Flink之Task解析
??對Flink的Task進行解析前,我們首先要清楚幾個角色TaskManager、Slot、Task、Subtask、TaskChain分別是什么
| 角色 | 注釋 |
|---|---|
| TaskManager | 在Flink中TaskManager就是一個管理task的進程,每個節點只有一個TaskManager |
| Slot | Slot就是TaskManager中的槽位,一個TaskManager中可以存在多個槽位,取決于服務器資源和用戶配置,可以在槽位中運行Task實例 |
| Task | 其實Task在Flink中就是一個類,其中可以包含一個或多個算子,這個取決于算子鏈的構成 |
| SubTask | SubTask就是Task類的并行實例可以是一個或多個,也就是說當代碼執行的那一刻開始,就根據用戶所設置或者默認的并行度創建出多個SubTask |
| TaskChain | TaskChain就是算子鏈,何為算子鏈?就是在一個Task實例中出現的串行算子,算子間必須是OneToOne模式且并行度相同. |
??上面對幾個角色進行了一個簡單的闡述,后面會結合圖解和偽代碼進行講解,這里我們以計算中比較經典wordcount為例子,偽代碼如下所示:
public class FLinkWordCount {public static void main(String[] args) throws Exception {// 創建流處理環境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();\// 設置并行度3env.setParallelism(3)// 讀取數據文件DataStreamSource<String> streamSource = env.readTextFile("xxx");// 轉大寫DataStreamSource<String> upperCaseSource = streamSource.map(word -> word.toUpperCase())// 轉成tuple2格式,計數1SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = upperCaseSource.map(word -> Tuple2.of(word, 1));// 按照單詞分組KeyedStream<Tuple2<String, Integer>, String> keyed = mapStream.keyBy(tup -> tup.f0);// 求和keyed.sum("f1")env.execute();}
}
??上面的代碼中我們使用了兩次map,一次keyBy,一次sum算子,我們下面就結合這幾個算子進行講解,講解之前有兩個條件需要先記住:
- 同一個Task并行實例不能放在同一個TaskSlot上運行,一個TaskSlot上可以運行多個不同的Task并行實例
- 同一個共享組的算子允許共享槽位,不同共享組的算子決不允許共享槽位
??上面這兩句話一定要記牢,以便于后面的理解.
算子鏈劃分及Task槽位分配
算子鏈劃分
可以根據上面的代碼理解下圖:
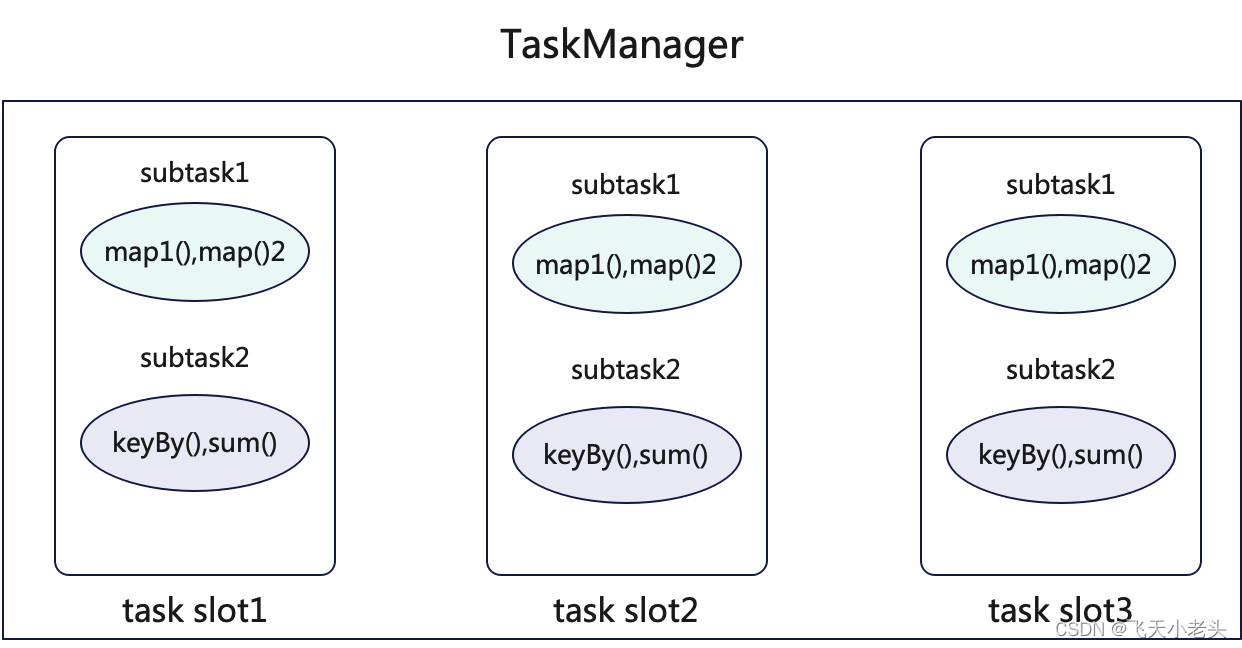
