目錄
1.視覺中的Attention
?2.VIT框架(圖像分類,不需要decoder)
2.1整體框架
2.2.CNN和Transformer遇到的問題
2.3.1CNN
2.3.2Transformer
2.3.3二者對比
2.4.公式理解
3TNT
參考文獻
1.視覺中的Attention
? ? ? 對于人類而言看到一幅圖可以立即區分背景和主體,我們希望計算機也可以清楚區分背景和主體,這樣就可以專注在主體上提取特征。?

?2.VIT框架(圖像分類,不需要decoder)
2.1整體框架
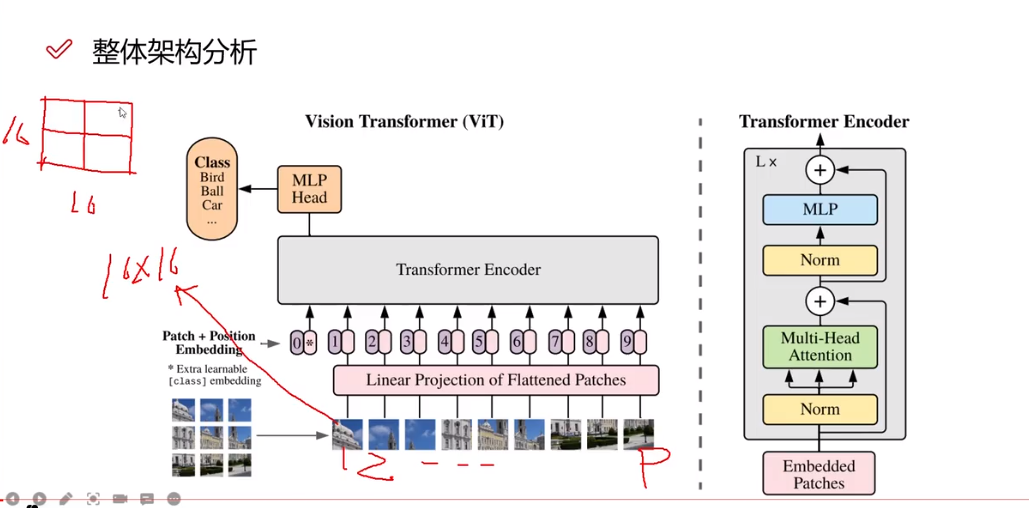
? ? ? 如下圖所示,transformer框架需要輸入為序列形式,但圖像是高維的,所以首先要對圖像預處理,簡單理解,假設下圖是一個30*30*3的輸入,將其分為9塊,每塊大小為10*10*3,再對其做一個卷積處理,變成300*1。?
? ? ? 同樣圖像處理也要考慮到位置編碼(Position Embedding),有兩種方式,一種是直接再一維空間用1,2,3,4....,一種是在二維空間用(1,1),(1,2)...。一維,二維對結果影響不大(僅圖像分類)。但編碼方式,也是一個創新點。
? ? ? 下圖框架為分類任務,多加了一部分![]() ,簡單理解,目的在于整合所有輸入量,最后用其進行分類
,簡單理解,目的在于整合所有輸入量,最后用其進行分類
? ? ? ?和文本處理,區別在于多了一個圖像的數據處理,要將高維變成序列形式,
? ? ? ?最后說下下圖右的框架,Norm是歸一化處理,Multi-Head Attention是多頭注意力機制,MLP是全連接層。

