字符串操作截取后面的字符串
We have to represent every bit of data in numerical values to be processed and analyzed by machine learning and deep learning models. However, strings do not usually come in a nice and clean format and require preprocessing to convert to numerical values. Pandas offers many versatile functions to modify and process string data efficiently.
我們必須以數值表示數據的每一位,以便通過機器學習和深度學習模型進行處理和分析。 但是,字符串通常不會采用簡潔的格式,需要進行預處理才能轉換為數值。 熊貓提供了許多通用功能,可以有效地修改和處理字符串數據。
In this post, we will discover how Pandas can manipulate strings. I grouped string functions and methods under 5 categories:
在本文中,我們將發現Pandas如何操縱字符串。 我將字符串函數和方法分為5類:
Splitting
分裂
Stripping
剝離
Replacing
更換
Filtering
篩選
Combining
結合
Let’s first create a sample dataframe to work on for examples.
讓我們首先創建一個示例數據框以進行示例。
import numpy as np
import pandas as pdsample = {
'col_a':['Houston,TX', 'Dallas,TX', 'Chicago,IL', 'Phoenix,AZ', 'San Diego,CA'],
'col_b':['$64K-$72K', '$62K-$70K', '$69K-$76K', '$62K-$72K', '$71K-$78K' ],
'col_c':['A','B','A','a','c'],
'col_d':[' 1x', ' 1y', '2x ', '1x', '1y ']
}df_sample = pd.DataFrame(sample)
df_sample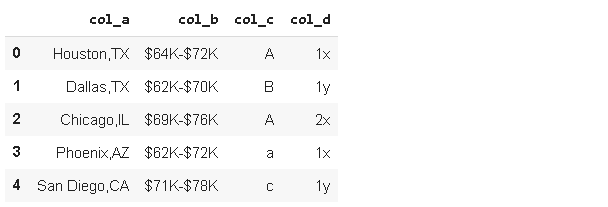
1.分裂 (1. Splitting)
Sometimes strings carry more than one piece of information and we may need to use them separately. For instance, “col_a” contains both city and state. The split function of pandas is a highly flexible function to split strings.
有時字符串包含不止一條信息,我們可能需要單獨使用它們。 例如,“ col_a”包含城市和州。 pandas的split函數是用于拆分字符串的高度靈活的函數。
df_sample['col_a'].str.split(',')0 [Houston, TX]
1 [Dallas, TX]
2 [Chicago, IL]
3 [Phoenix, AZ]
4 [San Diego, CA]
Name: col_a, dtype: objectNow each element is converted to a list based on the character used for splitting. We can easily export individual elements from those lists. Let’s create a “state” column.
現在,每個元素都會根據用于拆分的字符轉換為列表。 我們可以輕松地從這些列表中導出單個元素。 讓我們創建一個“狀態”列。
df_sample['state'] = df_sample['col_a'].str.split(',').str[1]df_sample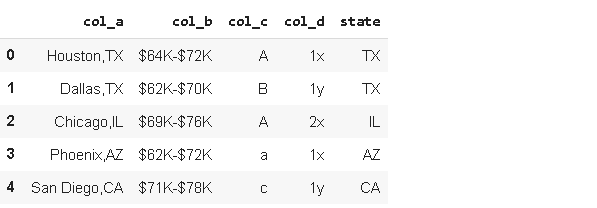
Warning: Subscript ([1]) must be applied with str keyword. Otherwise, we will get the list in the specified row.
警告 :下標([1])必須與str關鍵字一起應用。 否則,我們將在指定的行中獲取列表。
df_sample['col_a'].str.split(',')[1]
['Dallas', 'TX']The splitting can be done on any character or letter.
可以對任何字符或字母進行拆分。
The split function returns a dataframe if expand parameter is set as True.
如果將expand參數設置為True,則split函數將返回一個數據幀。
df_sample['col_a'].str.split('a', expand=True)
拆分vs rsplit (split vs rsplit)
By default, splitting is done from the left. To do splitting on the right, use rsplit.
默認情況下,拆分是從左側開始的。 要在右側進行拆分,請使用rsplit 。
Consider the series below:
考慮以下系列:

Let’s apply split function and limit the number of splits with n parameter:
讓我們應用split函數并使用n參數限制拆分次數:
categories.str.split('-', expand=True, n=2)
Only 2 splits on the left are performed. If we do the same operation with rsplit:
左側僅執行2個拆分。 如果我們對rsplit執行相同的操作:
categories.str.rsplit('-', expand=True, n=2)
Same operation is done but on the right.
完成相同的操作,但在右側。
2.剝離 (2. Stripping)
Stripping is like trimming tree branches. We can remove spaces or any other characters at the beginning or end of a string.
剝離就像修剪樹枝。 我們可以刪除字符串開頭或結尾的空格或任何其他字符。
For instance, the strings in “col_b” has $ character at the beginning which can be removed with lstrip:
例如,“ col_b”中的字符串開頭有$字符,可以使用lstrip將其刪除:
df_sample['col_b'].str.lstrip('$')0 64K-$72K
1 62K-$70K
2 69K-$76K
3 62K-$72K
4 71K-$78K
Name: col_b, dtype: objectSimilary, rstrip is used to trim off characters from the end.
類似地, rstrip用于從末尾修剪字符。
Strings may have spaces at the beginning or end. Consider “col_d” in our dataframe.
字符串的開頭或結尾可以有空格。 考慮一下我們數據框中的“ col_d”。

Those leading and trailing spaces can be removed with strip:
那些前導和尾隨空格可以用strip除去:
df_sample['col_d'] = df_sample['col_d'].str.strip()
3.更換 (3. Replacing)
Pandas replace function is used to replace values in rows or columns. Similarly, replace as a string operation is used to replace characters in a string.
熊貓替換功能用于替換行或列中的值。 同樣,替換為字符串操作用于替換字符串中的字符。
Let’s replace “x” letters in “col_d” with “z”.
讓我們用“ z”替換“ col_d”中的“ x”個字母。
df_sample['col_d'] = df_sample['col_d'].str.replace('x', 'z')
4.篩選 (4. Filtering)
We can filter strings based on the first and last characters. The functions to use are startswith() and endswith().
我們可以根據第一個和最后一個字符來過濾字符串。 要使用的函數是startswith()和endswith() 。
Here is our original dataframe:
這是我們的原始數據框:
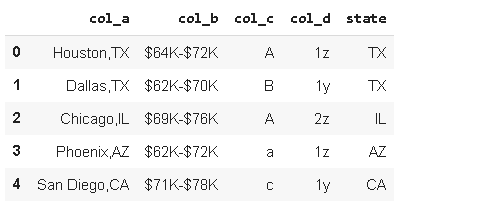
Here is a filtered version that only includes rows in which “col_a” ends with the letter “x”.
這是一個過濾的版本,僅包含“ col_a”以字母“ x”結尾的行。
df_sample[df_sample['col_a'].str.endswith('X')]
Or, rows in which “col_b” starts with “$6”:
或者,其中“ col_b”以“ $ 6”開頭的行:
df_sample[df_sample['col_b'].str.startswith('$6')]
We can also filter strings by extracting certain characters. For instace, we can get the first 2 character of strings in a column or series by str[:2].
我們還可以通過提取某些字符來過濾字符串。 對于instace,我們可以通過str [:2]獲得列或系列中字符串的前2個字符。
“col_b” represents a value range but numerical values are hidden in a string. Let’s extract them with string subscripts:
“ col_b”表示值范圍,但數值隱藏在字符串中。 讓我們用字符串下標提取它們:
lower = df_sample['col_b'].str[1:3]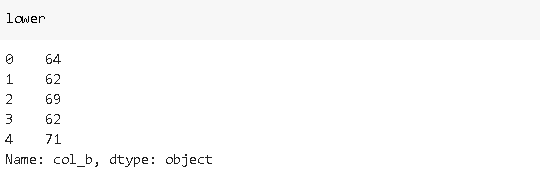
upper = df_sample['col_b'].str[-3:-1]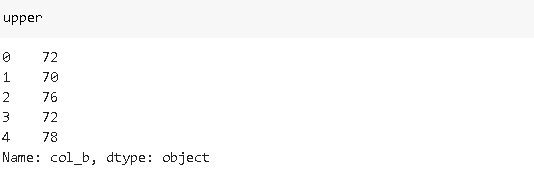
5.結合 (5. Combining)
Cat function can be used to concatenate strings.
Cat函數可用于連接字符串。
We need pass an argument to put between concatenated strings using sep parameter. By default, cat ignores missing values but we can also specify how to handle them using na_rep parameter.
我們需要傳遞一個參數,以使用sep參數在串聯字符串之間放置。 默認情況下,cat會忽略缺失值,但我們也可以使用na_rep參數指定如何處理它們。
Let’s create a new column by concatenating “col_c” and “col_d” with “-” separator.
讓我們通過將“ col_c”和“ col_d”與“-”分隔符連接起來創建一個新列。
df_sample['new']=df_sample['col_c'].str.cat(df_sample['col_d'], sep='-')df_sample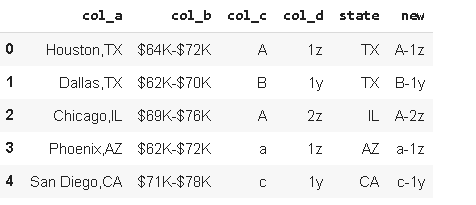
獎勵:對象與字符串 (Bonus: Object vs String)
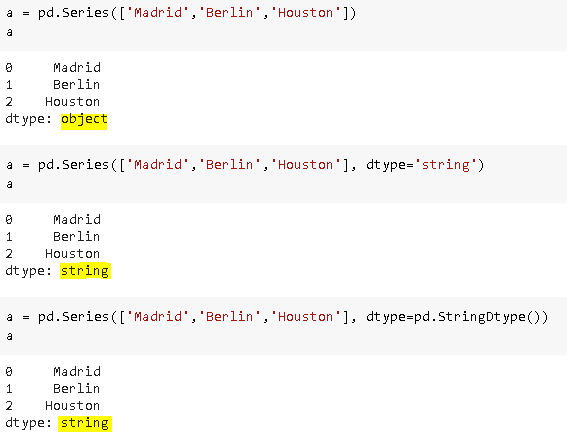
Before pandas 1.0, only “object” datatype was used to store strings which cause some drawbacks because non-string data can also be stored using “object” datatype. Pandas 1.0 introduces a new datatype specific to string data which is StringDtype. As of now, we can still use object or StringDtype to store strings but in the future, we may be required to only use StringDtype.
在pandas 1.0之前,僅使用“對象”數據類型存儲字符串,這會帶來一些缺點,因為非字符串數據也可以使用“對象”數據類型進行存儲。 Pandas 1.0引入了特定于字符串數據的新數據類型StringDtype 。 到目前為止,我們仍然可以使用object或StringDtype來存儲字符串,但是在將來,可能需要我們僅使用StringDtype。
One important thing to note here is that object datatype is still the default datatype for strings. To use StringDtype, we need to explicitly state it.
這里要注意的一件事是對象數據類型仍然是字符串的默認數據類型。 要使用StringDtype,我們需要明確聲明它。
We can pass “string” or pd.StringDtype() argument to dtype parameter to string datatype.
我們可以將“ string ”或pd.StringDtype()參數傳遞給dtype參數,以傳遞給字符串數據類型。
Thank you for reading. Please let me know if you have any feedback.
感謝您的閱讀。 如果您有任何反饋意見,請告訴我。
翻譯自: https://towardsdatascience.com/5-must-know-pandas-operations-on-strings-4f88ca6b8e25
字符串操作截取后面的字符串
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388207.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388207.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388207.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