上圖中我們可以看到兩個map組成一個task chain,keyBy和sum組成一個task chain,這里說一下原因,首先就是兩個map的并行度是一致的,而且是OneToOne模式,所以可以將兩個map綁定成一個算子鏈,并將其放入到一個SubTask中,而到了keyBy這里為什么不能再放入到一個task chain中,這里我們可以思考一下,keyBy時會發生什么?以spark的角度來說會發生shuffle對吧,這就導致了不能滿足OneToOne的模式,簡單來說我們也可以想清楚,如果keyBy和map組成一個task chain那么還怎么做wordcount?
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-bckucHbv-1692099761760)(/Users/jinlong/data/Typora_WorkSpase/FlinkTask/task2.png)]](https://img-blog.csdnimg.cn/589a720a88b84aebabb5ef71b1da22af.png)
通過上圖應該很容易理解了.
Task槽位分配
??上面講了關于task chain怎么劃分的,為什么這樣劃分,這里講一下為什么同一個Task的并行實例(SubTask)不能在同一個task slot中.其實這個也很容易就想清楚,如果同一Task的多個SubTask都出現在一個task slot中那么還有什么意義呢?當這些SubTask出現在一個task slot中時就會發生串行計算,那并行的意義也就沒有了.
??同時這種機制也保證了任務的容錯性,也就是說對于同一個Task一旦某一個task slot出現異常的情況,其他的task slot中的SubTask還能正常運行,如果將這些SubTask放到一個task slot中,當這個task slot出現異常情況時,就會影響整個任務的執行.
??總結來說,這種設計保證了Flink任務的隔離性、容錯性、資源利用性.這里用圖解的方式便于大家記憶,如下:
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-rlgqeo6A-1692099761760)(/Users/jinlong/data/Typora_WorkSpase/FlinkTask/task3.png)]](https://img-blog.csdnimg.cn/c0e80184d18b44cebf8faaaa72c59ca8.png)
槽位共享及算子鏈斷/連
槽位共享
??前面講過同一個Task的多個SubTask不能出現在一個task slot中,但是不同Task的SubTask是可以共享同一個task slot的,但是在Flink中有一個機制,就是用戶(開發人員)可以自定義不同的算子間是否可以共享同一個task slot,如上面的例子中兩個map的并行度一致并且符合OneToOne的模式,在正常情況下必然會會分到一個task chain中,但是Flink給用戶提供了的slot group的概念,也就是說用戶可以將這兩個map分配到不同的slot group中,這種情況下兩個map就不會劃分到一個task chain中,試想一下當兩個map都不允許共享同一個task slot時,怎么可能劃分到同一個task chain中呢?
