文章目錄
- 1. 計算機網絡
- 1.1 請介紹七層網絡體系結構。
- 1.2 請介紹五層網絡體系結構。
- 1.3 了解網絡編程協議嗎?客戶端發送給服務器的請求,怎么確定具體的協議?
- 1.4 TCP、HTTP、FTP分別屬于哪一層?
- 1.5 講一下TCP/IP協議。
- 1.6 說一說你對ARP協議的理解。
- 1.7 IP協議包含哪些字段?
- 1.8 應用層都包含什么協議?
- 1.9 應用層報文怎么傳輸到另一個應用層?
- 1.10 介紹一下tcp的三次握手。
- 1.11 介紹一下tcp的四次揮手。
- 1.12 為什么需要四次揮手?
- 1.13 為什么要有最后一次ACK?
- 1.14 說一說你對tcp抓包的理解。
- 1.15 介紹一下tcp粘包、拆包的機制。
- 1.16 介紹一下TCP和UDP的區別。
- 1.17 TCP和UDP對于網絡穩定性有什么要求?
- 1.18 如何讓UDP可靠一些?
- 1.19 TCP報文首部中序號占多少字節?
- 1.20 TCP中的緩存有什么作用?
- 1.21 說一說TCP是怎么控制流量的?
- 1.22 HTTP2.0中TCP阻塞了怎么辦?
- 1.23 TCP如何保證可靠性?
- 1.24 說一說TCP里的reset狀態。
- 1.25 如何利用UDP實現可靠傳輸?
- 1.26 報文亂序怎么辦?
- 1.27 說一說你對IP分類的了解。
- 1.28 IP為什么要分類?
- 1.29 IPV4和IPV6有什么區別?
- 1.30 說一下http和https的區別。
- 1.31 https為什么采用混合加密機制?
- 1.32 https支持什么加密算法?
- 1.33 說一說HTTPS的秘鑰交換過程。
- 1.34 說一說HTTPS的證書認證過程。
- 1.35 HTTP請求頭中包含什么內容?
- 1.36 HTTP是基于TCP還是UDP?
- 1.37 HTTP1.1和HTTP2.0有什么區別?
- 1.38 HTTP2.0和HTTP3.0有什么區別?
- 1.39 談談HTTP的緩存機制,服務器如何判斷當前緩存過期?
- 1.40 介紹一下HTTP協議中的長連接和短連接。
- 1.41 介紹一下HTTPS的流程。
- 1.42 介紹一下HTTP的失敗碼。
- 1.43 說一說你知道的http狀態碼。
- 1.44 301和302有什么區別?
- 1.45 302和304有什么區別?
- 1.46 請描述一次完整的HTTP請求的過程。
- 1.47 什么是重定向?
- 1.48 重定向和請求轉發有什么區別?
- 1.49 介紹一下DNS尋址的過程。
- 1.50 說一說你對TIME_WAIT的理解。
- 1.51 TIME_WAIT、CLOSE_WAIT狀態發生在哪一步?
- 1.52 有大量的TIME_WAIT狀態怎么辦?
- 1.53 請介紹socket通信的具體步驟。
- 1.54 服務端怎么提高處理socket連接的性能?
- 1.55 介紹一下流量控制和擁塞控制。
- 1.56 對路由協議是否有所了解?
- 1.57 直播可能需要使用到什么樣的協議?
- 1.58 談談單工、雙工、半雙工的通信方式。
- 1.59 說一說內網和外網通信的過程。
- 1.59 說一說內網和外網通信的過程。
1. 計算機網絡
1.1 請介紹七層網絡體系結構。
參考回答
-
為什么分七層
支持異構網絡的互聯互通。
-
七層分別負責的內容(功能)
OSI 模型把網絡通信的工作分為 7 層,從下到上分別是物理層、數據鏈路層、網絡層、傳輸層、會話層、表示層和應用層。
(1) 物理層
任務:透明地傳輸比特流。
功能:為數據段設備提供傳送數據通路
傳輸單位:比特
所實現的硬件:集線器,中繼器
(2)數據鏈路層
任務:將網絡層傳輸下來的IP數據報組裝成幀
功能:a. 鏈路連接的建立、拆除和分離
b. 幀定界和幀同步
c.差錯檢測
傳輸單位:幀
所實現的硬件:交換機、網橋
協議:PPP,HDLC、SDLC、STP、ARQ
(3)網絡層
任務:a. 將傳輸層傳下來的報文段封裝成分組
b.選擇合適的路由,使得傳輸層傳下來的分組能夠交付到目的主機
功能:a. 為傳輸層提供服務
b. 組包和拆包
c. 路由選擇
d.擁塞控制
傳輸單位:數據段
所實現的硬件:路由器
協議:ICMP、ARP、RARP、IP、IGMP、OSPF
(4)傳輸層
任務:負責主機中兩個進程之間的通信
功能:
a. 為端到端連接提供可靠的服務
b. 為端到端連接提供流量控制、差錯控制、服務質量等管理服務
傳輸單位:報文段(TCP)或用戶數據報(UDP)
協議:TCP、UDP
(5)會話層
任務:不同主機上各進程間的對話
功能:管理主機間的會話進程,包括建立、管理以及終止進程間的會話。是一種端到端的服務
(6)表示層
負責處理在兩個內部數據表示結構不同的通信系統之間交換信息的表示格式,為數據加密和解密以及為提高傳輸效率提供必需的數據壓縮以及解壓等功能。
(7)應用層
任務:提供系統與用戶的接口
功能:
a.文件傳輸
b. 訪問和管理
c. 電子郵件服務
協議:FTP、SMTP、POP3、HTTP、DNS、TELnet
1.2 請介紹五層網絡體系結構。
參考回答
五層網絡體系結構分分別為:應用層、運輸層、網絡層、數據鏈路層、物理層。各層功能分別如下:
-
第五層——應用層(application layer)
(1) 應用層(application layer):是體系結構中的最高。直接為用戶的應用進程提供服務。
(2) 在因特網中的應用層協議很多,如支持萬維網應用的HTTP協議,支持電子郵件的SMTP協議,支持文件傳送的FTP協議等等。
-
第四層——運輸層(transport layer)
(1) 運輸層(transport layer):負責向兩個主機中進程之間的通信提供服務。由于一個主機可同時運行多個進程,因此運輸層有復用和分用的功能。
a. 復用,就是多個應用層進程可同時使用下面運輸層的服務。
b. 分用,就是把收到的信息分別交付給上面應用層中相應的進程。
(2) 運輸層主要使用以下兩種協議:
**(``1``) 傳輸控制協議TCP(Transmission Control Protocol):**面向連接的,數據傳輸的單位是報文段,能夠提供可靠的交付。``**(``2``) 用戶數據包協議UDP(User Datagram Protocol):**無連接的,數據傳輸的單位是用戶數據報,不保證提供可靠的交付,只能提供“盡最大努力交付”。 -
第三層——網絡層(network layer)
網絡層(network layer)主要包括以下兩個任務:
(1) 負責為分組交換網上的不同主機提供通信服務。在發送數據時,網絡層把運輸層殘生的報文段或用戶數據報封裝成分組或包進行傳送。在TCP/IP體系中,由于網絡層使用IP協議,因此分組也叫做IP數據報,或簡稱為數據報。
(2) 選中合適的路由,使源主機運輸層所傳下來的分組,能夠通過網絡中的路由器找到目的主機。
-
第二層——數據鏈路層(data link layer)
**數據鏈路層(data link layer):**常簡稱為鏈路層,我們知道,兩個主機之間的數據傳輸,總是在一段一段的鏈路上傳送的,也就是說,在兩個相鄰結點之間傳送數據是直接傳送的(點對點),這時就需要使用專門的鏈路層的協議。
在兩個相鄰結點之間傳送數據時,數據鏈路層將網絡層交下來的IP數據報組裝成幀(framing),在兩個相鄰結點之間的鏈路上“透明”地傳送幀中的數據。
每一幀包括數據和必要的控制信息(如同步信息、地址信息、差錯控制等)。典型的幀長是幾百字節到一千多字節。
注意:”透明”是一個很重要的術語。它表示,某一個實際存在的事物看起來卻好像不存在一樣。”在數據鏈路層透明傳送數據”表示無力什么樣的比特組合的數據都能夠通過這個數據鏈路層。因此,對所傳送的數據來說,這些數據就“看不見”數據鏈路層。或者說,數據鏈路層對這些數據來說是透明的。
(``1``) 在接收數據時,控制信息使接收端能知道一個幀從哪個比特開始和到哪個比特結束。這樣,數據鏈路層在收到一個幀后,就可從中提取出數據部分,上交給網絡層。``(``2``) 控制信息還使接收端能檢測到所收到的幀中有無差錯。如發現有差錯,數據鏈路層就簡單地丟棄這個出了差錯的幀,以免繼續傳送下去白白浪費網絡資源。如需改正錯誤,就由運輸層的TCP協議來完成。 -
第一層——物理層(physical layer)
**物理層(physical layer):**在物理層上所傳數據的單位是比特。物理層的任務就是透明地傳送比特流。
1.3 了解網絡編程協議嗎?客戶端發送給服務器的請求,怎么確定具體的協議?
參考回答
了解,客戶端發送給服務器端的請求,可以根據統一資源定位系統(uniform resource locator,URL)來確定具體使用的協議。
答案解析
一個完整的URL包括–協議部分、網址、文件地址部分。協議部分以//為分隔符,在interner中,我們可以使用多種協議:
HTTP——HyperText Transfer Protocol(超文本傳輸協議)
FTP——File Transfer Protocol(文件傳輸協議)
Gopher——The Internet Gopher Protocol(網際Gopher協議)
File——本地文件傳輸協議
HTTPS——安全套接字層超文本傳輸協議(http的安全版)
例如牛客網址:http://nowcoder.com,可以看出使用的是http協議。
1.4 TCP、HTTP、FTP分別屬于哪一層?
參考回答
TCP、HTTP、FTP分別屬于傳輸層、應用層、應用層。
答案解析
-
TCP協議簡介
(1)TCP協議的特性
TCP是面向連接的,提供全雙工的服務,數據流可以雙向傳輸。也是點對點的,即在單個發送放方和單個接收方之間的連接。
(2)TCP 報文段結構
序號:TCP 的序號是數據流中的字節數,不是分組的序號。表示該報文段數據字段首字節的序號。
確認號:TCP 使用累積確認,確認號是第一個未收到的字節序號,表示希望接收到的下一個字節。
首部長度:通常選項字段為空,所以一般 TCP 首部的長度是 20 字節。
選項字段(可選與變長的):用于發送方與接收方協商 MSS(最大報文段長),或在高速網絡環境下用作窗口
調節因子。
標志字段
ACK:指示確認字段中的值是有效的
RST,SYN,FIN:連接建立與拆除
PSH:指示接收方應立即將數據交給上層
URG:報文段中存在著(被發送方的上層實體置位)“緊急”的數據
接收窗口:用于流量控制(表示接收方還有多少可用的緩存空間)。
TCP RFC 并沒有規定失序到達的分組應該如何處理,而是交給程序員。可以選擇丟棄或保留。如果發生超時,TCP 只重傳第一個已發送而未確認的分組,超時時間間隔會設置為原來的 2 倍。
(3)流量控制
如果應用程序讀取數據相當慢,而發送方發送數據太多、太快,會很容易使接收方的接收緩存溢出,流量控制就是用來進行發送速度和接收速度的匹配。發送方維護一個“接收窗口”變量,這個變量表示接收方當前可用的緩存空間。
-
HTTP(超文本傳輸協議)簡介
(1)HTTP協議的特性
HTTP 協議一共有五大特點:a. 支持客戶/服務器模式;b. 簡單快速;c. 靈活;d. 無連接;e. 無狀態。
**無連接含義:**限制每次連接只處理一個請求。服務器處理完客戶的請求,并收到客戶的應答后,即斷開連接。采用這種方式可以節省傳輸時間。
**無狀態含義:**指協議對于事務處理沒有記憶能力,服務器不知道客戶端是什么狀態。即我們給服務器發送 HTTP 請求之后,服務器根據請求,會給我們發送數據過來,但是,發送完,不會記錄任何信息。
(2)HTTP 客戶機及服務器
HTTP 客戶機:web 瀏覽器
HTTP 服務器:web 服務器,包含 web 對象(HTML 文件、JPEG 文件、java 小程序、視頻片段等)
(3)HTTP 方法字段:
GET:絕大部分 HTTP 請求報文使用 GET 方法
POST:用戶提交表單時(如向搜索引擎提供關鍵字),但提交表單不一定要用 POST 方法
HEAD:類似于 GET,區別在于服務器返回的響應報文中不包含請求對象(常用于故障跟蹤)
PUT:用于向服務器上傳對象
DELETE:用于刪除服務器上的對象
(4)HTTP 狀態信息
301 Permanently Moved 被請求的資源已永久移動到新位置,新的URL在Location頭中給出,瀏覽器應該自動地訪問新的URL。
302 Found 請求的資源現在臨時從不同的URL響應請求。301是永久重定向,而302是臨時重定向。
200 OK 表示從客戶端發來的請求在服務器端被正確處理
304 Not Modified 304狀態碼是告訴瀏覽器可以從緩存中獲取所請求的資源。
400 bad request 請求報文存在語法錯誤
403 forbidden 表示對請求資源的訪問被服務器拒絕
404 not found 表示在服務器上沒有找到請求的資源
500 internal sever error 表示服務器端在執行請求時發生了錯誤
503 service unavailable 表明服務器暫時處于超負載或正在停機維護,無法處理請求
(4)HTTP中常見的文件格式
text/html: HTML格式
text/plain:純文本格式
image/jpeg:jpg圖片格式
application/json: JSON數據格式
application/x-www-form-urlencoded: form表單數據被編碼為key/value格式發送到服務器(表單默認的提交數據格式)
multipart/form-data: 在表單中進行文件上傳時使用
-
FTP(文件傳輸協議簡介)
FTP 使用兩個并行的 TCP 連接來傳輸文件:
(1)**控制連接(持久):**傳輸控制信息,如用戶標識、口令、改變遠程目錄命令、文件獲取上傳的命令;
(2)**數據連接(非持久):**傳輸實際文件。
FTP 客戶機發起向 FTP 服務器的控制連接,然后在該連接上發送用戶標識和口令、改變遠程目錄的命令。FTP服務器收到命令后,發起一個到客戶機的數據連接,在該連接上準確地傳送一個文件并關閉連接。
有狀態的協議:FTP 服務器在整個會話期間保留用戶的狀態信息。服務器必須把特定的用戶賬號和控制連接
聯系起來。
-
傳輸層簡介
(1)傳輸層的服務基本原理
a. 多路復用和解復用(分路)技術
**復用:**發送方的不同的應用進程都可以使用同一個傳輸層協議傳送數據;
分路技術:接收方的傳輸層剝去報文首部之后能把這些數據正確的傳輸到正確的應用進程上。
b. 可靠數據傳輸
c. 流量控制和擁塞控制
(2)傳輸層提供的服務
a. 傳輸層尋址和端口
端口號就是用來標識應用進程的數字標識。其端口號的長度為16Bit;也就是能夠標識2^16個不同的端口號。另外端口號根據端口范圍分為2類。分別為服務端使用的端口號(熟知端口號數值范圍:0-1023;登記端口號數值范圍:1024-49151)和客戶端使用的端口號(數值范圍為49152-65535)。常見端口號如下:
FTP:21
TELNET:23
SMTP:25
DNS:53
TFTP:69
HTTP:80
SNMP:161
b. 無連接服務和面向連接服務
(3)流量控制和擁塞控制
a. **流量控制:**如果發送方把數據發送得過快,接收方可能會來不及接收,這就會造成數據的丟失。
b. **擁塞控制:**擁塞控制就是防止過多的數據注入到網絡中,這樣可以使網絡中的路由器或鏈路不致過載。
兩者的區別:流量控制是為了預防擁塞。如:在馬路上行車,交警跟紅綠燈是流量控制,當發生擁塞時,如何進行疏散,是擁塞控制。流量控制指點對點通信量的控制。而擁塞控制是全局性的,涉及到所有的主機和降低網絡性能的因素。
-
應用層簡介
應用層的具體內容就是規定應用進程在通信時所遵循的協議。應用層協議分類如下:
(1). 域名系統(Domain Name System,DNS):用于實現網絡設備名字到IP地址映射的網絡服務。
(2). 文件傳輸協議(File Transfer Protocol,FTP):用于實現交互式文件傳輸功能。
(3). 簡單郵件傳送協議(Simple Mail Transfer Protocol, SMTP):用于實現電子郵箱傳送功能
(4). 超文本傳輸協議(HyperText Transfer Protocol,HTTP):用于實現WWW服務。
(5). 簡單網絡管理協議(simple Network Management Protocol,SNMP):用于管理與監視網絡設備。
(6). 遠程登錄協議(Telnet):用于實現遠程登錄功能。
1.5 講一下TCP/IP協議。
參考回答
-
TCP/IP協議定義
TCP/IP(Transmission Control Protocol/Internet Protocol,傳輸控制協議/網際協議)是指能夠在多個不同網絡間實現信息傳輸的協議簇。TCP/IP協議不僅僅指的是TCP和IP兩個協議,而是指一個由FTP、SMTP、TCP、UDP、IP等協議構成的協議簇, 只是因為在TCP/IP協議中TCP協議和IP協議最具代表性,所以被稱為TCP/IP協議。
-
TCP/IP協議組成
TCP/IP結構模型分為**應用層、傳輸層、網絡層、鏈路層(網絡接口層)**四層,以下是各層的詳細介紹:
(1)應用層
應用層是TCP/IP協議的第一層,是直接為應用進程提供服務的。
a. 對不同種類的應用程序它們會根據自己的需要來使用應用層的不同協議,郵件傳輸應用使用了SMTP協議、萬維網應用使用了HTTP協議、遠程登錄服務應用使用了有TELNET協議。
b. 應用層還能加密、解密、格式化數據。
c. 應用層可以建立或解除與其他節點的聯系,這樣可以充分節省網絡資源。
(2)傳輸層
作為TCP/IP協議的第二層,運輸層在整個TCP/IP協議中起到了中流砥柱的作用。且在運輸層中,TCP和UDP也同樣起到了中流砥柱的作用。
(3)網絡層
網絡層在TCP/IP協議中的位于第三層。在TCP/IP協議中網絡層可以進行網絡連接的建立和終止以及IP地址的尋找等功能。
(4)鏈路層(網絡接口層)
在TCP/IP協議中,網絡接口層位于第四層。由于網絡接口層兼并了物理層和數據鏈路層。所以,網絡接口層既是傳輸數據的物理媒介,也可以為網絡層提供一條準確無誤的線路。
-
TCP/IP協議特點
TCP/IP協議能夠迅速發展起來并成為事實上的標準,是它恰好適應了世界范圍內數據通信的需要。它有以下特點:
(1)協議標準是完全開放的,可以供用戶免費使用,并且獨立于特定的計算機硬件與操作系統;
(2)獨立于網絡硬件系統,可以運行在廣域網,更適合于互聯網;
(3)網絡地址統一分配,網絡中每一設備和終端都具有一個唯一地址;
(4)高層協議標準化,可以提供多種多樣可靠網絡服務。
1.6 說一說你對ARP協議的理解。
參考回答
ARP協議即地址解析協議,是根據IP地址獲取MAC地址的一個網絡層協議。
-
工作原理
ARP首先會發起一個請求數據包,數據包的首部包含了目標主機的IP地址,然后這個數據包會在鏈路層進行再次包裝,生成以太網數據包,最終由以太網廣播給子網內的所有主機,每一臺主機都會接收到這個數據包,并取出標頭里的IP地址,然后和自己的IP地址進行比較,如果相同就返回自己的MAC地址,如果不同就丟棄該數據包。ARP接收返回消息,以此確定目標機的MAC地址;與此同時,ARP還會將返回的MAC地址與對應的IP地址存入本機ARP緩存中并保留一定時間,下次請求時直接查詢ARP緩存以節約資源。
-
工作過程
主機A的IP地址為192.168.1.1,MAC地址為0A-11-22-33-44-01;
主機B的IP地址為192.168.1.2,MAC地址為0A-11-22-33-44-02;
當主機A要與主機B通信時,地址解析協議可以將主機B的IP地址(192.168.1.2)解析成主機B的MAC地址,以下為工作流程:
第1步:根據主機A上的路由表內容,IP確定用于訪問主機B的轉發IP地址是192.168.1.2。然后A主機在自己的本地ARP緩存中檢查主機B的匹配MAC地址。
第2步:如果主機A在ARP緩存中沒有找到映射,它將詢問192.168.1.2的硬件地址,從而將ARP請求幀廣播到本地網絡上的所有主機。源主機A的IP地址和MAC地址都包括在ARP請求中。本地網絡上的每臺主機都接收到ARP請求并且檢查是否與自己的IP地址匹配。如果主機發現請求的IP地址與自己的IP地址不匹配,它將丟棄ARP請求。
第3步:主機B確定ARP請求中的IP地址與自己的IP地址匹配,則將主機A的IP地址和MAC地址映射添加到本地ARP緩存中。
第4步:主機B將包含其MAC地址的ARP回復消息直接發送回主機A。
第5步:當主機A收到從主機B發來的ARP回復消息時,會用主機B的IP和MAC地址映射更新ARP緩存。本機緩存是有生存期的,生存期結束后,將再次重復上面的過程。主機B的MAC地址一旦確定,主機A就能向主機B發送IP通信了。
-
ARP報文格式

硬件類型:指明了發送方想知道的硬件接口類型,以太網的值為1;
協議類型:指明了發送方提供的高層協議類型,IP為0800(16進制);
硬件地址長度和協議長度:指明了硬件地址和高層協議地址的長度,這樣ARP報文就可以在任意硬件和任意協議的網絡中使用;
操作類型:用來表示這個報文的類型,ARP請求為1,ARP響應為2,RARP請求為3,RARP響應為4;
發送方硬件地址(0-3字節):源主機硬件地址的前3個字節;
發送方硬件地址(4-5字節):源主機硬件地址的后3個字節;
發送方IP地址(0-1字節):源主機硬件地址的前2個字節;
發送方IP地址(2-3字節):源主機硬件地址的后2個字節;
目標硬件地址(0-1字節):目的主機硬件地址的前2個字節;
目標硬件地址(2-5字節):目的主機硬件地址的后4個字節;
目標IP地址(0-3字節):目的主機的IP地址。
1.7 IP協議包含哪些字段?
參考回答
IP所包含字段結構圖如下:
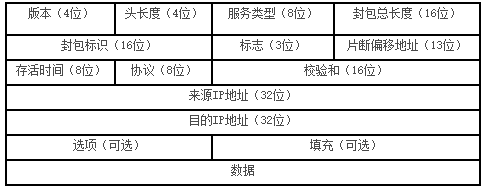
IP協議包含字段如下:
**4位版本號:**指定IP協議的版本,對于IPv4來說就是4
**4位頭部長度:**IP頭部長度有多少個4字節,所以頭部最大長度就是15*4=60字節
**8位服務類型:**3位優先權(已棄用),4位TOS字段,1位保留字段(必須設置為0)。4為TOS為:最小延時,最大吞吐量,最高可靠性,最小成本,這四個只能選擇一個
**16位總長度:**IP數據報整體占多少字節
**16為標識:**唯一的標識主機發送的報文,IP報文在數據鏈路層被分片,那么每一個片中的標識都是相同的
**3位標志字段:**第一位保留,第二位置1表示進制分片(報文長度超過MTU,丟棄報文),第三位更多分片,最后一個分片是1,其他是0
**13位分片偏移:**相對于原始IP報文開始處的偏移
**8位生存時間:**數據報到達目的地的最大報文跳數,每經過一個路由,TTL-=1,一直到0都沒有到達目的地,報文丟棄。
8位協議:表示上層協議類型,把IP交給TCP還是UDP,其中ICMP是1,TCP是6,UDP是17
**16位頭部校驗和:**使用CRC校驗,鑒別頭部是否損壞
**32位源地址和32位目標地址:**表示發送端和接收端
1.8 應用層都包含什么協議?
參考回答
應用層包含的協議有DNS、FTP、SMTP、HTTP、SNMP、Telnet等,其作用分別如下:
- 域名系統(Domain Name System,DNS):用于實現網絡設備名字到IP地址映射的網絡服務。
- 文件傳輸協議(File Transfer Protocol,FTP):用于實現交互式文件傳輸功能。
- 簡單郵件傳送協議(Simple Mail Transfer Protocol, SMTP):用于實現電子郵箱傳送功能。
- 超文本傳輸協議(HyperText Transfer Protocol,HTTP):用于實現WWW服務。
- 簡單網絡管理協議(simple Network Management Protocol,SNMP):用于管理與監視網絡設備。
- 遠程登錄協議(Telnet):用于實現遠程登錄功能。
答案解析
應用層協議定義了運行在不同端系統上的應用程序進程如何相互傳遞消息。特別是定義了:
- 交換的消息類型,如請求消息和響應消息。
- 各種消息類型的語法,如消息中的各個字段及其詳細描述。
- 字段的語義,即包含在字段中的信息的含義。
- 進程何時、如何發送消息及對消息進行響應的規則。
- 有些應用層協議是由RFC文檔定義的,因此它們位于公共領域,例如HTTP。
- 有些應用層協議是公司或者個人私有的,位于私人領域,例如QQ。
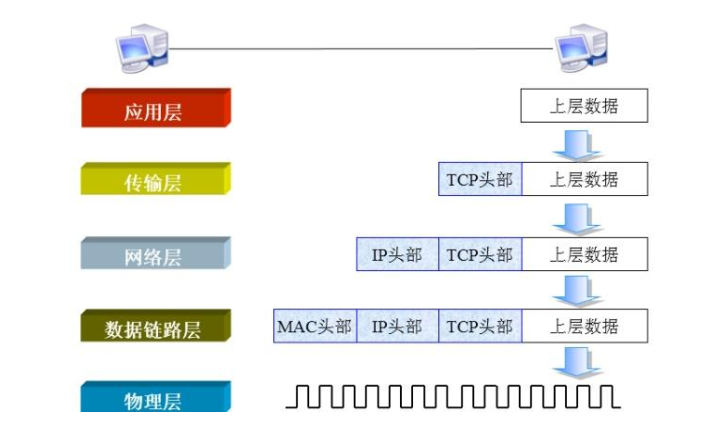
1.9 應用層報文怎么傳輸到另一個應用層?
