非監督學習之k-means
K-means通常被稱為勞埃德算法,這在數據聚類中是最經典的,也是相對容易理解的模型。算法執行的過程分為4個階段。
1、從數據中選擇k個對象作為初始聚類中心;
2、計算每個聚類對象到聚類中心的距離來劃分;
3、再次計算每個聚類中心
4、2~3步for循環,直到達到最大迭代次數,則停止,否則,繼續操作。
5、確定最優的聚類中心
歐氏距離:
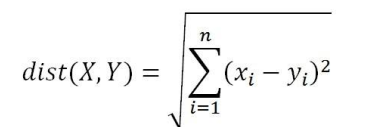
步驟圖: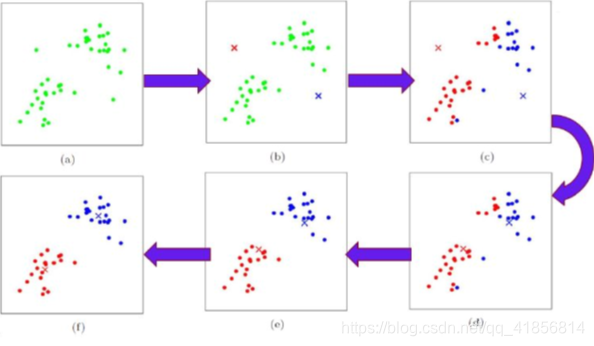
K-Means主要最重大的缺陷——都和初始值有關
- K是事先給定的,這個K值的選定是非常難以估計的。很多時候,事先并不知道給定的數據集應該分成多少個類別才最合適。(ISODATA算法通過類的自動合并和分裂,得到較為合理的類型數目K)
K-Means算法需要用初始隨機種子點來搞,這個隨機種子點太重要,不同的隨機種子點會有得到完全不同的結果。(K-Means++算法可以用來解決這個問題,其可以有效地選擇初始點)
看到這里,你會說,K-Means算法看來很簡單,而且好像就是在玩坐標點,沒什么真實用處。而且,這個算法缺陷很多,還不如人工呢。是的,前面的例子只是玩二維坐標點,的確沒什么意思。但是你想一下面的代碼實例:
使用K-Means圖片壓縮 代碼案例
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline#需是二維from sklearn.cluster import KMeans
import warnings
warnings.filterwarnings('ignore')
bird = plt.imread('./bird_small.png')
bird.shape# (128, 128, 3)#轉為二維
X = bird.reshape(-1,3)
kmeans =KMeans(4)
kmeans.fit(X)
y_ = kmeans.predict(X)
y_
array([0, 0, 0, …, 1, 1, 1])
#圖片像素被分成了四類 ,四個聚類中心
#對圖片中像素進行聚類,聚類中心就是這些像素的中心,當然也是像素值
colors = kmeans.cluster_centers_
colors
array([[0.79367614, 0.6389619 , 0.41842377],
[0.12838763, 0.13014919, 0.12066123],
[0.9112854 , 0.8586482 , 0.74024725],
[0.48819345, 0.40055096, 0.3231333 ]], dtype=float32)
colors
array([[0.79367614, 0.6389619 , 0.41842377],
[0.12838763, 0.13014919, 0.12066123],
[0.9112854 , 0.8586482 , 0.74024725],
[0.48819345, 0.40055096, 0.3231333 ]], dtype=float32)
bird2 = colors[y_]
plt.imshow(bird2.reshape(128,128,3))

kmeans =KMeans(256)
kmeans.fit(X)y_ = kmeans.predict(X)colors = kmeans.cluster_centers_
# plt.figure(figsize=(8,8))
bird3 = colors[y_]
plt.imshow(bird3.reshape(128,128,3))





的配置問題)






)





)

