
- 01 -
終于等來了預算,這就把服務遷移到最新的 CPU 平臺上去,這樣前端的同事立馬就能感受我們帶來的速度提升了。可是…… 這些性能指標怎么回事?不僅沒有全面提升,有些反而下降了。不應該這樣啊,這可怎么辦?
花費了幾個月時間終于搞定了業務模塊的重構,立刻部署升級讓業務煥然一新。可是……長尾延遲居然還增加了一倍,說好的業務效果提升呢,到底是哪里出了問題?
上面的這些問題,對于開發運維工程師來說一定不陌生,經常被這類出乎意料的狀況打個措手不及。但是,性能優化是一項高技術門檻的工作,這通常需要運維人員有豐富的系統知識和經驗,對業務反復進行分析、定位、測試、驗證。遇到麻煩的 case,有時候可能需要花費數周時間。如果團隊中缺乏這類運維人員,那就只能盯著性能指標下降卻沒有有效的方法,最后影響了業務上線效果。
在將業務遷移至不同計算平臺,或者進行新業務上線的過程中,為了能夠完全發揮計算平臺的能力,及時找出性能瓶頸,對系統進行全面優化,百度智能云推出了「應用程序性能診斷工具 Btune」。
就像電腦管家可以快速對 PC 進行性能優化,Btune 能夠對云上業務進行一鍵性能調優,短時間內完成性能瓶頸的定位并提供優化建議,使得初級運維人員可以勝任高技術門檻的性能調優工作。
