑇+1.𝐺𝑜, . . .,十、𝑡𝐺𝑜]被輸入到時空模型中(如第3.4節所述),以生成每個時隙的輸出,表示為H𝑡:𝑡+𝑇′,𝐿𝐺𝑜, 哪里𝐿是時空模型中的層數。

然后,STSM獲取最后一個時間步長的時空模型的最后一層輸出,即H𝑡+𝑇′,𝐿𝐺𝑜, 以獲得圖的表示Z𝑡+𝑇′𝐺𝑜. 將所有位置的表示分解,并將其投影到一個新的潛在空間中,公式化為等式16,其中𝜙(·)是alinear函數。我們按照相同的步驟生成表示Z𝑡+𝑇′𝐺𝑚𝑜屬于𝐺𝑚𝑜

一批𝑀在訓練時對輸入時間窗口進行采樣,形成2𝑀表示,其中(Z𝑡+𝑇′𝐺𝑜,Z𝑡+𝑇′𝐺𝑚𝑜)是一個正對(即圖𝐺𝑜和圖形𝐺𝑚𝑜從同一時間槽形成正對)。負巴黎是由另一個產生的𝑀?1批次中的圖形(即圖形𝐺𝑜和圖形𝐺𝑚𝑜從一批中的不同時隙形成負對),表示為(Z𝑡+𝑇′𝐺𝑜,Z𝑡′+𝑇′𝐺𝑚𝑜). 我們采用對比損失來最大化樣本對的相互信息
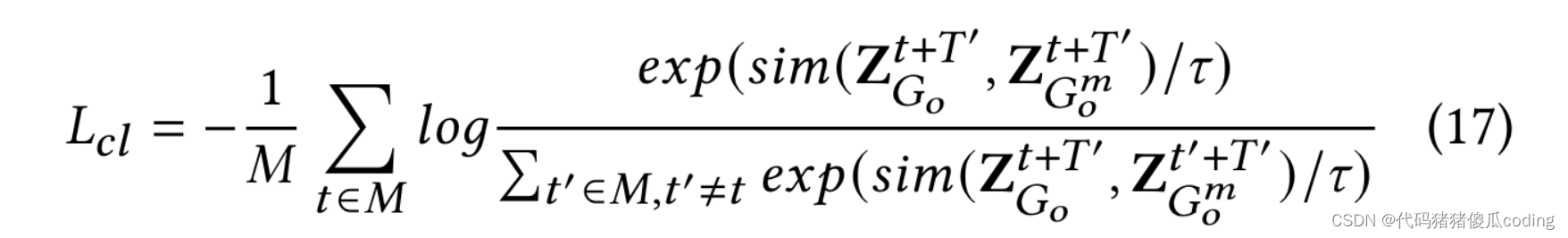

優化STSM的最終損失函數為:
![]()
𝜆是一個平衡預測損失和對比學習損失的系數。
5 EXPERIMENTS(實驗
5.1 Experimental Setup(實驗設置

5.1.1數據集。我們在三個高速公路交通數據集、一個城市交通數據集和一個空氣質量數據集上進行了實驗。

PEMS灣[16]包含2017年1月至6月期間從加利福尼亞州灣區高速公路上的325個傳感器收集的交通速度數據

PEMS-07[4]包含洛杉磯高速公路上傳感器收集的交通速度數據。根據之前的一項研究[20],我們隨機抽取了400個傳感器,并將其在2022年9月至12月期間收集的數據作為數據集。


PEMS-08[4]包含加利福尼亞州圣貝納迪諾地區高速公路上傳感器收集的交通速度數據。同樣,我們使用了2022年9月至12月期間400個隨機采樣傳感器收集的數據。

墨爾本包含2022年7月至9月期間澳大利亞墨爾本市182個傳感器從AIMES項目收集的交通速度數據[26]

AirQ[40]包含2014年5月至2015年4月期間由中國兩個相鄰城市北京和天津的63個傳感器收集的污染物濃度數據(PM2.5)。

從PEMS收集的所有交通記錄都是在5分鐘窗口內給出的,即每天288個時隙,而墨爾本數據集的交通記錄是在15分鐘窗口內提供的,即每日96個時隙。空氣質量記錄以小時為單位,即每天24個時段。表2總結了數據集的統計數據,圖5顯示了所有數據集之間的傳感器分布。用于選擇性掩蔽的區域和道路網絡信息從OpenStreetMap[19]中獲得。