參考回答
**應用層數據(報文)向外發送時,數據是由最上面的應用層向下經過一層層封裝后發送給物理層;而接收數據時,數據是由物理層向上經過一層層解封后發給應用層。**數據的封裝和解封過程如下:
-
數據的封裝過程簡介
傳輸層及其以下的機制由內核提供, 應用層由用戶進程提供, 應用程序對通訊數據的含義進行解釋, 而傳輸層及其以下處理通訊的細節,將數據從一臺計算機通過一定的路徑發送到另一臺計算機。 應用層數據通過協議棧發到網絡上時,每層協議都要加上一個相對應的頭部(header ),該過程稱為封裝封裝過程如下圖所示:
-
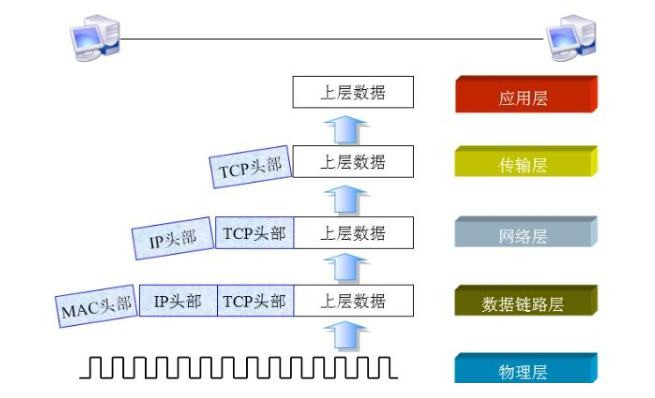
數據的解封過程簡介
不 同 的 協 議 層 對 數 據 包 有 不 同的 稱 謂 ,在 傳 輸 層 叫 做 段(segment ),在網絡層叫做數據報( datagram) ,在鏈路層叫做幀(frame )。數據封裝成幀后發到傳輸介質上,到達目的主機后,每層協議再剝掉相應的頭部,最后將應用層數據交給應用程序處理,該過程稱為解封。解封過程如下圖所示:
-
舉例說明數據封裝和解封裝過程
(1)從計算機 A 的應用層內網通軟件向計算機 B 發出一個消息,生成數據;
(2)請求從計算機 A 的應用層下到 計算機A 的傳輸層,傳輸層在上層數據前面加上 TCP報頭,報頭中包括目標端口以及源端口;
(3)傳輸層數據下到網絡層,計算機A 在網絡層封裝,源 IP地址為 計算機A地址,目標 IP地址為 計算機 B 地址;
(4)計算機 A 將計算機B 的 IP 地址和子網掩碼與自己做比對,可以發現 計算機 B 與自己處于相同的子網。所以數據傳輸不必經過網關設備;
(5)數據包下到 計算機 A 的數據鏈路層進行封裝,源 MAC 地址為 計算機A的 MAC地址,目標 MAC 地址查詢自己的 ARP 表。
(6)計算機 A 把幀轉換成 bit 流,從物理接口網卡發出;
(7)物理層接收到電信號,把它交給數據鏈路層進行查看幀的目標 MAC 地址,和自己是否相等,如果相等說明該幀是發送給自己的,于是將MAC幀頭解開并接著上傳到網絡層;
(8)網絡層查看目標 IP 地址和自己是否匹配,如果匹配即解開 IP 頭封裝。然后再把數據上傳到傳輸層;
(9)傳輸層解開對應的包頭之后,繼續把數據傳給應用層,計算機 B 即可接收到計算機 A 發的消息。
答案解析
報文、報文段、分組、包、數據報、幀、數據流的概念區別如下:
-
報文(message)
我們將位于應用層的信息分組稱為報文。報文是網絡中交換與傳輸的數據單元,也是網絡傳輸的單元。報文包含了將要發送的完整的數據信息,其長短不需一致。報文在傳輸過程中會不斷地封裝成分組、包、幀來傳輸,封裝的方式就是添加一些控制信息組成的首部,那些就是報文頭。
-
報文段(segment)
通常是指起始點和目的地都是傳輸層的信息單元。
-
分組/包(packet)
分組是在網絡中傳輸的二進制格式的單元,為了提供通信性能和可靠性,每個用戶發送的數據會被分成多個更小的部分。在每個部分的前面加上一些必要的控制信息組成的首部,有時也會加上尾部,就構成了一個分組。它的起始和目的地是網絡層。
-
數據報(datagram)
面向無連接的數據傳輸,其工作過程類似于報文交換。采用數據報方式傳輸時,被傳輸的分組稱為數據報。通常是指起始點和目的地都使用無連接網絡服務的的網絡層的信息單元。
-
幀(frame)
幀是數據鏈路層的傳輸單元。它將上層傳入的數據添加一個頭部和尾部,組成了幀。它的起始點和目的點都是數據鏈路層。
-
數據單元(data unit)
指許多信息單元。常用的數據單元有服務數據單元(SDU)、協議數據單元(PDU)。
SDU是在同一機器上的兩層之間傳送信息。PDU是發送機器上每層的信息發送到接收機器上的相應層(同等層間交流用的)。
1.10 介紹一下tcp的三次握手。
參考回答
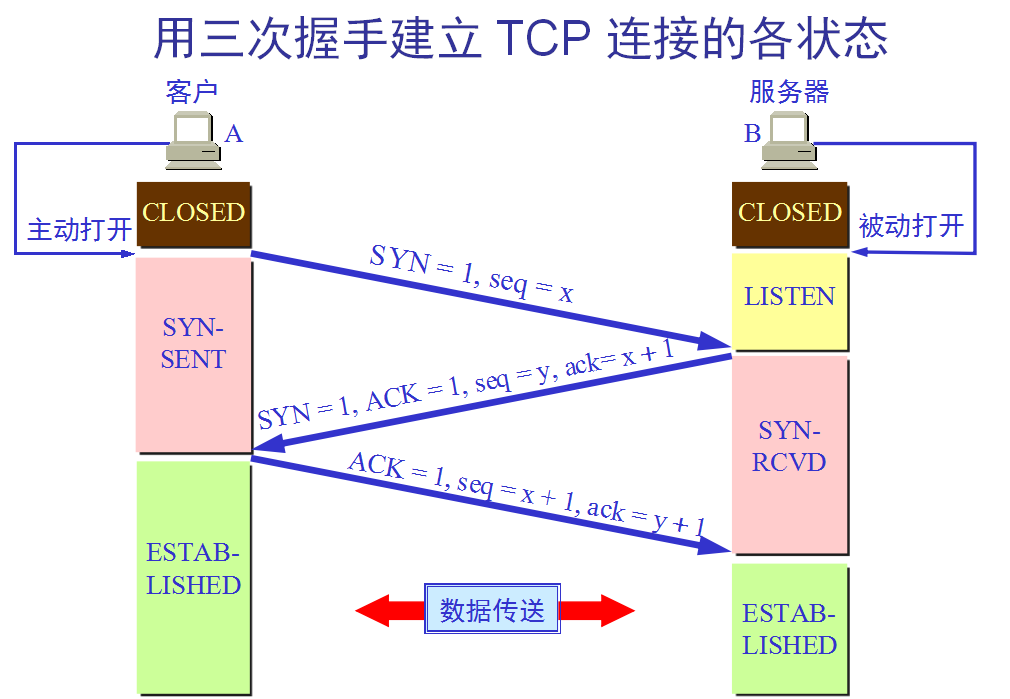
- 第一次握手:建立連接時,客戶端發送syn包(syn=x)到服務器,并進入SYN_SENT狀態,等待服務器確認;SYN:同步序列編號(Synchronize Sequence Numbers)。
- 第二次握手:服務器收到syn包,必須確認客戶的SYN(ack=x+1),同時自己也發送一個SYN包(syn=y),即SYN+ACK包,此時服務器進入SYN_RECV狀態;
- 第三次握手:客戶端收到服務器的SYN+ACK包,向服務器發送確認包ACK(ack=y+1),此包發送完畢,客戶端和服務器進入ESTABLISHED(TCP連接成功)狀態,完成三次握手。
1.11 介紹一下tcp的四次揮手。
參考回答
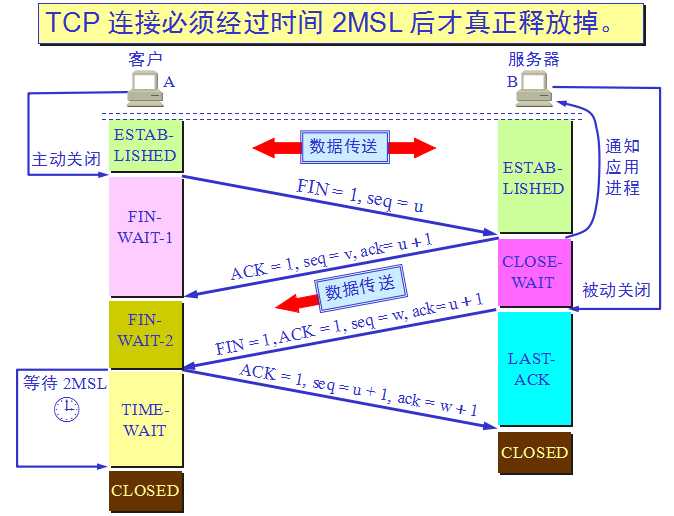
- 客戶端進程發出連接釋放報文,并且停止發送數據。釋放數據報文首部,FIN=1,其序列號為seq=u(等于前面已經傳送過來的數據的最后一個字節的序號加1),此時,客戶端進入FIN-WAIT-1(終止等待1)狀態。 TCP規定,FIN報文段即使不攜帶數據,也要消耗一個序號。
- 服務器收到連接釋放報文,發出確認報文,ACK=1,ack=u+1,并且帶上自己的序列號seq=v,此時,服務端就進入了CLOSE-WAIT(關閉等待)狀態。TCP服務器通知高層的應用進程,客戶端向服務器的方向就釋放了,這時候處于半關閉狀態,即客戶端已經沒有數據要發送了,但是服務器若發送數據,客戶端依然要接受。這個狀態還要持續一段時間,也就是整個CLOSE-WAIT狀態持續的時間。
- 客戶端收到服務器的確認請求后,此時,客戶端就進入FIN-WAIT-2(終止等待2)狀態,等待服務器發送連接釋放報文(在這之前還需要接受服務器發送的最后的數據)。
- 服務器將最后的數據發送完畢后,就向客戶端發送連接釋放報文,FIN=1,ack=u+1,由于在半關閉狀態,服務器很可能又發送了一些數據,假定此時的序列號為seq=w,此時,服務器就進入了LAST-ACK(最后確認)狀態,等待客戶端的確認。
- 客戶端收到服務器的連接釋放報文后,必須發出確認,ACK=1,ack=w+1,而自己的序列號是seq=u+1,此時,客戶端就進入了TIME-WAIT(時間等待)狀態。注意此時TCP連接還沒有釋放,必須經過2??MSL(最長報文段壽命)的時間后,當客戶端撤銷相應的TCB后,才進入CLOSED狀態。
- 服務器只要收到了客戶端發出的確認,立即進入CLOSED狀態。同樣,撤銷TCB后,就結束了這次的TCP連接。可以看到,服務器結束TCP連接的時間要比客戶端早一些。
1.12 為什么需要四次揮手?
參考回答
-
四次揮手示意圖
-
四次揮手過程
(1)客戶端向服務器發送FIN控制報文段(首部中的 FIN 比特被置位);
(2)服務端收到FIN,回復ACK。服務器進入關閉等待狀態,發送FIN;
(3)客戶端收到FIN,給服務器回復ACK,客戶端進入等待狀態(進入“等待”,以確保服務器收到ACK真正關閉連接);
(4)服務端收到ACK,鏈接關閉。
-
四次揮手原因
TCP協議是一種面向連接的、可靠的、基于字節流的運輸層通信協議。TCP是全雙工模式,這就意味著,當客戶端發出FIN報文段時,只是表示客戶端已經沒有數據要發送了,客戶端告訴服務器,它的數據已經全部發送完畢了;但是,這個時候客戶端還是可以接受來自服務端的數據;當服務端返回ACK報文段時,表示它已經知道客戶端沒有數據發送了,但是服務端還是可以發送數據到客戶端的;當服務端也發送了FIN報文段時,這個時候就表示服務端也沒有數據要發送了,就會告訴客戶端,我也沒有數據要發送了,之后彼此就會愉快的中斷這次TCP連接。
簡單地說,前 2 次揮手用于關閉一個方向的數據通道,后兩次揮手用于關閉另外一個方向的數據通道。
1.13 為什么要有最后一次ACK?
參考回答
-
三次握手示意圖
-
四次揮手過程
(1)客戶端發送一個SYN0給服務器(選擇初始序列號,不攜帶任何數據)
(2)服務器收到SYN0,回復SYN1和ACK(服務器分配緩存,選擇自己初始序列號)
(3)客戶端收到SYN1、ACK,回復ACK(可以包含數據)
-
為什么要有最后一次ACK
客戶端首先向服務器發送一個連接請求,但是可能這個連接請求走了遠路,等了很長時間,服務器都沒有收到,那么客戶端可能會再次發送,此時服務器端收到并且回復SYN、ACK;在這個時候最先發送的那個連接請求到達服務器,那么服務器會回復一個SYN,ACK;但是客戶端表示自己已經收到確認了,并不搭理這個回復,那么服務器可能陷入等待,如果這種情況多了,那么會導致服務器癱瘓,所以要發送第三個確認。
答案解析
1.14 說一說你對tcp抓包的理解。
參考回答
-
TCP抓包定義
tcp抓包是指通過抓取計算機訪問Web網站過程抓到的數據包,分析驗證TCP報文段的結構。可以用抓包工具進行抓包分析。
答案解析
示例(wireshark抓包分析流程):
Wireshark捕獲的是網卡的網絡包,當機器上有多塊網卡的時候,需要先選擇網卡。開始界面中的Interface List,即網卡列表,選擇我們需要的監控的網卡。點擊Capture Options,選擇正確的網卡,然后點擊"Start"按鈕, 開始抓包。
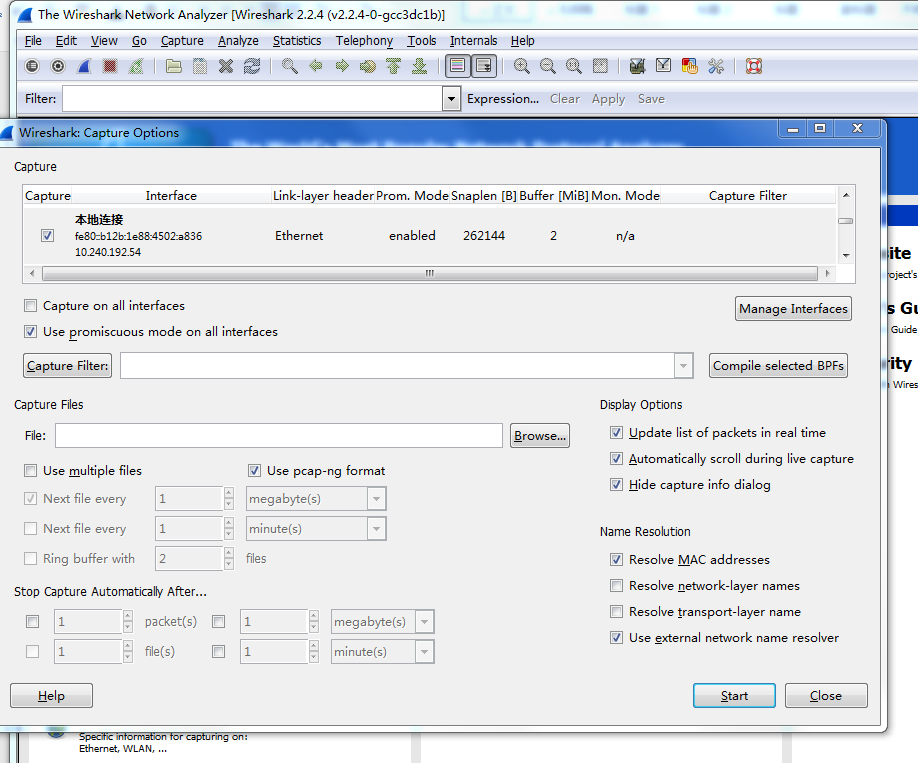
我們打開瀏覽器輸入任意http網址,連接再關閉,比如:http://blog.csdn.net。然后,我們回到Wireshark界面,點擊左上角的停止按鍵。查看此時Wireshark的抓包信息。在看抓包信息之前,先簡單介紹下Wireshark界面的含義。其中,封包列表的面板中顯示編號、時間戳、源地址、目標地址、協議、長度,以及封包信息。
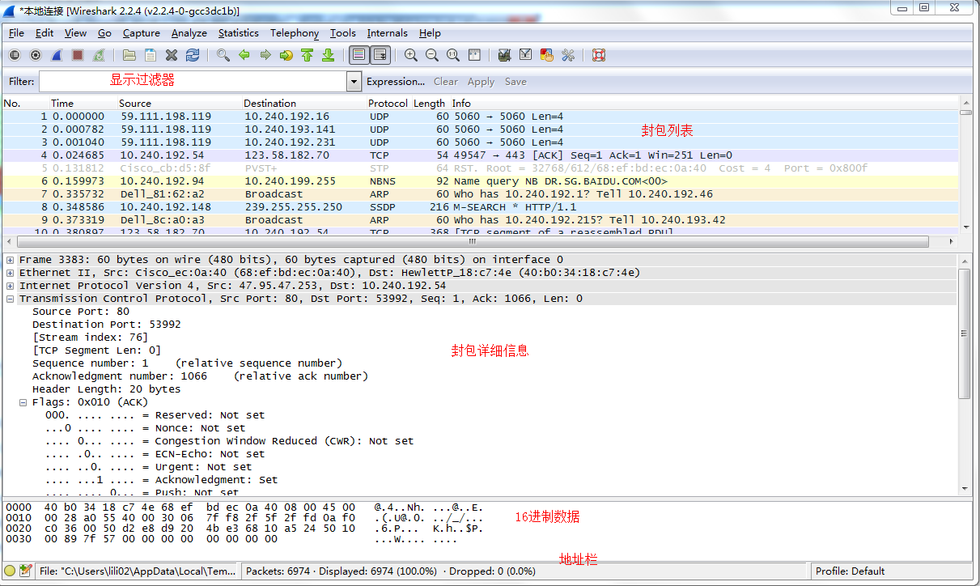
**封包詳細信息是用來查看協議中的每一個字段。**各行信息分別對應TCP/IP協議的不同層級。以下圖為例,分別表示:傳輸層、網絡層、數據鏈路層、物理層,一共四層。如果有應用層數據會顯示第五層,即一共會出現五層。

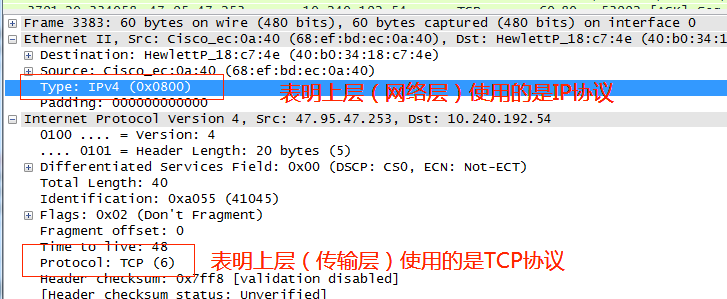
每一層都有一個字段指向上一層,表明上一層是什么協議。這大概是因為發包的時候會在數據上依次加上應用層、傳輸層、網絡層、鏈路層的頭部,但是對方收到數據包后是從最底層(鏈路層)開始層層剝去頭部解包的,所以在每層上有一個字段指向上層,表明上層的協議,對方就知道下一步該怎么解包了。以TCP/IP協議為例,下圖中分別是:IPv4、TCP。由于建立TCP連接用不到應用層協議,所以傳輸層就沒有相應的指明上層(應用層)的字段了。
在了解Wireshark界面后,我們來分析TCP協議。這里有很多數據包,我們需要先過濾,添加對應的過濾條件。比如,添加了目標的ip地址和端口號:tcp and ip.addr47.95.47.253 and tcp.port53992,此時獲取到的封包列表如下。
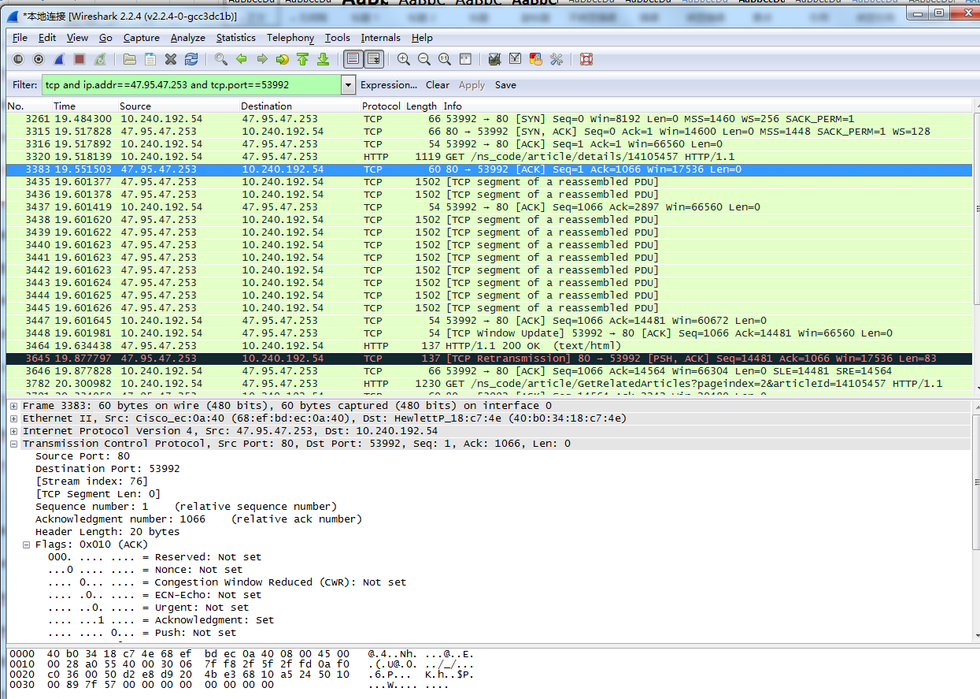
在此之前,看下TCP/IP報文的格式。

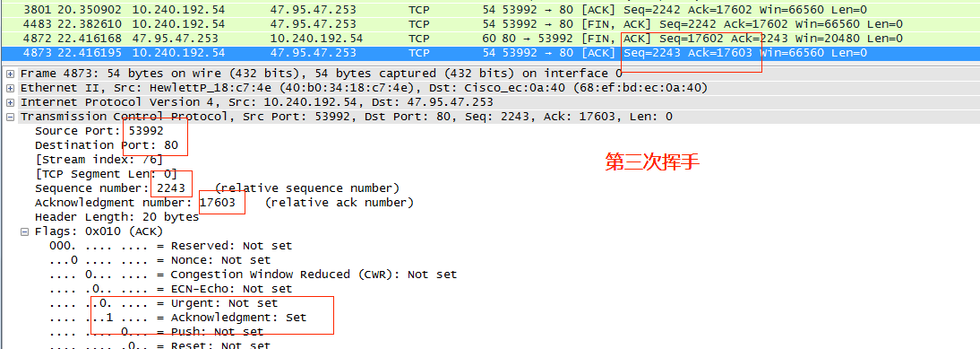
根據上述報文格式我們可以將wireshark捕獲到的TCP包中的每個字段與之對應起來,更直觀地感受一下TCP通信過程。先看三次握手,下圖中的3條數據包就是一次TCP建立連接的過程。

第一次握手,客戶端發送一個TCP,標志位為SYN=1,序號seq為Sequence number=0, 53992 -> 80,代表客戶端請求建立連接;
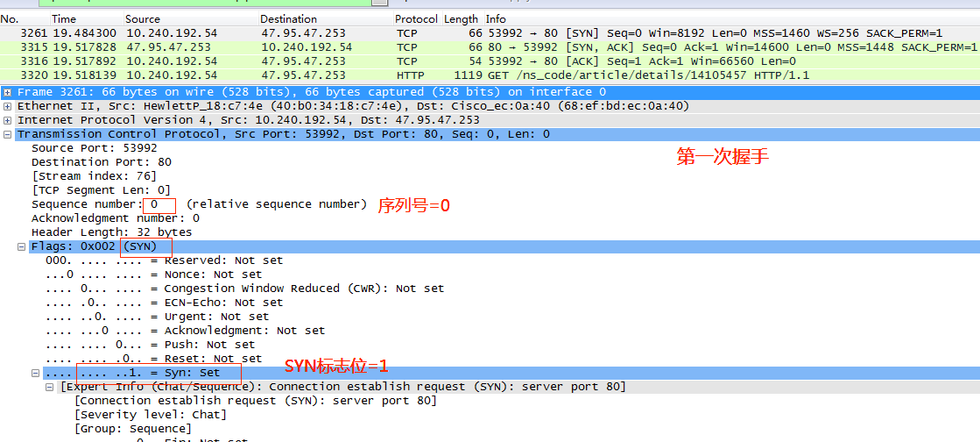
第二次握手,服務器向客戶端返回一個數據包,SYN=1,ACK=1,80 -> 53992,將確認序號(Acknowledgement Number)設置為客戶的序號seq(Sequence number)加1,即0+1=1;
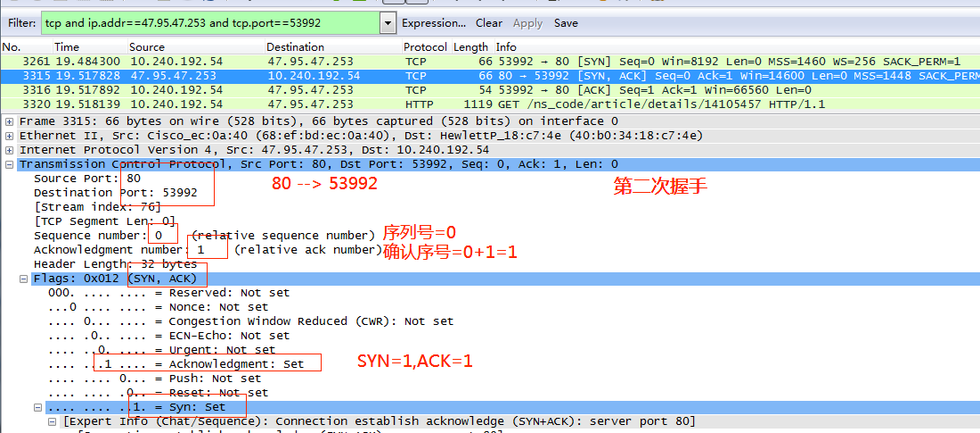
第三次握手,客戶端收到服務器發來的包后檢查確認序號(Acknowledgement Number)是否正確,即第一次發送的序號seq加1(X+1= 0+1=1)。以及標志位ACK是否為1。若正確,客戶端會再向服務器端發送一個數據包,SYN=0,ACK=1,確認序號(Acknowledgement Number)=Y+1=0+1=1,并且把服務器發來ACK的序號seq(Sequence number)加1發送給對方,發送序號seq為X+1= 0+1=1。客戶端收到后確認序號值與ACK=1,53992 -> 80,至此,一次TCP連接就此建立,可以傳送數據了。
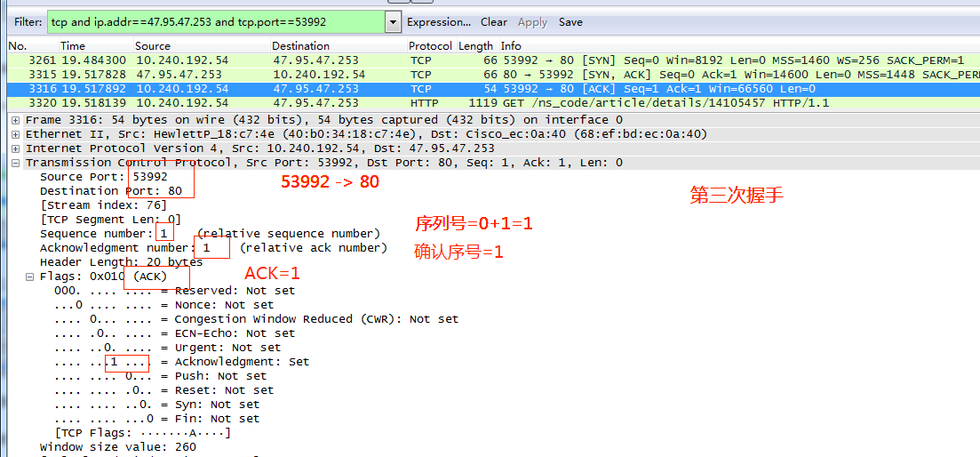
還可以通過直接看標志位查看三次握手的數據包,如下圖所示,第一個數據包標志位【SYN】,這是第一次握手;第二個數據包標志位【SYN,ACK】,這是第二次握手;第三個數據包標志位【ACK】,這是第三次握手。

在三次握手的三個數據包之后,第四個包才是HTTP的, 這說明HTTP的確是使用TCP建立連接的。

再往下看其他數據包,會發現存在大量的TCP segment of a reassembled PDU,字面意思是要重組的協議數據單元(PDU:Protocol Data Unit)的TCP段,這是TCP層收到上層大塊報文后分解成段后發出去。
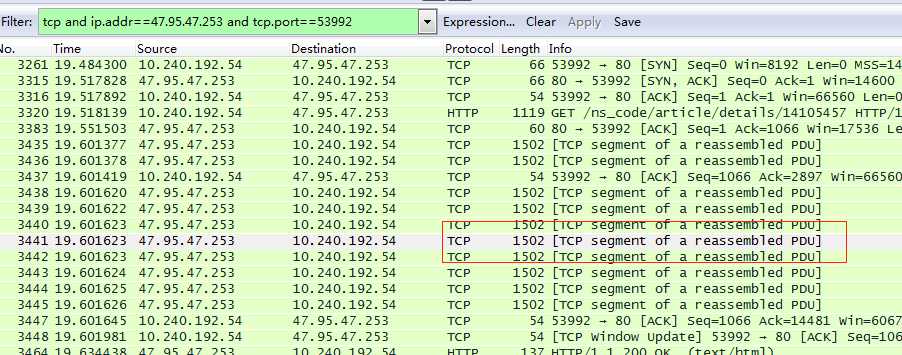
每個數據包的Protocol Length都是1502 Byte,這是因為以太網幀的封包格式為:Frame = Ethernet Header + IP Header + TCP Header + TCP Segment Data。即:
(1)Ethernet Header = 14 Byte = Dst Physical Address(6 Byte)+ Src Physical Address(6 Byte)+ Type(2 Byte),以太網幀頭以下稱之為數據幀。
(2)IP Header = 20 Byte(without options field),數據在IP層稱為Datagram,分片稱為Fragment。
(3)TCP Header = 20 Byte(without options field),數據在TCP層稱為Stream,分段稱為Segment(UDP中稱為Message)。
(4)TCP Segment Data = 1448 Byte(從下圖可見)。
所以,每個數據包的Protocol Length = 14 Byte + 20 Byte + 20 Byte + 1448 Byte = 1502 Byte。
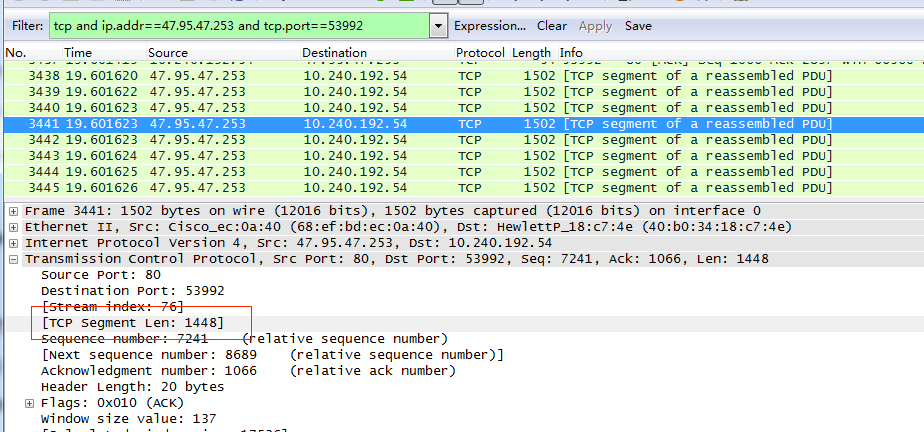
我們再來看四次揮手。TCP斷開連接時,會有四次揮手過程,標志位是FIN,我們在封包列表中找到對應位置,理論上應該找到4個數據包,但我試了好幾次,實際只抓到3個數據包。查了相關資料,說是因為服務器端在給客戶端傳回的過程中,將兩個連續發送的包進行了合并。因此下面會按照合并后的三次揮手解釋。

**第一次揮手:**客戶端給服務器發送TCP包,用來關閉客戶端到服務器的數據傳送。將標志位FIN和ACK置為1,序號seq=X=2242,確認序號ack=Z=17602,53992 -> 80;
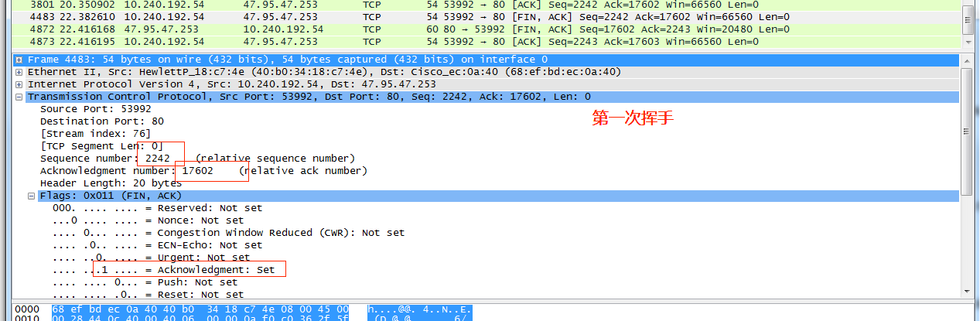
**第二次揮手:**服務器收到FIN后,服務器關閉與客戶端的連接,發回一個FIN和ACK(標志位FIN=1,ACK=1),確認序號ack為收到的序號加1,即X=X+1=2243。序號seq為收到的確認序號=Z=17602,80 -> 53992;
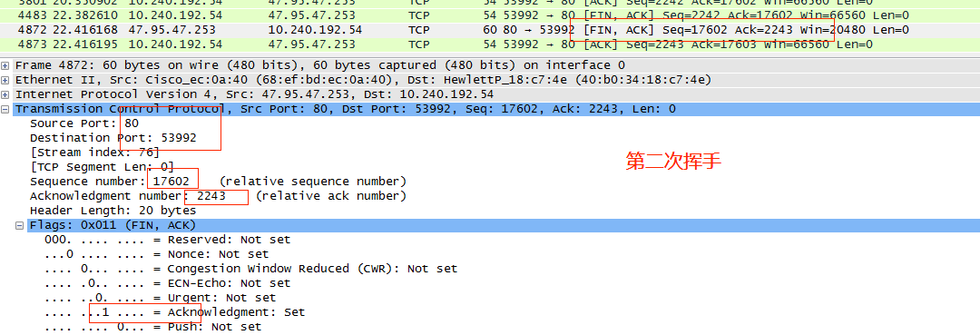