源自百度智能云多年在各種服務器 CPU(Intel、AMD、ARM) 和多類業務(推薦、搜索、廣告、大數據、數據庫、視頻編解碼等)上的性能調優經驗,Btune 支持多維度應用性能分析,可以自動生成優化建議提高應用性能,并提供可視化分析數據展示。
- 02 -
Btune 內置了百度自研的瓶頸分析樹模塊,通過自頂向下的方式,從 CPU、內存、磁盤、網絡、并發等 5 個維度對業務應用進行性能剖析和瓶頸定位,并從應用、runtime、系統、硬件等多個層次對每個瓶頸給出可操作的優化建議。
借助 Btune 的專業能力,用戶不僅能知道性能問題的根因,還能獲得問題優化的方法。只需在 Btune 的前端界面進行一鍵操作,幾分鐘后就可以得到一份完整的性能瓶頸和優化建議報告。
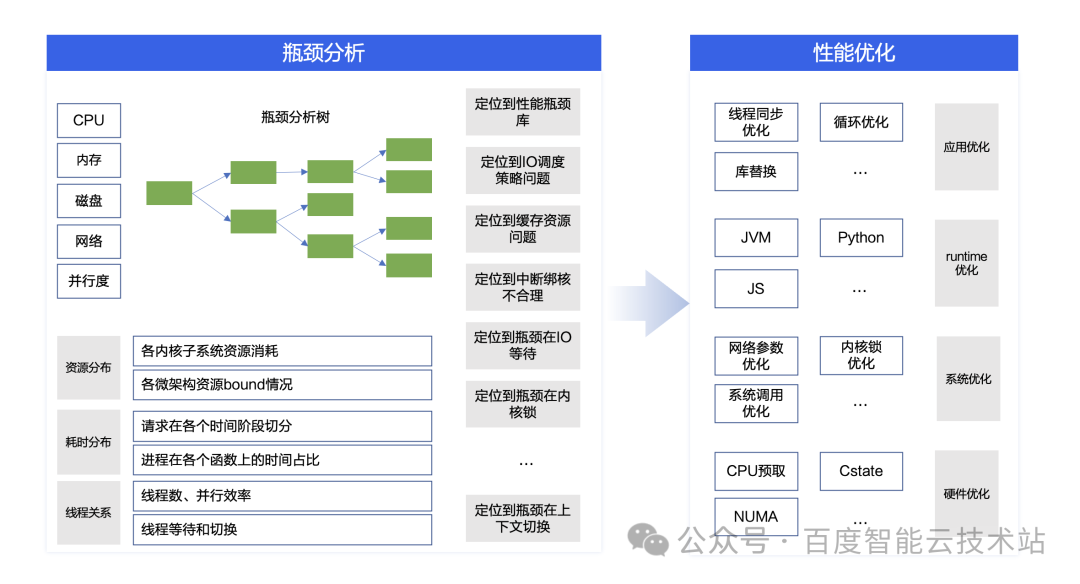
在 Btune 提供的性能瓶頸和優化建議報告中包含兩部分:分析摘要和分析詳情。其中,「分析摘要」清晰地展示了業務性能瓶頸點和相應的優化建議,可以滿足絕大部分的場景的需求。「分析詳情」提供了更詳細的性能分析數據,從系統配置、系統性能、進程線程模型、函數指令熱點等多個維度呈現負載的資源分布、耗時分布、線程關系等運行特性,滿足用戶更細粒度性能優化。
- 03 -
接下來,我們通過一個測試用例介紹如何使用 「應用程序性能診斷工具 Btune」。(此測試用例僅用于展示 Btune 基本功能和使用方法,實際生產環境業務負載比較復雜,但 Btune 使用方法和分析原理相同。)
