交叉驗證
導包
import numpy as npfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn import datasets#model_selection :模型選擇
# cross_val_score: 交叉 ,validation:驗證(測試)
#交叉驗證
from sklearn.model_selection import cross_val_score
讀取datasets中鳶尾花(yuan1wei3hua)數據
X,y= datasets.load_iris(True)
X.shape
(150, 4)
一般情況不會超過數據的開方數
#參考
150**0.5
#K 選擇 1~13
12.24744871391589
knn = KNeighborsClassifier()score = cross_val_score(knn,X,y,scoring='balanced_accuracy',cv=11)
score.mean()
0.968181818181818
應用cross_val_score篩選 n_neighbors k值
errors =[]
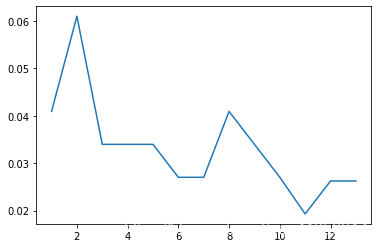
for k in range(1,14):knn = KNeighborsClassifier(n_neighbors=k)score = cross_val_score(knn,X,y, scoring='accuracy',cv = 6).mean()#誤差越小 說明K選擇越合適 越好errors.append(1-score)import matplotlib.pyplot as plt
%matplotlib inline#k = 11時 誤差最小 說明最合適的k值
plt.plot(np.arange(1,14),errors)
[<matplotlib.lines.Line2D at 0x17ece9ff0b8>]
應用cross_val_score篩選 weights
weights =['uniform','distance']for w in weights:knn = KNeighborsClassifier(n_neighbors = 11,weights= w)print(w,cross_val_score(knn,X,y, scoring='accuracy',cv = 6).mean())
uniform 0.98070987654321
distance 0.9799382716049383
模型如何調參的,參數調節
result = {}
for k in range(1,14):for w in weights:knn = KNeighborsClassifier(n_neighbors=k,weights=w)sm = cross_val_score(knn,X,y,scoring='accuracy',cv=6).mean()result[w+str(k)] =sma =result.values()
list(a)np.array(list(a)).argmax()
20
list(result)[20]
‘uniform11’















、均方誤差、均方根誤差(標準誤差)、均方根解釋)



