數據質量提升
Author Vlad Ri?cu?ia is joined for this article by co-authors Wayne Yim and Ayyappan Balasubramanian.
作者 Vlad Ri?cu?ia 和合著者 Wayne Yim 和 Ayyappan Balasubramanian 共同撰寫了這篇文章 。
為什么要數據質量? (Why data quality?)
Data quality is a critical aspect of ensuring high quality business decisions. An estimate of the yearly cost of poor data quality is $3.1 trillion per year for the United States alone, equating to approximately 16.5 percent of GDP.1 For a business such as Microsoft, where data-driven decisions are ingrained within the fabric of the company, ensuring high data quality is paramount. Not only is data used to drive, steer, and grow the Microsoft business from a tactical and strategic perspective, but there are also regulatory obligations to produce accurate data for quarterly financial reporting.
數據質量是確保高質量業務決策的關鍵方面。 據估計,僅在美國,不良數據質量的年成本就高達每年3.1萬億美元,約占GDP的16.5%。1對于像Microsoft這樣的企業,數據驅動型決策根深蒂固,確保高數據質量至關重要。 從戰術和戰略角度來看,不僅使用數據來驅動,指導和發展Microsoft業務,而且還存在監管義務,要求為季度財務報告生成準確的數據。
DataCop的歷史 (History of DataCop)
In the Experiences and Devices (E+D) division at Microsoft, a central data team called IDEAs (Insights Data Engineering and Analytics) generates key business metrics that are used to grow and steer the business. As one of its first undertakings, the team created the Office 365 Commercial Monthly Active User (MAU) measure to track the usage and growth of Office 365. This was a complicated endeavor due to the sheer scale of data, the number of Office products and services involved, and the heterogenous nature of the data pipelines across different products and services. In addition, many other business metrics, tracking the growth and usage of all Office products and services, also needed to be created.
在Microsoft的“體驗和設備”(E + D)部門中,一個名為IDEA(Insights數據工程和分析)的中央數據團隊生成了用于發展和指導業務的關鍵業務指標。 作為其首批任務之一,該團隊創建了Office 365商業月度活動用戶(MAU)措施來跟蹤Office 365的使用和增長。由于數據規模巨大,Office產品和服務的數量龐大,這是一項復雜的工作。涉及的服務以及跨不同產品和服務的數據管道的異構性質。 此外,還需要創建許多其他業務指標,以跟蹤所有Office產品和服務的增長和使用情況。
In the process of creating these critical business metrics, it was clear that generating them at scale and in a reliable way with high data quality was of the utmost importance, as key tactical and strategic business decisions would be based on them. In addition, because of the team’s charge to generate key metrics for release with quarterly earnings, producing high quality data was also a regulatory requirement.
在創建這些關鍵業務指標的過程中,很明顯,以關鍵的戰術和戰略業務決策將基于它們,以高質量的數據大規模可靠地生成它們至關重要。 另外,由于團隊負責生成關鍵指標以按季度收入發布,因此生成高質量數據也是監管要求。
The IDEAs team formed as a data quality team consisting of program management, engineering, and data science representatives, and set out to investigate internal and external data quality solutions. The team examined internal data quality systems and researched public whitepapers from other companies that worked with huge amounts of data. Members of the team also spent a considerable amount of time with LinkedIn, learning about their data quality system called “Data Sentinel”2 to potentially leverage what they had built, as they had already spent a considerable amount of time developing Data Sentinel and are also part of Microsoft.