在這個例子中,首先我們編寫一個測試程序作為分析對象。在這個程序中主要是調用 glibc 庫的 memset 和 memcpy 函數對內存進行操作。然后通過 numactl 命令模擬程序跨 NUMA 訪問內存的情況。我們通過 Btune 對這個程序進行分析給出性能瓶頸和優化建議。在 Btune 輸出的報告中,給出了兩類建議:
-
在計算方面,給出了內存操作熱點函數和對應的熱點庫升級建議。
-
在內存方面,給出了跨 NUMA 訪存優化建議。
最后我們根據 Btune 給出的建議對程序進行優化,可以看到優化后程序性能提高了 36.8%,優化效果顯著。
測試程序代碼如下,程序會無限循環執行簡單的內存拷貝操作,可通過編譯命令:gcc -o test test.c 和啟動命令:nohup numactl -N 0 -m 1 ./test & 來運行此程序。
#include "stdio.h"
#include "stdlib.h"
#include "string.h"#define ARRAY_SIZE 1000000000void main()
{int i=0;int *a = malloc(sizeof(int)*ARRAY_SIZE);int *b = malloc(sizeof(int)*ARRAY_SIZE);while(1){memset(a, 0, sizeof(int)*ARRAY_SIZE);memset(b, 0, sizeof(int)*ARRAY_SIZE);memcpy(b, a, sizeof(int)*ARRAY_SIZE);};}具體操作步驟如下:
1. 登錄云服務器控制臺
創建一個云服務器實例,登陸實例并拷貝、啟動測試程序 test。然后在百度智能云控制臺側邊欄選擇云服務器并選擇「運維與監控」下面的「自助診斷工具」進入性能分析界面。
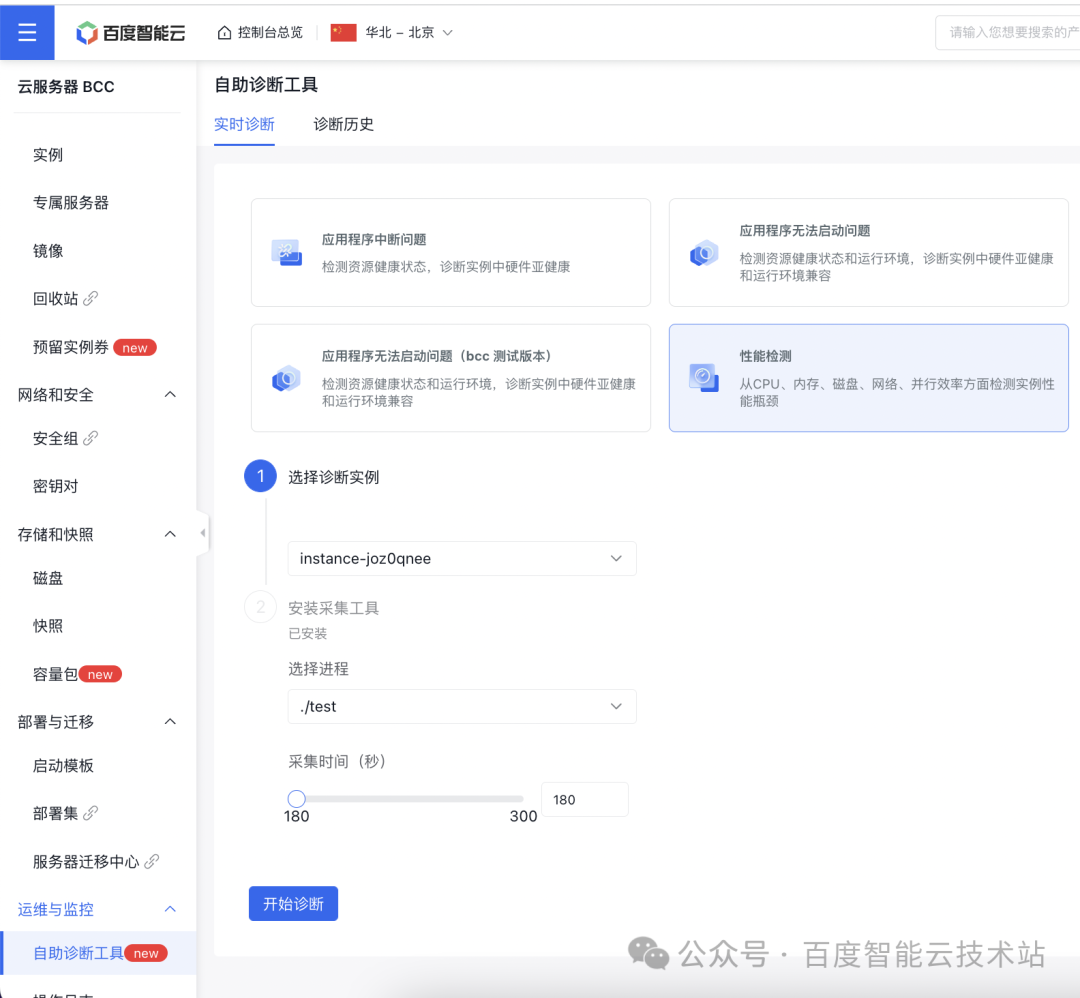
2. 啟動性能檢測
在自助診斷工具頁面選擇「性能檢測」選項,然后選擇剛才創建的云服務器實例作為診斷實例,以及選擇 test 進程作為診斷進程,Btune 需要一定周期的采集時間分析該進展。參數配置完可開始檢測。
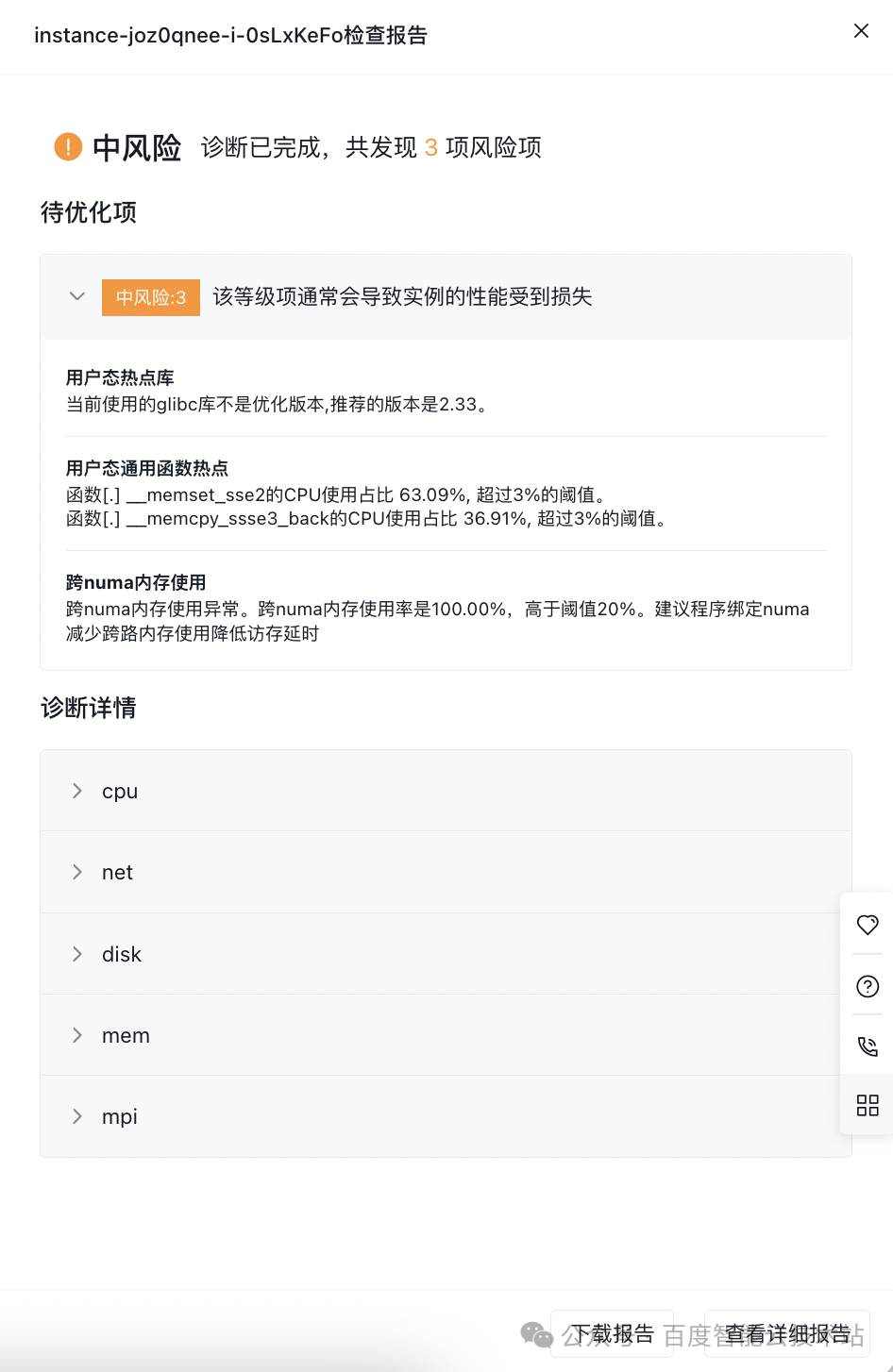
3. 查看分析摘要報告
幾分鐘后,診斷完畢。Btune 輸出分析摘要報告:
(1)待優化項
列出了程序的幾個瓶頸點,并給出了優化建議。在此例中,有 3 條優化建議:前 2 條給出了熱點函數 memset 和 memcpy 的熱點占比,并推薦升級 glibc2.33 進行優化(當前 CentOS 7.9 默認 glibc 是 2.17,版本較低,性能差)。第 3 條給出了當前程序跨 NUMA 內存使用率是 100%,建議減少跨 NUMA 訪問。