**第三次揮手:**客戶端收到服務器發送的FIN之后,發回ACK確認(標志位ACK=1),確認序號為收到的序號加1,即Y+1=17603。序號為收到的確認序號X=2243,53992 -> 80。
至此,整個TCP通信過程已經介紹完畢。
1.15 介紹一下tcp粘包、拆包的機制。
參考回答
-
TCP粘包和拆包問題
TCP是一個“流”協議,所謂流,就是沒有界限的一長串二進制數據。TCP作為傳輸層協議并不了解上層業務數據的具體含義,它會根據TCP緩沖區的實際情況進行數據包的劃分,所以在業務上認為是一個完整的包,可能會被TCP拆分成多個包進行發送,也有可能把多個小的包封裝成一個大的數據包發送,這就是所謂的TCP粘包和拆包問題。
-
產生TCP粘包和拆包的原因
我們知道TCP是以流動的方式傳輸數據的,傳輸的最小單位為一個報文段(Segment)。TCP Header中有個Options標識位。常見的標識位為MSS(Maximum Segment Size)指的是,連接層每次傳輸的數據有個最大限制MTU(Maximum Transmission Unit),一般是1500bit,超過這個量要分成多個報文段,MSS則是這個最大限制減去TCP的header,光是要傳輸的數據的大小,一般為1460bit。換算成字節,也就是180多字節。
TCP為提高性能,發送端會將需要發送的數據發送到緩沖區,等待緩沖區滿了以后,再將緩沖中的數據發送到接收方。同理,接收方也有緩沖區這樣的機制來接受數據。發生TCP粘包、拆包主要是以下原因:
(1)應用程序寫入數據大于套接字緩沖區大小,會發生拆包;(2)應用程序寫入數據小于套接字緩沖區大小,網卡將應用多次寫入的數據發送到網絡上,這將會發送粘包;(3)進行MSS(最大報文長度)大小的TCP分段,當TCP報文長度——TCP header長度>MSS 的時候會發生拆包;(4)接收方法不及時讀取套接字緩沖區數據,這將發生粘包。 -
如何處理粘包和拆包
假設應用層協議是http
我從瀏覽器中訪問了一個網站,網站服務器給我發了200k的數據。建立連接的時候,通告的MSS是50k,所以為了防止ip層分片,tcp每次只會發送50k的數據,一共發了4個tcp數據包。如果我又訪問了另一個網站,這個網站給我發了100k的數據,這次tcp會發出2個包,問題是,客戶端收到6個包,怎么知道前4個包是一個頁面,后兩個是一個頁面。既然是tcp將這些包分開了,那tcp會將這些包重組嗎,它送給應用層的是什么?這是我自己想的一個場景,正式一點講的話,這個現象叫拆包。
我們再考慮一個問題。
tcp中有一個negal算法,用途是這樣的:通信兩端有很多小的數據包要發送,雖然傳送的數據很少,但是流程一點沒少,也需要tcp的各種確認,校驗。這樣小的數據包如果很多,會造成網絡資源很大的浪費,negal算法做了這樣一件事,當來了一個很小的數據包,我不急于發送這個包,而是等來了更多的包,將這些小包組合成大包之后一并發送,不就提高了網絡傳輸的效率的嘛。這個想法收到了很好的效果,但是我們想一下,如果是分屬于兩個不同頁面的包,被合并在了一起,那客戶那邊如何區分它們呢?這就是粘包問題。
從粘包問題我們更可以看出為什么tcp被稱為流協議,因為它就跟水流一樣,是沒有邊界的,沒有消息的邊界保護機制,所以tcp只有流的概念,沒有包的概念。
我們還需要有兩個概念:
(1)長連接: Client方與Server方先建立通訊連接,連接建立后不斷開, 然后再進行報文發送和接收。
? (2)短連接:Client方與Server每進行一次報文收發交易時才進行通訊連接,交易完畢后立即斷開連接。此種方式常用于一點對多點 通訊,比如多個Client連接一個Server。實際,我想象的關于粘包的場景是不對的,http連接是短連接,請求之后,收到回答,立馬斷開連接,不會出現粘包。 拆包現象是有可能存在的。
處理拆包這里提供兩種方法:
(1)通過包頭+包長+包體的協議形式,當服務器端獲取到指定的包長時才說明獲取完整。
? (2) 指定包的結束標識,這樣當我們獲取到指定的標識時,說明包獲取完整。處理粘包我們從上面的分析看到,雖然像http這樣的短連接協議不會出現粘包的現象,但是一旦建立了長連接,粘包還是有可能會發生的。處理粘包的方法如下:
(1)發送方對于發送方造成的粘包問題,可以通過關閉Nagle算法來解決,使用TCP_NODELAY選項來關閉算法。
(2)接收方沒有辦法來處理粘包現象,只能將問題交給應用層來處理。應用層的解決辦法簡單可行,不僅能解決接收方的粘包問題,還可以解決發送方的粘包問題。解決辦法:循環處理,應用程序從接收緩存中讀取分組時,讀完一條數據,就應該循環讀取下一條數據,直到所有數據都被處理完成,判斷每條數據的長度的方法有兩種:
a. 格式化數據:每條數據有固定的格式(開始符,結束符),這種方法簡單易行,但是選擇開始符和結束符時一定要確保每條數據的內部不包含開始符和結束符。
b. 發送長度:發送每條數據時,將數據的長度一并發送,例如規定數據的前4位是數據的長度,應用層在處理時可以根據長度來判斷每個分組的開始和結束位置。
答案解析
擴展資料
UDP會不會產生粘包問題呢?
TCP為了保證可靠傳輸并減少額外的開銷(每次發包都要驗證),采用了基于流的傳輸,基于流的傳輸不認為消息是一條一條的,是無保護消息邊界的(保護消息邊界:指傳輸協議把數據當做一條獨立的消息在網上傳輸,接收端一次只能接受一條獨立的消息)。UDP則是面向消息傳輸的,是有保護消息邊界的,接收方一次只接受一條獨立的信息,所以不存在粘包問題。
舉個例子:有三個數據包,大小分別為2k、4k、6k,如果采用UDP發送的話,不管接受方的接收緩存有多大,我們必須要進行至少三次以上的發送才能把數據包發送完,但是使用TCP協議發送的話,我們只需要接受方的接收緩存有12k的大小,就可以一次把這3個數據包全部發送完畢。
1.16 介紹一下TCP和UDP的區別。
參考回答
TCP和UDP有如下區別:
- 連接:TCP面向連接的傳輸層協議,即傳輸數據之前必須先建立好連接;UDP無連接。
- 服務對象:TCP點對點的兩點間服務,即一條TCP連接只能有兩個端點;UDP支持一對一,一對多,多對一,多對多的交互通信。
- 可靠性:TCP可靠交付:無差錯,不丟失,不重復,按序到達;UDP盡最大努力交付,不保證可靠交付。
- 擁塞控制/流量控制:有擁塞控制和流量控制保證數據傳輸的安全性;UDP沒有擁塞控制,網絡擁塞不會影響源主機的發送效率。
- 報文長度:TCP動態報文長度,即TCP報文長度是根據接收方的窗口大小和當前網絡擁塞情況決定的;UDP面向報文,不合并,不拆分,保留上面傳下來報文的邊界。
- 首部開銷:TCP首部開銷大,首部20個字節;UDP首部開銷小,8字節(源端口,目的端口,數據長度,校驗和)。
- 適用場景(由特性決定):數據完整性需讓位于通信實時性,則應該選用TCP 協議(如文件傳輸、重要狀態的更新等);反之,則使用 UDP 協議(如視頻傳輸、實時通信等)。
1.17 TCP和UDP對于網絡穩定性有什么要求?
參考回答
-
TCP優缺點
優點:可靠、穩定
TCP的可靠體現在TCP在傳輸數據之前,會有三次握手來建立連接,而且在數據傳遞時,有確認、窗口、重傳、擁塞控制機制,在數據傳完之后,還會斷開連接用來節約系統資源。
缺點:慢,效率低,占用系統資源高,易被攻擊
在傳遞數據之前要先建立連接,這會消耗時間,而且在數據傳遞時,確認機制、重傳機制、擁塞機制等都會消耗大量時間,而且要在每臺設備上維護所有的傳輸連接。然而,每個鏈接都會占用系統的CPU、內存等硬件資源。因為TCP有確認機制、三次握手機制,這些也導致TCP容易被利用,實現DOS、DDOS、CC等攻擊。
-
UDP優缺點
優點:快,比TCP稍安全
UDP沒有TCP擁有的各種機制,是一個無狀態的傳輸協議,所以傳遞數據非常快,沒有TCP的這些機制,被攻擊利用的機制就少一些,但是也無法避免被攻擊。
缺點:不可靠,不穩定
因為沒有TCP的那些機制,UDP在傳輸數據時,如果網絡質量不好,就會很容易丟包,造成數據的缺失。
-
適用場景(網絡穩定性要求)
TCP:當對網絡通訊質量有要求時,比如HTTP、HTTPS、FTP等傳輸文件的協議, POP、SMTP等郵件傳輸的協議
UDP:對網絡通訊質量要求不高時,要求網絡通訊速度要快的場景。
所以,TCP對網絡穩定性要求高,而UDP相對弱一些。
1.18 如何讓UDP可靠一些?
參考回答
-
為什么需要可靠的UDP
在弱網(2G、3G、信號不好)環境下,使用 TCP 連接的延遲很高,影響體驗。使用 UDP 是很好的解決方案,既然把 UDP 作為弱網里面的 TCP 來使用,就必須保證數據傳輸能像 TCP 一樣可靠
-
如何實現可靠的UDP
UDP它不屬于連接型協議,因而具有資源消耗小,處理速度快的優點,所以通常音頻、視頻和普通數據在傳送時使用UDP較多,因為它們即使偶爾丟失一兩個數據包,也不會對接收結果產生太大影響。傳輸層無法保證數據的可靠傳輸,只能通過應用層來實現了。實現的方式可以參照tcp可靠性傳輸的方式,只是實現不在傳輸層,實現轉移到了應用層。關鍵在于兩點,從應用層角度考慮:
(1)提供超時重傳,能避免數據報丟失。
(2)提供確認序列號,可以對數據報進行確認和排序。
本端:首先在UDP數據報定義一個首部,首部包含確認序列號和時間戳,時間戳是用來計算RTT(數據報傳輸的往返時間),計算出合適的RTO(重傳的超時時間)。然后以等-停的方式發送數據報,即收到對端的確認之后才發送下一個的數據報。當時間超時,本端重傳數據報,同時RTO擴大為原來的兩倍,重新開始計時。
對端:接受到一個數據報之后取下該數據報首部的時間戳和確認序列號,并添加本端的確認數據報首部之后發送給對端。根據此序列號對已收到的數據報進行排序并丟棄重復的數據報。
答案解析
擴展資料
- 已經實現的可靠UDP:
(1)RUDP 可靠數據報傳輸協議;
(2)RTP 實時傳輸協議
為數據提供了具有實時特征的端對端傳送服務;
Eg:組播或單播網絡服務下的交互式視頻、音頻或模擬數據
(3)UDT
基于UDP的數據傳輸協議,是一種互聯網傳輸協議;
主要目的是支持高速廣域網上的海量數據傳輸,引入了新的擁塞控制和數據可靠性控制機制(互聯網上的標準數據傳輸協議TCP在高帶寬長距離的網絡上性能很差);
UDT是面向連接的雙向的應用層協議,同時支持可靠的數據流傳輸和部分可靠的數據報服務;
應用:高速數據傳輸,點到點技術(P2P),防火墻穿透,多媒體數據傳輸;
1.19 TCP報文首部中序號占多少字節?
參考回答
序號字段占4個字節(32位)。
答案解析
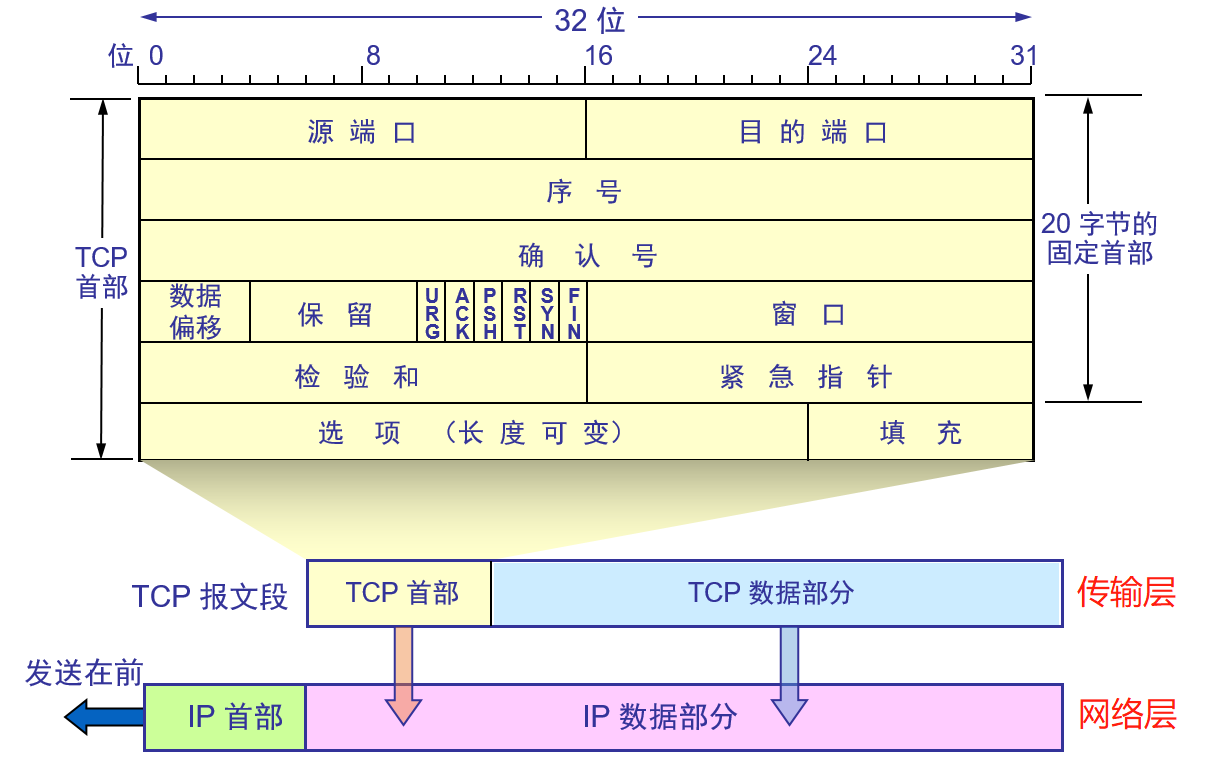
TCP首部字段詳細圖
TCP首部包括20字節的固定首部部分及長度可變的其他選項,所以TCP首部長度可變。20個字節又分為5部分,每部分4個字節32位,如圖中的5行,每行表示32位。
-
源端口和目的端口字段——各占 2 字節(16位)。端口是運輸層與應用層的服務接口。運輸層的復用和分用功能都要通過端口才能實現。
-
序號字段——占 4 字節。TCP 連接中傳送的數據流中的每一個字節都編上一個序號。序號字段的值則**指的是本報文段所發送的數據的第一個字節的序號。**比如分組的第一個數據包由文件的14個字節數據組成,那么該數據包所添加的序號就是1,同理第二個數據包由文件的59個字節數據組成,那么該數據包所添加的序號就是5;
-
確認號字段——占 4 字節,是期望收到對方的下一個報文段的數據的第一個字節的序號。比如接收端收到由文件14個字節數據+TCP首部組成的數據包后,刪除首部提取14個字節數據,返回的確認號為5,即告訴發送端下一次應該發送文件的第5個字節及其之后字節組成的數據包過來。
-
數據偏移(即首部長度)——占 4 位,它指出 TCP 報文段的數據起始處距離 TCP 報文段的起始處有多遠,也就是TCP首部的長度。“數據偏移”的單位是 32 位字(以 4 字節為計算單位),最大1111表示15x4=60個字節,即表示TCP首部最大長度為60個字節,因此“選項”部分最多40個字節。
-
保留字段——占 6 位,保留為今后使用,但目前應置為 0。
-
這里的六位二進制位,分別表示不同含義:
(1)緊急 URG —— 當 URG = 1 時,表明緊急指針字段有效。它告訴系統此報文段中有緊急數據,應盡快傳送(相當于高優先級的數據)。 即URG=1的數據包不用排隊直接優先傳輸。
(2)同步 SYN —— 同步 SYN = 1 表示這是一個連接請求或連接接受報文。即A想與B建立連接,發送過去的第一個數據包(第一次握手)中SYN=1;B返回的數據包(第二次握手)中SYN=1表示同意建立連接。
(3)確認 ACK —— 只有當 ACK = 1 時確認號字段才有效。當 ACK = 0 時,確認號無效。
-
窗口字段 —— 占 2 字節,用來讓對方設置發送窗口的依據,單位為字節。
-
檢驗和 —— 占 2 字節。檢驗和字段檢驗的范圍包括首部和數據這兩部分。在計算檢驗和時,要在 TCP 報文段的前面加上 12 字節的偽首部。
-
緊急指針字段 —— 占 16 位,指出在本報文段中緊急數據共有多少個字節(緊急數據放在本報文段數據的最前面)。
-
選項字段 —— 長度可變。TCP 最初只規定了一種選項,即最大報文段長度 MSS (Maximum Segment Size)是 TCP 報文段中的數據字段的最大長度。數據字段加上 TCP 首部才等于整個的 TCP 報文段。MSS 告訴對方 TCP:“我的緩存所能接收的報文段的數據字段的最大長度是 MSS 個字節。”其他選項有:窗口擴大選項、時間戳選項、選擇確認選項(SACK)。
-
填充字段 —— 這是為了使整個首部長度是 4 字節的整數倍。
1.20 TCP中的緩存有什么作用?
參考回答
-
TCP緩沖區是什么
每個 socket 被創建后,都會分配兩個緩沖區,輸入緩沖區和輸出緩沖區。
-
緩沖區的意義(作用)
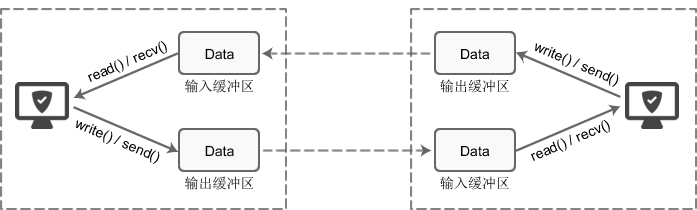
TCP套接字的I/O緩沖區示意圖
TCP的發送緩沖區是用來緩存應用程序的數據,發送緩沖區的每個字節都有序列號,被應答確認的序列號對應的數據會從發送緩沖區刪除掉。
write()/send() 并不立即向網絡中傳輸數據,而是先將數據寫入緩沖區中,再由TCP協議將數據從緩沖區發送到目標機器。一旦將數據寫入到緩沖區,函數就可以成功返回,不管它們有沒有到達目標機器,也不管它們何時被發送到網絡,這些都是TCP協議負責的事情。
? TCP協議獨立于 write()/send() 函數,數據有可能剛被寫入緩沖區就發送到網絡,也可能在緩沖區中不斷積壓,多次寫入的數據被一次性發送到網絡,比如nagle算法,這取決于當時的網絡情況、當前線程是否空閑等諸多因素,不由程序員控制。
? read()/recv() 函數也是如此,也從輸入緩沖區中讀取數據,而不是直接從網絡中讀取。 -
I/O緩沖區特性
(1)I/O緩沖區在每個TCP套接字中單獨存在;
(2)I/O緩沖區在創建套接字時自動生成;
(3)即使關閉套接字也會繼續傳送輸出緩沖區中遺留的數據;
(4)關閉套接字將丟失輸入緩沖區中的數據。
輸入輸出緩沖區的默認大小一般都是 8K,可以通過 getsockopt() 函數獲取:
//代碼實例(緩沖區大小獲取) int servSock = socket(PF_INET, SOCK_STREAM, 0); unsigned optVal; int optLen = sizeof(int); getsockopt(servSock, SOL_SOCKET, SO_SNDBUF, (char*)&optVal, &optLen); /*運行結果:Buffer length: 8192 */
1.21 說一說TCP是怎么控制流量的?