IDEA團隊組成了一個由程序管理,工程和數據科學代表組成的數據質量團隊,并著手研究內部和外部數據質量解決方案。 該團隊檢查了內部數據質量系統,并研究了處理大量數據的其他公司的公開白皮書。 團隊成員還花了很多時間在LinkedIn上,了解他們稱為“ Data Sentinel”2的數據質量系統,以潛在地利用他們所構建的內容,因為他們已經花費了大量時間來開發Data Sentinel,并且微軟的一部分。
The vision for a data quality platform in IDEAs was that it would be extensible, scalable, able to work with the multiple data fabrics involved, and be leveraged by the wider data science community at Microsoft. For example, data scientists and data analysts should be able to write data quality checks in languages familiar to them such as Python, R, and Scala, among others, and have these data quality checks operate reliably at scale.
IDEA中的數據質量平臺的愿景是,它是可擴展的,可伸縮的,能夠與所涉及的多個數據結構配合使用,并被Microsoft的更廣泛的數據科學社區所利用。 例如,數據科學家和數據分析人員應該能夠用他們熟悉的語言(例如Python,R和Scala等)編寫數據質量檢查,并使這些數據質量檢查可靠地大規模運行。
Another key requirement was to have the data quality platform function as a DaaS, or “Data as a Service,” resulting in the need to apply the same “service rigor” in engineering, operations, and processes that were used to create and operate Office 365, the largest SaaS in the world. This meant having very high engineering standards around change management, monitoring, security controls, and auditability, and tightly integrating with Microsoft incident management systems to ensure that systems operate with high availability, efficiency, and security.
另一個關鍵要求是使數據質量平臺具有DaaS或“數據即服務”的功能,因此需要在用于創建和操作Office的工程,操作和流程中應用相同的“服務嚴格性” 365,世界上最大的SaaS。 這意味著在變更管理,監視,安全控制和可審核性方面具有很高的工程標準,并與Microsoft事件管理系統緊密集成,以確保系統以高可用性,效率和安全性運行。
In the end, the team decided to build its own extensible data quality system from scratch in order for it to function with the scale and reliability of a DaaS and for it to interface with other internal Microsoft data systems. The initial functional specification was written in late 2018, and by early 2019 DataCop was born. Today, DataCop is part of the DataHub platform that also consists of Data Build and Data Catalog. Data Build generates the datasets required by the business in a compliant and scalable way and Data Catalog is a search store for all assets and surfaces with metadata such as data quality scores from DataCop, as well as access and privacy information. Future articles will describe how Data Catalog and Data Build are used to generate the metrics and insights that drive, steer, and grow the E+D business and serve as critical components of the data quality journey.
最后,團隊決定從頭開始構建自己的可擴展數據質量系統,以使其能夠與DaaS的規模和可靠性一起運行,并與其他內部Microsoft數據系統進行交互。 最初的功能規范寫于2018年底,到2019年初DataCop誕生了。 今天,DataCop已成為DataHub平臺的一部分,該平臺還包括數據構建和數據目錄。 Data Build以合規且可擴展的方式生成企業所需的數據集,Data Catalog是具有元數據(例如來自DataCop的數據質量得分以及訪問和隱私信息)的所有資產和表面的搜索存儲。 未來的文章將描述如何使用“數據目錄”和“數據構建”來生成度量標準和見解,以推動,指導和發展E + D業務,并充當數據質量之旅的關鍵組成部分。