(2)診斷詳情
診斷詳情可查看 CPU、內存、網絡、磁盤、并發等 5 個維度的監控數據。我們以 CPU、內存和并發 3 個診斷項說明如下:
- CPU 診斷項:內核的網絡、存儲和調度正常,主要風險是 glibc 熱點函數和庫版本。

- 內存診斷項:無內存泄漏,采用匿名大頁,整機內存使用量較少,主要風險是跨 NUMA 使用內存。
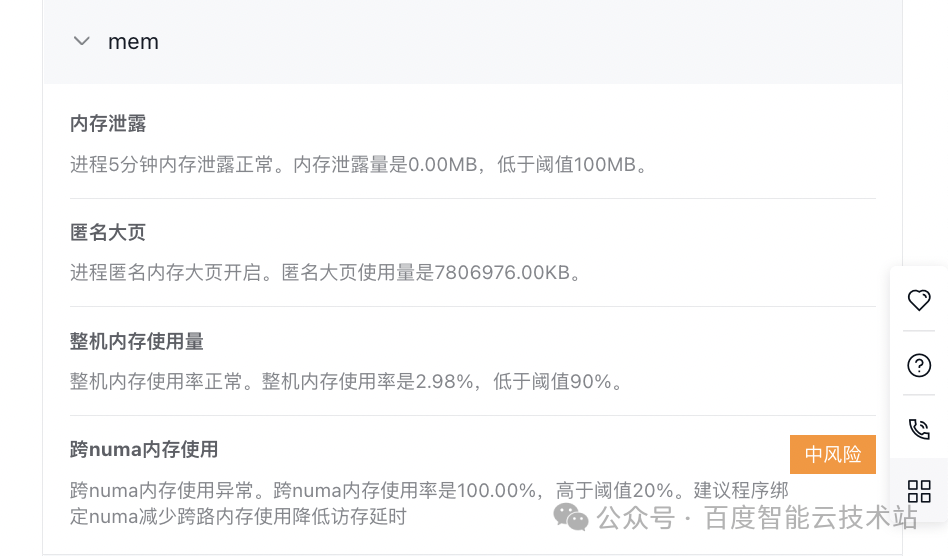
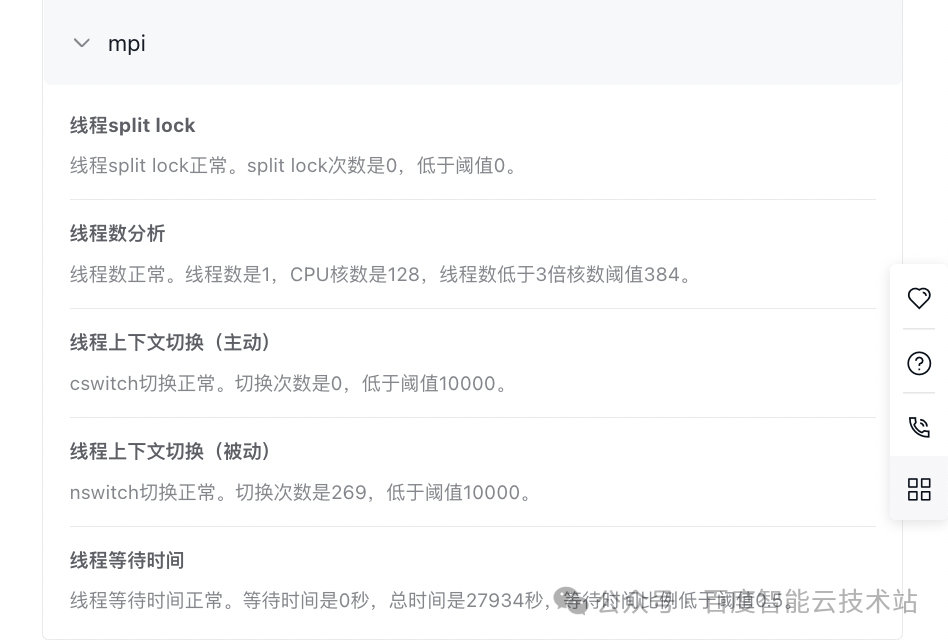
- 并發診斷項(mpi):線程數是 1,由于內存默認對齊所以沒有出現 split lock 情況,線程上下文切換和線程等待時間均正常,無風險。
4. 查看分析詳情報告
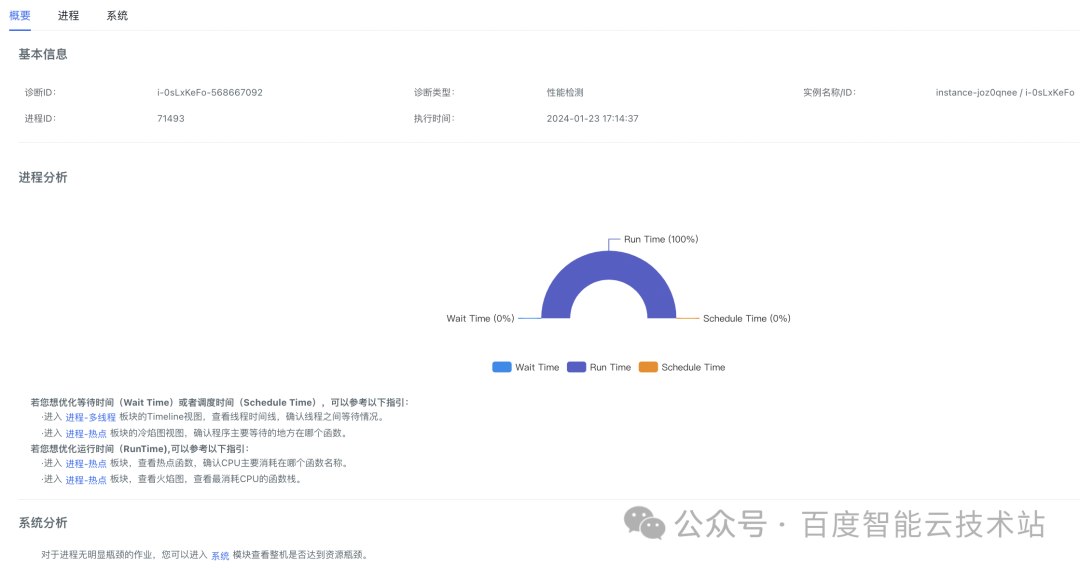
點擊檢測報告右下角的「查看詳細報告」,可以查看詳細的性能性能分析數據。
詳細報告界面分為三部分:概要、進程和系統。「概要」從程序運行時間維度給出了初步分析;「進程」給出了進程粒度的分析數據(CPU、內存、磁盤、網絡、熱點、多線程并發);「系統」給出了整機粒度的分析數據(CPU、內存、磁盤、網絡)。
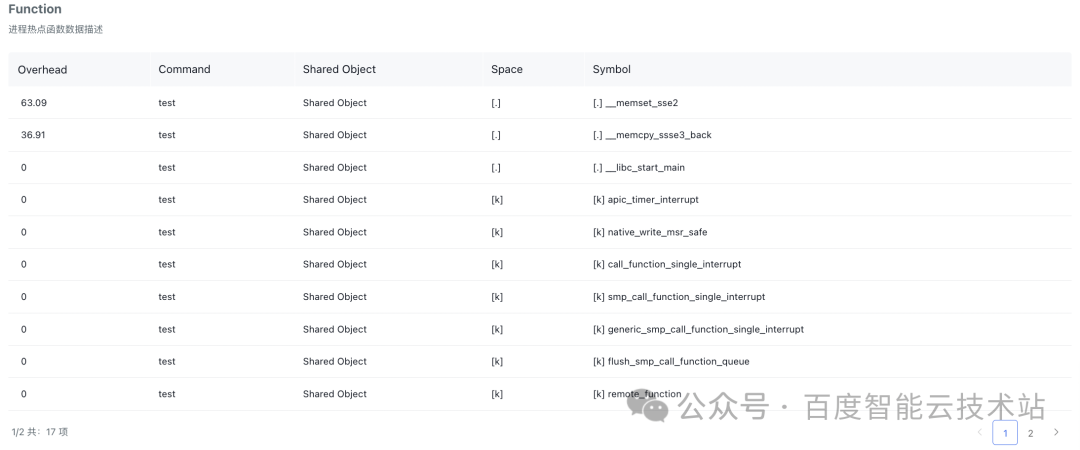
此案例中,通過進程「熱點」可以查看熱點函數 list,跨路的熱點函數 list,火焰圖,跨路火焰圖等,具體如下:
