1寫在前面
今天可算把key搞好了,不得不說🏥里手握生殺大權的人,都在自己的能力范圍內盡可能的難為你。😂
我等小大夫也是很無奈,畢竟奔波霸、霸波奔是要去抓唐僧的。 🤐
好吧,今天是詞云(Wordcloud)教程,大家都說簡單,但實際操作起來又有一些難度,一起試試吧。😋
2用到的包
rm(list = ls())
library(tidyverse)
library(tm)
library(wordcloud)
3示例數據
這里我準備好了2個文件用于繪圖,首先是第一個文件,每行含有n個詞匯。🤣
dataset <- read.delim("./wordcloud/dataset.txt", header=FALSE)
DT::datatable(dataset)
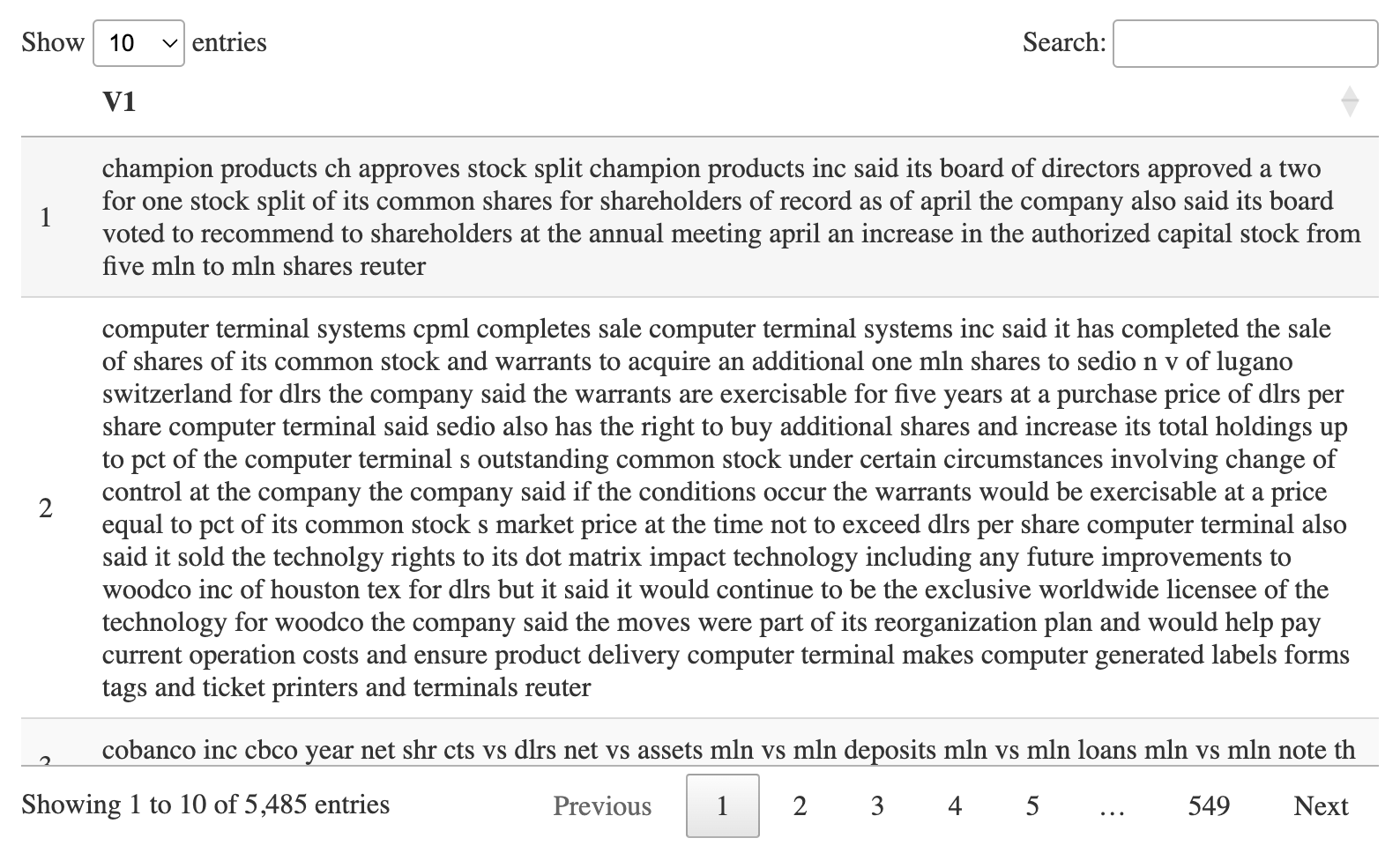
接著是第2個文件,代表dataset文件中每一行的label。🥸
dataset_labels <- read.delim("./wordcloud/labels.txt",header=FALSE)
dataset_labels <- dataset_labels[,1]
dataset_labels_p <- paste("class",dataset_labels,sep="_")
unique_labels <- unique(dataset_labels_p)
unique_labels

4數據初步整理
然后我們利用sapply函數把數據整理成list。😘
可能會有小伙伴問sapply和lapply有什么區別呢!?😂
ok, sapply()函數與lapply()函數類似,但返回的是一個簡化的對象,例如向量或矩陣。😜
如果應用函數的結果具有相同的長度和類型,則sapply()函數將返回一個向量。
如果結果具有不同的長度或類型,則sapply()函數將返回一個矩陣。😂