在基線工作[30]之后,我們使用過去兩個小時的記錄來預測接下來的兩個小時,即。,𝑇=𝑇′=2.?𝑜𝑢𝑟𝑠在用于交通數據集的等式1中。在另一項基線工作[39]之后,我們使用過去24小時的記錄來預測接下來的24小時,即。,𝑇=𝑇′=24?𝑜𝑢𝑟𝑠在空氣質量數據集的等式1中。

我們以4:1:5將每個數據集分為三組進行訓練、驗證和測試,其中每組中的位置彼此相鄰。請注意,訓練集中和驗證集中的位置被視為觀察到的位置,而測試集中的位置則被視為未觀察到的地點。數據集分割是基于空間的,根據傳感器的地理坐標將傳感器水平或垂直劃分為三組。

對于每個數據集,我們創建四個不同的分割,并報告每個數據集的平均性能。我們使用前70%的訓練時間和后30%的測試時間記錄的數據。圖6顯示了PEMS Bay上的數據集劃分及其時間劃分。


5.1.2競爭對手。
我們提出的問題沒有現有的模型。我們采用以下自適應模型與我們提出的模型STSM進行實證比較:
?? GE-GAN[32]是一種基于生成對抗性網絡(GAN)的轉導數據插補方法,利用生成器生成估計值,并利用判別器對真實值和生成值進行分類。

? IGNNK[30]是一種用于時空克里格的歸納圖神經網絡。
? INCREASE[39]是一個基于GRU和時空克里格技術的歸納圖表示學習網絡

5.1.3實施細節。
我們使用源代碼中基線模型的默認設置。基線模型是為數據插補而提出的,而我們的目標是預測。

我們將它們的地面實況改變為未來的時間窗口,而不是過去的時間窗口來訓練模型并獲得預測。

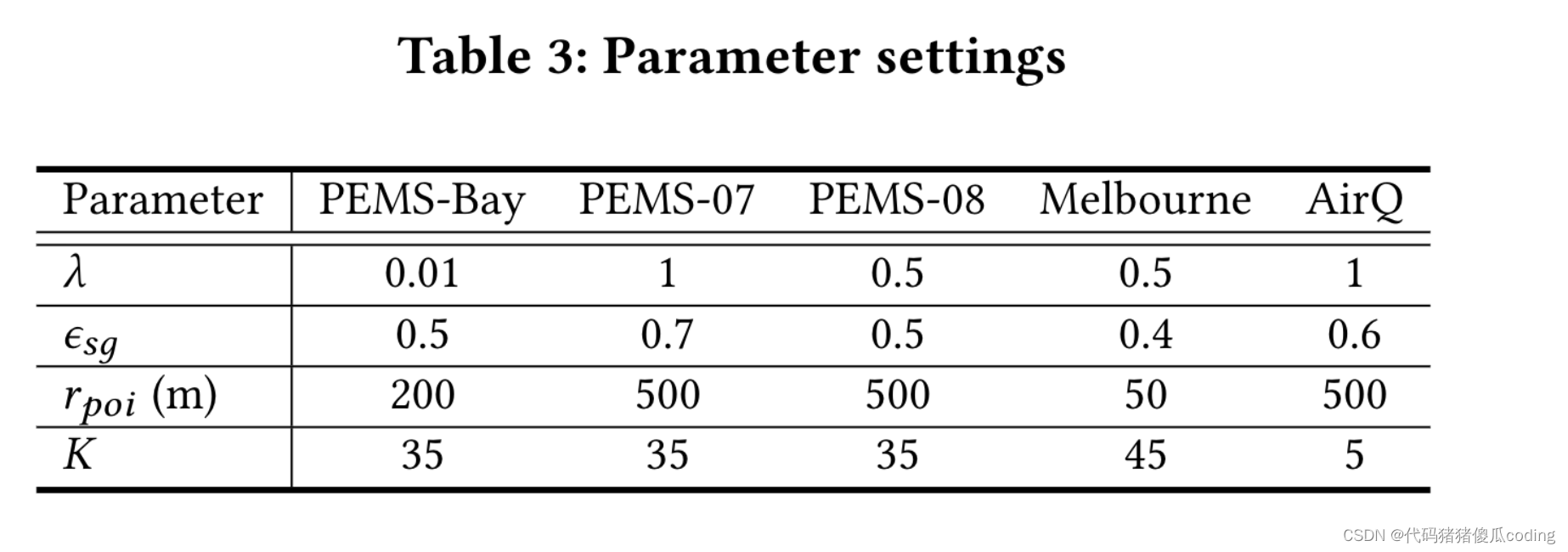
我們使用Adam優化器訓練我們的模型,學習率從0.01開始。批量大小為32。對于我們模型中的超參數,𝜏為0.5,𝜎𝑚為0.5,𝜖𝑠為0.05并且𝑞𝑘𝑘和𝑞𝑘𝑢設置為1。我們將其他模型超參數的細節(即。,𝜆,𝜎𝑠𝑔,𝑟𝑝𝑜𝑖和𝐾) 如表3所示。這些參數值是通過驗證集上的網格搜索獲得的,除了𝑟𝑝𝑜𝑖其僅基于子圖和未觀察到的區域之間的相似性(即。𝑆𝑠𝑔).

