在用sklearn的時候經常用到feature_importances_ 來做特征篩選,那這個屬性到底是啥呢。

分析源碼發現來源于每個base_estimator的決策樹的
feature_importances_



?
由此發現計算邏輯來源于cython文件,這個文件可以在其github上查看源代碼

而在DecisionTreeRegressor和DecisionTreeClassifier的對feature_importances_定義中

到此決策樹的feature_importances_就很清楚了:impurity就是gini值,weighted_n_node_samples 就是各個節點的加權樣本數,最后除以根節點nodes[0].weighted_n_node_samples的總樣本數。
下面以一個簡單的例子來驗證下:
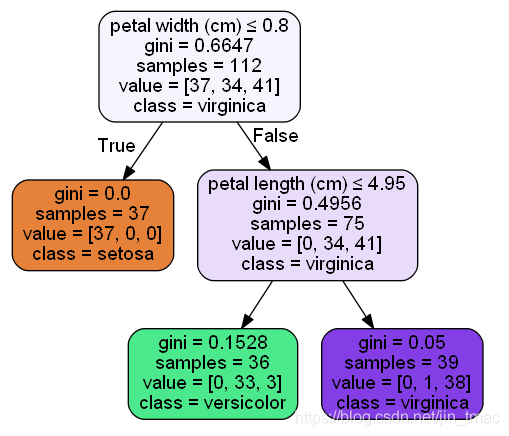
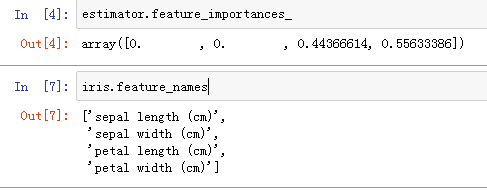
上面是決策樹跑出來的結果,來看petal width (cm)就是根節點,
featureimportance=(112?0.6647?75?0.4956?37?0)/112=0.5564007189feature_importance=(112*0.6647-75*0.4956-37*0)/112=0.5564007189featurei?mportance=(112?0.6647?75?0.4956?37?0)/112=0.5564007189,
petal length (cm)的
featureimportance=(75?0.4956?39?0.05?36?0.1528)/112=0.4435992811feature_importance=(75*0.4956-39*0.05-36*0.1528)/112=0.4435992811featurei?mportance=(75?0.4956?39?0.05?36?0.1528)/112=0.4435992811
忽略圖上gini計算的小數位數,計算結果相同。
?
#待更新







學習及實例使用其將圖片壓縮)




的配置問題)






)