參考回答
-
所謂流量控制就是讓發送發送速率不要過快,讓接收方來得及接收。
-
TCP控制流量的方法
利用滑動窗口機制就可以實施流量控制。
原理就是運用TCP報文段中的窗口大小字段來控制,發送方的發送窗口不可以大于接收方發回的窗口大小。考慮一種特殊的情況,就是接收方若沒有緩存足夠使用,就會發送零窗口大小的報文,此時發送放將發送窗口設置為0,停止發送數據。之后接收方有足夠的緩存,發送了非零窗口大小的報文,但是這個報文在中途丟失的,那么發送方的發送窗口就一直為零導致死鎖。
解決這個問題,TCP為每一個連接設置一個持續計時器(persistence timer)。只要TCP的一方收到對方的零窗口通知,就啟動該計時器,周期性的發送一個零窗口探測報文段。對方就在確認這個報文的時候給出現在的窗口大小(注意:TCP規定,即使設置為零窗口,也必須接收以下幾種報文段:零窗口探測報文段、確認報文段和攜帶緊急數據的報文段)。
答案解析
-
TCP的滑動窗口
為了提高信道的利用率TCP協議不使用停止等待協議,而是使用連續ARQ協議,意思就是可以連續發出若干個分組然后等待確認,而不是發送一個分組就停止并等待該分組的確認。
TCP的兩端都有發送/接收緩存和發送/接收窗口。TCP的緩存是一個循環隊列,其中發送窗口可以用3個指針表示。而發送窗口的大小受TCP數據報中窗口大小的影響,TCP數據報中的窗口大小是接收端通知發送端其還可以接收多少數據,所以發送窗口根據接收的的窗口大小的值動態變化。
以下的幾張圖片就幫助理解一下滑動窗口的機制:
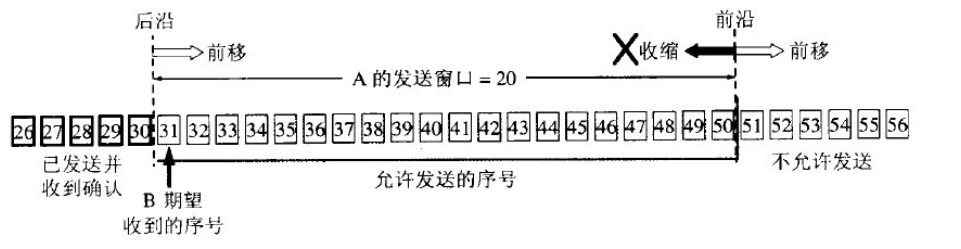
圖1 根據B給出的窗口值,A構造出自己的發送窗口
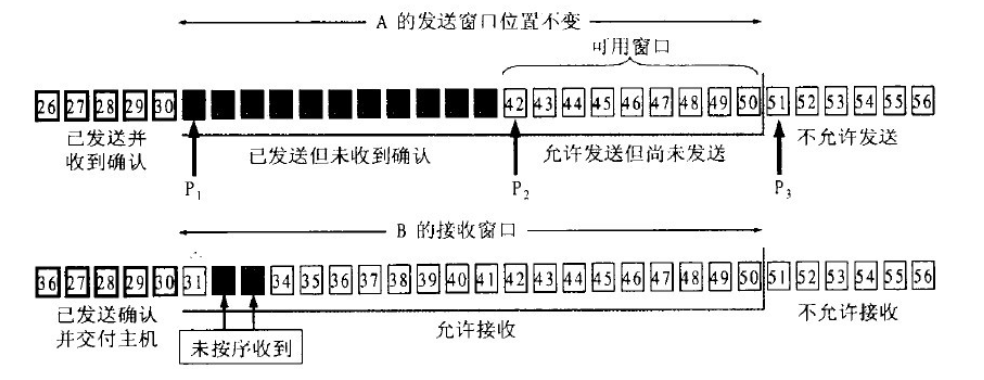
圖2 A發送了11個字節的數據
注意上圖中的3個指針P1、P2、P3!此時接收窗口中接收的數據可能是失序的,但是也先存儲在接收緩存之中。發送確認號的時候依然發送31,表示B期望接收的下一個數據報的標示符是31。
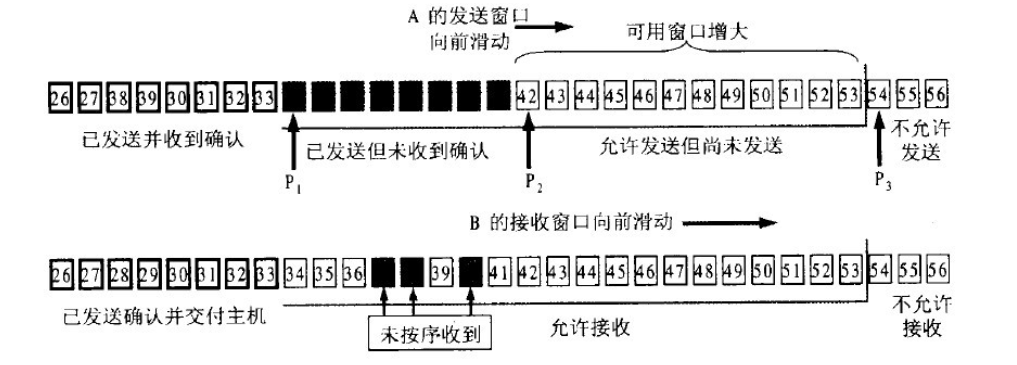
圖3 A收到新的確認號,發送窗口向前滑動
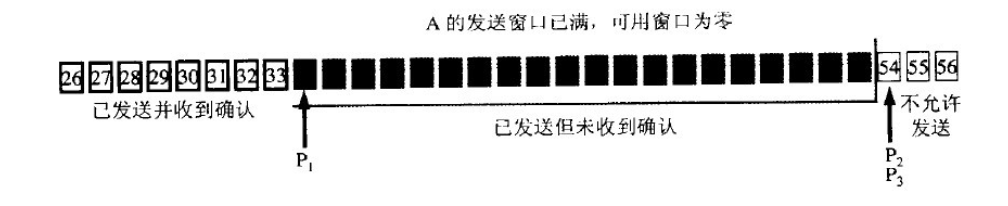
圖4 發送窗口內的序號都屬于已經發送但未被確認
如果發送窗口中的數據報都屬于已發送但未被確認的話,那么A就不能再繼續發送數據,而需要進行等待。
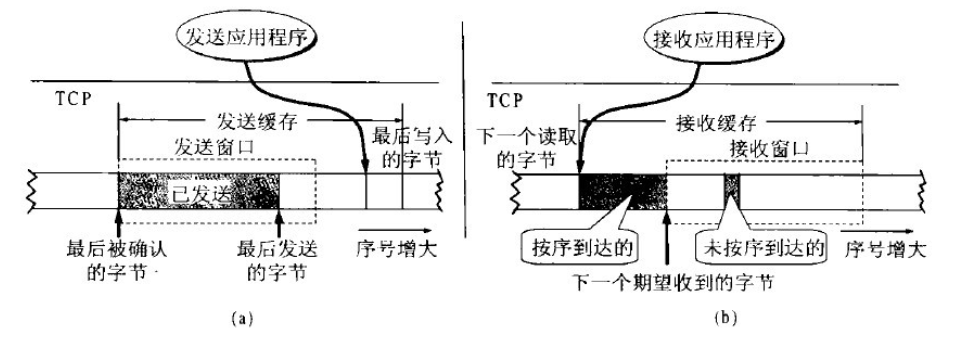
圖5 TCP的發送緩存和發送窗口(a)與接收緩存和接收窗口(b)
-
傳輸效率及Nagle算法
TCP的數據傳輸分為交互數據流和成塊數據流,交互數據流一般是一些交互式應用程序的命令,所以這些數據很小,而考慮到TCP報頭和IP報頭的總和就有40字節,如果數據量很小的話,那么網絡的利用效率就較低。
數據傳輸使用Nagle算法,Nagle算法很簡單,就是規定一個TCP連接最多只能有一個未被確認的未完成的小分組。在該分組的確認到達之前不能發送其他的小分組。
但是也要考慮另一個問題,叫做糊涂窗口綜合癥。當接收方的緩存已滿的時候,交互應用程序一次只從緩存中讀取一個字節(這時候緩存中騰出一個字節),然后向發送方發送確認信息,此時發送方再發送一個字節(收到的窗口大小為1),這樣網絡的效率很低。
要解決這個問題,可以讓接收方等待一段時間,使得接收緩存已有最夠的空間容納一個最長報文段,或者等到接收緩存已有一半的空間。只要這兩種情況出現一種,就發送確認報文,同時發送方可以把數據積累成大的報文段發送。
1.22 HTTP2.0中TCP阻塞了怎么辦?
參考回答
HTTP2.0中TCP阻塞了有如下兩種方法可以解決:
(1)并發TCP連接(瀏覽器一個域名采用6-8個TCP連接,并發HTTP請求)
? (2)域名分片(多個域名,可以建立更多的TCP連接,從而提高HTTP請求的并發)
答案解析
1. TCP隊頭阻塞
TCP數據包是有序傳輸,中間一個數據包丟失,會等待該數據包重傳,造成后面的數據包的阻塞。
2. HTTP隊頭阻塞
http隊頭阻塞和TCP隊頭阻塞完全不是一回事。
http1.x采用長連接(Connection:keep-alive),可以在一個TCP請求上,發送多個http請求。
有非管道化和管道化,兩種方式。
非管道化,完全串行執行,請求->響應->請求->響應…,后一個請求必須在前一個響應之后發送。
管道化,請求可以并行發出,但是響應必須串行返回。后一個響應必須在前一個響應之后。原因是,沒有序號標明順序,只能串行接收。
管道化請求的致命弱點:
(1)會造成隊頭阻塞,前一個響應未及時返回,后面的響應被阻塞
? (2)請求必須是冪等請求,不能修改資源。因為,意外中斷時候,客戶端需要把未收到響應的請求重發,非冪等請求,會造成資源破壞。
由于這個原因,目前大部分瀏覽器和Web服務器,都關閉了管道化,采用非管道化模式。
無論是非管道化還是管道化,都會造成隊頭阻塞(請求阻塞)。
解決http隊頭阻塞的方法:
(1)并發TCP連接(瀏覽器一個域名采用6-8個TCP連接,并發HTTP請求)
? (2)域名分片(多個域名,可以建立更多的TCP連接,從而提高HTTP請求的并發)
2. HTTP2方式
http2使用一個域名單一TCP連接發送請求,請求包被二進制分幀,不同請求可以互相穿插,避免了http層面的請求隊頭阻塞。
? 但是不能避免TCP層面的隊頭阻塞。
1.23 TCP如何保證可靠性?
參考回答
TCP協議保證數據傳輸可靠性的方式主要有:校驗和、序列號、確認應答、超時重傳、連接管理、流量控制、擁塞控制。
-
校驗和
**計算方式:**在數據傳輸的過程中,將發送的數據段都當做一個16位的整數。將這些整數加起來。并且前面的進位不能丟棄,補在后面,最后取反,得到校驗和。
**發送方:**在發送數據之前計算檢驗和,并進行校驗和的填充。
**接收方:**收到數據后,對數據以同樣的方式進行計算,求出校驗和,與發送方的進行比對。**

**注意:**如果接收方比對校驗和與發送方不一致,那么數據一定傳輸有誤。但是如果接收方比對校驗和與發送方一致,數據不一定傳輸成功。
-
序列號和確認應答
**序列號:**TCP傳輸時將每個字節的數據都進行了編號,這就是序列號。
**確認應答:**TCP傳輸的過程中,每次接收方收到數據后,都會對傳輸方進行確認應答。也就是發送ACK報文。這個ACK報文當中帶有對應的確認序列號,告訴發送方,接收到了哪些數據,下一次的數據從哪里發。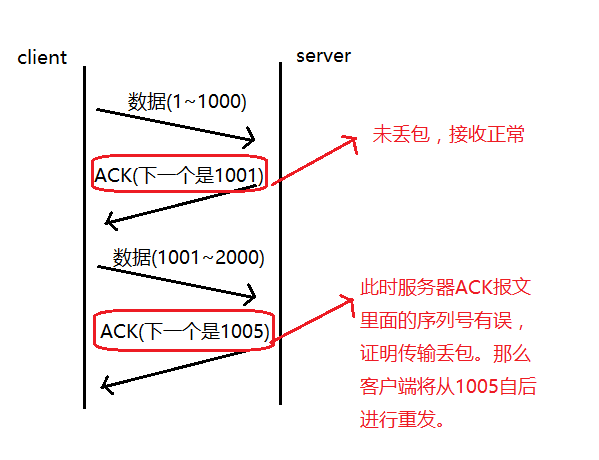
序列號的作用不僅僅是應答的作用,有了序列號能夠將接收到的數據根據序列號排序,并且去掉重復序列號的數據。這也是TCP傳輸可靠性的保證之一。
-
超時重傳
在進行TCP傳輸時,由于確認應答與序列號機制,也就是說發送方發送一部分數據后,都會等待接收方發送的ACK報文,并解析ACK報文,判斷數據是否傳輸成功。如果發送方發送完數據后,遲遲沒有等到接收方的ACK報文,這該怎么辦呢?而沒有收到ACK報文的原因可能是什么呢?
首先,發送方沒有接收到響應的ACK報文原因可能有兩點:
(1)數據在傳輸過程中由于網絡原因等直接全體丟包,接收方根本沒有接收到。
(2)接收方接收到了響應的數據,但是發送的ACK報文響應卻由于網絡原因丟包了。
TCP在解決這個問題的時候引入了一個新的機制,叫做超時重傳機制。**簡單理解就是發送方在發送完數據后等待一個時間,時間到達沒有接收到ACK報文,那么對剛才發送的數據進行重新發送。**如果是剛才第一個原因,接收方收到二次重發的數據后,便進行ACK應答。如果是第二個原因,接收方發現接收的數據已存在(判斷存在的根據就是序列號,所以上面說序列號還有去除重復數據的作用),那么直接丟棄,仍舊發送ACK應答。
-
連接管理
連接管理就是三次握手與四次揮手的過程,保證可靠的連接,是保證可靠性的前提。
-
流量控制
收端在接收到數據后,對其進行處理。如果發送端的發送速度太快,導致接收端的結束緩沖區很快的填充滿了。此時如果發送端仍舊發送數據,那么接下來發送的數據都會丟包,繼而導致丟包的一系列連鎖反應,超時重傳呀什么的。而TCP根據接收端對數據的處理能力,決定發送端的發送速度,這個機制就是流量控制。
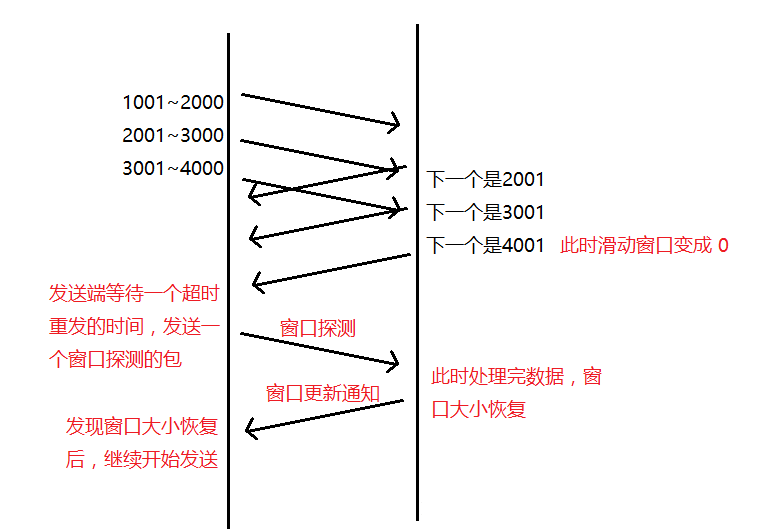
在TCP協議的報頭信息當中,有一個16位字段的窗口大小。在介紹這個窗口大小時我們知道,窗口大小的內容實際上是接收端接收數據緩沖區的剩余大小。這個數字越大,證明接收端接收緩沖區的剩余空間越大,網絡的吞吐量越大。接收端會在確認應答發送ACK報文時,將自己的即時窗口大小填入,并跟隨ACK報文一起發送過去。而發送方根據ACK報文里的窗口大小的值的改變進而改變自己的發送速度。如果接收到窗口大小的值為0,那么發送方將停止發送數據。并定期的向接收端發送窗口探測數據段,讓接收端把窗口大小告訴發送端。
-
擁塞控制
TCP傳輸的過程中,發送端開始發送數據的時候,如果剛開始就發送大量的數據,那么就可能造成一些問題。網絡可能在開始的時候就很擁堵,如果給網絡中在扔出大量數據,那么這個擁堵就會加劇。擁堵的加劇就會產生大量的丟包,就對大量的超時重傳,嚴重影響傳輸。
所以TCP引入了慢啟動的機制,在開始發送數據時,先發送少量的數據探路。探清當前的網絡狀態如何,再決定多大的速度進行傳輸。這時候就引入一個叫做擁塞窗口的概念。發送剛開始定義擁塞窗口為 1,每次收到ACK應答,擁塞窗口加 1。在發送數據之前,首先將擁塞窗口與接收端反饋的窗口大小比對,取較小的值作為實際發送的窗口。
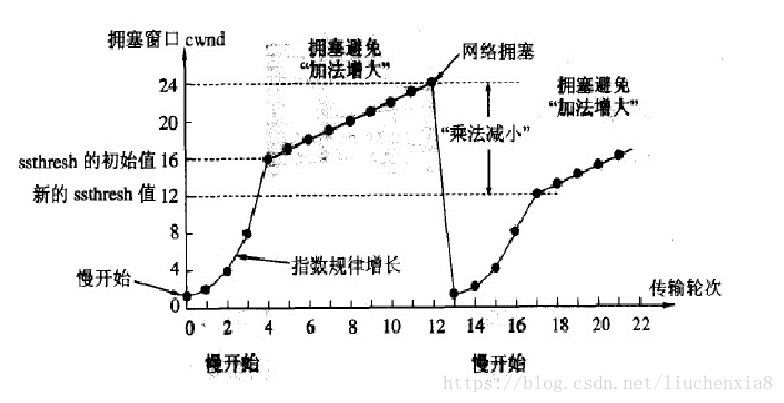
擁塞窗口的增長是指數級別的。慢啟動的機制只是說明在開始的時候發送的少,發送的慢,但是增長的速度是非常快的。為了控制擁塞窗口的增長,不能使擁塞窗口單純的加倍,設置一個擁塞窗口的閾值,當擁塞窗口大小超過閾值時,不能再按照指數來增長,而是線性的增長。在慢啟動開始的時候,慢啟動的閾值等于窗口的最大值,一旦造成網絡擁塞,發生超時重傳時,慢啟動的閾值會為原來的一半(這里的原來指的是發生網絡擁塞時擁塞窗口的大小),同時擁塞窗口重置為 1。
擁塞控制是TCP在傳輸時盡可能快的將數據傳輸,并且避免擁塞造成的一系列問題。是可靠性的保證,同時也是維護了傳輸的高效性。
答案解析
無
1.24 說一說TCP里的reset狀態。
參考回答
-
TCP異常終止(reset報文)
TCP的異常終止是相對于正常釋放TCP連接的過程而言的,我們都知道,TCP連接的建立是通過三次握手完成的,而TCP正常釋放連接是通過四次揮手來完成,但是有些情況下,TCP在交互的過程中會出現一些意想不到的情況,導致TCP無法按照正常的四次揮手來釋放連接,如果此時不通過其他的方式來釋放TCP連接的話,這個TCP連接將會一直存在,占用系統的部分資源。在這種情況下,我們就需要有一種能夠釋放TCP連接的機制,這種機制就是TCP的reset報文。reset報文是指TCP報頭的標志字段中的reset位置一的報文。
-
RST標志位(Reset)
RST表示復位,用來異常的關閉連接,在TCP的設計中它是不可或缺的。就像上面說的一樣,發送RST包關閉連接時,不必等緩沖區的包都發出去(不像上面的FIN包),直接就丟棄緩存區的包發送RST包。而接收端收到RST包后,也不必發送ACK包來確認。
TCP處理程序會在自己認為的異常時刻發送RST包。例如,A向B發起連接,但B之上并未監聽相應的端口,這時B操作系統上的TCP處理程序會發RST包。
又比如,AB正常建立連接了,正在通訊時,A向B發送了FIN包要求關連接,B發送ACK后,網斷了,A通過若干原因放棄了這個連接(例如進程重啟)。網通了后,B又開始發數據包,A收到后表示壓力很大,不知道這野連接哪來的,就發了個RST包強制把連接關了,B收到后會出現connect reset by peer錯誤。
答案解析
-
TCP異常終止的常見情形
(1)客戶端嘗試與服務器未對外提供服務的端口建立TCP連接,服務器將會直接向客戶端發送reset報文。
(2)客戶端和服務器的某一方在交互的過程中發生異常(如程序崩潰等),該方系統將向對端發送TCP reset報文,告之對方釋放相關的TCP連接。
(3)接收端收到TCP報文,但是發現該TCP的報文,并不在其已建立的TCP連接列表內,則其直接向對端發送reset報文。
(4)在交互的雙方中的某一方長期未收到來自對方的確認報文,則其在超出一定的重傳次數或時間后,會主動向對端發送reset報文釋放該TCP連接。
(5)有些應用開發者在設計應用系統時,會利用reset報文快速釋放已經完成數據交互的TCP連接,以提高業務交互的效率。
1.25 如何利用UDP實現可靠傳輸?
參考回答
-
實現方法:
(1)將實現放到應用層,然后類似于TCP,實現確認機制、重傳機制和窗口確認機制;
(2)給數據包進行編號,按順序接收并存儲,接收端收到數據包后發送確認信息給發送端,發送端接收到確認信息后繼續發送,若接收端接收的數據不是期望的順序編號,則要求重發;(主要解決丟包和包無序的問題)
-
已經實現的可靠UDP:
(1)RUDP 可靠數據報傳輸協議;
(2)RTP 實時傳輸協議
為數據提供了具有實時特征的端對端傳送服務;例如:組播或單播網絡服務下的交互式視頻、音頻或模擬數據。
(3)UDT
基于UDP的數據傳輸協議,是一種互聯網傳輸協議; 主要目的是支持高速廣域網上的海量數據傳輸,引入了新的擁塞控制和數據可靠性控制機制(互聯網上的標準數據傳輸協議TCP在高帶寬長距離的網絡上性能很差);
UDT是面向連接的雙向的應用層協議,同時支持可靠的數據流傳輸和部分可靠的數據報服務;
應用:高速數據傳輸,點到點技術(P2P),防火墻穿透,多媒體數據傳輸;
答案解析
無
1.26 報文亂序怎么辦?