- 熱點函數:此例中主要熱點是內存操作函數__memset_sse2 和__memcpy_sse3_back,分別占比 63.09% 和 36.91%。
- 跨 NUMA 熱點函數:此例中主要跨路熱點函數是__memcpy_sse3_back,占比 100%。

- 火焰圖:此例中,glibc 中的__memset_sse2 和__memcpy_sse3_back 占比最大。
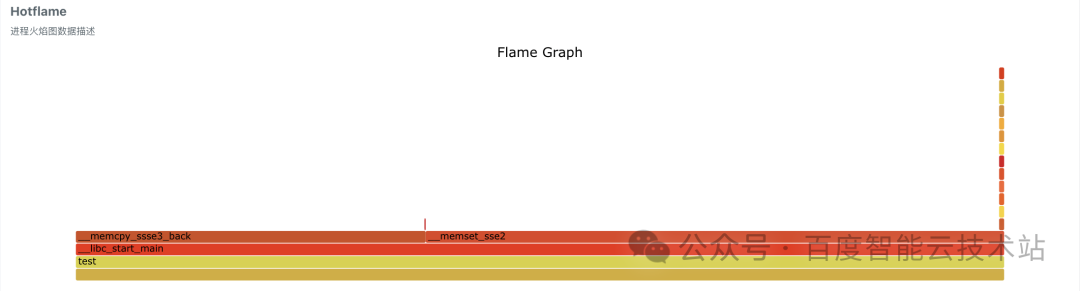
- 跨 NUMA 火焰圖:此例中,glibc 中的__memcpy_sse3_back 占比最大。

5. 程序優化效果
根據 Btune 給出的優化建議,我們需要做兩項優化措施:一個是升級 glibc 到 2.33,一個是減少跨 NUMA 訪存。
為了方便對比優化前后性能差異,我們統計核心代碼段的耗時,修改程序如下:
clock_gettime(CLOCK_REALTIME, &start);memset(a, 0, sizeof(int)*ARRAY_SIZE);
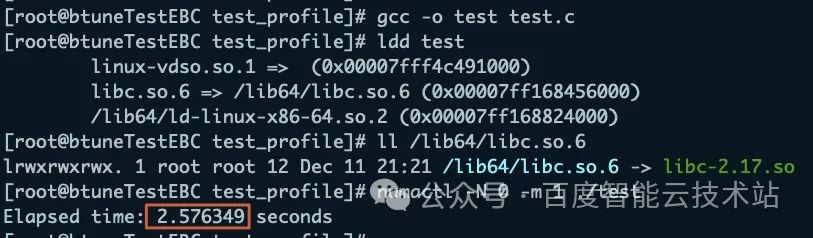