2.2.CNN和Transformer遇到的問題
2.3.1CNN
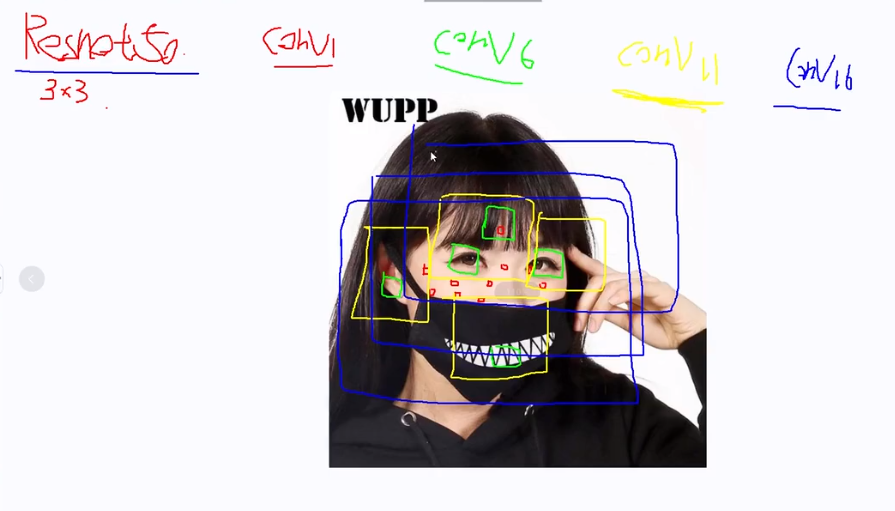
? ? ? 以Resnet50為例,首先回憶一下感受野的概念,即當前層神經元(特征圖)可以看到的原圖的區域,我們假設conv1,conv6,conv11,conv16,此時我們想做一個分類任務,區分這個女生好不好看,對于conv1它的感受野為紅色小框,顯然特征過小,conv4為綠色小框,此時已經能看到眼睛,但還是不足以做出判斷,conv11為黃色框,此時已經能看到較多的局部特征,但還不足以準確判斷,最后來到conv16,此時足以看到整個臉,可以進行判別,但我們發現想要得到一個全局信息這個過程需要多層嵌套才能實現,比較麻煩。?
? ? ? 對比一下,CNN通常第一層卷積用3*3的核也就是說只能看到原圖3*3大小的區域,可能要最后一層才能看到全局,而transformer可以實現第一層就看到全局。
2.3.2Transformer
transformer對于CNN需要極大數據集才能得到好的結果。
2.3.3二者對比

2.4.公式理解
? ? ? E為全連接層,目的是對輸入數據進行預處理,就是將高維圖像變成序列形式,假設P*P=196,就是圖像分割的塊數,像上面將圖分為9塊的意思,C=256是每一塊含有的向量,D=512,目的是將256映射成512,N=196是位置信息編碼,+1是因為圖像分類任務要多一個輸入,LN是歸一化處理,MSA是多頭自注意力機制,MLP是全連接層。![]() 類似于殘差鏈接 。可以對比流程圖理解。
類似于殘差鏈接 。可以對比流程圖理解。

