中文官方文檔:http://lightgbm.apachecn.org/cn/latest/Installation-Guide.html
英文官方文檔:https://lightgbm.readthedocs.io/en/latest/
一、lightGBM安裝
在anaconda中輸入:pip install lightGBM即可
輸入import lightgbm as lgb做測試
二、lightGBM改進
原理推薦:原理討論一、原理討論二
XGB有什么優缺點
優點:
- 1、XGB利用了二階梯度來對節點進行劃分,相對其他GBM、GBDT來說,精度更加高。
- 2、利用局部近似算法對分裂節點的貪心算法優化,取適當的eps時,可以保持算法的性能且提高算法的運算速度。
- 3、在損失函數中加入了L1/L2項,控制模型的復雜度,提高模型的魯棒性。
- 4、提供并行計算能力,主要是在樹節點求不同的候選的分裂點的Gain Infomation(分裂后,損失函數的差值)
- 5、Tree Shrinkage,column subsampling等不同的處理細節。
缺點:
- 1、需要pre-sorted,這個會耗掉很多的內存空間(2 * #data * # features)
- 2、數據分割點上,由于XGB對不同的數據特征使用pre-sorted算法而不同特征其排序順序是不同的,所以分裂時需要對每個特征單獨做依次分割,遍歷次數為#data * #features來將數據分裂到左右子節點上。
- 3、盡管使用了局部近似計算,但是處理粒度還是太細了
- 4、由于pre-sorted處理數據,在尋找特征分裂點時(level-wise),會產生大量的cache隨機訪問。
?
因此LightGBM針對這些缺點進行了相應的改進
- LightGBM基于histogram算法代替pre-sorted所構建的數據結構,利用histogram后,會有很多有用的tricks。例如histogram做差,提高了cache命中率(主要是因為使用了leaf-wise)
- 在機器學習當中,我們面對大數據量時候都會使用采樣的方式(根據樣本權值)來提高訓練速度。又或者在訓練的時候賦予樣本權值來關于于某一類樣本(如Adaboost)。LightGBM利用了GOSS來做采樣算法
- 由于histogram算法對稀疏數據的處理時間復雜度沒有pre-sorted好。因為histogram并不管特征值是否為0。因此我們采用了EFB來預處理稀疏數據
- 1.直方圖差加速:直方圖算法的基本思想是先把連續的浮點特征值離散化成k個整數,同時構造一個寬度為k的直方圖。在遍歷數據的時候,根據離散化后的值作為索引在直方圖中累積統計量,當遍歷一次數據后,直方圖累積了需要的統計量,然后根據直方圖的離散值,遍歷尋找最優的分割點。內存消耗降低,計算上的代價也大幅降低
- 2.leaf-wise:每次從當前所有葉子中,找到分裂增益最大的一個葉子,然后分裂,如此循環。因此同Level-wise相比,在分裂次數相同的情況下,Leaf-wise可以降低更多的誤差,得到更好的精度。可能會長出比較深的決策樹,產生過擬合。因此LightGBM在Leaf-wise之上增加了一個最大深度限制,在保證高效率的同時防止過擬合。
- 3.特征并行和數據并行:特征并行的主要思想是在不同機器在不同的特征集合上分別尋找最優的分割點,然后在機器間同步最優的分割點。數據并行則是讓不同的機器先在本地構造直方圖,然后進行全局的合并,最后在合并的直方圖上面尋找最優分割點。