建筑 (Architecture)
DataCop is designed with a mindset that no one team can solve this challenge on its own. The data ecosystem at Microsoft consists of multiple data fabrics, with data arriving in minutes to a month later. The system must be flexible and simple enough for other developers across Microsoft to add plugins and workers for adding to the data fabric or quality checks they want to build on. As a result, DataCop was built as a distributed message broker based on Azure Service Bus with quality check results stored on Cosmos DB.
DataCop的設計思想是,任何團隊都無法獨自解決這一挑戰。 Microsoft的數據生態系統由多個數據結構組成,數據在數分鐘至一個月后到達。 該系統必須足夠靈活和簡單,以使Microsoft的其他開發人員可以添加插件和工作程序,以添加到他們想要建立的數據結構或質量檢查中。 結果,DataCop被構建為基于Azure Service Bus的分布式消息代理,質量檢查結果存儲在Cosmos DB中 。
Messages in the message broker must be self-contained and allow workers to work on them exclusively. This would allow messages from Orchestrator to run scheduled checks or from an Azure Data Factory (ADF) pipeline itself. Every time a data check or new fabric needs to be added, the developer can simply implement an override and develop their own worker process without affecting the rest of the system. The Azure team leveraged this to build on it quickly, as described below.
消息代理中的消息必須是獨立的,并允許工作人員專門處理它們。 這將允許來自Orchestrator的消息運行計劃的檢查,或者來自Azure數據工廠 (ADF)管道本身的消息。 每次需要添加數據檢查或新結構時,開發人員都可以簡單地實現覆蓋并開發自己的工作進程,而不會影響系統的其余部分。 如下所述,Azure團隊利用它來快速構建它。
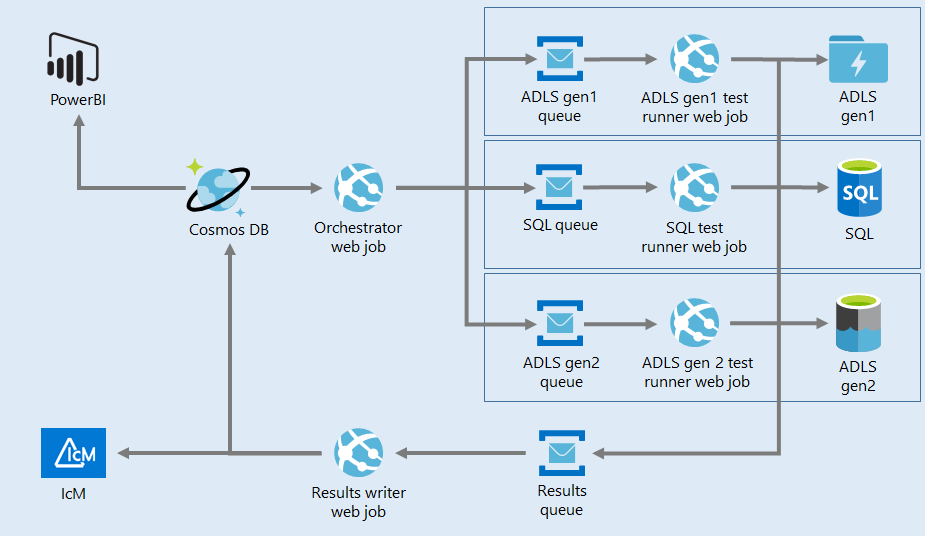
Workers are run today as Azure Web Jobs. Workers typically leverage another compute in Azure such as Azure Databricks or Azure SQL to execute quality checks against the actual data. Workers are lightweight and used to determine whether the checks are successful. This makes Azure Web Jobs a perfect fit for running them. For consistency, Orchestrator is hosted as a web job as well. Orchestrator is a time-triggered web job that generates the sets of quality checks that need to be executed and puts them in a respective worker-specific service bus queue.
今天, 工作人員作為Azure Web Jobs運行。 工作人員通常利用Azure中的另一種計算(例如Azure Databricks或Azure SQL)對實際數據執行質量檢查。 工人很輕巧,可用來確定檢查是否成功。 這使得Azure Web Jobs非常適合運行它們。 為了保持一致性,Orchestrator也作為Web作業托管。 Orchestrator是一個時間觸發的Web作業,它生成需要執行的質量檢查集,并將它們放入相應的特定于工作人員的服務總線隊列中。
The next important part of any data quality system is alerting. All Microsoft services use IcM, the company-wide incident management system. Data alerts are not like service alerts: Data arrives at a higher latency compared to typical services and can be recovered in some situations. If there is a need to restate bad data, an issue can be potentially open longer until the data is restated. So, alert suppression is set to handle a very different number of cases — data not available due to upstream issues for x days should result in one alert, and data not available downstream due to a common upstream issue should be suppressed.