參考回答
數據包會因為IP層所規劃的路由鏈路的不同導致數據包的接收順序與發送順序會有所不同。另外因為TCP是一種全雙工的協議,亂序可能發生在正向鏈路,也可能發生在反向鏈路,這兩種不同的情況給TCP帶來的影響也會略有差異。
-
正向鏈路亂序
此時TCP會無法判斷是數據包丟失還是亂序,因為丟包和亂序都會導致接收端收到次序混亂的數據包,造成接收端的數據空洞。TCP會將這種情況暫定為數據包的亂序,因為亂序是時間問題(可能是數據包的遲到),而丟包則意味著重傳。當TCP意識到包出現亂序的情況時,會立即ACK,該ACK的TSER部分包含的TSEV值會記錄當前接收端收到有序報文段的時刻。這會使得數據包的RTT樣本值增大,進一步導致RTO時間延長。這對TCP來說無疑是有益的,因為TCP有充分的時間判斷數據包到底是失序還是丟了來防止不必要的數據重傳。當然嚴重的亂序則會讓發送端以為是丟包一旦重復的ACK超過TCP的閾值,便會觸發超時重傳機制,以及時解決這種問題。
-
反向鏈路(ACK)亂序
顧名思義,如果發生這種情況,就會導致發送端窗口快速前移,這會導致發送端出現不必要的流量突發,影響網絡帶寬。
答案解析
無
1.27 說一說你對IP分類的了解。
參考回答
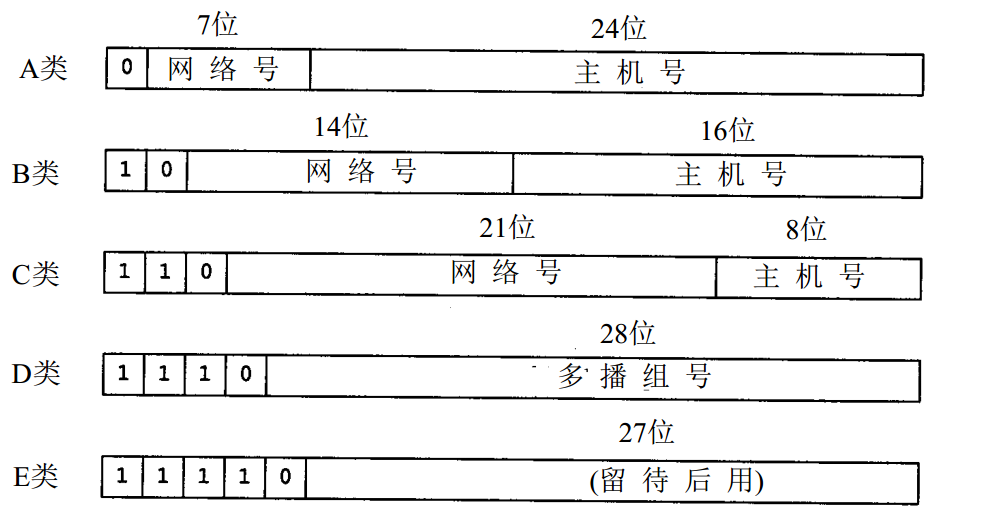
五類互聯網地址
IP地址根據網絡號和主機號來分,分為A、B、C三類及特殊地址D、E。 全0和全1的都保留不用。
- A類:(1.0.0.0-126.0.0.0)(默認子網掩碼:255.0.0.0或 0xFF000000)第一個字節為網絡號,后三個字節為主機號。該類IP地址的最前面為“0”,所以地址的網絡號取值于1~126之間。一般用于大型網絡。
- B類:(128.0.0.0-191.255.0.0)(默認子網掩碼:255.255.0.0或0xFFFF0000)前兩個字節為網絡號,后兩個字節為主機號。該類IP地址的最前面為“10”,所以地址的網絡號取值于128~191之間。一般用于中等規模網絡。
- C類:(192.0.0.0-223.255.255.0)(子網掩碼:255.255.255.0或 0xFFFFFF00)前三個字節為網絡號,最后一個字節為主機號。該類IP地址的最前面為“110”,所以地址的網絡號取值于192~223之間。一般用于小型網絡。
- D類:是多播地址。該類IP地址的最前面為“1110”,所以地址的網絡號取值于224~239之間。一般用于多路廣播用戶 。
- E類:是保留地址。該類IP地址的最前面為“1111”,所以地址的網絡號取值于240~255之間。
1.28 IP為什么要分類?
參考回答
根據IP地址訪問終端是通過路由器,路由設備當中有一張路由表,該路由表記錄了所有IP地址的位置,這樣就可以進行包的轉發了,如果我們不區分網絡地址,那么這張路由表當中就要保存有所有IP地址的方向,這張路由表就會很大,就像下面說的那樣:如果不分網絡位和主機位,路由器的路由表就是都是32位的地址,那所有的路由器維護的路由表會很大,轉發速度會變慢(因為查詢變慢)。而且所有的路由器都要有全Internet的地址,所有人的路由器都要有足夠的性能來存下全網地址。估計建造這樣的Internet成本是現在的幾萬倍,甚至更高。
有了網絡地址,就可以限定擁有相同網絡地址的終端都在同一個范圍內,那么路由表只需要維護這個網絡地址的方向,就可以找到相應的終端了。
1.29 IPV4和IPV6有什么區別?
參考回答
IPv4和IPv6是是目前使用的兩種Internet協議版本,IPv4和IPv6協議之間存在各種差異,包括它們的功能,但關鍵的一點是它生成的地址(地址空間)的數量的區別。
-
協議地址的區別
(1)地址長度
IPv4協議具有32位(4字節)地址長度;IPv6協議具有128位(16字節)地址長度。
(2)地址的表示方法
IPv4地址是以小數表示的二進制數。 IPv6地址是以十六進制表示的二進制數。
(3)地址配置
IPv4協議的地址可以通過手動或DHCP配置的。
IPv4協議需要使用Internet控制消息協議版本6(ICMPv6)或DHCPv6的無狀態地址自動配置(SLAAC)。
-
數據包的區別
(1)包的大小
IPv4協議的數據包需要576個字節,碎片可選 ;IPv6協議的數據包需要1280個字節,不會碎片。
(2)包頭
IPv4協議的包頭的長度為20個字節,不識別用于QoS處理的數據包流,包含checksum,包含最多40個字節的選項字段。
IPv6協議的包頭的長度為40個字節,包含指定QoS處理的數據包流的Flow Label字段,不包含checksum;IPv6協議沒有字段,但IPv6擴展標頭可用。
(3)數據包碎片
IPv4協議的數據包碎片會由轉發路由器和發送主機完成。IPv6協議的數據包碎片僅由發送主機完成。
-
DNS記錄
IPv4協議的地址(A)記錄,映射主機名;指針(PTR)記錄,IN-ADDR.ARPA DNS域。
IPv6協議的地址(AAAA)記錄,映射主機名;指針(PTR)記錄,IP6.ARPA DNS域
-
IPSec支持
IPv4協議的IPSec支持只是可選的;IPv6協議有內置的IPSec支持。
-
地址解析協議
IPv4協議:地址解析協議(ARP)可用于將IPv4地址映射到MAC地址。
IPv6協議:地址解析協議(ARP)被鄰居發現協議(NDP)的功能所取代。
-
身份驗證和加密
Pv6提供身份驗證和加密;但IPv4不提供。
答案解析
無
1.30 說一下http和https的區別。
參考回答
https和https主要存在以下的區別:
- HTTPS 協議需要到 CA (Certificate Authority,證書頒發機構)申請證書,一般免費證書較少,因而需要一定費用。(以前的網易官網是http,而網易郵箱是 https 。)
- HTTP 是超文本傳輸協議,信息是明文傳輸,HTTPS 則是具有安全性的 SSL 加密傳輸協議。
- HTTP 和 HTTPS 使用的是完全不同的連接方式,用的端口也不一樣,前者是80,后者是443。
- HTTP 的連接很簡單,是無狀態的。HTTPS 協議是由 SSL+HTTP 協議構建的可進行加密傳輸、身份認證的網絡協議,比 HTTP 協議安全。(無狀態的意思是其數據包的發送、傳輸和接收都是相互獨立的。無連接的意思是指通信雙方都不長久的維持對方的任何信息。)
答案解析
-
超文本傳輸協議(HTTP,HyperText Transfer Protocol)是互聯網上應用最為廣泛的一種網絡協議。設計 HTTP 最初的目的是為了提供一種發布和接收 HTML 頁面的方法。它可以使瀏覽器更加高效。HTTP 協議是以明文方式發送信息的,如果黑客截取了 Web 瀏覽器和服務器之間的傳輸報文,就可以直接獲得其中的信息。
-
HTTP原理
(1)客戶端的瀏覽器首先要通過網絡與服務器建立連接,該連接是通過 TCP 來完成的,一般 TCP 連接的端口號是80。 建立連接后,客戶機發送一個請求給服務器,請求方式的格式為:統一資源標識符(URL)、協議版本號,后邊是 MIME 信息包括請求修飾符、客戶機信息和許可內容。
(2)服務器接到請求后,給予相應的響應信息,其格式為一個狀態行,包括信息的協議版本號、一個成功或錯誤的代碼,后邊是 MIME 信息包括服務器信息、實體信息和可能的內容。
-
HTTPS(Hyper Text Transfer Protocol over SecureSocket Layer)是以安全為目標的 HTTP 通道,是 HTTP 的安全版。HTTPS 的安全基礎是 SSL。SSL 協議位于 TCP/IP 協議與各種應用層協議之間,為數據通訊提供安全支持。SSL 協議可分為兩層:SSL 記錄協議(SSL Record Protocol),它建立在可靠的傳輸協議(如TCP)之上,為高層協議提供數據封裝、壓縮、加密等基本功能的支持。SSL 握手協議(SSL Handshake Protocol),它建立在 SSL 記錄協議之上,用于在實際的數據傳輸開始前,通訊雙方進行身份認證、協商加密算法、交換加密密鑰等。
-
HTTPS的工作原理
我們都知道HTTPS能夠加密信息,以免敏感信息被第三方獲取,所以很多銀行網站或電子郵箱等等安全級別較高的服務都會采用HTTPS協議。
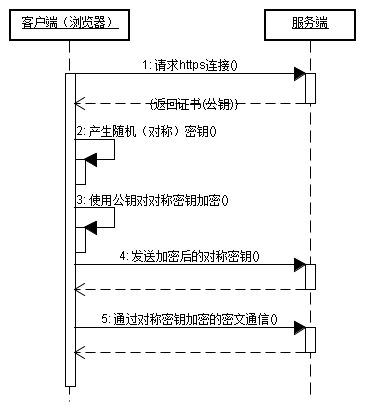
客戶端在使用HTTPS方式與Web服務器通信時有以下幾個步驟,如圖上圖所示:
(1)客戶使用https的URL訪問Web服務器,要求與Web服務器建立SSL連接。
(2)Web服務器收到客戶端請求后,會將網站的證書信息(證書中包含公鑰)傳送一份給客戶端。
(3)客戶端的瀏覽器與Web服務器開始協商SSL連接的安全等級,也就是信息加密的等級。
(4)客戶端的瀏覽器根據雙方同意的安全等級,建立會話密鑰,然后利用網站的公鑰將會話密鑰加密,并傳送給網站。
(5)Web服務器利用自己的私鑰解密出會話密鑰。
(6)Web服務器利用會話密鑰加密與客戶端之間的通信。
-
HTTPS的優點
盡管HTTPS并非絕對安全,掌握根證書的機構、掌握加密算法的組織同樣可以進行中間人形式的攻擊,但HTTPS仍是現行架構下最安全的解決方案,主要有以下幾個好處:
(1)使用HTTPS協議可認證用戶和服務器,確保數據發送到正確的客戶機和服務器;
(2)HTTPS協議是由SSL+HTTP協議構建的可進行加密傳輸、身份認證的網絡協議,要比http協議安全,可防止數據在傳輸過程中不被竊取、改變,確保數據的完整性。
(3)HTTPS是現行架構下最安全的解決方案,雖然不是絕對安全,但它大幅增加了中間人攻擊的成本。
(4)谷歌曾在2014年8月份調整搜索引擎算法,并稱“比起同等HTTP網站,采用HTTPS加密的網站在搜索結果中的排名將會更高”。
-
HTTPS的缺點
雖然說HTTPS有很大的優勢,但其相對來說,還是存在不足之處的:
(1)HTTPS協議握手階段比較費時,會使頁面的加載時間延長近50%,增加10%到20%的耗電;
(2)HTTPS連接緩存不如HTTP高效,會增加數據開銷和功耗,甚至已有的安全措施也會因此而受到影響;
(3)SSL證書需要錢,功能越強大的證書費用越高,個人網站、小網站沒有必要一般不會用。
(4)SSL證書通常需要綁定IP,不能在同一IP上綁定多個域名,IPv4資源不可能支撐這個消耗。
(5)HTTPS協議的加密范圍也比較有限,在黑客攻擊、拒絕服務攻擊、服務器劫持等方面幾乎起不到什么作用。最關鍵的,SSL證書的信用鏈體系并不安全,特別是在某些國家可以控制CA根證書的情況下,中間人攻擊一樣可行。
1.31 https為什么采用混合加密機制?
參考回答
一方面,第一階段的非對稱加密,保證了對稱密鑰的安全性;另一方面,第二階段的對稱加密,可以提高加密/解密處理的速度,提高數據傳輸的效率。
答案解析
-
為什么需要加密?
因為http的內容是明文傳輸的,明文數據會經過中間代理服務器、路由器、wifi熱點、通信服務運營商等多個物理節點,如果信息在傳輸過程中被劫持,傳輸的內容就完全暴露了,他還可以篡改傳輸的信息且不被雙方察覺,這就是中間人攻擊。所以我們才需要對信息進行加密。最簡單容易理解的就是對稱加密。
-
什么是對稱加密?
就是有一個密鑰,它可以對一段內容加密,加密后只能用它才能解密看到原本的內容,和我們日常生活中用的鑰匙作用差不多。
-
用對稱加密可行嗎?
如果通信雙方都各自持有同一個密鑰,且沒有別人知道,這兩方的通信安全當然是可以被保證的(除非密鑰被破解)。然而最大的問題就是這個密鑰怎么讓傳輸的雙方知曉,同時不被別人知道。如果由服務器生成一個密鑰并傳輸給瀏覽器,那這個傳輸過程中密鑰被別人劫持弄到手了怎么辦?之后他就能用密鑰解開雙方傳輸的任何內容了,所以這么做當然不行。
? 換種思路?試想一下,如果瀏覽器內部就預存了網站A的密鑰,且可以確保除了瀏覽器和網站A,不會有任何外人知道該密鑰,那理論上用對稱加密是可以的,這樣瀏覽器只要預存好世界上所有HTTPS網站的密鑰就行啦!這么做顯然不現實。
? 所以我們就需要神奇的非對稱加密。 -
什么是非對稱加密?
有兩把密鑰,通常一把叫做公鑰、一把叫做私鑰,用公鑰加密的內容必須用私鑰才能解開,同樣,私鑰加密的內容只有公鑰能解開。
-
用非對稱加密可行嗎?
鑒于非對稱加密的機制,我們可能會有這種思路:服務器先把公鑰直接明文傳輸給瀏覽器,之后瀏覽器向服務器傳數據前都先用這個公鑰加密好再傳,這條數據的安全似乎可以保障了!**因為只有服務器有相應的私鑰能解開這條數據**。`` ``然而**由服務器到瀏覽器的這條路怎么保障安全?**如果服務器用它的的私鑰加密數據傳給瀏覽器,那么瀏覽器用公鑰可以解密它,而這個公鑰是一開始通過明文傳輸給瀏覽器的,這個公鑰被誰劫持到的話,他也能用該公鑰解密服務器傳來的信息了。所以**目前似乎只能保證由瀏覽器向服務器傳輸數據時的安全性**(其實仍有漏洞,下文會說)。 -
混合加密
非對稱加密耗時,非對稱加密+對稱加密結合可以嗎?而且得盡量減少非對稱加密的次數。當然是可以的,而且非對稱加密、解密各只需用一次即可。以下就是加密過程:
(1)某網站擁有用于非對稱加密的公鑰A、私鑰A’。
(2)瀏覽器像網站服務器請求,服務器把公鑰A明文給傳輸瀏覽器。
(3)瀏覽器隨機生成一個用于對稱加密的密鑰X,用公鑰A加密后傳給服務器。
(4)服務器拿到后用私鑰A’解密得到密鑰X。
(5)這樣雙方就都擁有密鑰X了,且別人無法知道它。之后雙方所有數據都用密鑰X加密解密。
完美!HTTPS基本就是采用了這種方案。
1.32 https支持什么加密算法?
參考回答
常見的對稱加密算法有:DES、3DES、Blowfish、IDEA、RC4、RC5、RC6和AES ;
常見的非對稱加密算法有:RSA、ECC(移動設備用)、Diffie-Hellman、El Gamal、DSA(數字簽名用);
常見的Hash算法有:MD2、MD4、MD5、HAVAL、SHA;
答案解析
-
對稱加密技術
對稱加密采用了對稱密碼編碼技術,它的特點是文件加密和解密使用相同的密鑰加密。也就是密鑰也可以用作解密密鑰,這種方法在密碼學中叫做對稱加密算法,對稱加密算法使用起來簡單快捷,密鑰較短,且破譯困難,除了數據加密標準(DES),另一個對稱密鑰加密系統是國際數據加密算法(IDEA),它比DES的加密性好,而且對計算機功能要求也沒有那么高。對稱加密算法在電子商務交易過程中存在幾個問題:
(1)要求提供一條安全的渠道使通訊雙方在首次通訊時協商一個共同的密鑰。直接的面對面協商可能是不現實而且難于實施的,所以雙方可能需要借助于郵件和電話等其它相對不夠安全的手段來進行協商;
(2)密鑰的數目難于管理。因為對于每一個合作者都需要使用不同的密鑰,很難適應開放社會中大量的信息交流;
(3)對稱加密算法一般不能提供信息完整性的鑒別。它無法驗證發送者和接受者的身份;
(4)對稱密鑰的管理和分發工作是一件具有潛在危險的和煩瑣的過程。對稱加密是基于共同保守秘密來實現的,采用對稱加密技術的貿易雙方必須保證采用的是相同的密鑰,保證彼此密鑰的交換是安全可靠的,同時還要設定防止密鑰泄密和更改密鑰的程序。
假設兩個用戶需要使用對稱加密方法加密然后交換數據,則用戶最少需要2個密鑰并交換使用,如果企業內用戶有n個,則整個企業共需要n×(n-1) 個密鑰,密鑰的生成和分發將成為企業信息部門的惡夢。
常見的對稱加密算法有DES、3DES、Blowfish、IDEA、RC4、RC5、RC6和AES
-
非對稱加密技術
與對稱加密算法不同,非對稱加密算法需要兩個密鑰:公開密鑰(publickey)和私有密鑰(privatekey)。
公開密鑰與私有密鑰是一對,如果用公開密鑰對數據進行加密,只有用對應的私有密鑰才能解密;如果用私有密鑰對數據進行加密,那么只有用對應的公開密鑰才能解密。因為加密和解密使用的是兩個不同的密鑰,所以這種算法叫作非對稱加密算法。
非對稱加密算法實現機密信息交換的基本過程是:甲方生成一對密鑰并將其中的一把作為公用密鑰向其它方公開;得到該公用密鑰的乙方使用該密鑰對機密信息進行加密后再發送給甲方;甲方再用自己保存的另一把專用密鑰對加密后的信息進行解密。甲方只能用其專用密鑰解密由其公用密鑰加密后的任何信息。
非對稱加密的典型應用是數字簽名。
常見的非對稱加密算法有:RSA、ECC(移動設備用)、Diffie-Hellman、El Gamal、DSA(數字簽名用)
Hash算法(摘要算法)
-
Hash算法
Hash算法特別的地方在于它是一種單向算法,用戶可以通過hash算法對目標信息生成一段特定長度的唯一hash值,卻不能通過這個hash值重新獲得目標信息。因此Hash算法常用在不可還原的密碼存儲、信息完整性校驗等。
常見的Hash算法有MD2、MD4、MD5、HAVAL、SHA
1.33 說一說HTTPS的秘鑰交換過程。
參考回答
HTTPS的密鑰交換過程如下:
-
客戶端要訪問一個網站,向支持https的服務器發起請求。
-
客戶端向服務器發送自己支持的秘鑰交換算法列表。
-
服務器選取一種秘鑰交換算法加上CA證書返回給客戶端。
-
客戶端驗證服務器是否合法,并生成一個隨機數然后用協商好的加密算法加密生成隨機秘鑰,并用剛才從CA證書中拿到的公鑰對其加密后發送給服務器。
-
服務器收到后用自己的私鑰解密(中間人沒有服務器的私鑰,所以沒有辦法看到傳輸的數據,另外確認秘鑰交換算法是在第一步,中間人是不知道秘鑰交換算法(中間人是無法在第一步做手腳的,那等同于它自己就是一個真實客戶端發起了一個新的請求,唯一一種情況攻擊人有一個合法CA下發的證書,且客戶端(一般為安卓設備)沒有對CA下發的證書中的內容網站地址和當前請求地址做對比校驗),就算攻擊者有公鑰,因為不知道協商協議,所以做不出來隨機秘鑰,頂多就是在傳輸過程中將報文攔截下來,亂改,但是給到服務器后,私鑰是解不開亂改之后的密文的)。
-
服務器私鑰解密之后,拿到對稱秘鑰,并且用它再加密一個信息,返回給瀏覽器。
**注意:**最關鍵的一步就是在客戶端采用 RSA 或 Diffie-Hellman 等加密算法生成 Pre-master,這個隨機秘鑰是用來計算最終的對稱秘鑰的,用公鑰加密之后攻擊人是不知道這個這個隨機秘鑰的,只有服務器才能解的開。
1.34 說一說HTTPS的證書認證過程。
參考回答
HTTPS的證書認證過程如下:
-
瀏覽器將自己支持的一套加密規則發送給網站。
-
網站從中選出一組加密算法與HASH算法,并將自己的身份信息以證書的形式發回給瀏覽器。證書里面包含了網站地址,加密公鑰,以及證書的頒發機構等信息。
-
瀏覽器獲得網站證書之后瀏覽器要做以下工作:
(1) 驗證證書的合法性(頒發證書的機構是否合法,證書中包含的網站地址是否與正在訪問的地址一致等),如果證書受信任,則瀏覽器欄里面會顯示一個小鎖頭,否則會給出證書不受信的提示。
(2)如果證書受信任,或者是用戶接受了不受信的證書,瀏覽器會生成一串隨機數的密碼,并用證書中提供的公鑰加密。
(3)使用約定好的HASH算法計算握手消息,并使用生成的隨機數對消息進行加密,最后將之前生成的所有信息發送給網站。 -
網站接收瀏覽器發來的數據之后要做以下的操作:
(1) 使用自己的私鑰將信息解密取出密碼,使用密碼解密瀏覽器發來的握手消息,并驗證HASH是否與瀏覽器發來的一致。
(2) 使用密碼加密一段握手消息,發送給瀏覽器。 -
瀏覽器解密并計算握手消息的HASH,如果與服務端發來的HASH一致,此時握手過程結束,之后所有的通信數據將由之前瀏覽器生成的隨機密碼并利用對稱加密算法進行加密。
1.35 HTTP請求頭中包含什么內容?
參考回答
HTTP請求頭中包含如下三個內容:
User-Agent:產生請求的瀏覽器類型。
Accept:客戶端可識別的內容類型列表。
Host:主機地址。
答案解析
-
請求報文(請求行/請求頭/請求數據/空行)
(1) 請求行
求方法字段、URL字段和HTTP協議版本
例如:GET /index.html HTTP/1.1
get方法將數據拼接在url后面,傳遞參數受限
請求方法:
GET、POST、HEAD、PUT、DELETE、OPTIONS、TRACE、CONNECT
(2) 請求頭(key value形式)
User-Agent:產生請求的瀏覽器類型。
Accept:客戶端可識別的內容類型列表。
Host:主機地址
(3) 請求數據
post方法中,會把數據以key value形式發送請求
(4) 空行
發送回車符和換行符,通知服務器以下不再有請求頭
-
響應報文(狀態行、消息報頭、響應正文)
狀態行
消息報頭
響應正文
1.36 HTTP是基于TCP還是UDP?
參考回答
HTTP是基于TCP的。
HTTP協議是建立在請求/響應模型上的。首先由客戶建立一條與服務器的TCP鏈接,并發送一個請求到服務器,請求中包含請求方法、URI、協議版本以及 相關的MIME樣式的消息。服務器響應一個狀態行,包含消息的協議版本、一個成功和失敗碼以及相關的MIME式樣的消息。
? HTTP/1.0為每一次HTTP的請求/響應建立一條新的TCP鏈接,因此一個包含HTML內容和圖片的頁面將需要建立多次的短期的TCP鏈接。一次TCP鏈接的建立將需要3次握手。
? 另 外,為了獲得適當的傳輸速度,則需要TCP花費額外的回路鏈接時間(RTT)。每一次鏈接的建立需要這種經常性的開銷,而其并不帶有實際有用的數據,只是 保證鏈接的可靠性,因此HTTP/1.1提出了可持續鏈接的實現方法。HTTP/1.1將只建立一次TCP的鏈接而重復地使用它傳輸一系列的請求/響應消 息,因此減少了鏈接建立的次數和經常性的鏈接開銷。
答案解析
無
1.37 HTTP1.1和HTTP2.0有什么區別?
參考回答
-
HTTP2.0使用了多路復用的技術,做到同一個連接并發處理多個請求,而且并發請求的數量比HTTP1.1大了好幾個數量級。HTTP1.1也可以多建立幾個TCP連接,來支持處理更多并發的請求,但是創建TCP連接本身也是有開銷的。
-
在HTTP1.1中,HTTP請求和響應都是由狀態行、請求/響應頭部、消息主體三部分組成。一般而言,消息主體都會經過gzip壓縮,或者本身傳輸的就是壓縮過后的二進制文件,但狀態行和頭部卻沒有經過任何壓縮,直接以純文本傳輸。隨著Web功能越來越復雜,每個頁面產生的請求數也越來越多,導致消耗在頭部的流量越來越多,尤其是每次都要傳輸UserAgent、Cookie這類不會頻繁變動的內容,完全是一種浪費。 HTTP1.1不支持header數據的壓縮,HTTP2.0使用HPACK算法對header的數據進行壓縮,這樣數據體積小了,在網絡上傳輸就會更快。
-
服務端推送是一種在客戶端請求之前發送數據的機制。網頁使用了許多資源:HTML、樣式表、腳本、圖片等等。在HTTP1.1中這些資源每一個都必須明確地請求。這是一個很慢的過程。瀏覽器從獲取HTML開始,然后在它解析和評估頁面的時候,增量地獲取更多的資源。因為服務器必須等待瀏覽器做每一個請求,網絡經常是空閑的和未充分使用的。
為了改善延遲,HTTP2.0引入了server push,它允許服務端推送資源給瀏覽器,在瀏覽器明確地請求之前,免得客戶端再次創建連接發送請求到服務器端獲取。這樣客戶端可以直接從本地加載這些資源,不用再通過網絡。
答案解析
無
1.38 HTTP2.0和HTTP3.0有什么區別?
參考回答
HTTP2.0和HTTP3.0的區別在于前者使用tcp協議而后者使用udp協議。
答案解析
http發展歷程:從http0.9 到 http3.0
-
HTTP0.9
最簡單的只有請求行 GET index.html
-
HTTP1.0
(1)增加請求頭、響應頭,讓請求和相應都更清晰
(2)增加狀態碼,讓響應更清晰
(3)增加緩存功能,已請求過的內容再次請求時就可直接使用緩存
GET index.html HTTP/1.0
accept: application/html
accept-charset: utf-8
accept-encoding: gzip
accept-language: zh-CN
HTTP/1.0 200 OK
<!DOCTYPE html>
<html>
<head></head>
<body>hello world!</body>
</html>
a. accept 解決文件格式問題,是json還是html,瀏覽器根據不同文件格式來解析文件;
b. accept-charset 解決文件編碼問題,告知瀏覽器如何將字符流解析成字節流;
c. accept-encoding 解決大文件壓縮問題,瀏覽器采用指定的解壓方式來解壓;
d. accept-language 解決國際化問題,不同國家請求不同語言的文件。
-
HTTP1.1
(1)持久連接,多個http請求使用同一個tcp連接,減少了tcp建立連接時的開銷
(2)客戶端和服務器之間可以建立多個tcp連接以解決隊頭阻塞的問題
(3)響應體可以分塊傳輸,無需一次傳輸全部內容
(4)響應頭增加content-length字段滿足動態內容無法一次計算出長度和無法一次傳輸完成的問題
(5)增加了安全機制和cookie機制
-
HTTP2.0
多路復用,客戶端和服務器之間只建立一條tcp,每個http請求被切分成多幀,多個http的幀混合在一起在一個tcp連接上傳送 -
HTTP3.0
不再使用tcp協議,因為tcp依然是順序發送,順序接收的,依然有隊頭堵塞問題,干掉tcp才能解決隊頭堵塞問題。google的QUIC就使用了udp協議。
1.39 談談HTTP的緩存機制,服務器如何判斷當前緩存過期?