此外,參數值可以在具有相似分布的數據集之間共享,例如,當只有感覺的數量或密度發生變化時(參見表6和表7)。在實驗中,我們對基于空間的矩陣使用了不同的閾值𝐴𝑠和𝐴𝑠𝑔.圖7顯示了PEMS Bay上的兩個鄰接矩陣。實驗在NVIDIA特斯拉V100 GPU上運行。

我們采用四種常用的指標來評估模型性能,包括均方根誤差(RMSE)、平均絕對誤差(MAE)、平均百分比誤差(MAPE)和R平方(R2)。前三個測量預測誤差,而R2測量模型預測結果與僅使用平均觀測值作為結果相比有多好[39]
5.2 Experimental Results(實驗結果

我們首先將我們的模型的總體性能與基線方法進行比較。然后,我們報告了消融研究的結果,以驗證STSM中每個模塊的有效性。最后,我們研究了參數對測試模型穩健性的影響。

5.2.1模型性能比較。
我們首先將STSM與基線方法進行比較。
(1) 總體結果
表4總結了總體性能結果。STSM及其變體,包括基本模型STSM RNC(詳見第5.2.2節),在所有四個數據集上都優于所有競爭對手,但AirQ上的MAPE測量除外。

GE-GAN是一種利用基于圖形嵌入的相似位置為未觀測位置生成值的轉導方法。當大面積存在許多未觀測到的位置時,很難找到相似的位置,導致預測精度很低。在墨爾本市等城市地區,GE-GAN的表現優于其他兩個基線模型,因為該地區相對較小。

IGNNK是一個歸納模型,使用GNN對空間相關性進行建模,使用一維卷積神經網絡獲取時間相關性。它在我們的任務中很困難,因為連續位置的數據丟失使GNN很難獲得空間相關性模式。盡管它在AirQ上的MAPE略低,但在該數據集上,它的MAE和RMSE仍然比我們的模型STSM大得多。這可以解釋

