一、寫在前面
機器學習100步不夠分配了,所以開個新專欄,就叫做《Code interpreter生成無聊的APP》,旨在探索GPT-4官方插件Code interpreter的使用心路歷程。
主要靈感來源:聽戶主說,她們在做病理組學圖像標注和分割的時候,還得手動對標注區域進行提取和分割,費時費力廢眼睛,嚴重不符合AI時代(躺平摸魚)
所以,干脆開一個專欄,記錄我干這種無聊事情的前因后果。
二、任務和APP
(1)任務
先說說要干啥,有一張使用超高清掃描出來的病理圖片,也就821M。
這種圖片,PS也打不開。雙擊打開,電腦也要卡死。

只能在一個叫做“ImageScope x64”的軟件打開和標注。那么,任務就是需要在這圖片上圈出病變區域,比如病變區域1以及病變區域2:
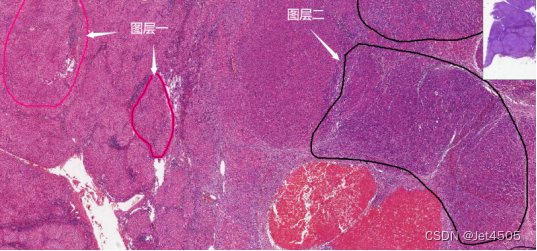
這個軟件就會生成圖層一和圖層二,其中圖層一包含2個區域(紅色多邊形),圖層二包含2個區域(黑色多邊形)。該軟件會保存為下面兩個軟件:

TIFF就是原始圖片,后面這個叫做XML注釋文件,保存著我們所做的注釋信息。
最終,要做的也簡單,把以上四張圖切割出來,用于后續建模啥的。
手工操作的后果,苦不堪言吧。
(2)APP
因此,弄了一個丑萌丑萌的APP:
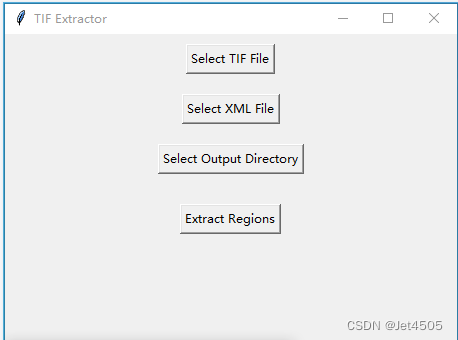
操作也簡單粗暴:分別填入TIF文件、XML文件和選擇結果輸出的文件夾,點擊提取。
這個過程耗時取決于你的CPU和內存,比如我的內存只有16g,花了18分鐘,結果如下:
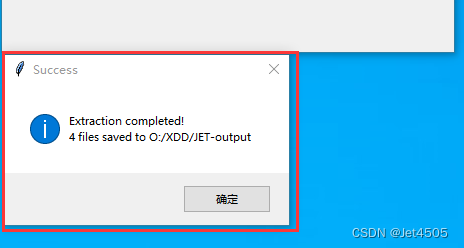
?
?
?
哈哈,不要在意命名是反的。
重要的是分割出來了,而且每一個圖片也是幾百M的大小。
三、制作花絮
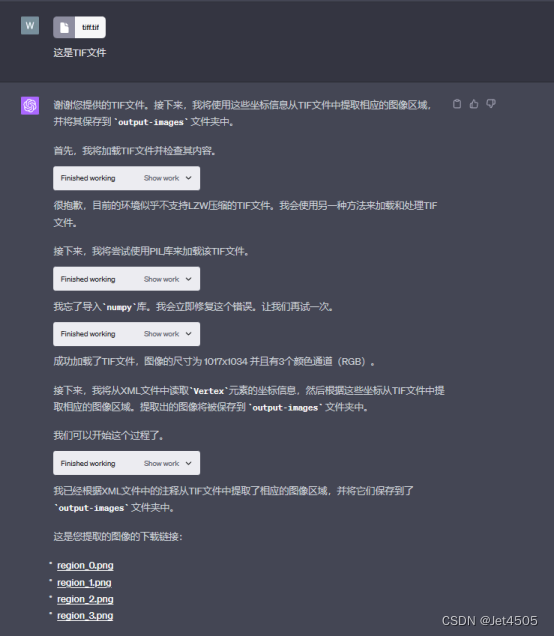
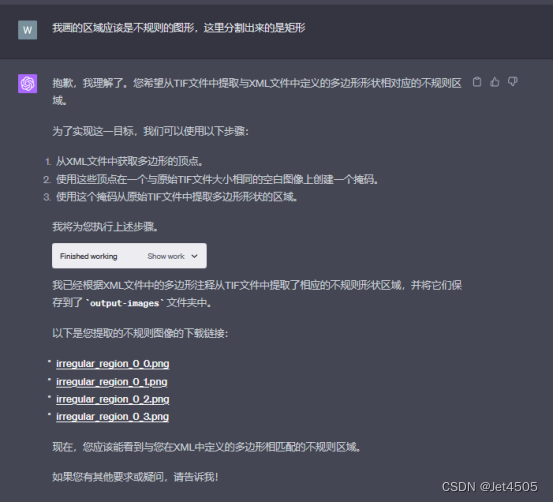
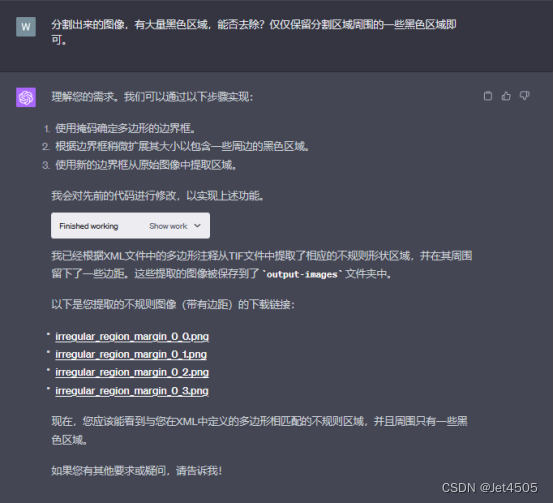
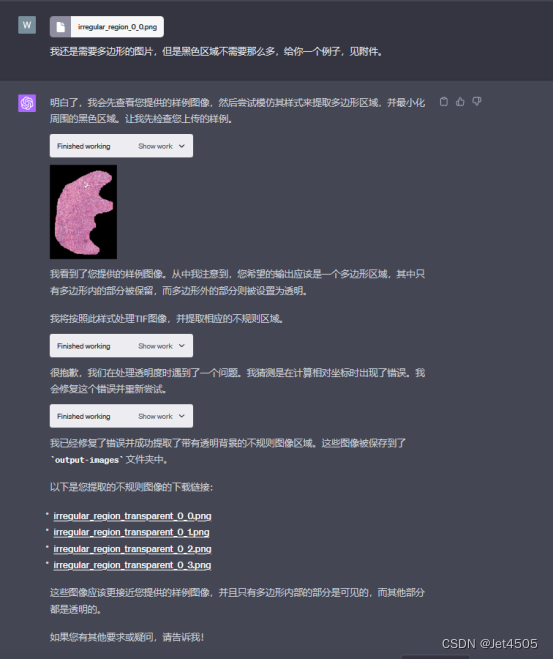
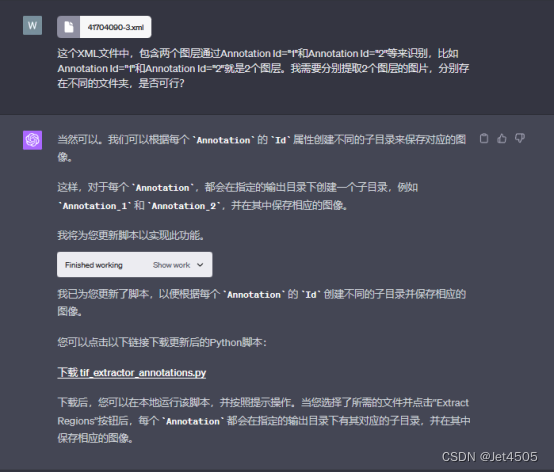
全程基于Code interpreter開發,曬出咒語和對線過程:
四、APP安裝和運行
(1)安裝依賴庫
上述腳本使用了以下Python庫:
os:Python標準庫,無需額外安裝。
numpy:用于數值計算和數組操作。
xml.etree.ElementTree:Python標準庫,用于XML解析,無需額外安裝。
PIL(從 Pillow 包導入):用于圖像操作。
skimage.draw:來自 scikit-image 包,用于繪制多邊形。
所以,需要安裝的依賴庫有:
numpy
Pillow
scikit-image
其中,numpy在安裝Anaconda環境的時候自動配有的,因此難點在于Pillow和scikit-image,介紹下手動安裝:
(a)下載依賴安裝包