memset(b, 0, sizeof(int)*ARRAY_SIZE);memcpy(b, a, sizeof(int)*ARRAY_SIZE);clock_gettime(CLOCK_REALTIME, &end);elapsed = (end.tv_sec - start.tv_sec) + (end.tv_nsec - start.tv_nsec) / 1e9;printf("Elapsed time: %f seconds\n", elapsed);首先,優化前的默認程序執行單次耗時 2.576349 秒。
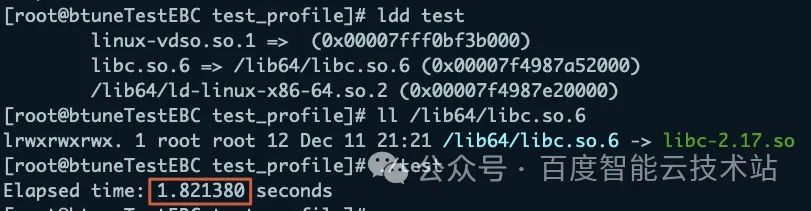
然后,執行 Btune 的建議優化項其一,關閉跨 NUMA 啟動并保持 2.17 版本 glibc,此時程序耗時 1.821380 秒,優化 29.3%。
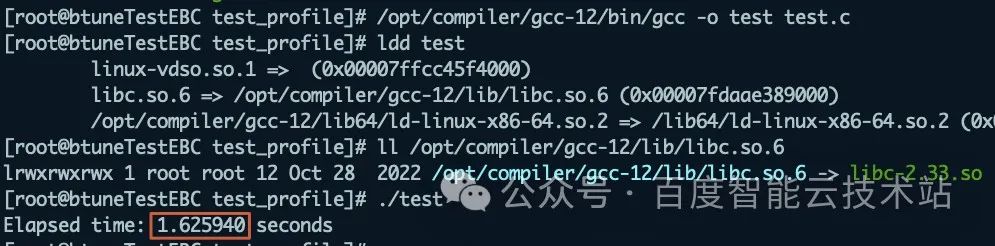
最后,執行 Btune 的全部優化建議,升級到 2.33 版本 glibc,并關閉跨 NUMA 啟動,耗時 1.625940 秒,共優化 36.8%。
- - - - - - - - - - END - - - - - - - - - -
推薦閱讀
一文詳解靜態圖和動態圖中的自動求導機制
千萬級高性能長連接Go服務架構實踐
百度搜索Push個性化:新的突破
數據交付變革:研發到產運自助化的轉型之路












)


)

——開發環境的搭建)

—— 條件語句)