參考回答
-
HTTP報文
在瀏覽器和服務器進行Http通信時發送的數據即為Http報文,其中分為兩部分:
(1)header - 報文的首部或頭部,其中保存著各類請求的屬性字段,關于Http的緩存相關規則信息均保存在header中;
(2)body - 請求體部分,Http請求真正傳輸的主體部分。
-
首次請求基本規則
HTTP緩存主要涉及三個角色:一是瀏覽器,二是瀏覽器的緩存數據庫,三是服務器。當瀏覽器端向服務器發出第一次請求時的流程圖如下圖所示(瀏覽器再次執行同一的請求時,根據不同的緩存類型將會執行不同的行為):
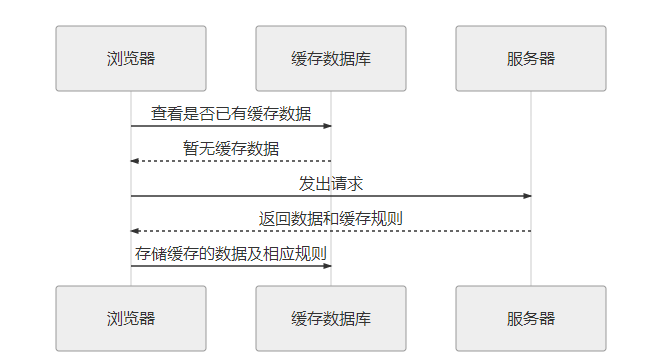
瀏覽器向服務器發出第一次請求后執行流程
-
緩存的類型
HTTP緩存主要分為兩種:強緩存和協商緩存。
? 兩種緩存分別通過HTTP報文頭部不同的字段進行控制。 -
服務器如何判斷當前緩存過期
(1)強緩存
強緩存基本原理是:所請求的數據在緩存數據庫中尚未過期時,不與服務器進行交互,直接使用緩存數據庫中的數據。當緩存未命中時,則重新向服務器請求數據,其基本流程分別如下:
當緩存未過期:
當緩存未命中(基本流程與首次請求時相似):
控制強緩存過期時間的主要有兩個規則字段,如下圖:
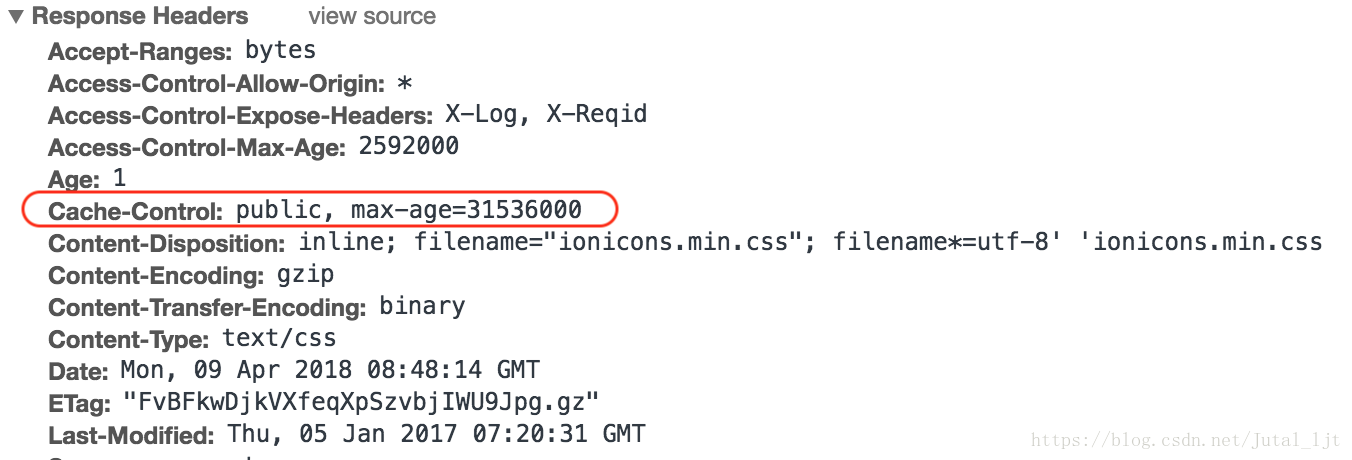
Expire: 其指定了一個日期/時間, 在這個日期/時間之后,HTTP響應被認為是過時的。但是它本身是一個HTTP1.0標準下的字段,所以如果請求中還有一個置了 “max-age” 或者 “s-max-age” 指令的Cache-Control響應頭,那么 Expires 頭就會被忽略。
? **Cache-Control:**通用消息頭用于在http 請求和響應中通過指定指令來實現緩存機制。其常用的幾個取值有:
? private:客戶端可以緩存
? public:客戶端和代理服務器都可以緩存
? max-age=xxx:緩存的內容將在xxx 秒后失效
? s-max-age=xxx:同s-max-age,但僅適用于共享緩存(比如各個代理),并且私有緩存中忽略。
? no-cache:需要使用協商緩存來驗證緩存數據
? no-store:所有內容都不會緩存,強緩存和協商緩存都不會觸發
? must-revalidate:緩存必須在使用之前驗證舊資源的狀態,并且不可使用過期資源。(2)協商緩存
當強緩存過期未命中或者響應報文Cache-Control中有must-revalidate標識必須每次請求驗證資源的狀態時,便使用協商緩存的方式去處理緩存文件。
? 協商緩存主要原理是:從緩存數據庫中取出緩存的標識,然后向瀏覽器發送請求驗證請求的數據是否已經更新,如果已更新則返回新的數據,若未更新則使用緩存數據庫中的緩存數據,具體流程如下:當協商緩存命中:
協商緩存未命中:
結合具體的請求來看,首先是第一次發送某請求后服務器的response:
兩個字段etag和last-modified是用于協商緩存的規則字段。其中etag是所請求的數據在服務器中的唯一標識,而last-modifind標識所請求資源最后一次修改的時間。
在緩存時間3600秒過去之后,我們再次發起同樣的請求:可以看到,在我們的請求中有這樣兩個字段if-modifind-since和if-none-match,兩個字段分別對應著響應中的last-Modified和etag,用來對協商緩存進行判斷:
a. 首先,如果在第一次請求中有etag和last-modified時,緩存數據庫會保存這兩個字段,并且在再次發起同樣的請求時以if-none-match和if-modified-since發送保存的last-modified和etag數據。
b. 服務器收到請求后會以優先級if-none-match > if-modifind-since的順序進行判斷,如果資源的etag和if-none-match相等,即所請求的資源沒有變化,此時瀏覽器即可以使用緩存數據庫中的數據,此時http的請求狀態碼為304,請求的資源未變化。
c. 如果請求字段中沒有if-none-match,就使用if-modified-since來判斷。如果if-modified-since的值和所請求的資源時間一致,即所請求的資源相同,瀏覽器即可以使用緩存數據庫中的數據。http狀態碼304。
-
瀏覽器緩存機制流程圖
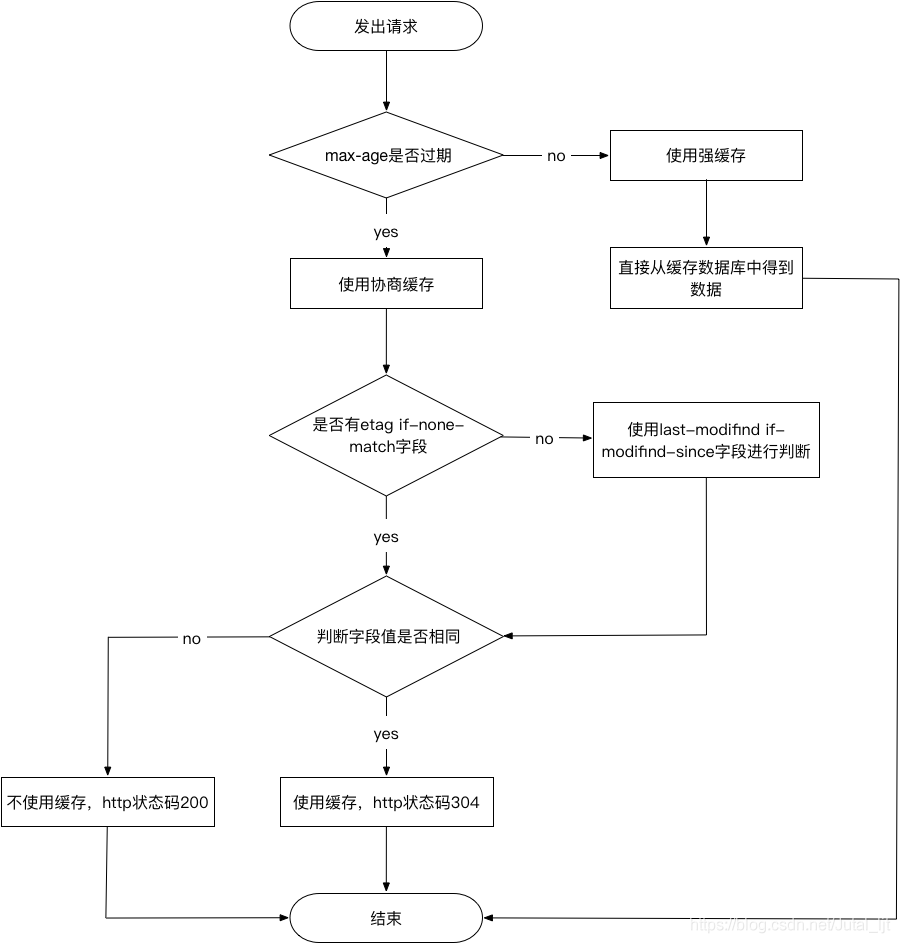
1.40 介紹一下HTTP協議中的長連接和短連接。
參考回答
HTTP協議的底層使用TCP協議,所以HTTP協議的長連接和短連接在本質上是TCP層的長連接和短連接。由于TCP建立連接、維護連接、釋放連接都是要消耗一定的資源,浪費一定的時間。所對于服務器來說,頻繁的請求釋放連接會浪費大量的時間,長時間維護太多的連接的話又需要消耗資源。所以長連接和短連接并不存在優劣之分,只是適用的場合不同而已。長連接和短連接分別有如下優點和缺點:
**長連接優點:**可以節省較多的TCP連接和釋放的操作,節約時間,對于頻繁請求資源的用戶來說,適合長連接。
**長連接缺點:**由于有保活功能,當遇到大量的惡意連接時,服務器的壓力會越來越大。這時服務器需要采取一些策略,關閉一些長時間沒有進行讀寫事件的的連接。
**短連接優點:**短連接對服務器來說管理比較簡單,只要存在的連接都是有效連接,不需要額外的控制手段,而且不會長時間占用資源 。
**短連接缺點:**如果客戶端請求頻繁的話,會在TCP的建立和釋放上浪費大量的時間。
注意:從HTTP/1.1版本起,默認使用長連接用以保持連接特性。使用長連接的HTTP協議,會在響應消息報文段加入: Connection: keep-alive。TCP中也有keep alive,但是TCP中的keep alive只是探測TCP連接是否活著,而HTTP中的keep-alive是讓一個TCP連接獲得更久一點。
答案解析
無
1.41 介紹一下HTTPS的流程。
參考回答
**HTTPS在傳輸的過程中會涉及到三個密鑰:**服務器端的公鑰和私鑰,用來進行非對稱加密;客戶端生成的隨機密鑰,用來進行對稱加密。一個HTTPS請求實際上包含了兩次HTTP傳輸,如下圖可以細分為以下8步:
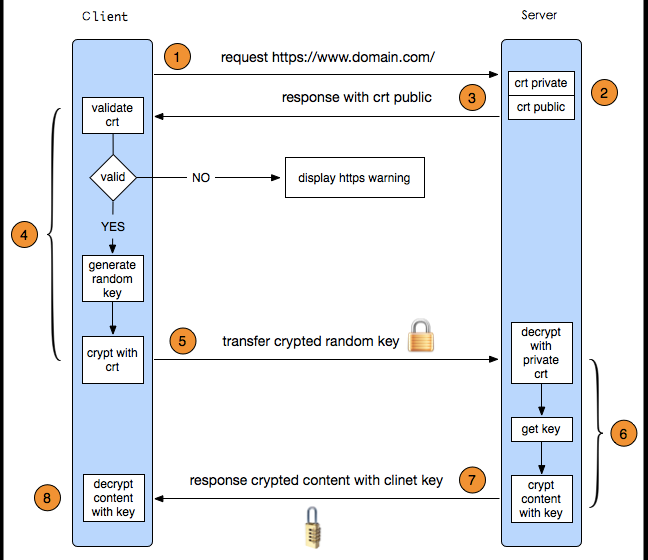
- 客戶端向服務器發起HTTPS請求,連接到服務器的443端口
- 服務器端有一個密鑰對,即公鑰和私鑰,是用來進行非對稱加密使用的,服務器端保存著私鑰,不能將其泄露,公鑰可以發送給任何人。
- 服務器將自己的公鑰發送給客戶端。
- 客戶端收到服務器端的公鑰之后,會對公鑰進行檢查,驗證其合法性,如果發現發現公鑰有問題,那么HTTPS傳輸就無法繼續。嚴格的說,這里應該是驗證服務器發送的數字證書的合法性,關于客戶端如何驗證數字證書的合法性,下文會進行說明。如果公鑰合格,那么客戶端會生成一個隨機值,這個隨機值就是用于進行對稱加密的密鑰,我們將該密鑰稱之為client key,即客戶端密鑰,這樣在概念上和服務器端的密鑰容易進行區分。然后用服務器的公鑰對客戶端密鑰進行非對稱加密,這樣客戶端密鑰就變成密文了,至此,HTTPS中的第一次HTTP請求結束。
- 客戶端會發起HTTPS中的第二個HTTP請求,將加密之后的客戶端密鑰發送給服務器。
- 服務器接收到客戶端發來的密文之后,會用自己的私鑰對其進行非對稱解密,解密之后的明文就是客戶端密鑰,然后用客戶端密鑰對數據進行對稱加密,這樣數據就變成了密文。
- 然后服務器將加密后的密文發送給客戶端。
- 客戶端收到服務器發送來的密文,用客戶端密鑰對其進行對稱解密,得到服務器發送的數據。這樣HTTPS中的第二個HTTP請求結束,整個HTTPS傳輸完成。
答案解析
無
1.42 介紹一下HTTP的失敗碼。
參考回答
HTTP的錯誤碼包含客戶端錯誤4XX 和服務端錯誤5XX ,兩種錯誤分別如下:
-
客戶端錯誤 4XX
這類的狀態碼是適用于客戶端似乎有錯誤的情況。除了響應給HEAD請求外,服務器應該包含一個包括錯誤情況描述的實體,和它是暫時的還是永久性的。這些狀態碼適用于任何請求方法。用戶代理應該展示所有包含的實體給用戶。
如果客戶端正在發送數據,使用TCP的服務器應該在服務器關閉輸出鏈接時,仔細確保客戶端確認收到包含響應的數據包(receipt of the packet(s) ) 。如果客戶端繼續在服務器關閉后發送數據,服務器的TCP棧將會發生一個重置包給客戶端,這可能會在 HTTP 應用程序讀取和解釋客戶端的未確認輸入緩沖區(input buffers)之前將其擦除。
400(錯誤請求) 服務器不理解請求的語法。
401(未授權) 請求要求進行身份驗證。登錄后,服務器可能會返回對頁面的此響應。
403(已禁止) 服務器拒絕請求。如果在 Googlebot 嘗試抓取您網站上的有效網頁時顯示此狀態代碼(您可在 Google 網站管理員工具中診斷下的網絡抓取頁面上看到此狀態代碼),那么,這可能是您的服務器或主機拒絕 Googlebot 對其進行訪問。
404(未找到) 服務器找不到請求的網頁。例如,如果請求是針對服務器上不存在的網頁進行的,那么,服務器通常會返回此代碼。
如果您的網站上沒有 robots.txt 文件,而您在 Google 網站管理員工具”診斷”標簽的 robots.txt 頁上發現此狀態,那么,這是正確的狀態。然而,如果您有 robots.txt 文件而又發現了此狀態,那么,這說明您的 robots.txt 文件可能是命名錯誤或位于錯誤的位置。(該文件應當位于頂級域名上,且應當名為 robots.txt)。
如果您在 Googlebot 嘗試抓取的網址上發現此狀態(位于”診斷”標簽的 HTTP 錯誤頁上),那么,這表示 Googlebot 所追蹤的可能是另一網頁中的無效鏈接(舊鏈接或輸入有誤的鏈接)。
405(方法禁用) 禁用請求中所指定的方法。
406(不接受) 無法使用請求的內容特性來響應請求的網頁。
407(需要代理授權) 此狀態代碼與 401(未授權)類似,但卻指定了請求者應當使用代理進行授權。如果服務器返回此響應,那么,服務器還會指明請求者應當使用的代理。
408(請求超時) 服務器等候請求時超時。
409(沖突) 服務器在完成請求時發生沖突。服務器必須包含有關響應中所發生的沖突的信息。服務器在響應與前一個請求相沖突的 PUT 請求時可能會返回此代碼,同時會提供兩個請求的差異列表。
410(已刪除) 如果請求的資源已被永久刪除,那么,服務器會返回此響應。該代碼與 404(未找到)代碼類似,但在資源以前有但現在已經不復存在的情況下,有時會替代 404 代碼出現。如果資源已被永久刪除,那么,您應當使用 301 代碼指定該資源的新位置。
411(需要有效長度) 服務器不會接受包含無效內容長度標頭字段的請求。
412(未滿足前提條件) 服務器未滿足請求者在請求中設置的其中一個前提條件。
413(請求實體過大) 服務器無法處理請求,因為請求實體過大,已超出服務器的處理能力。
414(請求的 URI 過長) 請求的 URI(通常為網址)過長,服務器無法進行處理。
415(不支持的媒體類型) 請求的格式不受請求頁面的支持。
416(請求范圍不符合要求) 如果請求是針對網頁的無效范圍進行的,那么,服務器會返回此狀態代碼。
417(未滿足期望值) 服務器未滿足”期望”請求標頭字段的要求。
-
服務端錯誤 5XX
響應狀態碼已數字5開頭,表明了這類服務器知道其錯誤或者無法執行請求的情況。出了響應HEAD請求外,服務器應該包括一個包含錯誤情況說明的實體,以及他是暫時地還是永久性的,用戶代理應該將所有包含的實體展示給用戶。這些響應代碼適用于任何請求方法。
500(服務器內部錯誤) 服務器遇到錯誤,無法完成請求。
501(尚未實施) 服務器不具備完成請求的功能。例如,當服務器無法識別請求方法時,服務器可能會返回此代碼。
502(錯誤網關) 服務器作為網關或代理,從上游服務器收到了無效的響應。
503(服務不可用) 目前無法使用服務器(由于超載或進行停機維護)。通常,這只是一種暫時的狀態。
504(網關超時) 服務器作為網關或代理,未及時從上游服務器接收請求。
505(HTTP 版本不受支持) 服務器不支持請求中所使用的 HTTP 協議版本。
1.43 說一說你知道的http狀態碼。
參考回答
HTTP狀態碼由三個十進制數字組成,第一個十進制數字定義了狀態碼的類型,后兩個數字沒有分類的作用。HTTP狀態碼共分為5種類型,分類及分類描述如下表:
| 分類 | 分類描述 |
|---|---|
| 1** | 信息,服務器收到請求,需要請求者繼續執行操作 |
| 2** | 成功,操作被成功接收并處理 |
| 3** | 重定向,需要進一步的操作以完成請求 |
| 4** | 客戶端錯誤,請求包含語法錯誤或無法完成請求 |
| 5** | 服務器錯誤,服務器在處理請求的過程中發生了錯誤 |
各類別常見狀態碼有如下幾種:
-
2xx (3種)
**200 OK:**表示從客戶端發送給服務器的請求被正常處理并返回;
**204 No Content:**表示客戶端發送給客戶端的請求得到了成功處理,但在返回的響應報文中不含實體的主體部分(沒有資源可以返回);
**206 Patial Content:**表示客戶端進行了范圍請求,并且服務器成功執行了這部分的GET請求,響應報文中包含由Content-Range指定范圍的實體內容。
-
3xx (5種)
**301 Moved Permanently:**永久性重定向,表示請求的資源被分配了新的URL,之后應使用更改的URL;
**302 Found:**臨時性重定向,表示請求的資源被分配了新的URL,希望本次訪問使用新的URL;
301與302的區別:前者是永久移動,后者是臨時移動(之后可能還會更改URL)
**303 See Other:**表示請求的資源被分配了新的URL,應使用GET方法定向獲取請求的資源;
302與303的區別:后者明確表示客戶端應當采用GET方式獲取資源
**304 Not Modified:**表示客戶端發送附帶條件(是指采用GET方法的請求報文中包含if-Match、If-Modified-Since、If-None-Match、If-Range、If-Unmodified-Since中任一首部)的請求時,服務器端允許訪問資源,但是請求為滿足條件的情況下返回該狀態碼;
**307 Temporary Redirect:**臨時重定向,與303有著相同的含義,307會遵照瀏覽器標準不會從POST變成GET;(不同瀏覽器可能會出現不同的情況);
-
4xx (4種)
**400 Bad Request:**表示請求報文中存在語法錯誤;
**401 Unauthorized:**未經許可,需要通過HTTP認證;
**403 Forbidden:**服務器拒絕該次訪問(訪問權限出現問題)
**404 Not Found:**表示服務器上無法找到請求的資源,除此之外,也可以在服務器拒絕請求但不想給拒絕原因時使用;
-
5xx (2種)
**500 Inter Server Error:**表示服務器在執行請求時發生了錯誤,也有可能是web應用存在的bug或某些臨時的錯誤時;
**503 Server Unavailable:**表示服務器暫時處于超負載或正在進行停機維護,無法處理請求;
答案解析
無
1.44 301和302有什么區別?
參考回答
301和302的區別在于,301重定向是永久的重定向,搜索引擎在抓取新內容的同時也將舊的網址交換為重定向之后的網址。302重定向是暫時的重定向,搜索引擎會抓取新的內容而保存舊的網址。由于效勞器前往302代碼,搜索引擎以為新的網址只是暫時的。
1.45 302和304有什么區別?