較小的觀測值出現較低的MAE,而較大的觀測值則出現較高的MAE
表4:整體模型性能。“↓” 和↑”) 指示值越低(和越大)越好。最佳基線結果用下劃線表示,所提出的STSM模型的最佳結果用粗體表示。改進計算所提出的模型的最佳變體與最佳基線模型相比所產生的誤差,其中N/A表示由于基線方法上的負測量值,無法計算改進結果
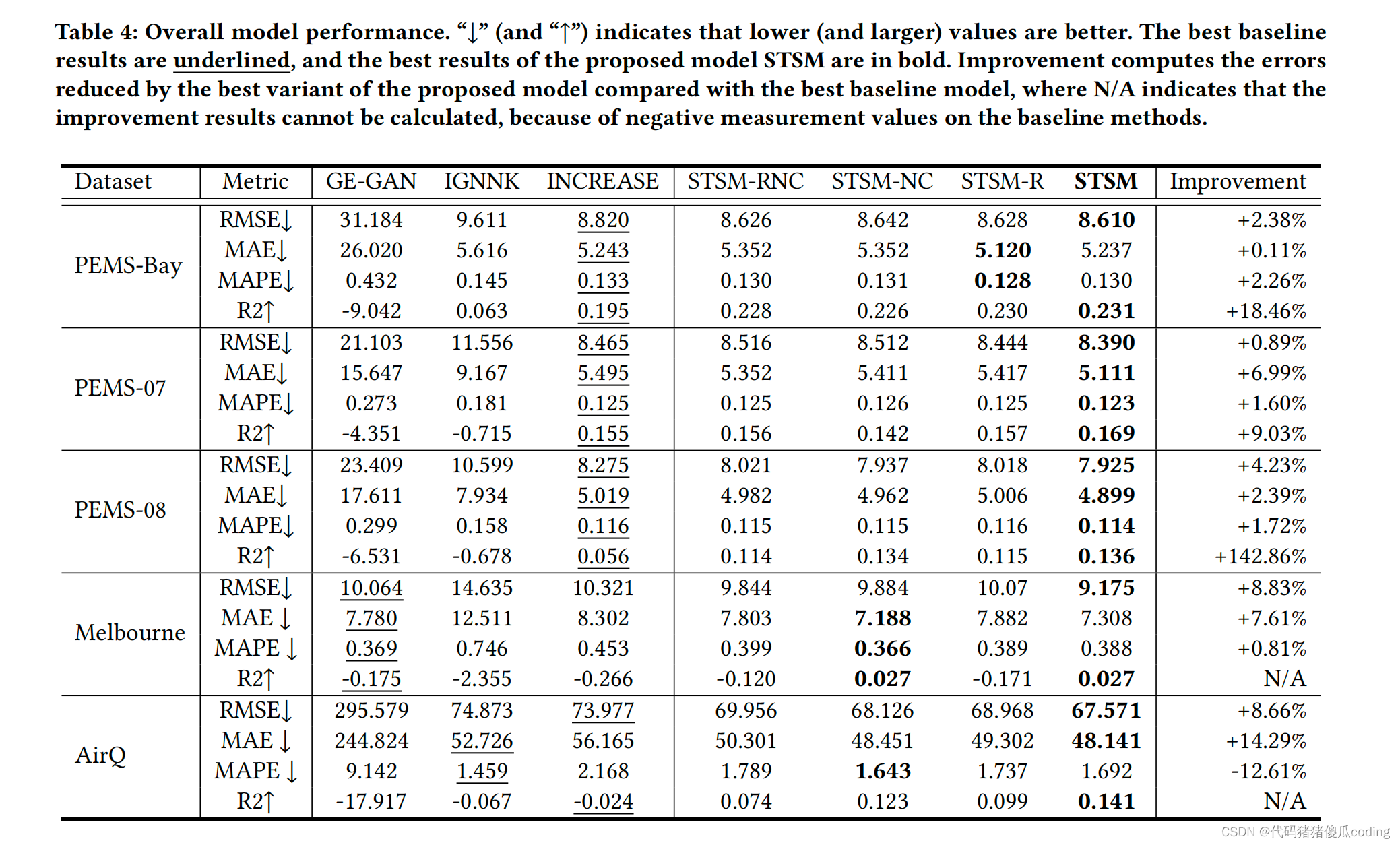