dataset_s <- sapply(unique_labels,function(label) list( dataset[dataset_labels_p %in% label,1] ) )
str(dataset_s)
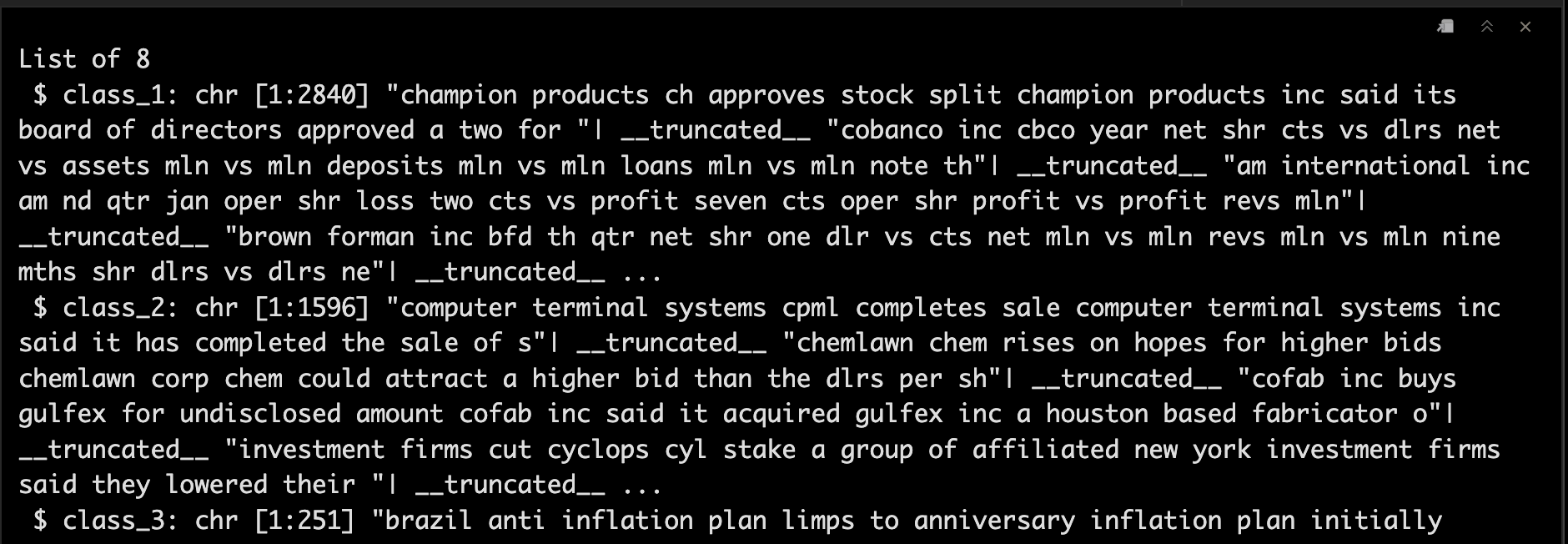
5數據整理成Corpus
接著我們把上面整理好的list中每個元素都整理成一個單獨的Corpus。🤩
dataset_corpus <- lapply(dataset_s, function(x) Corpus(VectorSource( toString(x) )))
然后再把Cporus合并成一個。🧐
dataset_corpus_all <- dataset_corpus
6去除部分詞匯
修飾一下, 去除標點、數字、無用的詞匯等等。😋
dataset_corpus_all <- lapply(dataset_corpus_all, tm_map, removePunctuation)
dataset_corpus_all <- lapply(dataset_corpus_all, tm_map, removeNumbers)
dataset_corpus_all <- lapply(dataset_corpus_all, tm_map, function(x) removeWords(x,stopwords("english")))
words_to_remove <- c("said","from","what","told","over","more","other","have",
"last","with","this","that","such","when","been","says",
"will","also","where","why","would","today")