參考回答
302和304是網頁請求的兩個不同的響應狀態碼。302 (臨時移動)表示 服務器目前從不同位置的網頁響應請求,但請求者應繼續使用原有位置來進行以后的請求。 304 (未修改)表示 自從上次請求后,請求的網頁未修改過。 服務器返回此響應時,不會返回網頁內容。
答案解析
無
1.46 請描述一次完整的HTTP請求的過程。
參考回答
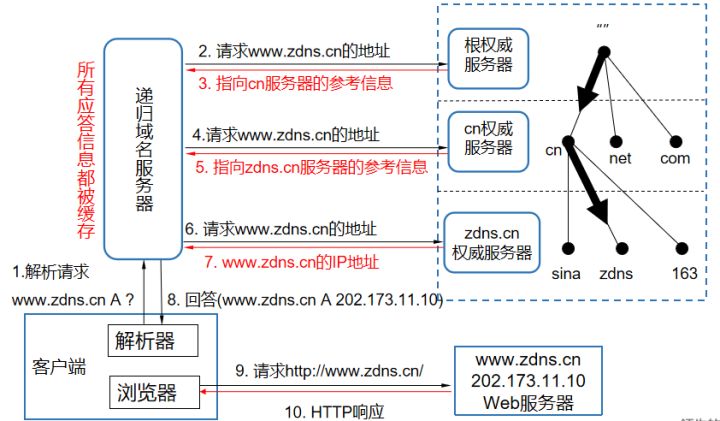
DNS解析流程圖
- 首先客戶端位置是一臺電腦或手機,在打開瀏覽器以后,比如輸入http://www.zdns.cn的域名,它首先是由瀏覽器發起一個DNS解析請求,如果本地緩存服務器中找不到結果,則首先會向根服務器查詢,根服務器里面記錄的都是各個頂級域所在的服務器的位置,當向根服務器請求http://www.zdns.cn的時候,根服務器就會返回.cn服務器的位置信息;
- 遞歸服務器拿到.cn的權威服務器地址以后,就會尋問.cn的權威服務器,知不知道http://www.zdns.cn的位置。這個時候.cn權威服務器查找并返回http://zdns.cn服務器的地址;
- 繼續向http://zdns.cn的權威服務器去查詢這個地址,由http://zdns.cn的服務器給出了地址:202.173.11.10;
- 最終進入http的鏈接,順利訪問網站;
補充說明:一旦遞歸服務器拿到解析記錄以后,就會在本地進行緩存,如果下次客戶端再請求本地的遞歸域名服務器相同域名的時候,就不會再這樣一層一層查了,因為本地服務器里面已經有緩存了,這個時候就直接把http://www.zdns.cn的記錄返回給客戶端就可以了。
1.47 什么是重定向?
參考回答
**重定向(Redirect)**就是通過各種方法將各種網絡請求重新定個方向轉到其它位置(如:網頁重定向、域名的重定向、路由選擇的變化也是對數據報文經由路徑的一種重定向)。
答案解析
-
需要重定向的情況
(1)網站調整(如改變網頁目錄結構);
(2)網頁被移到一個新地址;
(3)網頁擴展名改變(如應用需要把.php改成.Html或.shtml)。
這幾種情況下,如果不做重定向,則用戶收藏夾或搜索引擎數據庫中舊地址只能讓訪問客戶得到一個404 頁面錯誤信息,訪問流量白白喪失;再者某些注冊了多個域名的網站,也需要通過重定向讓訪問這些域名的用戶自動跳轉到主站點等。
-
常用的重定向的方式
(1)301 redirect-----永久性轉移
當用戶或搜索引擎向網站服務器發出瀏覽請求時,服務器返回的HTTP數據流中頭信息(header)中的狀態碼的一種,表示本網頁永久性轉移到另一個地址。
(2)302 redirect-----暫時性轉移 (Temporarily Moved )
也被認為是暫時重定向(temporary redirect),一條對網站瀏覽器的指令來顯示瀏覽器被要求顯示的不同的URL,當一個網頁經歷過短期的URL的變化時使用。一個暫時重定向是一種服務器端的重定向,能夠被搜索引擎蜘蛛正確地處理。
-
新舊重定向方式的區別
302重定向是暫時的重定向,搜索引擎會抓取新的內容而保存舊的網址。由于效勞器前往302代碼,搜索引擎以為新的網址只是暫時的;
301重定向是永久的重定向,搜索引擎在抓取新內容的同時也將舊的網址交換為重定向之后的網址。
-
為什么302 重定向和網址劫持有關聯
從網址A 做一個302 重定向到網址B 時,主機服務器的隱含意思是網址A 隨時有可能改主意,重新顯示本身的內容或轉向其他的地方。大部分的搜索引擎在大部分情況下,當收到302 重定向時,一般只要去抓取目標網址就可以了,也就是說網址B。如果搜索引擎在遇到302 轉向時,百分之百的都抓取目標網址B 的話,就不用擔心網址URL 劫持了。問題就在于,有的時候搜索引擎,尤其是Google,并不能總是抓取目標網址。
比如說,有的時候A 網址很短,但是它做了一個302 重定向到B 網址,而B 網址是一個很長的亂七八糟的URL 網址,甚至還有可能包含一些問號之類的參數。很自然的,A 網址更加用戶友好,而B 網址既難看,又不用戶友好。這時Google 很有可能會仍然顯示網址A。由于搜索引擎排名算法只是程序而不是人,在遇到302 重定向的時候,并不能像人一樣的去準確判定哪一個網址更適當,這就造成了網址URL 劫持的可能性。也就是說,一個不道德的人在他自己的網址A 做一個302 重定向到你的網址B,出于某種原因, Google 搜索結果所顯示的仍然是網址A,但是所用的網頁內容卻是你的網址B 上的內容,這種情況就叫做網址URL 劫持。你辛辛苦苦所寫的內容就這樣被別人偷走了。
302 重定向所造成的網址URL 劫持現象,已經存在一段時間了。不過到目前為止,似乎也沒有什么更好的解決方法。在正在進行的數據中心轉換中,302 重定向問題也是要被解決的目標之一。從一些搜索結果來看,網址劫持現象有所改善,但是并沒有完全解決。
1.48 重定向和請求轉發有什么區別?
參考回答
-
請求轉發
客戶首先發送一個請求到服務器端,服務器端發現匹配的servlet,并指定它去執行,當這個servlet執行完之后,它要調用getRequestDispacther()方法,把請求轉發給指定的student_list.jsp,整個流程都是在服務器端完成的,而且是在同一個請求里面完成的,因此servlet和jsp共享的是同一個request,在servlet里面放的所有東西,在student_list中都能取出來,因此,student_list能把結果getAttribute()出來,getAttribute()出來后執行完把結果返回給客戶端。整個過程是一個請求,一個響應。
-
重定向
客戶發送一個請求到服務器,服務器匹配servlet,servlet處理完之后調用了sendRedirect()方法,立即向客戶端返回這個響應,響應行告訴客戶端你必須要再發送一個請求,去訪問student_list.jsp,緊接著客戶端收到這個請求后,立刻發出一個新的請求,去請求student_list.jsp,這里兩個請求互不干擾,相互獨立,在前面request里面setAttribute()的任何東西,在后面的request里面都獲得不了。可見,在sendRedirect()里面是兩個請求,兩個響應。(服務器向瀏覽器發送一個302狀態碼以及一個location消息頭,瀏覽器收到請求后會向再次根據重定向地址發出請求)
-
二者區別
(1)請求次數:重定向是瀏覽器向服務器發送一個請求并收到響應后再次向一個新地址發出請求,轉發是服務器收到請求后為了完成響應跳轉到一個新的地址;重定向至少請求兩次,轉發請求一次;
(2)地址欄不同:重定向地址欄會發生變化,轉發地址欄不會發生變化;
(3)是否共享數據:重定向兩次請求不共享數據,轉發一次請求共享數據(在request級別使用信息共享,使用重定向必然出錯);
(4)跳轉限制:重定向可以跳轉到任意URL,轉發只能跳轉本站點資源;
(5)發生行為不同:重定向是客戶端行為,轉發是服務器端行為。
答案解析
無
1.49 介紹一下DNS尋址的過程。
參考回答
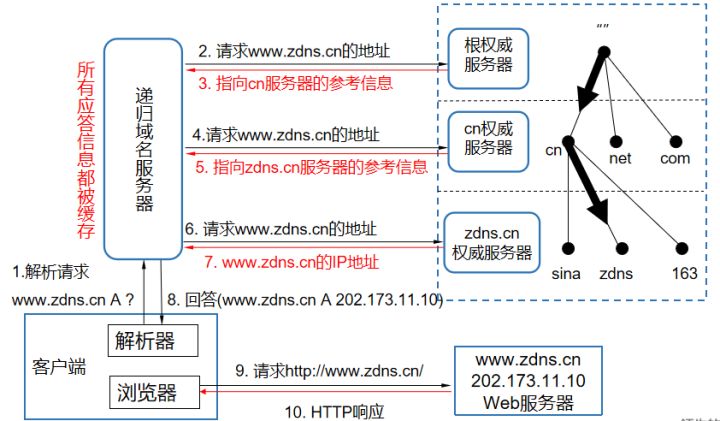
DNS解析流程圖
- 首先客戶端位置是一臺電腦或手機,在打開瀏覽器以后,比如輸入http://www.zdns.cn的域名,它首先是由瀏覽器發起一個DNS解析請求,如果本地緩存服務器中找不到結果,則首先會向根服務器查詢,根服務器里面記錄的都是各個頂級域所在的服務器的位置,當向根服務器請求http://www.zdns.cn的時候,根服務器就會返回.cn服務器的位置信息;
- 遞歸服務器拿到.cn的權威服務器地址以后,就會尋問.cn的權威服務器,知不知道http://www.zdns.cn的位置。這個時候.cn權威服務器查找并返回http://zdns.cn服務器的地址;
- 繼續向http://zdns.cn的權威服務器去查詢這個地址,由http://zdns.cn的服務器給出了地址:202.173.11.10;
- 最終進入http的鏈接,順利訪問網站;
補充說明:一旦遞歸服務器拿到解析記錄以后,就會在本地進行緩存,如果下次客戶端再請求本地的遞歸域名服務器相同域名的時候,就不會再這樣一層一層查了,因為本地服務器里面已經有緩存了,這個時候就直接把http://www.zdns.cn的記錄返回給客戶端就可以了。
答案解析
-
什么是DNS
DNS就是域名系統,是因特網中的一項核心服務,是用于實現域名和IP地址相互映射的一個分布式數據庫,能夠使用戶更方便的訪問互聯網,而不用去記住能夠被機器直接讀取的IP數串。通過主機名,得到該主機名對應的IP地址的過程叫做域名解析(或主機名解析)。
-
域名解析結構
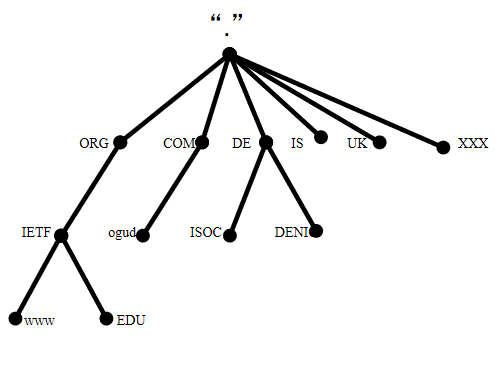
如上圖所示,域名結構是樹狀結構,樹的最頂端代表根服務器,根的下一層就是由我們所熟知的.com、.net、.cn等通用域和.cn、.uk等國家域組成,稱為頂級域。網上注冊的域名基本都是二級域名,比如http://baidu.com、http://taobao.com等等二級域名,它們基本上是歸企業和運維人員管理。接下來是三級或者四級域名,這里不多贅述。總體概括來說域名是由整體到局部的機制結構。
1.50 說一說你對TIME_WAIT的理解。
參考回答
-
出現 TIME_WAIT的狀態原因
TIME_WAIT狀態之所以存在,是為了保證網絡的可靠性。由于TCP連接是雙向的,所以在關閉連接的時候,兩個方向各自都需要關閉。先發FIN包的一方執行的是主動關閉,后發送FIN包的一方執行的是被動關閉。主動關閉的一方會進入TIME_WAIT狀態,并且在此狀態停留2MSL時長。如果Server端一直沒有向client端發送FIN消息(調用close() API),那么這個CLOSE_WAIT會一直存在下去。
-
MSL概念
其指的是報文段的最大生存時間。如果報文段在網絡中活動了MSL時間,還沒有被接收,那么就會被丟棄。關于MSL的大小,RFC 793協議中給出的建議是2分鐘,不過Linux中,通常是半分鐘。
-
TIME_WAIT持續兩個MSL的作用
首先,可靠安全地關閉TCP連接。比如網絡擁塞,如果主動關閉方最后一個ACK沒有被被動關閉方接收到,這時被動關閉方會對FIN進行超時重傳,在這時尚未關閉的TIME_WAIT就會把這些尾巴問題處理掉,不至于對新連接及其他服務產生影響。其次,防止由于沒有持續TIME_WAIT時間導致的新的TCP連接建立起來,延遲的FIN重傳包會干擾新的連接。
-
TIME_WAIT占用的資源
少量內存(大概4K)和一個文件描述符fd。
-
TIME_WAIT關閉的危害
首先,當網絡情況不好時,如果主動方無TIME_WAIT等待,關閉前個連接后,主動方與被動方又建立起新的TCP連接,這時被動方重傳或延時過來的FIN包到達后會直接影響新的TCP連接;其次,當網絡情況不好時,同時沒有TIME_WAIT等待時,關閉連接后無新連接,那么當接收到被動方重傳或延遲的FIN包后,會給被動方回送一個RST包,可能會影響被動方其他的服務連接。
答案解析
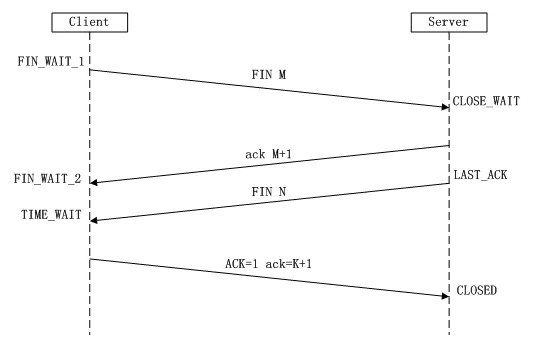
當client端傳輸完成數據,或者需要斷開連接時:
- Client端發送一個FIN報文給Server端。表示要終止Client到Server這個方向的連接。通過調用close(socket) API。表示Client不再會發送數據到Server端。(但Server還能繼續發給Client端)。Client狀態變為FIN_WAIT_1。
- Server端收到FIN后,發送一個ACK報文給Client端(序號為M+1)。Server狀態變為CLOSE_WAIT,Client收到序號為(M+1)的ACK后狀態變為FIN_WAIT_2。Server端也發送一個FIN報文給Client端。(序號為N)
表示Server也要終止到Client端這個方向的連接。通過調用close(socket) API。Server端狀態變為LAST_ACK。 - Client端收到報文FIN后,也發送一個ACK報文給服務器。(序號N+1),Client狀態變為TIME_WAIT。
- Server端收到序號為(N+1)的ACK, Server的狀態變為CLOSED。
- 等帶2MSL之后,Client的狀態也變為CLOSE。
至此,一個完整的TCP連接就關閉了。
1.51 TIME_WAIT、CLOSE_WAIT狀態發生在哪一步?
參考回答
-
TIME_WAIT狀態發生在客戶端主動關閉連接時,發送最后一個ack后;CLOSE_WAIT狀態發生在在Sever端收到Client的FIN消息之后。
-
出現 TIME_WAIT的狀態原因
TIME_WAIT狀態之所以存在,是為了保證網絡的可靠性。由于TCP連接是雙向的,所以在關閉連接的時候,兩個方向各自都需要關閉。先發FIN包的一方執行的是主動關閉,后發送FIN包的一方執行的是被動關閉。主動關閉的一方會進入TIME_WAIT狀態,并且在此狀態停留2MSL時長。如果Server端一直沒有向client端發送FIN消息(調用close() API),那么這個CLOSE_WAIT會一直存在下去。
-
出現CLOSE_WAIT的狀態原因
假設最終的ACK丟失,server將重發FIN,client必須維護TCP狀態信息以便可以重發最終的ACK,否則會發送RST,結果server認為發生錯誤。TCP實現必須可靠地終止連接的兩個方向(全雙工關閉),client必須進入 TIME_WAIT 狀態,因為client可能面臨重發最終ACK的情形。
-
為什么 TIME_WAIT 狀態需要保持 2MSL 這么長的時間?
如果 TIME_WAIT 狀態保持時間不足夠長(比如小于2MSL),第一個連接就正常終止了。第二個擁有相同相關五元組的連接出現,而第一個連接的重復報文到達,干擾了第二個連接。TCP實現必須防止某個連接的重復報文在連接終止后出現,所以讓TIME_WAIT狀態保持時間足夠長(2MSL),連接相應方向上的TCP報文要么完全響應完畢,要么被丟棄。建立第二個連接的時候,不會混淆。
答案解析
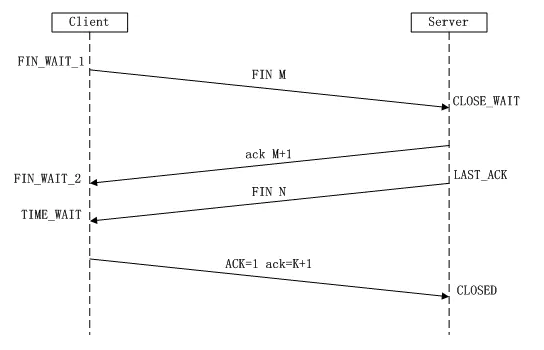
當client端傳輸完成數據,或者需要斷開連接時:
- Client端發送一個FIN報文給Server端。表示要終止Client到Server這個方向的連接。通過調用close(socket) API。表示Client不再會發送數據到Server端。(但Server還能繼續發給Client端)。Client狀態變為FIN_WAIT_1。
- Server端收到FIN后,發送一個ACK報文給Client端(序號為M+1)。Server狀態變為CLOSE_WAIT,Client收到序號為(M+1)的ACK后狀態變為FIN_WAIT_2。Server端也發送一個FIN報文給Client端。(序號為N)
表示Server也要終止到Client端這個方向的連接。通過調用close(socket) API。Server端狀態變為LAST_ACK。 - Client端收到報文FIN后,也發送一個ACK報文給服務器。(序號N+1),Client狀態變為TIME_WAIT。
- Server端收到序號為(N+1)的ACK, Server的狀態變為CLOSED。
- 等帶2MSL之后,Client的狀態也變為CLOSE。
至此,一個完整的TCP連接就關閉了。
1.52 有大量的TIME_WAIT狀態怎么辦?
參考回答
-
time_wait 狀態的影響
TCP 連接中,主動發起關閉連接的一端,會進入 time_wait 狀態,time_wait 狀態,默認會持續 2 MSL(報文的最大生存時間),一般是 2x2 mins,time_wait 狀態下,TCP 連接占用的端口,無法被再次使用,TCP 端口數量,上限是 6.5w(65535,16 bit),大量 time_wait 狀態存在,會導致新建 TCP 連接會出錯,address already in use : connect異常。
-
解決辦法
(1)客戶端:HTTP 請求的頭部,connection 設置為 keep-alive,保持存活一段時間:現在的瀏覽器,一般都這么進行了 。
(2)服務器端
a. 允許 time_wait狀態的 socket 被重用
b. 縮減 time_wait 時間,設置為 1 MSL(即,2 mins)
答案解析
無
1.53 請介紹socket通信的具體步驟。
參考回答
sockets(套接字)編程有三種:流式套接字(SOCK_STREAM),數據報套接字(SOCK_DGRAM),原始套接字(SOCK_RAW);基于TCP的socket編程是采用的流式套接字。
-
服務器端編程的步驟
(1)加載套接字庫,創建套接字(WSAStartup()/socket());
(2)綁定套接字到一個IP地址和一個端口上(bind());
(3)將套接字設置為監聽模式等待連接請求(listen());
(4)請求到來后,接受連接請求,返回一個新的對應于此次連接的套接字(accept());
(5)用返回的套接字和客戶端進行通信(send()/recv());
(6)返回,等待另一連接請求;
(7)關閉套接字,關閉加載的套接字庫(closesocket()/WSACleanup())。
-
客戶端編程的步驟:
(1)加載套接字庫,創建套接字(WSAStartup()/socket());
(2)向服務器發出連接請求(connect());
(3)和服務器端進行通信(send()/recv());
(4)關閉套接字,關閉加載的套接字庫(closesocket()/WSACleanup())。
答案解析
//代碼實例(服務器)
#include <stdio.h>
#include <Winsock2.h>
void main()
{WORD wVersionRequested;WSADATA wsaData;int err;wVersionRequested = MAKEWORD( 1, 1 );err = WSAStartup( wVersionRequested, &wsaData );if ( err != 0 ) {return;}if ( LOBYTE( wsaData.wVersion ) != 1 ||HIBYTE( wsaData.wVersion ) != 1 ) {WSACleanup( );return;}SOCKET sockSrv=socket(AF_INET,SOCK_STREAM,0);SOCKADDR_IN addrSrv;addrSrv.sin_addr.S_un.S_addr=htonl(INADDR_ANY);addrSrv.sin_family=AF_INET;addrSrv.sin_port=htons(6000);bind(sockSrv,(SOCKADDR*)&addrSrv,sizeof(SOCKADDR));listen(sockSrv,5);SOCKADDR_IN addrClient;int len=sizeof(SOCKADDR);while(1){SOCKET sockConn=accept(sockSrv,(SOCKADDR*)&addrClient,&len);char sendBuf[50];sprintf(sendBuf,"Welcome %s to here!",inet_ntoa(addrClient.sin_addr));send(sockConn,sendBuf,strlen(sendBuf)+1,0);char recvBuf[50];recv(sockConn,recvBuf,50,0);printf("%s\n",recvBuf);closesocket(sockConn);}}
//代碼實例(客戶端)
#include <stdio.h>
#include <Winsock2.h>
void main()
{WORD wVersionRequested;WSADATA wsaData;int err;wVersionRequested = MAKEWORD( 1, 1 );err = WSAStartup( wVersionRequested, &wsaData );if ( err != 0 ) {return;}if ( LOBYTE( wsaData.wVersion ) != 1 ||HIBYTE( wsaData.wVersion ) != 1 ) {WSACleanup( );return;}SOCKET sockClient=socket(AF_INET,SOCK_STREAM,0);SOCKADDR_IN addrSrv;addrSrv.sin_addr.S_un.S_addr=inet_addr("127.0.0.1");addrSrv.sin_family=AF_INET;addrSrv.sin_port=htons(6000);connect(sockClient,(SOCKADDR*)&addrSrv,sizeof(SOCKADDR));send(sockClient,"hello",strlen("hello")+1,0);char recvBuf[50];recv(sockClient,recvBuf,50,0);printf("%s\n",recvBuf);closesocket(sockClient);WSACleanup();
}
1.54 服務端怎么提高處理socket連接的性能?
參考回答
提高處理socket連接的性能,請遵循以下技巧:
- 最小化報文傳輸的延時。
- 最小化系統調用的負載。
- 為 Bandwidth Delay Product 調節 TCP 窗口。
- 動態優化 GNU/Linux TCP/IP 棧。
答案解析
-
最小化報文傳輸的延時。
在通過 TCP socket 進行通信時,數據都拆分成了數據塊,這樣它們就可以封裝到給定連接的 TCP payload(指 TCP 數據包中的有效負荷)中了。TCP payload 的大小取決于幾個因素(例如最大報文長度和路徑),但是這些因素在連接發起時都是已知的。為了達到最好的性能,我們的目標是使用盡可能多的可用數據來填充每個報文。當沒有足夠的數據來填充 payload 時(也稱為最大報文段長度(maximum segment size)或 MSS),TCP 就會采用 Nagle 算法自動將一些小的緩沖區連接到一個報文段中。這樣可以通過最小化所發送的報文的數量來提高應用程序的效率,并減輕整體的網絡擁塞問題。
-
最小化系統調用的負載。
任何時候通過一個 socket 來讀寫數據時,都是在使用一個系統調用(system call)。這個調用(例如 read 或 write)跨越了用戶空間應用程序與內核的邊界。另外,在進入內核之前,該調用會通過 C 庫來進入內核中的一個通用函數(system_call())。從 system_call()中,這個調用會進入文件系統層,內核會在這兒確定正在處理的是哪種類型的設備。最后,調用會進入 socket 層,數據就是在這里進行讀取或進行排隊從而通過 socket 進行傳輸的(這涉及數據的副本)。
這個過程說明系統調用不僅僅是在應用程序和內核中進行操作的,而且還要經過應用程序和內核中的很多層次。這個過程耗費的資源很高,因此調用次數越多,通過這個調用鏈進行的工作所需要的時間就越長,應用程序的性能也就越低。由于我們無法避免這些系統調用,因此唯一的選擇是最小化使用這些調用的次數。
-
為 Bandwidth Delay Product 調節 TCP 窗口。
TCP 的性能取決于幾個方面的因素。兩個最重要的因素是鏈接帶寬(link bandwidth)(報文在網絡上傳輸的速率)和 往返時間(round-trip time) 或 RTT(發送報文與接收到另一端的響應之間的延時)。這兩個值確定了稱為 Bandwidth Delay Product(BDP)的內容。
給定鏈接帶寬和 RTT 之后,就可以計算出 BDP 的值了,不過這代表什么意義呢?BDP 給出了一種簡單的方法來計算理論上最優的 TCP socket 緩沖區大小(其中保存了排隊等待傳輸和等待應用程序接收的數據)。如果緩沖區太小,那么 TCP 窗口就不能完全打開,這會對性能造成限制。如果緩沖區太大,那么寶貴的內存資源就會造成浪費。如果設置的緩沖區大小正好合適,那么就可以完全利用可用的帶寬。
-
動態優化 GNU/Linux TCP/IP 棧。
標準的 GNU/Linux 發行版試圖對各種部署情況都進行優化。這意味著標準的發行版可能并沒有對現有的環境進行特殊的優化。GNU/Linux 提供了很多可調節的內核參數,可以使用這些參數為自己的操作系統進行動態配置。
1.55 介紹一下流量控制和擁塞控制。
參考回答
-
流量控制和擁塞控制定義
流量控制
如果發送方把數據發送得過快,接收方可能會來不及接收,這就會造成數據的丟失。流量控制就是讓發送方慢點,要讓接收方來得及接收。
擁塞控制
擁塞控制就是防止過多的數據注入到網絡中,這樣可以使網絡中的路由器或鏈路不致過載。
-
流量控制和擁塞控制區別
流量控制是端到端的控制,例如A通過網絡給B發數據,A發送的太快導致B沒法接收(B緩沖窗口過小或者處理過慢),這時候的控制就是流量控制,原理是通過滑動窗口的大小改變來實現。
擁塞控制是A與B之間的網絡發生堵塞導致傳輸過慢或者丟包,來不及傳輸。防止過多的數據注入到網絡中,這樣可以使網絡中的路由器或鏈路不至于過載。擁塞控制是一個全局性的過程,涉及到所有的主機、路由器,以及與降低網絡性能有關的所有因素。
-
TCP流量控制解決方法
TCP的流量控制是利用滑動窗口機制實現的,接收方在返回的數據中會包含自己的接收窗口的大小,以控制發送方的數據發送。
-
TCP擁塞控制解決方法
TCP擁塞控制的四種算法:慢開始、擁塞避免、快重傳、快恢復。
(1)**慢開始算法:**當主機開始發送數據時,并不清楚網絡的負載情況,所以由小到大逐漸增大擁塞窗口,每經過一個傳輸輪次沒有出現超時就將擁塞窗口加倍。同時還需要設置一個慢開始門限,在擁塞窗口小于慢開始門限時使用慢開始算法,大于慢開始門限時,使用擁塞避免算法;
(2)**擁塞避免算法:**在擁塞窗口大于慢開始門限時,讓擁塞窗口按線性規律緩慢增長。即每經過一個傳輸輪次,擁塞窗口增大一個MSS最大報文段尺寸。(擁塞避免并非完全能夠避免擁塞,只是使網絡比較不容易出現擁塞)
(3)**快重傳算法:**使發送方今早知道發生了個別報文段丟失,并不是出現網絡擁塞。
要求接受不要登塞自己發送數據時才進行捎帶確認,而是立即發送確認,即使收到了失序的報文段也要立即發出對已收到報文段的重復確認。而發送方一旦受到三個連續的重讀確認,就將相應的報文段立即重傳。
(4)**快恢復算法:**發送方知道只有個別報文段丟失而不是網絡擁塞時,不啟動慢開始算法,而是執行快恢復算法,將慢開始門限和擁塞窗口值調整為當前窗口的一半,開始執行擁塞避免算法
1.56 對路由協議是否有所了解?