- 4.直接支持類別特征:可以直接輸入類別特征,不需要額外的0/1 展開,LightGBM 是第一個直接支持類別特征的 GBDT 工具。
三、常用參數解釋
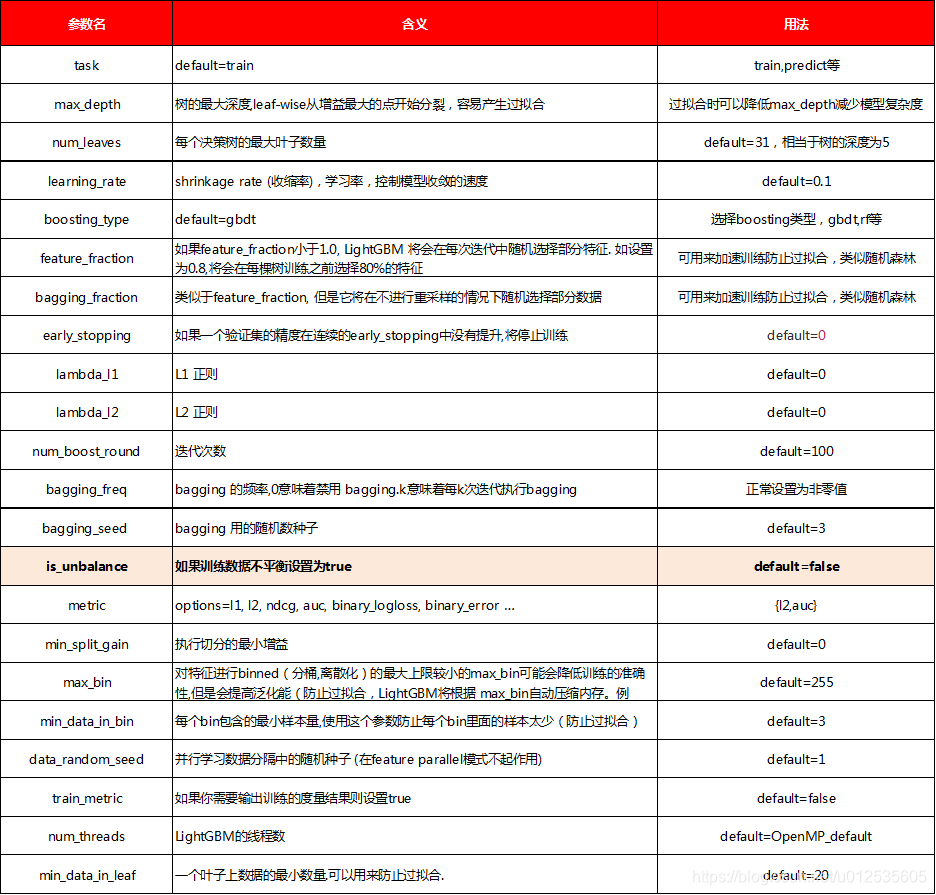
4.lightGBM使用
根據天池蒸汽賽代碼進行使用和對比xgboost
天池大賽地址:https://tianchi.aliyun.com/competition/entrance/231693/information
import numpy as np
import pandas as pd
from lightgbm import LGBMRegressor
from xgboost import XGBClassifier,XGBRegressortrain = pd.read_csv('../xgboost算法/zhengqi_train.txt',sep = '\t')
test = pd.read_csv('../xgboost算法/zhengqi_test.txt',sep = '\t')X_train.head()X_train = train.iloc[:,:-1]
y_train = train['target']
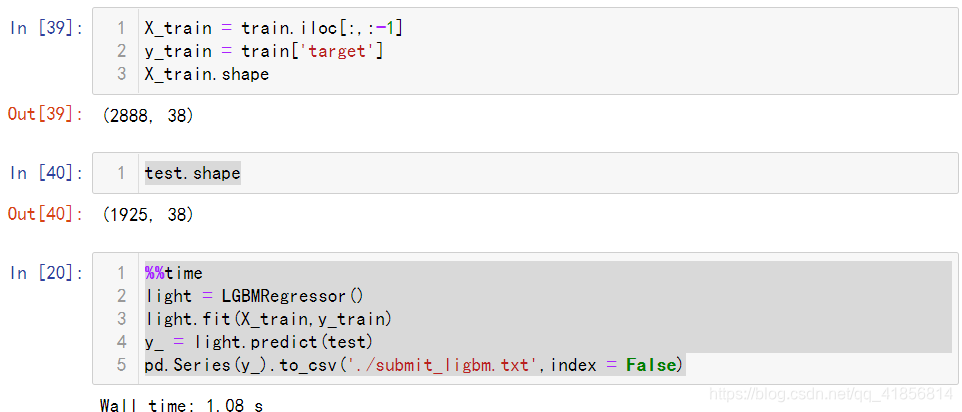
X_train.shapetest.shape%%time
light = LGBMRegressor()
light.fit(X_train,y_train)
y_ = light.predict(test)
pd.Series(y_).to_csv('./submit_ligbm.txt',index = False)%%time
xbg = XGBRegressor(n_estimators=3,max_depth=100)
xbg.fit(X_train,y_train)
y_ = xbg.predict(test)
pd.Series(y_).to_csv('./submit_xgb2.txt',index = False)train.var().array# 協方差 ,兩個屬性之間的關系,
# 協方差絕對值越大,連個屬性之間的關系越密切
cov = train.cov()
cov#刪除波動數據后用 lightbgm算法
light = LGBMRegressor()
light.fit(X_train,y_train)
y_ = light.predict(test)
pd.Series(y_).to_csv('./submit_ligbm3.txt',index = False)#刪除波動數據后用 xgb算法對比
from xgboost import XGBRegressor
xgb = XGBRegressor()xgb.fit(X_train,y_train)
y_ = xgb.predict(test)
pd.Series(y_).to_csv('./submit_xgb2.txt',index = False)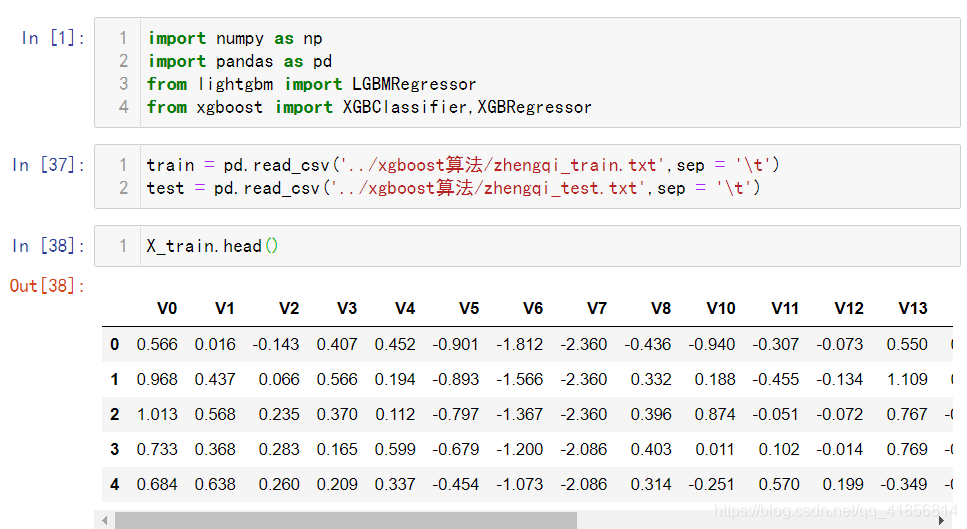
?
?
最終上傳成績提升了幾個點無截圖!









)




)


)