dataset_corpus_all <- lapply(dataset_corpus_all, tm_map, function(x)removeWords(x, words_to_remove))
7計算term matrix并去除部分詞匯
document_tm <- TermDocumentMatrix(dataset_corpus_all)
document_tm_mat <- as.matrix(document_tm)
colnames(document_tm_mat) <- unique_labels
document_tm_clean <- removeSparseTerms(document_tm, 0.8)
document_tm_clean_mat <- as.matrix(document_tm_clean)
colnames(document_tm_clean_mat) <- unique_labels
# 去除長度小于4的term
index <- as.logical(sapply(rownames(document_tm_clean_mat), function(x) (nchar(x)>3) ))
document_tm_clean_mat_s <- document_tm_clean_mat[index,]
head(document_tm_clean_mat_s)
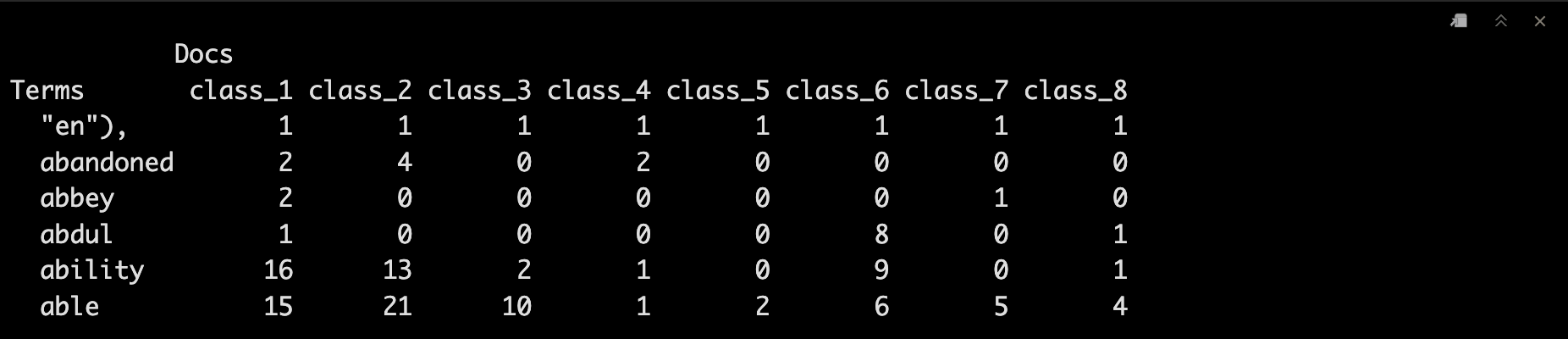
8可視化
8.1 展示前500個詞匯
comparison.cloud(document_tm_clean_mat_s,
max.words=500,
random.order=F,
use.r.layout = F,
scale = c(10,0.4),
title.size=1.4,
title.bg.colors = "white"
)

8.2 展示前2000個詞匯