參考回答
有了解。
-
路由協議定義
路由協議(英語:Routing protocol)是一種指定數據包轉送方式的網上協議。Internet網絡的主要節點設備是路由器,路由器通過路由表來轉發接收到的數據。轉發策略可以是人工指定的(通過靜態路由、策略路由等方法)。在具有較小規模的網絡中,人工指定轉發策略沒有任何問題。但是在具有較大規模的網絡中(如跨國企業網絡、ISP網絡),如果通過人工指定轉發策略,將會給網絡管理員帶來巨大的工作量,并且在管理、維護路由表上也變得十分困難。為了解決這個問題,動態路由協議應運而生。動態路由協議可以讓路由器自動學習到其他路由器的網絡,并且網絡拓撲發生改變后自動更新路由表。網絡管理員只需要配置動態路由協議即可,相比人工指定轉發策略,工作量大大減少。
-
原理
路由協議通過在路由器之間共享路由信息來支持可路由協議。路由信息在相鄰路由器之間傳遞,確保所有路由器知道到其它路由器的路徑。總之,路由協議創建了路由表,描述了網絡拓撲結構;路由協議與路由器,執行路由選擇和數據包轉發功能。
-
路由器的作用以及常見的路由協議
**路由協議主要運行于路由器上,路由協議是用來確定到達路徑的,起到一個地圖導航,負責找路的作用。**它工作在網絡層。它包括RIP,IGRP(Cisco私有協議),EIGRP(Cisco私有協議),OSPF,IS-IS,BGP。以下為這六個協議的詳細說明:
(1)RIP(路由信息協議)
RIP很早就被用在Internet上,是最簡單的路由協議。它是“路由信息協議(Route Information Protocol)”的簡寫,主要傳遞路由信息,通過每隔30秒廣播一次路由表,維護相鄰路由器的位置關系,同時根據收到的路由表信息計算自己的路由表信息。RIP是一個距離矢量路由協議,最大跳數為15跳,超過15跳的網絡則認為目標網絡不可達。此協議通常用在網絡架構較為簡單的小型網絡環境。分為RIPv1和RIPv2兩個版本,后者支持VLSM技術以及一系列技術上的改進。RIP的收斂速度較慢。
(2)IGRP(內部網關路由協議)
IGRP協議是“內部網關路由協議(Interior Gateway Routing Protocol)”的縮寫,由Cisco于二十世紀八十年代獨立開發,屬于Cisco私有協議。IGRP和RIP一樣,同屬距離矢量路由協議,因此在諸多方面有著相似點,如IGRP也是周期性的廣播路由表,也存在最大跳數(默認為100跳,達到或超過100跳則認為目標網絡不可達)。IGRP最大的特點是使用了混合度量值,同時考慮了鏈路的帶寬、延遲、負載、MTU、可靠性5個方面來計算路由的度量值,而不像其他IGP協議單純的考慮某一個方面來計算度量值。IGRP已經被Cisco獨立開發的EIGRP協議所取代,版本號為12.3及其以上的Cisco IOS(Internetwork Operating System)已經不支持該協議,已經罕有運行IGRP協議的網絡。
(3)EIGRP(增強型內部網關路由協議)
由于IGRP協議的種種缺陷以及不足,Cisco開發了EIGRP協議(增強型內部網關路由協議)來取代IGRP協議。EIGRP屬于高級距離矢量路由協議(又稱混合型路由協議),繼承了IGRP的混合度量值,最大特點在于引入了非等價負載均衡技術,并擁有極快的收斂速度。EIGRP協議在Cisco設備網絡環境中廣泛部署。
(4)OSPF(開放式最短路徑優先)
OSPF協議是“開放式最短路徑優先(Open Shortest Path First)”的縮寫,屬于鏈路狀態路由協議。OSPF提出了“區域(area)”的概念,每個區域中所有路由器維護著一個相同的鏈路狀態數據庫(LSDB)。區域又分為骨干區域(骨干區域的編號必須為0)和非骨干區域(非0編號區域),如果一個運行OSPF的網絡只存在單一區域,則該區域可以是骨干區域或者非骨干區域。如果該網絡存在多個區域,那么必須存在骨干區域,并且所有非骨干區域必須和骨干區域直接相連。OSPF利用所維護的鏈路狀態數據庫,通過最短路徑優先算法(SPF算法)計算得到路由表。OSPF的收斂速度較快。由于其特有的開放性以及良好的擴展性,OSPF協議在各種網絡中廣泛部署。
(5)IS-IS(中間系統到中間系統)
IS-IS協議是Intermediate system to intermediate system(中間系統到中間系統)的縮寫,屬于鏈路狀態路由協議。標準IS-IS協議是由國際標準化組織制定的ISO/IEC 10589:2002所定義的,標準IS-IS不適合用于IP網絡,因此IETF制定了適用于IP網絡的集成化IS-IS協議(Integrated IS-IS)。和OSPF相同,IS-IS也使用了“區域”的概念,同樣也維護著一份鏈路狀態數據庫,通過最短生成樹算法(SPF)計算出最佳路徑。IS-IS的收斂速度較快。集成化IS-IS協議是ISP骨干網上最常用的IGP協議。
(6)BGP(邊界網關協議)
為了維護各個ISP的獨立利益,標準化組織制定了ISP間的路由協議BGP。BGP是“邊界網關協議(Border Gateway Protocol)”的縮寫,處理各ISP之間的路由傳遞。但是BGP運行在相對核心的地位,需要用戶對網絡的結構有相當的了解,否則可能會造成較大損失。
答案解析
無
1.57 直播可能需要使用到什么樣的協議?
參考回答
視頻直播有多種協議,使用rtmp協議的就是rtmp直播。直播流就是視頻流,即傳遞的視頻數據。常見的協議有RTMP、RTSP、HTTP協議,這三個協議都屬于互聯網TCP/IP五層體系結構中應用層的協議。理論上這三種都可以用來做視頻直播或點播。但通常來說,**直播一般用RTMP、RTSP,而點播用HTTP。**下面分別介紹下三者的特點。
-
RTMP協議
(1)是流媒體協議;
(2)RTMP協議是Adobe的私有協議,未完全公開;
(3)RTMP協議一般傳輸的是flv,f4v格式流;
(4)RTMP一般在TCP1個通道上傳輸命令和數據。
-
RTSP協議
(1)是流媒體協議;
(2)RTSP協議是共有協議,并有專門機構做維護;
(3)RTSP協議一般傳輸的是ts、mp4格式的流;
(4)RTSP傳輸一般需要2-3個通道,命令和數據通道分離。
-
HTTP協議
(1)不是是流媒體協議;
(2)HTTP協議是共有協議,并有專門機構做維護;
(3)HTTP協議沒有特定的傳輸流;
(4)HTTP傳輸一般需要2-3個通道,命令和數據通道分離。
答案解析
擴展資料
一個完整的視頻直播過程,包括采集、處理、編碼、封裝、推流、傳輸、轉碼、分發、解碼、播放等。
-
采集
音頻采集音頻的采集過程主要通過設備將環境中的模擬信號采集成 PCM 編碼的原始數據,然后編碼壓縮成 MP3 等格式的數據分發出去。常見的音頻壓縮格式有:MP3,AAC,HE-AAC,Opus,FLAC,Vorbis (Ogg),Speex 和 AMR等。
圖像采集 圖像的采集過程主要由攝像頭等設備拍攝成 YUV 編碼的原始數據,然后經過編碼壓縮成 H.264 等格式的數據分發出去。常見的視頻封裝格式有:MP4、3GP、AVI、MKV、WMV、MPG、VOB、FLV、SWF、MOV、RMVB 和 WebM 等。
-
處理
視頻或者音頻完成采集之后得到原始數據,為了增強一些現場效果或者加上一些額外的效果,我們一般會在將其編碼壓縮前進行處理。
視頻:美顏、水印、路徑、自定義。
音頻:混音、降噪、特效、自定義。
-
編碼
對流媒體傳輸來說,編碼非常重要,它的編碼性能、編碼速度和編碼壓縮比會直接影響整個流媒體傳輸的用戶體驗和傳輸成本。
常見的視頻編碼器:
(1)H.264/AVC
(2)HEVC/H.265
(3)VP8
(4)VP9
(5)FFmpeg
音頻編碼器:Mp3, AAC等。
-
封裝
把編碼器生成的多媒體內容(視頻,音頻,字幕,章節信息等)混合封裝在一起幾種常見的封裝格式:
(1)AVI 格式(后綴為 .avi)
(2)DV-AVI 格式(后綴為 .avi)
(3)QuickTime File Format 格式(后綴為 .mov)
(4)MPEG 格式(文件后綴可以是 .mpg .mpeg .mpe .dat .vob .asf .3gp .mp4等)
(5)WMV 格式(后綴為.wmv .asf)
(6)Real Video 格式(后綴為 .rm .rmvb)
(7)Flash Video 格式(后綴為 .flv)
(8)Matroska 格式(后綴為 .mkv)
(9)MPEG2-TS 格式 (后綴為 .ts)
目前,我們在流媒體傳輸,尤其是直播中主要采用的就是 FLV 和 MPEG2-TS 格式,分別用于 RTMP/HTTP-FLV 和 HLS 協議。
-
推流
推流是指使用推流工具等內容抓取軟件把直播內容傳輸到服務器的過程。推送協議主要有三種:
(1)RTSP(Real Time Streaming Protocol):實時流傳送協議,是用來控制聲音或影像的多媒體串流協議, 由Real Networks和Netscape共同提出的;
(2)RTMP(Real Time Messaging Protocol):實時消息傳送協議,是Adobe公司為Flash播放器和服務器之間音頻、視頻和數據傳輸 開發的開放協議;
(3)HLS(HTTP Live Streaming):是蘋果公司(Apple Inc.)實現的基于HTTP的流媒體傳輸協議;RTMP是目前主流的流媒體傳輸協議,廣泛用于直播領域,市面上絕大多數的直播產品都采用了這個協議。
RTMP協議基于 TCP,是一種設計用來進行實時數據通信的網絡協議,主要用來在 flash/AIR 平臺和支持 RTMP 協議的流媒體/交互服務器之間進行音視頻和數據通信。支持該協議的軟件包括 Adobe Media Server/Ultrant Media Server/red5 等。它有三種變種:
(1)RTMP工作在TCP之上的明文協議,使用端口1935;
(2)RTMPT封裝在HTTP請求之中,可穿越防火墻;
(3)RTMPS類似RTMPT,但使用的是HTTPS連接;
RTMP協議就像一個用來裝數據包的容器,這些數據可以是AMF格式的數據,也可以是FLV中的視/音頻數據。一個單一的連接可以通過不同的通道傳輸多路網絡流。這些通道中的包都是按照固定大小的包傳輸的。
-
傳輸
推送出去的流媒體需要傳輸到觀眾,整個鏈路就是傳輸網絡。
-
轉碼
視頻直播播流端的碼率是根據推流端決定的,即播流端的碼率是與推流端的碼率一致的。但是遇到以下場景會造成直播效果較差:推流端碼率與播流端帶寬不相匹配。當推流端碼率較高而客戶端帶寬資源有限就會導致播放出現卡頓,而當推流端碼率較低但是客戶端對于直播效率要求較高時會導致播放效果較差。播放器插件需要實現多碼率切換。前端播放器插件常可以設置碼率切換,這就需要同一路推流可以同時提供多種碼率的播流地址。因此,視頻直播提供了實時轉碼功能對同一路推流地址同時提供多路不同碼率播流地址提供服務。
-
分發
流媒體服務器的作用是負責直播流的發布和轉播分發功能。
-
解碼
編碼器(Encoder):壓縮信號的設備或程序;
解碼器(Decoder):解壓縮信號的設備或程序;
編解碼器(Codec):編解碼器對。
-
播放器流播放主要是實現直播節目在終端上的展現。因為這里使用的傳輸協議是RTMP, 所以只要支持 RTMP 流協議的播放器都可以使用。
1.58 談談單工、雙工、半雙工的通信方式。
參考回答
- **單工:**數據傳輸只支持數據在一個方向上傳輸;在同一時間只有一方能接受或發送信息,不能實現雙向通信。舉例:電視,廣播。
- **半雙工:**半雙工數據傳輸允許數據在兩個方向上傳輸,但是,在某一時刻,只允許數據在一個方向上傳輸,它實際上是一種切換方向的單工通信;在同一時間只可以有一方接受或發送信息,可以實現雙向通信。舉例:對講機。
- **雙工:**全雙工數據通信允許數據同時在兩個方向上傳輸,因此,全雙工通信是兩個單工通信方式的結合,它要求發送設備和接收設備都有獨立的接收和發送能力;在同一時間可以同時接受和發送信息,實現雙向通信。舉例:電話通信。
答案解析
擴展資料:
單工、半雙工和全雙工是電信計算機網絡中的三種通信信道。這些通信信道可以提供信息傳達的途徑。通信信道可以是物理傳輸介質或通過多路復用介質的邏輯連接。物理傳輸介質是指能夠傳播能量波的材料物質,例如數據通信中的導線。并且邏輯連接通常指電路交換連接或分組模式虛擬電路連接,例如無線電信通道。由于通信信道的幫助,信息可以無障礙地傳輸。
單工模式一般用在只向一個方向傳輸數據的場合。例如計算機與打印機之間的通信是單工模式,因為只有計算機向打印機傳輸數據,而沒有相反方向的數據傳輸。還有在某些通信信道中,如單工無線發送等。
1.59 說一說內網和外網通信的過程。
參考回答
-
公有IP和私有IP概念
公有地址(Public address):由 Inter NIC(Internet Network Information Center 因特網信息中心)負責。這些 IP 地址分配給注冊并向Inter NIC提出申請的組織機構,公有 IP 全球唯一,通過它直接訪問因特網(直接能上網)。
私有地址(Private address):屬于非注冊地址,專門為組織機構內部使用,說白了,私有 IP 不能直接上網。
家里路由器分出來的IP就是私有IP(局域網IP),真正擁有公有IP的是運營商(電信、移動、聯通),運營商購買了一些公有IP(外網IP),然后通過這些公有IP分出來,再分給一個一個的用戶使用。所以,A 家庭的局域網 IP 和 B 家庭的局域網 IP 相同很正常,但是,最終 A 和 B 能上網(數據走出去)還是通過運營商的公有 IP,畢竟,公有 IP 的資源有限,這一片區域的用戶使用的很有可能(實際上就是這樣的)是同一個公有 IP。
-
內網和外網通信過程
內網和外網的通信是通過端口映射來實現的。
我們平時經過路由器,通過寬帶,最終去到運營商那邊,數據是從運營商出去,最終數據是回到運營商那邊,運營商再把數據發送到用戶的電腦。路由器,至少有兩個端口:WAN 口和 LAN 口。WAN口接外部 IP 地址用,通常指的是出口,轉發來自內部 LAN 接口的 IP 數據包,這個口的 IP 是唯一的。LAN口接內部 IP 地址用,LAN 內部是交換機。
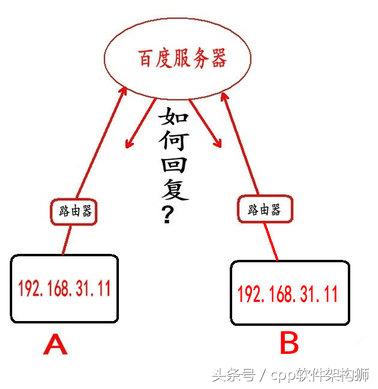
**舉例:**假如 A 和 B 的局域網(內網) IP 相同(192.168.31.11),當他們同時訪問百度服務器(外網)的時候,百度服務器如何區分哪個是 A,哪個是 B 呢?
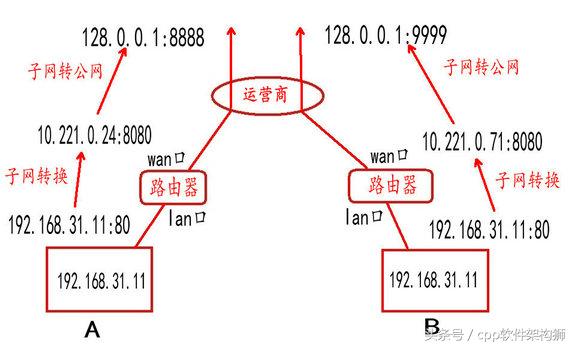
**分析:**為了方便大家理解,我們把 IP 的轉化方向反過來分析(準確來說,公網轉局域網)。A 電腦的 IP 是局域網 IP(192.168.31.11),這個 IP(192.168.31.11)是從路由器的 lan口分配的。
當我們上百度的時候,經過路由器的 wan口,進行相應的IP、端口轉化:192.168.31.11:80 -> 10.221.0.24:8080,所以,從 wan口出去的地址為:10.221.0.24:8080。如下圖:

最后,經過運營商,運營商那邊會做相應的端口映射(而且是動態端口映射),子網 IP(10.221.0.24:8080)轉化為公網 IP(128.0.0.1:8888),通過這個公網 IP 去訪問百度服務器。

同理,B 的過程也是一樣。通過這樣的層層端口映射,最終保證地址(IP + 端口)的唯一性。A 和 B 訪問百度服務器,盡管它們的局域網 IP 是一樣的,但是最終它們訪問百度的地址(IP + 端口)是唯一的,所以,百度服務器回復時,原路返回時能夠區分到底給誰回。
答案解析
-
概念
內網(局域網)
指在某一區域內由多臺計算機互聯成的計算機組。一般是方圓幾千米以內。局域網可以實現文件管理、應用軟件共享、打印機共享、工作組內的日程安排、電子郵件和傳真通信服務等功能。局域網是封閉型的,可以由辦公室內的兩臺計算機組成,也可以由一個公司內的上千臺計算機組成。
外網(廣域網)
又稱公網。是連接不同地區局域網或城域網計算機通信的遠程網。通常跨接很大的物理范圍,所覆蓋的范圍從幾十公里到幾千公里,它能連接多個地區、城市和國家,或橫跨幾個洲并能提供遠距離通信,形成國際性的遠程網絡。廣域網并不等同于互聯網。
-
內網和外網的區別
(1)ip地址設置的區別,一般內網有自己的IP號段,也不會和互聯網號段沖突,內網就是從路由器以下開始的,而且IP都是以192開頭的IP。一般是不能擁有外網IP的,因為個人或者小群體用外網也是一種資源浪費,所以一般都是通過內網去上網的,外網Ip一般都是用于公司企業,學校等機構的。
(2)內網電腦連接外網需要一個統一出口,可能被限制一些不必要的訪問,而外網就不經路由器或交換機就可以上網的網絡,可以直接被外界所訪問到,無需經如何設備,直接連接電腦。
(3)內網相對外網會多一層安全防火墻(外網路由),相對來說抵御來自外網的攻擊能力會好一些;內網不足之處在于,可能會遭到來自內部的攻擊;因為要共享帶寬,相對網速可能會慢些(終端越多越慢)。
送信息,可以實現雙向通信。舉例:對講機。
3. **雙工:**全雙工數據通信允許數據同時在兩個方向上傳輸,因此,全雙工通信是兩個單工通信方式的結合,它要求發送設備和接收設備都有獨立的接收和發送能力;在同一時間可以同時接受和發送信息,實現雙向通信。舉例:電話通信。
答案解析
擴展資料:
單工、半雙工和全雙工是電信計算機網絡中的三種通信信道。這些通信信道可以提供信息傳達的途徑。通信信道可以是物理傳輸介質或通過多路復用介質的邏輯連接。物理傳輸介質是指能夠傳播能量波的材料物質,例如數據通信中的導線。并且邏輯連接通常指電路交換連接或分組模式虛擬電路連接,例如無線電信通道。由于通信信道的幫助,信息可以無障礙地傳輸。
單工模式一般用在只向一個方向傳輸數據的場合。例如計算機與打印機之間的通信是單工模式,因為只有計算機向打印機傳輸數據,而沒有相反方向的數據傳輸。還有在某些通信信道中,如單工無線發送等。
1.59 說一說內網和外網通信的過程。
參考回答
-
公有IP和私有IP概念
公有地址(Public address):由 Inter NIC(Internet Network Information Center 因特網信息中心)負責。這些 IP 地址分配給注冊并向Inter NIC提出申請的組織機構,公有 IP 全球唯一,通過它直接訪問因特網(直接能上網)。
私有地址(Private address):屬于非注冊地址,專門為組織機構內部使用,說白了,私有 IP 不能直接上網。
家里路由器分出來的IP就是私有IP(局域網IP),真正擁有公有IP的是運營商(電信、移動、聯通),運營商購買了一些公有IP(外網IP),然后通過這些公有IP分出來,再分給一個一個的用戶使用。所以,A 家庭的局域網 IP 和 B 家庭的局域網 IP 相同很正常,但是,最終 A 和 B 能上網(數據走出去)還是通過運營商的公有 IP,畢竟,公有 IP 的資源有限,這一片區域的用戶使用的很有可能(實際上就是這樣的)是同一個公有 IP。
-
內網和外網通信過程
內網和外網的通信是通過端口映射來實現的。
我們平時經過路由器,通過寬帶,最終去到運營商那邊,數據是從運營商出去,最終數據是回到運營商那邊,運營商再把數據發送到用戶的電腦。路由器,至少有兩個端口:WAN 口和 LAN 口。WAN口接外部 IP 地址用,通常指的是出口,轉發來自內部 LAN 接口的 IP 數據包,這個口的 IP 是唯一的。LAN口接內部 IP 地址用,LAN 內部是交換機。
**舉例:**假如 A 和 B 的局域網(內網) IP 相同(192.168.31.11),當他們同時訪問百度服務器(外網)的時候,百度服務器如何區分哪個是 A,哪個是 B 呢?
[外鏈圖片轉存中…(img-SvX3yxD7-1641473552266)]
[外鏈圖片轉存中…(img-q1H9jRei-1641473552267)]
**分析:**為了方便大家理解,我們把 IP 的轉化方向反過來分析(準確來說,公網轉局域網)。A 電腦的 IP 是局域網 IP(192.168.31.11),這個 IP(192.168.31.11)是從路由器的 lan口分配的。
當我們上百度的時候,經過路由器的 wan口,進行相應的IP、端口轉化:192.168.31.11:80 -> 10.221.0.24:8080,所以,從 wan口出去的地址為:10.221.0.24:8080。如下圖:
[外鏈圖片轉存中…(img-zihWaNk2-1641473552268)]
最后,經過運營商,運營商那邊會做相應的端口映射(而且是動態端口映射),子網 IP(10.221.0.24:8080)轉化為公網 IP(128.0.0.1:8888),通過這個公網 IP 去訪問百度服務器。
[外鏈圖片轉存中…(img-jJ17eWtx-1641473552268)]
同理,B 的過程也是一樣。通過這樣的層層端口映射,最終保證地址(IP + 端口)的唯一性。A 和 B 訪問百度服務器,盡管它們的局域網 IP 是一樣的,但是最終它們訪問百度的地址(IP + 端口)是唯一的,所以,百度服務器回復時,原路返回時能夠區分到底給誰回。
答案解析
-
概念
內網(局域網)
指在某一區域內由多臺計算機互聯成的計算機組。一般是方圓幾千米以內。局域網可以實現文件管理、應用軟件共享、打印機共享、工作組內的日程安排、電子郵件和傳真通信服務等功能。局域網是封閉型的,可以由辦公室內的兩臺計算機組成,也可以由一個公司內的上千臺計算機組成。
外網(廣域網)
又稱公網。是連接不同地區局域網或城域網計算機通信的遠程網。通常跨接很大的物理范圍,所覆蓋的范圍從幾十公里到幾千公里,它能連接多個地區、城市和國家,或橫跨幾個洲并能提供遠距離通信,形成國際性的遠程網絡。廣域網并不等同于互聯網。
-
內網和外網的區別
(1)ip地址設置的區別,一般內網有自己的IP號段,也不會和互聯網號段沖突,內網就是從路由器以下開始的,而且IP都是以192開頭的IP。一般是不能擁有外網IP的,因為個人或者小群體用外網也是一種資源浪費,所以一般都是通過內網去上網的,外網Ip一般都是用于公司企業,學校等機構的。
(2)內網電腦連接外網需要一個統一出口,可能被限制一些不必要的訪問,而外網就不經路由器或交換機就可以上網的網絡,可以直接被外界所訪問到,無需經如何設備,直接連接電腦。
(3)內網相對外網會多一層安全防火墻(外網路由),相對來說抵御來自外網的攻擊能力會好一些;內網不足之處在于,可能會遭到來自內部的攻擊;因為要共享帶寬,相對網速可能會慢些(終端越多越慢)。
(4)內網的ip可以經常換,可以自己定義規則;而外網的ip一般都是固定的,你裝好寬帶的時候,你的ip就固定下來了。


的使用)





![[轉]windows系統激活](http://pic.xiahunao.cn/[轉]windows系統激活)




在線教育平臺(六))