任何數據質量系統的下一個重要部分是警報。 所有Microsoft服務都使用IcM(公司范圍的事件管理系統)。 數據警報與服務警報不同:與典型服務相比,數據延遲更高,并且在某些情況下可以恢復。 如果需要重述錯誤的數據,則可能需要更長的時間才能解決該問題,直到重新陳述數據為止。 因此,將警報抑制設置為處理非常不同的情況-由于x天上游問題導致的數據不可用將導致一個警報,而由于常見上游問題而導致下游數據不可用的數據將被抑制。
This is a good place to touch upon another important topic in the data quality landscape: Anomaly detection. Data volume and metrics change often and are prone to seasonality. Having an anomaly detection system that can handle seasonality helps with a move away from monitoring data volumes and daily trends to a more sophisticated system. DataCop leverages Azure anomaly detector APIs to measure completeness stats such as file size and a few key metrics along multiple dimensions. This is a work in progress with further updates to come.
這是接觸數據質量領域中另一個重要主題的好地方:異常檢測。 數據量和指標經常更改,并且容易出現季節性變化。 擁有可以處理季節性的異常檢測系統有助于從監視數據量和每日趨勢轉變為更復雜的系統。 DataCop利用Azure異常檢測器API來測量完整性統計信息,例如文件大小和沿多個維度的一些關鍵指標。 這是一項正在進行的工作,將進行進一步的更新。
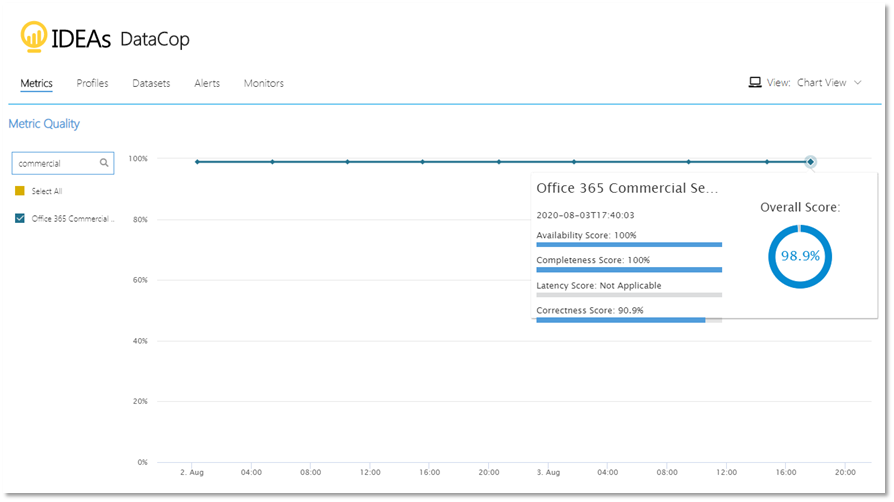
It was apparent that developers need a way to quickly author data quality checks and also deploy them. As a result, we integrated with Azure DevOps workflow to automatically deploy these data quality monitors. Today, the IDEAs team runs close to 2000 tests on about 750 key datasets that include externally reported financial metrics.
顯然,開發人員需要一種快速編寫數據質量檢查并進行部署的方法。 因此,我們與Azure DevOps工作流集成在一起,以自動部署這些數據質量監視器。 如今,IDEA團隊對約750個關鍵數據集(包括外部報告的財務指標)進行了近2000次測試。
M365與Azure之間的合作伙伴關系 (Partnership between M365 and Azure)
The Customer Growth and Analytics team (CGA) is a centralized data science team in the Cloud+AI division at Microsoft. The team’s mission is to learn from customers and empower them to make the most of Azure services.3
客戶增長和分析團隊(CGA)是Microsoft的Cloud + AI部門中的集中數據科學團隊。 該團隊的任務是向客戶學習,并使其能夠充分利用Azure服務。3
Last year, as CGA’s scope was growing, an effort began to standardize technologies. Having a smaller number of technologies upon which CGA’s data platform is built makes it easier to move engineering resources as needed, share knowledge, and in general increase the reliability of the overall system. The use of Azure PaaS offerings reduced the need for writing custom code. The team standardized on Azure Data Factory for data movement and Azure Monitor for monitoring, among others. Unfortunately, at this writing, Azure doesn’t offer a PaaS data quality testing framework.
去年,隨著CGA范圍的不斷擴大,人們開始努力使技術標準化。 使用CGA數據平臺所基于的技術數量較少,可以更輕松地根據需要移動工程資源,共享知識并總體上提高整個系統的可靠性。 使用Azure PaaS產品減少了編寫自定義代碼的需要。 該團隊在Azure數據工廠(用于數據移動)和Azure監視器(用于監視)上進行了標準化。 不幸的是,在撰寫本文時,Azure沒有提供PaaS數據質量測試框架。
CGA realized the need for a reliable and scalable data quality solution, especially as the data platform evolved to support more and more production workloads where data issues can have large impacts, and so evaluated multiple options.
CGA意識到了對可靠且可擴展的數據質量解決方案的需求,特別是隨著數據平臺的發展以支持越來越多的生產工作負載,其中數據問題可能會產生重大影響,因此評估了多種選擇。