最新 Unity3D鼠標滑輪控制物體放大縮小 [

sublime-text3 安裝 emmet 插件

數據科學家訪談錄 百度網盤_您應該在數據科學訪談中向THEM提問。
![unity3d]鼠標點擊地面人物自動走動(也包含按鍵wasdspace控制)](http://pic.xiahunao.cn/unity3d]鼠標點擊地面人物自動走動(也包含按鍵wasdspace控制))
unity3d]鼠標點擊地面人物自動走動(也包含按鍵wasdspace控制)
)
uva 524(Prime Ring Problem UVA - 524 )


power bi函數_在Power BI中的行上使用聚合函數

關于如何在Python中使用靜態、類或抽象方法的權威指南

廣義估計方程估計方法_廣義估計方程簡介


Unity3d鼠標點擊屏幕來控制人物的走動

Java中的ReentrantLock和synchronized兩種鎖定機制的對比

10.15 lzxkj

大數定理 中心極限定理_中心極限定理:直觀的遍歷

萬惡之源 - Python數據類型二

230. Kth Smallest Element in a BST
-不要問如何,不要問什么)
探索性數據分析(EDA)-不要問如何,不要問什么

unity3d 攝像機跟隨鼠標和鍵盤的控制

《必然》九、享受重混盛宴,是每個人的機會