3TNT
假設VIT每一個patch是16*16.TNT希望這個patch更小。
? ? ?
? ? ? 基于這個思想,TNT將數據預處理,分為外部和內部兩塊,外部和VIT一樣,內部就是對外部的信息再次細分,比方說外部一個patch是16*16,內部就用4*4的塊進行分割,下面超像素的概念就是不想按照1*1大小進行分割,多選擇幾個像素點分割。
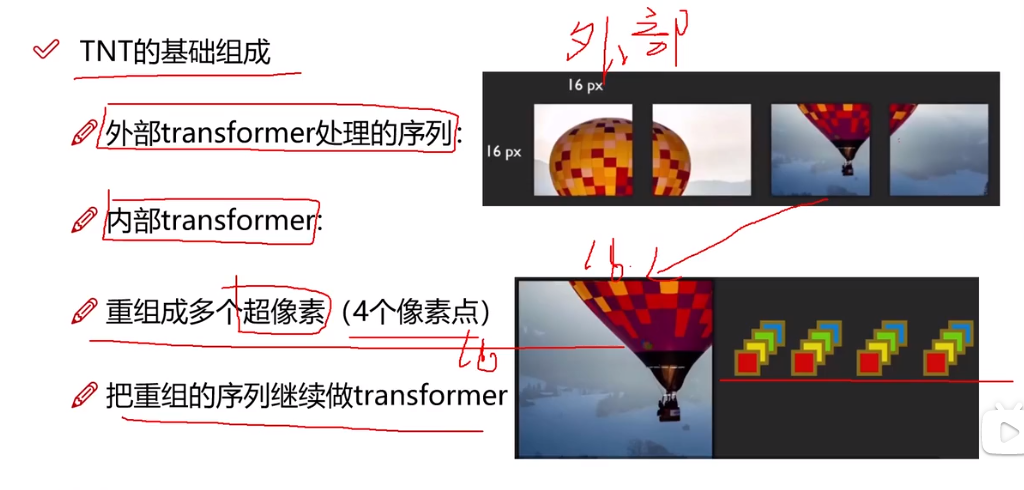
? ? ? 在實際應用中,如下圖所示,將一個圖分為4塊(外部),VIT中是直接預處理后變成一個4維向量輸入了,而在TNT中,假設第3塊(外部),進行了一個內部分割,然后重構后也變成一個4維向量,將其加入外部的4維向量。同樣內外部都做位置編碼時效果最好。

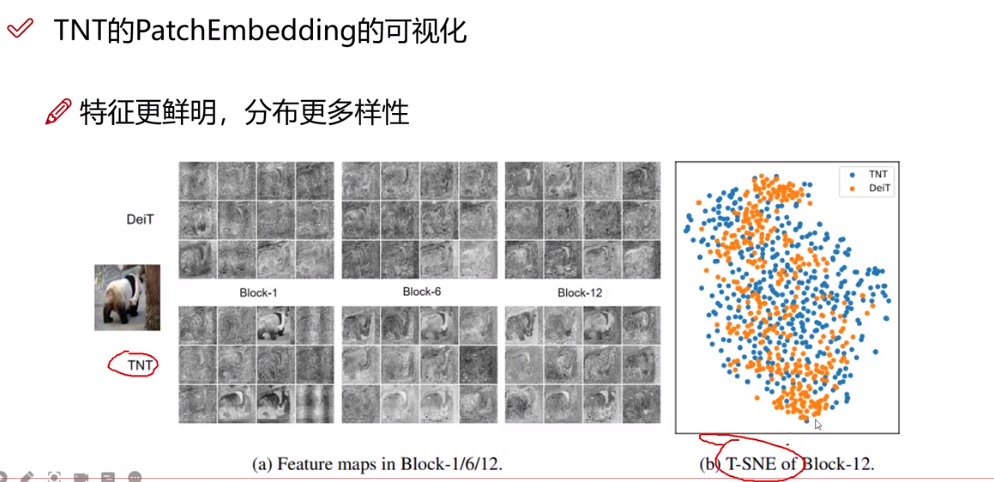
? ? ? 從可視化角度看,TNT在不同層下得到的結果更好,從T-SNE看,TNT更集中,效果更好。
參考文獻
1.【VIT算法模型源碼解讀】1-項目配置說明1.mp4_嗶哩嗶哩_bilibili

)




![[英語單詞] compat; compatibility;compact;entry_SYSENTER_compat](http://pic.xiahunao.cn/[英語單詞] compat; compatibility;compact;entry_SYSENTER_compat)

![三、python Django ORM postgresql[數據定時備份、數據恢復]](http://pic.xiahunao.cn/三、python Django ORM postgresql[數據定時備份、數據恢復])



![C#調用C++ DLL傳參byte[]數組字節值大于127時會變為0x3f的問題解決](http://pic.xiahunao.cn/C#調用C++ DLL傳參byte[]數組字節值大于127時會變為0x3f的問題解決)


 對比 C++ memcpy())

電機凈化報警Proteus仿真設計(程序+Proteus仿真+配套資料等))