CGA tried out several data quality testing solutions with the code base, but quickly realized they were built for smaller projects, made some rigid assumptions, and would require significant investment to scale out to cover the entire platform.
CGA使用代碼庫嘗試了幾種數據質量測試解決方案,但很快意識到它們是為較小的項目構建的,做出了一些嚴格的假設,并且需要大量投資才能擴展到整個平臺。
Discussions with other data science organizations within the company to see how they were handling this led to LinkedIn and an introduction to Data Sentinel. Its main limitation is that it runs exclusively on Spark. CGA must support multiple data fabrics: In some cases, different compute scenarios require the specific best solution for the job, such as Azure Data Explorer for analytics or Azure Data Lake Storage and Azure Machine Learning for ML workloads. In other cases, data ingested from other teams comes from a variety of storage locations: Azure SQL, blob storage, and Azure Data Lake Storage gen1, among others.
與公司內其他數據科學組織的討論,以了解他們如何處理此問題,從而導致了LinkedIn和Data Sentinel的介紹。 它的主要限制是它只能在Spark上運行。 CGA必須支持多種數據結構:在某些情況下,不同的計算方案需要特定的最佳解決方案來完成工作,例如用于分析的Azure Data Explorer或用于ML工作負載的Azure Data Lake Storage和Azure Machine Learning 。 在其他情況下,從其他團隊提取的數據來自各種存儲位置:Azure SQL,blob存儲和Azure Data Lake Storage gen1等。
Further outreach led to discussions with the M365 data science team and led to an introduction to DataCop, the solution described in this article. Its capabilities were compelling: Test scheduling, integration with the standard Microsoft alerting platform, and a declarative way of describing tests. Its main limitation was that DataCop didn’t support Azure Data Explorer.
進一步的擴展導致與M365數據科學團隊的討論,并導致對DataCop(本文中描述的解決方案)進行了介紹。 它的功能引人注目:測試計劃,與標準Microsoft警報平臺的集成以及描述測試的聲明方式。 它的主要限制是DataCop不支持Azure Data Explorer。
Because Azure Data Explorer (ADX) is core to CGA’s platform, this could have been a showstopper, but in true One Microsoft spirit, the DataCop team was more than happy to work with CGA to light up the missing capability. The teams agreed to treat this as an “internal open source” project, with CGA contributing code to the DataCop solution from which both teams could benefit. Due to its flexible design, adding ADX capabilities was significantly easier than the alternative (investing in a home-grown solution).
因為Azure數據資源管理器(ADX)是CGA平臺的核心,所以這本來可以成為熱門。但是,本著一種Microsoft的精神,DataCop團隊非常樂意與CGA合作以減輕缺失的功能。 團隊同意將其視為“內部開源”項目,CGA向DataCop解決方案貢獻代碼,這兩個團隊都可以從中受益。 由于其靈活的設計,添加ADX功能比選擇其他方法(投資自家解決方案)要容易得多。
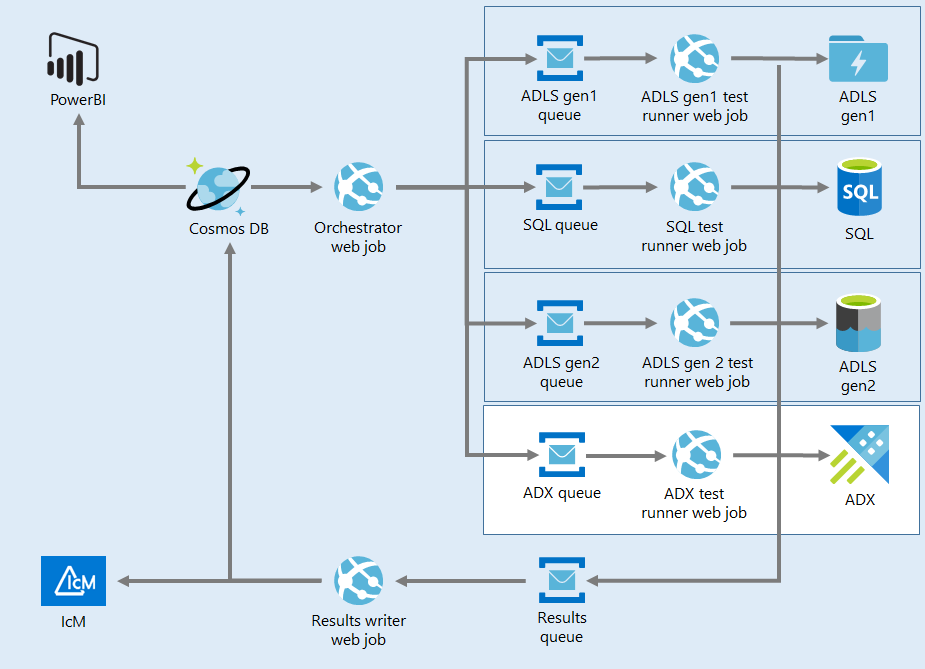
CGA deployed an instance of DataCop in its environment and over the following months had a big data quality push, including training the team on how to author tests and increasing test coverage to 100 percent of the datasets in CGA’s platform. At the time of writing, CGA has around 400 tests covering close to 300 key datasets. Over the past 30 days, CGA ran more than 4000 tests, identifying and quickly acting to mitigate multiple data issues that would have caused significant anomalies in CGA’s system. Onboarding DataCop saved significant engineering effort, which was refocused on test authoring.