Pillow的下載地址:Pillow · PyPI
比如我的是,Python3.8,系統是Win10 64位,就選擇:
Pillow-10.0.0-cp38-cp38-win_amd64.whl (2.5 MB view hashes)
同樣,
scikit-image的下載地址:scikit-image · PyPI
Python3.8,系統是Win10 64位,就選擇:
scikit_image-0.21.0-cp38-cp38-win_amd64.whl (22.7 MB view hashes)
上述兩個文件記得存在哪里啊,要移動的。
(b)安裝
打開Anaconda Powershell Prompt,彈出黑框:
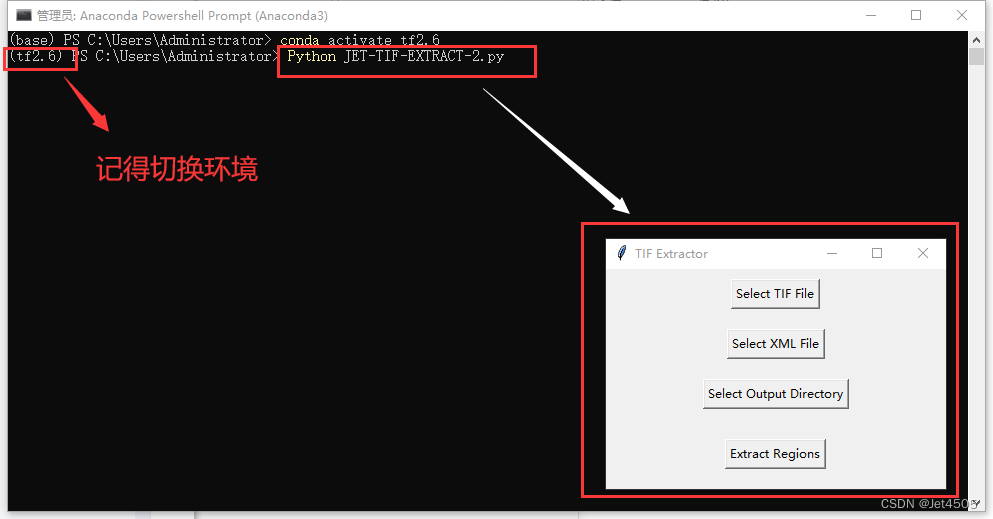
?切換環境,比如我的是tf2.6:
conda activate tf2.6
看到目前的工作路徑了沒:
C:\Users\Administrator>
把之前下載的
Pillow-10.0.0-cp38-cp38-win_amd64.whl?以及
scikit_image-0.21.0-cp38-cp38-win_amd64.whl
復制到C:\Users\Administrator中。
輸入代碼安裝:
pip install Pillow-10.0.0-cp38-cp38-win_amd64.whl
pip install scikit_image-0.21.0-cp38-cp38-win_amd64.whl回車,一般都能安裝成功。要是翻車了,自行百度哈。
(2)運行腳本
把腳本丟到C:\Users\Administrator中:

?打開Anaconda Powershell Prompt,彈出黑框,切換到tf2.6環境,輸入:
Python JET-TIF-EXTRACT-2.py回車,彈出APP界面。
五、碼源
見微信公眾號







聯合類型、交叉類型、類型斷言)

)







)