??偽代碼如下:
public class FLinkWordCount {public static void main(String[] args) throws Exception {// 創建流處理環境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();\// 設置并行度3env.setParallelism(1)// 讀取數據文件DataStreamSource<String> streamSource = env.readTextFile("xxx");// 轉大寫DataStreamSource<String> upperCaseSource = streamSource.map(word -> word.toUpperCase())// 通過slotSharingGroup()將upperCaseSource作為一個分組"g1"SingleOutputStreamOperator<String> slotGroup1 = upperCaseSource.slotSharingGroup("g1");// 轉成tuple2格式,計數1SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = upperCaseSource.map(word -> Tuple2.of(word, 1));// 通過slotSharingGroup()將mapStream作為一個分組"g3"SingleOutputStreamOperator<Tuple2<String, Integer>> slotGroup2 = mapStream.slotSharingGroup("g2");// 按照單詞分組KeyedStream<Tuple2<String, Integer>, String> keyed = mapStream.keyBy(tup -> tup.f0);// 求和keyed.sum("f1")env.execute();}
}
上面的代碼中我們將upperCaseSource和mapStream分成了兩個task slot,這樣兩個map就不可以共享相同的task slot,同時代碼中將并行度改為了1,這樣便于圖解,如下圖:
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-saLgMu0Q-1692099761760)(/Users/jinlong/data/Typora_WorkSpase/FlinkTask/task4.png)]](https://img-blog.csdnimg.cn/c791831068674b58b13c2987e671c6a3.png)
如果說集群中總task slot只有3個,并且在代碼中兩個map設置了不同的task slot且兩個map的并行度都為3時會怎么樣?很簡單,提交任務時就會報錯,因為提交任務所需要的資源已經超出了集群的資源.
??這里說一下對于對task slot進行分組處理的實際用處,就以代碼中兩個map為例子,在實際的業務中如果兩個map處理的數據量都極大,如果將兩個map的計算都放到一個節點的一個task slot時會發生什么?數據的積壓、任務異常失敗等等都有可能發生,但是有slotSharingGroup我們就可以保證同一個task slot不會承載過大的計算任務,也就達到了資源合理分配的目的.
算子鏈斷/連
??前面講了關于將兩個map進行slotSharingGroup后會將兩個map劃分到不同的task chain,如果有這樣一個情況兩個map滿足OneToOne的模式且并行度相同時,我們不使用slotSharingGroup能否將兩個map劃分成不同的task chain?答案是當然可以的,Flink為我們提供了對應的API,偽代碼如下:
public class FLinkWordCount {public static void main(String[] args) throws Exception {// 創建流處理環境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();\// 設置并行度3env.setParallelism(3)// 讀取數據文件DataStreamSource<String> streamSource = env.readTextFile("xxx");// 轉大寫DataStreamSource<String> upperCaseSource = streamSource.map(word -> word.toUpperCase())// 轉成tuple2格式,計數1SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = upperCaseSource.map(word -> Tuple2.of(word, 1));// 將mapStream劃分到一個新的task chain中SingleOutputStreamOperator<Tuple2<String, Integer>> newTaskChainMapStream = mapStream.startNewChain();// 按照單詞分組KeyedStream<Tuple2<String, Integer>, String> keyed = mapStream.keyBy(tup -> tup.f0);// 求和keyed.sum("f1")env.execute();}
}
在上面代碼中我們調用了startNewChain()后就可以將mapStream劃分到一個新的task chain中,這樣的情況下,兩個map既屬于不同的task chain又可以共享同一個task slot,如下圖:
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-jOIlz8uH-1692099761760)(/Users/jinlong/data/Typora_WorkSpase/FlinkTask/task5.png)]](https://img-blog.csdnimg.cn/2314559b6cad40358b5606dec3b91305.png)
以上就是對于Task的講解,如有錯誤歡迎指出,如有問題共同探討.



_kaic)



k8s及kuboard V3)





《正則表達式-grep工具》)

按鍵掃描與定時器中斷)
 CCodec Native服務實現分析)
微分中值定理和導數的應用)