CGA在其環境中部署了一個DataCop實例,并且在接下來的幾個月中,數據質量得到了很大的推動,包括培訓團隊如何編寫測試以及將測試覆蓋率提高到CGA平臺中100%的數據集。 在撰寫本文時,CGA擁有約400個測試,涵蓋了近300個關鍵數據集。 在過去的30天里,CGA運行了4000多個測試,識別并Swift采取措施來緩解可能導致CGA系統出現重大異常的多個數據問題。 入職的DataCop節省了大量的工程設計工作,這些工作重新集中在測試創作上。
總結思想/總結 (Closing thoughts/summary)
This article described DataCop, the data quality solution developed by the M365 data team in partnership with the Azure data team.
本文介紹了DataCop,它是M365數據團隊與Azure數據團隊合作開發的數據質量解決方案。
- Data quality is a critical aspect of a business, both for informing decisions and for regulatory obligations. 數據質量對于通知決策和監管義務都是業務的關鍵方面。
- The diverse data fabrics in use and their huge scale led to development of DataCop, a data quality solution for supporting the Microsoft business. 使用中的各種數據結構及其巨大規模促成了DataCop的發展,DataCop是一種支持Microsoft業務的數據質量解決方案。
- DataCop is a cloud-native Azure solution, consisting of a set of web jobs that communicate via service bus. DataCop是云原生的Azure解決方案,由一組通過服務總線進行通信的Web作業組成。
- The plug-in architecture allowed the CGA team to quickly develop an Azure Data Explorer test runner and expand the scope of DataCop from the M365 team to also cover the Azure business. 插件體系結構使CGA團隊可以快速開發Azure Data Explorer測試運行程序,并從M365團隊擴展DataCop的范圍,以涵蓋Azure業務。
- Today, DataCop runs hundreds of tests every day to ensure the quality of data throughout multiple systems on both teams. 今天,DataCop每天運行數百個測試,以確保兩個團隊中多個系統的數據質量。
Vlad Ri?cu?ia is on LinkedIn.
Vlad Ri?cu?ia在 LinkedIn上 。
[1] The Four V’s of Big Data, IBM, 2016.
[1] 大數據的四個V ,IBM,2016年。
[2] Data Sentinel: Automating Data Validation, LinkedIn, March 2010.
[2] 數據前哨:自動化數據驗證 ,LinkedIn,2010年3月。
[3] Using Azure to Understand Azure, by Ron Sielinski, January 2020.
[3] Ron Sielinski于2020年1月使用 “ 使用Azure來理解Azure” 。
翻譯自: https://medium.com/data-science-at-microsoft/partnering-for-data-quality-dc9123557f8b
數據質量提升
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388214.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388214.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388214.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章
解決第三方庫引發的問題)
黑魔法(method-swizzling)解決第三方庫引發的問題
)
Python 操作 MySQL 的5種方式(轉)

unity3d 人員控制代碼

刪除wallet里面登機牌_登機牌丟失問題

PHP 備份還原 MySql 數據庫
)
Java? 教程(Queue接口)

字符串操作截取后面的字符串_對字符串的5個必知的熊貓操作

最新 Unity3D鼠標滑輪控制物體放大縮小 [

sublime-text3 安裝 emmet 插件

數據科學家訪談錄 百度網盤_您應該在數據科學訪談中向THEM提問。
![unity3d]鼠標點擊地面人物自動走動(也包含按鍵wasdspace控制)](http://pic.xiahunao.cn/unity3d]鼠標點擊地面人物自動走動(也包含按鍵wasdspace控制))
unity3d]鼠標點擊地面人物自動走動(也包含按鍵wasdspace控制)
)
uva 524(Prime Ring Problem UVA - 524 )


power bi函數_在Power BI中的行上使用聚合函數

關于如何在Python中使用靜態、類或抽象方法的權威指南

廣義估計方程估計方法_廣義估計方程簡介


Unity3d鼠標點擊屏幕來控制人物的走動

Java中的ReentrantLock和synchronized兩種鎖定機制的對比