comparison.cloud(document_tm_clean_mat_s,
max.words=2000,
random.order=F,
use.r.layout = T,
scale = c(6,0.4),
title.size=1.4,
title.bg.colors = "white"
)
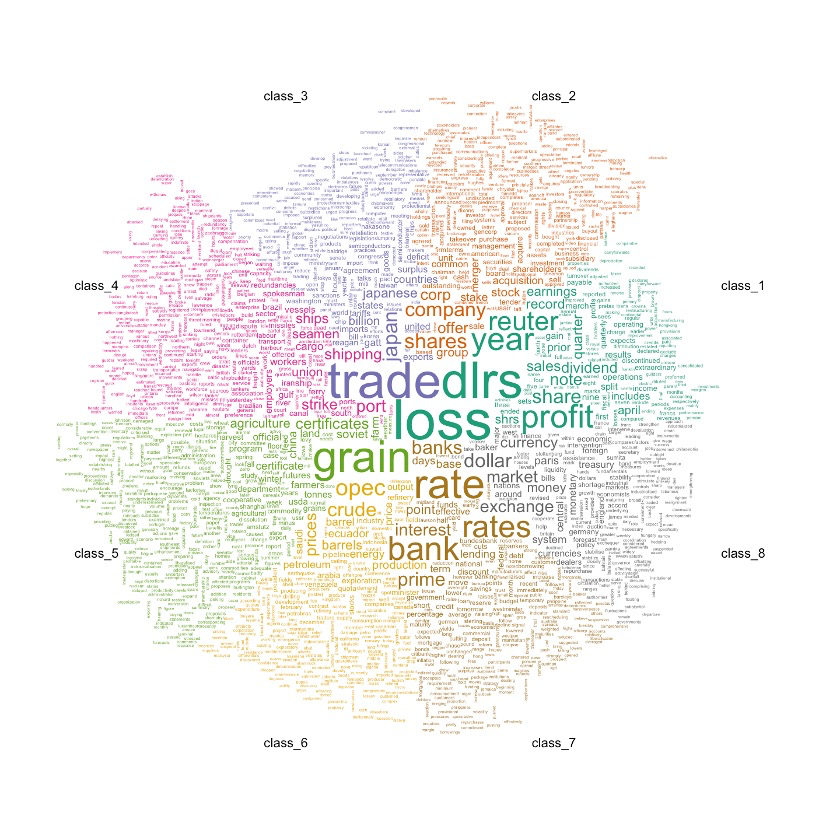
8.3 展示前2000個common詞匯
commonality.cloud(document_tm_clean_mat_s,
max.words=2000,
random.order=F)


點個在看吧各位~ ?.???? ??? ?
📍 🤩 LASSO | 不來看看怎么美化你的LASSO結果嗎!?
📍 🤣 chatPDF | 別再自己讀文獻了!讓chatGPT來幫你讀吧!~
📍 🤩 WGCNA | 值得你深入學習的生信分析方法!~
📍 🤩 ComplexHeatmap | 顏狗寫的高顏值熱圖代碼!
📍 🤥 ComplexHeatmap | 你的熱圖注釋還擠在一起看不清嗎!?
📍 🤨 Google | 谷歌翻譯崩了我們怎么辦!?(附完美解決方案)
📍 🤩 scRNA-seq | 吐血整理的單細胞入門教程
📍 🤣 NetworkD3 | 讓我們一起畫個動態的桑基圖吧~
📍 🤩 RColorBrewer | 再多的配色也能輕松搞定!~
📍 🧐 rms | 批量完成你的線性回歸
📍 🤩 CMplot | 完美復刻Nature上的曼哈頓圖
📍 🤠 Network | 高顏值動態網絡可視化工具
📍 🤗 boxjitter | 完美復刻Nature上的高顏值統計圖
📍 🤫 linkET | 完美解決ggcor安裝失敗方案(附教程)
📍 ......
本文由 mdnice 多平臺發布





聯合類型、交叉類型、類型斷言)

)







)