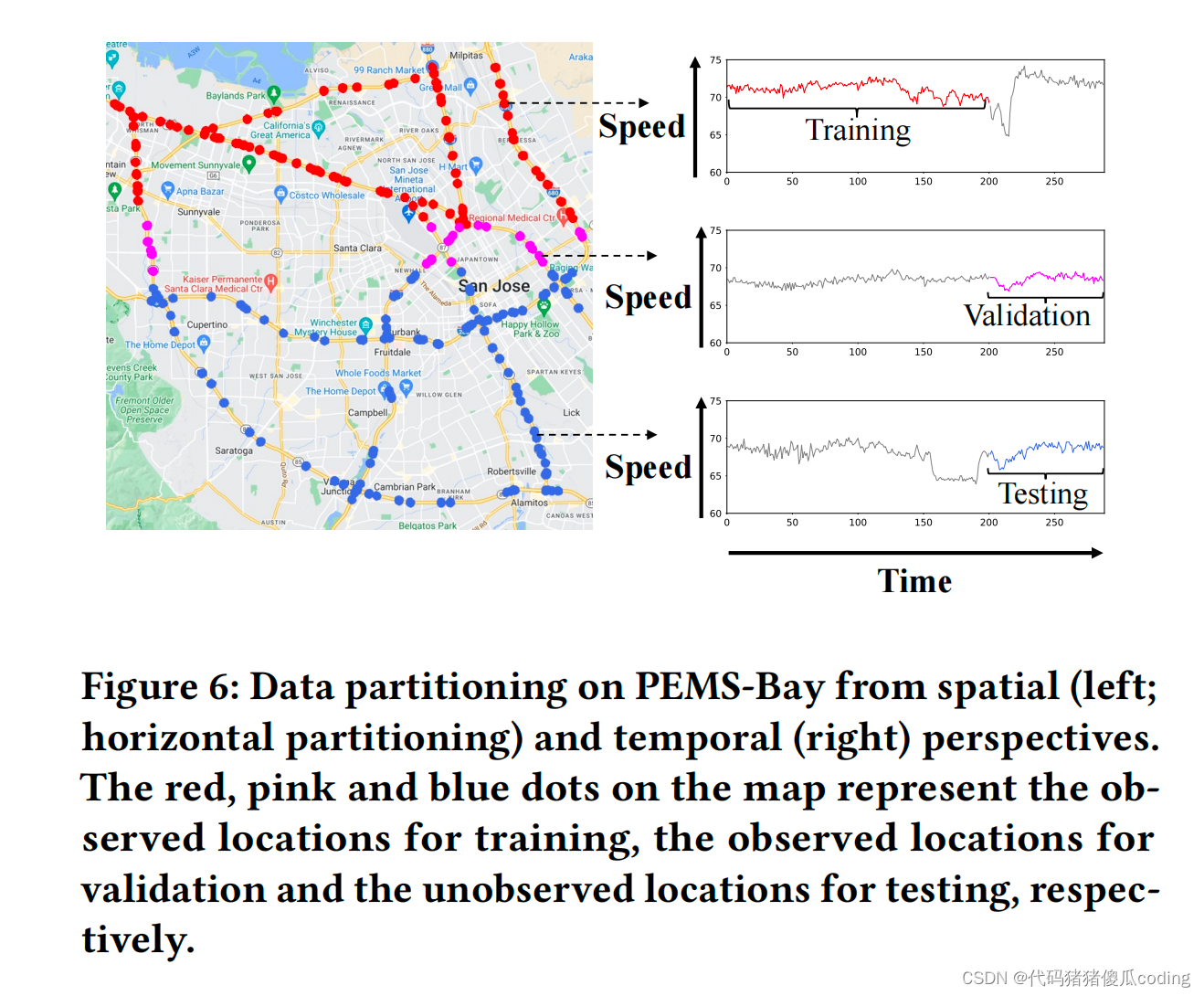
圖6:從空間(左;水平分區)和時間(右)角度對PEMS灣進行數據分區。地圖上的紅色、粉色和藍色圓點分別代表觀察到的訓練位置、觀察到的驗證位置和未觀察到的測試位置。
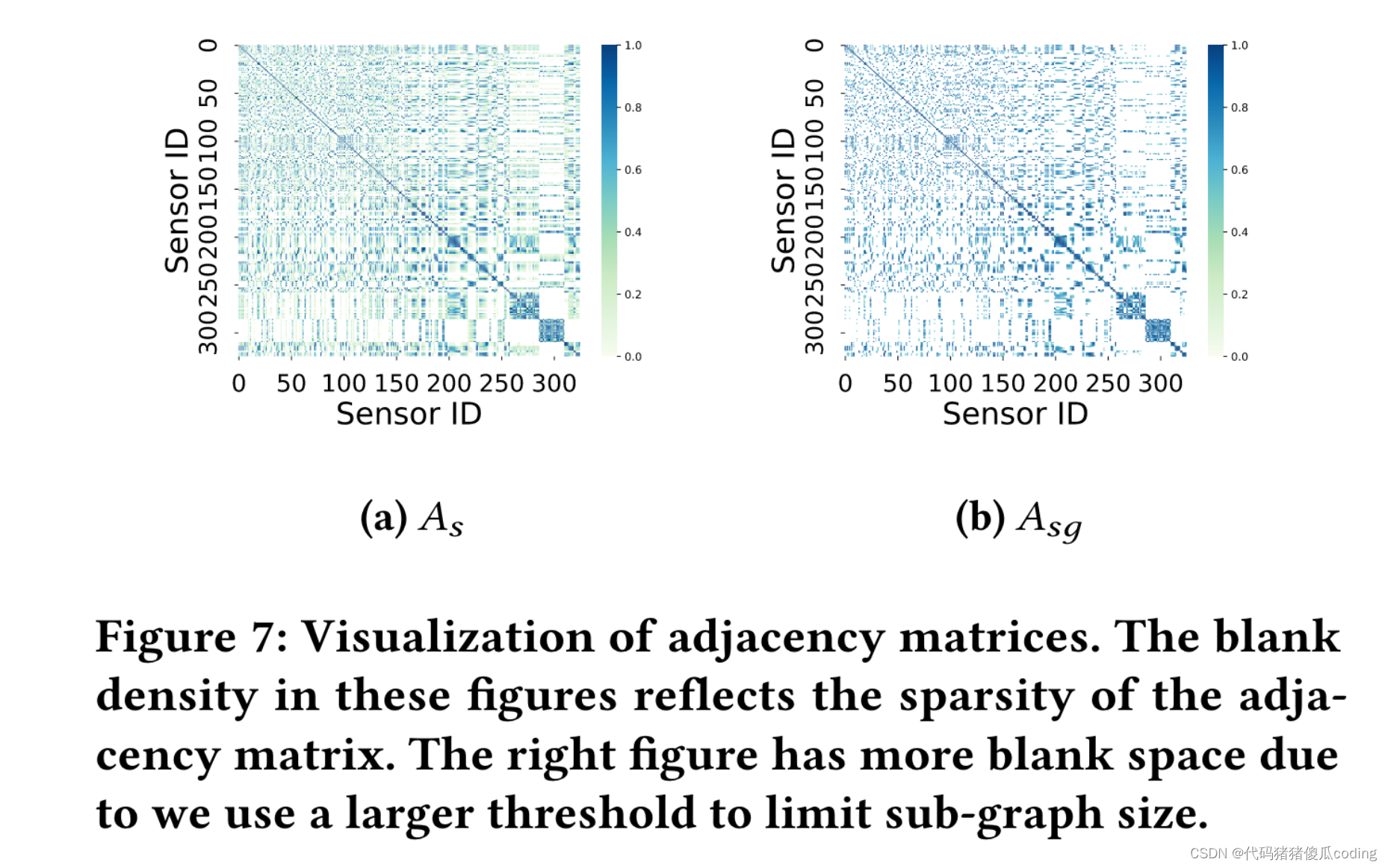
圖7:鄰接矩陣的可視化。這些圖中的空白密度反映了鄰接矩陣的稀疏性。右圖有更多的空白空間,因為我們使用了更大的閾值來限制子圖的大小

INCREASE是最先進的時空克里格模型,它學習異構的空間關系和不同的時間模式,在基線模型中表現出最好的性能。然而,它仍然優于我們的STSM模型。我們的模型在AirQ數據集上將預測誤差減少了14%,在PEMS-08數據集上使R2增加了142%

由于我們的時間鄰接矩陣來建模時間相似性,我們的選擇性掩蔽模塊來建模空間和空間相似性,以及對比學習來增強模型的穩健性
6 CONCLUSIONS AND FUTURE WORK(結論和未來的工作
We proposed a new task - spatial-temporal forecasting for aregion of interest without historical observations while this re-gion’s adjacent region has such data. We design a novel modelnamed STSM for the task. We propose a selective masking mod-ule based on region, road network and spatial distance features.This module can guide STSM to mask locations in the adjacentregion that have higher similarity with those in the region ofinterest, which is beneficial for extending the forecasting capa-bility of STSM to the region of interest.
我們提出了一個新的任務——在沒有歷史觀測的情況下對感興趣的區域進行時空預測,而該區域的相鄰區域有這樣的數據。我們為該任務設計了一個新的模型STSM。我們提出了一種基于區域、道路網絡和空間距離特征的選擇性掩蔽模型。該模塊可以引導STSM屏蔽相鄰區域中與感興趣區域中相似性較高的位置,有利于將STSM的預測能力擴展到感興趣區域。

相反,STSM利用對比學習來提高模型預測的有效性。在包括交通數據和空氣質量數據在內的真實世界數據集上的實驗結果表明,STSM在預測精度方面始終優于最先進的模型。這一優勢得益于(1)選擇性掩蔽模塊,它引導模型掩蔽與感興趣區域更相似的區域,從而更好地概括預測;(2)對比學習,它提高了模型對不完整數據的準確性;(3)基于時間相似性的鄰接矩陣計算,它增強了GCN的學習能力,允許消息從觀察到的位置傳遞到未知的位置。

我們只考慮了一個未觀察到的地區。未來,我們計劃將STSM擴展到同時處理多個未觀測到的區域。
閱讀方法:
先通讀了一遍,感覺大概看得懂;
再讀第二遍,開始整理筆記,看翻譯,做批注。
論文閱讀
)

)




| 默認構造函數 | 拷貝構造函數 | 析構函數 | 運算符重載 | const成員函數)





之環境安裝)
)

DM8數據庫sysbench部署及壓力測試)

的MATLAB實現(源代碼))
